PowerPoint 프레젠테이션
|
|
|
- 현섭 염
- 5 years ago
- Views:
Transcription
1 Hadoop 2015
2 Content Introduction Big Data Hadoop Hadoop 기본개념 Hadoop Eco System Hadoop 설치 HDFS(Hadoop Distributed File System) Hadoop 2.0
3 Big Data 빅데이터의 3 대요소 : 크기 (Volume), 속도 (Velocity), 다양성 (Variety) Volume 수십terabyte ~ 수십petabyte 분산컴퓨팅기법으로데이터를저장, 분석해야함 솔루션 : 구글의 GFS, 아파치의하둡 Velocity 빠른속도로생성되는디지털데이터를처리하기위해실시간으로데이터를생산, 저장, 유통, 수집, 분석처리해야함 수집된대량의데이터를장기적이고전략적인차원에서접근하여분석해야함 데이터마이닝, 기게학습, 자연어처리, 패턴인식등을활용 Variety 정형 (Structured) 데이터 : 고정된필드에저장되는데이터 반정형 (Semi-structured) 데이터 : XML, HTML 같이메타데이터나스키마등을포함하는데이터 비정형 (Unstructed) 데이터 : 인터넷상에서발생하는 SNS 데이터, 동영상, 위치정보, 통화내용등 GFS: Google File System
4 Hadoop 하둡이란 대용량데이터를분산처리할수있는자바기반의오픈소스프레임워크 분산파일시스템인 HDFS(Hadoop Distributed Files System) 에데이터를저장하고분산처리시스템인맵리듀스를이용해데이터를처리 2005년에더그커팅 (Doug Cutting) 이구글이논문으로발표한 GFS(Google File System) 와 MapReduce를구현한결과물 데이터의복제본을저장하기때문에데이터의유실이나장애가발상했을때도데이터의복구가가능함 정형데이터 RDBMS 저장 (RDBMS 는라이선스비용이비쌈 ) RDBMS: 데이터가저장된서버에서데이터를처리 비정형데이터 ( 사이즈큼 ) Hadoop 저장 하둡 : 여러대의서버에데이터를저장하고, 데이터가저장된각서버에서동시에데이터를처리
5 Hadoop Q1. 하둡이 MS-SQL, Sybase, MySQL 같은 RDBMS 를대체한다? 하둡은기존 RDBMS를대체하지않음. 오히려 RDBMS와상호보완적인특성을갖음 하둡은 ETL과정에도움을줌 (ETL; Extraction, Transformation, Loading) ETL은자체적으로셸스크립트나 SQL문을이용해진행하거나, Data Stage같은상용솔루션을이용해진행 Text Transformation Text Extraction Loading RDBMS Data Warehouse Data Mart
6 Hadoop Q2. 하둡은 NoSQL? (RDBMS 가아니니까 NoSQL 이다?) 하둡은 SQL 언어를사용할수있음 (Hive 에서 HiveQL 이라는쿼리언어제공 ) NoSQL 관계형데이터모델과 SQL문을사용하지않는데이터베이스시스템혹은데이터저장소 단순히키와값의쌍으로만이뤄져있음 인덱스와데이터가분리되어별도로운영됨 조인이없음 데이터를하나의집합된형태로저장 Sharding : 데이터를분할해서다른서버에나누어저장 RDBMS 엔티티간의관계에중점을두고테이블구조를설계하는방식 데이터가여러행 (row) 으로존재함 핵심데이터관리 ( 데이터무결성과정합성제공 )








7 Hadoop
8 Hadoop Ecosystem - 비즈니스에효율적으로적용하기위한다양한서브프로젝트 데이터분석 (Pig, Hive) 데이터마이닝 (Mahout) 분산코디네이터 (Zookeeper) 워크플로우관리 (Oozie) 분산데이터베이스 (Hbase) 메타데이터관리 (Hcatalog) 분산데이터처리 (MapReduce) 직렬화 (Avro) 분산데이터저장 (HDFS) 비정형데이터수집 (Chukwa, Flume, Scribe) 정형데이터수집 (Sqoop, hiho)
9 Hadoop Ecosystem Zookeeper 분산환경에서서버간의산호조정이필요한다양한서비스를제공하는시스템 분산코디네이터 (Zookeeper) 1. 하나의서버에만서비스가집중되지않게서비스를알맞게분산해동시에처리하게해줌 2. 하나의서버에서처리한결과를다른서버와도동기화해서데이터의안정성을보장해줌 3. 운영 (active) 서버가문제가발생해서서비스를제공할수없을경우, 다른대기중인서버를 운영서버로바꿔서서비스가중지없기제공되게함 4. 분산환경을구성하는서버들의환경설정을통합적으로관리
10 Hadoop Ecosystem 워크플로우관리 (Oozie) 분산데이터베이스 (Hbase) Hbase HDFS 기반의칼럼기반데이터베이스 실시간랜덤조회및업데이트가능 각프로세스는개인의데이터를비동기적으로업데이트 단, 맵리듀스는일괄처리방식으로수행됨 트위터, 야후!, 어도비, 국내 NHN( 모바일메신저 Line) Oozie 하둡작업을관리하는워크플로우및코디네이터시스템 자바서블릿컨테이너에서실행되는자바웹애플리케이션서버 맵리듀스작업이나피그 ( 데이터분석 ) 작업같은특화된액션으로구성된워크플로우를제어
11 Hadoop Ecosystem Pig 야후! 에서개발, 현재아파치프로젝트에속함 복잡한맵리듀스프로그래밍을대체할 Pig Latin 이라는자체언어제공 맵리듀스 API를크게단순화함 SQL과유사한형태. 단, SQL 활용이어려운편임 Hive 데이터웨어하우징용솔루션 페이스북에서개발, 현재아파치프로젝트에속함 SQL과매우유사한 HiveQL 쿼리제공 ( 내부적으로맵리듀스잡으로변환되어실행됨 ) 자바를모르는데이터분석가들도쉽게하둡데이터를분석할수있게도와줌 짧은임시쿼리보다는일괄적인 MapReduce처리에이상적임 데이터분석 (Pig, Hive) Mahout 데이터마이닝 (Mahout) 하둡기반으로데이터마이닝알고리즘을구현하였음 분류 (Classification) 클러스터링 (Clustering) 추천및협업필터링 (Recommenders/Collaborative filtering) 패턴마이닝 (Pattern Mining) 회귀분석 (Regression) 차원리덕션 (Dimension reduction) 진화알고리즘 (Evolutionary Algorithms)
12 Hadoop Ecosystem Hcatalog 하둡으로생성한데이터를위한테이블및스토리지관리서비스 하둡에코시스템간의상호운용성향상에큰영향 Hcatalog의이용으로 Hive에서생성한테이블이나데이터모델을 Pig나맵리듀스에서손쉽게이용할수있음 ( 이전엔모델공유는가능했으나, 상당한백엔드작업이필요했었음 ) 메타데이터관리 (Hcatalog) 직렬화 (Avro) Avro RPC(Remote Procedure Call) 과데이터직렬화를지원 JSON을이용해데이터형식과프로토콜을정의 작고빠른바이너리포맷으로데이터를직렬화
13 Hadoop Ecosystem Chukwa 분산환경에서생성되는데이터를 HDFS에안정적으로저장하는플랫폼 ( 야후! 에서개발 ) 분산된각서버에서에이전트 (agent) 를실행하고, 콜렉터 (collector) 가에이전트로부터데이터를받아 HDFS에저장 콜렉터는 100개의에이전트당하나씩구동 데이터중복제거등작업은맵리듀스로처리 Flume Chukwa처럼분산된서버에에이전트가설치되고, 에이전트로부터데이터를전달받는콜렉터로구성 전체데이터의흐름을관리하는마스터서버가있음 즉, 데이터를어디서수집, 어떤방식으로전송, 어디에저장할지를동적으로변경할수있음 ( 클라우데라개발 ) Scribe 데이터수집플랫폼 ( 페이스북에서개발 ) 데이터를중앙집중서버로전송 최종데이터는 HDFS 외다양한저장소를활용할수있음 설치와구성이쉽도록다양한프로그래밍언어를지원 HDFS에데이터저장을위해 JNI(Java Native Interface) 이용해야함 Sqoop 대용량데이터전송솔루션 HDFS, RDBMS, DW, NoSQL 등다양한저장소에대용량데이터를신속하게전송할수있는방법제공 상용RDBMS도지원하고, MySQL, PostgreSQL 오픈소스 RDBMS도지원함 Hiho 대용량데이터전송솔루션 하둡에서데이터를가져오기위한 SQL을지정할수있음 JDBC 인터페이스지원 오라클과 MySQL의데이터전송만지원함 비정형데이터수집 (Chukwa, Flume, Scribe) 정형데이터수집 (Sqoop, hiho)
14 Hadoop 설치 Virtual Box에하둡설치 실습순서 Virtual Box 설치및설정 1개의가상머신을생성 : 호스트명 (hadoop01) Linux 설치 -> 하둡설치


15 Hadoop 설치 Virtual Box 설치 Virtual Box 설치 ( 다운로드 : 파일 : VirtualBox Win.exe [ 실행 ] 설치시유의사항 네트워크에문제가발생할경우 Virtual Box 를삭제한후 PC 를리부팅하고다시설치하세요. [Install] 과정에서다음과같은창이뜹니다. [v] 체크하세요
")
![-> [ 환경설정 ] -> 입력 -> 두번째 TAB [ 가상머신 (M)]](/docs-images/82/86154023/images/16-2.jpg "호스트키조합의단축키를 [ Ctrl + Alt ] 로변경후키보드 [ 아래화살표")
16 Hadoop 설치 Virtual Box 설정 가상머신윈도우에서쉽게빠져나올수있도록 [ 호스트키조합 ] 을설정 파일 (F) -> [ 환경설정 ] -> 입력 -> 두번째 TAB [ 가상머신 (M)] 호스트키조합의단축키를 [ Ctrl + Alt ] 로변경후키보드 [ 아래화살표 ] 누른후 [ 확인 ] Ctrl + Alt
17 Hadoop 설치 가상머신생성 가상머신생성 Virtual Box 어플리케이션에서 [ 새로만들기 ] 설치시유의사항 가상머신의이름과종류및버전 [ 이름 ] hadoop01 [NOTE] hadoop02, hadoop03 [ 종류 ] Linux [ 버전 ] Red Hat 또는 Red Hat(32비트 )[ 주의 ] Red Hat(64비트 ) 는선택하지마세요. [ 메모리크기 ] 권장 2GB / 최대 2.8GB [ 하드드라이브 ] - [ 하드드라이브종류 ] VDI» [ 동적 / 고정 ] 고정크기» [ 파일크기 ] 10GB

18 Hadoop 설치 가상머신설정 실습관련 Case 1 : 리눅스부터하둡설치까지직접설치 Case 2 : 리눅스와하둡이설치된 VDI 파일을사용 설정시유의사항 [ 네트워크 ] 두번째 TAB [ 어댑터2] [V] 네트워크어댑터사용하기체크연결 : 호스트전용어댑터
19 Hadoop 설치 리눅스설치 설치개요 CentOS 6.X 32비트설치 [NOTE] 64비트는설치안되는경우가많음 파티션설정이나사용자정의패키지설치는학습범위를벗어남 설치시유의사항 [ 호스트명 ] hadoop01 [ 네트워크설정 ] eth0, eth1 : [V] 자동으로연결선택 [root 비밀번호 ] hadoop [ 소프트웨어설치 ] Desktop 선택
20 Hadoop 설치 Linux 설치

