슬라이드 1
|
|
|
- 유미 저
- 4 years ago
- Views:
Transcription


1 누리온슈퍼컴퓨터소개및실습 Intel Parallel Computing Center at KISTI
2 Agenda 09:00 10:30 누리온소개 10:45 12:15 접속및누리온실습 12:15 13:30 점심 13:30 15:00 성능최적화실습 (I) 15:15 16:45 성능최적화실습 (II) 2

![th -2] SUN B6048[4 th -1]](/docs-images/100/146097198/images/3-5.jpg "NEC SX-6[3 rd -2] Cray")
![T3E NEC SX-5[3 rd -1]](/docs-images/100/146097198/images/3-6.jpg "Tera Cluster Cray 2S[1 st")
![] Cray CS500[5 th ] 1988](/docs-images/100/146097198/images/3-7.jpg "1993 1997 2000 2001 2002")



![7PFlops Cray C90[2 nd ]](/docs-images/100/146097198/images/3-11.jpg "HP GS320 HPC 160/320")
3 History of KISTI Supercomputer SUN B6275[4 th -2] SUN B6048[4 th -1] NEC SX-6[3 rd -2] Cray T3E NEC SX-5[3 rd -1] Tera Cluster Cray 2S[1 st ] Cray CS500[5 th ] GFlops 16GFlops 131GFlops 242GFlops 306GFlops 1,407GFlops 8,000GFlops 30TFlops TFlops 25.7PFlops Cray C90[2 nd ] HP GS320 HPC 160/320 Pluto cluster IBM p690[3 rd -1] IBM p690[3 rd -2] IBM p595[4 th ] 3
 / 1 socket 메인메모리 이론성능 노드당 96GB DDR + 16GB MCDRAM 노드당 3.0464TFlops 구분 모델 운영체제 내용 노드수 132 Cray 3111-BA000T CentOS 7.4 (Linux, 64-bit) CPU Intel Xeon Skylake(Gold 6148) 2.")
4 Nurion System 누리 ( 세상, 세계, 함께누리다 )+ 온 ( 전부, 모두의 ) 온국민이다함께누리는국가슈퍼컴퓨터 KNL Node( 누리온 ) SKL Node( 누리온 ) 구분 모델 운영체제 내용 노드수 8305 Cray 3112-AA000T CentOS 7.4 (Linux, 64-bit) CPU Intel Xeon Phi KNL GHz(68-core) / 1 socket 메인메모리 이론성능 노드당 96GB DDR + 16GB MCDRAM 노드당 TFlops 구분 모델 운영체제 내용 노드수 132 Cray 3111-BA000T CentOS 7.4 (Linux, 64-bit) CPU Intel Xeon Skylake(Gold 6148) 2.4GHz(20-core) /2 sockets 메인메모리 이론성능 노드당 192GB DDR4 Memory 노드당 3.072TFlops 4


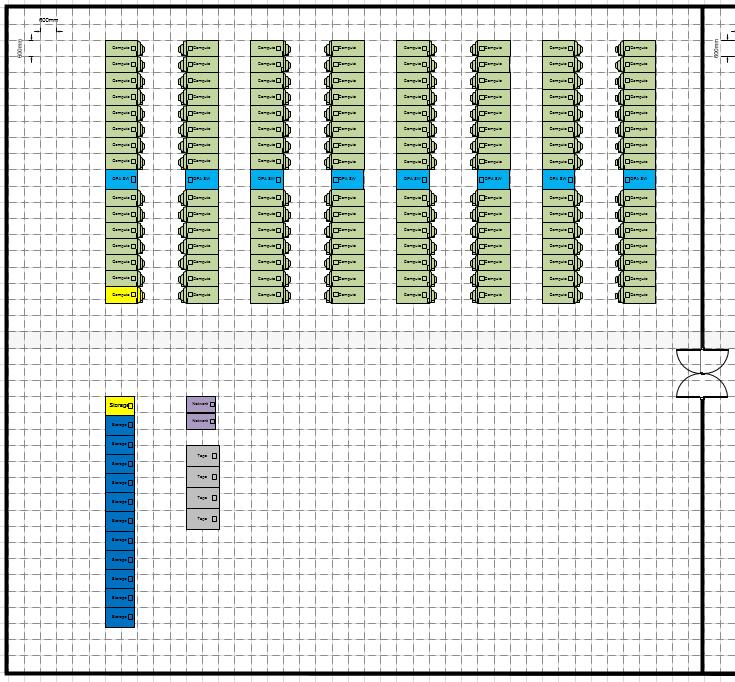







5 누리온시스템하드웨어 후면냉각도어 전면 상부 OPA 케이블 8 열, 126 랙 15x CS500 12x DDN Lustre Storage 병렬파일시스템 (20PB) Testbed Network Switch TS 4500 Tape Library 5 OPA Core Switch 테이프스토리지 (10PB)




6 Compute Node(KNL) Cray 3112-AA000T 1 x Intel Xeon Phi KNL 7250 processor(68 cores per processor) 96GB(6*16GB) DDR-2400 RAM 1x Single-port 100Gbps OPA HFI card 1x On-board GigE(RJ45) port 6

 DDR4-2666 RAM 1x")
")
7 Compute Node(SKL) Cray 3111-BA000T 2 x Intel Xeon SKL 6148 processors 192GB (12x 16GB) DDR RAM 1x Single-port 100Gbps OPA HFI card 1x On-board GigE(RJ45) port 7
8 Performance(Flops) 노드당성능 KNL Core : (8*2)*(2)*1.4G = 44.8Gflops Node : 44.8*68=3046.4Gflops SKL Core : (8*2)*(2)*2.4G=76.8Gflops Node : 2*20*76.8Gflops/core = 3.072Tflops KNL SKL Number of cores SIMD width (doubles) 8 * 2 8 * 2 Multiply/add in 1 cycle 2 2 Clock speed(gcycle/s) DP Gflop/s/core DP Gflops/s/processor 누리온 KNL SKL 8305 nodes : Tflps*8305=25.3Pflops 132 nodes : 3.072Tflps*132=405.5Tflops=0.4Pflops KNL+SKL : ( ) Pflops = 25.7Pflops Tachyon2 : Tflops Benchmarks HPL HPCG GRAPH IO Performance 13.92PF (No.13) TF (No.8) GTEPS(No.23) 16.67pt(No.2) 8
9 SW 리스트 구분 항목 Cray 의존라이브러리 cdt/17.10 cray-impi/1.1.4(default) mvapich2_cce/2.2rc1.0.3_noslurm(default) cray-ccdb/3.0.3(default) mvapich2_gnu/2.2rc1.0.3_noslurm perftools-lite/6.5.2(default) cray-lgdb/3.0.7(default) PrgEnv-cray/1.0.2(default) 컴파일러 cce/8.6.3(default) gcc/6.1.0 gcc/7.2.0 intel/17.0.5(default) intel/ intel/ MPI 라이브러리 ime/mvapich-verbs/2.2.ddn1.4 impi/17.0.5(default) impi/ openmpi/3.1.0 ime/openmpi/1.10.ddn1.0 impi/ mvapich2/2.3 MPI 의존라이브러리 fftw_mpi/2.1.5 fftw_mpi/3.3.7 hdf5-parallel/ netcdfhdf5-parallel/4.6.1 parallel-netcdf/ pio/2.3.1 Libraries hdf4/ hdf5/ lapack/3.7.0 ncl/6.5.0 ncview/2.1.7 netcdf/4.6.1 Commercial applications cfx/v145 cfx/v181 fluent/v145 fluent/v181 gaussian/g16.a03 lsdyna/mpp cfx/v170 cfx/v191 fluent/v170 fluent/v191 gaussian/g16.a03.linda lsdyna/smp applications advisor/ forge/ ImageMagick/ python/3.7 R/3.5.0 singularity/2.5.1 vtune/ advisor/ grads/2.2.0 lammps/8mar18 qe/6.1 siesta/4.0.2 singularity/2.5.2 vtune/ advisor/ gromacs/ namd/2.12 qt/4.8.7 siesta/4.1-b3 singularity/3.0.1 vtune/ cmake/ gromacs/5.0.6 python/ qt/5.9.6 singularity/2.4.2 tensorflow/


10 KNL Architecture 최대 36 tile ( 72 cores / 256 threads) 2 cores / tile 1MB shared L2 cache /tile 2 * 512-bit VPUs /cores Based on Intel Atom architecture 2D mesh interconnect 2 DDR memory controller 6 channels DDR4 Up to 90 GB/s 16 GB MCDRAM 8 embedded DRAM controllers Up to 450 GB/s 10
=64byte Double Precision :")
11 Vector Registers KNL 512-bit register 512bit*(1byte/8bit)=64byte Double Precision : 64byte*(1DP/8byte)=8DP 11
12 Instruction Set Architecture(ISA) 인텔 AVX-512 instruction set architecture(isa) 종류 AVX-512 Foundation Instructions : AVX-512F AVX-512 Conflict Detection Instructions: AVX-512CD AVX-512 Exponential and Reciprocal Instructions: AVX-512ER AVX-512 Prefetch Instructions: AVX-512PF AVX-512BW, AVX-512DQ, AVX-512VL(for Xeon processor) 인텔컴파일러옵션 -xcommon-avx512 = AVX-512F + AVX-512CD -xmic-avx512 = AVX-512F + AVX-512ER + AVX-512PF -xcore-avx512 = AVX-512F + AVX-512CD + AVX-512BW + AVX-512DQ + AVX-512VL 12
13 컴파일명령예시 Serial SKL : icc -O3 -xcore-avx512 (-qopt-report=5) pi.c -o pi_skl.x KNL : icc -O3 -xmic-avx512 (-qopt-report=5) pi.c -o pi_knl.x OpenMP SKL : icc -O3 -xcore-avx512 -qopenmp piopenmp.c -o piopenmp_skl.x KNL : icc -O3 -xmic-avx512 -qopenmp piopenmp.c -o piopenmp_knl.x MPI SKL : mpiicc -O3 -xcore-avx512 pimpi.c -o pimpi_skl.x KNL : mpiicc -O3 -xmic-avx512 pimpi.c -o pimpi_knl.x Hybrid SKL : mpiicc -O3 -xcore-avx512 -qopenmp pihybrid.c -o pihybrid_skl.x KNL : mpiicc -O3 -xmic-avx512 -qopenmp pihybrid.c -o pihybrid_knl.x 13
14 클러스터모드 (Cluster modes) 3가지클러스터모드를지원하며, 각모드는성능향상을위해서로다른 affinity를제공 all-to-all mode quadrant mode(or hemisphere) (default) sub-numa clustering(snc) mode(snc-4 or SNC-2) 14
15 클러스터모드 (Cluster modes) Quadrant mode each memory type is UMA SNC-4 The latency from any given core to any memory location within the same memory type(mcdram or DDR) is essentially the same. each memory type is NUMA The cores and memory are divided into (four) quadrants with lower latency for near memory accesses (within the same quadrant) and higher latency for far (within a different quadrant) memory accesses. SNC-4 is well suited for MPI applications that utilize four, or a multiple of four, ranks per KNL. 15
16 클러스터모드 (Cluster modes) Hemisphere and SNC-2 Variations on quadrant and SNC-4 Identical to quadrant and SNC-4, except divided the cores and memory into halves instead of quadrants All-to-all It can be used with any DDR DIMM configuration. This mode will be lowest in general performance than the other modes. 16
17 MCDRAM and DDR MCDRAM(Multi-Channel DRAM) is the high-bandwidth memory 8 MCDRAM devices integrated: 8 * 2 GB = 16 GB 8 devices have their own memory controllers (EDC) Bandwidth up to 475 GB/s DDR offers high-capacity memory 2 DDR4 memory controllers( 2 * 3 = 6 channels) Max 64 GB/channel 384 GB Bandwidth up to 90 GB/s 17

18 메모리모드 (Memory Modes) Cache(default) Flat MCDRAM acts as L3 Cache MCDRAM, DDR4 are all just RAM numactl command memkind/autohbw library different NUMA nodes Hybrid MCDRAM is used as a L3 cache as a DDR 18
19 Default Cluster Mode and Memory Mode 클러스터모드로는 Quadrant 모드, 메모리모드로는 Cache 모드의사용이대 부분의응용프로그램에대해좋은선택임 MPI+X (e.g., MPI+OpenMP) 형태의응용프로그램은클러스터모드로 SNC-4 모드를사용할경우성능이잘나올수있음 Quadrant 모드또한충분히근접한성능을낼수있으며, 균일한사용환경을위해누리온은이를지원하지않음 대부분의응용프로그램은메모리모드를 Cache Mode로사용하기를권장하지만, 아래와같은일부경우 Flat Mode에서성능이더잘나올수있음 사용하는메모리크기가작아서 MCDRAM만사용할수있는경우 Memory-bounded 프로그램이아니어서 L3 Cache가필요하지않은경우 ( 대표적인경우가 HPL임 ) 19
 + cache : 1 NUMA (DDR)")
20 numactl numactl -H quadrant (all-to-all or hemisphere) + cache : 1 NUMA (DDR) 20
 + flat : 2 NUMA (MCDRAM and DDR)")
21 numactl numactl -H quadrant (all-to-all or hemisphere) + flat : 2 NUMA (MCDRAM and DDR) 21

22 numactl numactl -H SNC-4 + flat : 8 NUMA(4 MCDRAM and 4 DDR) DDR nodes are listed first, and the MCDRAM nodes are listed last. The distances reflect the affinization of DDR and MCDRAM to the divisions of KNL in this mode. example : 64 cores(4threads/core), DDR : 64G, MCDRAM : 16G 22
23 numactl MCDRAM 사용 (flat 모드만해당 ) -m 옵션과해당되는 NUMA 노드를명시 numactl -m 1./a.out (quadrant + flat, DDR이 0, MCDRAM이 1) numactl -m 4-7./a.out (SNC-4 + flat, DDR이 0~3, MCDRAM이 4~7) -m 대신 -p 옵션사용을권장 -p 옵션은 preference를의미 : MCDRAM 사용이필수가아닌선호 MCDRAM이모두사용되었을경우, DDR 메모리를자동으로사용함. -m 의경우메모리부족으로프로그램종료 numactl -p 1./a.out (quadrant + flat) numactl -p 4-7./a.out (SNC-4 + flat) 23
24 Basic Environment(1) 1. 시스템접속 2. Linux 기초 기본명령어 VI Editor 3. Environment Module Module 명령어 avail add rm list purge 권장컴파일러옵션
25 시스템접속 노드구성 호스트명 CPU Limit 비고 ssh/scp/sftp 접속가능 로그인노드 nurion.ksc.re.kr 20 분 컴파일및 batch 작업제출용 ftp 접속불가 ssh/scp/sftp 접속가능 Datamover 노드 nurion-dm.ksc.re.kr - ftp 접속가능 컴파일및작업제출불가 계산노드 KNL node[ ] - PBS 스케줄러를통해작업실행가능 CPU-Only cpu[ ] - 일반사용자직접접근불가 25


