이학석사학위논문 규칙과기계학습을이용한한국어 상호참조해결 박천음 강원대학교대학원 컴퓨터과학과
|
|
|
- 나은 지
- 5 years ago
- Views:
Transcription
1 이학석사학위논문 규칙과기계학습을이용한한국어 상호참조해결 박천음 강원대학교대학원 컴퓨터과학과
2 2016 년 02 월이창기교수지도 이학석사학위논문 규칙과기계학습을이용한한국어 상호참조해결 Coreference Resolution for Korean using Rule and Machine Learning 강원대학교대학원 컴퓨터과학과 박천음
3 박천음의석사학위논문을 합격으로판정함 2016 년 02 월 심사위원장최미정인 위원이창기인 위원임현승인
4 규칙과기계학습을이용한한국어상호참조해결 박천음 강원대학교대학원컴퓨터과학과 상호참조해결 (Coreference Resolution) 이란같은의미의단어들을군집화 (clustering) 하는것을말한다. 즉, 어떤개체에대한여러표현들이서로간의참조관계를이루고있는데, 이관계를밝히는것이상호참조해결이다. 멘션 (mention) 은상호참조해결을수행하기위한후보단어들의집합으로, 명사또는명사구를기반으로추출하며, 이과정을멘션탐지 (Mention Detection) 라한다. 본논문에서는한국어상호참조해결을위해딥러닝 (Deep Learning) 을이용하는멘션페어모델을제안하고, 다단계시브 (Multi-pass Sieve) 기반의규칙기반시스템과딥러닝기반의멘션페어 (Mention Pair) 모델을같이사용하는시스템을제안한다. 실험결과, 본논문에서제안한시스템이규칙과통계를각각사용하는시스템보다좋은성능을보였다. i
5 목 차 1. 서론 1 2. 관련연구 규칙기반상호참조해결 기계학습기반상호참조해결 4 3. 문제정의 상호참조해결 (Coreference Resolution) 멘션및엔티티 (Mention and Entity) 7 4. 상호참조해결을위한멘션탐지 규칙기반멘션탐지 (Mention Detection) 딥러닝을이용한멘션탐지 Feed-forward Neural Network (FFNN) Recurrent Neural Network (RNN) Long Short-term Memory RNN (LSTM-RNN) LSTM Recurrent CRF (LSTM-CRM) Bidirectional LSTM-CRF (Bi-LSTM-CRF) 멘션탐지에사용한자질 23 ii
6 4.3.1 일반자질 추가자질 다단계시브를이용한한국어상호참조해결 다단계시브 (Multi-pass Sieve) Sieve 0: 불가능한상호참조 (Impossible Coreference) Sieve 1: 정확한문자열매치 (Exact String Match) Sieve 2: 엄밀한구문 (Precise Construct) 엄밀한구문 : 동격역할 (Role Appositive) 엄밀한구문 : 약어 (Acronym) Sieve 3, 4, 5: 엄격한중심어일치 (Strict Head Match 3, 4, 5) 단어포함 호환가능한수식어 Not I within I Sieve 6: 고유중심어일치 (Proper Head Match) Sieve 7: 관대한중심어일치 (Relaxed Head Match) Sieve 8: 대명사상호참조해결 (Pronominal Coreference Resolution) 확장된대명사상호참조해결 후처리 (Post Processing) 기계학습기반한국어상호참조해결 딥러닝을이용한멘션페어모델 (Mention Pair Model) 41 iii
7 6.2 가이드멘션페어모델 (Guided Mention Pair Model) 자질 (Features) 실험및결과 실험데이터 멘션탐지실험 실험환경 성능실험결과 상호참조해결실험 평가방법 성능실험결과 규칙기반실험결과 하이브리드상호참조해결실험결과 딥러닝을이용한멘션탐지적용실험결과 결론 59 참고문헌 63 iv
8 그림목차 그림 1. 한국어상호참조해결시스템. 6 그림 2. 멘션탐지그래프. 12 그림 3. 멘션탐지알고리즘. 15 그림 4. FFNN 기반멘션탐지. 18 그림 5. RNN 모델. 19 그림 6. Long Short-Term Memory Cell. 20 그림 7. LSTM Recurrent CRF 모델. 21 그림 8. Bidirectional LSTM-CRF. 23 그림 9. 다단계시브를이용한상호참조해결. 28 그림 10. 단어표현을이용한차원축소. 42 그림 11. 상호참조해결을위한신경망구조. 43 그림 12. SNN을이용한일반멘션상호참조해결. 62 그림 13. Ptr Net을이용한대명사상호참조해결. 62 v
9 표목차 표 1. 엔티티데이터구조. 8 표 2. 멘션탐지를수행한예. 13 표 3. 긴문장에대한멘션탐지. 15 표 4. 멘션간의크로스문제. 16 표 5. 오류누적에의한멘션탐지오류. 16 표 6. 안은멘션과안긴멘션의 BIO 표현. 24 표 7. 단어포함의예. 32 표 8. 호환가능한수식어의예. 32 표 9. 고유중심어일치예. 34 표 10. 요소의특징에따른가중치. 36 표 11. 대명사상호참조해결예. 37 표 12. 후처리를수행한예. 40 표 13. 딥러닝상호참조해결에사용한자질. 44 표 14. 기계학습기반학습데이터정의. 45 표 15. 멘션탐지실험결과 (F1) 46 표 16. 규칙기반상호참조해결의시브단계별성능 ( 멘션바운더리 ). 50 표 17. 규칙기반상호참조해결의시브단계별성능 ( 중심어바운더리 ). 51 vi
10 표 18. 전체데이터에대한규칙기반상호참조해결성능. 54 표 19. 신경망의입력 ( 단어및자질 ). 54 표 20. 딥러닝파라미터최적화. 55 표 21. 하이브리드상호참조해결성능. 55 표 22. 딥러닝멘션탐지를적용한상호참조해결성능 57 vii
11 1. 서론 자연어 (Natural language) 는사람이의사를표현하거나전달할때사용하는수단이다. 특히, 어떤개체 (Entity) 를표현할때해당개체의의미에대하여고유의이름 ( 또는명칭 ) 등을정의하여전달한다. 즉, 모든개체는개체를표현하는단어로정의되며, 문맥에서어떤개체를표현할때위와같이정의된이름을이용하여표현한다. 그러나자연어는나라마다표현하는방법이다르고, 사람에따라해당개체를약어 (acronym) 나별명 (anonymity, demonym) 등을이용하여재표현하는경우가있다. 또한문맥내에서해당개체를계속표현할경우에는같은이름으로표현하기보다, 대명사 (pronoun) 나한정명사구 (determiner) 등을이용하는것이문맥상더욱자연스럽다. 이와같이, 특정개체를표현할때고유의이름뿐만아니라다른표현을이용하여재표현하는것을대용어 (anaphora) 또는상호참조 (coreference) 라고한다. 대용어와상호참조는언어적규칙으로어떤개체를가리키고있는단어들을찾는목적은유사하지만정의하는규칙에차이가있다. 먼저대용어는문맥의흐름에따라등장하는단어순서대로같은개체를찾아정의하는개념이다. 즉, 현재등장하는단어가선행사가되고다음에등장하는단어가앞서언급한선행사의의미 ( 즉, 대명사또는별명등을통하여 ) 를받게된다면, 해당단어와선행사는대용어관계이다. 이런특성을전이적특성 ( 즉, A B) 이라하며, 대용어해결은전이적특성기반으로문제를정의한다. 상호참조해결은좀더까다로운규칙을갖는다. 사람은글을읽을때집중하는부분이문맥에따라이동하기때문에상호참조해결도기본적으로전이적특성을포함하게되며, 여기에더하여재귀적, 대칭적특성도갖는다. 즉, 전이적특성은 A is B (A B), B is C (B C), 재귀적특성은 C is B (C B), B is A (B A), 대칭적특성은 A == C와같다. 따라서상호참조해결은임의의개체에대하여표현한단어들이서로다를때, 이단어들을상호참조관계로군집화 (clustering) 하여표현할수있다. 대용어해결과상호참조해결에대하여예를들면다음과같다. 영국전원지방을무대로사 랑과연애를다룬다. 와같은문장에서대용어해결은전이적특성때문에 [ 영국전원지방 ] 을 [ 무대 ] 로받을수있다. 하지만상호참조해결에서는 [ 영국전원지방 ] 과 [ 무대 ] 는엄연히서로 1
12 다른개체이므로서로참조가불가능하다. 그러나두단어가시간정보나공간정보등에관하여좀더명확한의미를갖고같은개체를가리킨다면서로참조가가능하다. 즉, 광화문 ( 光化門 ) 은경복궁의남쪽에있는정문이며 와같은문장에서 [ 광화문 ( 光化門 )] 과 [ 경복궁의남쪽에있는정문 ] 의의미는명확하며, 서로같은 광화문 을가리키고있다 ( 즉, 앞에서정의한상호참조해결 3가지규칙에성립한다 ). 따라서이둘은서로상호참조해결이가능하다. 상호참조해결의또다른예로는다음과같다. 질의문서 : 조선왕조시기인재양성을위해유학교육등을실시한최고교육기관은무엇인가?, 정답문서 : 성균관 ( 成均館 ) 은고려말부터이어진조선의최고교육기관이다., 한국의옛대학으로그명칭은고려충렬왕때국학을성균관으로개명한데서비롯하였다. 와같은질의응답문서가있다. 이경우에질문문서에서말하는 [~ 최고교육기관, 무엇 ] 은정답문서의 [ 성균관 ( 成均館 ), 고려말부터이어진조선의최고교육기관, 한국의옛대학 ( 大學 ), 성균관 ] 들과연관되므로, 질문에서말하는 ~ 최고교육기관 이 성균관 ( 成均館 ) 임을알수있다. 이와같은특성을가진상호참조해결은자연언어로쓰여진문서를요약하거나, 대용어와유의어를포함한문서를검색할때사용된다. 또한요약된문서의정확도를높이고, 검색시, 조회된문서의재현율 (recall) 을높일수있으며, 이를응용하여자연어이해 (Natural language understanding) 나질의응답 (Question & answering), 정보추출 (Information extraction) 문제등에유용하게사용될수있다. 2
13 2. 관련연구 상호참조해결은정보추출 (Information extraction) 기술중하나로같은개체를서로다르게표현한단어들을찾아주는방법이며의미분석과질의응답등에응용된다. 기존상호참조해결에대한연구는규칙기반과기계학습기반으로나눌수있으며, 서로독립적으로연구되어왔다. 본논문에서는이런상호참조해결에관하여규칙기반과기계학습기반을각각개발하고이둘을같이사용하는방법을제안한다. 본논문의구성은다음과같다. 본 2장에서규칙기반및기계학습기반상호참조해결에대한관련연구를소개하고, 3장에서는상호참조해결에대한용어정의와본논문에서제안한시스템에대하여소개한다. 그이후본논문은크게두가지로나뉘는데, 먼저 4장에서멘션탐지 (Mention Detection) 에대한정의및방법을설명한다. 멘션탐지는상호참조해결을수행하기위한시작부분의문제이지만, 그문제를정확하게해결하기에는쉽지않기때문에규칙기반및기계학습기반등을사용한다. 이에따라멘션탐지에대한규칙기반방법과기계학습기반방법에대하여자세히설명한다. 그다음으로 5장과 6장에서각각규칙기반과기계학습기반상호참조해결에대하여설명하며, 5장에서다단계시브 (Multi-pass sieve) 를이용한규칙기반상호참조해결에대하여자세히다루고, 6장에서멘션페어 (Mention pair) 를이용한기계학습기반상호참조해결에대하여설명한다. 그리고 7장에서상호참조해결에대한실험및결과를보이고 8장을마지막으로논문의결론을내린다. 2.1 규칙기반상호참조해결 본논문에서는 Stanford의다단계시브 [1] 를한국어에적용하여규칙기반상호참조해결을수행하였다 [2]. 다단계시브는엔티티중심 (Entity-centric coreference) 에기반하여상호참조해결을수행하는데, 이것은임의의개체에대하여참조해결된멘션들을 entity cluster(i.e., 엔티티 ) 로다루고, 각엔티티에포함된멘션들간에는서로의속성을공유하는특성을가진다. 상호참조해결에서최종적으로수행하는것은바로대명사해결이다. 즉, 대명사해결을위 3
14 하여각시브마다참조관계를파악하고하나의엔티티로군집화를수행하는것이다. 이런대명사에대한해결방법으로는주로대용어해결이사용되어왔다. 이중크게세가지모델이있는데, 바로중심화이론 (Centering theory) 과 Hobbs 알고리즘 (Hobbs algorithm), RAP (Resolution of Anaphora Procedure) 알고리즘이다 [3, 4, 5, 6]. 앞서언급한세가지모델들의공통점은바로주어의중심어 (head) 가문장에서가장큰영향력이있다고보고대용어해결을진행하는것이다. 그러나두모델 ( 중심화이론 [3], Hobbs 알고리즘 [4]) 은각각에대하여문장이길어지거나문법구조가복잡해지는경우, 대명사해결이어려워진다. 그리고영어권에서제안된것이라한국어에맞춰재해석하기에어려움이있으며, Hobbs는문법트리에기반하고있다. 그와반대로 RAP 알고리즘은문법의복잡함에있어독립적이며, 본논문에서사용하는의존트리 (Dependency tree) 에적용하기어렵지않다. 더하여 RAP 알고리즘의특성은중심화이론에서중요시여기는몇가지요소 ( 즉, grammatical role, recency, repeated mention, current discourse topic, parallelism)[5] 들을내포하며, 문법체계에서의특징을두드러지게표현하여사용하였다 ( 즉, 문법구조상각특징들을점수화하였다 ). RAP 알고리즘과중심화이론의추가적인설명은 5.7장을참고하며, 본논문에서의대명사해결은중심화이론과 RAP 알고리즘, 다단계시브방법을이용한다. 이에따라, 본논문은규칙기반시스템에엔티티중심의다단계시브를적용하여적합함 을보이고, 그이후에다단계시브로부터추출한자질들을이용하여기계학습기반과결합할 것을제안한다. 2.2 기계학습기반상호참조해결 기계학습기반상호참조해결은 [7] 과같이기계학습을멘션페어 (Mention pair), 멘션랭킹 (Mention ranking) 등의모델에적용하여처리한다. 이런모델들과함께사용되는기계학습방법은 Support Vector Machine (SVM), Neural Network (NN) 등이있다. 이에따라, [8] 에서는 SVM과함께멘션페어모델을이용하여한국어상호참조해결을진행할것을제안했지만, 학습데이터의부족과자질디자인에대한어려움으로인해좋은성능을보이지못했다. 4
15 기계학습기반은일반적으로규칙기반에비해더좋은성능을보이지만자질디자인이잘되어야하는제한이있다. 즉, 일반적인기계학습은사람이직접자질을추출하고최적의자질조합을찾아야하며, 여기에는많은시간과노력이필요하다. 그러나최근딥러닝 (Deep learning) 의등장으로기계학습의이런어려움들을극복할수있게되었다 [9, 10]. 딥러닝은사람의뇌를모방하여만든인공신경망 (Artificial neural network) 에서확장된방법으로, 여러층의히든레이어 (Hidden layer) 를기반으로구성되며, 각레이어마다비선형의활성함수 (Activation function) 를이용한다. 또한학습에는역전파 (Back-propagation) 방법을이용하여가중치들을갱신한다. 딥러닝은자질디자인 (Feature design) 에대한자동화가가능하고, 레이어가깊어질수록더욱높은수준의추상화를진행할수있다. 그러나신경망의레이어가깊어지면계산량이많아져학습시간이오래걸리고학습이어려워진다. 이에따라, 딥러닝에서는사전학습 (Pre-training), 드랍아웃 (drop-out), Rectifier Linear hidden Unit (ReLU) 등의방법을고안하여문제를해결하였다 [11, 12, 13]. 본논문에서는 [8] 의문제를해결하기위하여딥러닝기반멘션페어모델을적용한기 계학습기반상호참조해결을수행하고, 이를확장한가이드자질을사용할것을제안한다. 5


16 3. 문제정의 3.1 상호참조해결 상호참조해결은임의의개체를표현한단어들간의관계를해결해주는것으로, 1장에서언급했듯이전이적, 재귀적, 대칭적인특성을만족해야한다. 즉, 특정개체에대하여설명하는문서내에서개체의고유명사가등장하고, 그이후로해당개체의별명또는약어등이나대명사로표현한경우에그단어들은서로상호참조관계에포함되어있다. 따라서상호참조해결은문서내에서이런관계를명확히밝혀서군집화하는것이다. 자연어처리시스템은보통규칙기반과기계학습기반으로나뉘는데, 상호참조해결도마찬가지로규칙기반과기계학습기반의방법으로수행할수있다. 본논문에서의상호참조해결시스템은이런규칙기반과기계학습기반을함께사용하며, 시스템구조는 [ 그림 1] 과같다. 6
17 그림 1. 한국어상호참조해결시스템 [ 그림 1] 은언어분석기로부터추출한정보들을입력으로한다 ( 즉, 언어분석기를이용하여임의의문서로부터형태소, 개체명, POS-tagging, SRL, 의존트리정보등을추출한다 ). 먼저의존트리정보에의하여가능한모든멘션을추출한다. 그리고규칙기반인엔티티중심의다단계시브를이용하여상호참조를해결한다. 그다음으로, 규칙기반시스템의결과를자질로사용하는딥러닝기반멘션페어모델을적용하여규칙기반의결과를새로갱신한다. 마지막으로, 후처리를통하여상호참조해결의최종결과를추출한다. 3.2 멘션및엔티티 상호참조해결을후보멘션들을기반으로참조관계를파악하고상호참조가가능한멘션들간 의엔티티를생성해간다. 멘션 (mention) 은상호참조해결의대상이되는모든명사구 ( 즉, 명사, 명사구등 ) 를의미한다. 각멘션에서실질적인의미를나타내는단어를중심어 (head) 라고하며, 멘션은중심어를중심으로이를수식하는수식어를포함한다. 본논문에서는멘션을생성할때의존구문분석기의결과인의존트리를기반으로하며, 기본적으로모든형태의명사구들을멘션으로선택한다. 시스템내에서멘션을생성하면각멘션은어절의인덱스에기반한다 ( 자세한설명은 4장을참조한다 ). 멘션은수식어를포함한멘션바운더리 (mention boundary) 와중심어만가지는중심어바운더리 (head boundary) 등두가지기준으로나뉜다. 먼저멘션바운더리는수식어를포함하기때문에멘션의시작인덱스는멘션의첫수식어의위치가되고멘션의중심어의위치가멘션의마지막인덱스가된다 ( 예를들어, 꼬리가짧은고양이가지나갔다. 의경우, [ 꼬리가짧은고양이 ], start_eid: 0, end_eid: 2와같다 ). 다음으로중심어바운더리는멘션의시작과끝이오직중심어를가리키는것으로, 예를들어앞서설명한문장과같은경우, [ 고양이 ], start_eid: 2, end_eid: 2와같이나타낸다 ([ 표 1] 의엔티티구조참고 ). 이와같이멘션바운더리는시스템내에서수식어관계가명확하여상호참조해결의규칙기반에서쉽게이용가능하다. 이에반해, 중심어바운더리는수식어정보가정의되지않았기때문에시스템내의알고리즘이복잡해진다. 그러나상호참조해결의성능측정척도 (measure) 에 7
18 서는멘션바운더리를포함하지않기때문에상호참조해결자체의성능을확인할경우, 중 심어바운더리를이용하는것이더좋은성능을보인다 ( 성능측정척도는멘션의시작위치 도성능측정에포함됨, 자세한표현은 7 장참고 ). 엔티티 (entity) 는서로참조가가능한멘션들의집합이다. 본논문에서는엔티티중심에기반하기때문에선행멘션 (antecedent) 과현재등장한멘션 (current mention) 간의상호참조를해결할때, 이전에참조된멘션정보와엔티티의속성을이용할수있다. 예를들어, { 토니블레어총리, 토니블레어, 그, 블레어 } 와같이하나의엔티티로묶인멘션들은서로가가진속성들 ( 즉, animacy, number, type 등 ) 을공유할수있다. 이와같이, 멘션과엔티티는상호참조해결을수행하는데기본단위가되며, 상호참조해 결이수행되기전의멘션들을후보멘션 (candidate) 이라하고, 참조해결과정중에등장한 현재멘션이전의후보멘션들을선행멘션이라한다. 본논문에서의엔티티에대한구조는 JSON 을기반으로구성되며, [ 표 1] 과같이나타낸 다. [ 표 1] 은엔티티의구조와엔티티에서공유되는멘션들의속성정보를확인할수있다. 표 1. 엔티티데이터구조 { entity : [ { id : entity`s id, type : NE label, number : {singular plural}, gender : {male female}, person : {1 2 3}, animacy : {human thing time place}, mention : [ { id : mention`s id, text : mention`s text, sent_id : sentence`s id, start_eid : begin id of mention(np), end_eid : end id of mention(np), ne_id : id of NE label}, ] }, { id : 0, type : PS_NAME, number : singular, gender : male, person : 3, animacy : human, mention : [ { id : 48, text : 토니블레어총리, sent_id : 5, start_eid : 4, end_eid : 6, ne_id : 3}, { id : 49, text : 토니블레어, sent_id : 5, 8
19 start_eid : 4, end_eid : 5, ne_id : 3}, { id : 55, text : 그, sent_id : 6, start_eid : 0, end_eid : 0, ne_id : 3}, { id : 81, text : 블레어, sent_id : 9, start_eid : 5, end_eid : 5, ne_id : 3}] }, { }, ] } 9
20 4. 상호참조해결을위한멘션탐지 4.1 규칙기반멘션탐지 (Mention Detection) 멘션은해당멘션내에존재하는개체명정보와, 중심어정보등을포함하며, 이를멘션탐지과정중에추가하여나중에실행되는단계에서조회할수있게한다. 이후, 모든과정들은본과정의산출물인멘션을기반으로참조여부를확인하며, 이에따라상호참조해결의성능은멘션탐지에종속되게된다. 즉, 멘션을생성함에있어누락이존재한다면, 추후시브단계에서그오류가누적되며, 결국엔시스템전체의성능이떨어지게된다. 그러므로해당단계는가능한최대의재현율을이끌어내는것을목표로설정하였다. 본논문에서의멘션탐지는다음과같은규칙을갖는다. 그리고 [ 그림 2] 와 [ 표 2] 에서 멘션탐지에대한과정을보인다. 모든멘션은명사 ( 구 ) 에기반한다. 멘션탐지단계는의존구문트리에서등장하는모든명사또는명사구를멘션으로잡는다. 이에따라, 일반명사이외로복합명사, 대명사등도멘션으로정의하며, 누구, 언제, 어디, 무엇등과같이명사를가리킬수있는의문사도멘션으로정의한다. 멘션은기본적으로어절단위로처리한다. 품사, 구문정보는의존트리에기반하기때문에멘션은어절단위로처리한다. 이에 기반하여, 명사구에서가장의미를갖는명사를중심어 (head) 라한다. 수식정보를포함한멘션생성 ( 즉, 명사구 ) 의존구문트리는단어마다수식정보 ( 즉, mod) 를가지기때문에이것을이용하여수식정보를포함한완벽한명사구를생성한다. 즉, 각단어에포함된 mod 인덱스를따라가수식어를포함한하나의멘션을만드는데, 멘션의중심어는항상명사류 ( 즉, NP가포함된태그정보 ) 로정의한다. 만약, 멘션의중심어가동사류 ( 즉, VP가포함된태그정보 ) 이면멘션탐지정의에의하여해당단어는멘션으로추출하지않는다. 10
21 동격의지정사구 (a is b) 성균관은조선의최고교육기관이다. 와같이지정사구에대한문장인경우, 해당단어도멘션으로추출한다 ( 즉, 수식어를포함한 ~ 이다 인 [ 조선의최고교육기관이다 ] 를멘션으로추출 ). 개체명의원자성개체명은멘션에서의미가있는단어의최소단위로본다. 그러므로상호참조해결을진행할때개체명을멘션으로또는멘션의자질로서참조하기때문에추출하는멘션이개체명보다작은단위가있어서는안된다. 따라서멘션추출시 중심어중복처리 의상황과둘중하나가개체명이라면, 개체명을멘션으로하고그보다작은멘션은제거한다. 예를들어, [[ 르노 ] 0 1 자동차 ] 0 0 [ 르노자동차 ] 0 0 와같은결과를가진다. 즉, [ 르노 ] 0 1는개체명이없지만, [ 르노자동차 ] 0 0는 OGG_BUSINESS 라는개체명을가진다. 따라서 [ 르노 ] 0 1를 [ 르노자동차 ] 0 0에포함시켜제거한다. 중심어의중복처리멘션추출시중심어와중심어의위치가같은두개이상의명사구가추출될경우, 더큰멘션을선택하며작은멘션은제거한다. 크기가같은멘션은중복처리 ( 즉, 하나만남긴다 ) 를한다. 예를들어, [ 오바마 [ 대통령 ] 0 1] 0 0 [ 오바마대통령 ] 0 0과같이두개의멘션 [ 오바마대통령 ] 0 0, [ 대통령 ] 0 1은서로중심어와그위치가같다. 따라서멘션이더큰 [ 오바마대통령 ] 0 0을추출하고멘션의크기가작은 [ 대통령 ] 0 1을제거한다. 불용어처리 (stop words) 멘션의중심어가미리정의된불용사전에포함될경우, 멘션으로추출하지않는다. 예를들어, 특수문자, 명사류를제외한문법들, ~ 걸, ~ 수, ~ 중, 중간에, ~ 간, ~ 인채 대명사분류 세종전자사전에기술된대명사들을중심어로하는멘션들과한정사구멘션들에대 하여대명사, 한정사구표시를하고, 대명사상호참조해결 (Pronominal Coreference 11