21 Hadoop 설치 Linux 설치

22 Hadoop 설치 Linux 설치

23 Hadoop 설치 Linux 설치
24 Hadoop 설치 Hadoop 설치 설치개요 root 계정 : 네트워크설정 hadoop 계정생성 방화벽설정 JDK 설치 환경설정 저장디렉토리생성 hadoop 계정 : 하둡설치 하둡설정 HDFS 포멧 하둡서비스시작 / 중단 하둡서비스확인 ( 개인환경설정 )
25 Hadoop 설치 Hadoop 하둡설치 root 계정 네트워크설정 - IP 확인하기 ( 혹은 102, ) [root@hadoop01 ~]# ifconfig - 호스트설정 ( 기존에있는 2줄아래에추가 ) [root@hadoop01 ~]# vi /etc/hosts localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain hadoop01 - 방화벽중단하기 [root@hadoop01 ~]# ntsysv... [*] ip6tables -> [ ] ip6tables [*] iptables -> [ ] iptables... [root@hadoop01 ~]# iptables -F
26 Hadoop 설치 root 계정 ( 계속 ) 하둡계정추가 / JDK 설치 / 환경설정 - 리눅스하둡계정추가 ( 이미존재한다면넘어감 ) [root@hadoop01 ~]# adduser hadoop - JDK설치 - 다운로드 [root@hadoop01 ~]# cp./jdk-7u75-linux-i586.tar.gz /usr/local [root@hadoop01 ~]# cd /usr/local [root@hadoop01 local]# tar xvfz jdk-7u75-linux-i586.tar.gz [root@hadoop01 local]# ln -s jdk1.7.0_75 java -리눅스전역환경설정 [root@hadoop01 ~]# vim /etc/profile export JAVA_HOME=/usr/local/java export PATH=$PATH:$JAVA_HOME/bin export CLASSPATH=. export BASEHOME=/home/hadoop export HADOOP_HOME=$BASEHOME/hadoop [root@hadoop01 ~]# source /etc/profile - 확인하기 ( jps 앞에나오는 7786은프로세스 ID로계속달라짐 ) [root@hadoop01 ~]# javac version javac 1.8.0_31 [root@hadoop01 ~]# jps 7786 Jps
27 Hadoop 설치 계정 ( 계속 ) - 실제데이터저장디렉토리생성 [root@hadoop01 ~]# mkdir p /data/hadoop/tmp [root@hadoop01 ~]# mkdir p /data/hadoop/dfs/name [root@hadoop01 ~]# mkdir p /data/hadoop/dfs/data - /data/hadoop owner 변경 [root@hadoop01 ~]# chown R hadoop:hadoop /data/hadoop
28 Hadoop 설치 하둡설치 hadoop 계정 hadoop 계정으로작업 ~]# su - hadoop [hadoop@hadoop01 ~]$ SSH 설정 -.ssh 디렉토리만들기 ( 비밀번호입력하지말고그냥 ENTER 키를여러번입력하세요 ) [hadoop@hadoop01 ~]$ ssh localhost The authenticity of host 'localhost (::1)' can't be established. RSA key fingerprint is 78:28:9d:9e:0e:4f:03:9c:fd:8d:60:d1:78:13:8d:33. Are you sure you want to continue connecting (yes/no)? yes -SSH 설정순서 1) 열쇠 + 자물쇠생성하기 2) 인증키박스 ( 현관 ) 에자물쇠등록 3) 확인하기
29 Hadoop 설치 ( 계속 ) hadoop 계정 환경변수등록 [hadoop@hadoop01 ~]$ vim ~/.bash_profile #JAVA export JAVA_HOME=/usr/local/java export PATH=$PATH:$JAVA_HOME/bin export HADOOP_HOME=/home/hadoop/hadoop export PATH=$PATH:$HADOOP_HOME/bin [hadoop@hadoop01 ~]$ source ~/.bash_profile
30 Hadoop 설치 ( 계속 ) hadoop 계정 SSH 설정 ( 계속 ) - 열쇠 + 자물쇠생성하기 [hadoop@hadoop01 ~]$ ssh-keygen -t dsa < 비밀번호입력하지말고엔터 3 번 > - 인증키박스에자물쇠등록 [hadoop@hadoop01 ~]$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys [hadoop@hadoop01 ~]$ chmod 400 ~/.ssh/authorized_keys - 확인하기 ( localhost, hadoop01 모두확인해야함 ) [hadoop@hadoop01 ~]$ ssh localhost [hadoop@hadoop01 ~]$ exit logout Connection to localhost closed. [hadoop@hadoop01 ~]$ ssh hadoop01 The authenticity of host 'hadoop01 ( )' can't be established. RSA key fingerprint is 78:28:9d:9e:0e:4f:03:9c:fd:8d:60:d1:78:13:8d:33. Are you sure you want to continue connecting (yes/no)? yes [hadoop@hadoop01 ~]$ exit [hadoop@hadoop01 ~]$ ll.ssh
31 Hadoop 설치 ( 계속 ) hadoop 계정 하둡설치 [ 하둡버전 ] [ 하둡설정 ] : 개인배포설정 (Free) -하둡설치 ( 다운로드, 압축풀기, 심벌릭링크 ) [hadoop@hadoop01 ~]$ wget [hadoop@hadoop01 ~]$ tar xvzf hadoop tar.gz [hadoop@hadoop01 ~]$ ln -s /home/hadoop/hadoop /home/hadoop/hadoop -마스터와슬레이브추가 - $HADOOP_HOME/etc/hadoop/masters localhost - $HADOOP_HOME/etc/hadoop/slaves localhost -$HADOOP_HOME/etc/hadoop/hadoop-env.sh 수정 export JAVA_HOME=/usr/local/java
32 Hadoop 설치 ( 계속 ) hadoop 계정 환경변수추가 $HADOOP_HOME/etc/hadoop/hadoop-env.sh export HADOOP_COMMON_LIB_NATIVE_DIR=/home/hadoop/hadoop/lib/native Export HADOOP_OPTS= -Djava.library.path=/home/hadoop/hadoop/lib $HADOOP_HOME/etc/hadoop/yarn-env.sh export HADOOP_COMMON_LIB_NATIVE_DIR=/home/hadoop/hadoop/lib/native Export HADOOP_OPTS= -Djava.library.path=/home/hadoop/hadoop/lib
33 Hadoop 설치 Core-site.xml <configuration> <property> <name>fs.defaultfs</name> <value>hdfs://localhost:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/data/hadoop/tmp</value> </property> </configuration>
34 Hadoop 설치 Hdfs-site.xml <configuration> <property> </property> <property> </property> <property> </property> <property> </property> <property> </property> <property> </property> <property> </property> </configuration> <name>dfs.replication</name> <value>1</value> <name>dfs.namenode.name.dir</name> <value>/data/hadoop/dfs/name</value> <final>true</final> <name>dfs.namenode.checkpoint.dir</name> <value>/data/hadoop/dfs/namesecondary</value> <final>true</final> <name>dfs.http.address</name> <value>hadoop01:50070</value> <name>dfs.secondary.http.address</name> <value>hadoop01:50090</value> <name>dfs.datanode.data.dir</name> <value>/data/hadoop/dfs/data</value> <final>true</final> <name>dfs.permissions</name> <value>false</value>
35 Hadoop 설치 Mapred-site.xml <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapred.local.dir</name> <value>/data/hadoop/hdfs/mapred</value> </property> <property> <name>mapred.system.dir</name> <value>/data/hadoop/hdfs/mapred</value> </property> </configuration>
36 Hadoop 설치 Yarn-site.xml <configuration> <property> </property> <property> </property> <property> </property> <property> <property> </property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> <name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name> <value>org.apache.hadoop.mapred.shufflehandler</value> <name>yarn.resourcemanager.resource-tracker.address</name> <value>hadoop01:8025</value> <name>yarn.resourcemanager.scheduler.address</name> <value>hadoop01:8030</value></property> <name>yarn.resourcemanager.address</name> <value>hadoop01:8035</value> </configuration>
37 Hadoop 설치 계속 ) hadoop 계정 HDFS Format [hadoop@hadoop01 ~]$ hadoop namenode -format Hadoop 실행 [hadoop@hadoop01 ~]$./hadoop/sbin/start-dfs.sh [hadoop@hadoop01 ~]$./hadoop/sbin/start-yarn.sh [hadoop@hadoop01 ~]$./hadoop/sbin/mr-jobhistory-daemon.sh start historyserver 실행확인 [hadoop@hadoop01 ~]$ jps 웹에서실행확인하기 - 하둡서비스중단하기 [hadoop@hadoop01 ~]$./hadoop/sbin/stop-yarn.sh [hadoop@hadoop01 ~]$./hadoop/sbin/stop-dfs.sh
38 HDFS(Hadoop Distributed File System) HDFS(Hadoop Distributed File System) 수십테라바이트또는페타바이트이상의대용량파일을분산된서버에저장하고, 많은클라이언트가저장된데이터를빠르게처리할수있게설계된파일시스템 저사양서버를이용해스토리지를구성할수있음 대규모데이터를저장, 배치로처리하는경우 대용량파일시스템 특징 DAS(Direct-Attached Storage) 서버에직접연결된스토리지 여러개의하드디스크를장착할수있는외장형하드디스크 NAS(Network-Attached Storage) 파일시스템을안정적으로공유할수있음 별도의운영체제사용 SAN(Storage Area Network) 수십-수백대의 SAN스토리지를데이터서버에연결해총괄적으로관리해주는네트워크 DBMS와같이안정적으로빠른접근이필요한데이터를저장하는데사용 ( 고성능, 고가용성 )
39 HDFS 설계목표 1. 장애복구 - 디스크오류로인한데이터저장실패및유실과같은장애를빠른시간에감지하고대처 - 데이터를저장하면, 복제데이터도함께저장해서데이터유실을방지함 - 분산서버간주기적인상태체크 2. 스트리밍방식의데이터접근 - HDFS에파일저자및조회를위해스트리밍방식으로데이터에접근해야함 - 배치작업과높은데이터처리량을위해스트리밍방식을사용 3. 대용량데이터저장 - 하나의파일이기가바이트에서테라바이트이상의사이즈로저장될수있게설계 - 높은데이터전송대역폭, 하나의클러스터에서수백대의노드를지원 - 하나의인스턴스에서수백만개이상의파일을지원 4. 데이터무결성 - 한번저장한데이터를수정할수없음 ( 읽기만가능 ) - 파일이동, 삭제, 복사할수있는인터페이스제공
40 HDFS 기본 하나의 HDFS에하나의네임스페이스제공 파일은블록들로저장됨 보통 64MB ~ 128MB 큰파일을다루는데적합한시스템 하부운영체제의파일시스템을그대로사용 복제를통한안정성 각블록은 3 대의 DataNode 에복제 Write Once Read Many File Overwrite not Append 마스터가모든메타데이터관리 간단한중앙집중관리 No 데이터캐시 데이터사이즈가커서캐시로인한혜택없음
41 HDFS(Hadoop Distributed File System) 네임노드 파일시스템의 NameSapce 관리 파일명과블록들의집합을관리 블록과블록이위치한데이터노드들의정보관리 블록에대한복제스케줄링 메타데이터 Fsimage : 네임스페이스 /Inode 정보 파일들의리스트, 파일별속성정보 각블록별 DataNode 들의리스트 Edit Log : 트랜잭션로그 파일생성, 삭제기록들
42 HDFS(Hadoop Distributed File System) Secondary NameNode NameNode 의 fsimage와트랜잭션로그를복사함 복사한 fsimage와트랜잭션로그 (Edit log) 병합 새로운 fsimage를 NameNode에게보냄 Secondary NameNode NameNode의단순백업데몬이아님 Fsimage 관리를공동담당
43 HDFS(Hadoop Distributed File System) DataNode 블록서버 블록을메타데이터를로컬에저장 (ext3) 클라이언트에게블록 & 메타데이터제공 블록보고 주기적으로 (Heart Beat) 존재하는모든블록들의리스트를 NameNode에보고 기본 3초마다 (dfs.heartbeat.interval in hdfs-site.xml) Pipelining 데이터저장 데이터를다른 DataNode 에전달 블록배치순서 첫번째복제본은로컬노드에저장 두번째복제본은원격 Rack에저장 세번째복제본은같은 Rack에저장 클라이언트읽기 로컬노드 -> 같은 Rack -> 원격 Rack 순서
 320MB 파일 블록 1 블록 2 블록 3 블록 4 블록 5 파일저장 블록 1 블록 3 블록 4 블록 2 블록 3 블록 4 블록 1 블록 3 블록 5 HDFS 블록 2 블록 4 블록 5 블록 1 블록 2 블록")
44 HDFS 아키텍처 블록구조파일시스템 블록사이즈가기본적으로 64MB로설정돼있음 ( 설정파일에서수정가능 ) 파일사이즈가기본블록설정보다작을경우파일사이즈로저장 블록을저장할때기본적으로 3개씩블록의복제본을저장 ( 수정가능 ) 320MB 파일 블록 1 블록 2 블록 3 블록 4 블록 5 파일저장 블록 1 블록 3 블록 4 블록 2 블록 3 블록 4 블록 1 블록 3 블록 5 HDFS 블록 2 블록 4 블록 5 블록 1 블록 2 블록 5
45 HDFS 아키텍처 애플리케이션 네임노드와데이터노드 1. 파일저장, 파일읽기 HDFS 클라이언트 2. 블록위치조회 2. 클라이언트는네임노드에접속해원하는파일이저장된블록의위치를조회하고 3. 해당블록이저장된데이터노드에서직접데이터를조회함 3. 데이터조회 네임노드 메타데이터 HDFS 의모든메타데이터관리 클라이언트가 HDFS 에저장된파일에접근할수있게함 HDFS 에저장된파일의디렉터리명, 파일명이저장됨 파일의복제본수, 블록위치관리 HDFS 4. 상태보고 - 주기적으로하트비트 (heartbeat) 와블록의목록이저장된블록리포트 (blockreport) 전송 데이터노드데이터노드데이터노드 4. 네임노드는하트비트를통해데이터노드가정상작동하는지확인하고블록리포트를통해데이터노드의모든블록을확인, 파일복제본의위치결정
46 HDFS 의파일저장 파일저장요청 클라이언트 JVM 1. 스트림요청 클라이언트 DistributedFileSystem 4. 스트림반환 2. 스트림생성 DFSClient DFSOutputStream 3. 블록위치요청 4. 블록위치반화 네임노드
47 HDFS 의파일저장 패킷전송 클라이언트 1. 저장요청 클라이언트 JVM DFSOutputStream 2. 데이터노드목록요청 4. 패킷저장 DataStreamer ResponseProcessor 3. 데이터노드목록반환 네임노드 7. run 5. ACK 6. 블록저장결과알림 6. 블록저장결과알림 6. 블록저장결과알림 DataXceiverServer 데이터노드 5. ACK DataXceiverServer 5. ACK 데이터노드 4. 패킷저장 4. 패킷저장 DataXceiverServer 데이터노드
48 HDFS 의파일저장 파일닫기 클라이언트 JVM 1. 스트림닫기 클라이언트 DistributedFileSystem 2. 스트림닫기 DFSClient DFSOutputStream 네임노드 3. 저장완료
49 HDFS 의파일읽기 파일조회요청 클라이언트 JVM 1. 스트림요청 클라이언트 DistributedFileSystem 4. 스트림반환 2. 스트림생성 DFSClient DFSInputStream 네임노드 3. 유효성검사요청
50 HDFS 의파일읽기 블록조회 클라이언트 1. 조회요청 클라이언트 JVM 2. 블록리더기생성 DFSClient DFSInPutStream 4. 블록위치요청 네임노드 BlockReaderLocal 2. 블록리더기생성 5. 블록위치반환 RemoteBlockReader 3. 블록조회 3. 블록조회 3. 블록조회 DataXceiverServer 데이터노드 DataXceiverServer 데이터노드 DataXceiverServer 데이터노드
51 HDFS 의파일읽기 입력스트림닫기 클라이언트 JVM 클라이언트 1. 스트림닫기요청 2. 블록리더기닫기 DFSClient DFSInPutStream BlockReaderLocal 2. 블록리더기닫기 RemoteBlockReader
52 HDFS CLI hdfs (d)fs cmd <args> [appendtofile <localsrc> <dst>] [-ls <path>] [-du <path>] [-cp <src> <dst>] [-rm <path>] [-put <localsrc> <dst>] [-copyfromlocal <localsrc> <dst>] [-movefromlocal <localsrc> <dst>] [-get [-crc] <src> <localdst>] [-cat <src>] [-copytolocal [-crc] <src> <localdst>] [-movetolocal [-crc] <src> <localdst>] [-mkdir <path>] [-touchz <path>] [-text -[ezd] <path>] [-stat [format] <path>] [-help [cmd]]
53 HDFS CLI appendtofile hdfs dfs -appendtofile <localsrc>... <dst> HDFS에존재하는파일에한개또는다수의파일을추가함 STDIN 입력을읽어서도추가가능
54 HDFS CLI cat hdfs dfs -cat URI [URI...] 파일내용을나타냄 압축된파일을읽기위해서는 fs 대신 text 명령어사용
55 HDFS CLI chgrp hdfs dfs -chgrp [-R] GROUP URI [URI...] 파일과디렉터리의그룹을변경함 -R 옵션은변경을재귀적으로적용 사용자는해당파일의소유자이거나슈퍼유저여야함
56 HDFS CLI chmod hdfs dfs -chmod [-R] <MODE[,MODE]... OCTALMODE> URI [URI...] 유닉스와유사하게권한모드는세자리 8진수모드또는 +/-{rwxx} -R 옵션은변경을재귀적으로적용 사용자는해당파일의소유자이거나슈퍼유저여야함 chwon hdfs dfs -chown [-R] [OWNER][:[GROUP]] URI [URI ] 파일과디렉터리의소유자를변경 -R 옵션은변경을재귀적으로적용 사용자는슈퍼유저여야함
57 HDFS CLI copyfromlocal hdfs dfs -copyfromlocal <localsrc> URI put과동일함 로컬파일시스템으로부터파일들을복사 copytolocal hdfs dfs -copytolocal [-ignorecrc] [-crc] URI <localdst> get과동일함 파일들을로컬파일시스템으로복사
58 HDFS CLI count hdfs dfs -count [-q] [-h] <paths> PATH에있는모든파일과디렉터리에대한이름, 사용된바이트수, 파일개수 -q 옵션은할당정보를나타냄
59 HDFS CLI cp hdfs dfs -cp [-f] [-p -p[topax]] URI [URI...] <dest> 소스에있는파일들을목적지로복사함 만약다수의소수파일들이지정되면, 목적지는디렉터리여야함
60 HDFS CLI du dus hdfs dfs -du [-s] [-h] URI [URI...] 파일크기를나타냄 만약 PATH가디렉터리이면, 그디렉터리에있는각파일의크기가리포트됨 파일명앞에전체 URI 프로토콜이붙음 비록 du는디스크사용량을나타내지만있는그대로받아들여서는안됨 디스크사용량은블록크기와복제요소들에따라다르기때문 hdfs dfs -dus <args> du와비슷함 그런데디렉터리에대해서 dus는개별적으로나타내기보다는합계 ( 파일크기 ) 를리포트함
61 HDFS CLI expunge hdfs dfs -expunge 휴지통을비움 만약휴지통기능이활성화되어있으면, 파일이삭제되었을때우선임시.Trash/ 폴더로이동하게됨 사용자가설정한시간후에.Trash/ 폴더에있는파일들을강제적으로삭제.Trash/ 폴더에파일이존재하는한그것을원래위치로이동시켜해당파일을복구할수있음
62 HDFS CLI get hdfs dfs -get [-ignorecrc] [-crc] <src> <localdst> 파일들을로컬파일시스템으로복사할때, 만약다수의소스파일들이지정되면로컬목적지는디렉터리여야함 만약 LOCALDST가 이면, 그파일들은 stdout 으로복사됨 HDFS는파일에대한각블록의체크섬을계산함 파일에대한체크섬은숨김파일에저장되고, 해당파일이 HDFS에읽힐때숨김파일에있는체크섬들은해당파일의무결성을확인하는데사용 Get 명령어에서 crc 옵션을사용하면, 숨김파일도복사하고, -ignorecrc 옵션은복사할때체크섬을확인하는과정을건너뜀
63 HDFS CLI getmerge hdfs dfs -getmerge <src> <localdst> [addnl] SRC에서확인된모든파일을가져와합치고, 로컬파일시스템에존재하는하나의 LOCALDST 파일에기록함 ddnl 옵션은각파일의끝을나타내는개행문자를 LOCALDST 파일에추가함
64 HDFS CLI ls hdfs dfs -ls [-R] <args> 파일과디렉터리를조회함 각엔트리는명칭, 권한, 소유자, 그룹, 크기, 수정일을나타냄 파일엔트리는복제요소도포함해서보여줌 lsr hdfs dfs -lsr <args> ls 의재귀적버전
65 HDFS CLI mv hdfs dfs -mv URI [URI...] <dest> SRC에있는파일들을 DST로옮김 만약다수의소스파일들이지정되면, 목적지는디렉터리여야함 파일시스템들간이동은허가되지않음 movetolocal hdfs dfs -movetolocal [-crc] <src> <dst> 아직구현되지않음
66 HDFS CLI put hdfs dfs -put <localsrc>... <dst> 로컬시스템으로부터파일과디렉터리를목적지파일시스템으로복사 만약 LOCALSRC가 로설정되어있으면입력은 STDIN으로지정되고, DST는파일이어야함
67 HDFS CLI rm hdfs dfs -rm [-f] [-r -R] [-skiptrash] URI [URI...] 파일과빈디렉터리를삭제함 rmr hdfs dfs -rmr [-skiptrash] URI [URI...] rm 의재귀적버전
68 HDFS CLI setrep hdfs dfs -setrep [-R] [-w] <numreplicas> <path> 주어진파일들에대한대상복제갯수를 REP로설정함 -R 옵션은 PATH에의해확인된디렉터리들에대한파일들의대상복제갯수를재귀적으로적용함 stat hdfs dfs stat [FORMAT] URI [URI...] 파일의통계정보를보여줌 FORMAT : %d ( 파일크기 ), %F( 파일형식 ), %n( 파일이름 ), %r( 복제 ), %o( 블록크기 )
69 HDFS CLI tail hdfs dfs -tail [-f] URI 파일의마지막 1K byte 의내용을출력 test hdfs dfs -test -[ezd] URI PATH에다음의형식점검을수행함 -e PATH 존재유무, PATH가존재하면 0을반환함 -z 빈파일여부, 파일길이가 0이면 0을반환함 -d PATH가디렉터리이면 0을반환함
70 HDFS CLI text hdfs dfs -text <src> 파일의텍스트내용을나타냄 만약파일이텍스트파일이라면 cat 명령과동일함 압축형식 (gzip과하둡의바이너리시퀀스파일포맷 ) 으로알려진파일들은우선압축을해제함 touchz hdfs dfs -touchz URI [URI...] 길이가 0인파일을생성함 만약길이가 0이아닌파일이이미존재하면에러가발생함
71 HDFS CLI Balancer 실행 $hadoop balancer 데이터가분산이잘되는지확인 distcp 실행 원격 DFS의 /user/hadoop/distcp의모든내용을자신의 DFS로복사 $hadoop distcp p update <src> <dst>
72 Hadoop 2015
73 Content hadoop 운영
74 하둡운영 파일시스템상태확인 $hadoop fsck 상태 Over-replicated blocks Under-replicated blocks Mis-replicated blocks Corrupt blocks 내용 복제본이과도하게생성된경우를의미 (3 개의복제본이저장돼야하는데,3 개를초과해서복제본이저장된경우 ) 부족하게복제된블록개수를의미 (3 개의복제본이저장돼야하는데,2 개혹은 1 개의복제본만저장돼있다면부족하게저장된복제본으로인식합니다주로네임노드가다운되기직전이나직후에데이터를저장할경우발생 ) 복제된블록이유실된상태 블록에오류가발생한경우 $hadoop balancer -threshold [threshold] $sbin/hadoop-daemon.sh start balancer
75 하둡운영 HDFS 어드민명령어 $hadoop dfsadmin [option] -report Hdfs의기본적인정보와상태출력 -safemode [enter leave] 파일쓰기변경작업금지읽기만허용 -savenamespace 로컬파일시스템에저장돼있는파일시스템이미지파일과에디트로그를현재벼전으로갱신 안전모드상태에서실행가능
76 하둡운영 파일관리 $hadoop dfsadmin [option] -setquota 파일과하위디렉토리개수설정» $hadoop fs -mkdir quota_test» $hadoop dfsadmin -setquota 2 quota_test» $hadoop fs -put.. /data/2008.csv quota_test/2008. Csv» $hadoop fs -put.. /data/2008.csv quota_test/2008. Csv -clrquota 쿼터해제또는재설정» hadoop dfsadmin -clrquota quota_test -setspacequota 용량제한» $hadoop dfsadmin -setspacequota 1500m quota_test -clrspacequota 용량제한해제» $hadoop dfsadmin -clrspacequota quota_test
77 하둡운영 데이터노드제거 hdfs-site.xml <property> <name>dfs.hosts.exclude</name> <value>/home/hadoop/hadoop/conf/exclude_server</value> </property> exclude_server 파일에제거할데이터노드의호스트명작성 ex> hadoop02 $hadoop dfsadmin refreshnodes hdfs-site.xml 의 dsf-hosts.exclude 와 dfs.hosts 를리프레쉬 데이터노드를제거했을때남게되는데이터노드의수가 dfs.replication(hdfs 데이터복제본수 ) 옵션으로설정한값보다크거나같아야함
78 하둡운영 데이터노드추가 네임노드의 slaves 파일에데이터노드를추가한다. 데이터노드의환경설정파일 (hdfs-site.xml, core-site.xml, mapred-site.xm) 에네임노드접속주소를설정한다. 데이터노드용서버에서데이더노드와태스크트래커를구동한다. hdfs-site.xml <property> <name>dfs.hosts</name> <value>/home/hadoop/hadoop/conf/include_server</value> </property> include_server 파일에추가할데이터노드의호스트명작성 ex> hadoop01 hadoop02 hadoop03 $hadoop dfsadmin refreshnodes hdfs-site.xml 의 dsf-hosts.exclude 와 dfs.hosts 를리프레쉬 $hadoop-daemon.sh start balancer
79 하둡운영 네임노드장애복구 네임노드의디렉토리구조 디렉토리 ${dfs name.dir}/current/version ${dfs.name.dir}/current/fsimage ${dfs.name.dir}/current/fstime ${dfs.name.dir}/current/edits ${dfs.name.dir}/image/fsimage ${dfs.name.dir}/previous.checkpoint/ 내용파일시스템레이아웃체크포인팅한시점의파일시스템레이아웃체크포인팅을실행한시간체크포인팅이후의 HDFS 트랜잭션로그체크포인팅을시작하기직전의파일시스템이미지마지막으로체크포인팅 보조네임노드의디렉토리구조 디렉토리 내용 ${fs.checkpoint.dir}/current/version 파일시스템레이아웃 ${fs.checkpoint.dir}/current/fsimage 체크포인팅한시점의파일시스템레이아웃 ${fs.checkpoint.dir}/current/fstime 체크포인팅을실행한시간 ${fs.checkpoint.dir}/current/edits 체크포인팅이후의 HDFS 트랜잭션로그 ${fs.checkpoint.dir}/image/fsimage 체크포인팅을시작하기직전의파일시스템이미지
80 하둡운영 네임노드장애복구 보조네임노드를이용한장애복구 hadoop]$./bin/stop-all.sh hadoop]$ rm -rf /data/dfs/name hadoop]$ hadoop namenode hadoop]$ mkdir /data/dfs/name hadoop]$ hadoop namenode importcheckpoint hadoop]$ $HADOOP_HOME/sbin/start-all.sh hadoop]$ ls -l /data/dfs/name 보조파일시스템을사용하여복구 <property> <name>dfs.name.dir</name> <value> 로컬파일시스템디렉터리, NFS 디렉터2.1</value> </ property>
81 하둡운영 데이터노드장애복구 해당데이터노드를중지 손상된디스크를언마운트하고새로운디스크를마운트 새로운디스크에 dfs.data.dir 속성으로설정한디렉터리를생성 데이터노드를재실행 네임노드서버에서밸런서를실행 HDFS 웹 UI에서해당데이터노드가조회되는지확인
82 Hadoop 2.x 2015
83 Content Hdfs 페더레이션 ( Federation ) YARN Namenode HA
84 HDFS 페더레이션 HDFS 페더레이션 HDFS 가네임노드에기능이집중되는것을막기위함
85 HDFS 페더레이션 기존 HDFS 문제점 네임노드 네임스페이스 네임스페이스 블록관리 블록저장소 데이터노드데이터노드데이터노드
86 HDFS 페더레이션 기존 HDFS 문제점 네임노드확장 성능 수평정확장불가능 네임노드구동시전체파일시스템이미지를메모리에생성 64GB ram 약 2 억 5 천만개파일과블록저장가능 HDFS에대한모든요청이네임노드에요청됨 쓰기시트랜잭션에대한에디트로그생성 동일네임노드사용 네임스페이스와블록관리의지나친결합
87 HDFS 페더레이션 HDFS 페더레이션아키텍쳐 네임노드 - 1 네임노드 - n 네임노드 - n 네임스페이스 네임스페이스 1 네임스페이스 k 네임스페이스 n 블록풀 1 블록풀 k 블록풀 n 블록저장소 데이터노드데이터노드데이터노드
88 HDFS 페더레이션 HDFS 페더레이션의장점 네임노드분리 기존구성변경불필요 네임노드등록삭제시재시작불필요 밸런서디터미션네임노드개별적수행가능
89 HDFS 페더레이션 네임스페이스관리 마운트테이블 data home tmp 네임노드 -1 네임노드 -2 네임노드 -2
90 HDFS 페더레이션 기존 <property> <name>fs.default.name</name> <value>hdfs://namenodeofclusterx:port</value> </property> Mount table <property> <name>fs.default.name</name> <value>viewfs://clusterx</value> </property> <property> <name>fs.viewfs.mounttable.default.link./nn1home</name> <value>hdfs://namenode1:9001/home</value> </property> <property> <name>fs.viewfs.mounttable.default.link./nn2home</name> <value>hdfs://namenode2:9001/home</value> </property>
91 YARN YARN 등장배경 잡트래커가모든잡의스케줄링과자원관리 잡트래커구조확장의필요성 메모리소비개선 스레드모델개선 등
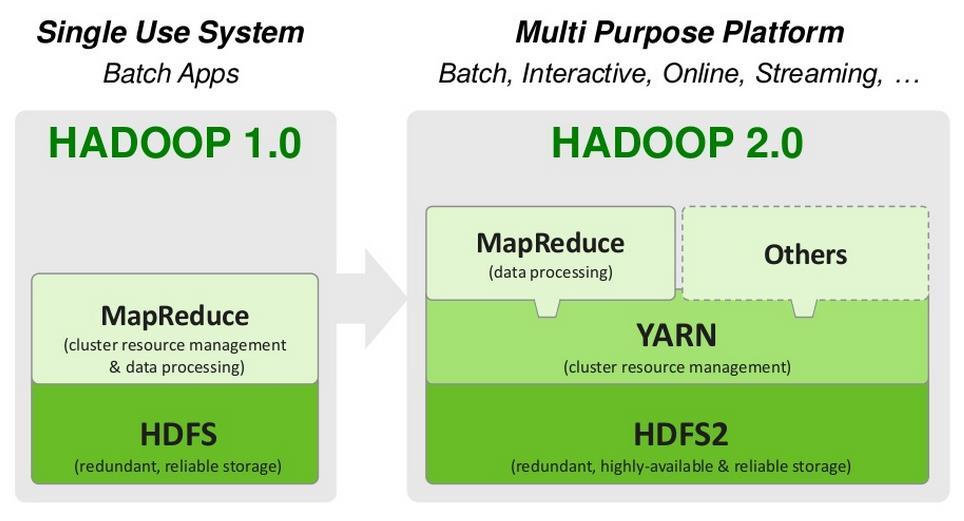
92 YARN
93 YARN Hadoop 1.0 의단점 한노드에서실행할수있는 Map 과 Reduce 용작업숫자가제한되어, 노드에여유자원이있어도그자원을활용하지못하는상황이발생 클러스터의규모와는상관없이 Job Tracker 의개수는 1 개 ( 병목지점 ) 자원분배및작업관리의비효율성 YARN (Yet Another Resource Negotiator) 자원관리, Job 상태관리를 ResourceManager 와 ApplicationMaster 로분리하여, 기존 Job Tracker 에몰리던병목을제거 MapReduce 외에다양한어플리케이션을실행할수있으며, 어플리케이션마다자원 (CPU, 메모리 ) 을할당받음 클러스터에는여러개의 Application 이동작가능 각 Application 은 Application Master 가모든 task 를관리 HADOOP 2 HADOOP 1 (Job Tracker) Resource Manager Application Master