26 시스템접속 Xming X 환경실행을위해필요 Putty 사용 Host Name : nurion.ksc.re.kr( port : 22) Xming 실행필요 26
27 시스템접속 접속 ID & otp sedu##( 01~48) OTP : xxxx Passwd : xxxxxxxxx Last login: Mon Jan 7 10:00: from xxx.xxx.xxx.xx ================ KISTI 5th NURION System ==================== * Compute Nodes(node[ ],cpu[ ) - KNL(XeonPhi GHz 68C) / 16GB(MCDRAM),96GB(DDR4) - CPU-only(XeonSKL GHz 20C x2) / 192GB(DDR4) * Software - OS: CentOS 7.4( el7.x86_64) - System S/W: BCM v8.1, PBS v14.2, Lustre v2.10 * Current Configurations - All KNL Cluster modes - Quadrant - Memory modes : Cache-node[ , ]/Flat-node[ ] : PBS job sharing mode-exclusive(running 1 job per node) (Except just the commercial queue) * Policy on User Job. (Use the # showq & # pbs_status commands for more queue info.) 27
28 시스템접속 Policy on User Job Queue Wall-Clock Limit Max Running jobs Max Active Jobs (running+waiting) exclusive unlimited normal 48h burst_buffer 48h long 120h flat 48h debug 48h 2 2 commercial 48h 5 10 norm_skl 48h
29 Linux 기초 File Hierarchy 경로 절대경로 : /home/userid/mpi/examples 상대경로 :../../MPI/example 29
30 Linux 기초 명령어구조 (command) + (options) + (arguments) ls ls -a ls -a /home Manual page 시스템에서제공하는도움말 (man page) 기본적으로 command 마다해당 man page를가짐 다음페이지를보기위해서는 space bar 또는 f 입력 이전페이지를보기위해서는 b 입력 마치려면 q 입력 $ man who WHO(1) WHO(1) User Commands NAME who - show who is logged on SYNOPSIS who [OPTION]... [ FILE ARG1 ARG2 ] DESCRIPTION -a, --all same as -b -d --login -p -r -t -T -u -b, --boot time of last system boot -d, --dead print dead processes 30
31 ls 기본명령어 디렉터리내의파일목록을위한명령 자주사용되는명령어 명령어 cd pwd mkdir cp rm mv cat echo diff file 내용디렉터리이동명령현재디렉터리위치를보여줌새로운디렉터리를만들때사용파일복사명령, 속성을유지할경우 -a 옵션사용파일이나디렉터리삭제파일과디렉터리의이름을변경하거나경로를옮길때사용간단한텍스트파일내용확인텍스트를화면상에출력 2개의텍스트파일내용을비교할때사용, 바이너리파일인경우같은지여부만알려줌파일의타입 (ASCII, Binary) 를알아볼때사용 31
32 기본명령어 tar 명령어 단순하게파일을압축하는용도가아닌파일이나디렉터리를묶는용도 gzip, unzip과같이압축프로그램과같이쓰이는게일반적 기본적인옵션 -z : gzip으로압축또는압축해제할때사용 -f : tar 명령어를이용할때반드시사용 (default) x : tar 파일로묶여있는것을해제할때사용 (extract) c : tar 파일을생성할때사용 (create) 32
33 VI Editor vim(vi) 가장기본적인텍스트에디터, OS에기본적으로포함됨 VIsual display editor를의미 파일개방 $ vi file( 편집모드 ) $ view file( 읽기모드 ) modes 입력모드 입력모드로전환 : i (,I, a, A, o, O, R) 입력하는모든것이편집버퍼에입력됨 입력모드에서빠져나올때 ( 명령행모드로변경시 ) : ESC key 명령행모드 입력하는모든것이명령어해석됨 파일저장 / 종료명령 명령행모드에서 :w ( 저장 ), :q ( 종료 ), :wq( 저장후종료 ), :q! ( 저장없이종료 ) 33
34 Environment Module 사용자가쉘환경 (shell environment) 을관리하도록도와주는도구 module 명령 부명령 (subcommand) avail(av) 사용가능한모듈파일들 (modulefiles) 을보여줌 add(load) 쉘환경으로모듈파일들을적재함 (load) rm(unload) 쉘환경에서적재된모듈파일들을제거함 li(list) 적재된모듈파일들을나열함 purge 적재된모든모듈파일들을제거함 34
35 Environment Module Default modulefiles login 을하면, 기본모듈파일이적재됨 $ module list Currently Loaded Modulefiles: 1) craype-network-opa module 명령 사용가능모듈확인 (avail) $ module avail /opt/cray/craype/default/modulefiles craype-mic-knl craype-network-opa craype-x86-skylake /opt/cray/modulefiles cdt/17.10 cray-impi/1.1.4(default) perftools-base/6.5.2(default) /apps/modules/modulefiles/compilers cce/8.6.3(default) gcc/6.1.0 gcc/7.2.0 intel/17.0.5(default) intel/ intel/
36 Environment Module 모듈명령 모듈정보출력 $ module help impi/ Module Specific Help for 'impi/17.0.5' This module is for use of impi/ use example: $ module load intel/ impi/ 모듈적재 $ module load craype-mic-knl $ module load intel/ (or $ module add craype-mic-knl intel/ ) 36
37 Environment Module Default modulefiles in Nurion 적재된모듈파일확인 (list subcommand) $ module list Currently Loaded Modulefiles: 1) craype-network-opa 2) craype-mic-knl 3) intel/ 적재된모듈삭제 / 모듈추가 (rm / add subcommand) $ module rm craype-mic-knl $ module add craype-x86-skylake $ module list Currently Loaded Modulefiles: 1) craype-network-opa 2) intel/ ) craype-x86-skylake 적재된모든모듈삭제 $ module list Currently Loaded Modulefiles: 1) craype-network-opa 2) intel/ ) craype-x86-skylake $ module purge $ module li No Modulefiles Currently Loaded. 37
38 Basic Environment 프로그래밍도구설치현황 컴파일러및라이브러리모듈 구분 아키텍처구분모듈 craype-mic-knl craype-x86-skylake Cray 모듈 perftools/6.5.2 perftools-base/6.5.2 컴파일러 cce/8.6.3 gcc/7.2.0 gcc/6.1.0 컴파일러의존라이브러리 hdf4/ hdf5/ lapack/3.7.0 MPI 라이브러리 impi/17.0.5(default) impi/ impi/ 항목 craype-network-opa PrgEnv-cray/1.0.2 intel/17.0.5(default) intel/ intel/ ncl/6.5.0 ncview/2.1.7 netcdf/4.6.1 openmpi/3.1.0 mvapich2/2.3 38
39 Basic Environment 프로그래밍도구설치현황 컴파일러및라이브러리모듈 구분 MPI 의존라이브러리 fftw_mpi/2.1.5 fftw_mpi/3.3.7 hdf5-parallel/ Intel 패키지 advisor/ advisor/ advisor/ 응용소프트웨어 forge/ ImageMagick/ python/ python/3.7 gromacs/ namd/2.12 qt/4.8.7 qt/5.9.6 가상화모듈 singularity/2.5.1 singularity/2.5.2 singularity/3.0.1 항목 netcdf-hdf5-parallel/4.6.1 parallel-netcdf/ pio/2.3.1 vtune/ vtune/ vtune/ R/3.5.0 grads/2.2.0 lammps/8mar18 qe/6.1 siesta/4.0.2 siesta/4.1-b3 cmake/ gromacs/5.0.6 singularity/2.4.2 tensorflow/
40 Basic Environment 상용소프트웨어설치정보 분야소프트웨어버전라이선스디렉터리위치 구조역학 열유체역학 화학 / 생명 Abaqus MSC ONE (Nastran) LS-DYNA ANSYS CFX ANSYS Fluent Gaussian 토큰 R R9.2.0 V145 V170 V181 V191 G16-a03 G16- a03.linda 151 토큰 /apps/commercial/abaqus/ 최대 128 코어사용가능 17 Solvers (HPC 640) 작업수제한없음단일노드내 CPU 수제한없음 /apps/commercial/msc/nas tran /apps/commercial/lsdyna /apps/commercial/ansys/ /apps/commercial/g16/g16 40
41 Basic Environment 프로그램컴파일 누리온시스템 Intel 컴파일러, GNU 컴파일러, Cray 컴파일러제공 Intel MPI(IMPI), Mvapich2, OpenMPI 제공 기본필요모듈 craype-network-opa craype-mic-knl(knl), craype-x86-skylake(skl) 41
42 Basic Environment 프로그램컴파일 순차프로그램컴파일 프로그램벤더컴파일러소스확장자사용모듈 C / C++ Intel icc / icpc intel/ intel/ intel/ GNU gcc / g++.c,.cc,.cpp,.cxx,.c++ gcc/6.1.0 gcc/7.2.0 Cray cc / CC PrgEnv-cray/1.0.2 & cce/8.6.3 F77/F90 intel/ intel/ Intel ifort.f,.for,.ftn,.f90,.fpp, intel/ f,.for,.ftn,.fpp, GNU gfortran gcc/6.1.0 gcc/7.2.0.f90 Cray ftn PrgEnv-cray/1.0.2 & cce/
43 Basic Environment 프로그램컴파일 순차프로그램컴파일 Intel 컴파일러주요옵션 -O[1 2 3] 컴파일러옵션 -qopt-report=[ ] -xcore-avx512 -xmic-avx512 -qopenmp -fpic, -fpic 설명 오브젝트최적화, 숫자는최적화레벨 벡터진단정보의양을조절 512bit 레지스터를가진 CPU 지원 512bit 레지스터를가진 MIC 지원 OpenMP 기반의 multi-thread 코드사용 PIC(Position Independent Code) 가생성되도록컴파일 권장옵션 -O3 -fpic -xcore-avx512 ( Skylake) -O3 -fpic -xmic-avx512 (KnightsLanding) -O3 -fpic -xcommon-avx512(skylake & KnightsLanding) $ icc ifort o test.exe O3 fpic xmic-avx512 test.[c cc f90] 43
44 Basic Environment 프로그램컴파일 순차프로그램컴파일 GNU 컴파일러주요옵션 -O[1 2 3] 컴파일러옵션 -march=skylake-avx512 -march=knl -Ofast -fopenmp -fpic 설명 오브젝트최적화, 숫자는최적화레벨 512bits 레지스터를가진 CPU 지원 512bits 레지스터를가진 MIC 지원 -O3 -ffast-math 매크로 OpenMP 기반의 multi-thread 코드사용 PIC(Position Independent Code) 가생성되도록컴파일 권장옵션 -O3 -fpic -march=skylake-avx512 ( Skylake) -O3 -fpic -march=knl (KnightsLanding) -O3 -fpic -mpku (Skylake & KnightsLanding) $ gcc gfortran o test.exe O3 fpic march=knl test.[c cc f90] 44
45 Basic Environment 프로그램컴파일 순차프로그램컴파일 Cray 컴파일러주요옵션 컴파일러옵션 -O[1 2 3] -hcpu=mic-knl -homp(default) 설명 오브젝트최적화, 숫자는최적화레벨 512bits 레지스터를가진 MIC 지원사용하지않으면 Skylake 지원 (default) OpenMP 기반의 multi-thread 코드사용 -h pic 2GB 이상의 static memory 가필요한경우사용 (-dynamic 과함께사용 ) -dynamic 공유라이브러리를링크 권장옵션 Default 옵션사용을권장 $ cc ftn o test.exe hcpu=mic-knl test.[c cc f90] 45
46 Basic Environment 프로그램컴파일 병렬프로그램컴파일 OpenMP 컴파일 OpenMP는컴파일러지시어만으로멀티스레드를활용할수있도록개발된기법임 컴파일러옵션을추가하여병렬컴파일을할수있음» Intel compiler : -qopenmp» GNU compiler : -fopenmp» Cray compiler : -homp $ icc ifort o test.exe qopenmp O3 fpic xmic-avx512 test.[c cc f90] $ gcc gfortran o test.exe fopenmp O3 fpic march=knl test.[c cc f90] $ cc ftn o test.exe homp hcpu=mic-knl test.[c cc f90] 46
47 Basic Environment 프로그램컴파일 병렬프로그램컴파일 MPI 컴파일 MPI 명령을이용하여컴파일 MPI 명령은일종의 wrapper로써지정된컴파일러가소스를컴파일함 구분 Intel GNU Cray Fortran ifort gfortran ftn Fortran + MPI mpiifort mpif90 ftn C icc gcc cc C + MPI mpiicc mpicc cc C++ icpc g++ CC C++ + MPI mpiicpc mpicxx CC $ mpiicc mpiifort o test.exe O3 fpic xmic-avx512 test.[c 90] $ mpicc mpif90 o test.exe O3 fpic march=knl test.[c f90] $ cc ftn o test.exe hcpu=mic-knl test.[c f90] 47
48 Basic Environment 작업디렉터리및쿼터정책 구분 디렉터리경로 용량제한 파일수제한 파일삭제정책파일시스템백업유무 홈디렉터리 /home01 64GB 100K N/A Lustre 스크래치디렉터리 /scratch 100TB 1M 15일동안접근하지않은파일은자동삭제 O X 현재사용량확인 $ lfs quota /home01 Disk quotas for usr sedu01 (uid ): Filesystem kbytes quota limit grace files quota limit grace /home $ lfs quota /scratch Disk quotas for usr sedu01 (uid ): Filesystem kbytes quota limit grace files quota limit grace /scratch Disk quotas for grp in0163 (gid ): 홈디렉터리는용량및 I/O 성능이제한되어있기때문에, 모든계산작업은스크래 치디렉터리에서이루어져야함. 48
49 실습파일복사 cp -r /home01/sedu49/01_testbed_usage./ cp r /home01/sedu49/02_knl_tutorial_src./ 49
50 Job Scheduler 1. PBS command 2. Job script examples Serial code OpenMP code MPI code Hybrid code 3. Using PBS for interactive jobs
51 Scheduler 명령어모음 KISTI Scheduler 명령비교 누리온은 PBS(Portable Batch System) job scheduler 를사용함 User Commands PBS (Nurion) SGE (Tachyon2) Slurm (KAT) LoadLeveler (Sinbaram) 작업제출 qsub [script_file] qsub [script_file] sbatch [script_file] llsubmit [script_file] 작업삭제 qdel [job_id] qdel [job_id] scancle [job_id] llcancel [job_id] 작업조회 (job_id) qstat [job_id] qstat -u\* [-j job_id] squeue [job_id] llq -l [job_id] 작업조회 (user) qstat -u [user_name] qstat [-u user_name] squeue -u [user_name] llq -u [user_name] Queue 목록 qstat -Q qconf -sql squeue llclass Node 목록 pbsnodes -as qhost sinfo -N or scontrol show nodes llstatus -L machine Cluster 상태 pbsnodes -asj qhost -q sinfo llstatus -L cluster GUI xpbsmon qmon sview xload 51
52 Nurion Queue 큐정책 Queue Wall-Clock Limit Max Running jobs KISTI 큐정책에의해변경될수있음 Max Active Jobs (running+waiting) exclusive unlimited normal 48h burst_buffer 48h long 120h flat 48h debug 48h 2 2 commercial 48h 5 10 norm_skl 48h
53 Nurion Queue 큐정책 누리온시스템은배타적노드할당정책을기본으로함 한노드에한사용자의작업만이실행될수있도록보장 normal 큐 일반사용자를위한큐 commercial 큐 상용 SW 수행을위한큐 공유노드정책이적용됨 노드의규모가크지않아서효율적으로자원을활용하기위함임 debug 큐 공유노드정책이적용됨 사용한자원만큼만과금됨 Interactive job 제출이가능 53
54 Nurion Queue 큐조회 showq, pbs_status 54
55 PBS command : Queue 목록조회 qstat Queue 목록조회 : -Q Queue 상세정보조회 : -f $ qstat -Q Queue Max Tot Ena Str Que Run Hld Wat Trn Ext Type exclusive 0 1 yes yes Exec commercial 0 6 yes yes Exec norm_skl 0 56 yes yes Exec $ qstat -Qf normal Queue: normal queue_type = Execution Priority = 100 total_jobs = 143 state_count = Transit:0 Queued:0 Held:8 Waiting:0 Running:135 Exiting:0 Beg un:0 max_queued = [u:pbs_generic=40] acl_host_enable = False acl_user_enable = False resources_max.walltime = 48:00:00 resources_min.walltime = 00:00:00 55
56 Nurion Queue 큐조회 현재계정으로사용가능한큐리스트조회 pbs_queue_check 56
57 PBS command : node 조회및변경 pbsnodes -a : 등록된계산노드목록조회 -asj : 노드사용내역조회 $ pbsnodes asj mem ncpus nmics ngpus vnode state njobs run susp f/t f/t f/t f/t jobs node0001 free gb/110gb 68/68 0/0 0/0 -- node0007 free gb/110gb 4/68 0/0 0/ node0008 free gb/110gb 68/68 0/0 0/0 -- node0009 free gb/110gb 68/68 0/0 0/0 -- node0010 free gb/110gb 68/68 0/0 0/0 -- cpu0004 job-busy gb/188gb 0/40 0/0 0/ cpu0003 job-busy gb/188gb 0/40 0/0 0/ cpu0002 job-busy gb/188gb 0/40 0/0 0/ cpu0001 job-busy gb/188gb 0/40 0/0 0/ ( : pilot system에서출력예임 ) Column mem ncpus nmics ngpus f/t Description 기가바이트 (GB) 단위의메모리양 이용가능한총 CPU 개수 이용가능한많은통합코어들 (MIC) 의총개수 - Intel 이용가능한총 GPU 의개수 f=free, t=total 57
58 PBS command : 작업제출 작업제출 사용자작업은반드시 /scratch 에서만제출이가능함 /home 디렉터리에서제출불가능 qsub {job_scropt_name} depend 옵션을사용하여의존성있는작업제출가능 qsub -W depend={option}:{jobid} {job_scropt_name} afterok : 의존작업이성공시다음작업수행 afternotok : 의존작업이실패시다음작업수행 afterany : 의존작업의성공여부에관계없이다음작업수행 $ qsub serial.sh pbs $ qsub -W depend=afterok: pbs serial.sh pbs $ qstat -u sedu01" pbs: Req'd Req'd Elap Job ID Username Queue Jobname SessID NDS TSK Memory Time S Time pbs sedu01 normal Serial_Job :10 R 00: pbs sedu01 normal Serial_Job :10 H -- 58
59 PBS command : 작업제출및삭제 qdel 제출된작업삭제 qdel {JOBID} $ qstat -u sedu01" pbs: Req'd Req'd Elap Job ID Username Queue Jobname SessID NDS TSK Memory Time S Time pbs sedu01 normal Serial_Job :10 R 00: pbs sedu01 normal Serial_Job :10 H -- $ qdel pbs $ qstat -u sedu01" pbs: Req'd Req'd Elap Job ID Username Queue Jobname SessID NDS TSK Memory Time S Time pbs sedu01 normal Serial_Job :10 R 00:00 59
60 PBS command : 수행중작업조회 qstat 실행및대기중인작업조회 기본값은모든사용자의작업목록출력 지정계정작업목록출력 : -u 작업수행계산노드정보출력 : -n $ qstat Job id Name User Time Use S Queue pbs G16-Si-b-TD x1679a :42: R long pbs G16-Si-c-TD x1679a :10: R long pbs Serial_Job sedu01 00:00:00 R normal $ qstat u sedu01 pbcm: Req'd Req'd Elap Job ID Username Queue Jobname SessID NDS TSK Memory Time S Time pbs sedu01 normal Serial_Job :10 R 00:00 $ qstat -n -u sedu01 pbcm: Req'd Req'd Elap Job ID Username Queue Jobname SessID NDS TSK Memory Time S Time pbs sedu01 normal Serial_Job :10 R 00:00 node2780/0 60
61 PBS command : 종료된작업조회 qstat -x 기본값은모든사용자의작업출력 -u : 지정계정의종료작업목록출력 -f {JOBID} : 종료작업상세정보출력 $ qstat xu sedu01 pbcm: Req'd Req'd Elap Job ID Username Queue Jobname SessID NDS TSK Memory Time S Time pbs sedu01 norm_skl Serial_Job :10 F 00: pbs sedu01 normal Serial_Job :10 F 00:01 $ qstat -xf pbs Job Id: pbs Job_Name = Serial_Job Job_Owner = sedu01@login01 resources_used.cpupercent = 99 resources_used.cput = 00:00:57 resources_used.mem = 3636kb resources_used.ncpus = 1 resources_used.vmem = kb resources_used.walltime = 00:01:11 61