22 Resolution) 시브이전까지멘션들과별도로처리하여문자열이같아참조되는경우를방지하였다. 대명사멘션의경우에는중심어 ( 즉, 대명사 ) 만멘션으로정의한다. 예를들어, 장-마르크르푸는이날기자들에게 그는르노가 의문장에서멘션은다음과같이추출것이다. [ 장-마르크르푸 ] 0 0, [ 이날 ] 0 1, [ 기자들 ] 0 2, [ 그 ] 0 3, [ 르노 ] 0 4, 이렇게추출된멘션들중 [ 이날 ] 0 1과 [ 그 ] 0 3는대명사로서, 멘션에서확인하여대명사에대한표시를하고대명사의자질로사용한다. 즉, 대명사에대한표시를한멘션은대명사시브이전엔상호참조가발생하지않는다. [ 그림 2] 는멘션탐지를위해의존구문트리를시각화한것이다. 입력된문장위에는각단어의의존구문트리의태그로태깅되어있고그순서에맞게 id가매겨져있다. 또한명사구마다표시를하였으며, 멘션탐지알고리즘초기에이명사구에따라어절단위로멘션을추출한다. 그리고문장아래 mod 위치정보를표시하였으며, 이수식정보 ( 즉, mod 위치정보가가리키는단어의 id) 는화살표를따라가며알수있다. Index Mod index , 6 7 그림 2. 멘션탐지그래프 [ 표 2] 는각규칙에따른멘션탐지에대하여수행한결과를확인할수있다. 즉, 입력문장, 어절단위멘션추출, 수식정보확장, 개체명원자성그리고중심어중복처리에대한결과를각단계마다순서대로보이며, 마지막으로멘션탐지의결과를보인다. 이중에서개체명원자성은먼저개체명이존재하는멘션에대하여표시를한뒤결과를보였다. [ 표 2] 에서보이는모든결과에대한과정은 [ 그림 2] 를참조하며확인한다. 12
23 표 2. 멘션탐지를수행한예 - Input document`s sentence 프랑스의르노자동차그룹은한국삼성자동차인수를공식제의할것이다. - Step 1: Extracting word of sentence [ 프랑스 ], [ 르노 ], [ 자동차 ], [ 그룹 ], [ 한국 ], [ 삼성자동차 ], [ 인수 ] - Step 2: Extending modifier [ 프랑스 ], [ 르노 ], [ 자동차 ], [ 르노자동차 ], [ 한국 ], [ 삼성자동차 ], [ 한국삼성자동차 ], [ 인수 ], [ 한국삼성자동차인수 ] - Step 3: Named entity atomicity i. Marking NE [ 프랑스 ]: LCP_COUNTRY, [ 르노 ], [ 르노자동차 ]: OGG_BUSINESS, [ 그룹 ], [ 르노자동차그룹 ], [ 프랑스의르노자동차그룹 ], [ 한국 ]: LCP_COUNTRY, [ 삼성자동차 ]: OGG_ BUSINESS, [ 인수 ], [ 한국삼성자동차인수 ] ii. Result of this step [ 프랑스 ], [ 르노자동차 ], [ 그룹 ], [ 르노자동차그룹 ], [ 프랑스의르노자동차그룹 ], [ 한국 ], [ 삼성자동차 ], [ 인수 ], [ 한국삼성자동차인수 ] - Step 4: Processing duplication of head [ 프랑스 ], [ 르노자동차 ], [ 프랑스의르노자동차그룹 ], [ 한국 ], [ 삼성자동차 ], [ 한국삼성자동차인수 ] - Result of Mention Detection [[ 프랑스 ] 1 1 의 [ 르노자동차 ] 2 2 그룹 ] 0 0 은 [[ 한국 ] 4 4 [ 삼성자동차 ] 3 3 인수 ] 5 5 를공식제의할것이다. [ 그림 3] 은 [ 표 2] 에대해수행하는멘션탐지알고리즘이다. 알고리즘은첫번째반복문에서어절단위로멘션을추출하고수식정보를확장하여멘션을명확한명사구로정의한다. 그다음반복문에서개체명원자성을확인한뒤다음세번째반복문에서중심어중복처리를진행한다. 그리고마지막으로대명사를탐색한후, 대명사와일치하는멘션이존재한다면대명사에대한상태체크를하고대명사후보로사용한다. 13
24 Algorithm Mention-Detection(doc) 1. Structure doc // input document 2. Variable w, h, ne // w doc`s Dependency, h is w`s head, ne doc`s NE 3. Variable mention S // S(i.e., head, NE or word) belong to mention 4. Variable i, j // i =i-th mention, j = j-th mention 5. List modifier_tree S // whole modifier`s label tree of S 6. List pronouns // append pronouns in pronouns list 7. Function generate(*m) // generate mention of correct condition // (i.e., m {head, modifier_tree, NE, word}) 8. Function check(mention) // check this mention 9. Function search(pronouns) // search pronouns in mention S 10. for each w in doc`s Dependency do 11. if w`s label is NP and w not in mention then 12. generate(mention w ); 13. end-if 14. if h`s label for w is NP then 15. if w`s label is VP_MOD then 16. generate(mention h, modifier_tree h ); 17. else 18. if h not in mention then 19. generate(mention h ); 20. end-if 21. if w not in mention then 22. generate(mention w ); 23. end-if 24. mention h.append(mention w.w); 25. end-if 26. end-if 27. end-for 28. for each ne in doc`s NE do 29. generate(mention ne ); 30. if partition of NE`s text belong to mention`s text then 31. mention ne.append(remaining w) 32. end-if 33. end-for 34. for each men i in mention do 35. for each men j in mention do 36. if men i`s h is men j `s h and men j smaller than men i then 37. remove(men j ) 38. end-if 39. if men i`s h is men j `s h and men i is men j then 40. remove(men j ) 41. end-if 42. end-for 43. end-for 14
25 44. search(pronouns) 45. for each men in mention do 46. if men in pronouns then 47. check(men) 48. end-if 49. end-for 그림 3. 멘션탐지알고리즘 4.2 딥러닝을이용한멘션탐지 규칙기반멘션탐지시스템은의존트리 (dependency tree) 에기반하여모든명사와수식어를포함한명사구를추출하게된다. 이와같이멘션들을추출할때, 일반적으로단일명사에대한멘션은정확하게추출하지만, 수식어가포함되어명사구의길이가길어진경우에는정확한멘션으로추출하기어렵다. 즉, [ 표 3] 과같이입력된문장이긴경우에는수식어구와안긴문장, 안은문장등으로멘션의바운더리 (boundary) 구분이모호해지기때문에정확한멘션을추출하기어려운문제가발생한다. 또한 [ 표 4] 와같이모든문장에대하여수식어포함규칙을적용하기어렵기때문에두개이상의멘션간에크로스 (cross) 가발생하는문제가있다. 마지막으로멘션탐지는형태소분석, 구문분석등의정보를기반으로수행되기때문에앞단계의분석에서발생한오류가누적되어멘션탐지에영향을미치는경우가있다 [ 표 5]. 표 3. 긴문장에대한멘션탐지 멘션탐지오류 지은이는 [ 조선태조이성계를도와조선건국과창업에공이큰조선제 3 대의임금, 태종으로이작품은반대당인정몽주 ( 鄭夢周 ) 의진심을떠보고회유하기위하여마련된자리 ] 에서지어부른작품이다. 올바른멘션탐지 [ 지은이 ] 는 [[[ 조선태조이성계 ] 를도와 [[ 조선건국 ] 과 [ 창업 ]] 에 [ 공 ] 이큰 15
26 [ 조선 ] [ 제 3 대 ] 의임금 ], 태종 ] 으로 [ 이작품 ] 은 [[[[ 반대당인정몽주 ( 鄭夢周 )] 의진심 ] 을떠보고회유하기위하여마련된자리 ] 에서지어부른작품 ] 이다. 표 4. 멘션간의크로스문제멘션탐지오류 [ 수심 200m [ 이내 ] 의완만한경사 ] 올바른멘션탐지 [[ 수심 200m 이내 ] 의완만한경사 ] 표 5. 오류누적에의한멘션탐지오류 멘션탐지오류 형태소문제 [[ 대청 :NNG] 도 :JX 와 [ 소청도 :NNG]] 의존트리문제 [ 군밤타령 ] 은 [ 경쾌하고 [ 구성진 :NP] 민요 ] 이다. 올바른멘션탐지 형태소문제 [[ 대청도 :NNG] 와 [ 소청도 :NNG]] 의존트리문제 [ 군밤타령 ] 은 [ 경쾌하고구성진 :VP_MOD 민요 ] 이다. 위와같은문제들로인하여규칙기반멘션탐지만으로정확한명사구의멘션을추출하기어려운점이있으며, 멘션탐지는의존트리및문장에의존적이기때문에모든상황에대하여일관성있는규칙을정하기가쉽지않다. 이에따라, 본장에서는앞서언급한문제점들을해결하기위하여딥러닝을이용한멘션탐지를수행할것을보인다 [14, 15]. 딥러닝모델중하나인 RNN은순차데이터를모델링할수있는강력한모델이다. 그러나 RNN은그레디언트소멸문제 (vanishing gradient problem) 가발생하는문제가있다 [16, 17]. 이에따라, Long Short-Term Memory (LSTM) 기반의 RNN은히든레이어 (hidden layer) 에게이트 (gate) 를정의하고, 가중치 (weight) 행렬과게이트들을학습하여필요한부분 16
27 에에러율을전파하는방법으로그레디언트소멸문제를해결하였다 [16]. 최근에는 LSTM- RNN의출력결과 (output label) 에의존성 ( 전이확률 ) 을부여한 LSTM Recurrent CRF(LSTM- CRF) 의등장으로순차데이터문제해결성능이더욱향상되었으며 [18], 이러한 LSTM-CRF 를전방향 (forward) 모델뿐만아니라후방향 (backward) 모델을함께학습하여 POS 태깅, 개체명등의순차데이터문제에대하여우수한성능을보이고있다 [19]. 본논문에서는 Bidirectional LSTM CRF(Bi-LSTM-CRF) 를멘션탐지에적용하였으며, 각 RNN 모델들 ( 즉, RNN, LSTM-RNN, LSTM-CRF, Bi-LSTM-CRF 등 ) 에대한비교실험을통하여 Bi-LSTM-CRF 가멘션탐지문제에적합하다는것을보인다 Feed-Forward Neural Network 딥러닝은인공신경망을확장한것으로서여러층의히든레이어로구성되어있으며, 각레이어마다비선형의활성함수가적용된다. 따라서더높은차원의표현이가능해지며, 자질들간의조합이발생하게된다. 이런딥러닝을자연어처리에적용할경우, 자질차원이높아지는문제가있다. 이에따라대용량의데이터 (raw text) 를 NNLM로학습하여단어표현을갱신하고, 이것을딥러닝에적용하여사전학습및차원축소를수행한다. 본논문에서는 [9] 에서구현한 NNLM을이용하여, 한국어로학습한단어표현을사용하였다. [ 그림 4] 는본논문에서적용한 Feed Forward Neural Network(FFNN) 이다. 여기서입력레이어 (input layer) 에입력으로는각단어와자질에대한 One-hot 표현 ( 즉, [ ] 과같이입력되는단어가 1이고나머지는 0으로표현 ) 을사용한다. 그리고입력된벡터와단어표현 (LT, Lookup Table) 을서로곱한결과와자질연산의결과를하나의벡터 (concatenation) 로만든다음투사레이어 (projection layer) 로전달한다. 이과정중에사전학습효과와차원축소가발생하게된다. 그이후투사레이어와가중치매트릭스 (M 1 ) 간에곱을통하여갱신된결과를활성함수에적용하고비선형변형 (non-linear activation) 을수행한다. 이때사용되는활성함수는 Sigmoid 보다성능이좋은 ReLU을사용하였다. 그리고해당결과를히든레이어로전달하고, 위와마찬가지로히든레이어와가중치매트릭스 (M 2 ) 를서로곱한다. 그다음 Softmax 함수를적용하여각 BIO 태그 (tag) 의확률을구한뒤, 출력레이어 (output 17

28 layer) 로전달한다. 이에따른신경망의학습을위하여 Cross Entropy(CE) 척도 (measure) 와 역전파 (back propagation) 알고리즘을이용하였으며, 학습시발생하는과적합 (overfitting) 을 줄이기위하여드랍아웃을적용하였다. 그림 4. FFNN 기반멘션탐지 Recurrent Neural Network 하나의신경망은입력단어 x와출력레이블 y, 히든레이어의노드 h로구성된다. 이를기반으로히든레이어가여러층이되는구조를딥러닝이라한다. 일반적인 FFNN은고정된입력과출력에대한학습만가능하기때문에순차데이터에적합하지않다. 이에따라, 본논문에서는순차데이터에적합한 RNN 모델들을멘션탐지에적용하였다. 18
29 Recurrent Neural Network (RNN) 는 [ 그림 5] 과같이 FFNN 구조를입력단어열에따라확장한모델로서, 이전히든레이어의상태를누적하여사용하기때문에순차데이터문제에적합하다. [ 그림 5] 에서는멘션탐지에대하여순차데이터문제로표현한것으로, BIO 태그를이용한다. 여기서 B는멘션의시작단어에대한표현이고, I는멘션내에포함된단어를나타낸다. 그리고 O는멘션에포함되지않는단어를뜻한다. 예를들어, 김대중대통령은프랑스에방문할것이다 ( 즉, 김대중 /nnp 대통령 /nng 은 /jx 프랑스 /nnp 에 /jkb 방문 /nng 하 /xsv ㄹ /etm 것 /nnb 이 /vcp 다 /ef./sf) 와같은문장은각형태소에따라 [B I I B I O O O O O O O] 와같은태그열로표현된다 ( 입력에대한자세한설명은 4.3절을참고한다 ). RNN 의입력레이어 (input layer) 는입력단어열 x = (x 1,, x T ) 가되며, 출력레이어 (output layer) 는출력태그열 ( 멘션탐지태그열 ) y = (y 1,, y T ) 가된다. 이에따라, RNN 은 각입력에대한신경망이구성되며, 순차적분류가가능하게되고, 다음과같이정의된다. h t = f(ux t + Vh t 1 ) y t = g(wh t ) 위식에서 U, V, W 는가중치 (weight) 행렬이며, f 는활성함수 (sigmoid, tanh, relu 등 ), g 는 softmax 함수이다. 그림 5. RNN 모델 19
30 4.2.3 Long Short-term Memory RNN 본논문에서는 RNN 의그레디언트소멸문제를해결하기위하여 LSTM 을적용하였다. [ 그림 6] 은 LSTM 의메모리셀 (memory cell) 에대한구조를나타낸다. 그림 6. Long Short-Term Memory Cell [ 그림 6] 과같이각각의메모리셀들을갱신하여새로입력되는벡터와기존의셀 (cell) 벡터의값을조정한다. 이에따라, 멀리떨어진단어의자질값을손실없이전달할수있어 RNN 의그레디언트소멸문제를해결할수있다. LSTM-RNN 은다음과같이정의된다. i t = σ(w ix x t + W ih h t 1 + W ic c t 1 + b i ) f t = σ(w fx x t + W fh h t 1 + W fc c t 1 + b f ) c t = f t c t 1 + i t tanh(w cx x t + W ch h t 1 + b c ) 20
31 o t = σ(w ox x t + W oh h t 1 + W oc c t 1 + b o ) h t = o t tanh(c t ) y t = g(w yh h t + b y ) 위식에서 σ는 sigmoid 함수이며, 는벡터간의 element-wise product이다. i, f, o, c는각각 input gate, forget gate, output gate, memory cell이며, 모두같은히든레이어유닛수를가진다. W는가중치행렬 ( 예를들어, W ih 는 input-hidden gate 행렬이고, W ox 는 output-input gate 행렬이다 ) 이며, b는 bias term이다 LSTM Recurrent CRF (LSTM-CRF) 그림 7. LSTM Recurrent CRF 모델 [ 그림 7] 은 LSTM-CRF 에대한구조를나타낸다 [5]. LSTM-RNN 의경우에는각각독립적 21
32 인출력결과를갖는모델인반면, LSTM-CRF는각출력결과에의존성 ( 전이확률 ) 이부여된모델이다. LSTM-CRF는 LSTM의특징인이전시간의상태를누적하는것과 CRF의특징인문장단위의태그정보를적용할수있는것때문에순차데이터문제에보다더좋은성능을보일수있다. LSTM-CRF의 output layer의식은다음과같이확장된다. y = W yh h t + b y T s(x, y) = A(y t 1, y t ) + y t t=1 logp(y x) = s(x, y) log exp (s(x, y )) y 위식에서 A(y t 1, y t ) 는이전출력태그 y t 1 에서다음출력태그 y t 로전이될확률을의미하는함수이고, s(x, y) 는멘션탐지태그열의점수를구하는 score 함수이다. 여기서를구하기위하여 CRF와같이 forward 알고리즘을이용하며, 최적의태그열을찾기위해 viterbi search 알고리즘을이용한다 Bidirectional LSTM-CRF (Bi-LSTM-CRF) 본논문에서제안한 Bidirectional LSTM CRF(Bi-LSTM- CRF) 는앞서말한 LSTM-CRF를전방향 (forward) 학습뿐만아니라후방향 (backward) 학습도함께수행하는모델이다 [ 그림 8]. Bi-LSTM-CRF는과거입력자질 (past input feature) 에대한추상화뿐만아니라미래입력자질 (future input feature) 에대한추상화를모두적용할수있기때문에 Bi-LSTM-CRF는양방향모두의자질조합및추상화정보를얻을수있다. 본논문에서는 Bi-LSTM-CRF 모델의학습을수행하기위하여 Stochastic Gradient Descent(SGD) 와 Back- Propagation Through Time(BPTT) 알고리즘을이용한다. 22
33 그림 8. Bidirectional LSTM-CRF 4.3 멘션탐지에사용한자질 본논문에서제안하는멘션탐지는딥러닝을이용하여멘션을추출하는데, 일반적으로멘션은모든명사및명사구를기반으로한다. 이에따라, 멘션은하나이상의단어를포함하게되며, 본논문에서는이런시퀀스레이블링 (sequence labeling) 문제에적합한 BIO 태그를이용하여딥러닝에적용한다. 일반적으로명사구에는수식어가포함되며, 수식어는명사와형용사등으로구성된다. 예를들어, 미국대통령오바마는오늘한국에방문할것이다. 와같은문장에서 미국대통령오바마 는하나의명사구로서 [[ 미국 ] [ 대통령 ] 오바마는 ] 과같이멘션으로추출된다. 이와같은경우, 멘션의바운더리 (boundary) 가가장넓은안은멘션 ([ 미국대통령오바마는 ]) 과그안에포함되어좁은바운더리를가지는안긴멘션 ([ 미국 ], [ 대통령 ]) 으로나뉘게되며, [ 표 6] 과같이 BIO 태그로표현할수있다. 본논문에서의멘션탐지는어절단위이기때문에멘션에조사가포함된다. 23
34 표 6. 안은멘션과안긴멘션의 BIO 표현 형태소안은멘션태그안긴멘션태그 미국 대통령 오바마 는 오늘 한국 에 방문 할 것 이 다. B I I I B B I O O O O O O B B O O O O O O O O O O O 그러나 [ 표 6] 과같이안은멘션과안긴멘션에대하여 BIO 태그로표현하게되면서로중복되는문제가발생한다. 즉, BIO 태그에대한레이블정보가많아져학습과분류가어렵게된다. 따라서 2장에서언급한멘션탐지의문제와 BIO 태그중복문제를해결하기위하여, 본논문에서는가장큰멘션형태인안은멘션을 BIO 태그표현의기준으로딥러닝에적용하였다. 자연어처리연구에딥러닝을적용할경우, 자연어의특성상자질과함께학습하여야한다. 즉, 자연어는사람으로부터의미를가지는단어가표현되는것이고이런단어들은추상화된표현이기때문이다. 이에따라, 본논문에서는멘션탐지를수행하기위하여총 19종류의 53개의자질을사용하였으며, 차후실험을위하여크게일반자질과추가자질로분류하였다. 각자질에대한설명은다음과같다. 24
35 4.3.1 일반자질 단어표현 : 6만개의단어를 NNLM으로학습한모델에사용할단어정보이다. 이중, 숫자단어는모두 0으로정규화하였다. 형태소태그자질 : (-3, -2, -1, 0, 1, 2, 3) 위치에해당하는형태소의품사태그정보이다. 어절표현자질 : (-3, -2, -1, 0, 1, 2, 3) 위치에해당하는어절의단어정보이다. 의존트리태그자질 : (-3, -2, -1, 0, 1, 2, 3) 위치에해당하는의존트리의태그정보이다. 개체명정보자질 : (-3, -2, -1, 0, 1, 2, 3) 위치에해당하는명사의개체명정보이다. 구문태그자질 : (-2, -1, 0, 1, 2) 위치에해당하는입력문장에대한구문정보이다. 의존트리의수식어태그표현자질 : 멘션은명사및수식어를포함한명사구로이뤄진다. 따라서의존트리에나타나는명사구에포함된수식어정보를자질로사용한다. 의존트리의수식어태그표현개수자질 : 위와같은이유로사용하며, 해당명사의수식어구개수정보이다. 수식어구의개수 (c로표현 ) 표현은 [c < 3, c < 6, c < 10, c >= 10] 과같이정의하였다. 괄호정보자질 : 문장내에서괄호는인접단어에대한설명을보충하기위하여등장한다. 이런이유로멘션을추출할경우, 해당괄호정보를포함하여추출한다. 따라서괄호정보자질은문장내에괄호가포함됐는지확인하는정보이다. 의문사자질 : 해당단어가의문사 ( 즉, 무엇, 어디 등 ) 인지확인하는정보이다. 대명사자질 : 해당단어가대명사인지확인하는정보이다. 한정사구자질 : 해당단어가한정사구인지확인하는정보이다. 지정사구자질 : 상호참조해결에는두멘션간의동격을비교하여문제를해결하는규칙이있다. 이와같은경우는지정사구 ( 즉, ~ 이다 ) 를주어와비교하는것을말한다. 따라서지정사를찾고지정사의수식어를포함한지정사구에대한정보를자질로사용한다. 접속사구자질 : 접속사구를포함하는단어들에대한정보이다. 외국어자질 : 문장에등장하는외국어에대한정보이다. 소유격형태소 / 태그자질 : 입력된단어가소유격인지확인하는정보이다. 복합명사정보자질 : 복합명사가존재하는지에대한정보이다. 25
36 의존트리중심어자질 : 의존트리에서구를이룰때해당구문의중심어에대한정 보이다 추가자질 가이드학습자질 : (-3, -2, -1, 0, 1, 2, 3) 위치에해당하는가이드정보이다. 가이드학습 (guided learning) 은다른시스템의결과를자질로추출하여적용하는방법이다. 본논문에서는규칙기반시스템으로추출한멘션탐지자질을가이드학습자질로적용한다. 26
37 5. 규칙기반한국어상호참조해결 5.1 다단계시브 (Multi-pass Sieve) 본논문에서멘션탐지를거쳐생성된멘션들은다단계시브를이용하여정의된규칙에따라상호참조를해결한다. 다단계시브는총 9단계로구성되어있으며, 각단계마다서로다른규칙을가진다. 그리고선두부분은상호참조해결의정확률 (precision) 을높게잡으며, 각각서로다른규칙의시브를거치면서재현율 (recall) 을높여간다. 상호참조해결은먼저멘션을찾는멘션탐지과정과규칙기반방식인다단계시브를이용해상호참조를해결하며, 후처리로상호참조해결을마무리한다. [ 그림 9] 는상호참조해결의각단계별결과를보이며, Pass2는순서대로시브 0부터 8까지이다. [ 그림 9] 에서위첨자는엔티티의 id이고아래첨자는멘션의 id이다. 본논문은 [ 그림 9] 와같이상호참조를해결하기위해형태소분석, 개체명정보, 구문분석, 의존구문트리등의정보를이용한다. 또한하나의문서내에서등장한여러멘션들간에상호참조를해결하기위하여단계별로시브 (sieve) 를진행한다. 시브는 [ 그림 9] 와같이총 9단계로구성되어규칙에따라엔티티를정의해나가며상호참조를해결한다. 이과정중앞선시브에서발견하지못한참조관계를이후시브에서추가하는형식으로재현율을높이게된다. 본논문에서사용하는다단계시브는문법적규칙에의하여시브앞부분에서는정확률을 시브뒷부분에서재현율을향상시키는데에집중하였다. 특히시브 3~7 은명사구의중심어 를이용하여관련된멘션을찾는규칙들을적용하여재현율향상에많은도움이된다. 27