94 YARN Application 호환성 HADOOP 1 MapReduce 외에다른 Application 은클러스터의자원을공유할수없는문제 HADOOP 2 YARN 같은클러스터내에서 M/R 와다른 application 을실행할수있도록지원
95 YARN 자원할당의유연성 HADOOP 1 Slot에미리자원 (memory, cpu cores) 를할당후미리정해진설정에따라서 slot을 job 에할당 Job이모두끝나기전까지는자원이반납되지않는문제 HADOOP 2 YARN 요청이있을때마다요구하는자원의 spec에맞게자원을 container의개념으로할당 container마다다른 spec의자원을갖을수있음 모든 task는 container에서수행되고 task가끝나는즉시자원을반납
 스케줄러 (Scheduler) 어플리케이션마스터 (Application Master) 노드매니저 (Node Manager) 컨테이너")
96 YARN YARN (Yet Another Resource Negotiator) 리소스메니저 (Resource Manager) 어플리케이션매니저 (Applications Manager) 스케줄러 (Scheduler) 어플리케이션마스터 (Application Master) 노드매니저 (Node Manager) 컨테이너 (Container)
97 YARN YARN (Yet Another Resource Negotiator) 리소스메니저 (Resource Manager) master node에서동작 global resource scheduler application들의자원요구의할당및관리
98 YARN YARN (Yet Another Resource Negotiator) 노드매니저 (Node Manager) slave node에서동작 node의자원을관리 container에 node의자원을할당
99 YARN YARN (Yet Another Resource Negotiator) 컨테이너 (Container) RM(Resource Manager) 의요청에의해 NM(Node Manager) 에서할당 slave node의 CPU core, memory의자원을할당 applications은다수의 container로동작
100 YARN YARN (Yet Another Resource Negotiator) 어플리케이션마스터 (Application Master) application당한개씩존재 application의 spec을정의 container에서동작 application task를위해 container 할당을 RM에게요청
101 YARN YARN (Yet Another Resource Negotiator) 어플리케이션마스터 (Application Master) application당한개씩존재 application의 spec을정의 container에서동작 application task를위해 container 할당을 RM에게요청
102 YARN YARN 장점 확장성 가용성 Zookeeper 이용한 HA 호환성 리소스이용확대 YARN 은 CPU, 메모리, 디스크, 네트워크와같은리소스를기준으로애플리케이션수행을예약하고, 실행함 알고리즘지원확대 성능개선 ( x2 ) SSE4.2 fadvise 지원 linux native 로컬데이터읽기개선 셔플성능개선 ( x2 ) 소규모잡의실행환경개선 네임노드의에디트로그의단순화
103 네임노드 HA Hadoop Manual Failover NFS를통한 edit log 공유 Hadoop Automatic Failover 지원 NFS를통한 edit log 공유 Hadoop Automatic Failover 지워 QJM 지원
104 네임노드 HA HDFS HA using QJM core-site.xml <property> <name>fs.defaultfs</name> <value>hdfs://mycluster</value> </property> <property> <name>ha.zookeeper.quorum</name> <value>zookeeper1:2181,zookeeper2:2181,zookeeper3:2181</value> </property>
105 네임노드 HA HDFS HA using QJM Hdfs-site.xml <!-- Automatic failover configuration --> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <!-- Storage for edits' files --> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://namenode01:8485;namenode02:8485;namenode03:848 5/hadoop-cluster</value> </property>
106 네임노드 HA HDFS HA using QJM <!-- common server name --> <property> <name>dfs.nameservices</name> <value>hadoop-cluster</value> </property> <property> <name>dfs.name.dir</name> <value>/home/name</value> </property> <property> <name>dfs.data.dir</name> <value>/data1/hdfs,/data2/hdfs</value> </property> <property> <name>dfs.journalnode.edits.dir</name> <value>/home/hadoop/hdfs/jn</value> </property>
107 네임노드 HA HDFS HA using QJM <!-- HA configuration --> <property> <name>dfs.ha.namenodes.hadoop-cluster</name> <value>nn1,nn2</value> </property> <property> <name>dfs.namenode.rpc-address.hadoop-cluster.nn1</name> <value>namenode01:8020</value> </property> <property> <name>dfs.namenode.rpc-address.hadoop-cluster.nn2</name> <value>namenode02:8020</value> </property> <property> <name>dfs.namenode.http-address.hadoop-cluster.nn1</name> <value>namenode01:50070</value> </property> <property> <name>dfs.namenode.http-address.hadoop-cluster.nn2</name> <value>namenode02:50070</value> </property>
108 네임노드 HA HDFS HA using QJM $HADOOP_HOME/sbin/hadoop-daemon.sh start journalnode // 각노드에서 $HADOOP_HOME/sbin/hadoop-daemon.sh start zkfc // namenode 에서
109 Hadoop MapReduce 2015
110 Content MapReduce WordCount DepartureDelayCount
111 MapReduce 맵리듀스 HDFS에분산저장된데이터에스트리밍접근을요청하며빠르게분산처리하도록고안된프로그래밍모델, 이를지원하는시스템 대규모분산컴퓨팅혹은단일컴퓨팅환경에서개발자가대량의데이터를병렬로분석할수있음 개발자는맵리듀스알고리즘에맞게분석프로그램을개발하고, 데이터의입출력과병렬처리등기반작업은프레임워크가알아서처리해줌
112 MapReduce 맵 (Map) : (k1, v1) list(k2, v2) 데이터를가공해서분류 ( 연산가공자 ) 리듀스 (Reduce) : (k2, list(v2)) list(k3, v3) 분류된데이터를통합 ( 집계연산자 ) Start Map Map Map Map Combine Combine Sorting Reduce Reduce Finish 맵리듀스환경의분산프로세스 [1]
113 MapReduce 입력데이터분리 : 키와값으로분류 맵메서드 : 라인별로문장을체크, 키에해당하는글자별로글자수출력 정렬과병합 : 맵메서드의출력데이터를정렬, 병합 read a book write a book <#1, read a book> <#2, write a book> Map <read, 1> <a, 1> <book, 1> <write, 1> <a, 1> <book, 1> <read, (1)> <a, (1, 1)> <book, (1, 1)> <write, (1)> 리듀스메서드 : 키에해당하는글자별로글자수를합산해서출력 저장 : 하둡파일시스템에저장 Reduce <read, 1> <a, 2> <book, 2> <write, 1> read, 1 a, 2 book, 2 write, 1 Map input records=2 Map output records=6 Reduce input records=6 (Reduce input groups=4) Reduce output records=4
114 MapReduce Architecture 클라이언트 잡트래커 데이터노드데이터노드데이터노드 태스크트래커 태스크트래커 태스크트래커 맵 맵 맵 리듀스리듀스 리듀스 맵 맵 맵 리듀스리듀스 리듀스 맵 맵 맵 리듀스리듀스 리듀스
 ( 데이터노드에서실행 ) 잡트래커의작업수행요청을받아맵리듀스프로그램실행 잡트래커가요청한맵과리듀스개수만큼맵, 리듀스태스크를생성 새로운 JVM을구동해맵, 리듀스태스크실행 이때, JVM은재사용할수있게설정가능.")
115 MapReduce Architecture 클라이언트 맵리듀스프로그램 & API 잡트래커 (JobTracker) ( 네임노드서버에서실행 ) 맵리듀스프로그램은잡 (Job) 이라는하나의작업단위로관리됨 하둡클러스터에등록된전체잡의스케줄링을관리하고모니터링 사용자가새로운잡을요청하면잡트래커는잡을처리하기위해몇개의맵과리듀스를실행할지계산 어떤태스크트래커에서실행할지결정 잡할당 전체클러스터에서하나의잡트래커가실행됨 태스크트래커 (TaskTracker) ( 데이터노드에서실행 ) 잡트래커의작업수행요청을받아맵리듀스프로그램실행 잡트래커가요청한맵과리듀스개수만큼맵, 리듀스태스크를생성 새로운 JVM을구동해맵, 리듀스태스크실행 이때, JVM은재사용할수있게설정가능. 데이터노드가하나라도여러개의 JVM을실행해서데이터를동시에분석함 ( 병렬처리가능 )
116 MapReduce 작동방식 네임노드데이터노드사용자 1. 맵리듀스잡실행 * 입력스플릿결과 - 입력스플릿정보, 설정파일, 맵리듀스 JAR 파일을 HDFS 에저장 * 하트비트메서드를통해상태정보전송 - CPU, 메모리, 서버가용리소스정보, 현재실행중태스크개수, 실행가능한최대태스크개수, 신규태스크실행가능여부등 * 파티션 - 메모리에있는데이터를키에따라정렬후, 로컬디스크에저장, 하나의출력파일로병합, 정렬됨 잡클라이언트 3. 입력스플릿계산후잡트래커에잡시작준비완료전송 입력데이터 잡트래커 잡 2. 신규잡제출 잡 잡 4. 잡을큐에등록잡스케줄러가입력스플릿개수만큼맵태스크생성, ID 부여 잡할당 태스크트래커 태스크 태스크 태스크 6. 태스크트래커는맵태스크실행 매퍼 5. 주기적으로잡트래커키-값의하트비트메서드를호출해서상태정보를잡트 10. 정렬, 병합래커에전송 11. 리듀스메서드를호출해분석로리듀서직실행 파티셔너 매퍼 키 - 값 리듀서 7. 맵태스크는맵메서드에정의돼있는로직실행, 출력데이터를메모리버퍼에저장 8. 파티셔너는해당출력데이터가어떤리듀스태스크에전달돼야할지를결정, 그에맞는파티션을지정 9. 리듀스태스크는맵태스크의모든출력데이터가있어야작업을실행할수있음 입력스플릿 (input split) - 하나의맵에서처리해야하는입력파일의크기 - 하둡은맵리듀스잡의입력데이터를입력스플릿이라는고정된크기의조각으로분리 - 생성된입력스플릿마다맵태스크를하나씩생성 - 기본설정 64MB 로입력스플릿이생성됨 (HDFS 의기본블록사이즈 ) 키 - 값 출력데이터 키 - 값 12. 출력데이터를 HDFS 에 part-nnnnn 이라고저장. (nnnnn- 파티션 ID)
117 응용분야 Google Source Tree 에등록된응용프로그램 distributed Grep distributed Sort web access log stats inverted index construction document clustering machine learning statistical machine translation
118 하둡프로그래밍요소
119 하둡프로그래밍요소 1) 데이터타입 2) InputFormat 3) 매퍼 (Mapper) 4) 파티셔너 (Partitioner) 5) 리듀서 (Reducer) 6) 콤바이너 7) OutputFormat
120 1) 데이터타입 맵리듀스 API는자주쓰는데이터타입에대한 WritableComparable 인터페이스를구현한 Wrapper 클래스제공 WritableComparable 인터페이스 클래스명 BooleanWritable ByteWritable DoubleWritable FloatWritable IntWritable LongWritable Text Wrapper NullWritable 대상데이터타입 Boolean 단일 byte Double Float Integer Long UTF8 형식의문자열데이터값이필요없을경우에사용 Writable & Comparable 인터페이스를다중상속하고있음 Comparable 인터페이스 Java.lang 패키지의인터페이스로, 정렬을처리하기위해 compareto 메서드제공 Writable 인터페이스 write 메서드 데이터값을직렬화함 readfields 메서드 직렬화된데이터값을해제해서읽는역할
121 2) InputFormat 입력스플릿 (Input Split) 을맵메서드의입력파라미터로사용할수있게 InputFormat 추상화클래스제공 InputFormat 클래스 InputFormat TextInputFormat getsplits 메서드 입력스플릿을맵메서드가사용할수있도록함 createrecordreader 메서드 맵메서드가입력스플릿을키와목록의형태로사용할수 KeyValueTextInputFormat NLineInputFormat DelegatingInputFormat 있게 RecordReader 객체생성함 맵메서드는 RecordReader 객체에담겨있는키와값을읽어들여분석로직을수해함 기능 텍스트파일을분석할때사용. 키는 LongWritable 타입, 값은 Text 타입을사용 텍스트파일을입력파일로사용할때라인번호가아닌임의의키값을지정해서키와값의목록으로읽음 맵태스크가입력받은텍스트파이릐라인수를제한하고싶을때사용 여러개의서로다른입력포맷을사용하는경우에각경로에대한작업을위임 CombineFileInputFormat 여러개의파일을스플릿으로묶어서아용 ( 다른 InputFormat 은파일당스플릿을생성 ) SequenceFileInputFormat 시퀀스파일 ( 바이너리형태의키와값의목록으로구성된텍스트파일 ) 을입력데이터로쓸때사용. SequenceFileAsBinaryInputFormat SequenceFileAsTextInputFormat 시퀀스파일의키와값을임의의바이너리객체로변환해서사용 시퀀스파일의키와값을 Text 객체로변환해서사용
122 3) 매퍼 (Mapper) [ Mapper class ] 맵리듀스프레임워크는입력스플릿마다하나의맵태스크 ( 매퍼클래스 ) 를생성함. 대부분이매퍼클래스를상속바다매퍼클래스를새롭게구현하여사용함 Context 객체를이용해 job에대한정보를얻어오고, 입력스플릿을레코드단위로읽을수있음 RecordReader 로맵메서드가키와값의형태로데이터를읽을수있음 map 메서드 run 메서드 Context 객체에있는키를순회하면서맵메서드를호출함 Public class Context extends MapContext<KEYIN, VALUEIN, KEYOUT, VALUEOUT>{ public Context(Configuration conf, TaskAttemptID taskid, RecordReader<KEYIN, VALUEIN> reader, RecordWriter<KEYOUT, VALUEOUT> writer, OutputCommitter committer, StatusReporter reporter, InputSplit split) throws IOException, InterruptedException { super(conf, taskid, reader, writer, committer, reporter, split); } }
123 4) 파티셔너 (Partitioner) [ Partitioner ] 맵태스크의출력데이터가어떤리듀스태스크로전달될지결정함 getpartition 메서드 맵테스크의출력키, 값과전체리듀스태스크개수를파라미터로받아파티션을계산
124 5) 리듀서 (Reducer) 맵태스크의출력데이터를입력데이터로전달받아집게연산을수행
125 6) 콤바이너클래스 (Combiner) 셔플 (Shuffle) 맵태스크와리듀스태스크사이의데이터전달과정 맵태스크의출력데이터는네트워크를통해리듀스태스크로전달됨 콤바이너클래스 셔플할데이터의크기를줄이는데도움을줌 매퍼의출력데ㅣ터를입력데이터로전달받아연산을수행 로컬노드에서로컬에생성된매퍼의출력데이터를이용하기때문에네트워크비용이발생하지않음
126 7) OutputFormat OutputFormat TextOutputFormat SequenceFileOutputFormat SequenceFileAsBinaryOutputFormat FilterOutputFormat LazyOutputFormat NullOutputFormat 기능 텍스트파일에레코드를출력할때사용. 키, 값의구분자는탭을사용 시퀀스파일을출력물로쓸때사용 위에있는것을상속받아구현되었음. 바이너리포맷의키와값을 SequenceFile 컨테이너에씀 OutputFormat 클래스를편리하게사용할수있는메서드제공 (OutputFormat 클래스의 Wrapper 클래스 ) FileOutputFormat 을상속받은클래스는출력할내용이없을때도 part-nnnnn 을생성함. 이포맷을사용하면첫번째레코드가해당파티션 (part-nnnnn) 으로보내질때만출력파일을생성함 출력데이터가없을때사용
127 WordCountMapper.java import java.io.ioexception; import java.util.stringtokenizer; import org.apache.hadoop.io.intwritable; import org.apache.hadoop.io.longwritable; import org.apache.hadoop.io.text; import org.apache.hadoop.mapreduce.mapper; public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> { // 입력키, 입력값, 출력키, 출력값타입 private final static IntWritable one = new IntWritable(1); // 출력값 one 의초기값 1 로설정 private Text word = new Text(); public void map(longwritable key, Text value, Context context) // 입력키, 입력값타입, Context 객체 throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); //Tokenizer 선언 while (itr.hasmoretokens()) { // 공백단위로구분된 string 값을순회함 word.set(itr.nexttoken()); // context 객체의 write 메서드 매퍼의출력데이터에레코드를추가 // 키가 word, 값이 one 임 context.write(word, one);}}}
128 WordCountReducer.java import java.io.ioexception; import org.apache.hadoop.io.intwritable; import org.apache.hadoop.io.text; import org.apache.hadoop.mapreduce.reducer; public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> { private IntWritable result = new IntWritable(); // a<1,1> 과같이입력되는값이 group 으로되어있을때 Iterator 선언. // Iterator 를이용해입력값데이터를탐색하고계산할수있음 public void reduce(text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { // 입력값을순회하면서값을더함 sum += val.get(); } result.set(sum); context.write(key, result);}}
129 WordCount.java package wikibooks.hadoop.chapter04; import org.apache.hadoop.conf.configuration; import org.apache.hadoop.fs.path; import org.apache.hadoop.io.intwritable; import org.apache.hadoop.io.text; import org.apache.hadoop.mapreduce.job; import org.apache.hadoop.mapreduce.lib.input.fileinputformat; import org.apache.hadoop.mapreduce.lib.input.textinputformat; import org.apache.hadoop.mapreduce.lib.output.fileoutputformat; import org.apache.hadoop.mapreduce.lib.output.textoutputformat; public class WordCount { public static void main(string[] args) throws Exception { Configuration conf = new Configuration(); if (args.length!= 2) { System.err.println("Usage: WordCount <input> <output>"); System.exit(2); } Job job = new Job(conf, "WordCount"); job.setjarbyclass(wordcount.class); job.setmapperclass(wordcountmapper.class); job.setreducerclass(wordcountreducer.class); job.setinputformatclass(textinputformat.class); job.setoutputformatclass(textoutputformat.class); job.setoutputkeyclass(text.class); job.setoutputvalueclass(intwritable.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); } } job.waitforcompletion(true);
130 미국항공데이터 기본출력 Output value column 수늘리기 MultipleOutput