62 Job Script 작성 #PBS 지시자를사용하여옵션지정 chunk 단위로 host/vnode에자원할당 -l select 로 chunk 자원할당 -l select=<numerical>:<res1>=<value>:<res2>=<value> 각리소스는 colon(:) 으로구분 기본은 1 chunk == 1 task #PBS -l select=128 : 128개의 chunks #PBS -l select=1:mem=16gb+15:mem=1gb : 16GB를사용하는 1개의 chunk와 1GB를사용하는 15개의 chunk로작업수행 #!/bin/sh #PBS -V # 작업제출노드의쉘환경변수를컴퓨팅노드에도적용 #PBS -N hybrid_node # 작업이름지정 #PBS -q workq # 작업 queue 지정 #PBS -l walltime=01:00:00 # 작업 walltime 지정 #PBS -M abc@abc.com # 작업관련메일을수신할주소 #PBS -m abe # a( 작업실패 )/b( 작업시작 )/e( 작업종료 ) 시메일발송, n : 메일보내지않음 #PBS -l select=2 # 2 chunk 로작업자원할당지정 cd $PBS_O_WORKDIR # PBS 는작업제출경로가 WORKDIR 로설정되지만기본값으로 $HOME 에서 # 작업이실행됨. 상대경로파일을사용한경우 PBS_O_WORKDIR 로변경필요. mpirun -machinefile $PBS_NODEFILE./hostname.x 62
63 Job Script 작성 작업스크립트주요키워드 옵션 형식 설명 -V 환경변수내보내기 -N <alphanumeric> Job 이름지정 -q <queue_name> 서버나큐의이름지정 -l <resource_list> Job 리소스요청 -M 이메일받는사람리스트설정 -m <string> 이메일알람지정 -W sandbox= [HOME PRIVATE] 스테이징디렉터리와실행디렉터리 -X Interactive job으로부터의 X output PBS 배치작업수행하는경우 STDOUT과 STDERR을시스템디렉터리의 output에저장하였다가작업완료후사용자작업제출디렉터리로복사함 사용자는작업완료시까지작업진척내용을알수없음 #PBS W sandbox=private 을추가하여스크립트를작성하는경우, STDOUT과 STDERR을작업실행중확인가능 63
64 Job Script 작성 사용가능한환경변수 환경변수 설명 PBS_JOBID PBS_JOBNAME PBS_NODEFILE PBS_O_PATH PBS_O_WORK_DIR TMPDIR Job에할당되는식별자사용자에의해제공되는 Job 이름작업에할당된계산노드들의리스트를포함하고있는파일이름제출환경의경로값 qsub이실행된절대경로위치 Job을위해지정된임시디렉터리 64
65 PBS Job Script 사용예제 : (PI 코드 ) 코드컴파일 Intel Compiler/MPI 사용 $ module add intel/ impi/ KNL(Knights Landing) 노드사용시 craype-mic-knl 모듈사용 $ module add craype-mic-knl $ icc -xmic-avx512 source.c -o executable.x SKL(Skylake) 노드사용시 craype-x86-skylake 모듈사용 $ module add craype-x86-skylake $ icc -xcore-avx512 source.c -o executable.x craype-mic-knl 모듈과 craype-x86-skylake 모듈을동시에사용할수없음 모듈을변경할때충돌되는모듈을 unload 하고, 사용하고자하는모듈을 load 해야함 65
66 PBS Job Script 사용예제 : (PI 코드 ) 컴파일 (pi.c) KNL SKL $ module add craype-mic-knl $ icc pi.c -o pi_serial_no_vec_knl $ icc -xmic-avx512 pi.c -o pi_serial_vec_knl $ module rm craype-mic-knl $ module add craype-x86-skylake $ icc pi.c -o pi_serial_no_vec_skl $ icc -xcore-avx512 pi.c -o pi_serial_vec_skl 66
67 PBS Job Script 사용예제 : (PI 코드 ) serial.sh(knl) $ cat serial.sh #!/bin/bash #PBS -V #PBS -N Serial_job #PBS -q normal #PBS -l walltime=00:05:00 #PBS -l select=1 cd $PBS_O_WORKDIR./pi_serial_no_vec_knl./pi_serial_vec_knl serial.sh(skl) $ cat serial.sh #!/bin/bash #PBS -V #PBS -N Serial_job #PBS -q norm_skl #PBS -l walltime=00:05:00 #PBS -l select=1 cd $PBS_O_WORKDIR./pi_serial_no_vec_skl./pi_serial_vec_skl KNL w/o AVX512 PI= (Error = e-15) Elapsed Time = , [sec] w/ AVX512 PI= (Error = e-14) Elapsed Time = , [sec] SKL w/o AVX512 PI= (Error = e-15) Elapsed Time = , [sec] w/ AVX512 PI= (Error = e-15) Elapsed Time = , [sec] 67
68 PBS Job Script 사용예제 : (PI 코드 ) OpenMP(piOpenMP.c) #include <stdio.h> #include <math.h> #include <sys/time.h> #include <omp.h> inline double cputimer() { struct timeval tp; gettimeofday(&tp,null); return ((double)tp.tv_sec + (double)tp.tv_usec*1e-6); } int main() { double istart, ElapsedTime; const long num_step = ; long i; double sum, step, pi, x; int num_threads; step = (1.0/(double)num_step); sum = 0.0; istart=cputimer(); printf(" \n"); 68
69 PBS Job Script 사용예제 : (PI 코드 ) OpenMP(piOpenMP.c) #pragma omp parallel { #pragma omp master { num_threads=omp_get_num_threads(); printf("# of threads : %d\n",num_threads); } #pragma omp for reduction(+:sum), private(x) for(i=1;i<=num_step;i++){ x = ((double)i-0.5)*step; sum += 4.0/(1.0+x*x); } } pi = step*sum; ElapsedTime= cputimer() - istart; printf("pi= %.15f (Error = %e)\n",pi, fabs(acos(-1)-pi)); printf("elapsed Time = %f, [sec]\n", ElapsedTime); printf(" \n"); return 0; } 69
70 PBS Job Script 사용예제 : (PI 코드 ) 컴파일 (piopenmp.c) KNL $ module add craype-mic-knl $ icc qopenmp piopenmp.c -o piopenmp_no_vec $ icc qopenmp -xmic-avx512 piopenmp.c -o piopenmp_vec SKL $ module rm craype-mic-knl $ module add craype-x86-skylake $ icc qopenmp piopenmp.c -o piopenmp_no_vec $ icc qopenmp -xcore-avx512 piopenmp.c -o piopenmp_vec 70
71 PBS Job Script 사용예제 : (PI 코드 ) openmp.sh(knl) $ cat openmp.sh #!/bin/bash #PBS -V #PBS -N OMP_job #PBS -q normal #PBS -l walltime=00:02:00 #PBS -l select=1:ncpus=34:ompthreads=34 (#PBS -l select=1:ncpus=68:ompthreads=68) cd $PBS_O_WORKDIR./piOpenMP_no_vec./piOpenMP_vec KNL # of threads : 34 w/o AVX512 Elapsed Time = , [sec] w/ AVX512 Elapsed Time = , [sec] # of threads : 68 w/o AVX512 Elapsed Time = , [sec] w/ AVX512 Elapsed Time = , [sec] openmp.sh(skl) $ cat openmp.sh #!/bin/bash #PBS -V #PBS -N OMP_job #PBS -q norm_skl #PBS -l walltime=00:10:00 #PBS -l select=1:ncpus=20:ompthreads=20 (#PBS -l select=1:ncpus=40:ompthreads=40) cd $PBS_O_WORKDIR./piOpenMP_no_vec./piOpenMP_vec SKL # of threads : 20 w/o AVX512 Elapsed Time = , [sec] w/ AVX512 Elapsed Time = , [sec] # of threads : 40 w/o AVX512 Elapsed Time = , [sec] w/ AVX512 Elapsed Time = , [sec] 71
72 PBS Job Script 사용예제 : (PI 코드 ) MPI(piMPI.c) #include <stdio.h> #include <math.h> #include "mpi.h" int main(int argc, char *argv[]){ long i; int myrank, nprocs; const long num_step = ; double mypi, x, pi, h, sum; double st, et; MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &myrank); MPI_Comm_size(MPI_COMM_WORLD, &nprocs); if(myrank==0) printf("# of processes : %d\n",nprocs); h=1.0/(double)num_step; sum = 0.0; st = MPI_Wtime(); for(i=myrank;i<num_step;i+=nprocs){ x = h*((double)i-0.5); sum += 4.0/(1.0+x*x); } mypi= h*sum; MPI_Reduce(&mypi, &pi, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD); et=mpi_wtime(); if(myrank==0){ printf("pi= %.15f (Error = %e)\n",pi, fabs(acos(-1)-pi)); printf("elapsed Time = %f, [sec]\n", et-st); printf(" \n"); } MPI_Finalize(); return 0; } 72
73 PBS Job Script 사용예제 : (PI 코드 ) 컴파일 (pimpi.c) KNL $ module add craype-mic-knl $ mpiicc pimpi.c -o pimpi_no_vec $ mpiicc -xmic-avx512 pimpi.c -o pimpi_vec SKL $ module rm craype-mic-knl $ module add craype-x86-skylake $ mpiicc pimpi.c -o pimpi_no_vec $ mpiicc -xcore-avx512 pimpi.c -o pimpi_vec 73
74 PBS Job Script 사용예제 : (PI 코드 ) mpi.sh(knl) $ cat mpi.sh #!/bin/bash #PBS -V #PBS -N MPI_job #PBS -q normal #PBS -l walltime=00:02:00 #PBS -l select=1:ncpus=68:mpiprocs=68:ompthreads=1 (#PBS -l select=2:ncpus=68:mpiprocs=68:ompthreads=1) cd $PBS_O_WORKDIR mpirun -machinefile $PBS_NODEFILE./piMPI_no_vec mpirun -machinefile $PBS_NODEFILE./piMPI_vec KNL # of processes : 68 w/o AVX512 Elapsed Time = , [sec] w/ AVX512 Elapsed Time = , [sec] # of processes : 136 w/o AVX512 Elapsed Time = , [sec] w/ AVX512 Elapsed Time = , [sec] 74
75 PBS Job Script 사용예제 : (PI 코드 ) mpi.sh(skl) $ cat mpi.sh #!/bin/bash #PBS -V #PBS -N MPI_job #PBS -q norm_skl #PBS -l walltime=00:10:00 #PBS -l select=1:ncpus=40:mpiprocs=40:ompthreads=1 (#PBS -l select=2:ncpus=40:mpiprocs=40:ompthreads=1) cd $PBS_O_WORKDIR mpirun -machinefile $PBS_NODEFILE./piMPI_no_vec mpirun -machinefile $PBS_NODEFILE./piMPI_vec SKL # of processes : 40 w/o AVX512 Elapsed Time = , [sec] w/ AVX512 Elapsed Time = , [sec] # of processes : 80 w/o AVX512 Elapsed Time = , [sec] w/ AVX512 Elapsed Time = , [sec] 75
76 PBS Job Script 사용예제 : (PI 코드 ) Hybrid(piHybrid.c) #include <stdio.h> #include <math.h> #include "mpi.h" #include "omp.h" int main(int argc, char *argv[]) { long i; int myrank, nprocs,provide; const long num_step = ; double mypi, x, pi, h, sum; double st, et; int num_threads; MPI_Init_thread(&argc, &argv,mpi_thread_funneled,&provide); MPI_Comm_rank(MPI_COMM_WORLD, &myrank); MPI_Comm_size(MPI_COMM_WORLD, &nprocs); if(myrank==0)printf("# of processes : %d\n",nprocs); h=1.0/(double)num_step; sum = 0.0; st = MPI_Wtime(); 76
77 PBS Job Script 사용예제 : (PI 코드 ) Hybrid(piHybrid.c) #pragma omp parallel { #pragma omp master { num_threads=omp_get_num_threads(); printf("# of threads : %d\n",num_threads); } #pragma omp } } for reduction(+:sum), private(x) for(i=1;i<=num_step;i+=nprocs) { x = h*((double)i-0.5); sum += 4.0/(1.0+x*x); } mypi= h*sum; MPI_Reduce(&mypi, &pi, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD); et=mpi_wtime(); if(myrank==0){ printf("pi= %.15f (Error = %e)\n",pi, fabs(acos(-1)-pi)); printf("elapsed Time = %f, [sec]\n", et-st); printf(" \n"); } MPI_Finalize(); return 0; 77
78 PBS Job Script 사용예제 : (PI 코드 ) 컴파일 (pihybrid.c) KNL $ module add craype-mic-knl $ mpiicc qopenmp pihybrid.c -o pihybrid_no_vec $ mpiicc -qopenmp -xmic-avx512 pihybrid.c -o pihybrid_vec SKL $ module rm craype-mic-knl $ module add craype-x86-skylake $ mpiicc qopenmp pihybrid.c -o pihybrid_no_vec $ mpiicc -qopenmp -xcore-avx512 pihybrid.c -o pihybrid_vec 78
79 PBS Job Script 사용예제 : (PI 코드 ) hybrid.sh(knl) $ cat hybrid.sh #!/bin/bash #PBS -V #PBS -N Hybrid_job #PBS -q normal #PBS -l walltime=00:02:00 #PBS -l select=2:ncpus=68:mpiprocs=2:ompthreads=34 cd $PBS_O_WORKDIR mpirun -machinefile $PBS_NODEFILE./piHybrid_no_vec mpirun -machinefile $PBS_NODEFILE./piHybrid_vec KNL # of processes : 4 w/o AVX512 Elapsed Time = , [sec] # of processes : 4 w/ AVX512 Elapsed Time = , [sec] 79
80 PBS Job Script 사용예제 : (PI 코드 ) hybrid.sh(skl) $ cat hybrid.sh #!/bin/bash #PBS -V #PBS -N Hybrid_job #PBS -q norm_skl #PBS -l walltime=00:02:00 #PBS -l select=2:ncpus=40:mpiprocs=2:ompthreads=20 cd $PBS_O_WORKDIR mpirun -machinefile $PBS_NODEFILE./piHybrid_no_vec mpirun -machinefile $PBS_NODEFILE./piHybrid_vec SKL # of processes : 4 # of threads : 20 w/o AVX512 Elapsed Time = , [sec] # of processes : 4 w/ AVX512 Elapsed Time = , [sec] 80
81 PBS Interactive 작업제출 누리온시스템은 debug 노드대신 debug 큐를제공 debug 큐를이용하여작업을제출함으로써디버깅수행이가능 qsub I ( 대문자 i 임 ) qsub 를이용한 Interactive 작업사용예 (MPI) [sedu01@pbcm Pi_Calc]$ qsub -I -V -l select=1:ncpus=68:mpiprocs=68 -l walltime=00:10:00 -q debug qsub: waiting for job 6719.pbcm to start qsub: job 6719.pbcm ready Intel(R) Parallel Studio XE 2017 Update 2 for Linux* Copyright (C) Intel Corporation. All rights reserved. [sedu01@node8281 ~]$ cd $PBS_O_WORKDIR [sedu01@node8281 ~]$ mpirun -n 68./piMPI_vec [sedu01@node8281 Pi_Calc]$ mpirun -np 68./piMPI_vec # of processes : 68 PI= (Error = e-10) Elapsed Time = , [sec] [sedu01@node8281 ~]$ exit [sedu01@login04 ~] $ 81
82 PBS Interactive 작업 Interactive 작업조회 : qstat, pbsnodes $ qstat Job id Name User Time Use S Queue pbcm vasp_07 hskim :20 R knl 6615.pbcm vasp_13 hskim0 4664:02: R knl 6628.pbcm ESM_pos2_ hskim0 2387:09: R cpu 6638.pbcm vasp_16 hskim0 2536:51: R knl 6641.pbcm vasp_18 hskim0 2533:49: R knl 6643.pbcm ESM_pos1_ hskim0 1177:07: R cpu 6644.pbcm ESM_pos1_ hskim0 1176:39: R cpu 6719.pbcm STDIN sedu01 00:05:30 R knl $ pbsnodes -asj mem ncpus nmics ngpus vnode state njobs run susp f/t f/t f/t f/t jobs node8281 job-busy gb/110gb 0/68 0/0 0/ node8282 free gb/110gb 4/68 0/0 0/ node0010 free gb/110gb 68/68 0/0 0/0 -- cpu0004 job-busy gb/188gb 0/40 0/0 0/ cpu0003 job-busy gb/188gb 0/40 0/0 0/ cpu0002 job-busy gb/188gb 0/40 0/0 0/ cpu0001 free gb/188gb 40/40 0/0 0/
83 Compile Serial SKL : icc -O3 -xcore-avx512 (-qopt-report=5) pi.c -o pi_skl.x KNL : icc -O3 -xmic-avx512 (-qopt-report=5) pi.c -o pi_knl.x OpenMP SKL : icc -O3 -xcore-avx512 -qopenmp piopenmp.c -o piopenmp_skl.x KNL : icc -O3 -xmic-avx512 -qopenmp piopenmp.c -o piopenmp_knl.x MPI SKL : mpiicc -O3 -xcore-avx512 pimpi.c -o pimpi_skl.x KNL : mpiicc -O3 -xmic-avx512 pimpi.c -o pimpi_knl.x Hybrid SKL : mpiicc -O3 -xcore-avx512 -qopenmp pihybrid.c -o pihybrid_skl.x KNL : mpiicc -O3 -xmic-avx512 -qopenmp pihybrid.c -o pihybrid_knl.x 83
84 Code Optimization 1. Vectorization 2. MCDRAM Memory Modes 3. MCDRAM using by numactl command 4. MCDRAM using by memkind library Physical Cores & 256 Logical Cores 6. Thread Management 7. Set KMP_AFFINITY
 굽기 연산 (vector operation) A[0] B[0] A[1] B[1] A[2] B[2] A[3] B[3] CU ALU ALU ALU ALU C[0] C[1] C[2] C[3] 2")
85 Vectorization What is SIMD (Single Instruction Multiple Data)? 붕어빵굽기 반죽, 팥, 굽기 붕어빵 8 칸짜리틀 8 개의붕어빵 배열연산 A, B, 연산 C 8 칸짜리연산공간 8 개의 C 틀 연산공간 (vector register) 굽기 연산 (vector operation) A[0] B[0] A[1] B[1] A[2] B[2] A[3] B[3] CU ALU ALU ALU ALU C[0] C[1] C[2] C[3] bit VPUs (AVX512) per core vector register size: 512bit 한번에 8 개의 64Byte type (double, int64_t) 한번에 16 개의 32Byte type (float, int) 85
86 Vectorization Memory Alignment Conditions for High Vectorization 1. Memory alignment 2. Memory access pattern 3. Loop data dependency Memory align function _mm_malloc _mm_free hbw_posix_memalign for HBM POSIX posix_memaglign C11 algined_alloc Windows - _aligned_malloc Cache block Memory Cache block Memory
87 Physical Address Physical Address MCDRAM Memory Modes Three modes. Selected at boot Cache Mode Flat Mode Hybrid Mode 16GB MCDRAM 8 or 12 GB MCDRAM 16GB MCDRAM DDR DDR 4 or 8 GB MCDRAM DDR MCDRAM is used as a L3 cache MCDRAM is used as a DDR - numactl command - memkind library MCDRAM is used - as a L3 cache - as a DDR 87