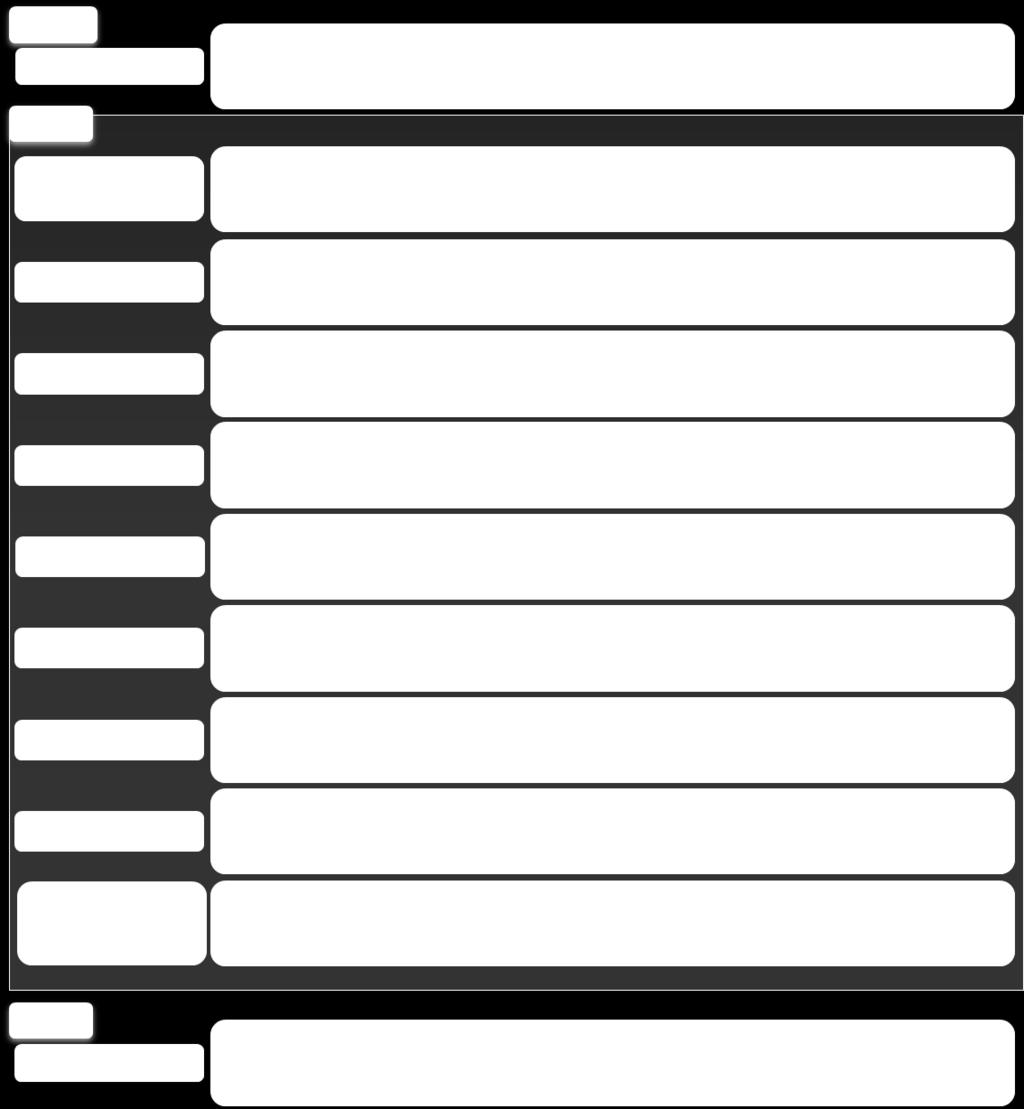
38 그림 9. 다단계시브를이용한상호참조해결 28
39 5.2 Sieve 0: 불가능한상호참조 (Impossible Coreference) 불가능한상호참조는다단계시브를수행하는동안상호참조해결이되어선안되는멘션들간의관계를정의하는부분이다. 즉, 불가능한상호참조규칙들에의하여불가능한상호참조로정의된멘션들은그에해당한멘션들과참조해결이발생하지않는다. 성씨가다른경우 : 두멘션의성씨가서로다른경우 ( 즉, [ 이씨 ], [ 김씨 ]) 에서로참조불가로정의한다. 지역정보가다른경우 : 두멘션의지역정보, 장소등이다르면서로참조불가로정의한다. 숫자가다른경우 : 두멘션에포함된수정보가다른경우, 서로참조불가로정의한다. I-within-I인경우 : 두멘션이서로 i-within-i 관계에해당하는경우, 서로참조불가로정의한다. 그러나다음과같은중심어의경우에는해당조건에서제외한다 ( 즉, 이름, 단어, 명칭, 필명, 별명, 의미, 뜻등 ). 같은격정보를갖지만대상이서로다른경우 : 후보멘션들중에는격정보 ( 즉, 직책, 직위등 ) 를갖는경우가있다. 이중에서멘션들의격정보가서로같지만각각의격정보멘션이서로다른멘션들을가리킨다면격정보를갖는멘션들은서로참조불가로정의한다. 접속사구연산정의 : 멘션들중접속사구에포함되는멘션들은접속사구연산에따라참조해결을수행한다. 접속사구연산은 and 연산, or 연산으로정의하며, 또는, 혹은 을제외한모든접속사는 and 연산으로처리한다. And 연산은접속사구에포함된멘션들간에상호참조가불가능하며, or 연산은가능하다. 예를들어, 무궁화는배달계그리고단심계, 아사달계로나뉜다. 와같은문장에서멘션은 [ 무궁화 ] 0 0, [ 배달계그리고단심계, 아사달계 ] 1 1, [ 배달계 ] 2 2, [ 단심계 ] 3 3, [ 아사달계 ] 4 4 와같이추출된다. 이문장에서접속사는 그리고 이므로해당접속사구에포함된멘션들 ( 즉 1~4번의멘션들 ) 은모두 and 연산으로정의되어서로참조불가로정의한다. 29
40 5.3 Sieve 1: 정확한문자열매치 (Exact String Match) 정확한문자열일치는문서내에서선행멘션과현재멘션의문자열이똑같이일치하는경 우에같은엔티티로참조된다 ( 즉, [ 프랑스의 ] 2 2, [ 프랑스 ] 2 8, [ 프랑스 ] 2 35 와같은경우하나의엔 티티로참조한다 ). 5.4 Sieve 2: 엄밀한구문 (Precise Construct) 엄밀한구문에서는다음규칙으로발생하는멘션간의참조를해결한다. 본논문에서는개체명정보를이용한동격역할 (Role Appositive) 과약어생성알고리즘을통해만들어진약어조회방법을사용하였다 엄밀한구문 : 동격역할 (Role Appositive) 자연어에서보편적으로사람이름멘션을직책멘션으로수식하거나, 반대로사람이름멘션뒤에직책등을나타내는멘션이붙는경우가있다 ( 즉, [[ 종교장관 ] 0 1 압델모네임살레 ] 0 0 를보면안은멘션 1 [ 종교장관압델모네임살레 ] 0 0와안긴멘션 2 [ 종교장관 ] 0 1이같은대상을지칭함을알수있다 ). 이와같은경우에안은멘션의개체명속성이사람, 직업, 직책등이고안긴멘션이사람, 직업, 직책등의개체명속성을갖는다. 이런특징을이용하여, 해당조건을만족했을때두멘션은서로참조한다. 그러나안은멘션과안긴멘션간에개체명속성이서로같아선안된다. 1 안은 mention: mention 안에다른 mention 을가지고있는것을의미한다. 2 안긴 mention: 하나의큰 mention 속에포함되어있는 mention 을의미한다. 30
41 5.4.2 엄밀한구문 : 약어 (Acronym) 정확한한국어에서약어는영어에서의약어 ( 즉, NLP: Natural Language Processing) 와달리명사에서음절등을축약하여사용한다 ( 즉, 한국전력공사 를 한전, 경상북도 를 경북 등 ). 이런약어들을생성하기위하여약어생성알고리즘을적용하고, 생성된약어를가진멘션과매핑되는멘션을같은엔티티로참조한다. 본논문에서는 [20] 의명사생략형, 음절조합형, 혼합형, 명사축약형중관대한중심어일치 (Relaxed Head Match) 에서수용가능한명사축약형을제외하고앞의 3가지규칙을사용하였다. 또한인칭약어규칙 ( 즉, 김대중대통령 을 김대통령 으로축약하는방법 ) 과영어약어규칙을추가하여총 5가지방법의약어규칙을구축하였으며, 각약어규칙은다음과같다. 명사생략형 : 복수명사중일부단일명사를생략하여명사를축약한다. ( 예를들어, 복수명사 : 르노자동차, 단일명사 : 르노, 자동, 차, 축약결과 : 르노자동, 르노차, 자동차 ) 음절조합형 : 명사를구성하는단일명사중첫음절로축약한다. ( 예를들어, 복수명사 : 한국전력공사, 단일명사 : 한국, 전력, 공사, 축약결과 : 한전, 전공, 한전공 ) 혼합형 : 명사생략형과음절조합형을합친개념으로복수명사중에서일부단일명사는그대로추출하며, 나머지단일명사들중첫음절을추출해축약한다. ( 예를들어, 복수명사 : 대우자동차판매, 단일명사 : 대우, 자동차, 판매, 축약결과 : 대우자판 ) 인칭약어규칙 : 인칭약어는사람이름과그사람의직위, 직업등이나왔을때그사람의성과직위로축약한다. 인칭약어로축약하는방법에대해서는개체명정보를조회하여 CV_POSITION( 직위 ) 을찾으면해당인덱스로부터최대 2번째까지의이전인덱스를조회하여 PS_NAME( 사람이름 ) 이존재하면해당 word만축약하여약어를생성한다. ( 예를들어, [ 현재멘션의개체명정보 = CV_POSITION: 대통령, 해당개체명의이전개체명정보 = PS_NAME: 김대중 ] 이면 김대통령 으로축약 ) 영어약어규칙 : 영어는한국어와달리단어의첫음절만축약한다. ( 예를들어, 복수명사 : Natural Language Processing, 단일명사 : Natural, Language, Processing, 축약결과 : NLP ) 31
42 5.5 Sieve 3, 4, 5: 엄격한중심어일치 (Strict Head Match 3, 4, 5) 본시브는아래의제약조건을만족하고, 중심어가같은멘션들의참조여부를결정한다. 엄격한중심어일치 A에서는세제약조건을모두만족하는멘션들을서로참조한다. 그리고엄격한중심어일치 B에서는 호환가능한수식어 (Compatible modifiers only) 제약조건을제외하고두제약조건을만족하는멘션들을참조하며, 엄격한중심어일치 C에서는 단어포함 (Word inclusion) 을제외한두제약조건을만족하는멘션들의경우에만참조한다 단어포함 문서내에서두멘션이참조된다면, 앞서등장한멘션의길이가이후에등장하는멘션의길 이보다길어야한다. 단어포함에대한예는 [ 표 7] 과같다. 표 7. 단어포함의예 - It is possible to refer two mentions [ 나이지리아남부아바마을 ] 6 0에서종족간의유혈분규로 450명의호사족주민이 [ 아바마을 ] 6 25에정통한정보망을갖고있는 호환가능한수식어 문서내에서두멘션이참조된다면, 뒤에등장하는멘션의수식어정보들은앞서등장하는 멘션에반드시포함되어야한다. [ 표 8] 는호환가능한수식어의예이다. 표 8. 호환가능한수식어의예 - It is possible to refer two mentions [ 환경에적응하여날지못하는새 ] 1 0 는보통 하지만 [ 날지못하는새 ] 1 1 는 - It is impossible to refer two mentions [ 어류 ] 0 0 는보통시각에의존하여먹이활동을한다. 하지만 [ 눈이퇴화된어류 ] 1 1 는촉각을이용하여먹이활동을한다.. 32
43 5.5.3 Not I within I 안긴멘션의중심어에 ~ 의 가붙어다음명사구를수식한다면안은멘션은 I within I 상 태의멘션이다. 이경우, 안긴멘션과안은멘션은서로참조하지않는다 ( 즉, [[ 남극 ] 1 1 의눈 물 ] 0 0 두멘션은참조하지않는다 ). 5.6 Sieve 6: 고유중심어일치 (Proper Head Match) 본절에서는고유중심어일치는앞서수행한엄격한중심어일치와상당히유사하다. 중심어가고유명사이고, 서로의미가같은두멘션일경우참조가가능하다. 즉, 해당시브를해결하기위해서다음조건을따르며모두만족할경우참조가발생한다. 본논문에서고유명사는형태소정보를이용하거나, 멘션에서나타내는의미의최소단위인개체명정보에기반하여추출한다. 선행사와현재멘션이서로같은중심어정보를갖는다. 선행사와현재멘션의수량정보가같다. ( 수량정보는중심어의단수또는복수를말 하며선행사와현재멘션간에수량정보가같아야한다.) 선행사와현재멘션의지역정보가같다. ( 여기서지역정보는나라, 수도등과같은 지역적인정보를말한다. 비교되는두멘션에지역정보가없을경우, 해당조건은무 시된다.) Not I within I 보통수량정보와지역정보는접속사또는개체명정보, 시소러스등을이용하여추출하지만, 본논문에서수량정보는중심어를수식하는수식어로구분하고, 지역정보는개체명정보만을이용하여추출한다. 이에따른고유중심어명사일치에대한예는 [ 표 9] 와같다. [ 표 9] 는수량정보에대한예와지역정보에대한예이며, 참조가가능할경우와참조가 33
44 불가능할경우로나뉜다. 표 9. 고유중심어일치예 - In the case that the current mention matches the number information of the antecedent mention [ 대부분의사람들 ] 0 0은불평불만 때문에 [ 그사람들이 ] 0 1 늘인류역사의수레바퀴를 - In the case that the current mention does not match the number information of the antecedent mention [ 순례길에오르는순례자 ] 0 0는차를타고 알라시드공항에서 [ 많은순례자들 ] 1 1을실어나르기위해 - In the case that the current mention matches the location information of the antecedent mention [ 미국대통령 ] 0 0이대중앞에나왔을때는 [ 미국대통령 ] 0 1은 - In the case that the current mention does not match the location information of the antecedent mention [ 프랑스의르노자동차그룹 ] 0 0은 [ 한국의르노사 ] 1 1와 5.7 Sieve 7: 관대한중심어일치 (Relaxed Head Match) 관대한중심어일치는다른중심어일치와달리휴리스틱에의하여좀더완화된규칙을가 지며해당제약조건은다음과같다. 현재멘션의중심어가후보멘션의명사단어집합에있을경우참조한다. 후보멘션과현재멘션의중심어가모두개체명일경우서로같은개체명속성을가져야한다 ( 예를들어, [ 프랑스의르노자동차 ], [ 르노삼성자동차 ], [ 르노사 ], [ 르노 ] 와같은 4개의멘션들은모두 OGG_BUSINESS 개체명속성을가지며 르노삼성자동차 라는개체를가리킨다. 따라서서로상호참조가가능하다 ). 34
45 5.8 Sieve 8: 대명사상호참조해결 (Pronominal Coreference Resolution) 한국어에서는존칭에따라인칭대명사의형태가매우다양하며, 그, 이, 저 등의지시관형사 (demonstrative pronoun) 와일반명사의조합 ( 즉, 한정사구 ) 이대명사의역할을수행한다. 따라서대명사의역할을하는멘션들을찾아내고, 그속성을부여하는과정이필요하다. 또한중심화이론, RAP 알고리즘등을이용하여대명사멘션과한정사구멘션을참조한다. 본논문에서는세종말뭉치의대명사사전을이용하여, 멘션중대명사의역할을하는 것들을찾아내어별도로처리한다. 대명사사전에기록된각대명사는 animacy, gender, number, 높임법등의속성들을갖고있다. 중심화이론은심리언어학등에서여러차례언급되어온방법론이다. 또한담화 (discourse) 내의문장, 즉발화 (utterance) 에서나타나는단어 ( 명사구 ) 의특징 (salience) 과응집성 (cohesion) 을고려하여, 현재화자와독자의생각이집중되는부분을찾아내는방법이다. 이처럼화자와독자가집중하고있는부분을중심 (center) 이라하고, 이것은발화의주제가되며, 결국엔담화를해석할수있다. 이발화내에서중심을식별하는데에는몇가지제약조건및규칙과함께 C f (forward-looking) 와 C b (backward-looking), C p (preferred center) 를사용한다. 그리고이것들을이용하여발화의전이, 즉중심의이동에대하여판별할수있다 [3]. RAP 알고리즘은문장내또는문장간의 3인칭대명사와어휘대용어 (lexical anaphors) 에대한선행사를찾아해결한다 [5, 6]. 이알고리즘은앞서언급한요소들에대한개념을포함시켜정의하고조건들을제안하였다. 또한이런요소적특징들을점수화하여가장높은점수를가진선행사 ( 또는멘션 ) 와대명사해결을진행하며, 문법적특징에따른점수가중치는 [ 표 10] 과같다. 35
46 표 10. 요소의특징에따른가중치 Factor type Initial weight (1) Sentence recency 100 (2) Subject emphasis 80 (3) Existential emphasis 70 (4) Accusative emphasis 50 (5) Indirect object and oblique emphasis 40 (6) Head noun emphasis 80 (7) Non-adverbial emphasis 50 RAP 알고리즘은입력된모든문장에대하여가중치를부여한다. 알고리즘의첫번째단계는현재등장한문장에존재하는요소들에대하여가중치를반으로나눈다. 이것은등장하는대명사로부터앞서등장한문장들과의거리차이를정의할수있다. 두번째로현재문장에등장하는멘션들에대하여 [ 표 10] 를이용하여문법적요소가맞는기준의가중치를부여한다. RAP 알고리즘에대하여예를들면다음과같다. (1) 은현재등장한문장에대한가중치로현재문장내의모든멘션들에가중치 100을더한다. (2) 는현재진행중인문장에서주어인멘션에가중치를더한다. (3) 은영어의 There be 와같은유도부사에대한특징이다. 영어에서는해당부분이멘션으로등장하면가중치를더하지만, 한국어에서는이와같은문법구조가없기때문에사용하지않는다. (4) 는직접목적어가등장하면가중치를더하며, (5) 는간접목적어가등장할경우가중치를더한다. 그러나역시한국어에는직접목적어와간접목적어의구분이명확하지않다. 따라서 (5) 에대한가중치는생략한다. (6) 은해당멘션의중심어가존재할경우, 즉하나의명사구에서중심어가되는명사를수식하는명사들이아니라, 그명사구의중심어에대한멘션인경우가중치를부여한다 ( 예를들어, 르노삼성자동차 인명사구에서중심어인 자동차 를포함한멘션 [ 르노삼성자동차 ] 에만가중치를부여하고이중심어를수식하는 [ 르노 ] 와 [ 삼성 ] 멘션에는부여하지않는다 ). (7) 은부사격에대한가중치부여이다. 36
47 이에따라, 본논문에서의대명사해결방법은 RAP 방법에기반하여대명사속성정보 ( 즉, number, person, animacy, NER label, Pronoun distance 등 )[1] 를적용하고, 중심의전이적인특성을이용한다. 즉, 대명사후보들에가중치를부여하는방법이며, 가중치부여방법은다음과같다. 멘션의주격, 목적격에따라가중치를부여한다. 대명사의속성과멘션의개체명정보를비교하여가중치를부여한다. 현재등장한대명사로부터떨어진문장의거리로가중치를부여한다. 현재등장한대명사와멘션후보들간에거리를이용하여가중치를부여한다. 각멘션후보마다속해있는문장에서의위치를고려하여가중치를부여한다. 위의방법에서는거리가중치를부여할경우에후방조응사 (cataphora) 를고려하지않 았기때문에대명사보다먼저나온선행사 (antecedent) 들과연산이이뤄진다. 이에따라, 중심화이론의기본적인개념인발화의전이적특징을내포하여각멘션후보 들에대명사의상호참조를해결하였다. 그에따른예는 [ 표 11] 에서확인할수있다. 표 11. 대명사상호참조해결예 Sentence 1 [[ 신문사 ] 1 1의한관계자 ] 0 0가밝혔다. Sentence 2 [ 장-마르크르푸 ] 2 2는 [[ 삼성차 ] 4 4 인수 ] 3 3를마무리하겠다고. Sentence 3 [ 그 ] 5 5는 [ 르노 ] 1 6가 [3월말] 7 7까지. [ 신문사의한관계자 ] 0 0 QT_MAN_COUNT NE label of each mentions [ 신문사 ] 1 1 OGG_BUSINESS [ 장 - 마르크르푸 ] 2 2 PS_NAME [ 삼성차인수 ] 3 3 none [ 삼성차 ] 4 4 OGG_BUSINESS [ 르노 ] 6 6 OGG_BUSINESS [3 월말 ] 7 7 DT_OTHERS Pronoun attribution [ 그 ] 5 5 3, singular, human Step Pronoun Mention Score [ 신문사의한관계자 ] 0 1 (Sub, Obj weight) [ 그 ] [ 장-마르크르푸 ]
48 2 (Features weight) [ 그 ] (Sentence id weight) [ 그 ] (Mention id weight) [ 그 ] (Word slot weight) [ 그 ] 5 5 Result (Pronominal Coreference Resolution) [ 삼성차인수 ] [ 신문사의한관계자 ] [ 신문사 ] [ 장 - 마르크르푸 ] [ 삼성차인수 ] [ 삼성차 ] [ 신문사의한관계자 ] [ 신문사 ] [ 장 - 마르크르푸 ] [ 삼성차인수 ] [ 삼성차 ] [ 신문사의한관계자 ] [ 신문사 ] [ 장 - 마르크르푸 ] [ 삼성차인수 ] [ 삼성차 ] [ 신문사의한관계자 ] [ 신문사 ] [ 장 - 마르크르푸 ] [ 삼성차인수 ] [ 삼성차 ] [ 그 ] 2 5 [ 장 - 마르크르푸 ] [ 표 11] 은문장및멘션속성과처리과정, 대명사상호참조해결결과로총 3단계로구성되어있다. 첫번째단계에서는 3개의입력된문장과각멘션이가지고있는개체명정보그리고대명사멘션의속성정보를나타낸다. 두번째는대명사상호참조해결의처리과정으로써앞에서제시한 5가지의조건에따라순차적으로처리되는것을보인다. Step 1은주격과목적격에따라가중치 100, 50을부여하고 Step 2는대명사의속성과각멘션의개체명정보를이용하여가중치를부여한다. 여기서대명사속성은 human, thing, time, place 등으로나뉘며, human에대응되는개체명일경우가중치를 10으로하고그외의것들에대응되는개체명에대해서는 1로한다. 그후, 추가로 50을곱하여가중치를부여한다. Step 3는각문장의위치에대한규칙으로, 문장의 id를이용하여가중치로주었다. Step 4 38
49 는현재등장한대명사와각멘션에대한거리가중치를부여하는것으로각멘션의 id가아닌멘션의시작 id를기준으로가중치를부여하였다. 마지막으로 Step 5는문장내에서멘션의위치관계를보는것으로어절의길이와멘션의시작 id를이용하여가중치를부여한다. 두번째단계인대명사상호참조해결처리과정을거쳐가중치가가장높은값을가진 멘션을선택하여대명사상호참조에대하여해결한다. 따라서 [ 표 6] 에서는 [ 그 ] 2 5 와 [ 장 - 마르 크르푸 ] 2 2 가서로상호참조한다 확장된대명사상호참조해결 대명사상호참조해결시브에서는대명사과한정명사구 ( 또는한정사구 ) 에대한상호참조해결을다룬다. 한정사구는지시관형사와명사를함께사용하는문법구조라한다. 지시관형사는어떤대상을가리키는관형사를말하며, 이관형사는선행하는대상의단어보다좀더상위개념의단어 ( 예를들어, 귀가큰당나귀, 이동물은 과같이여기서두번째문장에나타난범주어 [ 동물 ] 은첫번째문장의 [ 당나귀 ] 보다상위어다 ) 또는같은단어와함께사용된다. 한정사구는재표현될때선행사의상위어나같은단어를사용하기때문에대명사참조보다자질을더다양하게사용할수있다. 따라서확장된대명사상호참조해결에서는한정사구에대하여대명사속성을부여하고, 한정사구에포함된중심어를이용하여개체명정보를확인한다. 그외에도세종코퍼스로부터시소러스정보를추출하여의미사전 ( 즉, semclass) 을만들고, 이것을한정명사구의중심어에적용하여상호참조해결을수행한다. 이에대하여확장된방법은다음과같다. 대명사문자열매치 (pronoun string match) 선행사와한정명사구에대한중심어간의문자열매치 (head string match) 선행사와한정명사구에대한중심어간의의미매치 (head semantic match) 재귀대명사와의문사는현재문장의주어와상호참조한다. 39
50 5.9 후처리 (Post Processing) 후처리는위의시브들을거쳐생성된엔티티정보들중상호참조해결과관련없는멘션들을제거한다. 멘션탐지단계에서는모든명사구들을추출해낸다. 그리고다단계시브를진행하면서추출된멘션들의경우동일한멘션들간에참조가이뤄지고하나의엔티티에속하게된다. 그러나참조되지않은멘션들은하나의엔티티에하나의멘션만갖게되는데이것을단일개체 (singleton) 이라한다. 이처럼단일개체는다른멘션들과참조되지않기때문에상호참조라볼수없다. 따라서후처리단계에서단일개체를제거한다. 후처리에대한결과는 [ 표 12] 에서확인할수있다. 표 12. 후처리를수행한예 - Multi-pass Sieve result [ 레프야신 ] 0 0은 [[ 축구 ] 2 2 골키퍼 ] 0 1로서유일하게 [[ 유럽축구협회 ] 4 4가선정하는올해의선수 ] 0 3로뽑히기도했다. - Removing singleton [ 레프야신 ] 0 0은 [ 축구골키퍼 ] 0 1로서유일하게 [ 유럽축구협회가선정하는올해의선수 ] 0 3 로뽑히기도했다. 40
51 6. 기계학습기반한국어상호참조해결 [8] 에서는기계학습을멘션페어 (mention pair), 멘션랭킹 (mention ranking) 등의모델에적용 하였다. 본논문에서는이중멘션페어를이용하여기계학습기반상호참조해결에적용하였 으며, 기계학습방법으로는딥러닝을이용하였다. 본논문에서제안한규칙기반과기계학습기반을결합한상호참조해결은 6.2장에서언급하는가이드자질을이용하여수행된다. 즉, 규칙기반에서먼저상호참조해결을수행하고, 그결과를기계학습기반의자질로사용함으로써딥러닝의학습에상호참조해결의특성을부여한다. 그리고기계학습기반시스템으로부터추출된결과를기존규칙기반시스템의결과와함께수행하여상호참조해결의최종결과를구한다. 6.1 딥러닝을이용한멘션페어모델 (Mention Pair Model) 본논문에서제안하는멘션페어모델은멘션들간의쌍 ( 즉, 멘션페어 ) 을이뤄자질들을추출하고기계학습에적용하여상호참조가가능한지를판단한다. 즉, 후보선행사 (m i ) 와활성멘션 (m j, 현재멘션 ) 간에서로상호참조가가능한지확인하여분류하며, 본논문에서는멘션페어모델에딥러닝을이용한다. 딥러닝에서사용되는단어표현 (word embedding) 은자질차원이매우높은자연어처리에서주로차원축소와사전학습의목적으로사용하며, 본논문에서는 Neural Network Language Model (NNLM) 을기반으로구축된것을사용한다 [1]. 예를들어, [ 그림 10] 과같이입력유닛의크기가 1 V 이고 Lookup Table(LT) 의크기가 V n이면이둘의곱결과는 1 n의크기를갖게된다. 여기서 V는단어사전의크기가되고 n은임의의차원수 ( 보통 50차원 ) 가된다. [ 그림 11] 은본논문에적용한신경망구조이다. 입력으로는두멘션에대한멘션페어를받으며, 멘션의중심어 (head) 를 Word Lookup Table 41
 와곱하여출력레이어에전달하고, 출력레이어에서는 Softmax 함수를이용하여 output tag들의확률을구하게된다. 학습단계에서는신경망에의해추출된출력레이블 (output label) 과실제레이블 (target label) 간의에러율 (cross entropy) 을구하고이것을역전파알고리즘을이용하여가중치들을새로갱신한다.")