131 ASA(American Standards Association: 미국규격협회 ) 에서 2009 년공개한미국항공편운항통계데이터 년까지의미국내모든상업항공편에대한항공편도착과출발세부사항에대한정보제공

132 Download the data
 *")
133 1987.csv 파일상세 (29 개의칼럼 ) * 숫자형식으로데이터가존재함

134 총 22 개의파일 11.4GB
")
135 HDFS 에적재 ( 소요시간 6 분 )

136 ./bin/hadoop fs ls input 으로적재된데이터목록확인

137 DepartureDelayCount 실행소요시간 (19 분 )
138 출력결과 맵 (117개태스크 ) 에서 30초, 리듀서 (1개태스크 ) 에서 18분 30초소요. Map input records = 117,161,410 건 Map output & Reduce input records = 47,765,560 Reduce output records = 245 건
139 Input&output Data Type Task: 연도별로얼마나많은항공기이출발이지연됐는지계산 Class Input or Output Key Value Mapper Input 오프셋 항공운항통계데이터 Output 운항연도, 운항월 출발지연건수 Reducer Input 운항연도, 운항월 출발지연건수 Output 운항연도, 운항월 출발지연건수합계
140 DepartureDelayCountMapper.java import java.io.ioexception; import org.apache.hadoop.io.intwritable; import org.apache.hadoop.io.longwritable; import org.apache.hadoop.io.text; import org.apache.hadoop.mapreduce.mapper; public class DepartureDelayCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> { // map 출력값 private final static IntWritable outputvalue = new IntWritable(1); // map 출력키 private Text outputkey = new Text(); public void map(longwritable key, Text value, Context context) throws IOException, InterruptedException { if (key.get() > 0) { // 콤마구분자분리 String[] colums = value.tostring().split(","); if (colums!= null && colums.length > 0) { try { // 출력키설정 outputkey.set(colums[0] + "," + colums[1]); if (!colums[15].equals("na")) { int depdelaytime = Integer.parseInt(colums[15]); if (depdelaytime > 0) { // 출력데이터생성 context.write(outputkey, outputvalue);}} } catch (Exception e) { e.printstacktrace();}}}}}
141 DelayCountReducer.java import java.io.ioexception; import org.apache.hadoop.io.intwritable; import org.apache.hadoop.io.text; import org.apache.hadoop.mapreduce.reducer; public class DelayCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> { } private IntWritable result = new IntWritable(); public void reduce(text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable value : values) sum += value.get(); result.set(sum); context.write(key, result); }
142 DepartureDelayCount.java import org.apache.hadoop.conf.configuration; import org.apache.hadoop.fs.path; import org.apache.hadoop.io.intwritable; import org.apache.hadoop.io.text; import org.apache.hadoop.mapreduce.job; import org.apache.hadoop.mapreduce.lib.input.fileinputformat; import org.apache.hadoop.mapreduce.lib.input.textinputformat; import org.apache.hadoop.mapreduce.lib.output.fileoutputformat; import org.apache.hadoop.mapreduce.lib.output.textoutputformat; public class DepartureDelayCount { public static void main(string[] args) throws Exception { Configuration conf = new Configuration(); // 입력출데이터경로확인 if (args.length!= 2) { System.err.println("Usage: DepartureDelayCount <input> <output>"); System.exit(2); } // Job 이름설정 Job job = new Job(conf, "DepartureDelayCount"); // 입출력데이터경로설정 FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // Job 클래스설정 job.setjarbyclass(departuredelaycount.class); // Mapper 클래스설정 job.setmapperclass(departuredelaycountmapper.class); // Reducer 클래스설정 job.setreducerclass(delaycountreducer.class); // 입출력데이터포맷설정 job.setinputformatclass(textinputformat.class); job.setoutputformatclass(textoutputformat.class); // 출력키및출력값유형설정 job.setoutputkeyclass(text.class); job.setoutputvalueclass(intwritable.class); } } job.waitforcompletion(true);

143 130304_OutputKey<[0],[1],[8]>
144 130304_OutputKey<[0],[1],[8]>


145 MultipleOutput Hadoop: The Definitive Guide 217p 추가참고예정 org.apache.hadoop.mapreduce.lib.output.multipleoutputs 다수의파일출력 MultipleOutputs는여러개의 OutputCollectors를만들고각 OutputCollectors에대한출력경로, 출력포맷, 키와값유형을설정함 TASK: 기본으로 MULTIPLEOUTPUT 실행후코드변경하여 3개의파일이출력되도록해보기 if문추가하여변수추가
146 GenericOptionsParser, Tool, ToolRunner 131p( 노란하둡 ), 135p(The Defivitive guide)
147 GenericOptionsParser, Tool, ToolRunner( 사용자정의옵션 ) org.apache.hadoop.util 패키지에개발자가편리하게맵리듀스프로그램을개발할수있도록하는다양한핼퍼클래스가있음 GenericOptionsParser, Tool, ToolRunner 클래스를이용해 Job을실행할때환경설정정보확인, 잡드라이버클래스에서환경정보를수정할수있음 현재예제에서세가지옵션을이용하여구현한사항은다음과같음 DelayCount 에서입력이 A 일땐도착지연건수를, D 는출발지연건수를출력하는옵션
148 GenericOptionsParser 하둡콘솔명령어에서입력한옵션을분석하는클래스 사용자가하둡콘솔명령어에서네임노드, 잡트래커추가구성자원등을설정할수있는여러가지옵션을제공 GenericOptionsParser 클래스는내부적으로 Configuration 객체를만들어생성자에게전달받은환경설정정보를설정함 옵션 -conf< 파일명 > -D< 옵션 = 값 > -fs< 네임노드호스트 : 네임노드포트 > -jt< 잡트래커호스트 : 잡트래커포트 > -files< 파일 1, 파일 2,, 파일 n> 기능 명시한파일을환경설정에있는리소스정보에추가 하둡환경설정파일에있는옵션에새로운값을설정 네임노드를새롭게설정 잡트래커를새롭게설정 로컬에있는파일을 HDFS 에서사용하는공유파일시스템으로복사 -libjars<jar 파일 1, JAR 파일 2,,JAR 파일 n> 로컬에있는 JAR 파일을 HDFS 에서사용하는공유파일시스템으로복사하고, 맵리듀스의태스크클래스패스에추가 -archives< 아카이브파일 1, 아카이브파일 2,, 아카이브파일 n> 로컬에있는아카이브파일을 HDFS 에서사용하는공유파일시스템으로복사한후압축을풉니다.
149 Tool GenericOptionsParser 의콘솔설정옵션을지원하기위한인터페이스 GenericOptionsParser 가사용하는 Configuration 객체를상속받음
150 ToolRunner GenericOptionsParser를내부적으로선언한 ToolRunner 클래스 Tool인터페이스의실행을도와주는헬퍼클래스 즉, Configuration 객체를 Tool 인터페이스에전달한후, Tool 인터페이스의 run메서드를실행함
151 체인 하나의맵리듀스잡에서여러개의매퍼와리듀서를실행할수있게체인매퍼 (ChainMapper) 와체인리듀서 (ChainReducer) 제공 체인을이용하면입출력이감소할것임 매퍼1 매퍼2 리듀서 매퍼3 매퍼4의경우각 job에서나오는출력 key, value값이그다음매퍼혹은리듀서의입력 key, value가됨
152 정렬 (sorting) 보조정렬 (Secondary Sort) 부분정렬 (Partial Sort) 전체정렬 (Total Sort)
 를정의. 이때키값중어떤키를그룹핑키로사용할지결정 2. 복합키의레코드를정렬하기위한비교기 (Comparator) 를정의 3. 그룹핑키를파티셔닝할파티셔너 (Partitioner) 를정의 4.")
153 보조정렬 (Secondary Sort) 항공운항데이터분석결과를보면 월 의순서가제대로처리되지않았음 의순서로처리되어있음 Key 값이연도와월이합쳐진하나의문자열로인식되었기때문 보조정렬 Key의값들을그룹핑하고, 그룹핑된레코드에순서를부여하는방식 1. 기존 key의값들을조합한복합키 (composit key) 를정의. 이때키값중어떤키를그룹핑키로사용할지결정 2. 복합키의레코드를정렬하기위한비교기 (Comparator) 를정의 3. 그룹핑키를파티셔닝할파티셔너 (Partitioner) 를정의 4. 그룹핑키를정렬하기위한비교기 (Comparator) 를정의
154 보조정렬 (Secondary Sort) Task: 항공운항지연데이터의결과를월순서로정렬하기 복합키의연도를그룹키로사용 연도별로그룹핑된데이터들은월의순서대로정렬 1. 복합키구현 복합키란기존키값을조합한일종의키집합클래스 현재까지의출력key는단순한하나의문자열 복합키를적용하면연도와월이각각멤버변수로정의됨 WritableComparable 인터페이스 파라미터는바로자신인 DateKey로설정 여기엔세가지메서드가구현되어있어야함 readfields : 입력스트림에서연도와월을조회 write: 출력스트림에연도와월을출력 compareto : 복합키와복합키를비교해서순서정할때사용 연도는 string타입, 월은 integer타입 & setter와 getter 메서드를함께구현해야함 tostring 메서드를호출하여출력양식을구현하여값을출력 정의하지않으면자바에서사용하는클래스식별자가출력됨
155 보조정렬 (Secondary Sort) 2. 복합키비교기구현 복합키의정렬순서를부여하기위한클래스 두개의복합키를비교하며각멤버변수를비교해정렬순서를정함 WritableComparator를상속받아비교기구현 compare 메서드 : 기본으로객체를스트림에서조회한값을비교하게되므로정확한정렬순서반영하지못함. 그래서이메서드를재정의해서멤버변수를비교하는로직을구현해야함 compare 메서드에서파라미터로전달받은객체 w1, w2를 DateKey에서선언한멤버변수를조회하기위해 DateKey클래스로변환함 ( DateKey k1 = (DateKey) w1; ) 연도값비교 String 클래스에서제공하는 compareto 메서드사용하여 k1 == k2 일때 0, k1 > k2 일때 1, k1 < k2 일때 -1 임. 이건 compareto 메서드에정의되어있는것 Year에대해선같은연도안에서월의순서가정렬되어야하니까, 일치하기만하면월의정렬을하는코드로이동! 실제연도값을정렬하는건 그룹키비교기 에서함 월값비교 k1 == k2 일때 0, k1 > k2 일때 1, k1 < k2 일때 -1 을똑같이이용하여오름차순으로정렬 월값은 integer이므로 compareto 메서드를사용하는게아니라수동으로규칙을입력하여정렬
156 보조정렬 (Secondary Sort) 3. 그룹키파티셔너구현 파티셔너는맵태스크의출력데이터를리듀스태스크의입력데이터로보낼지결정함 이렇게파티셔닝된데이터는맵태스크의출력데이터의 key, value값에따라정렬됨 그룹핑키로사용하는연도에대한파티셔닝을수행함 Partitioner를상속받아구현해야함 두개의파라미터는 mapper 출력데이터의 key와 value getpartition 메서드로파티셔닝번호를조회하고, 재정의해서구현후연도에대한해시코드를조회해파티션번호생성 4. 그룹키비교기구현 같은연도에해당하는모든데이터를하나의 REDUCER 그룹에서처리할수있음 복합키비교기처럼 WritableComparator를상속받아클래스선언
157 보조정렬 (Secondary Sort) 위의네가지의 job을적용하여매퍼와리듀서를작성함 문제사항 : 리듀서에서 count를합산할경우데이터에오류발생 (171p) 2008년도데이터를처리할때, 2008년 12월만출력되고, 카운트는 2008년모든카운트가합산되어출력됨 그이유는 year정보인그룹키를기준으로연산을수행하기때문 이를해결하기위해복합키를구분해서처리해야하고, 그를위한것으로백업month (bmonth) 를이용해서데이터를나누어야함 bmonth와현재들어온 key.getmonth() 를비교해서일치하지않으면 bmonth의카운트를출력하는방식 다음순서의월의카운트를합산하기위해 sum변수를 0으로초기화함