88 MCDRAM using by numactl command Check memory details using numactl command $ numactl -hardware KNL with 2 NUMA nodes DDR KNL MC DRAM node 0 node 1 We can simply use MCDRAM with numactl command with membind option $ numactl -membind 1./myapp.ex 88

89 MCDRAM using by memkind library Use hbw_malloc / hbw_free function, instead of malloc / free function Add memkind library to your compile option CFLAGS = -O3 std=c11 qopenmp qop-report=5 xmic-avx512 -lmemkind Add a header file <hbwmalloc.h> in your source code #include <hbwmalloc.h> 89

90 64 Physical Cores & 256 Logical Cores $ vi /proc/cpuinfo 90

91 Thread Management Tread Binding Allocation of threads may affect performance seriously especially for computation with many threads export KMP_AFFINITY=compact,verbose Compact Scatter Threads are allocated to be close to each other Threads are allocated to be close to each other 91
92 Set KMP_AFFINITY Can you guess the env. option of process? OMP: Info #156: KMP_AFFINITY: 256 available OS procs OMP: Info #157: KMP_AFFINITY: Uniform topology OMP: Info #179: KMP_AFFINITY: 1 packages x 64 cores/pkg x 4 threads/core (64 total cores) OMP: Info #206: KMP_AFFINITY: OS proc to physical thread map: OMP: Info #171: KMP_AFFINITY: OS proc 0 maps to package 0 core 0 thread 0 OMP: Info #171: KMP_AFFINITY: OS proc 64 maps to package 0 core 0 thread 1 OMP: Info #242: KMP_AFFINITY: pid 4393 thread 0 bound to OS proc set {0} OMP: Info #242: KMP_AFFINITY: pid 4660 thread 1 bound to OS proc set {64} 92
93 Set KMP_AFFINITY Can you guess the env. option of process? OMP: Info #156: KMP_AFFINITY: 256 available OS procs OMP: Info #157: KMP_AFFINITY: Uniform topology OMP: Info #179: KMP_AFFINITY: 1 packages x 64 cores/pkg x 4 threads/core (64 total cores) OMP: Info #206: KMP_AFFINITY: OS proc to physical thread map: OMP: Info #171: KMP_AFFINITY: OS proc 0 maps to package 0 core 0 thread 0 OMP: Info #171: KMP_AFFINITY: OS proc 64 maps to package 0 core 0 thread 1 OMP: Info #242: KMP_AFFINITY: pid 4393 thread 0 bound to OS proc set {0} OMP: Info #242: KMP_AFFINITY: pid 4660 thread 1 bound to OS proc set {64} export OMP_NUM_THREADS export KMP_AFFINITY=compact,verbose 93
94 Examples 1. Dense Matrix multiplication 2. Dot Product 3. Histogram 4. Loop Dependency 5. SoA vs. AoS
95 Code compile Compile script(compile.sh) $ cat compile.sh if [ $# -lt 1 ] then echo "please, give one of numbers; 1, 2, or 3" fi case "$1" in 1) #01_MMmul icc 01_MMmul/MMmul.c -std=c11 -qopt-report=5 -O2 -no-vec -qopenmp -o 01_MMmul/MMmul_O2.ex mv 01_MMmul/MMmul.optrpt 01_MMmul/MMmul_O2.optrpt icc 01_MMmul/MMmul.c -std=c11 -qopt-report=5 -O3 -no-vec -qopenmp -o 01_MMmul/MMmul_O3.ex mv 01_MMmul/MMmul.optrpt 01_MMmul/MMmul_O2_AVX512.optrpt icc 01_MMmul/MMmul.c -std=c11 -qopt-report=5 -O3 -qopenmp xmic-avx512 -o 01_MMmul/MMmul_O3_AVX512.ex mv 01_MMmul/MMmul.optrpt 01_MMmul/MMmul_O3_AVX512.optrpt 2) icc 01_MMmul/MMmul.c -std=c11 -qopt-report=5 -O3 -qopenmp -xmic-avx512 -DHAVE_CBLAS -mkl -o 01_MMmul/MMmul_MKL.ex mv 01_MMmul/MMmul.optrpt 01_MMmul/MMmul_MKL.optrpt ;; #02_VVdot icc 02_VVdot/VVdot.c -std=c11 -O0 -qopt-report=5 -qopenmp -no-vec -o 02_VVdot/VVdot_O0.ex mv 02_VVdot/VVdot.optrpt 02_VVdot/VVdot_O0.optrpt icc 02_VVdot/VVdot.c -std=c11 -O1 -qopt-report=5 -qopenmp -no-vec -o 02_VVdot/VVdot_O1.ex mv 02_VVdot/VVdot.optrpt 02_VVdot/VVdot_O1.optrpt icc 02_VVdot/VVdot.c -std=c11 -O2 -qopt-report=5 -qopenmp -no-vec -o 02_VVdot/VVdot_O2.ex mv 02_VVdot/VVdot.optrpt 02_VVdot/VVdot_O2.optrpt icc 02_VVdot/VVdot.c -std=c11 -O2 -qopt-report=5 -qopenmp -xmic-avx512 -o 02_VVdot/VVdot_O2_AVX512.ex mv 02_VVdot/VVdot.optrpt 02_VVdot/VVdot_O2_AVX512.optrpt icc 02_VVdot/VVdot.c -std=c11 -O3 -qopt-report=5 -qopenmp -xmic-avx512 -o 02_VVdot/VVdot_O3_AVX512.ex mv 02_VVdot/VVdot.optrpt 02_VVdot/VVdot_O3_AVX512.optrpt ;; 95
96 Code compile Compile script(compile.sh) 3) #03_Histogram icc 03_Histogram/Histogram.c -std=c11 -qopt-report=5 -O2 -qopenmp -no-vec -o 03_Histogram/Histogram_O2.ex mv 03_Histogram/Histogram.optrpt 03_Histogram/Histogram_O2.optrpt icc 03_Histogram/Histogram.c -std=c11 -qopt-report=5 -O2 -qopenmp -xmic-avx512 -o 03_Histogram/Histogram_O2_AVX512.ex mv 03_Histogram/Histogram.optrpt 03_Histogram/Histogram_O2_AVX512.optrpt icc 03_Histogram/Histogram.c -std=c11 -qopt-report=5 -O3 -qopenmp -xmic-avx512 -o 03_Histogram/Histogram_O3_AVX512.ex mv 03_Histogram/Histogram.optrpt 03_Histogram/Histogram_O3_AVX512.optrpt ;; *) echo "Wrong argument. please check" ;; esac 04_loop, 05_soa 해당디렉터리로이동하여 make 실행 96
97 Example 1 : Dense Matrix multiplication Human friendly code for(int i=0; i<size; i++) { for(int j=0; j<size; j++) { double sum = 0; for(int k=0; k<size; k++) { sum += A[i][k] * B[k][j]; } C[i][j] = sum; } } For a 4 x 4 case - # of cache miss = 24 For a general case of SIZE x SIZE - # of cache miss SIZE + SIZE * SIZE + SIZE = SIZE * (SIZE+2) 97
98 Example 1 : Dense Matrix multiplication Cache & Vectorization friendly code for(int i=0; i<size; i++) { for(int k=0; k<size; k++) { double A_val = A[i][k]; for(int j=0; j<size; j++) { C[i][j] += A_val * B[k][j]; } } } For a 4 x 4 case - # of cache miss = 12 For a general case of SIZE x SIZE - # of cache miss SIZE + SIZE + SIZE = 3 * SIZE 98
99 Example 1 : Dense Matrix multiplication Source code - Mmmul.c #include <stdio.h> #include <string.h> #include <omp.h> #define SIZE 4096 int main(int argc, char *argv[]) { double time; double *A = (double*)_mm_malloc(sizeof(double)*size*size, 64); double *B = (double*)_mm_malloc(sizeof(double)*size*size, 64); double *C = (double*)_mm_malloc(sizeof(double)*size*size, 64); #pragma omp parallel for for(int i=0; i<size; i++) { #pragma vector aligned #pragma omp simd for(int j=0; j<size; j++) { A[i*SIZE+j] = (double)(i + j); B[i*SIZE+j] = (double)(j - i); } } 99
100 Example 1 : Dense Matrix multiplication Source code - Mmmul.c ///////////////////////////////////////////////// memset(c, 0, sizeof(double)*size*size); time = -omp_get_wtime(); #pragma omp parallel for for(int i=0; i<size; i++) { #pragma omp simd #pragma vector aligned for(int j=0; j<size; j++) { double sum = 0; for(int k=0; k<size; k++) { sum += A[i*SIZE+k] * B[k*SIZE+j]; } C[i*SIZE+j] = sum; } } time += omp_get_wtime(); printf("\ti-j-k MMmul time: %lf (secs)\n", time); printf("\t\tlast element: %lf\n\n", C[(SIZE-1)*SIZE+SIZE-1]); 100
101 Example 1 : Dense Matrix multiplication Source code - Mmmul.c ///////////////////////////////////////////////// memset(c, 0, sizeof(double)*size*size); time = -omp_get_wtime(); #pragma omp parallel for for(int i=0; i<size; i++) { for(int k=0; k<size; k++) { double A_val = A[i*SIZE+k]; #pragma omp simd #pragma vector aligned for(int j=0; j<size; j++) { C[i*SIZE+j] += A_val * B[k*SIZE+j]; } } } time += omp_get_wtime(); printf("\ti-k-j MMmul time: %lf (secs)\n", time); printf("\t\tlast element: %lf\n\n", C[(SIZE-1)*SIZE+SIZE-1]); ///////////////////////////////////////////////// _mm_free(a); _mm_free(b); _mm_free(c); } return 0; 101

 Auto vectorization")
102 Example 1 : Dense Matrix multiplication Results Vectorization (w/ simd directive) Auto vectorization (wo/ no simd) 102
 Auto vectorization (wo/ no")
103 Example 1 : Dense Matrix multiplication Results directives Vectorization (w/ simd directive) Auto vectorization (wo/ no simd) 103
104 Example 2 : Dot Product (Prefetch) Dot Product Between Sparse Vector and Dense Vector Code double A = malloc(sizeof *A * N); double B = malloc(sizeof *B * M); double B_ = malloc(sizeof *B_ * N); double C = malloc(sizeof *C * N); int index = malloc(sizeof *index * N); B for (int i = 0; i < N; i++) C[i] = A[i] * B[index[i]]; for (int i = 0; i < N; i++) B_[i] = B[index[i]]; for (int i = 0; i < N; i++) C[i] = A[i] * B_[i]; index index A C 104
105 Example 2 : Dot Product (Prefetch) Dot Product Between Sparse Vector and Dense Vector Code double A = malloc(sizeof *A * N); double B = malloc(sizeof *B * M); double B_ = malloc(sizeof *B_ * N); double C = malloc(sizeof *C * N); int index = malloc(sizeof *index * N); B for (int i = 0; i < N; i++) C[i] = A[i] * B[index[i]]; for (int i = 0; i < N; i++) B_[i] = B[index[i]]; for (int i = 0; i < N; i++) C[i] = A[i] * B_[i]; index index A C 105
106 Example 2 : Dot Product (Prefetch) Dot Product Between Sparse Vector and Dense Vector Code double A = malloc(sizeof *A * N); double B = malloc(sizeof *B * M); double B_ = malloc(sizeof *B_ * N); double C = malloc(sizeof *C * N); int index = malloc(sizeof *index * N); B for (int i = 0; i < N; i++) C[i] = A[i] * B[index[i]]; for (int i = 0; i < N; i++) B_[i] = B[index[i]]; for (int i = 0; i < N; i++) C[i] = A[i] * B_[i]; index index A C 106
107 Example 2 : Dot Product (Prefetch) Dot Product Between Sparse Vector and Dense Vector Code double A = malloc(sizeof *A * N); double B = malloc(sizeof *B * M); double B_ = malloc(sizeof *B_ * N); double C = malloc(sizeof *C * N); int index = malloc(sizeof *index * N); B for (int i = 0; i < N; i++) C[i] = A[i] * B[index[i]]; for (int i = 0; i < N; i++) B_[i] = B[index[i]]; for (int i = 0; i < N; i++) C[i] = A[i] * B_[i]; index index A C 107
108 Example 2 : Dot Product (Prefetch) Dot Product Between Sparse Vector and Dense Vector Code double A = malloc(sizeof *A * N); double B = malloc(sizeof *B * M); double B_ = malloc(sizeof *B_ * N); double C = malloc(sizeof *C * N); int index = malloc(sizeof *index * N); B for (int i = 0; i < N; i++) C[i] = A[i] * B[index[i]]; for (int i = 0; i < N; i++) B_[i] = B[index[i]]; for (int i = 0; i < N; i++) C[i] = A[i] * B_[i]; index A B_ C 108
109 Example 2 : Dot Product (Prefetch) Dot Product Between Sparse Vector and Dense Vector Code double A = malloc(sizeof *A * N); double B = malloc(sizeof *B * M); double B_ = malloc(sizeof *B_ * N); double C = malloc(sizeof *C * N); int index = malloc(sizeof *index * N); B for (int i = 0; i < N; i++) C[i] = A[i] * B[index[i]]; for (int i = 0; i < N; i++) B_[i] = B[index[i]]; for (int i = 0; i < N; i++) C[i] = A[i] * B_[i]; index A B_ C 109
110 Example 2 : Dot Product (Prefetch) Dot Product Between Sparse Vector and Dense Vector Code double A = malloc(sizeof *A * N); double B = malloc(sizeof *B * M); double B_ = malloc(sizeof *B_ * N); double C = malloc(sizeof *C * N); int index = malloc(sizeof *index * N); B for (int i = 0; i < N; i++) C[i] = A[i] * B[index[i]]; for (int i = 0; i < N; i++) B_[i] = B[index[i]]; for (int i = 0; i < N; i++) C[i] = A[i] * B_[i]; index A B_ C 110
111 Example 2 : Dot Product (Prefetch) Dot Product Between Sparse Vector and Dense Vector Code double A = malloc(sizeof *A * N); double B = malloc(sizeof *B * M); double B_ = malloc(sizeof *B_ * N); double C = malloc(sizeof *C * N); int index = malloc(sizeof *index * N); B for (int i = 0; i < N; i++) C[i] = A[i] * B[index[i]]; for (int i = 0; i < N; i++) B_[i] = B[index[i]]; for (int i = 0; i < N; i++) C[i] = A[i] * B_[i]; index A B_ C 111
112 Example 2 : Dot Product (Prefetch) Dot Product Between Sparse Vector and Dense Vector Code double A = malloc(sizeof *A * N); double B = malloc(sizeof *B * M); double B_ = malloc(sizeof *B_ * N); double C = malloc(sizeof *C * N); int index = malloc(sizeof *index * N); B for (int i = 0; i < N; i++) C[i] = A[i] * B[index[i]]; for (int i = 0; i < N; i++) B_[i] = B[index[i]]; for (int i = 0; i < N; i++) C[i] = A[i] * B_[i]; index A B_ C 112
113 Example 2 : Dot Product (Prefetch) Source Code of Dot Product 01: #include <stdio.h> 02: #include <stdlib.h> 03: #include <math.h> 04: #include <omp.h> 05: #define N : #define Nnz : int main(int argc, char **argv){ 09: double time; 10: int *index = malloc(sizeof *index * Nnz); 11: double *svector_in = malloc(sizeof *svector_in * Nnz); 12: double *fvector_in = malloc(sizeof *fvector_in * N ); 13: double *svector_out = malloc(sizeof *svector_out * Nnz); 14: double *temp = malloc(sizeof *temp * Nnz); 15: for (int i = 0; i < N; i++) 16: fvector_in[i] = (double)(i); 17: for (int i = 0; i < Nnz; i++) { 18: svector_in[i] = (double)(i); 19: index[i] = i * (int)(n / Nnz); 20: svector_out[i] = 0.; 21: temp[i] = fvector_in[index[i]]; 22: } 113
114 Example 2 : Dot Product (Prefetch) Source Code of Dot Product 23: time = -omp_get_wtime(); 24: #pragma omp parallel for 25: for (int j = 0; j < ; j++) 26: for (int i = 0; i < Nnz; i++) 27: svector_out[i] = svector_in[i] * fvector_in[index[i]]; 28: time += omp_get_wtime(); 29: printf("\t1 VVdot time:%lf (secs)\n", time); 30: 31: time = -omp_get_wtime(); 32: #pragma omp parallel for 33: for (int j = 0; j < ; j++) 34: for (int i = 0; i < Nnz; i++) 35: svector_out[i] = svector_in[i] * temp[i]; 36: time += omp_get_wtime(); 37: printf("\t2 VVdot time: %lf (secs)\n", time); 38: 39: free(index); free(svector_in); 40: free(svector_out); free(fvector_in); 41: return 0; 42: } 114


115 Example 2 : Dot Product (Prefetch) without MCDRAM 34 threads w/ scatter 68 threads w/ scatter $ cat openmp.sh #!/bin/bash #PBS -V #PBS -N OMP_job #PBS q normal #PBS -l walltime=00:10:00 #PBS -l select=1:ncpus=68:ompthreads=68 #PBS -l place=scatter cd $PBS_O_WORKDIR./02_VVdot/VVdot_O0.ex./02_VVdot/VVdot_O1.ex./02_VVdot/VVdot_O2.ex./02_VVdot/VVdot_O2_AVX512.ex./02_VVdot/VVdot_O3_AVX512.ex 115
116 Example 3 : Histogram Human friendly code for(int i=0; i<n; i++) { int index = (int)(age[i] / 20); hist[index]++; } age / 20 index 3 hist[3]++ hist
117 Example 3 : Histogram Human friendly code for(int i=0; i<n; i++) { int index = (int)(age[i] / 20); hist[index]++; } age / 20 index 1 hist[1]++ hist
118 Example 3 : Histogram Human friendly code for(int i=0; i<n; i++) { int index = (int)(age[i] / 20); hist[index]++; } age / 20 index 3 hist[3]++ hist
119 Example 3 : Histogram Human friendly code for(int i=0; i<n; i++) { int index = (int)(age[i] / 20); hist[index]++; } age / 20 index 2 hist[2]++ hist
120 Example 3 : Histogram Human friendly code for(int i=0; i<n; i++) { int index = (int)(age[i] / 20); hist[index]++; } age / 20 index 2 hist[2]++ hist
121 Example 3 : Histogram Cache & Vectorization friendly code for(int i=0; i<n; i++) { int index = (int)(age[i] / 20); hist[index]++; } age VL age[j] / 20 index hist[3]++ hist
122 Example 3 : Histogram Cache & Vectorization friendly code for(int i=0; i<n; i++) { int index = (int)(age[i] / 20); hist[index]++; } age VL age[j] / 20 index hist[1]++ hist
123 Example 3 : Histogram Cache & Vectorization friendly code for(int i=0; i<n; i++) { int index = (int)(age[i] / 20); hist[index]++; } age VL age[j] / 20 index hist[3]++ hist
124 Example 3 : Histogram Cache & Vectorization friendly code for(int i=0; i<n; i++) { int index = (int)(age[i] / 20); hist[index]++; } age VL age[j] / 20 index hist[3]++ hist
125 Example 3 : Histogram Cache & Vectorization friendly code for(int i=0; i<n; i++) { int index = (int)(age[i] / 20); hist[index]++; } age VL age[j] / 20 index hist[3]++ hist
126 Example 3 : Histogram Source code - Histogram.c #include <stdio.h> #include <time.h> #include <omp.h> #define N #define VL 512 int main(int argc, char *argv[]) { srand(time(null)); double time; int *age = (int*)_mm_malloc(sizeof(int)*n, 64); int hist[5]; int randomnum = 0; #pragma omp parallel { randomnum = rand() % 100; #pragma omp for simd #pragma vector aligned for(int i=0; i<n; i++) age[i] = randomnum; } ///////////////////////////////////////////////// for(int i=0; i<5; i++) hist[i] = 0; time = -omp_get_wtime(); for(int i=0; i<n; i++) { int index = (int)(age[i] / 20); hist[index]++; } time += omp_get_wtime(); printf("\t1 Histogram time: %lf (secs)\n", time); for(int i=0; i<5; i++) printf("\t\t%d\n", hist[i]); printf("\n"); 126
127 Example 3 : Histogram Source code - Histogram.c ///////////////////////////////////////////////// for(int i=0; i < 5; i++) hist[i] = 0; time = -omp_get_wtime(); #pragma omp parallel { int *index = (int*)_mm_malloc(sizeof(int)*vl, 64); int hist_private[5]; for(int i=0; i<5; i++) hist_private[i] = 0; #pragma omp for for(int i=0; i<n; i+=vl) { #pragma omp simd #pragma vector aligned for(int j=i; j<i+vl; j++) index[j-i] = (int)(age[j] / 20); for(int j=0; j<vl; j++) hist_private[index[j]]++; } #pragma omp critical { for(int i=0; i<5; i++) hist[i] += hist_private[i]; } _mm_free(index); } time += omp_get_wtime(); printf("\t2 Histogram time: %lf (secs)\n", time); for(int i=0; i<5; i++) printf("\t\t%d\n", hist[i]); printf("\n"); //////////////////////////////// _mm_free(age); } return 0; 127

128 Example 3 : Histogram Results 128
129 Example 3 : Histogram - PBS Results $ cat openmp.sh #!/bin/bash #PBS -V #PBS -N OMP_job #PBS -q normal #PBS -l walltime=00:10:00 #PBS -l select=1:ncpus=68:ompthreads=68 Histogram_O2_AVX512.ex cd $PBS_O_WORKDIR./Histogram_O2.ex./Histogram_O2_AVX512.ex./Histogram_O3_AVX512.ex Histogram_O2.ex Histogram_O3_AVX512.ex 129

130 Example 3 : Histogram Optimization Report 130

131 Example 3 : Histogram Optimization Report 131
132 Example 4 : Loop Dependency Loop Dependency and Vectorization #define N int *a = malloc(sizeof *a * (N + 1)); a for (int i = 0; i < N; i++) a[i] = a[i + 1]; for (int i = 1; i <= N; i++) a[i] = a[i - 1]; write read read 132
133 Example 4 : Loop Dependency Loop Dependency and Vectorization #define N int *a = malloc(sizeof *a * (N + 1)); for (int i = 0; i < N; i++) a[i] = a[i + 1]; a write write after read read read for (int i = 1; i <= N; i++) a[i] = a[i - 1]; 133
134 Example 4 : Loop Dependency Loop Dependency and Vectorization #define N int *a = malloc(sizeof *a * (N + 1)); a for (int i = 0; i < N; i++) a[i] = a[i + 1]; write write after read write after read write read after read read for (int i = 1; i <= N; i++) a[i] = a[i - 1]; 134
135 Example 4 : Loop Dependency Loop Dependency and Vectorization #define N int *a = malloc(sizeof *a * (N + 1)); a for (int i = 0; i < N; i++) a[i] = a[i + 1]; write write after read write after read write after read read for (int i = 1; i <= N; i++) a[i] = a[i - 1]; 135
136 Example 4 : Loop Dependency Loop Dependency and Vectorization #define N int *a = malloc(sizeof *a * (N + 1)); a for (int i = 0; i < N; i++) a[i] = a[i + 1]; write write after read write after read write after read write after read read for (int i = 1; i <= N; i++) a[i] = a[i - 1]; 136
137 Example 4 : Loop Dependency Loop Dependency and Vectorization #define N int *a = malloc(sizeof *a * (N + 1)); a for (int i = 0; i < N; i++) a[i] = a[i + 1]; for (int i = 1; i <= N; i++) a[i] = a[i - 1]; read write 137
138 Example 4 : Loop Dependency Loop Dependency and Vectorization #define N int *a = malloc(sizeof *a * (N + 1)); a for (int i = 0; i < N; i++) a[i] = a[i + 1]; read read after write write for (int i = 1; i <= N; i++) a[i] = a[i - 1]; 138
139 Example 4 : Loop Dependency Loop Dependency and Vectorization #define N int *a = malloc(sizeof *a * (N + 1)); a for (int i = 0; i < N; i++) a[i] = a[i + 1]; read read after write read after write write for (int i = 1; i <= N; i++) a[i] = a[i - 1]; 139
140 Example 4 : Loop Dependency Loop Dependency and Vectorization #define N int *a = malloc(sizeof *a * (N + 1)); a for (int i = 0; i < N; i++) a[i] = a[i + 1]; read read after write read after write read after write write for (int i = 1; i <= N; i++) a[i] = a[i - 1]; 140
141 Example 4 : Loop Dependency Loop Dependency and Vectorization #define N int *a = malloc(sizeof *a * (N + 1)); a for (int i = 0; i < N; i++) a[i] = a[i + 1]; read read after write read after write read after write read after write write for (int i = 1; i <= N; i++) a[i] = a[i - 1]; WAR : write after read RAW : read after write Which one is vectorizable? 141