52 에서찾아단어표현으로이용하였다. 그리고자질집합에대하여단어표현과유사한자질표현 (feature embedding) 을적용하였으며, 이두벡터를하나의벡터 (concat) 를만들고 Projection layer로전달한다. 그다음, Projection layer의유닛들과가중치매트릭스 (W 1 ) 와곱한뒤활성함수 (ReLU) 를적용하여히든레이어를구성한다. 히든레이어는다시가중치매트릭스 (W 2 ) 와곱하여출력레이어에전달하고, 출력레이어에서는 Softmax 함수를이용하여 output tag들의확률을구하게된다. 학습단계에서는신경망에의해추출된출력레이블 (output label) 과실제레이블 (target label) 간의에러율 (cross entropy) 을구하고이것을역전파알고리즘을이용하여가중치들을새로갱신한다. 이때, 드랍아웃 (drop-out) 3 을적용하여과적합을방지하게된다. 그림 10. 단어표현을이용한차원축소 3 드랍아웃은히든레이어에서특정확률 ( 보통 0.5) 로임의의유닛을 0 으로설정하는것이다. 42
 가이드학습 (guided learning) 은다른시스템의결과를자질로추출하여기계학습을적용하 는방법으로, 본논문에서는규칙기반으로상호참조해결을수행한결과를가이드자질로적")
53 그림 11. 상호참조해결을위한신경망구조 6.2 가이드멘션페어 (Guided Mention Pair) 가이드학습 (guided learning) 은다른시스템의결과를자질로추출하여기계학습을적용하 는방법으로, 본논문에서는규칙기반으로상호참조해결을수행한결과를가이드자질로적 용하여기계학습기반의자질중하나로추가하였다. 본논문에서수행한가이드학습상호참조해결은규칙기반과기계학습기반의결과를함 께고려하는방법으로하이브리드기반상호참조해결에이용한다. 6.3 자질 (Features) 43

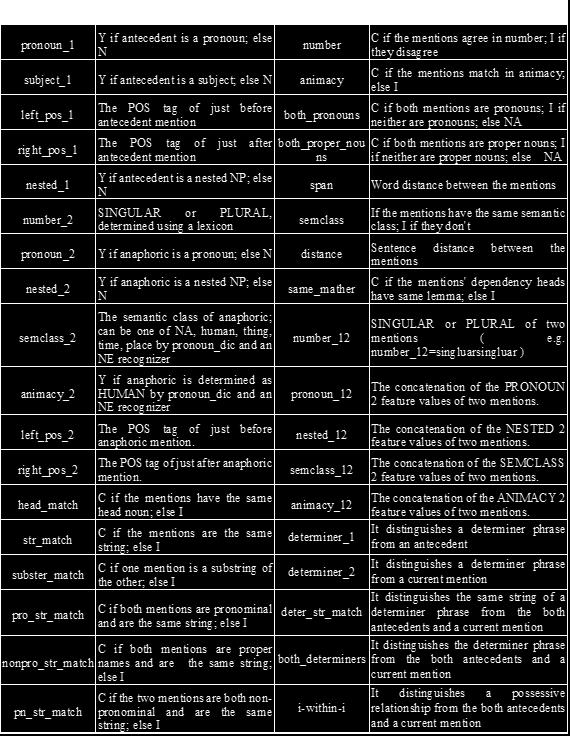
54 표 13. 딥러닝상호참조해결에사용한자질 44
55 7. 실험및결과 7.1 실험데이터 한국어상호참조해결과멘션탐지를실험하기위하여 ETRI 상호참조해결데이터셋을이용했으며, 이데이터셋은총 1779 문서 (5551 문장 ) 이다. 이중에서뉴스도메인은 153 문서, 퀴즈도메인 676 쌍 4 ( 즉, 1352 문서 ) 과퀴즈도메인 (QA 데이터 ) 의퀴즈 67 문서와정답 207 문서로구성된다. 여기서퀴즈도메인은 WiseQA 201 쌍과장학퀴즈 475 쌍과 274 문서로나뉜다. 상호참조해결과멘션탐지에서진행하는실험은뉴스도메인의뉴스 50, 퀴즈도메인의 GS 2.0, GS 3.0, GS 3.1 등과같이나눠진행하며, 기계학습기반실험은 [ 표 14] 와같이테스트 와학습데이터를정의한다. 표 14. 기계학습기반학습데이터정의 테스트데이터 학습데이터 데이터모델 뉴스도메인 ( 문서 ) 장학퀴즈 ( 쌍 ) 뉴스도메인 ( 문서 ) 장학퀴즈 ( 쌍 ) Wise QA ( 쌍 ) 장학퀴즈 ( 문서 ) News GS GS GS 쌍 +207문서 퀴즈도메인은질문 - 답쌍을한문서로다룬다. 45
56 7.2 멘션탐지실험 실험환경 본논문에서제안한 Bi-LSTM-CRF 모델을수행하기위하여 4.3.1장의자질은적용하였다. 자질표현 (feature embedding) 에는평균 0과분산 0.01이되도록무작위로초기화시킨값을이용하였으며, 단어표현 (word embedding) 은 10만단어에대한세종테그셋을 Neural Network Language Model(NNLM) 로학습한것을사용하였다. 그리고성능측정을위한척도 (measure) 는 F1 값을사용하였으며, 본논문에서제안한딥러닝모델들 ( 즉, FFNN, RNN, LSTM, LSTM-CRF, Bi-LSTM-CRF 등 ) 을이용하여비교실험을수행하였다. 또한각모델들은 1-layer LSTM으로학습을수행하였으며, 학습율 (learning rate) 은 0.1을시작으로성능개선이없으면 3 에포크 (epoch) 마다 50% 씩감소하도록정의하여학습하였다. 투사레이어 (projection layer) 와히든레이어 (hidden layer) 에는 drop-out을각각 0.2와 0.5의확률값으로적용하였고, 각레이어에대한활성함수는 sigmoid와 tanh를모두고려하여실험을수행하였다 (FFNN은 relu도적용하였다 ) 성능시험결과 [ 표 15] 는본논문에서제안한각딥러닝모델 ( 즉, FFNN, RNN, LSTM-RNN, LSTM-CRF, Bi- LSTM-CRF 등 ) 에따른멘션탐지실험결과이며, 퀴즈도메인문서 ( 즉, GS_2.0, GS_3.0, GS_3.1 등 ) 를이용하고, 각문서에대한 F1 값을구한다. 표 15. 멘션탐지실험결과 (F1) 모델 GS_2.0 F1 GS_3.0 F1 GS_3.1 F1 Rule based M.D FFNN (relu) RNN (tanh) LSTM-RNN (tanh) LSTM-CRF (tanh)
57 Bi-LSTM-CRF (sigm) 실험결과, GS_3.1 문서의경우에긴멘션바운더리의규칙기반멘션탐지성능은 27.48% 를보였다. 그다음으로딥러닝을이용한기계학습기반멘션탐지에서 FFNN은히든레이어의유닛수가 500이고 relu 함수를적용하였을때 65.61% 의성능을보였다. RNN은히든레이어유닛수가 100, sigmoid 함수를적용할경우에 61.76% 를보였고, LSTM-RNN은히든레이어유닛수를 500 그리고 tanh 함수를적용하여 66.78% 의성능을보였다. 여기서 RNN은베니싱그레디언트 (vanishing gradient) 문제로인하여 FFNN보다낮은성능을보였지만, LSTM-RNN은에러전파게이트로베니싱그레디언트문제를해결하여 FFNN과 RNN보다높은성능을보였다. LSTM-CRF는히든레이어유닛수가 100이고, tanh 함수를사용하였을때 70.33% 로이전모델들에비하여좋은성능을보였다. 이것은출력결과층 (layer) 에대하여의존성을부여함으로문장단위정보를포함하기때문인것으로보인다. 그리고마지막으로 Bi-LSTM-CRF는히든레이어유닛수가 200이고, sigmoid 함수를이용하였을때 FFNN 에비하여약 8.34% 향상되었고, LSTM-CRF보다약 3.62% 향상되어 73.95% 의성능으로모델들중에서가장높은성능을보였다. Bi-LSTM-CRF는각단어의과거 (forward) 와미래 (backward) 입력자질에대한추상화를이용하여학습을수행하는데, 이방법이순차데이터문제로정의한멘션탐지에적합하다는것을알수있다. 그외의문서인 GS_2.0와 GS_3.0에서의각딥러닝모델에대한활성함수는 GS_3.1에서적용한활성함수와같으며, 히든레이어유닛수는 GS_2.0의경우에, FFNN에서 1000개, 그리고 RNN에서 500개, LSTM- RNN에서 300개, LSTM-CRF에서 100개, Bi-LSTM-CRF에서 200개를정의하였을때각각딥러닝모델들중최고의성능을보였다. 그리고 GS_3.0에서는 FFNN에서 1000개, RNN에서 100개, LSTM-RNN에서 200개, LSTM-CRF에서 100개, Bi-LSTM-CRF에서 200개를히든레이어의유닛으로정의하였을때각딥러닝모델들중최고의성능을보였다. 개선된멘션탐지를상호참조해결에적용한실험은 7.3장을참고한다. 7.3 상호참조해결실험 47
58 상호참조해결실험은규칙기반과하이브리드기반으로나눠서수행한다. 규칙기반실험은엔 티티중심모델과다단계시브의특징을보이기위함이고하이브리드상호참조해결실험은 본논문에서제안한방법이한국어상호참조해결에적합하다는것을보이기위함이다 평가방법 본논문에서는 SemEval 평가프로그램 [21] 을이용하여 MUC[22] 와 B 3 [23] 와 Ceaf-e[24] 들의성능지표로본시스템의성능을평가하였다. 또한 CoNLL-2011에서는앞의세성능지표에대한 F1 평균 (Mean)[25] 을상호참조해결에대한공식성능지표로지정하였기때문에 Mean 값도구하였다. 본논문에서는상호참조해결성능평가를수행할때멘션의기준을멘션바운더리 (mention boundary), 중심어바운더리 (head boundary) 와같이두가지로정의한다. 먼저멘션바운더리는상호참조결과에대하여수식어를포함한멘션들을기준으로하여멘션탐지의성능까지고려한방법이다. 다음으로중심어바운더리는상호참조해결을수행한다음성능을측정할때멘션의중심어만기준으로하는방법으로써이것은오로지상호참조해결에대한성능만을고려한방법이다. 본논문에서평가를위해 gold entity set 과 predicted entity set 이필요하다. Gold entity set 은평가시스템에서 key 로정의되며, 사람이직접태깅한상호참조해결의정답데이터셋이 다. 반면에, predicted entity set 은평가시스템에서 response 로정의되며, 상호참조해결시스 템으로부터상호참조를해결한시스템데이터셋이다. 상호참조해결에서구하는 F1 값은 F1 = 2PR 으로본논문에서사용한모든성능지표에공통으로적용된다. P+R MUC: MUC 는링크기반측정방법으로다음과같이 key 와 response 각각에대한 recall 과 precision 을측정한다. 48
59 Recall = ( S i p(s i ) ) ( S i 1) (S i : key 의부분집합, i = 1 n.) Precision = ( S i p(s i ) ) ( S i 1) (S i : response 의부분집합, i = 1 n.) 예를들어, 어떤문서를평가를할때다음과같다. Key에대해 S={1, 2, 3}, {4, 5} 이고, response에대해 S={1, 2}, {3}, {4, 5} 이다. S 는 S의원소개수이며 S 1 = 3, S 2 = 2가된다 (response도같이구한다 ). p(s) 는집합 S가 response에관련되어링크된것을하나의원소로보고개수를센것으로 key에대하여 p(s 1 ) = 2, p(s 2 ) = 1이되고, response에대하여 p(s 1 ) = 1, p(s 2 ) = 1, p(s 3 ) = 1이된다. c(s) = ( S 1), c(s) 는 key( 또는 response) 에서올바르게링크 ( 참조 ) 된개수. m(s) = ( p(s) 1 ), m(s) 는 key( 또는 response) 로관계되는 response( 또는 key) 의링크중없는링크의수. 따라서하나의엔티티대한 recall/precision은 c(s) m(s) 와같이정의된다. 결과는 recall = 100%, precision = 100% 가된다. c(s) B 3 : MUC와달리 B 3 는멘션을기반으로하여성능을측정하는방법이다. 이방법은주어진멘션에대해전체 predicted와 gold mention cluster의비율을측정한다. 즉, recall은 key들로, precision은 response들로계산하며, key와 response의엔티티를교집합할때, 현재교집합된엔티티에있는멘션의개수로성능을구한다. Recall = K m i R mi i, Precision = K m i R mi K mi i R mi CEAF-e: 엔티티기반방법으로, key의엔티티와 response의엔티티들간에일-대-일맵핑으로확인하는데, 그값중가장높은값을선별한다. 즉, 각 response의엔티티는 key의엔티티들중최적의엔티티로맵핑된다 (g = argmax g Gm Φ(g)). CEAFe에서 response와 key의유사성을판별하는함수 (Φ(g)) 와 Recall, Precision을구하는방법은다음과같다. 49
60 Φ 4 (K i, R i ) = 2 K i R i, Recall = K i + R i Φ(g ) Φ(K i,k i ) i, Precision = Φ(g ) Φ(R i,r i ) i CoNLL F1: MUC, B 3 그리고 CEAF-e 의 F1 값들을평균한것으로, CoNLL-2011 에서 공식지정한지표이다 성능실험결과 본논문에서수행한상호참조해결의실험은규칙기반상호참조해결과기계학습기반상호참 조해결, 본논문에서제안한규칙기반과기계학습기반을함께사용하는상호참조해결 ( 하이 브리드상호참조해결 ) 에대한결과를보인다 규칙기반실험결과 먼저, 규칙기반상호참조해결에서는멘션간의재현율이중요하다. 재현율이높다는것은그만큼상호참조가발생했다는것을의미한다. 이에따라, 본논문에서는재현율을최대화하기위해멘션탐지단계에서가능한모든멘션을추출한다. 그리고다단계시브에서는초기에정확률을중심으로상호참조해결을수행하며, 시브를진행하면서재현율을높여간다. [ 표 16] 은단일개체를제거한각시브의단계에따른성능결과이다. 단일개체는엔티티안에하나의멘션만있어서상호참조라볼수없기때문이다. 그리고시브 0( 불가능한상호참조 ) 은 baseline으로서모든실험에기본적으로포함되어진행된다. 표 16. 규칙기반상호참조해결의시브단계별성능 ( 멘션바운더리 ) News 50 MUC B-cube CEAFE CoNLL(mean) R P F1 R P F1 R P F1 F1 Sieve Sieve Sieve
61 + Sieve Sieve Sieve Sieve Sieve GS_2.0 MUC B-cube CEAFE CoNLL(mean) R P F1 R P F1 R P F1 F1 Sieve Sieve Sieve Sieve Sieve Sieve Sieve Sieve GS_3.0 MUC B-cube CEAFE CoNLL(mean) R P F1 R P F1 R P F1 F1 Sieve Sieve Sieve Sieve Sieve Sieve Sieve Sieve GS_3.1 MUC B-cube CEAFE CoNLL(mean) R P F1 R P F1 R P F1 F1 Sieve Sieve Sieve Sieve Sieve Sieve Sieve Sieve 표 17. 규칙기반상호참조해결의시브단계별성능 ( 중심어바운더리 ) 51
62 News50H MUC B-cube CEAFE CoNLL(mean) R P F1 R P F1 R P F1 F1 Sieve Sieve Sieve Sieve Sieve Sieve Sieve Sieve GS_2.0H MUC B-cube CEAFE CoNLL(mean) R P F1 R P F1 R P F1 F1 Sieve Sieve Sieve Sieve Sieve Sieve Sieve Sieve GS_3.0H MUC B-cube CEAFE CoNLL(mean) R P F1 R P F1 R P F1 F1 Sieve Sieve Sieve Sieve Sieve Sieve Sieve Sieve GS_3.1H MUC B-cube CEAFE CoNLL(mean) R P F1 R P F1 R P F1 F1 Sieve Sieve Sieve % Sieve Sieve Sieve Sieve Sieve
63 [ 표 16, 17] 은뉴스도메인 50 문서와퀴즈도메인 GS_2.0, GS_3.0에대하여각각 50 쌍, GS_3.1에대하여 111 쌍을기준으로실험을수행하였다. 또한각도메인별로멘션바운더리 (News 50, GS_2.0, GS_3.0, GS_3.1) 와중심어바운더리 (News 50H, GS_2.0H, GS_3.0H, GS_3.1H) 의성능을보인다. [ 표 15] 에따른각시브별상호참조해결결과, 먼저뉴스도메인의멘션바운더리의경우에는시브1의정확한문자열일치에서상당히높은정확률을보이며 CoNLL F % 의성능을보였다. 시브2( 즉, 엄밀한구문 ) 에서도마찬가지로높은정확률을유지하며재현율을향상시켰다. 그다음, 시브3부터중심어기반규칙이적용되며해당시브인엄격한중심어일치에서약 4.3% 로가장많은성능향상을보였다. 이것은중심어를이용한상호참조해결이의미가있다는것을보이며, 그의미는영어와마찬가지로한국어에서도적합하다는것을알수있다. 또한이후시브들 (3-7) 은점증적으로재현율이향상되며, 정확률과 trade-off가발생하는것을확인할수있다. 그리고마지막으로시브8인대명사상호참조해결에서는앞에서참조해결된엔티티를기반으로대명사해결이수행된다. 그다음으로, 퀴즈도메인의경우에도위와마찬가지로각시브를수행할때마다재현율과정확률은서로 trade-off 관계로 F1 값이향상되는것을보인다. 그러나 GS_2.0은시브 2( 엄밀한구문 ) 에서그리고 GS_3.1은시브 5( 엄격한중심어일치 5) 에서오히려성능이저하되었다. 이것으로보아같은규칙이어도도메인에따라적용되는규칙의영향력이다르다는것을알수있다. 이와같은이유는사용되는어휘가문서도메인에종속적이기때문이며, 이전단계의언어분석결과가상호참조해결에영향을미치기때문이다. [ 표 17] 에따른중심어바운더리의경우에도멘션바운더리와같은양상을보였다. 이것은수식어들이다단계시브를통과할때만사용되고, 최종성능측정에서는제외하여오로지상호참조해결의결과만측정하는방법이다. 따라서상호참조해결결과에대한성능측정중에멘션탐지의오류를배제하고측정할수있으며, 그결과멘션바운더리와비교하여, 뉴스도메인은약 69.44% 이고 GS_2.0H는약 60.80%, GS_3.0H는약 57.73%, GS_3.1H는약 53.52% 의성능을보이며, 각각약 6.5%, 6.04%, 7.35%, 5.6% 의더높은성능을보인다. 상호참조해결의모든문서 ( 즉, 1779 문서 ) 에대한전체평가는 [ 표 18] 과같으며, [ 표 18] 은 53
64 중심어바운더리를이용한상호참조해결성능이다. 실험결과, 상호참조해결의모든문서의 F1 값은 MUC 59.33% 와 B %, Ceaf-e 58.60%, CoNLL 58.13% 의성능을보인다. 이에따라, 영어 [1] 의경우에는 Mean(CoNLL 2011 공식지표 F1) 값이 59.30% 로다단계시브가한국어에적합하다는것을알수있다. 표 18. 전체데이터에대한규칙기반상호참조해결성능 Recall Precision F1 MUC B Ceaf-e Mean (CoNLL F1) 하이브리드상호참조해결실험결과 하이브리드상호참조해결은본논문에서제안한규칙기반과기계학습기반을함께사용하여 상호참조해결을수행하는방법이다. 이에대한실험결과를보이기위해신경망의입력은 다음과같이정의하였다. 본논문에서는기본자질 (base) 36 개와하이브리드상호참조해결의가이드학습을위한 가이드자질 1 개를사용하였다. 이에따라신경망의입력은 [ 표 19] 와같다. 표 19. 신경망의입력 ( 단어및자질 ) 입력단어선행사의중심어현재멘션의중심어입력자질 설명선행사에서추출한중심어현재멘션에서추출한중심어설명 54
65 기본자질 (base) 36개의기본자질 ( 멘션페어모델 ) Guide-link 가이드자질 ( 가이드멘션페어모델 ) 본논문에서는기계학습기반의상호참조해결을수행하기위하여멘션페어모델 ( 즉, Mention Pair(MP)) 을적용하였다. 멘션페어모델은 [ 표 19] 에서가이드자질을제외한 36 개 의자질을사용한다. 딥러닝을이용한하이브리드기반 ( 즉, 가이드자질을적용한 Guided Mention Pair(GMP) 모델 ) 에대하여파라미터최적화를수행하였다. [ 표 20] 은해당파라미터값일때최적의성 능을보인파라미터이다. 표 20. 딥러닝파라미터최적화 상호참조해결모델도메인히든레이어유닛의수 Drop-out 자질표현뉴스 하이브리드기반장학퀴즈 본논문에서제안하는하이브리드상호참조해결에대한성능은 [ 표 21] 와같다. [ 표 21] 은본논문에서제안한하이브리드기반이상호참조해결에대하여적합한지보이기위한실험으로, 규칙기반상호참조해결과기계학습기반 ( 즉, 멘션페어 ) 상호참조해결에대한성능을보여비교실험을수행하였다. [ 표 21] 은뉴스도메인과퀴즈도메인을기준으로진행하였으며, 규칙기반과기계학습기반, 하이브리드상호참조해결에대한각각의성능을보인다. 표 21. 하이브리드상호참조해결성능 문서 News50H Rule Mention Pair Hybrid 성능지표 F1 F1 R P F1 R P R P (max) (max) MUC B Ceaf-e
66 GS_2.0H GS_3.0H GS_3.1H CoNLL MUC B Ceaf-e CoNLL MUC B Ceaf-e CoNLL MUC B Ceaf-e CoNLL [ 표 21] 은뉴스도메인과퀴즈도메인에대한중심어바운더리 ( 즉, News50H, GS_2.0H, GS_3.0H, GS_3.1H) 성능결과이다. 본논문에서제안한하이브리드상호참조해결의 F1 최대값은 News50H 문서일경우에, 약 69.53% 의성능을보였으며, 규칙기반에비하여약 0.09%, 기계학습기반에비하여약 6.92% 의향상된성능을보였다. GS_2.0H 문서일경우에는약 60.37% 로규칙기반에비하여약 0.47% 의성능하락이나타났지만, 기계학습기반에비하여약 1.76% 향상된성능을보였다. 그리고 GS_3.0H, GS_3.1H 문서모두규칙기반에비하여각각약 3.45%, 1.67% 의향상된성능과기계학습기반에비하여각각약 4.78%, 2.13% 향상된성능으로각각약 61.18%, 약 55.19% 의 F1 값을보였다. 이에따라, 본논문에서제안한하이브리드상호참조해결이문서에따라다르지만, 전반적으로좋은성능을보임을알수있다 딥러닝을이용한멘션탐지적용실험결과 규칙기반의멘션탐지에서긴문장에대한오류와멘션간의크로스문제, 오류누적에 의한멘션탐지오류등의문제로인하여탐지가어려운부분이있다. 이에따라본논문에 서는멘션탐지를수행하기어려운긴멘션들에대하여딥러닝을이용할것을제안하고더 56