158 보조정렬 (Secondary Sort) Ex. arrival_delay_count
159 부분정렬 (Partial Sort) 매퍼의출력데이터 ( 파티셔닝된것 ) 를맵파일 (MapFile) 로변경해서데이터를검색하는방법 특정키에대한데이터를검색할경우, 해당키에대한데이터가저장된맵파일에접근해서데이터를조회함 Task: 미국항공지연통계데이터를항공운항거리순서대로정렬하는부분정렬프로그램 1. 입력데이터를시퀀스파일로생성 2. 시퀀스파일을맵파일로변경 3. 맵파일에서데이터를검색



160 부분정렬 (Partial Sort) 1. 시퀀스파일생성 미국항공운항데이터를시퀀스파일로출력 이시퀀스파일은다음단계에서맵파일로변환됨 2008년도데이터를대상으로시퀀스파일생성 첫행은컬럼명이써져있기때문에출력하지않음 키를운항거리, 값은쉼표로구분된데이터들이출력됨 클래스입출력구분키값 매퍼입력오프셋 (LongWritable) 항공운항통계데이터 (Text) 출력운항거리 (IntWritable) 항공운항통계데이터 (Text)

161 부분정렬 (Partial Sort) 2. 맵파일생성 맵파일 : 키값을검색할수있게색인과함께정렬된시퀀스파일 물리적으로색인이저장된 index파일과데이터내용이저장돼있는 data 파일로구성됨 앞에서생성된시퀀스파일을변환해맵파일로생성할수있음 운항거리를기준으로정렬되어맵파일이출력됨

162 부분정렬 (Partial Sort) 3. 검색프로그램구현 맵파일에서우리가원하는키에해당하는값을검색하는방법 검색의 키 는 파티셔너 임 검색하고자하는키가속하는파티션번호를조회한후, 파티션번호로맵파일에접근해데이터를검색
163 전체정렬 (Total Sort) 하나의파티션만사용해서쉽게해결가능 모든맵리듀스잡은입력데이터의키를기준으로정렬하므로단일파티션에모든데이터가정렬되어출력됨 데이터가클때하나의파티션만사용해서정렬하면리듀스태스크가실행되는데이터노드만부하가집중될것임 전체정렬 ( 분산처리의장점을살리는방법 ) 입력데이터를샘플링해서데이터의분포도를조사 데이터의분포도에맞게파티션정보를미리생성 미리생성한파티션정보에맞게출력데이터를생성 각출력데이터를병합 org.apache.hadoop.mapred.lib.totalorderpartitioner, InputSampler 제공 TotalOrderPartitioner로파티션개수와파티션에저장할데이터범위설정가능 InputSampler로파티션에키를고르게배분, 입력데이터에서특정개수의데이터를추출해서키와데이터건수를샘플링함 ( 즉, 데이터의분포도를작성 ) TotalOrderPartitioner는이러한샘플링결과를기준으로파티션생성 맵리듀스잡은생성된파티션에출력데이터를생성
164 reference [1] 김철연, 맵리듀스환경에서웨이블릿시놉시스생성알고리즘, 정보과학회논문지, 제 39 권 26 호,
165 데이터분석 Query 언어 2015
166 Content 성능과생산성 프레임워크별동향 HIVE 실습
,")
167 Hadoop 성능과생산성 Yahoo 단일클러스터 하둡은 SQL언어를사용할수있음 (Hive에서 HiveQL이라는쿼리언어제공 ) 4000 Nodes, 2Quad Cores 4 x 1TB SATA Disk per Node 8GB RAM, 1GB Link(8GB Up), 40Nodes Rack

168 성능과생산성 Hadoop 성능 Jim Grey s Sort 벤치마크테스트 2008년 : 1TB 209초신기록 2009년 : 1TB 62초, 1PB 16.25시간 3800대클러스터, 서버별 8Cores & 8GB RAM

169 성능과생산성 Hadoop 생산성 18 ~ 25 세연령대의사용자가가장많이방문하는사이트 5 개를찾아라

170 성능과생산성 Hadoop 생산성 직접 MapReduce 프로그램을코딩할경우
171 성능과생산성 Hadoop 생산성 사용자보다는개발자중심 중복된코딩및노력의반복 실행을위한버전관리, 환경설정의복잡성 개발생산성개선필요
172 성능과생산성 고차원병렬처리언어 쉬운 MapReduce 를위한병렬처리언어 Pig by Yahoo Hive by FaceBook Top 5 사이트찾기를병렬처리언어로 Users = load users as (name, age); Fltrd = filter Users by age >= 18 and age <= 25; Pages = load pages as (user, url); Jnd = join Fltrd by name, Pages by user; Grpd = group Jnd by url; Smmd = foreach Grpd generate group, COUNT(Jnd) as clicks; Srtd = order Smmd by clicks desc; Top5 = limit Srtd 5; store Top5 into top5sites ;
173 프레임워크별동향 Google Sawzall 절차형프로그래밍언어 Google 에서가장많이사용되는언어 단일클러스터에서만월간 3PB 데이터처리 (2005 년 ), 일 1000 개이상의작업 (220 대 ) Pig, Hive 등의 Role Model 아파치 Pig 데이터처리를위한고차원언어 아파치 Top-Level 프로젝트 Yahoo 내 Hadoop 작업의 30% 2007 년배포이후 2~10 배성능개선 Native 대비 70 ~ 80 % 성능
174 프레임워크별동향 아파치 Hive 데이터웨어하우징 & 분석인프라 아파치 Top-Level 프로젝트 분석을위한 SQL 기반 Query 저장은 Hadoop DFS 사용 Query 내 Hadoop Streaming 연동 JDBC 지원 FaceBook 주도로개발 Hive 클러스터 at FaceBook 약 5,000여대의하둡클러스터 분석작업에 Hive 사용 수 PB 데이터압축관리 매일수백TB 이상데이터처리
175 프레임워크별동향 아파치 Hive Hive 개발동기 벤더데이터웨어하우스시스템교체 데이터확장성문제 ( 최초 10GB -> 수십TB) 라이선스등운영비용절감 벤더 DBMS 에서 Hadoop 으로교체결정 교체과정에서나타난필요기능을개발 사용자를위한 CLI 코딩없이 Ad-hoc 질의를할수있는기능 스키마정보들의관리
176 HIVE
177 HIVE Hive 구조 하이브클라이언트 CLI JDBC/ODBC/ 쓰리프트 웹인터페이스 하이브서버 드라이버 (Parser, Planner, Optimizer 메타스토어 Hadoop
178 HIVE Hive 내부
179 HIVE Metastore 데이터베이스 : 테이블들의네임스페이스 테이블속성보관 ( 타입, 물리적인배치 ) 데이터파티셔닝 JPOX 를지원하는 Derby, MySQL 등의다른일반 RDMBS 를사용가능
 데이터파티셔닝 JPOX")


180 HIVE Metastore 데이터베이스 : 테이블들의네임스페이스 테이블속성보관 ( 타입, 물리적인배치 ) 데이터파티셔닝 JPOX 를지원하는 Derby, MySQL 등의다른일반 RDMBS 를사용가능
181 HIVE Hive 언어모델 DDL (Data Definition Language) 테이블생성, 삭제, 변경 테이블및스키마조회 DML (Data Manipulation Language) 로컬 to DFS 업로드 Query 결과 to 테이블, 로컬, DFS Query Select, Group By, Sort By Join, Union, Sub Queries, Sampling,Trasform
182 HIVE Hive 데이터모델 테이블 컬럼타입지원 ( 정수, 실수, 문자열, 날짜등 ) 리스트나 Map 같은 Collection 타입도지원 파티션 예 ) 날짜기간에의한파티션등 Buckets 범위내에서해쉬파티션지원 (Sampling 및최적화된 Join 가능 )
183 HIVE 물리적인배치 HDFS 내의 warehouse 디렉토리 예 ) /user/hive/warehouse 테이블들은 warehouse 의서브디렉토리 Partitions 과 buckets 은테이블들의서브디렉토리 실제데이터는 Flat File 들로저장 구분자로분리된텍스트형식 SerDe 를통해임의의포맷지원가능
184 HIVE 물리적인배치 HDFS 내의 warehouse 디렉토리 예 ) /user/hive/warehouse 테이블들은 warehouse 의서브디렉토리 Partitions 과 buckets 은테이블들의서브디렉토리 실제데이터는 Flat File 들로저장 구분자로분리된텍스트형식 SerDe 를통해임의의포맷지원가능 SEQUENCEFILE, RCFILE, ORC, PARQUET
185 HIVE 파일포맷 항목텍스트파일시퀀스파일 RC 파일 ORC 파일파케이 저장기반로우기반로우기반칼럼기반칼럼기반칼럼기반 압축 파일압축 레코드 / 블록압축 블록압축블록압축블록압축 스플릿지원지원지원지원지원지원 압축적용시스플릿지원미지원지원지원지원지원 하이브키워드 TEXTFILE SEQUENCEFILE RCFILE ORCFILE PARQUET
186 HIVE 파일포맷사용 시퀀스파일 CREATE TABLE table_ex() ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.lazysimpleserde' STORED AS SEQUENCEFILE; CREATE TABLE table_ex() ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazybinary.lazybinaryserde' STORED AS SEQUENCEFILE;
187 HIVE 파일포맷사용 RC 파일 CREATE TABLE table_ex() ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.columnar.columnarserde' STORED AS RCFILE; CREATE TABLE table_ex() ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.columnar.lazybinarycolumnarser de' STORED AS RCFILE;
188 HIVE 파일포맷사용 ORC 파일 CREATE TABLE table_ex() STORED AS ORC tblproperties() ;
189 HIVE 파일포맷사용 파케이 CREATE TABLE table_parquet( id int, str string, mp MAP<STRING,STRING>, lst ARRAY<STRING>, strct STRUCT<A:STRING,B:STRING>) PARTITIONED BY (part string) STORED AS PARQUET;
190 HIVE 실습 2015

191 HIVE 실습 Hive 환경구성 Hive 다운로드 접속후다운로드 압축을풀고 hadoop 심볼릭링크를생성 $ tar zxvf apache-hive $ ln -s apache-hive hive.bash_profile에 HIVE_HOME과 PATH 추가
192 HIVE 실습 Hive metastore MySQL 설치 ~]$ su - root [root@hadoop01 ~]$yum install mysql-server [root@hadoop01 ~]$ mysqladmin -u root password hadoop [root@hadoop01 ~]$ service mysqld start [root@hadoop01 ~]$ chkconfig mysqld on [hadoop@hadoop01 ~]$ wget [hadoop@hadoop01 ~]$ tar -zxvf./mysql-connector-java tar.gz [hadoop@hadoop01 ~]$ cp./mysql-connector-java /mysql-connector-java bin.jar /home/hadoop/hive/lib/ [hadoop@hadoop01 ~]$mysql u root p mysql> grant all privileges on *.* to hive@localhost identified by 'hive' with grant option; mysql> flush privileges; mysql> grant all privileges on *.* to hive@'%' identified by 'hive' with grant option; mysql> flush privileges;
193 HIVE 실습 Hive-site <configuration> <property> <name>javax.jdo.option.connectionurl</name> <value>jdbc:mysql://hadoop01/hive?createdatabaseifnotexist=true</value> </property> <property> <name>javax.jdo.option.connectiondrivername</name> <value>com.mysql.jdbc.driver</value> </property> <property> <name>javax.jdo.option.connectionusername</name> <value>hive</value> </property> <property> <name>javax.jdo.option.connectionpassword</name> <value>hive</value> </property> <property> <name>hive.metastore.uris</name> <value>thrift://hadoop01:9083</value> </property> <property> <name>hive.hwi.listen.host</name> <value> </value> </property> <property> <name>hive.hwi.listen.port</name> <value>9999</value> </property> <property> <name>hive.hwi.war.file</name> <value>lib/hive-hwi war</value> </property> </configuration>
194 HIVE 실습 Hive 실행 hive]$./bin/hive --service metastore hive]$./bin/hive --service hiveserver2 hive 접속 hive]$ beeline Beeline version by Apache Hive beeline>!connect jdbc:hive2://hadoop01: : jdbc:hive2://hadoop01:10000>
195 HIVE 실습 테이블생성 0: jdbc:hive2://hadoop01:10000>create TABLE IF NOT EXISTS stocks(`exchange` STRING, symbol STRING, ymd STRING, price_open FLOAT, price_high FLOAT, price_low FLOAT, price_close FLOAT, volume INT, price_adj_close FLOAT) ROW FORMAT DELIMITED FIELDS TERMINATED BY ','; 0: jdbc:hive2://hadoop01:10000>desc stocks ;
196 HIVE 실습 데이터업로드 0: jdbc:hive2://hadoop01:10000> load data local inpath '/home/hadoop/sample_data/nasdaq/nasdaq_daily_price*' overwrite into table stocks; stocks;0: jdbc:hive2://hadoop01:10000> load data local inpath '/home/hadoop/sample_data/nyse/nyse_daily_prices*' into table stocks;
197 HIVE 실습 Simple query / Group by 데이터갯수확인 0: jdbc:hive2://hadoop01:10000>select count(*) FROM stocks; 뉴욕거래소및나스닥전체업종수 0: jdbc:hive2://hadoop01:10000>select count(distinct symbol) FROM stocks; 애플의각연도별종가평균 0: jdbc:hive2://hadoop01:10000>select year(ymd), avg(price_close) FROM stocks WHERE `exchange` = 'NASDAQ' AND symbol = 'AAPL GROUP BY year(ymd); 2010 장종가평균상위 5 개업체 0: jdbc:hive2://hadoop01:10000>select symbol, avg(price_open) as openprice from stocks where year(ymd) = '2010' group by symbol sort by openprice DESC limit 5
198 HIVE 실습 View Table View Table 은자주사용되는쿼리를일종의로지컬테이블처럼사용하는것. 복잡한쿼리를단순하게함 RAW table 로직접접근하는것이아니라제한을두는목적으로도사용함 테이블의모듈화에적합
199 HIVE 실습 View Table 0: jdbc:hive2://hadoop01:10000>select s2.year, s2.avg FROM (SELECT year(ymd) AS year, avg(price_close) AS avg FROM stocks WHERE `exchange` = 'NASDAQ' AND symbol = 'AAPL' GROUP BY year(ymd)) s2 WHERE s2.avg > 50.0; 0: jdbc:hive2://hadoop01:10000>create view stockview AS SELECT year(ymd) AS year, avg(price_close) AS avg FROM stocks WHERE `exchange` = 'NASDAQ' AND symbol = 'AAPL' GROUP BY year(ymd); 0: jdbc:hive2://hadoop01:10000>select stockview.year, stockview.avg from stockview where stockview.avg > 50; 0: jdbc:hive2://hadoop01:10000>
200 HIVE 실습 Partition partition 테이블만들기 0: jdbc:hive2://hadoop01:10000>create TABLE IF NOT EXISTS stocks_part ( ymd STRING, price_open FLOAT, price_high FLOAT, price_low FLOAT, price_close FLOAT, volume INT, price_adj_close FLOAT) PARTITIONED by ( exchange STRING, symbol STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
201 HIVE 실습 Partition partition 테이블과일반테이블
202 HIVE 실습 Partition partition 테이블에데이터로드 0: jdbc:hive2://hadoop01:10000>insert OVERWRITE TABLE stocks_part PARTITION(`exchange`='NASDAQ', symbol ='AAPL') SELECT ymd,price_open,price_high,price_low,price_close,volume int,price_adj_close FROM stocks WHERE `exchange` = 'NASDAQ' and symbol='aapl'; 확인 0: jdbc:hive2://hadoop01:10000>show partitions stocks_part;
203 HIVE 실습 다이니믹 Partition 설정 ( 기본값 ) hive.exec.dynamic.partition.mode=strict; hive.exec.dynamic.partition = false; hive.exec.max.dynamic.partitions.pernode=100; hive.exec.max.dynamic.partitions=1000; hive.exec.max.created.files=100000; partition 테이블에데이터로드 0: jdbc:hive2://hadoop01:10000>insert OVERWRITE TABLE stocks_part PARTITION(`exchange`, symbol) SELECT ymd,price_open,price_high,price_low,price_close,volume int,price_adj_close,`exchange`,symbol FROM stocks;
204 HIVE 실습 색인 데이터베이스의특정컬럼에대해검색가능한형태인자료구조를만드는것 I/O 의범위를전체적으로줄여주는역할을한다 색인자체가기본적인정렬이되어있기때문에검색시간도줄어든다
205 HIVE 실습 색인 table 에색인생성 symbol 컬럼에색인생성 0: jdbc:hive2://hadoop01:10000>create INDEX simple_index ON TABLE stocks (symbol) AS 'org.apache.hadoop.hive.ql.index.compact.compactindexhandler' WITH DEFERRED REBUILD; index 확인 0: jdbc:hive2://hadoop01:10000>show FORMATTED INDEX ON stocks; query 수행 0: jdbc:hive2://hadoop01:10000>select s2.year, s2.avg FROM (SELECT year(ymd) AS year, avg(price_close) AS avg FROM stocks WHERE symbol = 'AAPL' GROUP BY year(ymd)) s2 WHERE s2.avg > 50.0;
206 HIVE 실습 색인 인덱스생성 0: jdbc:hive2://hadoop01:10000>alter index simple_index on stocks rebuild; 필요한파일만다시로드 0: jdbc:hive2://hadoop01:10000>insert OVERWRITE DIRECTORY "/tmp/index_result" SELECT `_bucketname`, `_offsets` FROM default stocks_simple_index where symbol='aapl'; 기존테이블과연결 0: jdbc:hive2://hadoop01:10000>set hive.index.compact.file=/tmp/index_result; 0: jdbc:hive2://hadoop01:10000>set hive.input.format=org.apache.hadoop.hive.ql.index.compact.hivecompactindexinputfor mat; query 수행 0: jdbc:hive2://hadoop01:10000>select s2.year, s2.avg FROM (SELECT year(ymd) AS year, avg(price_close) AS avg FROM stocks WHERE symbol = 'AAPL' GROUP BY year(ymd)) s2 WHERE s2.avg > 50.0;