142 Example 4 : Loop Dependency Source Code 142
143 Example 4 : Loop Dependency Results of Code Run icc -std=c99 -qopt-report=5 -xmic-avx512 -o loop loop.c $./loop write after read : e+15 read after write : e+00 write after read (simd) : e+15 read after write (simd) : e
144 Example 4 : Loop Dependency - PBS Results of Code Run icc -std=c99 -qopt-report=5 -xcommon-avx512 -o loop loop.c $ cat serial.sh #!/bin/bash #PBS -V #PBS -N Serial_job #PBS -q normal #PBS -l walltime=00:20:00 #PBS -l select=1 cd $PBS_O_WORKDIR./loop $ cat Serial_job.o6803 write after read : e+15 read after write : e+00 write after read (simd) : e+15 read after write (simd) : e
145 Example 4 : Loop Dependency Loop Dependency and Vectorization #define N int *a = malloc(sizeof *a * (N + 1)); for (int i = 0; i < N; i++) a[i] = a[i + 1]; for (int i = 1; i <= N; i++) a[i] = a[i - 1]; 145
146 Example 4 : Loop Dependency Loop Dependency and Vectorization #define N int *a = malloc(sizeof *a * (N + 1)); for (int i = 0; i < N; i++) a[i] = a[i + 1]; for (int i = 1; i <= N; i++) a[i] = a[i - 1];!!!!! 146
147 Example 4 : Loop Dependency Optimization Report LOOP BEGIN at loop.c(30,5) remark #25401: memcopy(with guard) generated remark #15541: outer loop was not auto-vectorized: consider using SIMD directive LOOP BEGIN at loop.c(30,5) <Multiversioned v2> remark #15304: loop was not vectorized: non-vectorizable loop instance from multiversioning remark #25439: unrolled with remainder by 2 remark #25456: Number of Array Refs Scalar Replaced In Loop: 2 LOOP END LOOP BEGIN at loop.c(30,5) <Remainder, Multiversioned v2> LOOP END LOOP END 147
148 Example 5 : Structure of Array vs Array of Structure SOA and Vectorization point x y x y x y x y x y x y #define N struct { double x; double y; } *point = malloc(sizeof *point * N); struct { double *x; double *y; } set; set.x = malloc(sizeof *(set.x) * N); set.y = malloc(sizeof *(set.y) * N); 148
149 Example 5 : Structure of Array vs Array of Structure SOA and Vectorization point x y x y x y x y x y x y #define N set struct { double x; double y; } *point = malloc(sizeof *point * N); struct { double *x; double *y; } set; set.x = malloc(sizeof *(set.x) * N); set.y = malloc(sizeof *(set.y) * N); x y 149
150 Example 5 : Structure of Array vs Array of Structure SOA and Vectorization point x y x y x y x y x y x y stride = 2 #define N set struct { double x; double y; } *point = malloc(sizeof *point * N); struct { double *x; double *y; } set; set.x = malloc(sizeof *(set.x) * N); set.y = malloc(sizeof *(set.y) * N); x y stride = 1 150


151 Example 5 : Structure of Array vs Array of Structure Source Code 151
152 Example 5 : Structure of Array vs Array of Structure Performance on Xeon Phi Knights Landing 7210(64 cores, 4HyperT/core) without MCDRAM icc -std=c99 -qopt-report=5 -xmic-avx512 -o soa soa.c -lgomp $./soa Array of Structure: (secs) Structure of Array: (secs) 152
153 Example 5 : Structure of Array vs Array of Structure-PBS Performance on Xeon Phi Knights Landing 7250(68 cores, 4HyperT/core) without MCDRAM icc -std=c99 -qopt-report=5 -xcommon-avx512 -o soa soa.c -lgomp $ cat serial.sh #!/bin/bash #PBS -V #PBS -N Serial_job #PBS -q normal #PBS -l walltime=00:20:00 #PBS -l select=1 cd $PBS_O_WORKDIR./soa $ cat Serial_job.o6804 Array of Structure: (secs) Structure of Array: (secs) 153
154 Example 5 : Structure of Array vs Array of Structure Optimization Report LOOP BEGIN at soa.c(23,5) remark #15416: vectorization support: non-unit strided store was generated for the variable <point->y[i]>, stride is 2 [ soa.c(24,9) ] remark #15415: vectorization support: non-unit strided load was generated for the variable <point->x[i]>, stride is 2 [ soa.c(24,27) ] remark #15305: vectorization support: vector length 16 remark #15399: vectorization support: unroll factor set to 2 remark #15300: LOOP WAS VECTORIZED remark #15452: unmasked strided loads: 1 remark #15453: unmasked strided stores: 1 remark #15475: --- begin vector cost summary --- remark #15476: scalar cost: 7 remark #15477: vector cost: remark #15478: estimated potential speedup: remark #15488: --- end vector cost summary --- remark #25015: Estimate of max trip count of loop= LOOP END 154
155 Example 5 : Structure of Array vs Array of Structure Optimization Report LOOP BEGIN at soa.c(29,5) remark #15388: vectorization support: reference set.y[i] has aligned access [ soa.c(30,9) ] remark #15389: vectorization support: reference set.x[i] has unaligned access [ soa.c(30,25) ] remark #15381: vectorization support: unaligned access used inside loop body remark #15412: vectorization support: streaming store was generated for set.y[i] [ soa.c(30,9) ] remark #15412: vectorization support: streaming store was generated for set.y[i] [ soa.c(30,9) ] remark #15305: vectorization support: vector length 16 remark #15309: vectorization support: normalized vectorization overhead remark #15300: LOOP WAS VECTORIZED remark #15442: entire loop may be executed in remainder remark #15449: unmasked aligned unit stride stores: 1 remark #15450: unmasked unaligned unit stride loads: 1 remark #15467: unmasked aligned streaming stores: 2 remark #15475: --- begin vector cost summary --- remark #15476: scalar cost: 7 remark #15477: vector cost: remark #15478: estimated potential speedup: remark #15488: --- end vector cost summary --- remark #25015: Estimate of max trip count of loop= LOOP END 155