67 욱향상된성능을실험을통하여보였다. [ 표 22] 에서는딥러닝을이용하여탐지한멘션들을상호참조해결시스템에적용하여상호참조해결을수행할것을보인다. 퀴즈도메인에대한멘션바운더리 (GS_2.0, GS_3.0, GS_3.1) 와중심어바운더리 (GS_2.0H, GS_3.0H, GS_3.1H) 를이용하여성능을측정하였다. 성능지표는 CoNLL(Mean) 을적용하였다. 표 22. 딥러닝멘션탐지를적용한상호참조해결성능 문서 GS_2.0 GS_3.0 GS_3.1 GS_2.0H GS_3.0H GS_3.1H 멘션탐지모델 Rule Mention Pair Hybrid R P F1 R P F1 R P F1 규칙기반 딥러닝기반 규칙기반 딥러닝기반 규칙기반 딥러닝기반 규칙기반 딥러닝기반 규칙기반 딥러닝기반 규칙기반 딥러닝기반 [ 표 22] 의실험결과, 딥러닝멘션탐지를적용하여멘션바운더리상호참조해결을수행하였을경우에는 GS_3.0과 GS_3.1에대한규칙과기계학습 ( 즉, 멘션페어 ), 하이브리드기반등의성능이모두향상됨을보였다. 각 F1 값을보면, GS_3.0 문서에서는규칙기반이약 1.47%, 기계학습기반이약 1.81%, 하이브리드기반이약 0.69% 향상되었고, GS_3.1 문서에서는규칙기반이약 1.12%, 기계학습기반이약 1.58%, 하이브리드기반이약 1.61% 향상된것을볼수있다. 딥러닝멘션탐지를적용하여중심어바운더리상호참조해결을수행하였을경우에는 GS_2.0H 와 GS_3.1H 에대한규칙기반의 F1 성능이각각약 0.31%, 0.54% 향상었고고, GS_3.0H 와 GS_3.1H 에대한기계학습기반의 F1 성능이각각약 0.14%, 1.05% 향상됨을 57
68 볼수있다. 이에따라, 본논문에서제안한딥러닝기반멘션탐지방법을상호참조해결 에적용하는것이적합함을알수있으며, 특히멘션바운더리에더좋은성능을보였음 을알수있다. 58
69 8. 결론 본논문은한국어상호참조해결에대하여전반적인방법론들 ( 규칙기반및기계학습기반 ) 에대하여보였으며, 규칙기반과기계학습기반을결합한하이브리드상호참조해결을제안하였다. 그리고상호참조해결을위한멘션탐지에대하여규칙기반과기계학습기반등의방법을제안했으며, 규칙기반에서발생하는문제들에대하여해결방안을제안하고실험을수행하였다. 규칙기반상호참조해결의경우에는 Stanford의엔티티중심모델을기반으로다단계시브를한국어에적합하게적용하였다. 이중에서, 엔티티중심모델은상호참조해결을수행하는데있어서가장핵심적인개념이며, 그중요성을실험을통해확인하였다. 그리고상호참조해결의해결범위는문서전체이므로, 정확률에만의존하는것보다재현율도향상시켜야한다. 이에따라다단계시브는각단계를수행할때마다재현율을향상시킬수있어서적합한데, 본논문에서다단계시브를적용하고실험을통해적합함 ( 즉, 재현율이향상되는것 ) 을확인하였다. 최종적으로마지막시브까지수행한결과, F1 값이뉴스도메인에서멘션바운더리는약 61.72%, 중심어바운더리는약 69.44% 그리고퀴즈도메인 : GS 2.0에서멘션바운더리는약 54.86%, 중심어바운더리는약 60.80%, GS 3.0에서멘션바운더리는약 50.38%, 중심어바운더리는약 57.73%, GS 3.1에서멘션바운더리는약 47.92%, 중심어바운더리는약 53.52% 의성능을보였다. 기계학습기반상호참조해결및멘션탐지에서보인방법들은최근패턴인식, 이미지처리, 음성인식등에서우수한성능을보이고있는딥러닝을적용한것이다. 딥러닝은인공신경망의특성 ( 즉, 자질디자인을자동으로수행한다 ) 과딥러닝기법인사전학습, dropout, ReLU ( 활성함수 ) 등으로인하여기존의기계학습모델들보다월등한성능을보인다. 본논문의기계학습기반상호참조해결은 Feed-forward Neural Network(FFNN) 를이용하였다. 또한기계학습기반멘션탐지도마찬가지로규칙으로정의하기어려웠던긴멘션이나, 이전단계의언어분석으로부터의오류전파등에대하여딥러닝모델 ( 즉, FFNN, RNN, LSTM, LSTM-CRF, Bi-LSTM-CRF 등 ) 을이용하여해결하였다. 59
70 하이브리드상호참조해결은가이드자질을이용하여규칙기반과기계학습기반을결합하는방법이다. 실험결과, 뉴스도메인 (News 50H) 에대하여 F1 최고성능이 69.53% 로규칙기반에비하여약 0.09%, 기계학습기반에비하여약 6.92% 높은성능을보였다. 또한퀴즈도메인 GS_3.0H 문서에서 F1 최고성능이약 61.18% 로규칙기반상호참조해결에비하여약 3.45%, 기계학습기반에비하여 4.78% 향상된성능을보였고 GS_3.1H 문서에서하이브리드성능이약 55.19%, 그리고규칙기반성능이약 53.52%, 기계학습기반성능이약 53.06% 로하이브리드방법을적용한상호참조해결의성능이더높은것을확인하였다. 본논문에서는규칙기반멘션탐지에서발생하는오류및어려움에대하여딥러닝을이용할것을제안하였다. 이에따라, 멘션바운더리상호참조해결에서전반적으로좋은성능을보였으며, 중심어바운더리상호참조해결에서는 GS_2.0H 문서일경우에규칙기반상호참조해결에서약 61.11% 로약 0.31% 향상된성능을보였고, GS_3.0H 문서일경우에기계학습기반상호참조해결에서 56.54% 로약 0.14% 향상된성능을보였다. 마지막으로 GS_3.1H 문서일경우에규칙기반상호참조해결에서약 54.06% 로약 0.54% 향상된성능을보였다. 본논문에서제안한규칙기반한국어상호참조해결시스템은영어와마찬가지로문서내에상호참조해결시재현율을높이는데적합했다. 그러나상호참조해결을수행하는데있어의미적모호성에관한몇가지오류사항이있다. 보통사람은어휘적상식과개념적상식으로멘션간의참조관계를이해할수있다. 그러나기계의경우온톨로지또는시소러스등의사전정보를사용하여해당멘션의개념적이해나의미적관계를구분해야한다. 본논문에서적용한상호참조해결시스템은적은지식기반의데이터만을사용하였기때문에다음과같은오류가발생하였다. 본논문은상호참조해결의다단계시브중시브3부터멘션의중심어가기준인규칙을적용한다. 따라서서로의미가다른수식어구들로인한모호성과단어의상 하개념에대한모호성이발생하는경우가있다. 수식어는명사 (head) 를꾸며보다더명확하게만든다. 어떤멘션들의명사 (head) 를다른형태의단어가같은의미로수식하는경우와다른의미로수식하는경우, 이멘션들을구분하기가까다롭다. 그리고어떤단어에대해세부적으로여러단어들로나뉠경우, 그단어는여러단어들로나뉜것들의상위개념이된다 ( 예를들어, 무궁화는배달계, 단심계, 아사달계로구성된다. 와같은문장에서 [ 무궁화 ] [ 배달계, 단심 60
71 계, 아사달계 ] 의구조를갖는다 ). 이런상위개념과하위개념간의관계를해결하는데있어 어려움이있다. 자연어에서는단어가어떤개체를가리키는것을표현하는것뿐만아니라, 이유, 시간, 사건등어떤현상을나타내는단어나구들 ( 즉, ~ 것, ~ 때문 등 ) 도존재한다. 이런단어들같은경우에는개체를가리키는단어들에비하여구체적인속성이나확인할수있는의미들을추출해내기가어렵고, 다른경우에는문장자체가가리켜지는대상이된다. 이에따라본논문에서는현상을나타내는단어나구에대하여불용어로처리하여수행하였다. 따라서향후계획으로, 오류분석을통하여해결방안을모색하고, 온톨로지나시소러스등의지식기반데이터들을사용할것이다. 즉, Wikipedia의데이터베이스나그에딸린인포박스 (infobox), Freebase 등에서 world knowledge 데이터를추출하여별칭및약어, 해당멘션의관계등의사전을만들어활용할것이다. 그리고오류패턴들을분석하여규칙을정하는것외에도딥러닝의네트워크구조를확장하여규칙으로정의하기어려운부분을해결할것이다. 즉, 일반멘션에대한상호참조해결을수행하기위해 Siamese Neural Network (SNN), 대명사또는현상을나타내는단어에대한상호참조해결을수행하기위해 Pointer Network (Ptr Net) 등을적용할예정이다 [26, 27]. SNN 의경우에는 [ 그림 12] 와같이두개의병렬신경망을이용하여학습을하고두출 력결과에대하여유사도비교를수행하는방법이다. 이에따라멘션들에대하여순위 (ranking) 를정의할수있으며, 엔티티중심모델에기반하여참조관계를해결할수있다. 61

![sequence-to-sequence 모델 [28] 과어텐션매커니즘 (attention](/docs-images/93/117968964/images/72-2.jpg "mechanism)[29] 에기반하여출력결과를입력단어의위치로하여학습하는모델로써,")
72 그림 12. SNN 을이용한일반멘션상호참조해결 Ptr-Net의경우에는 [ 그림 13] 과같이 sequence-to-sequence 모델 [28] 과어텐션매커니즘 (attention mechanism)[29] 에기반하여출력결과를입력단어의위치로하여학습하는모델로써, 대명사에대한후보멘션이나현상을나타내는단어나구 ( 즉, ~ 것 과같은멘션 ) 을찾는데적합할것으로보인다. 그림 13. Ptr-Net 을이용한대명사상호참조해결 62
Multi-pass Sieve를 이용한 한국어 상호참조해결 반-자동 태깅 도구
 한국어대명사및한정명사구에대한상호참조해결 박천음, 최경호, 이홍규, 이창기 강원대학교 Intelligent Software Lab. 목차 관련연구 상호참조해결 대명사및한정명사구 RAP 알고리즘 대명사상호참조해결방법확장 실험및결과 질의응답 관련연구 대명사해결을위한기존연구들 상호참조해결및대용어해결을적용. 다단계시브 (Multi-pass sieve) 상호참조해결 (Stanford)
한국어대명사및한정명사구에대한상호참조해결 박천음, 최경호, 이홍규, 이창기 강원대학교 Intelligent Software Lab. 목차 관련연구 상호참조해결 대명사및한정명사구 RAP 알고리즘 대명사상호참조해결방법확장 실험및결과 질의응답 관련연구 대명사해결을위한기존연구들 상호참조해결및대용어해결을적용. 다단계시브 (Multi-pass sieve) 상호참조해결 (Stanford)
Naver.NLP.Workshop.SRL.Sogang_Alzzam
 : Natra Langage Processing Lab 한국어 ELMo 모델을이용한의미역결정 박찬민, 박영준 Sogang_Azzam Naver NLP Chaenge 서강대학교자연어처리연구실 목차 서론 제안모델 실험 결론 2 서론 의미역결정이란? 문장의술어를찾고, 그술어와연관된논항들사이의의미관계를결정하는문제 논항 : 의미역이부여된각명사구의미역 : 술어에대한명사구의의미역할
: Natra Langage Processing Lab 한국어 ELMo 모델을이용한의미역결정 박찬민, 박영준 Sogang_Azzam Naver NLP Chaenge 서강대학교자연어처리연구실 목차 서론 제안모델 실험 결론 2 서론 의미역결정이란? 문장의술어를찾고, 그술어와연관된논항들사이의의미관계를결정하는문제 논항 : 의미역이부여된각명사구의미역 : 술어에대한명사구의의미역할
딥러닝 첫걸음
 딥러닝첫걸음 4. 신경망과분류 (MultiClass) 다범주분류신경망 Categorization( 분류 ): 예측대상 = 범주 이진분류 : 예측대상범주가 2 가지인경우 출력층 node 1 개다층신경망분석 (3 장의내용 ) 다범주분류 : 예측대상범주가 3 가지이상인경우 출력층 node 2 개이상다층신경망분석 비용함수 : Softmax 함수사용 다범주분류신경망
딥러닝첫걸음 4. 신경망과분류 (MultiClass) 다범주분류신경망 Categorization( 분류 ): 예측대상 = 범주 이진분류 : 예측대상범주가 2 가지인경우 출력층 node 1 개다층신경망분석 (3 장의내용 ) 다범주분류 : 예측대상범주가 3 가지이상인경우 출력층 node 2 개이상다층신경망분석 비용함수 : Softmax 함수사용 다범주분류신경망
Multi-pass Sieve를 이용한 한국어 상호참조해결 반-자동 태깅 도구
 Siamese Neural Network 박천음 강원대학교 Intelligent Software Lab. Intelligent Software Lab. Intro. S2Net Siamese Neural Network(S2Net) 입력 text 들을 concept vector 로표현하기위함에기반 즉, similarity 를위해가중치가부여된 vector 로표현
Siamese Neural Network 박천음 강원대학교 Intelligent Software Lab. Intelligent Software Lab. Intro. S2Net Siamese Neural Network(S2Net) 입력 text 들을 concept vector 로표현하기위함에기반 즉, similarity 를위해가중치가부여된 vector 로표현
RNN & NLP Application
 RNN & NLP Application 강원대학교 IT 대학 이창기 차례 RNN NLP application Recurrent Neural Network Recurrent property dynamical system over time Bidirectional RNN Exploit future context as well as past Long Short-Term
RNN & NLP Application 강원대학교 IT 대학 이창기 차례 RNN NLP application Recurrent Neural Network Recurrent property dynamical system over time Bidirectional RNN Exploit future context as well as past Long Short-Term
Microsoft PowerPoint - 26.pptx
 이산수학 () 관계와그특성 (Relations and Its Properties) 2011년봄학기 강원대학교컴퓨터과학전공문양세 Binary Relations ( 이진관계 ) Let A, B be any two sets. A binary relation R from A to B, written R:A B, is a subset of A B. (A 에서 B 로의이진관계
이산수학 () 관계와그특성 (Relations and Its Properties) 2011년봄학기 강원대학교컴퓨터과학전공문양세 Binary Relations ( 이진관계 ) Let A, B be any two sets. A binary relation R from A to B, written R:A B, is a subset of A B. (A 에서 B 로의이진관계
KCC2011 우수발표논문 휴먼오피니언자동분류시스템구현을위한비결정오피니언형용사구문에대한연구 1) Study on Domain-dependent Keywords Co-occurring with the Adjectives of Non-deterministic Opinion
 Study on Domain-dependent Keywords Co-occurring with the Adjectives of Non-deterministic Opinion") KCC2011 우수발표논문 휴먼오피니언자동분류시스템구현을위한비결정오피니언형용사구문에대한연구 1) Study on Domain-dependent Keywords Co-occurring with the Adjectives of Non-deterministic Opinion 요약 본연구에서는, 웹문서로부터특정상품에대한의견문장을분석하는오피니언마이닝 (Opinion
KCC2011 우수발표논문 휴먼오피니언자동분류시스템구현을위한비결정오피니언형용사구문에대한연구 1) Study on Domain-dependent Keywords Co-occurring with the Adjectives of Non-deterministic Opinion 요약 본연구에서는, 웹문서로부터특정상품에대한의견문장을분석하는오피니언마이닝 (Opinion
Microsoft PowerPoint Relations.pptx
 이산수학 () 관계와그특성 (Relations and Its Properties) 2010년봄학기강원대학교컴퓨터과학전공문양세 Binary Relations ( 이진관계 ) Let A, B be any two sets. A binary relation R from A to B, written R:A B, is a subset of A B. (A 에서 B 로의이진관계
이산수학 () 관계와그특성 (Relations and Its Properties) 2010년봄학기강원대학교컴퓨터과학전공문양세 Binary Relations ( 이진관계 ) Let A, B be any two sets. A binary relation R from A to B, written R:A B, is a subset of A B. (A 에서 B 로의이진관계
자연언어처리
 제 7 장파싱 파싱의개요 파싱 (Parsing) 입력문장의구조를분석하는과정 문법 (grammar) 언어에서허용되는문장의구조를정의하는체계 파싱기법 (parsing techniques) 문장의구조를문법에따라분석하는과정 차트파싱 (Chart Parsing) 2 문장의구조와트리 문장 : John ate the apple. Tree Representation List
제 7 장파싱 파싱의개요 파싱 (Parsing) 입력문장의구조를분석하는과정 문법 (grammar) 언어에서허용되는문장의구조를정의하는체계 파싱기법 (parsing techniques) 문장의구조를문법에따라분석하는과정 차트파싱 (Chart Parsing) 2 문장의구조와트리 문장 : John ate the apple. Tree Representation List
<3235B0AD20BCF6BFADC0C720B1D8C7D120C2FC20B0C5C1FE20322E687770>
 25 강. 수열의극한참거짓 2 두수열 { }, {b n } 의극한에대한 < 보기 > 의설명중옳은것을모두고르면? Ⅰ. < b n 이고 lim = 이면 lim b n =이다. Ⅱ. 두수열 { }, {b n } 이수렴할때 < b n 이면 lim < lim b n 이다. Ⅲ. lim b n =0이면 lim =0또는 lim b n =0이다. Ⅰ 2Ⅱ 3Ⅲ 4Ⅰ,Ⅱ 5Ⅰ,Ⅲ
25 강. 수열의극한참거짓 2 두수열 { }, {b n } 의극한에대한 < 보기 > 의설명중옳은것을모두고르면? Ⅰ. < b n 이고 lim = 이면 lim b n =이다. Ⅱ. 두수열 { }, {b n } 이수렴할때 < b n 이면 lim < lim b n 이다. Ⅲ. lim b n =0이면 lim =0또는 lim b n =0이다. Ⅰ 2Ⅱ 3Ⅲ 4Ⅰ,Ⅱ 5Ⅰ,Ⅲ
04 Çмú_±â¼ú±â»ç
 42 s p x f p (x) f (x) VOL. 46 NO. 12 2013. 12 43 p j (x) r j n c f max f min v max, j j c j (x) j f (x) v j (x) f (x) v(x) f d (x) f (x) f (x) v(x) v(x) r f 44 r f X(x) Y (x) (x, y) (x, y) f (x, y) VOL.
42 s p x f p (x) f (x) VOL. 46 NO. 12 2013. 12 43 p j (x) r j n c f max f min v max, j j c j (x) j f (x) v j (x) f (x) v(x) f d (x) f (x) f (x) v(x) v(x) r f 44 r f X(x) Y (x) (x, y) (x, y) f (x, y) VOL.
Microsoft Word - PLC제어응용-2차시.doc
 과정명 PLC 제어응용차시명 2 차시. 접점명령 학습목표 1. 연산개시명령 (LOAD, LOAD NOT) 에대하여설명할수있다. 2. 직렬접속명령 (AND, AND NOT) 에대하여설명할수있다. 3. 병렬접속명령 (OR, OR NOT) 에대하여설명할수있다. 4.PLC의접점명령을가지고간단한프로그램을작성할수있다. 학습내용 1. 연산개시명령 1) 연산개시명령 (LOAD,
과정명 PLC 제어응용차시명 2 차시. 접점명령 학습목표 1. 연산개시명령 (LOAD, LOAD NOT) 에대하여설명할수있다. 2. 직렬접속명령 (AND, AND NOT) 에대하여설명할수있다. 3. 병렬접속명령 (OR, OR NOT) 에대하여설명할수있다. 4.PLC의접점명령을가지고간단한프로그램을작성할수있다. 학습내용 1. 연산개시명령 1) 연산개시명령 (LOAD,
PowerPoint Presentation
 Dependency Parser 자연언어처리 Probabilistic CFG (PCFG) - CFG - PCFG with saw with saw astronomers ears saw stars telescope astronomers ears saw stars telescope PCFG example Repeated work Parsing PCFG: CKY CKY
Dependency Parser 자연언어처리 Probabilistic CFG (PCFG) - CFG - PCFG with saw with saw astronomers ears saw stars telescope astronomers ears saw stars telescope PCFG example Repeated work Parsing PCFG: CKY CKY
adfasdfasfdasfasfadf
 C 4.5 Source code Pt.3 ISL / 강한솔 2019-04-10 Index Tree structure Build.h Tree.h St-thresh.h 2 Tree structure *Concpets : Node, Branch, Leaf, Subtree, Attribute, Attribute Value, Class Play, Don't Play.
C 4.5 Source code Pt.3 ISL / 강한솔 2019-04-10 Index Tree structure Build.h Tree.h St-thresh.h 2 Tree structure *Concpets : Node, Branch, Leaf, Subtree, Attribute, Attribute Value, Class Play, Don't Play.