207 HIVE 실습 UDF Before Writing UDF, internal Function is also UDF 0: jdbc:hive2://hadoop01:10000> show functions; 함수의정의를보려면 describe 사용 0: jdbc:hive2://hadoop01:10000> describe function abs;
208 HIVE 실습 UDF 종류 Standard Function UDAF UDF UDAF(User Defined Aggregation Function) Generic UDAF UDTF(User Defined Table generation Funtion)
209 HIVE 실습 UDF 종류 standard function ( 표준함수 ) 하나의로우 (row) 나다수의컬럼으로부터데이터를받아서처리 floor(), ucase(), concat() 과같은간단한함수
210 HIVE 실습 UDF 종류 UDAF(User Defined Aggregation Function) 사용자집계 (aggregation) 함수 하나이상의 raw 와 column 으로부터데이터를받아와서계산을수행하는함수 SELECT year(ymd), avg(price_close) FROM stocks WHERE exchange = 'NASDAQ' AND symbol = 'AAPL'GROUP BY year(ymd);
211 HIVE 실습 UDF 종류 UDTF(User Defined TablegenerationFunction) 하나의변수나컬럼을입력받아다수개의테이블로 (row) 를만드는모든함수 SELECT explode(array(1,2,3)) AS element FROM src;
212 HIVE 실습 UDF 예제 APPL 을 APPLE 로변환하는예제. package hive.udf.sample; import java.text.simpledateformat; import org.apache.hadoop.hive.ql.exec.description; import value = "_FUNC_(name)- from the input string"+" returns Fullname ", extended = "Example _Func_('aaple') from src;\n") public class Fullname extends UDF{ public Fullname (){ SimpleDateFormat df = new SimpleDateFormat("MM-dd-yyyy"); } public String evaluate(string shortname) { if( "aapl".equals(shortname) "AAPL".equals(shortname)) { return "AAPLE"; } else return shortname; } }
213 HIVE 실습 UDF 예제 UDF 등록 0: jdbc:hive2://hadoop01:10000> ADD JAR /home/hadoop/share/fullname.jar; 0: jdbc:hive2://hadoop01:10000> CREATE TEMPORARY FUNCTION fullname AS 'hive.udf.sample.fullname'; UDF 사용 0: jdbc:hive2://hadoop01:10000>describe function fullname; 0: jdbc:hive2://hadoop01:10000>describe FUNCTION EXTENDED fullname; 0: jdbc:hive2://hadoop01:10000>select ymd,fullname(symbol) FROM Stocks where symbol='aapl';
214 Flume 2015
215 Content Introduction 실습
 Header 는 key/value 형태이며, 라우팅을결정하거나, 구조화된정보 ( 예를들어, 이벤트가발생된서버의호스트명,")
216 Flume Event Flume 을통해전달되어지는데이터의기본 payload 를 event 라부른다. Event 는 O 이상의 Header 와 body 영역으로나뉜다. (Byte payload + set of string headers) Header 는 key/value 형태이며, 라우팅을결정하거나, 구조화된정보 ( 예를들어, 이벤트가발생된서버의호스트명, timestamp 등추가가능 ) 를운반할때활용된다

217 Flume Agent
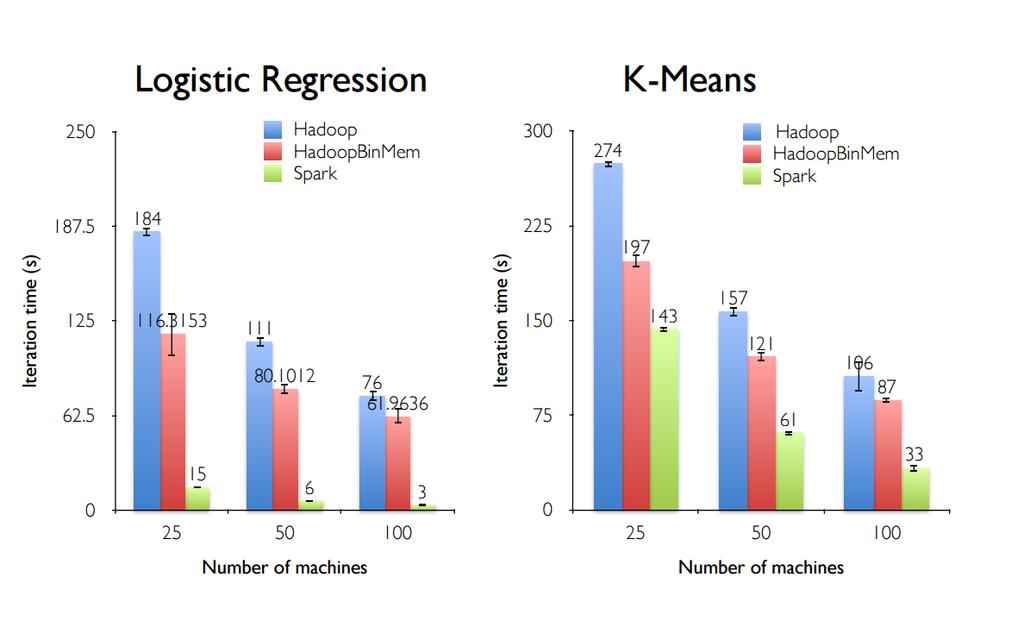
218 Flume Agent Source avro : Avro 클라이언트에서전송하는이벤트를입력으로사용, Agent 와 Agent 를연결해줄때유용 netcat : TCP 로라인단위수집 seq : 0 부터 1 씩증가하는 EVENT 생성 exec : System Command 를수행하고출력내용을수집 syslogtcp : System 로그를입력으로사용 spooldir : Spooling Directory 디렉토리에새롭게추가되는파일을데이터로사용 thirft : Thrift 클라이언트에서전송하는이벤트를입력으로사용 jms : JMS 메시지수집 Customize
219 Flume Agent Channel memory : Source 에서받은이벤트를 Memory 에가지고있는구조로, 간편하고빠른고성능 (High Throughput) 을제공하지만이벤트유실가능성이있다. 즉, 프로세스가비정상적으로죽을경우데이터가유실될수있다. jdbc : JDBC 로저장 file : JDBC 와마찬가지로속도는 Memory 기반에비해느리지만, 프로세스가비정상적으로죽더라도 transactional 하게프로세스를재시작하여재처리하여이벤트유실이없는것이장점이있다. Customize
220 Flume Agent Sink null : 이벤트를버림 logger : 테스트또는디버깅을위한로깅 avro : 다른 Avro 서버 (Avro Source) 로이벤트전달 hdfs : HDFS에저장 hbase : HBase에저장 elasticsearch : 이벤트를변환해서 ElasticSearch에저장 file_roll : 로컬파일에저장 thrift : 다른 Thrift 서버 (Thrift Source) 로이벤트전달 Customize
221 Flume Flow 설정 To Define flow, link source and sink via channel # list the sources, sinks and channels for the agent <Agent>.sources = <Source> <Agent>.sinks = <Sink> <Agent>.channels = <Channel1> <Channel2> # set channel for source <Agent>.sources.<Source>.channels = <Channel1><Channel2>... # set channel for sink <Agent>.sinks.<Sink>.channel = <Channel1>
222 Flume 활용 하둡클러스터내노드들의로그수집 웹서버, 메일서버같은기존시스템들의로그수집 광고네트워크애플리케이션들의노출정보수집 시스템들의성능정보수집 기본적인온라인스트리밍분석
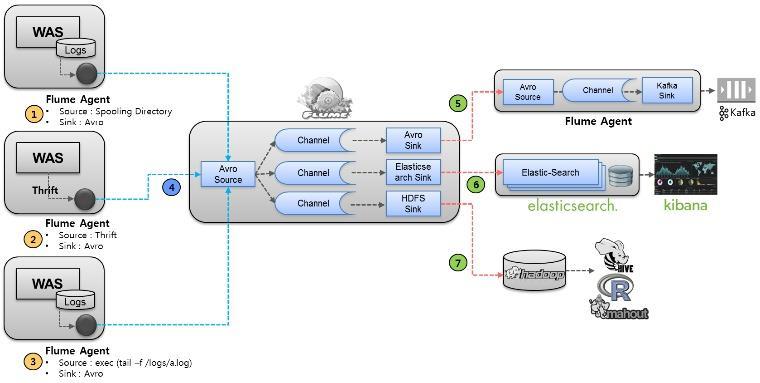
223 Flume 활용
224 Flume 실습
225 sqoop 2015
226 Content Introduction 실습
227 sqoop Sql to Hadoop RDBMS 로부터수집 / 저장 별도의로그수집시스템및데이터저장소가마련되지않아 Oracle, MySQL 등의 RDBMS 에로그를저장하는경우. 로그뿐아니라, 메타성데이터는대부분 RDBMS 에저장되어있는데, 이 RDBMS 의메타데이터를 Hadoop, Hive 등으로옮겨야하는경우 분산환경의 Hadoop, Hive 등에서분석된결과를 API 형태가아닌원격의 RDBMS 로전송할경우

228 sqoop Sqoop 1 / Sqoop 2
229 sqoop import

230 sqoop Export
231 sqoop 실습
232 Spark 2015
233 Content Introduction
234 Spark 빅데이터분석의시초 GFS(Google File System) 논문 (2003) 여러컴퓨터를연결하여저장용량과 I/O 성능을 scale 이를구현한오픈소스프로젝트인 Hadoop HDFS MapReduce 논문 (2004) Map 과 Reduce 연산을조합하여클러스터에서실행, 큰테이터를처리 이를구현한오픈소스프로젝트인 Hadoop MapReduce Hive MapReduce 코드를짜는건괴롭다 쿼리로 MapReduce 의거의모든기능을표현할수있다! HDFS 등에있는파일을읽어들여쿼리로분석수행 HiveQL 을작성하면 MapReduce 코드로변환되어실행
235 Spark MapReduce / Hive 장단점 장점 빅데이터시대를열어준선구적인기술 거대한데이터를안정적으로처리 많은사람들이사용중 단점 오래된기술이다보니, 발전이느리다 불편한점이많다 MapReduce 의문제점 MapReduce 는 Map 의입출력및 Reduce 의입출력을매번 HDFS 에쓰고, 읽는다 MapReduce 코드는작성하기불편하다


236 Spark M/R vs Spark
237 Spark RDD Resilient Distributed Dataset 탄력적으로분산된데이터셋 클러스터에분산된메모리를활용하여계산되는 List 데이터를어떻게구해낼지를표현하는 Transformation 을기술한 Lineage( 계보 ) 를 interactive 하게만들어낸후, Action 을통해 lazy 하게값을구해냄 클러스터중일부의고장등으로작업이중간에실패하더라도, Lineage 를통해데이터를복구
238 Spark 성능
239 Spark Fast