156 Q&A 계산과학응용센터 / 과학데이터스쿨 156

157 계산과학응용센터 / 과학데이터스쿨 157
강의10
 Computer Programming gdb and awk 12 th Lecture 김현철컴퓨터공학부서울대학교 순서 C Compiler and Linker 보충 Static vs Shared Libraries ( 계속 ) gdb awk Q&A Shared vs Static Libraries ( 계속 ) Advantage of Using Libraries Reduced
Computer Programming gdb and awk 12 th Lecture 김현철컴퓨터공학부서울대학교 순서 C Compiler and Linker 보충 Static vs Shared Libraries ( 계속 ) gdb awk Q&A Shared vs Static Libraries ( 계속 ) Advantage of Using Libraries Reduced
6주차.key
 6, Process concept A program in execution Program code PCB (process control block) Program counter, registers, etc. Stack Heap Data section => global variable Process in memory Process state New Running
6, Process concept A program in execution Program code PCB (process control block) Program counter, registers, etc. Stack Heap Data section => global variable Process in memory Process state New Running
PowerPoint 프레젠테이션
 7-Segment Device Control - Device driver Jo, Heeseung HBE-SM5-S4210 의 M3 Module 에는 6 자리를가지는 7-Segment 모듈이아래그림처럼실장 6 Digit 7-Segment 2 6-Digit 7-Segment LED controller 16비트로구성된 2개의레지스터에의해제어 SEG_Sel_Reg(Segment
7-Segment Device Control - Device driver Jo, Heeseung HBE-SM5-S4210 의 M3 Module 에는 6 자리를가지는 7-Segment 모듈이아래그림처럼실장 6 Digit 7-Segment 2 6-Digit 7-Segment LED controller 16비트로구성된 2개의레지스터에의해제어 SEG_Sel_Reg(Segment
PowerPoint 프레젠테이션
 KeyPad Device Control - Device driver Jo, Heeseung HBE-SM5-S4210 에는 16 개의 Tack Switch 를사용하여 4 행 4 열의 Keypad 가장착 4x4 Keypad 2 KeyPad 를제어하기위하여 FPGA 내부에 KeyPad controller 가구현 KeyPad controller 16bit 로구성된
KeyPad Device Control - Device driver Jo, Heeseung HBE-SM5-S4210 에는 16 개의 Tack Switch 를사용하여 4 행 4 열의 Keypad 가장착 4x4 Keypad 2 KeyPad 를제어하기위하여 FPGA 내부에 KeyPad controller 가구현 KeyPad controller 16bit 로구성된
Sena Technologies, Inc. HelloDevice Super 1.1.0
 HelloDevice Super 110 Copyright 1998-2005, All rights reserved HelloDevice 210 ()137-130 Tel: (02) 573-5422 Fax: (02) 573-7710 E-Mail: support@senacom Website: http://wwwsenacom Revision history Revision
HelloDevice Super 110 Copyright 1998-2005, All rights reserved HelloDevice 210 ()137-130 Tel: (02) 573-5422 Fax: (02) 573-7710 E-Mail: support@senacom Website: http://wwwsenacom Revision history Revision
PowerPoint 프레젠테이션
 7-Segment Device Control - Device driver Jo, Heeseung HBE-SM5-S4210 의 M3 Module 에는 6 자리를가지는 7-Segment 모듈이아래그림처럼실장 6 Digit 7-Segment 2 6-Digit 7-Segment LED Controller 16비트로구성된 2개의레지스터에의해제어 SEG_Sel_Reg(Segment
7-Segment Device Control - Device driver Jo, Heeseung HBE-SM5-S4210 의 M3 Module 에는 6 자리를가지는 7-Segment 모듈이아래그림처럼실장 6 Digit 7-Segment 2 6-Digit 7-Segment LED Controller 16비트로구성된 2개의레지스터에의해제어 SEG_Sel_Reg(Segment
K7VT2_QIG_v3
 1......... 2 3..\ 4 5 [R] : Enter Raid setup utility 6 Press[A]keytocreateRAID RAID Type: JBOD RAID 0 RAID 1: 2 7 " RAID 0 Auto Create Manual Create: 2 RAID 0 Block Size: 16K 32K
1......... 2 3..\ 4 5 [R] : Enter Raid setup utility 6 Press[A]keytocreateRAID RAID Type: JBOD RAID 0 RAID 1: 2 7 " RAID 0 Auto Create Manual Create: 2 RAID 0 Block Size: 16K 32K
APOGEE Insight_KR_Base_3P11
 Technical Specification Sheet Document No. 149-332P25 September, 2010 Insight 3.11 Base Workstation 그림 1. Insight Base 메인메뉴 Insight Base Insight Insight Base, Insight Base Insight Base Insight Windows
Technical Specification Sheet Document No. 149-332P25 September, 2010 Insight 3.11 Base Workstation 그림 1. Insight Base 메인메뉴 Insight Base Insight Insight Base, Insight Base Insight Base Insight Windows
 C 프로그래밍 언어 입문 C 프로그래밍 언어 입문 김명호저 숭실대학교 출판국 머리말..... C, C++, Java, Fortran, Python, Ruby,.. C. C 1972. 40 C.. C. 1999 C99. C99. C. C. C., kmh ssu.ac.kr.. ,. 2013 12 Contents 1장 프로그래밍 시작 1.1 C 10 1.2 12
C 프로그래밍 언어 입문 C 프로그래밍 언어 입문 김명호저 숭실대학교 출판국 머리말..... C, C++, Java, Fortran, Python, Ruby,.. C. C 1972. 40 C.. C. 1999 C99. C99. C. C. C., kmh ssu.ac.kr.. ,. 2013 12 Contents 1장 프로그래밍 시작 1.1 C 10 1.2 12
PowerPoint 프레젠테이션
 7-SEGMENT DEVICE CONTROL - DEVICE DRIVER Jo, Heeseung 디바이스드라이버구현 : 7-SEGMENT HBE-SM5-S4210 의 M3 Module 에는 6 자리를가지는 7-Segment 모듈이아래그림처럼실장 6 Digit 7-Segment 2 디바이스드라이버구현 : 7-SEGMENT 6-Digit 7-Segment LED
7-SEGMENT DEVICE CONTROL - DEVICE DRIVER Jo, Heeseung 디바이스드라이버구현 : 7-SEGMENT HBE-SM5-S4210 의 M3 Module 에는 6 자리를가지는 7-Segment 모듈이아래그림처럼실장 6 Digit 7-Segment 2 디바이스드라이버구현 : 7-SEGMENT 6-Digit 7-Segment LED
PowerPoint 프레젠테이션
 (Host) set up : Linux Backend RS-232, Ethernet, parallel(jtag) Host terminal Target terminal : monitor (Minicom) JTAG Cross compiler Boot loader Pentium Redhat 9.0 Serial port Serial cross cable Ethernet
(Host) set up : Linux Backend RS-232, Ethernet, parallel(jtag) Host terminal Target terminal : monitor (Minicom) JTAG Cross compiler Boot loader Pentium Redhat 9.0 Serial port Serial cross cable Ethernet
Microsoft PowerPoint - eSlim SV5-2410 [20080402]
![Microsoft PowerPoint - eSlim SV5-2410 [20080402]](/thumbs/40/20557413.jpg "Microsoft PowerPoint - eSlim SV5-2410 [20080402]") Innovation for Total Solution Provider!! eslim SV5-2410 Opteron Server 2008. 3 ESLIM KOREA INC. 1. 제 품 개 요 eslim SV5-2410 Server Quad-Core and Dual-Core Opteron 2000 Series Max. 4 Disk Bays for SAS and
Innovation for Total Solution Provider!! eslim SV5-2410 Opteron Server 2008. 3 ESLIM KOREA INC. 1. 제 품 개 요 eslim SV5-2410 Server Quad-Core and Dual-Core Opteron 2000 Series Max. 4 Disk Bays for SAS and
Microsoft Word - 3부A windows 환경 IVF + visual studio.doc
 Visual Studio 2005 + Intel Visual Fortran 9.1 install Intel Visual Fortran 9.1 intel Visual Fortran Compiler 9.1 만설치해서 DOS 모드에서실행할수있지만, Visual Studio 2005 의 IDE 를사용하기위해서는 Visual Studio 2005 를먼저설치후 Integration
Visual Studio 2005 + Intel Visual Fortran 9.1 install Intel Visual Fortran 9.1 intel Visual Fortran Compiler 9.1 만설치해서 DOS 모드에서실행할수있지만, Visual Studio 2005 의 IDE 를사용하기위해서는 Visual Studio 2005 를먼저설치후 Integration
Integ
 HP Integrity HP Chipset Itanium 2(Processor 9100) HP Integrity HP, Itanium. HP Integrity Blade BL860c HP Integrity Blade BL870c HP Integrity rx2660 HP Integrity rx3600 HP Integrity rx6600 2 HP Integrity
HP Integrity HP Chipset Itanium 2(Processor 9100) HP Integrity HP, Itanium. HP Integrity Blade BL860c HP Integrity Blade BL870c HP Integrity rx2660 HP Integrity rx3600 HP Integrity rx6600 2 HP Integrity
PowerPoint 프레젠테이션
 Reasons for Poor Performance Programs 60% Design 20% System 2.5% Database 17.5% Source: ORACLE Performance Tuning 1 SMS TOOL DBA Monitoring TOOL Administration TOOL Performance Insight Backup SQL TUNING
Reasons for Poor Performance Programs 60% Design 20% System 2.5% Database 17.5% Source: ORACLE Performance Tuning 1 SMS TOOL DBA Monitoring TOOL Administration TOOL Performance Insight Backup SQL TUNING
MAX+plus II Getting Started - 무작정따라하기
 무작정 따라하기 2001 10 4 / Version 20-2 0 MAX+plus II Digital, Schematic Capture MAX+plus II, IC, CPLD FPGA (Logic) ALTERA PLD FLEX10K Series EPF10K10QC208-4 MAX+plus II Project, Schematic, Design Compilation,
무작정 따라하기 2001 10 4 / Version 20-2 0 MAX+plus II Digital, Schematic Capture MAX+plus II, IC, CPLD FPGA (Logic) ALTERA PLD FLEX10K Series EPF10K10QC208-4 MAX+plus II Project, Schematic, Design Compilation,
PowerPoint 프레젠테이션
 Text-LCD Device Control - Device driver Jo, Heeseung M3 모듈에장착되어있는 Tedxt LCD 장치를제어하는 App 을개발 TextLCD 는영문자와숫자일본어, 특수문자를표현하는데사용되는디바이스 HBE-SM5-S4210 의 TextLCD 는 16 문자 *2 라인을 Display 할수있으며, 이 TextLCD 를제어하기위하여
Text-LCD Device Control - Device driver Jo, Heeseung M3 모듈에장착되어있는 Tedxt LCD 장치를제어하는 App 을개발 TextLCD 는영문자와숫자일본어, 특수문자를표현하는데사용되는디바이스 HBE-SM5-S4210 의 TextLCD 는 16 문자 *2 라인을 Display 할수있으며, 이 TextLCD 를제어하기위하여
DE1-SoC Board
 실습 1 개발환경 DE1-SoC Board Design Tools - Installation Download & Install Quartus Prime Lite Edition http://www.altera.com/ Quartus Prime (includes Nios II EDS) Nios II Embedded Design Suite (EDS) is automatically
실습 1 개발환경 DE1-SoC Board Design Tools - Installation Download & Install Quartus Prime Lite Edition http://www.altera.com/ Quartus Prime (includes Nios II EDS) Nios II Embedded Design Suite (EDS) is automatically
vm-웨어-앞부속
 VMware vsphere 4 This document was created using the official VMware icon and diagram library. Copyright 2009 VMware, Inc. All rights reserved. This product is protected by U.S. and international copyright
VMware vsphere 4 This document was created using the official VMware icon and diagram library. Copyright 2009 VMware, Inc. All rights reserved. This product is protected by U.S. and international copyright
PCServerMgmt7
 Web Windows NT/2000 Server DP&NM Lab 1 Contents 2 Windows NT Service Provider Management Application Web UI 3 . PC,, Client/Server Network 4 (1),,, PC Mainframe PC Backbone Server TCP/IP DCS PLC Network
Web Windows NT/2000 Server DP&NM Lab 1 Contents 2 Windows NT Service Provider Management Application Web UI 3 . PC,, Client/Server Network 4 (1),,, PC Mainframe PC Backbone Server TCP/IP DCS PLC Network
untitled
 Step Motor Device Driver Embedded System Lab. II Step Motor Step Motor Step Motor source Embedded System Lab. II 2 open loop, : : Pulse, 1 Pulse,, -, 1 +5%, step Step Motor (2),, Embedded System Lab. II
Step Motor Device Driver Embedded System Lab. II Step Motor Step Motor Step Motor source Embedded System Lab. II 2 open loop, : : Pulse, 1 Pulse,, -, 1 +5%, step Step Motor (2),, Embedded System Lab. II
SRC PLUS 제어기 MANUAL
 ,,,, DE FIN E I N T R E A L L O C E N D SU B E N D S U B M O TIO
,,,, DE FIN E I N T R E A L L O C E N D SU B E N D S U B M O TIO
Solaris Express Developer Edition
 Solaris Express Developer Edition : 2008 1 Solaris TM Express Developer Edition Solaris OS. Sun / Solaris, Java, Web 2.0,,. Developer Solaris Express Developer Edition System Requirements. 768MB. SPARC
Solaris Express Developer Edition : 2008 1 Solaris TM Express Developer Edition Solaris OS. Sun / Solaris, Java, Web 2.0,,. Developer Solaris Express Developer Edition System Requirements. 768MB. SPARC
fprintf(fp, "clf; clear; clc; \n"); fprintf(fp, "x = linspace(0, %d, %d)\n ", L, N); fprintf(fp, "U = [ "); for (i = 0; i <= (N - 1) ; i++) for (j = 0
; fprintf(fp, x = linspace(0, %d, %d)\n , L, N); fprintf(fp, U = [ ); for (i = 0; i <= (N - 1) ; i++) for (j = 0") 병렬계산을이용한열방정식풀기. 1. 처음 병렬계산을하기전에 C 언어를이용하여명시적유한차분법으로하나의열방정식을풀어본 다. 먼저 C 로열방정식을이해한다음초기조건만다르게하여클러스터로여러개의열방 정식을풀어보자. 2. C 를이용한명시적유한차분법으로열방적식풀기 열방정식을풀기위한자세한이론은앞서다룬 Finite-Difference method 을보기로하고 바로식 (1.10)
병렬계산을이용한열방정식풀기. 1. 처음 병렬계산을하기전에 C 언어를이용하여명시적유한차분법으로하나의열방정식을풀어본 다. 먼저 C 로열방정식을이해한다음초기조건만다르게하여클러스터로여러개의열방 정식을풀어보자. 2. C 를이용한명시적유한차분법으로열방적식풀기 열방정식을풀기위한자세한이론은앞서다룬 Finite-Difference method 을보기로하고 바로식 (1.10)
PowerPoint 프레젠테이션
 BOOTLOADER Jo, Heeseung 부트로더컴파일 부트로더소스복사및압축해제 부트로더소스는웹페이지에서다운로드 /working 디렉터리로이동한후, wget으로다운로드 이후작업은모두 /working 디렉터리에서진행 root@ubuntu:# cp /media/sm5-linux-111031/source/platform/uboot-s4210.tar.bz2 /working
BOOTLOADER Jo, Heeseung 부트로더컴파일 부트로더소스복사및압축해제 부트로더소스는웹페이지에서다운로드 /working 디렉터리로이동한후, wget으로다운로드 이후작업은모두 /working 디렉터리에서진행 root@ubuntu:# cp /media/sm5-linux-111031/source/platform/uboot-s4210.tar.bz2 /working
untitled
 Push... 2 Push... 4 Push... 5 Push... 13 Push... 15 1 FORCS Co., LTD A Leader of Enterprise e-business Solution Push (Daemon ), Push Push Observer. Push., Observer. Session. Thread Thread. Observer ID.
Push... 2 Push... 4 Push... 5 Push... 13 Push... 15 1 FORCS Co., LTD A Leader of Enterprise e-business Solution Push (Daemon ), Push Push Observer. Push., Observer. Session. Thread Thread. Observer ID.
<4D F736F F F696E74202D20B8B6C0CCC5A9B7CEC7C1B7CEBCBCBCAD202839C1D6C2F7207E203135C1D6C2F >
 10주차 문자 LCD 의인터페이스회로및구동함수 Next-Generation Networks Lab. 5. 16x2 CLCD 모듈 (HY-1602H-803) 그림 11-18 19 핀설명표 11-11 번호 분류 핀이름 레벨 (V) 기능 1 V SS or GND 0 GND 전원 2 V Power DD or V CC +5 CLCD 구동전원 3 V 0 - CLCD 명암조절
10주차 문자 LCD 의인터페이스회로및구동함수 Next-Generation Networks Lab. 5. 16x2 CLCD 모듈 (HY-1602H-803) 그림 11-18 19 핀설명표 11-11 번호 분류 핀이름 레벨 (V) 기능 1 V SS or GND 0 GND 전원 2 V Power DD or V CC +5 CLCD 구동전원 3 V 0 - CLCD 명암조절
MPLAB C18 C
 MPLAB C18 C MPLAB C18 MPLAB C18 C MPLAB C18 C #define START, c:\mcc18 errorlevel{0 1} char isascii(char ch); list[list_optioin,list_option] OK, Cancel , MPLAB IDE User s Guide MPLAB C18 C
MPLAB C18 C MPLAB C18 MPLAB C18 C MPLAB C18 C #define START, c:\mcc18 errorlevel{0 1} char isascii(char ch); list[list_optioin,list_option] OK, Cancel , MPLAB IDE User s Guide MPLAB C18 C
목차 BUG offline replicator 에서유효하지않은로그를읽을경우비정상종료할수있다... 3 BUG 각 partition 이서로다른 tablespace 를가지고, column type 이 CLOB 이며, 해당 table 을 truncate
 ALTIBASE HDB 6.1.1.5.6 Patch Notes 목차 BUG-39240 offline replicator 에서유효하지않은로그를읽을경우비정상종료할수있다... 3 BUG-41443 각 partition 이서로다른 tablespace 를가지고, column type 이 CLOB 이며, 해당 table 을 truncate 한뒤, hash partition
ALTIBASE HDB 6.1.1.5.6 Patch Notes 목차 BUG-39240 offline replicator 에서유효하지않은로그를읽을경우비정상종료할수있다... 3 BUG-41443 각 partition 이서로다른 tablespace 를가지고, column type 이 CLOB 이며, 해당 table 을 truncate 한뒤, hash partition
PowerPoint 프레젠테이션
 Network Programming Jo, Heeseung Network 실습 네트워크프로그래밍 멀리떨어져있는호스트들이서로데이터를주고받을수있도록프로그램을구현하는것 파일과는달리데이터를주고받을대상이멀리떨어져있기때문에소프트웨어차원에서호스트들간에연결을해주는장치가필요 이러한기능을해주는장치로소켓이라는인터페이스를많이사용 소켓프로그래밍이란용어와네트워크프로그래밍이랑용어가같은의미로사용
Network Programming Jo, Heeseung Network 실습 네트워크프로그래밍 멀리떨어져있는호스트들이서로데이터를주고받을수있도록프로그램을구현하는것 파일과는달리데이터를주고받을대상이멀리떨어져있기때문에소프트웨어차원에서호스트들간에연결을해주는장치가필요 이러한기능을해주는장치로소켓이라는인터페이스를많이사용 소켓프로그래밍이란용어와네트워크프로그래밍이랑용어가같은의미로사용
 OPCTalk for Hitachi Ethernet 1 2. Path. DCOMwindow NT/2000 network server. Winsock update win95. . . 3 Excel CSV. Update Background Thread Client Command Queue Size Client Dynamic Scan Block Block
OPCTalk for Hitachi Ethernet 1 2. Path. DCOMwindow NT/2000 network server. Winsock update win95. . . 3 Excel CSV. Update Background Thread Client Command Queue Size Client Dynamic Scan Block Block
02 C h a p t e r Java
 02 C h a p t e r Java Bioinformatics in J a va,, 2 1,,,, C++, Python, (Java),,, (http://wwwbiojavaorg),, 13, 3D GUI,,, (Java programming language) (Sun Microsystems) 1995 1990 (green project) TV 22 CHAPTER
02 C h a p t e r Java Bioinformatics in J a va,, 2 1,,,, C++, Python, (Java),,, (http://wwwbiojavaorg),, 13, 3D GUI,,, (Java programming language) (Sun Microsystems) 1995 1990 (green project) TV 22 CHAPTER
28 THE ASIAN JOURNAL OF TEX [2] ko.tex [5]
![28 THE ASIAN JOURNAL OF TEX [2] ko.tex [5]](/thumbs/91/105270926.jpg "28 THE ASIAN JOURNAL OF TEX [2] ko.tex [5]") The Asian Journal of TEX, Volume 3, No. 1, June 2009 Article revision 2009/5/7 KTS THE KOREAN TEX SOCIETY SINCE 2007 2008 ko.tex Installing TEX Live 2008 and ko.tex under Ubuntu Linux Kihwang Lee * kihwang.lee@ktug.or.kr
The Asian Journal of TEX, Volume 3, No. 1, June 2009 Article revision 2009/5/7 KTS THE KOREAN TEX SOCIETY SINCE 2007 2008 ko.tex Installing TEX Live 2008 and ko.tex under Ubuntu Linux Kihwang Lee * kihwang.lee@ktug.or.kr
MySQL-Ch10
 10 Chapter.,,.,, MySQL. MySQL mysqld MySQL.,. MySQL. MySQL....,.,..,,.,. UNIX, MySQL. mysqladm mysqlgrp. MySQL 608 MySQL(2/e) Chapter 10 MySQL. 10.1 (,, ). UNIX MySQL, /usr/local/mysql/var, /usr/local/mysql/data,
10 Chapter.,,.,, MySQL. MySQL mysqld MySQL.,. MySQL. MySQL....,.,..,,.,. UNIX, MySQL. mysqladm mysqlgrp. MySQL 608 MySQL(2/e) Chapter 10 MySQL. 10.1 (,, ). UNIX MySQL, /usr/local/mysql/var, /usr/local/mysql/data,
Orcad Capture 9.x
 OrCAD Capture Workbook (Ver 10.xx) 0 Capture 1 2 3 Capture for window 4.opj ( OrCAD Project file) Design file Programe link file..dsn (OrCAD Design file) Design file..olb (OrCAD Library file) file..upd