 (Hyunoo Shim) 1 / 24 (Discrete-time Markov Chain) * 그림 이산시간이다연쇄 (chain) 이다왜 Markov? (See below) ➀ 이산시간연쇄 (Discrete-time chain): : Y Y 의상태공간 = {0, 1, 2,..., n} Y n Y 의 n 시점상태 {Y n = j} Y 가 n 시점에상태 j 에있는사건
(Hyunoo Shim) 1 / 24 (Discrete-time Markov Chain) * 그림 이산시간이다연쇄 (chain) 이다왜 Markov? (See below) ➀ 이산시간연쇄 (Discrete-time chain): : Y Y 의상태공간 = {0, 1, 2,..., n} Y n Y 의 n 시점상태 {Y n = j} Y 가 n 시점에상태 j 에있는사건
C# Programming Guide - Types
 C# Programming Guide - Types 최도경 lifeisforu@wemade.com 이문서는 MSDN 의 Types 를요약하고보충한것입니다. http://msdn.microsoft.com/enus/library/ms173104(v=vs.100).aspx Types, Variables, and Values C# 은 type 에민감한언어이다. 모든
C# Programming Guide - Types 최도경 lifeisforu@wemade.com 이문서는 MSDN 의 Types 를요약하고보충한것입니다. http://msdn.microsoft.com/enus/library/ms173104(v=vs.100).aspx Types, Variables, and Values C# 은 type 에민감한언어이다. 모든
Introduction to Deep learning
 Introduction to Deep learning Youngpyo Ryu 동국대학교수학과대학원응용수학석사재학 youngpyoryu@dongguk.edu 2018 년 6 월 30 일 Youngpyo Ryu (Dongguk Univ) 2018 Daegu University Bigdata Camp 2018 년 6 월 30 일 1 / 66 Overview 1 Neuron
Introduction to Deep learning Youngpyo Ryu 동국대학교수학과대학원응용수학석사재학 youngpyoryu@dongguk.edu 2018 년 6 월 30 일 Youngpyo Ryu (Dongguk Univ) 2018 Daegu University Bigdata Camp 2018 년 6 월 30 일 1 / 66 Overview 1 Neuron
DIY 챗봇 - LangCon
 without Chatbot Builder & Deep Learning bage79@gmail.com Chatbot Builder (=Dialogue Manager),. We need different chatbot builders for various chatbot services. Chatbot builders can t call some external
without Chatbot Builder & Deep Learning bage79@gmail.com Chatbot Builder (=Dialogue Manager),. We need different chatbot builders for various chatbot services. Chatbot builders can t call some external
완벽한개념정립 _ 행렬의참, 거짓 수학전문가 NAMU 선생 1. 행렬의참, 거짓개념정리 1. 교환법칙과관련한내용, 는항상성립하지만 는항상성립하지는않는다. < 참인명제 > (1),, (2) ( ) 인경우에는 가성립한다.,,, (3) 다음과같은관계식을만족하는두행렬 A,B에
,, (2) ( ) 인경우에는 가성립한다.,,, (3) 다음과같은관계식을만족하는두행렬 A,B에") 1. 행렬의참, 거짓개념정리 1. 교환법칙과관련한내용, 는항상성립하지만 는항상성립하지는않는다. < 참인명제 > (1),, (2) ( ) 인경우에는 가성립한다.,,, (3) 다음과같은관계식을만족하는두행렬 A,B에대하여 AB=BA 1 가성립한다 2 3 (4) 이면 1 곱셈공식및변형공식성립 ± ± ( 복호동순 ), 2 지수법칙성립 (은자연수 ) < 거짓인명제 >
1. 행렬의참, 거짓개념정리 1. 교환법칙과관련한내용, 는항상성립하지만 는항상성립하지는않는다. < 참인명제 > (1),, (2) ( ) 인경우에는 가성립한다.,,, (3) 다음과같은관계식을만족하는두행렬 A,B에대하여 AB=BA 1 가성립한다 2 3 (4) 이면 1 곱셈공식및변형공식성립 ± ± ( 복호동순 ), 2 지수법칙성립 (은자연수 ) < 거짓인명제 >
Sequences with Low Correlation
 레일리페이딩채널에서의 DPC 부호의성능분석 * 김준성, * 신민호, * 송홍엽 00 년 7 월 1 일 * 연세대학교전기전자공학과부호및정보이론연구실 발표순서 서론 복호화방법 R-BP 알고리즘 UMP-BP 알고리즘 Normalied-BP 알고리즘 무상관레일리페이딩채널에서의표준화인수 모의실험결과및고찰 결론 Codig ad Iformatio Theory ab /15
레일리페이딩채널에서의 DPC 부호의성능분석 * 김준성, * 신민호, * 송홍엽 00 년 7 월 1 일 * 연세대학교전기전자공학과부호및정보이론연구실 발표순서 서론 복호화방법 R-BP 알고리즘 UMP-BP 알고리즘 Normalied-BP 알고리즘 무상관레일리페이딩채널에서의표준화인수 모의실험결과및고찰 결론 Codig ad Iformatio Theory ab /15
Microsoft PowerPoint - e pptx
 Import/Export Data Using VBA Objectives Referencing Excel Cells in VBA Importing Data from Excel to VBA Using VBA to Modify Contents of Cells 새서브프로시저작성하기 프로시저실행하고결과확인하기 VBA 코드이해하기 Referencing Excel Cells
Import/Export Data Using VBA Objectives Referencing Excel Cells in VBA Importing Data from Excel to VBA Using VBA to Modify Contents of Cells 새서브프로시저작성하기 프로시저실행하고결과확인하기 VBA 코드이해하기 Referencing Excel Cells
Chap 6: Graphs
 5. 작업네트워크 (Activity Networks) 작업 (Activity) 부분프로젝트 (divide and conquer) 각각의작업들이완료되어야전체프로젝트가성공적으로완료 두가지종류의네트워크 Activity on Vertex (AOV) Networks Activity on Edge (AOE) Networks 6 장. 그래프 (Page 1) 5.1 AOV
5. 작업네트워크 (Activity Networks) 작업 (Activity) 부분프로젝트 (divide and conquer) 각각의작업들이완료되어야전체프로젝트가성공적으로완료 두가지종류의네트워크 Activity on Vertex (AOV) Networks Activity on Edge (AOE) Networks 6 장. 그래프 (Page 1) 5.1 AOV
슬라이드 1
 Pairwise Tool & Pairwise Test NuSRS 200511305 김성규 200511306 김성훈 200614164 김효석 200611124 유성배 200518036 곡진화 2 PICT Pairwise Tool - PICT Microsoft 의 Command-line 기반의 Free Software www.pairwise.org 에서다운로드후설치
Pairwise Tool & Pairwise Test NuSRS 200511305 김성규 200511306 김성훈 200614164 김효석 200611124 유성배 200518036 곡진화 2 PICT Pairwise Tool - PICT Microsoft 의 Command-line 기반의 Free Software www.pairwise.org 에서다운로드후설치
Visual Basic 반복문
 학습목표 반복문 For Next문, For Each Next문 Do Loop문, While End While문 구구단작성기로익히는반복문 2 5.1 반복문 5.2 구구단작성기로익히는반복문 3 반복문 주어진조건이만족하는동안또는주어진조건이만족할때까지일정구간의실행문을반복하기위해사용 For Next For Each Next Do Loop While Wend 4 For
학습목표 반복문 For Next문, For Each Next문 Do Loop문, While End While문 구구단작성기로익히는반복문 2 5.1 반복문 5.2 구구단작성기로익히는반복문 3 반복문 주어진조건이만족하는동안또는주어진조건이만족할때까지일정구간의실행문을반복하기위해사용 For Next For Each Next Do Loop While Wend 4 For
Structural SVMs 및 Pegasos 알고리즘을 이용한 한국어 개체명 인식
 딥러닝 기반의 자연어처리 기술 강원대학교 IT대학 이창기 차례 자연어처리소개 딥러닝소개 딥러닝기반의자연어처리 Classification Problem Sequence Labeling Problem Sequence-to-Sequence Learning Pointer Network Machine Reading Comprehension 자연어처리 자연언어 인공언어에대응되는개념
딥러닝 기반의 자연어처리 기술 강원대학교 IT대학 이창기 차례 자연어처리소개 딥러닝소개 딥러닝기반의자연어처리 Classification Problem Sequence Labeling Problem Sequence-to-Sequence Learning Pointer Network Machine Reading Comprehension 자연어처리 자연언어 인공언어에대응되는개념
1_12-53(김동희)_.hwp
_.hwp") 본논문은 2012년전력전자학술대회우수추천논문임 Cascaded BuckBoost 컨버터를 이용한 태양광 모듈 집적형 저전압 배터리 충전 장치 개발 472 강압이 가능한 토폴로지를 이용한 연구도 진행되었지만 제어 알고리즘의 용의성과 구조의 간단함 때문에 BuckBoost 컨버터 또는 Sepic 컨버터를 이용하여 연구 가 진행되었다[10][13]. 태양광 발전
본논문은 2012년전력전자학술대회우수추천논문임 Cascaded BuckBoost 컨버터를 이용한 태양광 모듈 집적형 저전압 배터리 충전 장치 개발 472 강압이 가능한 토폴로지를 이용한 연구도 진행되었지만 제어 알고리즘의 용의성과 구조의 간단함 때문에 BuckBoost 컨버터 또는 Sepic 컨버터를 이용하여 연구 가 진행되었다[10][13]. 태양광 발전
도약종합 강의목표 -토익 700점이상의점수를목표로합니다. -토익점수 500점정도의학생들이 6주동안의수업으로 점향상시킵니다. 강의대상다음과같은분들에게가장적합합니다. -현재토익점수 500점에서 600점대이신분들에게가장좋습니다. -정기토익을 2-3번본적이있으신분
 도약종합 -토익 700점이상의점수를목표로합니다. -토익점수 500점정도의학생들이 6주동안의수업으로 100-200점향상시킵니다. -정기토익을 2-3번본적이있으신분. -수업도많이들어봤고, 문제도많이풀었지만문법정리가제대로되지않은분. 강의특징수업시간에토익과관련없는사적인잡담으로시간낭비하지않는수업입니다. LC : 파트별집중정리한문제풀이로유형을익혀나가는수업입니다. RC
도약종합 -토익 700점이상의점수를목표로합니다. -토익점수 500점정도의학생들이 6주동안의수업으로 100-200점향상시킵니다. -정기토익을 2-3번본적이있으신분. -수업도많이들어봤고, 문제도많이풀었지만문법정리가제대로되지않은분. 강의특징수업시간에토익과관련없는사적인잡담으로시간낭비하지않는수업입니다. LC : 파트별집중정리한문제풀이로유형을익혀나가는수업입니다. RC
3.2 함수의정의 Theorem 6 함수 f : X Y 와 Y W 인집합 W 에대하여 f : X W 는함수이다. Proof. f : X Y 가함수이므로 f X Y 이고, Y W 이므로 f X W 이므로 F0이만족된다. 함수의정의 F1, F2은 f : X Y 가함수이므로
 3.2 함수의정의 Theorem 6 함수 f : X Y 와 Y W 인집합 W 에대하여 f : X W 는함수이다. Proof. f : X Y 가함수이므로 f X Y 이고, Y W 이므로 f X W 이므로 F0이만족된다. 함수의정의 F1, F2은 f : X Y 가함수이므로성립한다. Theorem 7 두함수 f : X Y 와 g : X Y 에대하여, f = g f(x)
3.2 함수의정의 Theorem 6 함수 f : X Y 와 Y W 인집합 W 에대하여 f : X W 는함수이다. Proof. f : X Y 가함수이므로 f X Y 이고, Y W 이므로 f X W 이므로 F0이만족된다. 함수의정의 F1, F2은 f : X Y 가함수이므로성립한다. Theorem 7 두함수 f : X Y 와 g : X Y 에대하여, f = g f(x)
2017 년 6 월한국소프트웨어감정평가학회논문지제 13 권제 1 호 Abstract
 2017 년 6 월한국소프트웨어감정평가학회논문지제 13 권제 1 호 Abstract - 31 - 소스코드유사도측정도구의성능에관한비교연구 1. 서론 1) Revulytics, Top 20 Countries for Software Piracy and Licence Misuse (2017), March 21, 2017. www.revulytics.com/blog/top-20-countries-software
2017 년 6 월한국소프트웨어감정평가학회논문지제 13 권제 1 호 Abstract - 31 - 소스코드유사도측정도구의성능에관한비교연구 1. 서론 1) Revulytics, Top 20 Countries for Software Piracy and Licence Misuse (2017), March 21, 2017. www.revulytics.com/blog/top-20-countries-software
1 경영학을 위한 수학 Final Exam 2015/12/12(토) 13:00-15:00 풀이과정을 모두 명시하시오. 정리를 사용할 경우 명시하시오. 1. (각 6점) 다음 적분을 구하시오 Z 1 4 Z 1 (x + 1) dx (a) 1 (x 1)4 dx 1 Solut
 13:00-15:00 풀이과정을 모두 명시하시오. 정리를 사용할 경우 명시하시오. 1. (각 6점) 다음 적분을 구하시오 Z 1 4 Z 1 (x + 1) dx (a) 1 (x 1)4 dx 1 Solut") 경영학을 위한 수학 Fial Eam 5//(토) :-5: 풀이과정을 모두 명시하시오. 정리를 사용할 경우 명시하시오.. (각 6점) 다음 적분을 구하시오 4 ( ) (a) ( )4 8 8 (b) d이 성립한다. d C C log log (c) 이다. 양변에 적분을 취하면 log C (d) 라 하자. 그러면 d 4이다. 9 9 4 / si (e) cos si
경영학을 위한 수학 Fial Eam 5//(토) :-5: 풀이과정을 모두 명시하시오. 정리를 사용할 경우 명시하시오.. (각 6점) 다음 적분을 구하시오 4 ( ) (a) ( )4 8 8 (b) d이 성립한다. d C C log log (c) 이다. 양변에 적분을 취하면 log C (d) 라 하자. 그러면 d 4이다. 9 9 4 / si (e) cos si
chap 5: Trees
 5. Threaded Binary Tree 기본개념 n 개의노드를갖는이진트리에는 2n 개의링크가존재 2n 개의링크중에 n + 1 개의링크값은 null Null 링크를다른노드에대한포인터로대체 Threads Thread 의이용 ptr left_child = NULL 일경우, ptr left_child 를 ptr 의 inorder predecessor 를가리키도록변경
5. Threaded Binary Tree 기본개념 n 개의노드를갖는이진트리에는 2n 개의링크가존재 2n 개의링크중에 n + 1 개의링크값은 null Null 링크를다른노드에대한포인터로대체 Threads Thread 의이용 ptr left_child = NULL 일경우, ptr left_child 를 ptr 의 inorder predecessor 를가리키도록변경
Microsoft PowerPoint 웹 연동 기술.pptx
 웹프로그래밍및실습 ( g & Practice) 문양세강원대학교 IT 대학컴퓨터과학전공 URL 분석 (1/2) URL (Uniform Resource Locator) 프로토콜, 호스트, 포트, 경로, 비밀번호, User 등의정보를포함 예. http://kim:3759@www.hostname.com:80/doc/index.html URL 을속성별로분리하고자할경우
웹프로그래밍및실습 ( g & Practice) 문양세강원대학교 IT 대학컴퓨터과학전공 URL 분석 (1/2) URL (Uniform Resource Locator) 프로토콜, 호스트, 포트, 경로, 비밀번호, User 등의정보를포함 예. http://kim:3759@www.hostname.com:80/doc/index.html URL 을속성별로분리하고자할경우
이 장에서 사용되는 MATLAB 명령어들은 비교적 복잡하므로 MATLAB 창에서 명령어를 직접 입력하지 않고 확장자가 m 인 text 파일을 작성하여 실행을 한다
 이장에서사용되는 MATLAB 명령어들은비교적복잡하므로 MATLAB 창에서명령어를직접입력하지않고확장자가 m 인 text 파일을작성하여실행을한다. 즉, test.m 과같은 text 파일을만들어서 MATLAB 프로그램을작성한후실행을한다. 이와같이하면길고복잡한 MATLAB 프로그램을작성하여실행할수있고, 오류가발생하거나수정이필요한경우손쉽게수정하여실행할수있는장점이있으며,
이장에서사용되는 MATLAB 명령어들은비교적복잡하므로 MATLAB 창에서명령어를직접입력하지않고확장자가 m 인 text 파일을작성하여실행을한다. 즉, test.m 과같은 text 파일을만들어서 MATLAB 프로그램을작성한후실행을한다. 이와같이하면길고복잡한 MATLAB 프로그램을작성하여실행할수있고, 오류가발생하거나수정이필요한경우손쉽게수정하여실행할수있는장점이있으며,
PowerPoint Template
 JavaScript 회원정보 입력양식만들기 HTML & JavaScript Contents 1. Form 객체 2. 일반적인입력양식 3. 선택입력양식 4. 회원정보입력양식만들기 2 Form 객체 Form 객체 입력양식의틀이되는 태그에접근할수있도록지원 Document 객체의하위에위치 속성들은모두 태그의속성들의정보에관련된것
JavaScript 회원정보 입력양식만들기 HTML & JavaScript Contents 1. Form 객체 2. 일반적인입력양식 3. 선택입력양식 4. 회원정보입력양식만들기 2 Form 객체 Form 객체 입력양식의틀이되는 태그에접근할수있도록지원 Document 객체의하위에위치 속성들은모두 태그의속성들의정보에관련된것
2002년 2학기 자료구조
 자료구조 (Data Structures) Chapter 1 Basic Concepts Overview : Data (1) Data vs Information (2) Data Linear list( 선형리스트 ) - Sequential list : - Linked list : Nonlinear list( 비선형리스트 ) - Tree : - Graph : (3)
자료구조 (Data Structures) Chapter 1 Basic Concepts Overview : Data (1) Data vs Information (2) Data Linear list( 선형리스트 ) - Sequential list : - Linked list : Nonlinear list( 비선형리스트 ) - Tree : - Graph : (3)
김기남_ATDC2016_160620_[키노트].key
![김기남_ATDC2016_160620_[키노트].key](/thumbs/85/91488855.jpg "김기남_ATDC2016_160620_[키노트].key") metatron Enterprise Big Data SKT Metatron/Big Data Big Data Big Data... metatron Ready to Enterprise Big Data Big Data Big Data Big Data?? Data Raw. CRM SCM MES TCO Data & Store & Processing Computational
metatron Enterprise Big Data SKT Metatron/Big Data Big Data Big Data... metatron Ready to Enterprise Big Data Big Data Big Data Big Data?? Data Raw. CRM SCM MES TCO Data & Store & Processing Computational
로거 자료실
 redirection 매뉴얼 ( 개발자용 ) V1.5 Copyright 2002-2014 BizSpring Inc. All Rights Reserved. 본문서에대한저작권은 비즈스프링 에있습니다. - 1 - 목차 01 HTTP 표준 redirect 사용... 3 1.1 HTTP 표준 redirect 예시... 3 1.2 redirect 현상이여러번일어날경우예시...
redirection 매뉴얼 ( 개발자용 ) V1.5 Copyright 2002-2014 BizSpring Inc. All Rights Reserved. 본문서에대한저작권은 비즈스프링 에있습니다. - 1 - 목차 01 HTTP 표준 redirect 사용... 3 1.1 HTTP 표준 redirect 예시... 3 1.2 redirect 현상이여러번일어날경우예시...
Artificial Intelligence: Assignment 6 Seung-Hoon Na December 15, Sarsa와 Q-learning Windy Gridworld Windy Gridworld의 원문은 다음 Sutton 교재의 연습문제
 Artificial Intelligence: Assignment 6 Seung-Hoon Na December 15, 2018 1 1.1 Sarsa와 Q-learning Windy Gridworld Windy Gridworld의 원문은 다음 Sutton 교재의 연습문제 6.5에서 찾아볼 수 있다. http://incompleteideas.net/book/bookdraft2017nov5.pdf
Artificial Intelligence: Assignment 6 Seung-Hoon Na December 15, 2018 1 1.1 Sarsa와 Q-learning Windy Gridworld Windy Gridworld의 원문은 다음 Sutton 교재의 연습문제 6.5에서 찾아볼 수 있다. http://incompleteideas.net/book/bookdraft2017nov5.pdf
Windows 8에서 BioStar 1 설치하기
 / 콘텐츠 테이블... PC에 BioStar 1 설치 방법... Microsoft SQL Server 2012 Express 설치하기... Running SQL 2012 Express Studio... DBSetup.exe 설정하기... BioStar 서버와 클라이언트 시작하기... 1 1 2 2 6 7 1/11 BioStar 1, Windows 8 BioStar
/ 콘텐츠 테이블... PC에 BioStar 1 설치 방법... Microsoft SQL Server 2012 Express 설치하기... Running SQL 2012 Express Studio... DBSetup.exe 설정하기... BioStar 서버와 클라이언트 시작하기... 1 1 2 2 6 7 1/11 BioStar 1, Windows 8 BioStar
<4D6963726F736F667420576F7264202D20B1E2C8B9BDC3B8AEC1EE2DC0E5C7F5>
 주간기술동향 2016. 5.18. 컴퓨터 비전과 인공지능 장혁 한국전자통신연구원 선임연구원 최근 많은 관심을 받고 있는 인공지능(Artificial Intelligence: AI)의 성과는 뇌의 작동 방식과 유사한 딥 러닝의 등장에 기인한 바가 크다. 이미 미국과 유럽 등 AI 선도국에서는 인공지능 연구에서 인간 뇌 이해의 중요성을 인식하고 관련 대형 프로젝트들을
주간기술동향 2016. 5.18. 컴퓨터 비전과 인공지능 장혁 한국전자통신연구원 선임연구원 최근 많은 관심을 받고 있는 인공지능(Artificial Intelligence: AI)의 성과는 뇌의 작동 방식과 유사한 딥 러닝의 등장에 기인한 바가 크다. 이미 미국과 유럽 등 AI 선도국에서는 인공지능 연구에서 인간 뇌 이해의 중요성을 인식하고 관련 대형 프로젝트들을
BY-FDP-4-70.hwp
 RS-232, RS485 FND Display Module BY-FDP-4-70-XX (Rev 1.0) - 1 - 1. 개요. 본 Display Module은 RS-232, RS-485 겸용입니다. Power : DC24V, DC12V( 주문사양). Max Current : 0.6A 숫자크기 : 58mm(FND Size : 70x47mm 4 개) RS-232,
RS-232, RS485 FND Display Module BY-FDP-4-70-XX (Rev 1.0) - 1 - 1. 개요. 본 Display Module은 RS-232, RS-485 겸용입니다. Power : DC24V, DC12V( 주문사양). Max Current : 0.6A 숫자크기 : 58mm(FND Size : 70x47mm 4 개) RS-232,
EA0015: 컴파일러
 5 Context-Free Grammar 무엇을공부하나? 앞에서배운 " 정규식 " 은언어의 " 어휘 (lexeme)" 를표현하는도구로사용되었다. 언어의 " 구문 (syntax)" 은 " 정규언어 " 의범위를벗어나기때문에 " 정규식 " 으로표현이불가능하다. 본장에서배우는 " 문맥자유문법 " 은언어의 " 구문 (syntax)" 을표현할수있는도구이다. 어떤 " 문맥자유문법
5 Context-Free Grammar 무엇을공부하나? 앞에서배운 " 정규식 " 은언어의 " 어휘 (lexeme)" 를표현하는도구로사용되었다. 언어의 " 구문 (syntax)" 은 " 정규언어 " 의범위를벗어나기때문에 " 정규식 " 으로표현이불가능하다. 본장에서배우는 " 문맥자유문법 " 은언어의 " 구문 (syntax)" 을표현할수있는도구이다. 어떤 " 문맥자유문법
Chap 6: Graphs
 그래프표현법 인접행렬 (Adjacency Matrix) 인접리스트 (Adjacency List) 인접다중리스트 (Adjacency Multilist) 6 장. 그래프 (Page ) 인접행렬 (Adjacency Matrix) n 개의 vertex 를갖는그래프 G 의인접행렬의구성 A[n][n] (u, v) E(G) 이면, A[u][v] = Otherwise, A[u][v]
그래프표현법 인접행렬 (Adjacency Matrix) 인접리스트 (Adjacency List) 인접다중리스트 (Adjacency Multilist) 6 장. 그래프 (Page ) 인접행렬 (Adjacency Matrix) n 개의 vertex 를갖는그래프 G 의인접행렬의구성 A[n][n] (u, v) E(G) 이면, A[u][v] = Otherwise, A[u][v]
Microsoft PowerPoint - ch09 - 연결형리스트, Stack, Queue와 응용 pm0100
 2015-1 프로그래밍언어 9. 연결형리스트, Stack, Queue 2015 년 5 월 4 일 교수김영탁 영남대학교공과대학정보통신공학과 (Tel : +82-53-810-2497; Fax : +82-53-810-4742 http://antl.yu.ac.kr/; E-mail : ytkim@yu.ac.kr) 연결리스트 (Linked List) 연결리스트연산 Stack
2015-1 프로그래밍언어 9. 연결형리스트, Stack, Queue 2015 년 5 월 4 일 교수김영탁 영남대학교공과대학정보통신공학과 (Tel : +82-53-810-2497; Fax : +82-53-810-4742 http://antl.yu.ac.kr/; E-mail : ytkim@yu.ac.kr) 연결리스트 (Linked List) 연결리스트연산 Stack
step 1-1
 Written by Dr. In Ku Kim-Marshall STEP BY STEP Korean 1 through 15 Action Verbs Table of Contents Unit 1 The Korean Alphabet, hangeul Unit 2 Korean Sentences with 15 Action Verbs Introduction Review Exercises
Written by Dr. In Ku Kim-Marshall STEP BY STEP Korean 1 through 15 Action Verbs Table of Contents Unit 1 The Korean Alphabet, hangeul Unit 2 Korean Sentences with 15 Action Verbs Introduction Review Exercises
Chap 6: Graphs
 AOV Network 의표현 임의의 vertex 가 predecessor 를갖는지조사 각 vertex 에대해 immediate predecessor 의수를나타내는 count field 저장 Vertex 와그에부속된모든 edge 들을삭제 AOV network 을인접리스트로표현 count link struct node { int vertex; struct node
AOV Network 의표현 임의의 vertex 가 predecessor 를갖는지조사 각 vertex 에대해 immediate predecessor 의수를나타내는 count field 저장 Vertex 와그에부속된모든 edge 들을삭제 AOV network 을인접리스트로표현 count link struct node { int vertex; struct node
<B3EDB9AEC0DBBCBAB9FD2E687770>
 (1) 주제 의식의 원칙 논문은 주제 의식이 잘 드러나야 한다. 주제 의식은 논문을 쓰는 사람의 의도나 글의 목적 과 밀접한 관련이 있다. (2) 협력의 원칙 독자는 필자를 이해하려고 마음먹은 사람이다. 따라서 필자는 독자가 이해할 수 있는 말이 나 표현을 사용하여 독자의 노력에 협력해야 한다는 것이다. (3) 논리적 엄격성의 원칙 감정이나 독단적인 선언이
(1) 주제 의식의 원칙 논문은 주제 의식이 잘 드러나야 한다. 주제 의식은 논문을 쓰는 사람의 의도나 글의 목적 과 밀접한 관련이 있다. (2) 협력의 원칙 독자는 필자를 이해하려고 마음먹은 사람이다. 따라서 필자는 독자가 이해할 수 있는 말이 나 표현을 사용하여 독자의 노력에 협력해야 한다는 것이다. (3) 논리적 엄격성의 원칙 감정이나 독단적인 선언이
<322EBCF8C8AF28BFACBDC0B9AEC1A6292E687770>
 연습문제해답 5 4 3 2 1 0 함수의반환값 =15 5 4 3 2 1 0 함수의반환값 =95 10 7 4 1-2 함수의반환값 =3 1 2 3 4 5 연습문제해답 1. C 언어에서의배열에대하여다음중맞는것은? (1) 3차원이상의배열은불가능하다. (2) 배열의이름은포인터와같은역할을한다. (3) 배열의인덱스는 1에서부터시작한다. (4) 선언한다음, 실행도중에배열의크기를변경하는것이가능하다.