240 Spark Spark stack Standalone Scheduler YARN Mesos
슬라이드 1
 Hadoop Tutorial - 설치및실행 2008. 7. 17 한재선 (NexR 대표이사 ) jshan0000@gmail.com http://www.web2hub.com H.P: 016-405-5469 Brief History Hadoop 소개 2005년 Doug Cutting(Lucene & Nutch 개발자 ) 에의해시작 Nutch 오픈소스검색엔진의분산확장이슈에서출발
Hadoop Tutorial - 설치및실행 2008. 7. 17 한재선 (NexR 대표이사 ) jshan0000@gmail.com http://www.web2hub.com H.P: 016-405-5469 Brief History Hadoop 소개 2005년 Doug Cutting(Lucene & Nutch 개발자 ) 에의해시작 Nutch 오픈소스검색엔진의분산확장이슈에서출발
슬라이드 1
 Hadoop 기반 규모확장성있는패킷분석도구 충남대학교데이터네트워크연구실이연희 yhlee06@cnu.ac.kr Intro 목차 인터넷트래픽측정 Apache Hadoop Hadoop 기반트래픽분석시스템 Hadoop을이용한트래픽분석예제 - 2- Intro 트래픽이란 - 3- Intro Data Explosion - 4- Global Trend: Data Explosion
Hadoop 기반 규모확장성있는패킷분석도구 충남대학교데이터네트워크연구실이연희 yhlee06@cnu.ac.kr Intro 목차 인터넷트래픽측정 Apache Hadoop Hadoop 기반트래픽분석시스템 Hadoop을이용한트래픽분석예제 - 2- Intro 트래픽이란 - 3- Intro Data Explosion - 4- Global Trend: Data Explosion
DKE Templete
 Apache Hadoop Study 손시운 2017. 01. 11. Department of Computer Science, Kangwon National University 빅데이터 빅데이터란? 기존의시스템에서는관리하기어려운복잡한형태의대용량데이터 또는이러한데이터를처리하기위한기술 빅데이터의정의 : 3V 크기 (Volume) 테라바이트단위의대용량데이터 다양성
Apache Hadoop Study 손시운 2017. 01. 11. Department of Computer Science, Kangwon National University 빅데이터 빅데이터란? 기존의시스템에서는관리하기어려운복잡한형태의대용량데이터 또는이러한데이터를처리하기위한기술 빅데이터의정의 : 3V 크기 (Volume) 테라바이트단위의대용량데이터 다양성
빅데이터분산컴퓨팅-5-수정
 Apache Hive 빅데이터분산컴퓨팅 박영택 Apache Hive 개요 Apache Hive 는 MapReduce 기반의 High-level abstraction HiveQL은 SQL-like 언어를사용 Hadoop 클러스터에서 MapReduce 잡을생성함 Facebook 에서데이터웨어하우스를위해개발되었음 현재는오픈소스인 Apache 프로젝트 Hive 유저를위한
Apache Hive 빅데이터분산컴퓨팅 박영택 Apache Hive 개요 Apache Hive 는 MapReduce 기반의 High-level abstraction HiveQL은 SQL-like 언어를사용 Hadoop 클러스터에서 MapReduce 잡을생성함 Facebook 에서데이터웨어하우스를위해개발되었음 현재는오픈소스인 Apache 프로젝트 Hive 유저를위한
리한다. 그리고오픈소스이기때문에소규모회사및단체에서도무료로사용할수있으며디버깅, 모니터링을위한환경도제공한다. 본보고서에서는 Hadoop의설치를다루었던이전 TR [1] 에이어가상분산처리환경이아닌실제완전분산처리환경을구축하는방법에대해알아본다. 본보고서에서완전분산처리환경을구축하기
![리한다. 그리고오픈소스이기때문에소규모회사및단체에서도무료로사용할수있으며디버깅, 모니터링을위한환경도제공한다. 본보고서에서는 Hadoop의설치를다루었던이전 TR [1] 에이어가상분산처리환경이아닌실제완전분산처리환경을구축하는방법에대해알아본다. 본보고서에서완전분산처리환경을구축하기](/thumbs/70/63962791.jpg "리한다. 그리고오픈소스이기때문에소규모회사및단체에서도무료로사용할수있으며디버깅, 모니터링을위한환경도제공한다. 본보고서에서는 Hadoop의설치를다루었던이전 TR [1] 에이어가상분산처리환경이아닌실제완전분산처리환경을구축하는방법에대해알아본다. 본보고서에서완전분산처리환경을구축하기") 빅데이터분석을위한 Hadoop 설치및활용가이드 (II) Installation and Operation Guide of HADOOP for Big-data Analysis (II) 옥창석 부산대학교컴퓨터공학과, 그래픽스응용연구실 csock@pusan.ac.kr Abstract 본보고서에서는빅데이터분석을위한 Hadoop 설치및활용가이드 (I) [1] 에서다루었던
빅데이터분석을위한 Hadoop 설치및활용가이드 (II) Installation and Operation Guide of HADOOP for Big-data Analysis (II) 옥창석 부산대학교컴퓨터공학과, 그래픽스응용연구실 csock@pusan.ac.kr Abstract 본보고서에서는빅데이터분석을위한 Hadoop 설치및활용가이드 (I) [1] 에서다루었던
HDFS 맵리듀스
 맵리듀스 하둡실행 HDFS 맵리듀스 HDFS 작동방식 FileInputFormat subclass 를이용 Hadoop 은자동으로 HDFS 내의파일경로로부터데이터를입력 블록지역성을최대한활용하는방식 작업을클러스터에배분한다. JAVA 기반 HDFS1 hello.txt 라는이름의파일을생성 메시지를기록한 기록된파일읽어 화면에출력 해당파일이이미존재하는경우삭제한후작업 1:
맵리듀스 하둡실행 HDFS 맵리듀스 HDFS 작동방식 FileInputFormat subclass 를이용 Hadoop 은자동으로 HDFS 내의파일경로로부터데이터를입력 블록지역성을최대한활용하는방식 작업을클러스터에배분한다. JAVA 기반 HDFS1 hello.txt 라는이름의파일을생성 메시지를기록한 기록된파일읽어 화면에출력 해당파일이이미존재하는경우삭제한후작업 1:
쉽게 풀어쓴 C 프로그래밊
 Power Java 제 27 장데이터베이스 프로그래밍 이번장에서학습할내용 자바와데이터베이스 데이터베이스의기초 SQL JDBC 를이용한프로그래밍 변경가능한결과집합 자바를통하여데이터베이스를사용하는방법을학습합니다. 자바와데이터베이스 JDBC(Java Database Connectivity) 는자바 API 의하나로서데이터베이스에연결하여서데이터베이스안의데이터에대하여검색하고데이터를변경할수있게한다.
Power Java 제 27 장데이터베이스 프로그래밍 이번장에서학습할내용 자바와데이터베이스 데이터베이스의기초 SQL JDBC 를이용한프로그래밍 변경가능한결과집합 자바를통하여데이터베이스를사용하는방법을학습합니다. 자바와데이터베이스 JDBC(Java Database Connectivity) 는자바 API 의하나로서데이터베이스에연결하여서데이터베이스안의데이터에대하여검색하고데이터를변경할수있게한다.
슬라이드 1
 빅데이터기술개요 2016/8/20 ~ 9/3 윤형기 (hky@openwith.net) D2 http://www.openwith.net 2 Hadoop MR v1 과 v2 http://www.openwith.net 3 Hadoop1 MR Daemons http://www.openwith.net 4 필요성 Feature Multi-tenancy Cluster Utilization
빅데이터기술개요 2016/8/20 ~ 9/3 윤형기 (hky@openwith.net) D2 http://www.openwith.net 2 Hadoop MR v1 과 v2 http://www.openwith.net 3 Hadoop1 MR Daemons http://www.openwith.net 4 필요성 Feature Multi-tenancy Cluster Utilization
PowerPoint 프레젠테이션
 How Hadoop Works 박영택 컴퓨터학부 HDFS Basic Concepts HDFS 는 Java 로작성된파일시스템 Google 의 GFS 기반 기존파일시스템의상위에서동작 ext3, ext4 or xfs HDFS 의 file 저장방식 File 은 block 단위로분할 각 block 은기본적으로 64MB 또는 128MB 크기 데이터가로드될때여러 machine
How Hadoop Works 박영택 컴퓨터학부 HDFS Basic Concepts HDFS 는 Java 로작성된파일시스템 Google 의 GFS 기반 기존파일시스템의상위에서동작 ext3, ext4 or xfs HDFS 의 file 저장방식 File 은 block 단위로분할 각 block 은기본적으로 64MB 또는 128MB 크기 데이터가로드될때여러 machine
MySQL-.. 1
 MySQL- 기초 1 Jinseog Kim Dongguk University jinseog.kim@gmail.com 2017-08-25 Jinseog Kim Dongguk University jinseog.kim@gmail.com MySQL-기초 1 2017-08-25 1 / 18 SQL의 기초 SQL은 아래의 용도로 구성됨 데이터정의 언어(Data definition
MySQL- 기초 1 Jinseog Kim Dongguk University jinseog.kim@gmail.com 2017-08-25 Jinseog Kim Dongguk University jinseog.kim@gmail.com MySQL-기초 1 2017-08-25 1 / 18 SQL의 기초 SQL은 아래의 용도로 구성됨 데이터정의 언어(Data definition
DBMS & SQL Server Installation Database Laboratory
 DBMS & 조교 _ 최윤영 } 데이터베이스연구실 (1314 호 ) } 문의사항은 cyy@hallym.ac.kr } 과제제출은 dbcyy1@gmail.com } 수업공지사항및자료는모두홈페이지에서확인 } dblab.hallym.ac.kr } 홈페이지 ID: 학번 } 홈페이지 PW:s123 2 차례 } } 설치전점검사항 } 설치단계별설명 3 Hallym Univ.
DBMS & 조교 _ 최윤영 } 데이터베이스연구실 (1314 호 ) } 문의사항은 cyy@hallym.ac.kr } 과제제출은 dbcyy1@gmail.com } 수업공지사항및자료는모두홈페이지에서확인 } dblab.hallym.ac.kr } 홈페이지 ID: 학번 } 홈페이지 PW:s123 2 차례 } } 설치전점검사항 } 설치단계별설명 3 Hallym Univ.
슬라이드 1
 Hadoop Tutorial 2013.2 정재화 Copyright 2013 그루터. All Rights Reserved. 이문서는 그루터의지적자산이므로 그루터의승인없이이문서를임의로배포하거나다른용도로임의변경하여사용할수없습니다. ABOUT ME 현 ) 그루터책임개발자 (http://www.gruter.com ) 전 ) 큐릭스, NHN, 엔씨소프트 E-mail:
Hadoop Tutorial 2013.2 정재화 Copyright 2013 그루터. All Rights Reserved. 이문서는 그루터의지적자산이므로 그루터의승인없이이문서를임의로배포하거나다른용도로임의변경하여사용할수없습니다. ABOUT ME 현 ) 그루터책임개발자 (http://www.gruter.com ) 전 ) 큐릭스, NHN, 엔씨소프트 E-mail:
[Brochure] KOR_TunA
![[Brochure] KOR_TunA](/thumbs/95/123928128.jpg "[Brochure] KOR_TunA") LG CNS LG CNS APM (TunA) LG CNS APM (TunA) 어플리케이션의 성능 개선을 위한 직관적이고 심플한 APM 솔루션 APM 이란? Application Performance Management 란? 사용자 관점 그리고 비즈니스 관점에서 실제 서비스되고 있는 어플리케이션의 성능 관리 체계입니다. 이를 위해서는 신속한 장애 지점 파악 /
LG CNS LG CNS APM (TunA) LG CNS APM (TunA) 어플리케이션의 성능 개선을 위한 직관적이고 심플한 APM 솔루션 APM 이란? Application Performance Management 란? 사용자 관점 그리고 비즈니스 관점에서 실제 서비스되고 있는 어플리케이션의 성능 관리 체계입니다. 이를 위해서는 신속한 장애 지점 파악 /
 Amazon EBS (Elastic Block Storage) Amazon EC2 Local Instance Store (Ephemeral Volumes) Amazon S3 (Simple Storage Service) / Glacier Elastic File Syste (EFS) Storage Gateway AWS Import/Export 1 Instance
Amazon EBS (Elastic Block Storage) Amazon EC2 Local Instance Store (Ephemeral Volumes) Amazon S3 (Simple Storage Service) / Glacier Elastic File Syste (EFS) Storage Gateway AWS Import/Export 1 Instance
PowerPoint Presentation
 Class - Property Jo, Heeseung 목차 section 1 클래스의일반구조 section 2 클래스선언 section 3 객체의생성 section 4 멤버변수 4-1 객체변수 4-2 클래스변수 4-3 종단 (final) 변수 4-4 멤버변수접근방법 section 5 멤버변수접근한정자 5-1 public 5-2 private 5-3 한정자없음
Class - Property Jo, Heeseung 목차 section 1 클래스의일반구조 section 2 클래스선언 section 3 객체의생성 section 4 멤버변수 4-1 객체변수 4-2 클래스변수 4-3 종단 (final) 변수 4-4 멤버변수접근방법 section 5 멤버변수접근한정자 5-1 public 5-2 private 5-3 한정자없음
About me 현 ) 그루터 (www.gruter.com) 책임개발자 전 ) 큐릭스, NHN, 엔씨소프트 저서 ) 시작하세요! 하둡프로그래밍 : 기초부터실무
 그루터 (www.gruter.com) 책임개발자 전 ) 큐릭스, NHN, 엔씨소프트 저서 ) 시작하세요! 하둡프로그래밍 : 기초부터실무") 맵리듀스퍼포먼스튜닝하기 2012.11 정재화 이저작물은크리에이티브커먼즈코리아저작자표시 - 비영리 - 변경금지 2.0 대한민국라이선스에따라이용하실수있습니다. About me jhjung@gruter.com 현 ) 그루터 (www.gruter.com) 책임개발자 전 ) 큐릭스, NHN, 엔씨소프트 www.blrunner.com www.twitter.com/blrunner78
맵리듀스퍼포먼스튜닝하기 2012.11 정재화 이저작물은크리에이티브커먼즈코리아저작자표시 - 비영리 - 변경금지 2.0 대한민국라이선스에따라이용하실수있습니다. About me jhjung@gruter.com 현 ) 그루터 (www.gruter.com) 책임개발자 전 ) 큐릭스, NHN, 엔씨소프트 www.blrunner.com www.twitter.com/blrunner78
Spring Boot/JDBC JdbcTemplate/CRUD 예제
 Spring Boot/JDBC JdbcTemplate/CRUD 예제 오라클자바커뮤니티 (ojc.asia, ojcedu.com) Spring Boot, Gradle 과오픈소스인 MariaDB 를이용해서 EMP 테이블을만들고 JdbcTemplate, SimpleJdbcTemplate 을이용하여 CRUD 기능을구현해보자. 마리아 DB 설치는다음 URL 에서확인하자.
Spring Boot/JDBC JdbcTemplate/CRUD 예제 오라클자바커뮤니티 (ojc.asia, ojcedu.com) Spring Boot, Gradle 과오픈소스인 MariaDB 를이용해서 EMP 테이블을만들고 JdbcTemplate, SimpleJdbcTemplate 을이용하여 CRUD 기능을구현해보자. 마리아 DB 설치는다음 URL 에서확인하자.
Microsoft PowerPoint - 알고리즘_5주차_1차시.pptx
 Basic Idea of External Sorting run 1 run 2 run 3 run 4 run 5 run 6 750 records 750 records 750 records 750 records 750 records 750 records run 1 run 2 run 3 1500 records 1500 records 1500 records run 1
Basic Idea of External Sorting run 1 run 2 run 3 run 4 run 5 run 6 750 records 750 records 750 records 750 records 750 records 750 records run 1 run 2 run 3 1500 records 1500 records 1500 records run 1
<4D6963726F736F667420506F776572506F696E74202D20B8F9B0EDB5F0BAF15F32B1E220BDC9C8ADB0FAC1A4>
 HDFS, MapReduce 작성자 김성진(황금의미르) HDFS, MapReduce 문서번호 : HDFS, MapReduce 버전 : 1.0 목차 1. HDFS ----------------- 2 2. MapReduce ----------------- 11 3. 기타 1 2기 심화과정 스터디그룹 1. HDFS 1.1 HDFS는 무엇인가요? 1. HDFS(Hadoop
HDFS, MapReduce 작성자 김성진(황금의미르) HDFS, MapReduce 문서번호 : HDFS, MapReduce 버전 : 1.0 목차 1. HDFS ----------------- 2 2. MapReduce ----------------- 11 3. 기타 1 2기 심화과정 스터디그룹 1. HDFS 1.1 HDFS는 무엇인가요? 1. HDFS(Hadoop
본문서는 초급자들을 대상으로 최대한 쉽게 작성하였습니다. 본문서에서는 설치방법만 기술했으며 자세한 설정방법은 검색을 통하시기 바랍니다. 1. 설치개요 워드프레스는 블로그 형태의 홈페이지를 빠르게 만들수 있게 해 주는 프로그램입니다. 다양한 기능을 하는 플러그인과 디자인
 스마일서브 CLOUD_Virtual 워드프레스 설치 (WORDPRESS INSTALL) 스마일서브 가상화사업본부 Update. 2012. 09. 04. 본문서는 초급자들을 대상으로 최대한 쉽게 작성하였습니다. 본문서에서는 설치방법만 기술했으며 자세한 설정방법은 검색을 통하시기 바랍니다. 1. 설치개요 워드프레스는 블로그 형태의 홈페이지를 빠르게 만들수 있게
스마일서브 CLOUD_Virtual 워드프레스 설치 (WORDPRESS INSTALL) 스마일서브 가상화사업본부 Update. 2012. 09. 04. 본문서는 초급자들을 대상으로 최대한 쉽게 작성하였습니다. 본문서에서는 설치방법만 기술했으며 자세한 설정방법은 검색을 통하시기 바랍니다. 1. 설치개요 워드프레스는 블로그 형태의 홈페이지를 빠르게 만들수 있게
C# Programming Guide - Types
 C# Programming Guide - Types 최도경 lifeisforu@wemade.com 이문서는 MSDN 의 Types 를요약하고보충한것입니다. http://msdn.microsoft.com/enus/library/ms173104(v=vs.100).aspx Types, Variables, and Values C# 은 type 에민감한언어이다. 모든
C# Programming Guide - Types 최도경 lifeisforu@wemade.com 이문서는 MSDN 의 Types 를요약하고보충한것입니다. http://msdn.microsoft.com/enus/library/ms173104(v=vs.100).aspx Types, Variables, and Values C# 은 type 에민감한언어이다. 모든
PowerPoint Presentation
 빅데이터아키텍쳐소개 임상배 (sangbae.lim@oracle.com) Technology Sales Consulting, Oracle Korea Agenda 빅데이터아키텍쳐트랜드 빅데이터활용단계별요소기술 사업방향및활용사례 요약 Q&A 빅데이터아키텍쳐트랜드 빅데이터아키텍쳐트랜드 오픈소스와기간계, 정보계시스템과의융합 현재빅데이터의열풍의근원은하둡 (Hadoop)
빅데이터아키텍쳐소개 임상배 (sangbae.lim@oracle.com) Technology Sales Consulting, Oracle Korea Agenda 빅데이터아키텍쳐트랜드 빅데이터활용단계별요소기술 사업방향및활용사례 요약 Q&A 빅데이터아키텍쳐트랜드 빅데이터아키텍쳐트랜드 오픈소스와기간계, 정보계시스템과의융합 현재빅데이터의열풍의근원은하둡 (Hadoop)
JVM 메모리구조
 조명이정도면괜찮조! 주제 JVM 메모리구조 설미라자료조사, 자료작성, PPT 작성, 보고서작성. 발표. 조장. 최지성자료조사, 자료작성, PPT 작성, 보고서작성. 발표. 조원 이용열자료조사, 자료작성, PPT 작성, 보고서작성. 이윤경 자료조사, 자료작성, PPT작성, 보고서작성. 이수은 자료조사, 자료작성, PPT작성, 보고서작성. 발표일 2013. 05.
조명이정도면괜찮조! 주제 JVM 메모리구조 설미라자료조사, 자료작성, PPT 작성, 보고서작성. 발표. 조장. 최지성자료조사, 자료작성, PPT 작성, 보고서작성. 발표. 조원 이용열자료조사, 자료작성, PPT 작성, 보고서작성. 이윤경 자료조사, 자료작성, PPT작성, 보고서작성. 이수은 자료조사, 자료작성, PPT작성, 보고서작성. 발표일 2013. 05.
JAVA PROGRAMMING 실습 08.다형성
 2015 학년도 2 학기 1. 추상메소드 선언은되어있으나코드구현되어있지않은메소드 abstract 키워드사용 메소드타입, 이름, 매개변수리스트만선언 public abstract String getname(); public abstract void setname(string s); 2. 추상클래스 abstract 키워드로선언한클래스 종류 추상메소드를포함하는클래스
2015 학년도 2 학기 1. 추상메소드 선언은되어있으나코드구현되어있지않은메소드 abstract 키워드사용 메소드타입, 이름, 매개변수리스트만선언 public abstract String getname(); public abstract void setname(string s); 2. 추상클래스 abstract 키워드로선언한클래스 종류 추상메소드를포함하는클래스
JAVA 프로그래밍실습 실습 1) 실습목표 - 메소드개념이해하기 - 매개변수이해하기 - 새메소드만들기 - Math 클래스의기존메소드이용하기 ( ) 문제 - 직사각형모양의땅이있다. 이땅의둘레, 면적과대각
 실습목표 - 메소드개념이해하기 - 매개변수이해하기 - 새메소드만들기 - Math 클래스의기존메소드이용하기 ( ) 문제 - 직사각형모양의땅이있다. 이땅의둘레, 면적과대각") JAVA 프로그래밍실습 실습 1) 실습목표 - 메소드개념이해하기 - 매개변수이해하기 - 새메소드만들기 - Math 클래스의기존메소드이용하기 ( http://java.sun.com/javase/6/docs/api ) 문제 - 직사각형모양의땅이있다. 이땅의둘레, 면적과대각선의길이를계산하는메소드들을작성하라. 직사각형의가로와세로의길이는주어진다. 대각선의길이는 Math클래스의적절한메소드를이용하여구하라.
JAVA 프로그래밍실습 실습 1) 실습목표 - 메소드개념이해하기 - 매개변수이해하기 - 새메소드만들기 - Math 클래스의기존메소드이용하기 ( http://java.sun.com/javase/6/docs/api ) 문제 - 직사각형모양의땅이있다. 이땅의둘레, 면적과대각선의길이를계산하는메소드들을작성하라. 직사각형의가로와세로의길이는주어진다. 대각선의길이는 Math클래스의적절한메소드를이용하여구하라.
Microsoft Word - ntasFrameBuilderInstallGuide2.5.doc
 NTAS and FRAME BUILDER Install Guide NTAS and FRAME BUILDER Version 2.5 Copyright 2003 Ari System, Inc. All Rights reserved. NTAS and FRAME BUILDER are trademarks or registered trademarks of Ari System,
NTAS and FRAME BUILDER Install Guide NTAS and FRAME BUILDER Version 2.5 Copyright 2003 Ari System, Inc. All Rights reserved. NTAS and FRAME BUILDER are trademarks or registered trademarks of Ari System,
Windows 8에서 BioStar 1 설치하기
 / 콘텐츠 테이블... PC에 BioStar 1 설치 방법... Microsoft SQL Server 2012 Express 설치하기... Running SQL 2012 Express Studio... DBSetup.exe 설정하기... BioStar 서버와 클라이언트 시작하기... 1 1 2 2 6 7 1/11 BioStar 1, Windows 8 BioStar
/ 콘텐츠 테이블... PC에 BioStar 1 설치 방법... Microsoft SQL Server 2012 Express 설치하기... Running SQL 2012 Express Studio... DBSetup.exe 설정하기... BioStar 서버와 클라이언트 시작하기... 1 1 2 2 6 7 1/11 BioStar 1, Windows 8 BioStar