OrCAD Capture Workbook (Ver 10.xx) 0 Capture 1 2 3 Capture for window 4.opj ( OrCAD Project file) Design file Programe link file..dsn (OrCAD Design file) Design file..olb (OrCAD Library file) file..upd
PRO1_04E [읽기 전용]
![PRO1_04E [읽기 전용]](/thumbs/91/104875613.jpg "PRO1_04E [읽기 전용]") Siemens AG 1999 All rights reserved File: PRO1_04E1 Information and S7-300 2 S7-400 3 EPROM / 4 5 6 HW Config 7 8 9 CPU 10 CPU : 11 CPU : 12 CPU : 13 CPU : / 14 CPU : 15 CPU : / 16 HW 17 HW PG 18 SIMATIC
Siemens AG 1999 All rights reserved File: PRO1_04E1 Information and S7-300 2 S7-400 3 EPROM / 4 5 6 HW Config 7 8 9 CPU 10 CPU : 11 CPU : 12 CPU : 13 CPU : / 14 CPU : 15 CPU : / 16 HW 17 HW PG 18 SIMATIC
목차 1. 제품 소개... 4 1.1 특징... 4 1.2 개요... 4 1.3 Function table... 5 2. 기능 소개... 6 2.1 Copy... 6 2.2 Compare... 6 2.3 Copy & Compare... 6 2.4 Erase... 6 2
 유영테크닉스( 주) 사용자 설명서 HDD014/034 IDE & SATA Hard Drive Duplicator 유 영 테 크 닉 스 ( 주) (032)670-7880 www.yooyoung-tech.com 목차 1. 제품 소개... 4 1.1 특징... 4 1.2 개요... 4 1.3 Function table... 5 2. 기능 소개... 6 2.1 Copy...
유영테크닉스( 주) 사용자 설명서 HDD014/034 IDE & SATA Hard Drive Duplicator 유 영 테 크 닉 스 ( 주) (032)670-7880 www.yooyoung-tech.com 목차 1. 제품 소개... 4 1.1 특징... 4 1.2 개요... 4 1.3 Function table... 5 2. 기능 소개... 6 2.1 Copy...
untitled
 Embedded System Lab. II Embedded System Lab. II 2 RTOS Hard Real-Time vs Soft Real-Time RTOS Real-Time, Real-Time RTOS General purpose system OS H/W RTOS H/W task Hard Real-Time Real-Time System, Hard
Embedded System Lab. II Embedded System Lab. II 2 RTOS Hard Real-Time vs Soft Real-Time RTOS Real-Time, Real-Time RTOS General purpose system OS H/W RTOS H/W task Hard Real-Time Real-Time System, Hard
Mango220 Android How to compile and Transfer image to Target
 Mango220 Android How to compile and Transfer image to Target http://www.mangoboard.com/ http://cafe.naver.com/embeddedcrazyboys Crazy Embedded Laboratory www.mangoboard.com cafe.naver.com/embeddedcrazyboys
Mango220 Android How to compile and Transfer image to Target http://www.mangoboard.com/ http://cafe.naver.com/embeddedcrazyboys Crazy Embedded Laboratory www.mangoboard.com cafe.naver.com/embeddedcrazyboys
C++-¿Ïº®Çؼ³10Àå
 C C++. (preprocessor directives), C C++ C/C++... C++, C. C++ C. C C++. C,, C++, C++., C++.,.. #define #elif #else #error #if #itdef #ifndef #include #line #pragma #undef #.,.,. #include #include
C C++. (preprocessor directives), C C++ C/C++... C++, C. C++ C. C C++. C,, C++, C++., C++.,.. #define #elif #else #error #if #itdef #ifndef #include #line #pragma #undef #.,.,. #include #include
휠세미나3 ver0.4
 andromeda@sparcs:/$ ls -al dev/sda* brw-rw---- 1 root disk 8, 0 2014-06-09 18:43 dev/sda brw-rw---- 1 root disk 8, 1 2014-06-09 18:43 dev/sda1 brw-rw---- 1 root disk 8, 2 2014-06-09 18:43 dev/sda2 andromeda@sparcs:/$
andromeda@sparcs:/$ ls -al dev/sda* brw-rw---- 1 root disk 8, 0 2014-06-09 18:43 dev/sda brw-rw---- 1 root disk 8, 1 2014-06-09 18:43 dev/sda1 brw-rw---- 1 root disk 8, 2 2014-06-09 18:43 dev/sda2 andromeda@sparcs:/$
 61 62 63 64 234 235 p r i n t f ( % 5 d :, i+1); g e t s ( s t u d e n t _ n a m e [ i ] ) ; if (student_name[i][0] == \ 0 ) i = MAX; p r i n t f (\ n :\ n ); 6 1 for (i = 0; student_name[i][0]!= \ 0&&
61 62 63 64 234 235 p r i n t f ( % 5 d :, i+1); g e t s ( s t u d e n t _ n a m e [ i ] ) ; if (student_name[i][0] == \ 0 ) i = MAX; p r i n t f (\ n :\ n ); 6 1 for (i = 0; student_name[i][0]!= \ 0&&
Microsoft PowerPoint - [2009] 02.pptx
![Microsoft PowerPoint - [2009] 02.pptx](/thumbs/86/93202615.jpg "Microsoft PowerPoint - [2009] 02.pptx") 원시데이터유형과연산 원시데이터유형과연산 원시데이터유형과연산 숫자데이터유형 - 숫자데이터유형 원시데이터유형과연산 표준입출력함수 - printf 문 가장기본적인출력함수. (stdio.h) 문법 ) printf( Test printf. a = %d \n, a); printf( %d, %f, %c \n, a, b, c); #include #include
원시데이터유형과연산 원시데이터유형과연산 원시데이터유형과연산 숫자데이터유형 - 숫자데이터유형 원시데이터유형과연산 표준입출력함수 - printf 문 가장기본적인출력함수. (stdio.h) 문법 ) printf( Test printf. a = %d \n, a); printf( %d, %f, %c \n, a, b, c); #include #include
Microsoft PowerPoint - eSlim SV5-2510 [080116]
![Microsoft PowerPoint - eSlim SV5-2510 [080116]](/thumbs/39/20150967.jpg "Microsoft PowerPoint - eSlim SV5-2510 [080116]") Innovation for Total Solution Provider!! eslim SV5-2510 Opteron Server 2008. 03 ESLIM KOREA INC. 1. 제 품 개 요 eslim SV5-2510 Server Quad-Core and Dual-Core Opteron 2000 Series 6 internal HDD bays for SAS
Innovation for Total Solution Provider!! eslim SV5-2510 Opteron Server 2008. 03 ESLIM KOREA INC. 1. 제 품 개 요 eslim SV5-2510 Server Quad-Core and Dual-Core Opteron 2000 Series 6 internal HDD bays for SAS
PowerPoint 프레젠테이션
 DEVELOPMENT ENVIRONMENT 2 MAKE Jo, Heeseung MAKE Definition make is utility to maintain groups of programs Object If some file is modified, make detects it and update files related with modified one 2
DEVELOPMENT ENVIRONMENT 2 MAKE Jo, Heeseung MAKE Definition make is utility to maintain groups of programs Object If some file is modified, make detects it and update files related with modified one 2
solution map_....
 SOLUTION BROCHURE RELIABLE STORAGE SOLUTIONS ETERNUS FOR RELIABILITY AND AVAILABILITY PROTECT YOUR DATA AND SUPPORT BUSINESS FLEXIBILITY WITH FUJITSU STORAGE SOLUTIONS kr.fujitsu.com INDEX 1. Storage System
SOLUTION BROCHURE RELIABLE STORAGE SOLUTIONS ETERNUS FOR RELIABILITY AND AVAILABILITY PROTECT YOUR DATA AND SUPPORT BUSINESS FLEXIBILITY WITH FUJITSU STORAGE SOLUTIONS kr.fujitsu.com INDEX 1. Storage System
PowerPoint 프레젠테이션
 Web server porting 2 Jo, Heeseung Web 을이용한 LED 제어 Web 을이용한 LED 제어프로그램 web 에서데이터를전송받아타겟보드의 LED 를조작하는프로그램을작성하기위해다음과같은소스파일을생성 2 Web 을이용한 LED 제어 LED 제어프로그램작성 8bitled.html 파일을작성 root@ubuntu:/working/web# vi
Web server porting 2 Jo, Heeseung Web 을이용한 LED 제어 Web 을이용한 LED 제어프로그램 web 에서데이터를전송받아타겟보드의 LED 를조작하는프로그램을작성하기위해다음과같은소스파일을생성 2 Web 을이용한 LED 제어 LED 제어프로그램작성 8bitled.html 파일을작성 root@ubuntu:/working/web# vi
Microsoft PowerPoint - comp_prac_081223_2.pptx
 Computer Programming Practice (2008 Winter) Practice 2 기본 Unix/Linux 명령어숙지 2008. 12. 23 Contents Linux commands Basic commands File and Directory User Data Filtering Process Etc Conclusion & Recommended
Computer Programming Practice (2008 Winter) Practice 2 기본 Unix/Linux 명령어숙지 2008. 12. 23 Contents Linux commands Basic commands File and Directory User Data Filtering Process Etc Conclusion & Recommended
(Asynchronous Mode) ( 1, 5~8, 1~2) & (Parity) 1 ; * S erial Port (BIOS INT 14H) - 1 -
 ( 1, 5~8, 1~2) & (Parity) 1 ; * S erial Port (BIOS INT 14H) - 1 -") (Asynchronous Mode) - - - ( 1, 5~8, 1~2) & (Parity) 1 ; * S erial Port (BIOS INT 14H) - 1 - UART (Univ ers al As y nchronous Receiver / T rans mitter) 8250A 8250A { COM1(3F8H). - Line Control Register
(Asynchronous Mode) - - - ( 1, 5~8, 1~2) & (Parity) 1 ; * S erial Port (BIOS INT 14H) - 1 - UART (Univ ers al As y nchronous Receiver / T rans mitter) 8250A 8250A { COM1(3F8H). - Line Control Register
LCD Display
 LCD Display SyncMaster 460DRn, 460DR VCR DVD DTV HDMI DVI to HDMI LAN USB (MDC: Multiple Display Control) PC. PC RS-232C. PC (Serial port) (Serial port) RS-232C.. > > Multiple Display
LCD Display SyncMaster 460DRn, 460DR VCR DVD DTV HDMI DVI to HDMI LAN USB (MDC: Multiple Display Control) PC. PC RS-232C. PC (Serial port) (Serial port) RS-232C.. > > Multiple Display
Windows Embedded Compact 2013 [그림 1]은 Windows CE 로 알려진 Microsoft의 Windows Embedded Compact OS의 history를 보여주고 있다. [표 1] 은 각 Windows CE 버전들의 주요 특징들을 담고
![Windows Embedded Compact 2013 [그림 1]은 Windows CE 로 알려진 Microsoft의 Windows Embedded Compact OS의 history를 보여주고 있다. [표 1] 은 각 Windows CE 버전들의 주요 특징들을 담고](/thumbs/39/20150982.jpg "Windows Embedded Compact 2013 [그림 1]은 Windows CE 로 알려진 Microsoft의 Windows Embedded Compact OS의 history를 보여주고 있다. [표 1] 은 각 Windows CE 버전들의 주요 특징들을 담고") OT S / SOFTWARE 임베디드 시스템에 최적화된 Windows Embedded Compact 2013 MDS테크놀로지 / ES사업부 SE팀 김재형 부장 / jaei@mdstec.com 또 다른 산업혁명이 도래한 시점에 아직도 자신을 떳떳이 드러내지 못하고 있는 Windows Embedded Compact를 오랫동안 지켜보면서, 필자는 여기서 그와 관련된
OT S / SOFTWARE 임베디드 시스템에 최적화된 Windows Embedded Compact 2013 MDS테크놀로지 / ES사업부 SE팀 김재형 부장 / jaei@mdstec.com 또 다른 산업혁명이 도래한 시점에 아직도 자신을 떳떳이 드러내지 못하고 있는 Windows Embedded Compact를 오랫동안 지켜보면서, 필자는 여기서 그와 관련된
PowerPoint Presentation
 Data Protection Rapid Recovery x86 DR Agent based Backup - Physical Machine - Virtual Machine - Cluster Agentless Backup - VMware ESXi Deploy Agents - Windows - AD, ESXi Restore Machine - Live Recovery
Data Protection Rapid Recovery x86 DR Agent based Backup - Physical Machine - Virtual Machine - Cluster Agentless Backup - VMware ESXi Deploy Agents - Windows - AD, ESXi Restore Machine - Live Recovery
K&R2 Reference Manual 번역본
 typewriter structunion struct union if-else if if else if if else if if if if else else ; auto register static extern typedef void char short int long float double signed unsigned const volatile { } struct
typewriter structunion struct union if-else if if else if if else if if if if else else ; auto register static extern typedef void char short int long float double signed unsigned const volatile { } struct
/chroot/lib/ /chroot/etc/
 구축 환경 VirtualBox - Fedora 15 (kernel : 2.6.40.4-5.fc15.i686.PAE) 작동 원리 chroot유저 ssh 접속 -> 접속유저의 홈디렉토리 밑.ssh의 rc 파일 실행 -> daemonstart실행 -> daemon 작동 -> 접속 유저만의 Jail 디렉토리 생성 -> 접속 유저의.bashrc 의 chroot 명령어
구축 환경 VirtualBox - Fedora 15 (kernel : 2.6.40.4-5.fc15.i686.PAE) 작동 원리 chroot유저 ssh 접속 -> 접속유저의 홈디렉토리 밑.ssh의 rc 파일 실행 -> daemonstart실행 -> daemon 작동 -> 접속 유저만의 Jail 디렉토리 생성 -> 접속 유저의.bashrc 의 chroot 명령어
Microsoft PowerPoint - ch09 - 연결형리스트, Stack, Queue와 응용 pm0100
 2015-1 프로그래밍언어 9. 연결형리스트, Stack, Queue 2015 년 5 월 4 일 교수김영탁 영남대학교공과대학정보통신공학과 (Tel : +82-53-810-2497; Fax : +82-53-810-4742 http://antl.yu.ac.kr/; E-mail : ytkim@yu.ac.kr) 연결리스트 (Linked List) 연결리스트연산 Stack
2015-1 프로그래밍언어 9. 연결형리스트, Stack, Queue 2015 년 5 월 4 일 교수김영탁 영남대학교공과대학정보통신공학과 (Tel : +82-53-810-2497; Fax : +82-53-810-4742 http://antl.yu.ac.kr/; E-mail : ytkim@yu.ac.kr) 연결리스트 (Linked List) 연결리스트연산 Stack
LAMMPS-11Aug17 설치 문서
 LAMMPS (Large-scale Atomic/Molecular Massively Parallel Simulator) 설치문서 모아시스 이상윤 페이지 1 / 13 목차 1. overview... 3 2. 소스코드다운로드... 3 3. 설치환경... 4 4. 사전설치... 5 4.1. voro++ 설치... 5 5. 라이브러리패키지설치... 6 5.1. voronoi
LAMMPS (Large-scale Atomic/Molecular Massively Parallel Simulator) 설치문서 모아시스 이상윤 페이지 1 / 13 목차 1. overview... 3 2. 소스코드다운로드... 3 3. 설치환경... 4 4. 사전설치... 5 4.1. voro++ 설치... 5 5. 라이브러리패키지설치... 6 5.1. voronoi
프로그램을 학교 등지에서 조금이라도 배운 사람들을 위한 프로그래밍 노트 입니다. 저 역시 그 사람들 중 하나 입니다. 중고등학교 시절 학교 도서관, 새로 생긴 시립 도서관 등을 다니며 책을 보 고 정리하며 어느정도 독학으르 공부하긴 했지만, 자주 안하다 보면 금방 잊어
 개나리 연구소 C 언어 노트 (tyback.egloos.com) 프로그램을 학교 등지에서 조금이라도 배운 사람들을 위한 프로그래밍 노트 입니다. 저 역시 그 사람들 중 하나 입니다. 중고등학교 시절 학교 도서관, 새로 생긴 시립 도서관 등을 다니며 책을 보 고 정리하며 어느정도 독학으르 공부하긴 했지만, 자주 안하다 보면 금방 잊어먹고 하더라구요. 그래서,
개나리 연구소 C 언어 노트 (tyback.egloos.com) 프로그램을 학교 등지에서 조금이라도 배운 사람들을 위한 프로그래밍 노트 입니다. 저 역시 그 사람들 중 하나 입니다. 중고등학교 시절 학교 도서관, 새로 생긴 시립 도서관 등을 다니며 책을 보 고 정리하며 어느정도 독학으르 공부하긴 했지만, 자주 안하다 보면 금방 잊어먹고 하더라구요. 그래서,
Chap7.PDF
 Chapter 7 The SUN Intranet Data Warehouse: Architecture and Tools All rights reserved 1 Intranet Data Warehouse : Distributed Networking Computing Peer-to-peer Peer-to-peer:,. C/S Microsoft ActiveX DCOM(Distributed
Chapter 7 The SUN Intranet Data Warehouse: Architecture and Tools All rights reserved 1 Intranet Data Warehouse : Distributed Networking Computing Peer-to-peer Peer-to-peer:,. C/S Microsoft ActiveX DCOM(Distributed
ORANGE FOR ORACLE V4.0 INSTALLATION GUIDE (Online Upgrade) ORANGE CONFIGURATION ADMIN O
 ORANGE CONFIGURATION ADMIN O") Orange for ORACLE V4.0 Installation Guide ORANGE FOR ORACLE V4.0 INSTALLATION GUIDE...1 1....2 1.1...2 1.2...2 1.2.1...2 1.2.2 (Online Upgrade)...11 1.3 ORANGE CONFIGURATION ADMIN...12 1.3.1 Orange Configuration
Orange for ORACLE V4.0 Installation Guide ORANGE FOR ORACLE V4.0 INSTALLATION GUIDE...1 1....2 1.1...2 1.2...2 1.2.1...2 1.2.2 (Online Upgrade)...11 1.3 ORANGE CONFIGURATION ADMIN...12 1.3.1 Orange Configuration
PRO1_02E [읽기 전용]
![PRO1_02E [읽기 전용]](/thumbs/90/102160748.jpg "PRO1_02E [읽기 전용]") Siemens AG 1999 All rights reserved File: PRO1_02E1 Information and 2 STEP 7 3 4 5 6 STEP 7 7 / 8 9 10 S7 11 IS7 12 STEP 7 13 STEP 7 14 15 : 16 : S7 17 : S7 18 : CPU 19 1 OB1 FB21 I10 I11 Q40 Siemens AG
Siemens AG 1999 All rights reserved File: PRO1_02E1 Information and 2 STEP 7 3 4 5 6 STEP 7 7 / 8 9 10 S7 11 IS7 12 STEP 7 13 STEP 7 14 15 : 16 : S7 17 : S7 18 : CPU 19 1 OB1 FB21 I10 I11 Q40 Siemens AG
Microsoft PowerPoint - chap01-C언어개요.pptx
 #include int main(void) { int num; printf( Please enter an integer: "); scanf("%d", &num); if ( num < 0 ) printf("is negative.\n"); printf("num = %d\n", num); return 0; } 1 학습목표 프로그래밍의 기본 개념을
#include int main(void) { int num; printf( Please enter an integer: "); scanf("%d", &num); if ( num < 0 ) printf("is negative.\n"); printf("num = %d\n", num); return 0; } 1 학습목표 프로그래밍의 기본 개념을
BMP 파일 처리
 BMP 파일처리 김성영교수 금오공과대학교 컴퓨터공학과 학습내용 영상반전프로그램제작 2 Inverting images out = 255 - in 3 /* 이프로그램은 8bit gray-scale 영상을입력으로사용하여반전한후동일포맷의영상으로저장한다. */ #include #include #define WIDTHBYTES(bytes)
BMP 파일처리 김성영교수 금오공과대학교 컴퓨터공학과 학습내용 영상반전프로그램제작 2 Inverting images out = 255 - in 3 /* 이프로그램은 8bit gray-scale 영상을입력으로사용하여반전한후동일포맷의영상으로저장한다. */ #include #include #define WIDTHBYTES(bytes)
DocsPin_Korean.pages
 Unity Localize Script Service, Page 1 Unity Localize Script Service Introduction Application Game. Unity. Google Drive Unity.. Application Game. -? ( ) -? -?.. 준비사항 Google Drive. Google Drive.,.. - Google
Unity Localize Script Service, Page 1 Unity Localize Script Service Introduction Application Game. Unity. Google Drive Unity.. Application Game. -? ( ) -? -?.. 준비사항 Google Drive. Google Drive.,.. - Google
PowerPoint 프레젠테이션
 Development Environment 2 Jo, Heeseung make make Definition make is utility to maintain groups of programs Object If some file is modified, make detects it and update files related with modified one It
Development Environment 2 Jo, Heeseung make make Definition make is utility to maintain groups of programs Object If some file is modified, make detects it and update files related with modified one It
Oracle9i Real Application Clusters
 Senior Sales Consultant Oracle Corporation Oracle9i Real Application Clusters Agenda? ? (interconnect) (clusterware) Oracle9i Real Application Clusters computing is a breakthrough technology. The ability
Senior Sales Consultant Oracle Corporation Oracle9i Real Application Clusters Agenda? ? (interconnect) (clusterware) Oracle9i Real Application Clusters computing is a breakthrough technology. The ability
vi 사용법
 유닉스프로그래밍및실습 gdb 사용법 fprintf 이용 단순디버깅 확인하고자하는코드부분에 fprintf(stderr, ) 를이용하여그지점까지도달했는지여부와관심있는변수의값을확인 여러유형의단순한문제를확인할수있음 그러나자세히살펴보기위해서는디버깅툴필요 int main(void) { int count; long large_no; double real_no; init_vars();
유닉스프로그래밍및실습 gdb 사용법 fprintf 이용 단순디버깅 확인하고자하는코드부분에 fprintf(stderr, ) 를이용하여그지점까지도달했는지여부와관심있는변수의값을확인 여러유형의단순한문제를확인할수있음 그러나자세히살펴보기위해서는디버깅툴필요 int main(void) { int count; long large_no; double real_no; init_vars();
초보자를 위한 C++
 C++. 24,,,,, C++ C++.,..,., ( ). /. ( 4 ) ( ).. C++., C++ C++. C++., 24 C++. C? C++ C C, C++ (Stroustrup) C++, C C++. C. C 24.,. C. C+ +?. X C++.. COBOL COBOL COBOL., C++. Java C# C++, C++. C++. Java C#
C++. 24,,,,, C++ C++.,..,., ( ). /. ( 4 ) ( ).. C++., C++ C++. C++., 24 C++. C? C++ C C, C++ (Stroustrup) C++, C C++. C. C 24.,. C. C+ +?. X C++.. COBOL COBOL COBOL., C++. Java C# C++, C++. C++. Java C#
Poison null byte Excuse the ads! We need some help to keep our site up. List 1 Conditions 2 Exploit plan 2.1 chunksize(p)!= prev_size (next_chunk(p) 3