연습문제해답 5 4 3 2 1 0 함수의반환값 =15 5 4 3 2 1 0 함수의반환값 =95 10 7 4 1-2 함수의반환값 =3 1 2 3 4 5 연습문제해답 1. C 언어에서의배열에대하여다음중맞는것은? (1) 3차원이상의배열은불가능하다. (2) 배열의이름은포인터와같은역할을한다. (3) 배열의인덱스는 1에서부터시작한다. (4) 선언한다음, 실행도중에배열의크기를변경하는것이가능하다.
강의 개요
 DDL TABLE 을만들자 웹데이터베이스 TABLE 자료가저장되는공간 문자자료의경우 DB 생성시지정한 Character Set 대로저장 Table 생성시 Table 의구조를결정짓는열속성지정 열 (Clumn, Attribute) 은이름과자료형을갖는다. 자료형 : http://dev.mysql.cm/dc/refman/5.1/en/data-types.html TABLE
DDL TABLE 을만들자 웹데이터베이스 TABLE 자료가저장되는공간 문자자료의경우 DB 생성시지정한 Character Set 대로저장 Table 생성시 Table 의구조를결정짓는열속성지정 열 (Clumn, Attribute) 은이름과자료형을갖는다. 자료형 : http://dev.mysql.cm/dc/refman/5.1/en/data-types.html TABLE
PowerPoint 프레젠테이션
 Verilog: Finite State Machines CSED311 Lab03 Joonsung Kim, joonsung90@postech.ac.kr Finite State Machines Digital system design 시간에배운것과같습니다. Moore / Mealy machines Verilog 를이용해서어떻게구현할까? 2 Finite State
Verilog: Finite State Machines CSED311 Lab03 Joonsung Kim, joonsung90@postech.ac.kr Finite State Machines Digital system design 시간에배운것과같습니다. Moore / Mealy machines Verilog 를이용해서어떻게구현할까? 2 Finite State
빅데이터_DAY key
 Big Data Near You 2016. 06. 16 Prof. Sehyug Kwon Dept. of Statistics 4V s of Big Data Volume Variety Velocity Veracity Value 대용량 다양한 유형 실시간 정보 (불)확실성 가치 tera(1,0004) - peta -exazetta(10007) bytes in 2020
Big Data Near You 2016. 06. 16 Prof. Sehyug Kwon Dept. of Statistics 4V s of Big Data Volume Variety Velocity Veracity Value 대용량 다양한 유형 실시간 정보 (불)확실성 가치 tera(1,0004) - peta -exazetta(10007) bytes in 2020
FGB-P 학번수학과권혁준 2008 년 5 월 19 일 Lemma 1 p 를 C([0, 1]) 에속하는음수가되지않는함수라하자. 이때 y C 2 (0, 1) C([0, 1]) 가미분방정식 y (t) + p(t)y(t) = 0, t (0, 1), y(0)
![FGB-P 학번수학과권혁준 2008 년 5 월 19 일 Lemma 1 p 를 C([0, 1]) 에속하는음수가되지않는함수라하자. 이때 y C 2 (0, 1) C([0, 1]) 가미분방정식 y (t) + p(t)y(t) = 0, t (0, 1), y(0)](/thumbs/94/121635808.jpg "FGB-P 학번수학과권혁준 2008 년 5 월 19 일 Lemma 1 p 를 C([0, 1]) 에속하는음수가되지않는함수라하자. 이때 y C 2 (0, 1) C([0, 1]) 가미분방정식 y (t) + p(t)y(t) = 0, t (0, 1), y(0)") FGB-P8-3 8 학번수학과권혁준 8 년 5 월 9 일 Lemma p 를 C[, ] 에속하는음수가되지않는함수라하자. 이때 y C, C[, ] 가미분방정식 y t + ptyt, t,, y y 을만족하는해라고하면, y 는, 에서연속적인이계도함수를가지게확 장될수있다. Proof y 은 y 의도함수이므로미적분학의기본정리에의하여, y 은 y 의어떤원시 함수와적분상수의합으로표시될수있다.
FGB-P8-3 8 학번수학과권혁준 8 년 5 월 9 일 Lemma p 를 C[, ] 에속하는음수가되지않는함수라하자. 이때 y C, C[, ] 가미분방정식 y t + ptyt, t,, y y 을만족하는해라고하면, y 는, 에서연속적인이계도함수를가지게확 장될수있다. Proof y 은 y 의도함수이므로미적분학의기본정리에의하여, y 은 y 의어떤원시 함수와적분상수의합으로표시될수있다.
저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할
 저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할수없습니다. 변경금지. 귀하는이저작물을개작, 변형또는가공할수없습니다. 귀하는, 이저작물의재이용이나배포의경우,
저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할수없습니다. 변경금지. 귀하는이저작물을개작, 변형또는가공할수없습니다. 귀하는, 이저작물의재이용이나배포의경우,
Microsoft Word - FunctionCall
 Function all Mechanism /* Simple Program */ #define get_int() IN KEYOARD #define put_int(val) LD A val \ OUT MONITOR int add_two(int a, int b) { int tmp; tmp = a+b; return tmp; } local auto variable stack
Function all Mechanism /* Simple Program */ #define get_int() IN KEYOARD #define put_int(val) LD A val \ OUT MONITOR int add_two(int a, int b) { int tmp; tmp = a+b; return tmp; } local auto variable stack
제 12강 함수수열의 평등수렴
 제 강함수수열의평등수렴 함수의수열과극한 정의 ( 점별수렴 ): 주어진집합 과각각의자연수 에대하여함수 f : 이있다고가정하자. 이때 을집합 에서로가는함수의수열이라고한다. 모든 x 에대하여 f 수열 f ( x) lim f ( x) 가성립할때함수수열 { f } 이집합 에서함수 f 로수렴한다고한다. 또 함수 f 을집합 에서의함수수열 { f } 의극한 ( 함수 ) 이라고한다.
제 강함수수열의평등수렴 함수의수열과극한 정의 ( 점별수렴 ): 주어진집합 과각각의자연수 에대하여함수 f : 이있다고가정하자. 이때 을집합 에서로가는함수의수열이라고한다. 모든 x 에대하여 f 수열 f ( x) lim f ( x) 가성립할때함수수열 { f } 이집합 에서함수 f 로수렴한다고한다. 또 함수 f 을집합 에서의함수수열 { f } 의극한 ( 함수 ) 이라고한다.
Microsoft PowerPoint - Java7.pptx
 HPC & OT Lab. 1 HPC & OT Lab. 2 실습 7 주차 Jin-Ho, Jang M.S. Hanyang Univ. HPC&OT Lab. jinhoyo@nate.com HPC & OT Lab. 3 Component Structure 객체 (object) 생성개념을이해한다. 외부클래스에대한접근방법을이해한다. 접근제어자 (public & private)
HPC & OT Lab. 1 HPC & OT Lab. 2 실습 7 주차 Jin-Ho, Jang M.S. Hanyang Univ. HPC&OT Lab. jinhoyo@nate.com HPC & OT Lab. 3 Component Structure 객체 (object) 생성개념을이해한다. 외부클래스에대한접근방법을이해한다. 접근제어자 (public & private)
다른 JSP 페이지호출 forward() 메서드 - 하나의 JSP 페이지실행이끝나고다른 JSP 페이지를호출할때사용한다. 예 ) <% RequestDispatcher dispatcher = request.getrequestdispatcher(" 실행할페이지.jsp");
 메서드 - 하나의 JSP 페이지실행이끝나고다른 JSP 페이지를호출할때사용한다. 예 ) <% RequestDispatcher dispatcher = request.getrequestdispatcher( 실행할페이지.jsp);") 다른 JSP 페이지호출 forward() 메서드 - 하나의 JSP 페이지실행이끝나고다른 JSP 페이지를호출할때사용한다. 예 ) RequestDispatcher dispatcher = request.getrequestdispatcher(" 실행할페이지.jsp"); dispatcher.forward(request, response); - 위의예에서와같이 RequestDispatcher
다른 JSP 페이지호출 forward() 메서드 - 하나의 JSP 페이지실행이끝나고다른 JSP 페이지를호출할때사용한다. 예 ) RequestDispatcher dispatcher = request.getrequestdispatcher(" 실행할페이지.jsp"); dispatcher.forward(request, response); - 위의예에서와같이 RequestDispatcher
학습목차 2.1 다차원배열이란 차원배열의주소와값의참조
 - Part2- 제 2 장다차원배열이란무엇인가 학습목차 2.1 다차원배열이란 2. 2 2 차원배열의주소와값의참조 2.1 다차원배열이란 2.1 다차원배열이란 (1/14) 다차원배열 : 2 차원이상의배열을의미 1 차원배열과다차원배열의비교 1 차원배열 int array [12] 행 2 차원배열 int array [4][3] 행 열 3 차원배열 int array [2][2][3]
- Part2- 제 2 장다차원배열이란무엇인가 학습목차 2.1 다차원배열이란 2. 2 2 차원배열의주소와값의참조 2.1 다차원배열이란 2.1 다차원배열이란 (1/14) 다차원배열 : 2 차원이상의배열을의미 1 차원배열과다차원배열의비교 1 차원배열 int array [12] 행 2 차원배열 int array [4][3] 행 열 3 차원배열 int array [2][2][3]
2015 개정교육과정에따른정보과평가기준개발연구 연구책임자 공동연구자 연구협력관
 2015 개정교육과정에따른정보과평가기준개발연구 연구책임자 공동연구자 연구협력관 2015 개정교육과정에따른정보과평가기준개발연구 연구협력진 머리말 연구요약 차례 Ⅰ 서론 1 Ⅱ 평가준거성취기준, 평가기준, 성취수준, 예시평가도구개발방향 7 Ⅲ 정보과평가준거성취기준, 평가기준, 성취수준, 예시평가도구의개발 25 Ⅳ 정보과평가준거성취기준, 평가기준, 성취수준, 예시평가도구의활용방안
2015 개정교육과정에따른정보과평가기준개발연구 연구책임자 공동연구자 연구협력관 2015 개정교육과정에따른정보과평가기준개발연구 연구협력진 머리말 연구요약 차례 Ⅰ 서론 1 Ⅱ 평가준거성취기준, 평가기준, 성취수준, 예시평가도구개발방향 7 Ⅲ 정보과평가준거성취기준, 평가기준, 성취수준, 예시평가도구의개발 25 Ⅳ 정보과평가준거성취기준, 평가기준, 성취수준, 예시평가도구의활용방안
실험 5
 실험. OP Amp 의기초회로 Inverting Amplifier OP amp 를이용한아래와같은 inverting amplifier 회로를고려해본다. ( 그림 ) Inverting amplifier 위의회로에서 OP amp의 입력단자는 + 입력단자와동일한그라운드전압, 즉 0V를유지한다. 또한 OP amp 입력단자로흘러들어가는전류는 0 이므로, 저항에흐르는전류는다음과같다.
실험. OP Amp 의기초회로 Inverting Amplifier OP amp 를이용한아래와같은 inverting amplifier 회로를고려해본다. ( 그림 ) Inverting amplifier 위의회로에서 OP amp의 입력단자는 + 입력단자와동일한그라운드전압, 즉 0V를유지한다. 또한 OP amp 입력단자로흘러들어가는전류는 0 이므로, 저항에흐르는전류는다음과같다.
Microsoft PowerPoint - chap06-2pointer.ppt
 2010-1 학기프로그래밍입문 (1) chapter 06-2 참고자료 포인터 박종혁 Tel: 970-6702 Email: jhpark1@snut.ac.kr 한빛미디어 출처 : 뇌를자극하는 C프로그래밍, 한빛미디어 -1- 포인터의정의와사용 변수를선언하는것은메모리에기억공간을할당하는것이며할당된이후에는변수명으로그기억공간을사용한다. 할당된기억공간을사용하는방법에는변수명외에메모리의실제주소값을사용하는것이다.
2010-1 학기프로그래밍입문 (1) chapter 06-2 참고자료 포인터 박종혁 Tel: 970-6702 Email: jhpark1@snut.ac.kr 한빛미디어 출처 : 뇌를자극하는 C프로그래밍, 한빛미디어 -1- 포인터의정의와사용 변수를선언하는것은메모리에기억공간을할당하는것이며할당된이후에는변수명으로그기억공간을사용한다. 할당된기억공간을사용하는방법에는변수명외에메모리의실제주소값을사용하는것이다.
강의 개요
 정규화와 SELECT (II) 웹데이터베이스 학과 학생 과목 학과 지도교수 학과학번성명 수강과목 담당교수 A 김수정 A 0001 고길동 성질이론 김수정 B 허영만 A 0002 둘리 한식의멋 허영만 C 강풀 B 0003 희동이 심리학의이해 강풀 과목 _ 성적 학번 수강과목 성적 0001 성질이론 A 0001 한식의멋 C 0002 성질이론 A 0002 한식의멋
정규화와 SELECT (II) 웹데이터베이스 학과 학생 과목 학과 지도교수 학과학번성명 수강과목 담당교수 A 김수정 A 0001 고길동 성질이론 김수정 B 허영만 A 0002 둘리 한식의멋 허영만 C 강풀 B 0003 희동이 심리학의이해 강풀 과목 _ 성적 학번 수강과목 성적 0001 성질이론 A 0001 한식의멋 C 0002 성질이론 A 0002 한식의멋
딥러닝NLP응용_이창기
 딥러닝과 자연어처리 응용 강원대학교 IT대학 이창기 차례 딥러닝최신기술소개 딥러닝기반의자연어처리 Classification Problem Sequence Labeling Problem Sequence-to-Sequence Learning Pointer Network Recurrent Neural Network Many NLP problems can be viewed
딥러닝과 자연어처리 응용 강원대학교 IT대학 이창기 차례 딥러닝최신기술소개 딥러닝기반의자연어처리 Classification Problem Sequence Labeling Problem Sequence-to-Sequence Learning Pointer Network Recurrent Neural Network Many NLP problems can be viewed
PowerPoint 프레젠테이션
 I. 문서표준 1. 문서일반 (HY중고딕 11pt) 1-1. 파일명명체계 1-2. 문서등록정보 2. 표지표준 3. 개정이력표준 4. 목차표준 4-1. 목차슬라이드구성 4-2. 간지슬라이드구성 5. 일반표준 5-1. 번호매기기구성 5-2. 텍스트박스구성 5-3. 테이블구성 5-4. 칼라테이블구성 6. 적용예제 Machine Learning Credit Scoring
I. 문서표준 1. 문서일반 (HY중고딕 11pt) 1-1. 파일명명체계 1-2. 문서등록정보 2. 표지표준 3. 개정이력표준 4. 목차표준 4-1. 목차슬라이드구성 4-2. 간지슬라이드구성 5. 일반표준 5-1. 번호매기기구성 5-2. 텍스트박스구성 5-3. 테이블구성 5-4. 칼라테이블구성 6. 적용예제 Machine Learning Credit Scoring
OCW_C언어 기초
 초보프로그래머를위한 C 언어기초 4 장 : 연산자 2012 년 이은주 학습목표 수식의개념과연산자및피연산자에대한학습 C 의알아보기 연산자의우선순위와결합방향에대하여알아보기 2 목차 연산자의기본개념 수식 연산자와피연산자 산술연산자 / 증감연산자 관계연산자 / 논리연산자 비트연산자 / 대입연산자연산자의우선순위와결합방향 조건연산자 / 형변환연산자 연산자의우선순위 연산자의결합방향
초보프로그래머를위한 C 언어기초 4 장 : 연산자 2012 년 이은주 학습목표 수식의개념과연산자및피연산자에대한학습 C 의알아보기 연산자의우선순위와결합방향에대하여알아보기 2 목차 연산자의기본개념 수식 연산자와피연산자 산술연산자 / 증감연산자 관계연산자 / 논리연산자 비트연산자 / 대입연산자연산자의우선순위와결합방향 조건연산자 / 형변환연산자 연산자의우선순위 연산자의결합방향
(JBE Vol. 24, No. 1, January 2019) (Special Paper) 24 1, (JBE Vol. 24, No. 1, January 2019) ISSN 2287-
 (Special Paper) 24 1, (JBE Vol. 24, No. 1, January 2019) ISSN 2287-") (Special Paper) 24 1 2019 1 (JBE Vol. 24 No. 1 January 2019) https//doi.org/10.5909/jbe.2019.24.1.58 ISSN 2287-9137 (Online) ISSN 1226-7953 (Print) a) a) a) b) c) d) A Study on Named Entity Recognition
(Special Paper) 24 1 2019 1 (JBE Vol. 24 No. 1 January 2019) https//doi.org/10.5909/jbe.2019.24.1.58 ISSN 2287-9137 (Online) ISSN 1226-7953 (Print) a) a) a) b) c) d) A Study on Named Entity Recognition
Software Requirrment Analysis를 위한 정보 검색 기술의 응용
 EPG 정보 검색을 위한 예제 기반 자연어 대화 시스템 김석환 * 이청재 정상근 이근배 포항공과대학교 컴퓨터공학과 지능소프트웨어연구실 {megaup, lcj80, hugman, gblee}@postech.ac.kr An Example-Based Natural Language System for EPG Information Access Seokhwan Kim
EPG 정보 검색을 위한 예제 기반 자연어 대화 시스템 김석환 * 이청재 정상근 이근배 포항공과대학교 컴퓨터공학과 지능소프트웨어연구실 {megaup, lcj80, hugman, gblee}@postech.ac.kr An Example-Based Natural Language System for EPG Information Access Seokhwan Kim
설계란 무엇인가?
 금오공과대학교 C++ 프로그래밍 jhhwang@kumoh.ac.kr 컴퓨터공학과 황준하 6 강. 함수와배열, 포인터, 참조목차 함수와포인터 주소값의매개변수전달 주소의반환 함수와배열 배열의매개변수전달 함수와참조 참조에의한매개변수전달 참조의반환 프로그래밍연습 1 /15 6 강. 함수와배열, 포인터, 참조함수와포인터 C++ 매개변수전달방법 값에의한전달 : 변수값,
금오공과대학교 C++ 프로그래밍 jhhwang@kumoh.ac.kr 컴퓨터공학과 황준하 6 강. 함수와배열, 포인터, 참조목차 함수와포인터 주소값의매개변수전달 주소의반환 함수와배열 배열의매개변수전달 함수와참조 참조에의한매개변수전달 참조의반환 프로그래밍연습 1 /15 6 강. 함수와배열, 포인터, 참조함수와포인터 C++ 매개변수전달방법 값에의한전달 : 변수값,
<BBE7C8B8C0FBC0C7BBE7BCD2C5EBBFACB1B820C3D6C1BEBAB8B0EDBCAD2E687770>
 국립국어원 2007-01-42 사회적의사소통연구 : 성차별적언어표현사례조사및대안마련을위한연구 국립국어원 한국여성정책연구원 제출문 국립국어원장귀하 국립국어원의국고보조금지원으로수행한 사회적의사 소통연구 : 성차별적언어표현사례조사및대안마련을위한 연구 의결과보고서를작성하여제출합니다. 한국여성정책연구원 안상수 백영주, 양애경, 강혜란, 윤정주 목 차 연구개요 선행연구의고찰
국립국어원 2007-01-42 사회적의사소통연구 : 성차별적언어표현사례조사및대안마련을위한연구 국립국어원 한국여성정책연구원 제출문 국립국어원장귀하 국립국어원의국고보조금지원으로수행한 사회적의사 소통연구 : 성차별적언어표현사례조사및대안마련을위한 연구 의결과보고서를작성하여제출합니다. 한국여성정책연구원 안상수 백영주, 양애경, 강혜란, 윤정주 목 차 연구개요 선행연구의고찰
Microsoft PowerPoint - ch07 - 포인터 pm0415
 2015-1 프로그래밍언어 7. 포인터 (Pointer), 동적메모리할당 2015 년 4 월 4 일 교수김영탁 영남대학교공과대학정보통신공학과 (Tel : +82-53-810-2497; Fax : +82-53-810-4742 http://antl.yu.ac.kr/; E-mail : ytkim@yu.ac.kr) Outline 포인터 (pointer) 란? 간접참조연산자
2015-1 프로그래밍언어 7. 포인터 (Pointer), 동적메모리할당 2015 년 4 월 4 일 교수김영탁 영남대학교공과대학정보통신공학과 (Tel : +82-53-810-2497; Fax : +82-53-810-4742 http://antl.yu.ac.kr/; E-mail : ytkim@yu.ac.kr) Outline 포인터 (pointer) 란? 간접참조연산자
THE JOURNAL OF KOREAN INSTITUTE OF ELECTROMAGNETIC ENGINEERING AND SCIENCE Jul.; 29(7),
,") THE JOURNAL OF KOREAN INSTITUTE OF ELECTROMAGNETIC ENGINEERING AND SCIENCE. 2018 Jul.; 29(7), 550 559. http://dx.doi.org/10.5515/kjkiees.2018.29.7.550 ISSN 1226-3133 (Print) ISSN 2288-226X (Online) Human
THE JOURNAL OF KOREAN INSTITUTE OF ELECTROMAGNETIC ENGINEERING AND SCIENCE. 2018 Jul.; 29(7), 550 559. http://dx.doi.org/10.5515/kjkiees.2018.29.7.550 ISSN 1226-3133 (Print) ISSN 2288-226X (Online) Human
<BFACBDC0B9AEC1A6C7AEC0CC5F F E687770>
 IT OOKOOK 87 이론, 실습, 시뮬레이션 디지털논리회로 ( 개정 3 판 ) (Problem Solutions of hapter 9) . T 플립플롭으로구성된순서논리회로의해석 () 변수명칭부여 F-F 플립플롭의입력 :, F-F 플립플롭의출력 :, (2) 불대수식유도 플립플롭의입력 : F-F 플립플롭의입력 : F-F 플립플롭의출력 : (3) 상태표작성 이면,
IT OOKOOK 87 이론, 실습, 시뮬레이션 디지털논리회로 ( 개정 3 판 ) (Problem Solutions of hapter 9) . T 플립플롭으로구성된순서논리회로의해석 () 변수명칭부여 F-F 플립플롭의입력 :, F-F 플립플롭의출력 :, (2) 불대수식유도 플립플롭의입력 : F-F 플립플롭의입력 : F-F 플립플롭의출력 : (3) 상태표작성 이면,
법학박사학위논문 실손의료보험연구 2018 년 8 월 서울대학교대학원 법과대학보험법전공 박성민
 저작자표시 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 이차적저작물을작성할수있습니다. 이저작물을영리목적으로이용할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 귀하는, 이저작물의재이용이나배포의경우, 이저작물에적용된이용허락조건을명확하게나타내어야합니다.