!= prev_size (next_chunk(p) 3") Poison null byte Excuse the ads! We need some help to keep our site up. List 1 Conditions 2 Exploit plan 2.1 chunksize(p)!= prev_size (next_chunk(p) 3 Example 3.1 Files 3.2 Source code 3.3 Exploit flow
Poison null byte Excuse the ads! We need some help to keep our site up. List 1 Conditions 2 Exploit plan 2.1 chunksize(p)!= prev_size (next_chunk(p) 3 Example 3.1 Files 3.2 Source code 3.3 Exploit flow
Backup Exec
 (sjin.kim@veritas.com) www.veritas veritas.co..co.kr ? 24 X 7 X 365 Global Data Access.. 100% Storage Used Terabytes 9 8 7 6 5 4 3 2 1 0 2000 2001 2002 2003 IDC (TB) 93%. 199693,000 TB 2000831,000 TB.
(sjin.kim@veritas.com) www.veritas veritas.co..co.kr ? 24 X 7 X 365 Global Data Access.. 100% Storage Used Terabytes 9 8 7 6 5 4 3 2 1 0 2000 2001 2002 2003 IDC (TB) 93%. 199693,000 TB 2000831,000 TB.
김기남_ATDC2016_160620_[키노트].key
![김기남_ATDC2016_160620_[키노트].key](/thumbs/85/91488855.jpg "김기남_ATDC2016_160620_[키노트].key") metatron Enterprise Big Data SKT Metatron/Big Data Big Data Big Data... metatron Ready to Enterprise Big Data Big Data Big Data Big Data?? Data Raw. CRM SCM MES TCO Data & Store & Processing Computational
metatron Enterprise Big Data SKT Metatron/Big Data Big Data Big Data... metatron Ready to Enterprise Big Data Big Data Big Data Big Data?? Data Raw. CRM SCM MES TCO Data & Store & Processing Computational
13주-14주proc.PDF
 12 : Pro*C/C++ 1 2 Embeded SQL 3 PRO *C 31 C/C++ PRO *C NOT! NOT AND && AND OR OR EQUAL == = SQL,,, Embeded SQL SQL 32 Pro*C C SQL Pro*C C, C Pro*C, C C 321, C char : char[n] : n int, short, long : float
12 : Pro*C/C++ 1 2 Embeded SQL 3 PRO *C 31 C/C++ PRO *C NOT! NOT AND && AND OR OR EQUAL == = SQL,,, Embeded SQL SQL 32 Pro*C C SQL Pro*C C, C Pro*C, C C 321, C char : char[n] : n int, short, long : float
Microsoft Word - DELL_PowerEdge_TM_ R710 서버 성능분석보고서.doc
 DELL PowerEdge R710 Server 성능분석보고서 본자료는 클루닉스에서자사통합시뮬레이션시스템구성제품인 GridCenter를이용하여 Dell PowerEdge R710 서버의성능을분석한보고서입니다. 클루닉스와 DELL의협의없이발췌및배포를금합니다. BMT 환경 : GridCenter-CAP, GridCenter-HPC, CAE 어플리케이션 Abaqus,Fluent,Gaussian
DELL PowerEdge R710 Server 성능분석보고서 본자료는 클루닉스에서자사통합시뮬레이션시스템구성제품인 GridCenter를이용하여 Dell PowerEdge R710 서버의성능을분석한보고서입니다. 클루닉스와 DELL의협의없이발췌및배포를금합니다. BMT 환경 : GridCenter-CAP, GridCenter-HPC, CAE 어플리케이션 Abaqus,Fluent,Gaussian
T100MD+
 User s Manual 100% ) ( x b a a + 1 RX+ TX+ DTR GND TX+ RX+ DTR GND RX+ TX+ DTR GND DSR RX+ TX+ DTR GND DSR [ DCE TYPE ] [ DCE TYPE ] RS232 Format Baud 1 T100MD+
User s Manual 100% ) ( x b a a + 1 RX+ TX+ DTR GND TX+ RX+ DTR GND RX+ TX+ DTR GND DSR RX+ TX+ DTR GND DSR [ DCE TYPE ] [ DCE TYPE ] RS232 Format Baud 1 T100MD+
<목 차 > 제 1장 일반사항 4 I.사업의 개요 4 1.사업명 4 2.사업의 목적 4 3.입찰 방식 4 4.입찰 참가 자격 4 5.사업 및 계약 기간 5 6.추진 일정 6 7.사업 범위 및 내용 6 II.사업시행 주요 요건 8 1.사업시행 조건 8 2.계약보증 9 3
 열차운행정보 승무원 확인시스템 구축 제 안 요 청 서 2014.6. 제 1장 일반사항 4 I.사업의 개요 4 1.사업명 4 2.사업의 목적 4 3.입찰 방식 4 4.입찰 참가 자격 4 5.사업 및 계약 기간 5 6.추진 일정 6 7.사업 범위 및 내용 6 II.사업시행 주요 요건 8 1.사업시행 조건 8 2.계약보증 9 3.시운전 및 하자보증 10
열차운행정보 승무원 확인시스템 구축 제 안 요 청 서 2014.6. 제 1장 일반사항 4 I.사업의 개요 4 1.사업명 4 2.사업의 목적 4 3.입찰 방식 4 4.입찰 참가 자격 4 5.사업 및 계약 기간 5 6.추진 일정 6 7.사업 범위 및 내용 6 II.사업시행 주요 요건 8 1.사업시행 조건 8 2.계약보증 9 3.시운전 및 하자보증 10
다음 사항을 꼭 확인하세요! 도움말 안내 - 본 도움말에는 iodd2511 조작방법 및 활용법이 적혀 있습니다. - 본 제품 사용 전에 안전을 위한 주의사항 을 반드시 숙지하십시오. - 문제가 발생하면 문제해결 을 참조하십시오. 중요한 Data 는 항상 백업 하십시오.
 메 뉴 다음 사항을 꼭 확인하세요! --------------------------------- 2p 안전을 위한 주의 사항 --------------------------------- 3p 구성품 --------------------------------- 4p 각 부분의 명칭 --------------------------------- 5p 제품의 규격
메 뉴 다음 사항을 꼭 확인하세요! --------------------------------- 2p 안전을 위한 주의 사항 --------------------------------- 3p 구성품 --------------------------------- 4p 각 부분의 명칭 --------------------------------- 5p 제품의 규격
목차 BUG 문법에맞지않는질의문수행시, 에러메시지에질의문의일부만보여주는문제를수정합니다... 3 BUG ROUND, TRUNC 함수에서 DATE 포맷 IW 를추가지원합니다... 5 BUG ROLLUP/CUBE 절을포함하는질의는 SUBQUE
 ALTIBASE HDB 6.3.1.10.1 Patch Notes 목차 BUG-45710 문법에맞지않는질의문수행시, 에러메시지에질의문의일부만보여주는문제를수정합니다... 3 BUG-45730 ROUND, TRUNC 함수에서 DATE 포맷 IW 를추가지원합니다... 5 BUG-45760 ROLLUP/CUBE 절을포함하는질의는 SUBQUERY REMOVAL 변환을수행하지않도록수정합니다....
ALTIBASE HDB 6.3.1.10.1 Patch Notes 목차 BUG-45710 문법에맞지않는질의문수행시, 에러메시지에질의문의일부만보여주는문제를수정합니다... 3 BUG-45730 ROUND, TRUNC 함수에서 DATE 포맷 IW 를추가지원합니다... 5 BUG-45760 ROLLUP/CUBE 절을포함하는질의는 SUBQUERY REMOVAL 변환을수행하지않도록수정합니다....
PowerPoint 프레젠테이션
 @ Lesson 2... ( ). ( ). @ vs. logic data method variable behavior attribute method field Flow (Type), ( ) member @ () : C program Method A ( ) Method B ( ) Method C () program : Java, C++, C# data @ Program
@ Lesson 2... ( ). ( ). @ vs. logic data method variable behavior attribute method field Flow (Type), ( ) member @ () : C program Method A ( ) Method B ( ) Method C () program : Java, C++, C# data @ Program
<C0CCBCBCBFB52DC1A4B4EBBFF82DBCAEBBE7B3EDB9AE2D313939392D382E687770>
 i ii iii iv v vi 1 2 3 4 가상대학 시스템의 국내외 현황 조사 가상대학 플랫폼 개발 이상적인 가상대학시스템의 미래상 제안 5 웹-기반 가상대학 시스템 전통적인 교수 방법 시간/공간 제약을 극복한 학습동기 부여 교수의 일방적인 내용전달 교수와 학생간의 상호작용 동료 학생들 간의 상호작용 가상대학 운영 공지사항,강의록 자료실, 메모 질의응답,
i ii iii iv v vi 1 2 3 4 가상대학 시스템의 국내외 현황 조사 가상대학 플랫폼 개발 이상적인 가상대학시스템의 미래상 제안 5 웹-기반 가상대학 시스템 전통적인 교수 방법 시간/공간 제약을 극복한 학습동기 부여 교수의 일방적인 내용전달 교수와 학생간의 상호작용 동료 학생들 간의 상호작용 가상대학 운영 공지사항,강의록 자료실, 메모 질의응답,
PowerPoint 프레젠테이션
 주식회사미루웨어 deep learning 개발머쉰 미루웨어는 NVIDIA GPU Computing / GPU 가상화분야솔루션제공공식파트너사입니다. http://www.miruware.com / miruware@miruware.com T : 02-562-8993 / F : 02-562-8994 Deep Learning 개발환경 Unutu 장점 ( 개발머쉰 )
주식회사미루웨어 deep learning 개발머쉰 미루웨어는 NVIDIA GPU Computing / GPU 가상화분야솔루션제공공식파트너사입니다. http://www.miruware.com / miruware@miruware.com T : 02-562-8993 / F : 02-562-8994 Deep Learning 개발환경 Unutu 장점 ( 개발머쉰 )
Copyright 2012, Oracle and/or its affiliates. All rights reserved.,,,,,,,,,,,,,.,..., U.S. GOVERNMENT END USERS. Oracle programs, including any operat
 Sun Server X3-2( Sun Fire X4170 M3) Oracle Solaris : E35482 01 2012 9 Copyright 2012, Oracle and/or its affiliates. All rights reserved.,,,,,,,,,,,,,.,..., U.S. GOVERNMENT END USERS. Oracle programs, including
Sun Server X3-2( Sun Fire X4170 M3) Oracle Solaris : E35482 01 2012 9 Copyright 2012, Oracle and/or its affiliates. All rights reserved.,,,,,,,,,,,,,.,..., U.S. GOVERNMENT END USERS. Oracle programs, including
리뉴얼 xtremI 최종 softcopy
 SSD를 100% 이해한 CONTENTS SSD? 03 04 05 06 07 08 09 10 11 12 13 15 14 17 18 18 19 03 SSD SSD? Solid State Drive(SSD) NAND NAND DRAM SSD [ 1. SSD ] CPU( )RAM Cache Memory Firmware GB RAM Cache Memory Memory
SSD를 100% 이해한 CONTENTS SSD? 03 04 05 06 07 08 09 10 11 12 13 15 14 17 18 18 19 03 SSD SSD? Solid State Drive(SSD) NAND NAND DRAM SSD [ 1. SSD ] CPU( )RAM Cache Memory Firmware GB RAM Cache Memory Memory
LXR 설치 및 사용법.doc
 Installation of LXR (Linux Cross-Reference) for Source Code Reference Code Reference LXR : 2002512( ), : 1/1 1 3 2 LXR 3 21 LXR 3 22 LXR 221 LXR 3 222 LXR 3 3 23 LXR lxrconf 4 24 241 httpdconf 6 242 htaccess
Installation of LXR (Linux Cross-Reference) for Source Code Reference Code Reference LXR : 2002512( ), : 1/1 1 3 2 LXR 3 21 LXR 3 22 LXR 221 LXR 3 222 LXR 3 3 23 LXR lxrconf 4 24 241 httpdconf 6 242 htaccess
PowerPoint 프레젠테이션
 Deep Learning 작업환경조성 & 사용법 ISL 안재원 Ubuntu 설치 작업환경조성 접속방법 사용예시 2 - ISO file Download www.ubuntu.com Ubuntu 설치 3 - Make Booting USB Ubuntu 설치 http://www.pendrivelinux.com/universal-usb-installer-easy-as-1-2-3/
Deep Learning 작업환경조성 & 사용법 ISL 안재원 Ubuntu 설치 작업환경조성 접속방법 사용예시 2 - ISO file Download www.ubuntu.com Ubuntu 설치 3 - Make Booting USB Ubuntu 설치 http://www.pendrivelinux.com/universal-usb-installer-easy-as-1-2-3/
PowerChute Personal Edition v3.1.0 에이전트 사용 설명서
 PowerChute Personal Edition v3.1.0 990-3772D-019 4/2019 Schneider Electric IT Corporation Schneider Electric IT Corporation.. Schneider Electric IT Corporation,,,.,. Schneider Electric IT Corporation..
PowerChute Personal Edition v3.1.0 990-3772D-019 4/2019 Schneider Electric IT Corporation Schneider Electric IT Corporation.. Schneider Electric IT Corporation,,,.,. Schneider Electric IT Corporation..
슬라이드 1
 / 유닉스시스템개요 / 파일 / 프로세스 01 File Descriptor file file descriptor file type unix 에서의파일은단지바이트들의나열임 operating system 은파일에어떤포맷도부과하지않음 파일의내용은바이트단위로주소를줄수있음 file descriptor 는 0 이나양수임 file 은 open 이나 creat 로 file
/ 유닉스시스템개요 / 파일 / 프로세스 01 File Descriptor file file descriptor file type unix 에서의파일은단지바이트들의나열임 operating system 은파일에어떤포맷도부과하지않음 파일의내용은바이트단위로주소를줄수있음 file descriptor 는 0 이나양수임 file 은 open 이나 creat 로 file
4. #include <stdio.h> #include <stdlib.h> int main() { functiona(); } void functiona() { printf("hihi\n"); } warning: conflicting types for functiona
 { functiona(); } void functiona() { printf(hihi\n); } warning: conflicting types for functiona") 이름 : 학번 : A. True or False: 각각항목마다 True 인지 False 인지적으세요. 1. (Python:) randint 함수를사용하려면, random 모듈을 import 해야한다. 2. (Python:) '' (single quote) 는한글자를표현할때, (double quote) 는문자열을표현할때사용한다. B. 다음에러를수정하는방법을적으세요.
이름 : 학번 : A. True or False: 각각항목마다 True 인지 False 인지적으세요. 1. (Python:) randint 함수를사용하려면, random 모듈을 import 해야한다. 2. (Python:) '' (single quote) 는한글자를표현할때, (double quote) 는문자열을표현할때사용한다. B. 다음에러를수정하는방법을적으세요.
본문서는 초급자들을 대상으로 최대한 쉽게 작성하였습니다. 본문서에서는 설치방법만 기술했으며 자세한 설정방법은 검색을 통하시기 바랍니다. 1. 설치개요 워드프레스는 블로그 형태의 홈페이지를 빠르게 만들수 있게 해 주는 프로그램입니다. 다양한 기능을 하는 플러그인과 디자인
 스마일서브 CLOUD_Virtual 워드프레스 설치 (WORDPRESS INSTALL) 스마일서브 가상화사업본부 Update. 2012. 09. 04. 본문서는 초급자들을 대상으로 최대한 쉽게 작성하였습니다. 본문서에서는 설치방법만 기술했으며 자세한 설정방법은 검색을 통하시기 바랍니다. 1. 설치개요 워드프레스는 블로그 형태의 홈페이지를 빠르게 만들수 있게
스마일서브 CLOUD_Virtual 워드프레스 설치 (WORDPRESS INSTALL) 스마일서브 가상화사업본부 Update. 2012. 09. 04. 본문서는 초급자들을 대상으로 최대한 쉽게 작성하였습니다. 본문서에서는 설치방법만 기술했으며 자세한 설정방법은 검색을 통하시기 바랍니다. 1. 설치개요 워드프레스는 블로그 형태의 홈페이지를 빠르게 만들수 있게
11장 포인터
 Dynamic Memory and Linked List 1 동적할당메모리의개념 프로그램이메모리를할당받는방법 정적 (static) 동적 (dynamic) 정적메모리할당 프로그램이시작되기전에미리정해진크기의메모리를할당받는것 메모리의크기는프로그램이시작하기전에결정 int i, j; int buffer[80]; char name[] = data structure"; 처음에결정된크기보다더큰입력이들어온다면처리하지못함
Dynamic Memory and Linked List 1 동적할당메모리의개념 프로그램이메모리를할당받는방법 정적 (static) 동적 (dynamic) 정적메모리할당 프로그램이시작되기전에미리정해진크기의메모리를할당받는것 메모리의크기는프로그램이시작하기전에결정 int i, j; int buffer[80]; char name[] = data structure"; 처음에결정된크기보다더큰입력이들어온다면처리하지못함
untitled
 시스템소프트웨어 : 운영체제, 컴파일러, 어셈블러, 링커, 로더, 프로그래밍도구등 소프트웨어 응용소프트웨어 : 워드프로세서, 스프레드쉬트, 그래픽프로그램, 미디어재생기등 1 n ( x + x +... + ) 1 2 x n 00001111 10111111 01000101 11111000 00001111 10111111 01001101 11111000
시스템소프트웨어 : 운영체제, 컴파일러, 어셈블러, 링커, 로더, 프로그래밍도구등 소프트웨어 응용소프트웨어 : 워드프로세서, 스프레드쉬트, 그래픽프로그램, 미디어재생기등 1 n ( x + x +... + ) 1 2 x n 00001111 10111111 01000101 11111000 00001111 10111111 01001101 11111000
Oracle Database 10g: Self-Managing Database DB TSC
 Oracle Database 10g: Self-Managing Database DB TSC Agenda Overview System Resource Application & SQL Storage Space Backup & Recovery ½ Cost ? 6% 12 % 6% 6% 55% : IOUG 2001 DBA Survey ? 6% & 12 % 6% 6%
Oracle Database 10g: Self-Managing Database DB TSC Agenda Overview System Resource Application & SQL Storage Space Backup & Recovery ½ Cost ? 6% 12 % 6% 6% 55% : IOUG 2001 DBA Survey ? 6% & 12 % 6% 6%
01Àå
 CHAPTER 01 1 Fedora Fedora Linux Toolbox 2003 Fedora Core( ) http://fedoraproject.org www.redhat.com 2 CHAPTER Fedora RHEL GNU public license www.centos.org www.yellowdoglinux.com www. lineox.net www.
CHAPTER 01 1 Fedora Fedora Linux Toolbox 2003 Fedora Core( ) http://fedoraproject.org www.redhat.com 2 CHAPTER Fedora RHEL GNU public license www.centos.org www.yellowdoglinux.com www. lineox.net www.
<4D F736F F D20C5EBC7D5C7D8BCAEBDC3BDBAC5DB5F D2BC0C720424D54B0E1B0FABAB8B0EDBCAD2E646F63>
 통합해석시스템기반 STARCCM+ 의병렬계산성능 BMT 결과보고서 클루닉스 본자료는 클루닉스에서 CAE 해석 S/W(STARCCM+) 의병렬처리성능을측정한 BMT 결과보고서입니다. BMT 환경 : GridCenter-CAP, GridCenter-HPC BMT S/W : STARCCM+ BMT 진행 : 클루닉스 BMT 일자 : 2009년 08월 12일 ~2009년
통합해석시스템기반 STARCCM+ 의병렬계산성능 BMT 결과보고서 클루닉스 본자료는 클루닉스에서 CAE 해석 S/W(STARCCM+) 의병렬처리성능을측정한 BMT 결과보고서입니다. BMT 환경 : GridCenter-CAP, GridCenter-HPC BMT S/W : STARCCM+ BMT 진행 : 클루닉스 BMT 일자 : 2009년 08월 12일 ~2009년
Microsoft PowerPoint - chap13-입출력라이브러리.pptx
 #include int main(void) int num; printf( Please enter an integer: "); scanf("%d", &num); if ( num < 0 ) printf("is negative.\n"); printf("num = %d\n", num); return 0; 1 학습목표 스트림의 기본 개념을 알아보고,
#include int main(void) int num; printf( Please enter an integer: "); scanf("%d", &num); if ( num < 0 ) printf("is negative.\n"); printf("num = %d\n", num); return 0; 1 학습목표 스트림의 기본 개념을 알아보고,
10X56_NWG_KOR.indd
 디지털 프로젝터 X56 네트워크 가이드 이 제품을 구입해 주셔서 감사합니다. 본 설명서는 네트워크 기능 만을 설명하기 위한 것입니다. 본 제품을 올바르게 사 용하려면 이 취급절명저와 본 제품의 다른 취급절명저를 참조하시기 바랍니다. 중요한 주의사항 이 제품을 사용하기 전에 먼저 이 제품에 대한 모든 설명서를 잘 읽어 보십시오. 읽은 뒤에는 나중에 필요할 때
디지털 프로젝터 X56 네트워크 가이드 이 제품을 구입해 주셔서 감사합니다. 본 설명서는 네트워크 기능 만을 설명하기 위한 것입니다. 본 제품을 올바르게 사 용하려면 이 취급절명저와 본 제품의 다른 취급절명저를 참조하시기 바랍니다. 중요한 주의사항 이 제품을 사용하기 전에 먼저 이 제품에 대한 모든 설명서를 잘 읽어 보십시오. 읽은 뒤에는 나중에 필요할 때
Microsoft PowerPoint APUE(Intro).ppt
.ppt") 컴퓨터특강 () [Ch. 1 & Ch. 2] 2006 년봄학기 문양세강원대학교컴퓨터과학과 APUE 강의목적 UNIX 시스템프로그래밍 file, process, signal, network programming UNIX 시스템의체계적이해 시스템프로그래밍능력향상 Page 2 1 APUE 강의동기 UNIX 는인기있는운영체제 서버시스템 ( 웹서버, 데이터베이스서버
컴퓨터특강 () [Ch. 1 & Ch. 2] 2006 년봄학기 문양세강원대학교컴퓨터과학과 APUE 강의목적 UNIX 시스템프로그래밍 file, process, signal, network programming UNIX 시스템의체계적이해 시스템프로그래밍능력향상 Page 2 1 APUE 강의동기 UNIX 는인기있는운영체제 서버시스템 ( 웹서버, 데이터베이스서버
Microsoft PowerPoint - 알고리즘_1주차_2차시.pptx
 Chapter 2 Secondary Storage and System Software References: 1. M. J. Folk and B. Zoellick, File Structures, Addison-Wesley. 목차 Disks Storage as a Hierarchy Buffer Management Flash Memory 영남대학교데이터베이스연구실
Chapter 2 Secondary Storage and System Software References: 1. M. J. Folk and B. Zoellick, File Structures, Addison-Wesley. 목차 Disks Storage as a Hierarchy Buffer Management Flash Memory 영남대학교데이터베이스연구실
PowerPoint 프레젠테이션
 BASIC COMMANDS Jo, Heeseung ITER 서버 iterx.jbnu.ac.kr (X: 1,2) Dell PowerEdge R415 AMD Opteron(tm) Processor 4180-6 core x 2ea Memory: 32 GB HDD: SCSI 450 GB 주의사항 자료백업없음 동영상등의불필요파일업로드금지 2 LINUX 접속 Client
BASIC COMMANDS Jo, Heeseung ITER 서버 iterx.jbnu.ac.kr (X: 1,2) Dell PowerEdge R415 AMD Opteron(tm) Processor 4180-6 core x 2ea Memory: 32 GB HDD: SCSI 450 GB 주의사항 자료백업없음 동영상등의불필요파일업로드금지 2 LINUX 접속 Client
ePapyrus PDF Document
 프로그래밍 콘테스트 챌린징 for GCJ, TopCoder, ACM/ICPC, KOI/IOI 지은이 Takuya Akiba, Yoichi Iwata, Mastoshi Kitagawa 옮긴이 박건태, 김승엽 1판 1쇄 발행일 201 1년 10월 24일 펴낸이 장미경 펴낸곳 로드북 편집 임성춘 디자인 이호용(표지), 박진희(본문) 주소 서울시 관악구 신림동 1451-15
프로그래밍 콘테스트 챌린징 for GCJ, TopCoder, ACM/ICPC, KOI/IOI 지은이 Takuya Akiba, Yoichi Iwata, Mastoshi Kitagawa 옮긴이 박건태, 김승엽 1판 1쇄 발행일 201 1년 10월 24일 펴낸이 장미경 펴낸곳 로드북 편집 임성춘 디자인 이호용(표지), 박진희(본문) 주소 서울시 관악구 신림동 1451-15
슬라이드 제목 없음
 < > Target cross compiler Target code Target Software Development Kit (SDK) T-Appl T-Appl T-VM Cross downloader Cross debugger Case 1) Serial line Case 2) LAN line LAN line T-OS Target debugger Host System
< > Target cross compiler Target code Target Software Development Kit (SDK) T-Appl T-Appl T-VM Cross downloader Cross debugger Case 1) Serial line Case 2) LAN line LAN line T-OS Target debugger Host System
Remote UI Guide
 Remote UI KOR Remote UI Remote UI PDF Adobe Reader/Adobe Acrobat Reader. Adobe Reader/Adobe Acrobat Reader Adobe Systems Incorporated.. Canon. Remote UI GIF Adobe Systems Incorporated Photoshop. ..........................................................
Remote UI KOR Remote UI Remote UI PDF Adobe Reader/Adobe Acrobat Reader. Adobe Reader/Adobe Acrobat Reader Adobe Systems Incorporated.. Canon. Remote UI GIF Adobe Systems Incorporated Photoshop. ..........................................................