저작자표시 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 이차적저작물을작성할수있습니다. 이저작물을영리목적으로이용할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 귀하는, 이저작물의재이용이나배포의경우, 이저작물에적용된이용허락조건을명확하게나타내어야합니다.
지능정보연구제 16 권제 1 호 2010 년 3 월 (pp.71~92),.,.,., Support Vector Machines,,., KOSPI200.,. * 지능정보연구제 16 권제 1 호 2010 년 3 월
,.,.,., Support Vector Machines,,., KOSPI200.,. * 지능정보연구제 16 권제 1 호 2010 년 3 월") 지능정보연구제 16 권제 1 호 2010 년 3 월 (pp.71~92),.,.,., Support Vector Machines,,., 2004 5 2009 12 KOSPI200.,. * 2009. 지능정보연구제 16 권제 1 호 2010 년 3 월 김선웅 안현철 社 1), 28 1, 2009, 4. 1. 지능정보연구제 16 권제 1 호 2010 년 3 월 Support
지능정보연구제 16 권제 1 호 2010 년 3 월 (pp.71~92),.,.,., Support Vector Machines,,., 2004 5 2009 12 KOSPI200.,. * 2009. 지능정보연구제 16 권제 1 호 2010 년 3 월 김선웅 안현철 社 1), 28 1, 2009, 4. 1. 지능정보연구제 16 권제 1 호 2010 년 3 월 Support
Structural SVMs 및 Pegasos 알고리즘을 이용한 한국어 개체명 인식
 Deep Learning 차례 현재딥러닝기술수준소개 딥러닝 딥러닝기반의자연어처리 Object Recognition https://www.youtube.com/watch?v=n5up_lp9smm Semantic Segmentation https://youtu.be/zjmtdrbqh40 Semantic Segmentation VGGNet + Deconvolution
Deep Learning 차례 현재딥러닝기술수준소개 딥러닝 딥러닝기반의자연어처리 Object Recognition https://www.youtube.com/watch?v=n5up_lp9smm Semantic Segmentation https://youtu.be/zjmtdrbqh40 Semantic Segmentation VGGNet + Deconvolution
저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할
 저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할수없습니다. 변경금지. 귀하는이저작물을개작, 변형또는가공할수없습니다. 귀하는, 이저작물의재이용이나배포의경우,
저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할수없습니다. 변경금지. 귀하는이저작물을개작, 변형또는가공할수없습니다. 귀하는, 이저작물의재이용이나배포의경우,
PowerPoint 프레젠테이션
 Visual Search At SK-Planet sk-planet Machine Intelligence Lab. 나상일 1. 개발배경 2. 첫접근방법 3. 개선된방법 A. Visual recognition technology B. Guided search C. Retrieval system 개발배경 개발배경 상품검색을좀더쉽게 Key-word 트렌치코트버튺벨트
Visual Search At SK-Planet sk-planet Machine Intelligence Lab. 나상일 1. 개발배경 2. 첫접근방법 3. 개선된방법 A. Visual recognition technology B. Guided search C. Retrieval system 개발배경 개발배경 상품검색을좀더쉽게 Key-word 트렌치코트버튺벨트
chap x: G입력
 재귀알고리즘 (Recursive Algorithms) 재귀알고리즘의특징 문제자체가재귀적일경우적합 ( 예 : 피보나치수열 ) 이해하기가용이하나, 비효율적일수있음 재귀알고리즘을작성하는방법 재귀호출을종료하는경계조건을설정 각단계마다경계조건에접근하도록알고리즘의재귀호출 재귀알고리즘의두가지예 이진검색 순열 (Permutations) 1 장. 기본개념 (Page 19) 이진검색의재귀알고리즘
재귀알고리즘 (Recursive Algorithms) 재귀알고리즘의특징 문제자체가재귀적일경우적합 ( 예 : 피보나치수열 ) 이해하기가용이하나, 비효율적일수있음 재귀알고리즘을작성하는방법 재귀호출을종료하는경계조건을설정 각단계마다경계조건에접근하도록알고리즘의재귀호출 재귀알고리즘의두가지예 이진검색 순열 (Permutations) 1 장. 기본개념 (Page 19) 이진검색의재귀알고리즘
저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할
 저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할수없습니다. 변경금지. 귀하는이저작물을개작, 변형또는가공할수없습니다. 귀하는, 이저작물의재이용이나배포의경우,
저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할수없습니다. 변경금지. 귀하는이저작물을개작, 변형또는가공할수없습니다. 귀하는, 이저작물의재이용이나배포의경우,
Microsoft PowerPoint - 27.pptx
 이산수학 () n-항관계 (n-ary Relations) 2011년봄학기 강원대학교컴퓨터과학전공문양세 n-ary Relations (n-항관계 ) An n-ary relation R on sets A 1,,A n, written R:A 1,,A n, is a subset R A 1 A n. (A 1,,A n 에대한 n- 항관계 R 은 A 1 A n 의부분집합이다.)
이산수학 () n-항관계 (n-ary Relations) 2011년봄학기 강원대학교컴퓨터과학전공문양세 n-ary Relations (n-항관계 ) An n-ary relation R on sets A 1,,A n, written R:A 1,,A n, is a subset R A 1 A n. (A 1,,A n 에대한 n- 항관계 R 은 A 1 A n 의부분집합이다.)
<4D F736F F F696E74202D20C1A63036C0E520BCB1C5C3B0FA20B9DDBAB928B0ADC0C729205BC8A3C8AF20B8F0B5E55D>
 Power Java 제 6 장선택과반복 이번장에서학습할내용 조건문이란? if 문 if, else 문 중첩 if 문 switch 문 break문 continue문 지금까지는문장들이순차적으로실행된다고하였다. 하지만필요에따라서조건이만족되면문장의실행순서를변경할수있는기능이제공된다. 3 가지의제어구조 조건문 문장이실행되는순서에영향을주는문장 조건에따라서여러개의실행경로가운데하나를선택
Power Java 제 6 장선택과반복 이번장에서학습할내용 조건문이란? if 문 if, else 문 중첩 if 문 switch 문 break문 continue문 지금까지는문장들이순차적으로실행된다고하였다. 하지만필요에따라서조건이만족되면문장의실행순서를변경할수있는기능이제공된다. 3 가지의제어구조 조건문 문장이실행되는순서에영향을주는문장 조건에따라서여러개의실행경로가운데하나를선택
저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할
 저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할수없습니다. 변경금지. 귀하는이저작물을개작, 변형또는가공할수없습니다. 귀하는, 이저작물의재이용이나배포의경우,
저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할수없습니다. 변경금지. 귀하는이저작물을개작, 변형또는가공할수없습니다. 귀하는, 이저작물의재이용이나배포의경우,
프로그래밍개론및실습 2015 년 2 학기프로그래밍개론및실습과목으로본내용은강의교재인생능출판사, 두근두근 C 언어수업, 천인국지음을발췌수정하였음
 프로그래밍개론및실습 2015 년 2 학기프로그래밍개론및실습과목으로본내용은강의교재인생능출판사, 두근두근 C 언어수업, 천인국지음을발췌수정하였음 CHAPTER 9 둘중하나선택하기 관계연산자 두개의피연산자를비교하는연산자 결과값은참 (1) 아니면거짓 (0) x == y x 와 y 의값이같은지비교한다. 관계연산자 연산자 의미 x == y x와 y가같은가? x!= y
프로그래밍개론및실습 2015 년 2 학기프로그래밍개론및실습과목으로본내용은강의교재인생능출판사, 두근두근 C 언어수업, 천인국지음을발췌수정하였음 CHAPTER 9 둘중하나선택하기 관계연산자 두개의피연산자를비교하는연산자 결과값은참 (1) 아니면거짓 (0) x == y x 와 y 의값이같은지비교한다. 관계연산자 연산자 의미 x == y x와 y가같은가? x!= y
슬라이드 제목 없음
 5.2 ER 모델 ( 계속 ) 관계와관계타입 관계는엔티티들사이에존재하는연관이나연결로서두개이상의엔티티타입들사이의사상으로생각할수있음 관계집합은동질의관계들의집합 관계타입은동질의관계들의틀 관계집합과관계타입을엄격하게구분할필요는없음 요구사항명세에서흔히동사는 ER 다이어그램에서관계로표현됨 ER 다이어그램에서다이어몬드로표기 관계타입이서로연관시키는엔티티타입들을관계타입에실선으로연결함
5.2 ER 모델 ( 계속 ) 관계와관계타입 관계는엔티티들사이에존재하는연관이나연결로서두개이상의엔티티타입들사이의사상으로생각할수있음 관계집합은동질의관계들의집합 관계타입은동질의관계들의틀 관계집합과관계타입을엄격하게구분할필요는없음 요구사항명세에서흔히동사는 ER 다이어그램에서관계로표현됨 ER 다이어그램에서다이어몬드로표기 관계타입이서로연관시키는엔티티타입들을관계타입에실선으로연결함
 이보고서는 2010 년한국언론진흥재단의언론진흥기금을지원받아수행한것입니다. 보고서의내용은한국언론진흥재단의공식견해가아닌연구자의연구결과임을밝힙니다. 목 차 요약문 ⅳ Ⅰ. 서론 1 5 6 7 7 11 13 14 14 16 18 21 29 40-1 - 47 47 48 66 68 69 70 70 71 72 72 73 74-2 - < 표 > 목차 표 1 대한매일신보보급부수
이보고서는 2010 년한국언론진흥재단의언론진흥기금을지원받아수행한것입니다. 보고서의내용은한국언론진흥재단의공식견해가아닌연구자의연구결과임을밝힙니다. 목 차 요약문 ⅳ Ⅰ. 서론 1 5 6 7 7 11 13 14 14 16 18 21 29 40-1 - 47 47 48 66 68 69 70 70 71 72 72 73 74-2 - < 표 > 목차 표 1 대한매일신보보급부수
PowerPoint 프레젠테이션
 Autodesk Software 개인용 ( 학생, 교사 ) 다운로드가이드 진동환 (donghwan.jin@autodesk.com) Manager Autodesk Education Program - Korea Autodesk Education Expert 프로그램 www.autodesk.com/educationexperts 교육전문가프로그램 글로벌한네트워크 /
Autodesk Software 개인용 ( 학생, 교사 ) 다운로드가이드 진동환 (donghwan.jin@autodesk.com) Manager Autodesk Education Program - Korea Autodesk Education Expert 프로그램 www.autodesk.com/educationexperts 교육전문가프로그램 글로벌한네트워크 /
슬라이드 1
 빅데이터분석을위한데이터마이닝방법론 SAS Enterprise Miner 활용사례를중심으로 9 주차 예측모형에대한평가 Assessment of Predictive Model 최종후, 강현철 차례 6. 모형평가의기본개념 6.2 모델비교 (Model Comparison) 노드 6.3 임계치 (Cutoff) 노드 6.4 의사결정 (Decisions) 노드 6.5 기타모형화노드들
빅데이터분석을위한데이터마이닝방법론 SAS Enterprise Miner 활용사례를중심으로 9 주차 예측모형에대한평가 Assessment of Predictive Model 최종후, 강현철 차례 6. 모형평가의기본개념 6.2 모델비교 (Model Comparison) 노드 6.3 임계치 (Cutoff) 노드 6.4 의사결정 (Decisions) 노드 6.5 기타모형화노드들
WINDOW FUNCTION 의이해와활용방법 엑셈컨설팅본부 / DB 컨설팅팀정동기 개요 Window Function 이란행과행간의관계를쉽게정의할수있도록만든함수이다. 윈도우함수를활용하면복잡한 SQL 들을하나의 SQL 문장으로변경할수있으며반복적으로 ACCESS 하는비효율역
 WINDOW FUNCTION 의이해와활용방법 엑셈컨설팅본부 / DB 컨설팅팀정동기 개요 Window Function 이란행과행간의관계를쉽게정의할수있도록만든함수이다. 윈도우함수를활용하면복잡한 SQL 들을하나의 SQL 문장으로변경할수있으며반복적으로 ACCESS 하는비효율역시쉽게해결할수있다. 이번화이트페이퍼에서는 Window Function 중순위 RANK, ROW_NUMBER,
WINDOW FUNCTION 의이해와활용방법 엑셈컨설팅본부 / DB 컨설팅팀정동기 개요 Window Function 이란행과행간의관계를쉽게정의할수있도록만든함수이다. 윈도우함수를활용하면복잡한 SQL 들을하나의 SQL 문장으로변경할수있으며반복적으로 ACCESS 하는비효율역시쉽게해결할수있다. 이번화이트페이퍼에서는 Window Function 중순위 RANK, ROW_NUMBER,
SNU =10100 =minusby by1000 ÇÁto0.03exÇÁto0.03exÇÁ=10100 =minusby by1000 ·Îto0.03ex·Îto0.03ex·Î=10100 =minusby by1000
 SNU 4190.210 프로그래밍 원리 (Principles of Programming) Part III Prof. Kwangkeun Yi 차례 1 값중심 vs 물건중심프로그래밍 (applicative vs imperative programming) 2 프로그램의이해 : 환경과메모리 (environment & memory) 다음 1 값중심 vs 물건중심프로그래밍
SNU 4190.210 프로그래밍 원리 (Principles of Programming) Part III Prof. Kwangkeun Yi 차례 1 값중심 vs 물건중심프로그래밍 (applicative vs imperative programming) 2 프로그램의이해 : 환경과메모리 (environment & memory) 다음 1 값중심 vs 물건중심프로그래밍
보고싶었던 Deep Learning과 OpenCV를이용한이미지처리과정에대해공부를해볼수있으며더나아가 Deep Learning기술을이용하여논문을작성하는데많은도움을받을수있으며아직배우는단계에있는저에게는기존의연구를따라해보는것만으로도큰발전이있다고생각했습니다. 그래서이번 DSP스마
 특성화사업참가결과보고서 작성일 2017 12.22 학과전자공학과 참가활동명 EATED 30 프로그램지도교수최욱 연구주제명 Machine Learning 을이용한얼굴학습 학번 201301165 성명조원 I. OBJECTIVES 사람들은새로운사람들을보고인식을하는데걸리는시간은 1초채되지않다고합니다. 뿐만아니라사람들의얼굴을인식하는인식률은무려 97.5% 정도의매우높은정확도를가지고있습니다.
특성화사업참가결과보고서 작성일 2017 12.22 학과전자공학과 참가활동명 EATED 30 프로그램지도교수최욱 연구주제명 Machine Learning 을이용한얼굴학습 학번 201301165 성명조원 I. OBJECTIVES 사람들은새로운사람들을보고인식을하는데걸리는시간은 1초채되지않다고합니다. 뿐만아니라사람들의얼굴을인식하는인식률은무려 97.5% 정도의매우높은정확도를가지고있습니다.
게시판 스팸 실시간 차단 시스템
 오픈 API 2014. 11-1 - 목 차 1. 스팸지수측정요청프로토콜 3 1.1 스팸지수측정요청프로토콜개요 3 1.2 스팸지수측정요청방법 3 2. 게시판스팸차단도구오픈 API 활용 5 2.1 PHP 5 2.1.1 차단도구오픈 API 적용방법 5 2.1.2 차단도구오픈 API 스팸지수측정요청 5 2.1.3 차단도구오픈 API 스팸지수측정결과값 5 2.2 JSP
오픈 API 2014. 11-1 - 목 차 1. 스팸지수측정요청프로토콜 3 1.1 스팸지수측정요청프로토콜개요 3 1.2 스팸지수측정요청방법 3 2. 게시판스팸차단도구오픈 API 활용 5 2.1 PHP 5 2.1.1 차단도구오픈 API 적용방법 5 2.1.2 차단도구오픈 API 스팸지수측정요청 5 2.1.3 차단도구오픈 API 스팸지수측정결과값 5 2.2 JSP
소성해석
 3 강유한요소법 3 강목차 3. 미분방정식의근사해법-Ritz법 3. 미분방정식의근사해법 가중오차법 3.3 유한요소법개념 3.4 편미분방정식의유한요소법 . CAD 전처리프로그램 (Preprocessor) DXF, STL 파일 입력데이타 유한요소솔버 (Finite Element Solver) 자연법칙지배방정식유한요소방정식파생변수의계산 질량보존법칙 연속방정식 뉴톤의운동법칙평형방정식대수방정식
3 강유한요소법 3 강목차 3. 미분방정식의근사해법-Ritz법 3. 미분방정식의근사해법 가중오차법 3.3 유한요소법개념 3.4 편미분방정식의유한요소법 . CAD 전처리프로그램 (Preprocessor) DXF, STL 파일 입력데이타 유한요소솔버 (Finite Element Solver) 자연법칙지배방정식유한요소방정식파생변수의계산 질량보존법칙 연속방정식 뉴톤의운동법칙평형방정식대수방정식
(b) 미분기 (c) 적분기 그림 6.1. 연산증폭기연산응용회로
 미분기 (c) 적분기 그림 6.1. 연산증폭기연산응용회로") Lab. 1. I-V Characteristics of a Diode Lab. 6. 연산증폭기가산기, 미분기, 적분기회로 1. 실험목표 연산증폭기를이용한가산기, 미분기및적분기회로를구성, 측정및 평가해서연산증폭기연산응용회로를이해 2. 실험회로 A. 연산증폭기연산응용회로 (a) 가산기 (b) 미분기 (c) 적분기 그림 6.1. 연산증폭기연산응용회로 3. 실험장비및부품리스트
Lab. 1. I-V Characteristics of a Diode Lab. 6. 연산증폭기가산기, 미분기, 적분기회로 1. 실험목표 연산증폭기를이용한가산기, 미분기및적분기회로를구성, 측정및 평가해서연산증폭기연산응용회로를이해 2. 실험회로 A. 연산증폭기연산응용회로 (a) 가산기 (b) 미분기 (c) 적분기 그림 6.1. 연산증폭기연산응용회로 3. 실험장비및부품리스트
PowerPoint 프레젠테이션
 실습 1 배효철 th1g@nate.com 1 목차 조건문 반복문 System.out 구구단 모양만들기 Up & Down 2 조건문 조건문의종류 If, switch If 문 조건식결과따라중괄호 { 블록을실행할지여부결정할때사용 조건식 true 또는 false값을산출할수있는연산식 boolean 변수 조건식이 true이면블록실행하고 false 이면블록실행하지않음 3
실습 1 배효철 th1g@nate.com 1 목차 조건문 반복문 System.out 구구단 모양만들기 Up & Down 2 조건문 조건문의종류 If, switch If 문 조건식결과따라중괄호 { 블록을실행할지여부결정할때사용 조건식 true 또는 false값을산출할수있는연산식 boolean 변수 조건식이 true이면블록실행하고 false 이면블록실행하지않음 3
PowerPoint 프레젠테이션
 System Software Experiment 1 Lecture 5 - Array Spring 2019 Hwansoo Han (hhan@skku.edu) Advanced Research on Compilers and Systems, ARCS LAB Sungkyunkwan University http://arcs.skku.edu/ 1 배열 (Array) 동일한타입의데이터가여러개저장되어있는저장장소
System Software Experiment 1 Lecture 5 - Array Spring 2019 Hwansoo Han (hhan@skku.edu) Advanced Research on Compilers and Systems, ARCS LAB Sungkyunkwan University http://arcs.skku.edu/ 1 배열 (Array) 동일한타입의데이터가여러개저장되어있는저장장소
저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할
 저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할수없습니다. 변경금지. 귀하는이저작물을개작, 변형또는가공할수없습니다. 귀하는, 이저작물의재이용이나배포의경우,
저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할수없습니다. 변경금지. 귀하는이저작물을개작, 변형또는가공할수없습니다. 귀하는, 이저작물의재이용이나배포의경우,
Microsoft PowerPoint - chap06-1Array.ppt
 2010-1 학기프로그래밍입문 (1) chapter 06-1 참고자료 배열 박종혁 Tel: 970-6702 Email: jhpark1@snut.ac.kr 한빛미디어 출처 : 뇌를자극하는 C프로그래밍, 한빛미디어 -1- 배열의선언과사용 같은형태의자료형이많이필요할때배열을사용하면효과적이다. 배열의선언 배열의사용 배열과반복문 배열의초기화 유연성있게배열다루기 한빛미디어
2010-1 학기프로그래밍입문 (1) chapter 06-1 참고자료 배열 박종혁 Tel: 970-6702 Email: jhpark1@snut.ac.kr 한빛미디어 출처 : 뇌를자극하는 C프로그래밍, 한빛미디어 -1- 배열의선언과사용 같은형태의자료형이많이필요할때배열을사용하면효과적이다. 배열의선언 배열의사용 배열과반복문 배열의초기화 유연성있게배열다루기 한빛미디어
2 PX-8000과 RM-8000/LM-8000등의 관련 제품은 시스템의 간편한 설치와 쉬운 운영에 대한 고급 기술을 제공합니다. 또한 뛰어난 확장성으로 사용자가 요구하는 시스템을 손쉽게 구현할 수 있습니다. 메인컨트롤러인 PX-8000의 BGM입력소스를 8개의 로컬지
 PX-8000 SYSTEM 8 x 8 Audio Matrix with Local Control 2 PX-8000과 RM-8000/LM-8000등의 관련 제품은 시스템의 간편한 설치와 쉬운 운영에 대한 고급 기술을 제공합니다. 또한 뛰어난 확장성으로 사용자가 요구하는 시스템을 손쉽게 구현할 수 있습니다. 메인컨트롤러인 PX-8000의 BGM입력소스를 8개의 로컬지역에
PX-8000 SYSTEM 8 x 8 Audio Matrix with Local Control 2 PX-8000과 RM-8000/LM-8000등의 관련 제품은 시스템의 간편한 설치와 쉬운 운영에 대한 고급 기술을 제공합니다. 또한 뛰어난 확장성으로 사용자가 요구하는 시스템을 손쉽게 구현할 수 있습니다. 메인컨트롤러인 PX-8000의 BGM입력소스를 8개의 로컬지역에
Gray level 변환 및 Arithmetic 연산을 사용한 영상 개선
 Point Operation Histogram Modification 김성영교수 금오공과대학교 컴퓨터공학과 학습내용 HISTOGRAM HISTOGRAM MODIFICATION DETERMINING THRESHOLD IN THRESHOLDING 2 HISTOGRAM A simple datum that gives the number of pixels that a
Point Operation Histogram Modification 김성영교수 금오공과대학교 컴퓨터공학과 학습내용 HISTOGRAM HISTOGRAM MODIFICATION DETERMINING THRESHOLD IN THRESHOLDING 2 HISTOGRAM A simple datum that gives the number of pixels that a
세계 비지니스 정보
 - i - ii - iii - iv - v - vi - vii - viii - ix - 1 - 2 - 3 - - - - - - - - - - 4 - - - - - - 5 - - - - - - - - - - - 6 - - - - - - - - - 7 - - - - 8 - 9 - 10 - - - - - - - - - - - - 11 - - - 12 - 13 -
- i - ii - iii - iv - v - vi - vii - viii - ix - 1 - 2 - 3 - - - - - - - - - - 4 - - - - - - 5 - - - - - - - - - - - 6 - - - - - - - - - 7 - - - - 8 - 9 - 10 - - - - - - - - - - - - 11 - - - 12 - 13 -