Cloud Friendly System Architecture
 -Service Clients Administrator 1. -Service 구성도 : ( 좌측참고 ) LB(LoadBlancer) 2. -Service 개요 ucloud Virtual Router F/W Monitoring 개념 특징 적용가능분야 Server, WAS, DB 로구성되어 web service 를클라우드환경에서제공하기위한 service architecture
-Service Clients Administrator 1. -Service 구성도 : ( 좌측참고 ) LB(LoadBlancer) 2. -Service 개요 ucloud Virtual Router F/W Monitoring 개념 특징 적용가능분야 Server, WAS, DB 로구성되어 web service 를클라우드환경에서제공하기위한 service architecture
Microsoft PowerPoint - 10Àå.ppt
 10 장. DB 서버구축및운영 DBMS 의개념과용어를익힌다. 간단한 SQL 문법을학습한다. MySQL 서버를설치 / 운영한다. 관련용어 데이터 : 자료 테이블 : 데이터를표형식으로표현 레코드 : 테이블의행 필드또는컬럼 : 테이블의열 필드명 : 각필드의이름 데이터타입 : 각필드에입력할값의형식 학번이름주소연락처 관련용어 DB : 테이블의집합 DBMS : DB 들을관리하는소프트웨어
10 장. DB 서버구축및운영 DBMS 의개념과용어를익힌다. 간단한 SQL 문법을학습한다. MySQL 서버를설치 / 운영한다. 관련용어 데이터 : 자료 테이블 : 데이터를표형식으로표현 레코드 : 테이블의행 필드또는컬럼 : 테이블의열 필드명 : 각필드의이름 데이터타입 : 각필드에입력할값의형식 학번이름주소연락처 관련용어 DB : 테이블의집합 DBMS : DB 들을관리하는소프트웨어
Open Cloud Engine Open Source Big Data Platform Flamingo Project Open Cloud Engine Flamingo Project Leader 김병곤
 Open Cloud Engine Open Source Big Data Platform Flamingo Project Open Cloud Engine Flamingo Project Leader 김병곤 (byounggon.kim@opence.org) 빅데이터분석및서비스플랫폼 모바일 Browser 인포메이션카탈로그 Search 인포메이션유형 보안등급 생성주기 형식
Open Cloud Engine Open Source Big Data Platform Flamingo Project Open Cloud Engine Flamingo Project Leader 김병곤 (byounggon.kim@opence.org) 빅데이터분석및서비스플랫폼 모바일 Browser 인포메이션카탈로그 Search 인포메이션유형 보안등급 생성주기 형식
김기남_ATDC2016_160620_[키노트].key
![김기남_ATDC2016_160620_[키노트].key](/thumbs/85/91488855.jpg "김기남_ATDC2016_160620_[키노트].key") metatron Enterprise Big Data SKT Metatron/Big Data Big Data Big Data... metatron Ready to Enterprise Big Data Big Data Big Data Big Data?? Data Raw. CRM SCM MES TCO Data & Store & Processing Computational
metatron Enterprise Big Data SKT Metatron/Big Data Big Data Big Data... metatron Ready to Enterprise Big Data Big Data Big Data Big Data?? Data Raw. CRM SCM MES TCO Data & Store & Processing Computational
SQL Developer Connect to TimesTen 유니원아이앤씨 DB 기술지원팀 2010 년 07 월 28 일 문서정보 프로젝트명 SQL Developer Connect to TimesTen 서브시스템명 버전 1.0 문서명 작성일 작성자
 SQL Developer Connect to TimesTen 유니원아이앤씨 DB 팀 2010 년 07 월 28 일 문서정보 프로젝트명 SQL Developer Connect to TimesTen 서브시스템명 버전 1.0 문서명 작성일 2010-07-28 작성자 김학준 최종수정일 2010-07-28 문서번호 20100728_01_khj 재개정이력 일자내용수정인버전
SQL Developer Connect to TimesTen 유니원아이앤씨 DB 팀 2010 년 07 월 28 일 문서정보 프로젝트명 SQL Developer Connect to TimesTen 서브시스템명 버전 1.0 문서명 작성일 2010-07-28 작성자 김학준 최종수정일 2010-07-28 문서번호 20100728_01_khj 재개정이력 일자내용수정인버전
Microsoft PowerPoint - 02_Linux_Fedora_Core_8_Vmware_Installation [호환 모드]
![Microsoft PowerPoint - 02_Linux_Fedora_Core_8_Vmware_Installation [호환 모드]](/thumbs/39/20119028.jpg "Microsoft PowerPoint - 02_Linux_Fedora_Core_8_Vmware_Installation [호환 모드]") 리눅스 설치 Vmware를 이용한 Fedora Core 8 설치 소프트웨어실습 1 Contents 가상 머신 실습 환경 구축 Fedora Core 8 설치 가상 머신 가상 머신 가상 머신의 개념 VMware의 설치 VMware : 가상 머신 생성 VMware의 특징 실습 환경 구축 실습 환경 구축 Fedora Core 8 설치 가상 머신의 개념 가상 머신 (Virtual
리눅스 설치 Vmware를 이용한 Fedora Core 8 설치 소프트웨어실습 1 Contents 가상 머신 실습 환경 구축 Fedora Core 8 설치 가상 머신 가상 머신 가상 머신의 개념 VMware의 설치 VMware : 가상 머신 생성 VMware의 특징 실습 환경 구축 실습 환경 구축 Fedora Core 8 설치 가상 머신의 개념 가상 머신 (Virtual
슬라이드 1
 Pairwise Tool & Pairwise Test NuSRS 200511305 김성규 200511306 김성훈 200614164 김효석 200611124 유성배 200518036 곡진화 2 PICT Pairwise Tool - PICT Microsoft 의 Command-line 기반의 Free Software www.pairwise.org 에서다운로드후설치
Pairwise Tool & Pairwise Test NuSRS 200511305 김성규 200511306 김성훈 200614164 김효석 200611124 유성배 200518036 곡진화 2 PICT Pairwise Tool - PICT Microsoft 의 Command-line 기반의 Free Software www.pairwise.org 에서다운로드후설치
PowerPoint 프레젠테이션
 In-memory 클러스터컴퓨팅프레임워크 Hadoop MapReduce 대비 Machine Learning 등반복작업에특화 2009년, UC Berkeley AMPLab에서 Mesos 어플리케이션으로시작 2010년 Spark 논문발표, 2012년 RDD 논문발표 2013년에 Apache 프로젝트로전환후, 2014년 Apache op-level Project
In-memory 클러스터컴퓨팅프레임워크 Hadoop MapReduce 대비 Machine Learning 등반복작업에특화 2009년, UC Berkeley AMPLab에서 Mesos 어플리케이션으로시작 2010년 Spark 논문발표, 2012년 RDD 논문발표 2013년에 Apache 프로젝트로전환후, 2014년 Apache op-level Project
PowerPoint 프레젠테이션
 빅데이터 실전기술 Recommendation System using Mahout 2014.12.23 IT 가맹점개발팀이태영 Mahout 설치 1) Mahout 0.9 다운로드 http://mahout.apache.org 접속후다운로드 2) 계정홈디렉토리로 mv $ mv mahout-distribution-0.9.tar.gz ~ 3) 압축을풀고 mahout 심볼릭링크를생성
빅데이터 실전기술 Recommendation System using Mahout 2014.12.23 IT 가맹점개발팀이태영 Mahout 설치 1) Mahout 0.9 다운로드 http://mahout.apache.org 접속후다운로드 2) 계정홈디렉토리로 mv $ mv mahout-distribution-0.9.tar.gz ~ 3) 압축을풀고 mahout 심볼릭링크를생성
RUCK2015_Gruter_public
 Apache Tajo 와 R 을연동한빅데이터분석 고영경 / 그루터 ykko@gruter.com 목차 : R Tajo Tajo RJDBC Tajo Tajo UDF( ) TajoR Demo Q&A R 과빅데이터분석 ' R 1) R 2) 3) R (bigmemory, snowfall,..) 4) R (NoSQL, MapReduce, Hive / RHIPE, RHive,..)
Apache Tajo 와 R 을연동한빅데이터분석 고영경 / 그루터 ykko@gruter.com 목차 : R Tajo Tajo RJDBC Tajo Tajo UDF( ) TajoR Demo Q&A R 과빅데이터분석 ' R 1) R 2) 3) R (bigmemory, snowfall,..) 4) R (NoSQL, MapReduce, Hive / RHIPE, RHive,..)
PowerPoint Presentation
 Package Class 3 Heeseung Jo 목차 section 1 패키지개요와패키지의사용 section 2 java.lang 패키지의개요 section 3 Object 클래스 section 4 포장 (Wrapper) 클래스 section 5 문자열의개요 section 6 String 클래스 section 7 StringBuffer 클래스 section
Package Class 3 Heeseung Jo 목차 section 1 패키지개요와패키지의사용 section 2 java.lang 패키지의개요 section 3 Object 클래스 section 4 포장 (Wrapper) 클래스 section 5 문자열의개요 section 6 String 클래스 section 7 StringBuffer 클래스 section
<4D F736F F F696E74202D203137C0E55FBFACBDC0B9AEC1A6BCD6B7E7BCC72E707074>
 SIMATIC S7 Siemens AG 2004. All rights reserved. Date: 22.03.2006 File: PRO1_17E.1 차례... 2 심벌리스트... 3 Ch3 Ex2: 프로젝트생성...... 4 Ch3 Ex3: S7 프로그램삽입... 5 Ch3 Ex4: 표준라이브러리에서블록복사... 6 Ch4 Ex1: 실제구성을 PG 로업로드하고이름변경......
SIMATIC S7 Siemens AG 2004. All rights reserved. Date: 22.03.2006 File: PRO1_17E.1 차례... 2 심벌리스트... 3 Ch3 Ex2: 프로젝트생성...... 4 Ch3 Ex3: S7 프로그램삽입... 5 Ch3 Ex4: 표준라이브러리에서블록복사... 6 Ch4 Ex1: 실제구성을 PG 로업로드하고이름변경......
NoSQL
 MongoDB Daum Communications NoSQL Using Java Java VM, GC Low Scalability Using C Write speed Auto Sharding High Scalability Using Erlang Read/Update MapReduce R/U MR Cassandra Good Very Good MongoDB Good
MongoDB Daum Communications NoSQL Using Java Java VM, GC Low Scalability Using C Write speed Auto Sharding High Scalability Using Erlang Read/Update MapReduce R/U MR Cassandra Good Very Good MongoDB Good
MySQL-Ch10
 10 Chapter.,,.,, MySQL. MySQL mysqld MySQL.,. MySQL. MySQL....,.,..,,.,. UNIX, MySQL. mysqladm mysqlgrp. MySQL 608 MySQL(2/e) Chapter 10 MySQL. 10.1 (,, ). UNIX MySQL, /usr/local/mysql/var, /usr/local/mysql/data,
10 Chapter.,,.,, MySQL. MySQL mysqld MySQL.,. MySQL. MySQL....,.,..,,.,. UNIX, MySQL. mysqladm mysqlgrp. MySQL 608 MySQL(2/e) Chapter 10 MySQL. 10.1 (,, ). UNIX MySQL, /usr/local/mysql/var, /usr/local/mysql/data,
DKE Templete
 Apache Spark 첫걸음 조원형 * 김영국 Department of Computer Science, Kangwon National University Apache Spark 란? Apache Spark 빅데이터처리를위한범용적이며빠른분산처리엔진 하둡 (Apache Hadoop) 기반의맵리듀스 (MapReduce) 작업의단점을보완하기위해연구가시작됨 2009
Apache Spark 첫걸음 조원형 * 김영국 Department of Computer Science, Kangwon National University Apache Spark 란? Apache Spark 빅데이터처리를위한범용적이며빠른분산처리엔진 하둡 (Apache Hadoop) 기반의맵리듀스 (MapReduce) 작업의단점을보완하기위해연구가시작됨 2009
DocsPin_Korean.pages
 Unity Localize Script Service, Page 1 Unity Localize Script Service Introduction Application Game. Unity. Google Drive Unity.. Application Game. -? ( ) -? -?.. 준비사항 Google Drive. Google Drive.,.. - Google
Unity Localize Script Service, Page 1 Unity Localize Script Service Introduction Application Game. Unity. Google Drive Unity.. Application Game. -? ( ) -? -?.. 준비사항 Google Drive. Google Drive.,.. - Google
PowerPoint Presentation
 객체지향프로그래밍 클래스, 객체, 메소드 ( 실습 ) 손시운 ssw5176@kangwon.ac.kr 예제 1. 필드만있는클래스 텔레비젼 2 예제 1. 필드만있는클래스 3 예제 2. 여러개의객체생성하기 4 5 예제 3. 메소드가추가된클래스 public class Television { int channel; // 채널번호 int volume; // 볼륨 boolean
객체지향프로그래밍 클래스, 객체, 메소드 ( 실습 ) 손시운 ssw5176@kangwon.ac.kr 예제 1. 필드만있는클래스 텔레비젼 2 예제 1. 필드만있는클래스 3 예제 2. 여러개의객체생성하기 4 5 예제 3. 메소드가추가된클래스 public class Television { int channel; // 채널번호 int volume; // 볼륨 boolean
이도경, 최덕재 Dokyeong Lee, Deokjai Choi 1. 서론
 이도경, 최덕재 Dokyeong Lee, Deokjai Choi 1. 서론 2. 관련연구 2.1 MQTT 프로토콜 Fig. 1. Topic-based Publish/Subscribe Communication Model. Table 1. Delivery and Guarantee by MQTT QoS Level 2.1 MQTT-SN 프로토콜 Fig. 2. MQTT-SN
이도경, 최덕재 Dokyeong Lee, Deokjai Choi 1. 서론 2. 관련연구 2.1 MQTT 프로토콜 Fig. 1. Topic-based Publish/Subscribe Communication Model. Table 1. Delivery and Guarantee by MQTT QoS Level 2.1 MQTT-SN 프로토콜 Fig. 2. MQTT-SN
파일로입출력하기II - 파일출력클래스중에는데이터를일정한형태로출력하는기능을가지고있다. - PrintWriter와 PrintStream을사용해서원하는형태로출력할수있다. - PrintStream은구버전으로가능하면 PrintWriter 클래스를사용한다. PrintWriter
 파일로입출력하기II - 파일출력클래스중에는데이터를일정한형태로출력하는기능을가지고있다. - PrintWriter와 PrintStream을사용해서원하는형태로출력할수있다. - PrintStream은구버전으로가능하면 PrintWriter 클래스를사용한다. PrintWriter 클래스의사용법은다음과같다. PrintWriter writer = new PrintWriter("output.txt");
파일로입출력하기II - 파일출력클래스중에는데이터를일정한형태로출력하는기능을가지고있다. - PrintWriter와 PrintStream을사용해서원하는형태로출력할수있다. - PrintStream은구버전으로가능하면 PrintWriter 클래스를사용한다. PrintWriter 클래스의사용법은다음과같다. PrintWriter writer = new PrintWriter("output.txt");
PowerPoint 프레젠테이션
 Flamingo Big Data Performance Management Product Documentation It s the Best Big Data Performance Management Solution. Maximize Your Hadoop Cluster with Flamingo. Monitoring, Analyzing, and Visualizing.
Flamingo Big Data Performance Management Product Documentation It s the Best Big Data Performance Management Solution. Maximize Your Hadoop Cluster with Flamingo. Monitoring, Analyzing, and Visualizing.
PowerPoint Presentation
 FORENSICINSIGHT SEMINAR SQLite Recovery zurum herosdfrc@google.co.kr Contents 1. SQLite! 2. SQLite 구조 3. 레코드의삭제 4. 삭제된영역추적 5. 레코드복원기법 forensicinsight.org Page 2 / 22 SQLite! - What is.. - and why? forensicinsight.org
FORENSICINSIGHT SEMINAR SQLite Recovery zurum herosdfrc@google.co.kr Contents 1. SQLite! 2. SQLite 구조 3. 레코드의삭제 4. 삭제된영역추적 5. 레코드복원기법 forensicinsight.org Page 2 / 22 SQLite! - What is.. - and why? forensicinsight.org
PowerPoint 프레젠테이션
 Deep Learning 작업환경조성 & 사용법 ISL 안재원 Ubuntu 설치 작업환경조성 접속방법 사용예시 2 - ISO file Download www.ubuntu.com Ubuntu 설치 3 - Make Booting USB Ubuntu 설치 http://www.pendrivelinux.com/universal-usb-installer-easy-as-1-2-3/
Deep Learning 작업환경조성 & 사용법 ISL 안재원 Ubuntu 설치 작업환경조성 접속방법 사용예시 2 - ISO file Download www.ubuntu.com Ubuntu 설치 3 - Make Booting USB Ubuntu 설치 http://www.pendrivelinux.com/universal-usb-installer-easy-as-1-2-3/
PowerPoint 프레젠테이션
 Spider For MySQL 실전사용기 피망플러스유닛최윤묵 Spider For MySQL Data Sharding By Spider Storage Engine http://spiderformysql.com/ 성능 8 만 / 분 X 4 대 32 만 / 분 많은 DB 중에왜 spider 를? Source: 클라우드컴퓨팅구 선택의기로 Consistency RDBMS
Spider For MySQL 실전사용기 피망플러스유닛최윤묵 Spider For MySQL Data Sharding By Spider Storage Engine http://spiderformysql.com/ 성능 8 만 / 분 X 4 대 32 만 / 분 많은 DB 중에왜 spider 를? Source: 클라우드컴퓨팅구 선택의기로 Consistency RDBMS
API STORE 키발급및 API 사용가이드 Document Information 문서명 : API STORE 언어별 Client 사용가이드작성자 : 작성일 : 업무영역 : 버전 : 1 st Draft. 서브시스템 : 문서번호 : 단계 : Docum
 API STORE 키발급및 API 사용가이드 Document Information 문서명 : API STORE 언어별 Client 사용가이드작성자 : 작성일 : 2012.11.23 업무영역 : 버전 : 1 st Draft. 서브시스템 : 문서번호 : 단계 : Document Distribution Copy Number Name(Role, Title) Date
API STORE 키발급및 API 사용가이드 Document Information 문서명 : API STORE 언어별 Client 사용가이드작성자 : 작성일 : 2012.11.23 업무영역 : 버전 : 1 st Draft. 서브시스템 : 문서번호 : 단계 : Document Distribution Copy Number Name(Role, Title) Date
PowerPoint 프레젠테이션
 실습 1 배효철 th1g@nate.com 1 목차 조건문 반복문 System.out 구구단 모양만들기 Up & Down 2 조건문 조건문의종류 If, switch If 문 조건식결과따라중괄호 { 블록을실행할지여부결정할때사용 조건식 true 또는 false값을산출할수있는연산식 boolean 변수 조건식이 true이면블록실행하고 false 이면블록실행하지않음 3
실습 1 배효철 th1g@nate.com 1 목차 조건문 반복문 System.out 구구단 모양만들기 Up & Down 2 조건문 조건문의종류 If, switch If 문 조건식결과따라중괄호 { 블록을실행할지여부결정할때사용 조건식 true 또는 false값을산출할수있는연산식 boolean 변수 조건식이 true이면블록실행하고 false 이면블록실행하지않음 3
1. Windows 설치 (Client 설치 ) 원하는위치에다운받은발송클라이언트압축파일을해제합니다. Step 2. /conf/config.xml 파일수정 conf 폴더에서 config.xml 파일을텍스트에디터를이용하여 Open 합니다. config.xml 파일에서, 아
 원하는위치에다운받은발송클라이언트압축파일을해제합니다. Step 2. /conf/config.xml 파일수정 conf 폴더에서 config.xml 파일을텍스트에디터를이용하여 Open 합니다. config.xml 파일에서, 아") LG U+ SMS/MMS 통합클라이언트 LG U+ SMS/MMS Client Simple Install Manual LG U+ SMS/MMS 통합클라이언트 - 1 - 간단설치매뉴얼 1. Windows 설치 (Client 설치 ) 원하는위치에다운받은발송클라이언트압축파일을해제합니다. Step 2. /conf/config.xml 파일수정 conf 폴더에서 config.xml
LG U+ SMS/MMS 통합클라이언트 LG U+ SMS/MMS Client Simple Install Manual LG U+ SMS/MMS 통합클라이언트 - 1 - 간단설치매뉴얼 1. Windows 설치 (Client 설치 ) 원하는위치에다운받은발송클라이언트압축파일을해제합니다. Step 2. /conf/config.xml 파일수정 conf 폴더에서 config.xml
Windows Server 2012
 Windows Server 2012 Shared Nothing Live Migration Shared Nothing Live Migration 은 SMB Live Migration 방식과다른점은 VM 데이터파일의위치입니다. Shared Nothing Live Migration 방식은 Hyper-V 호스트의로컬디스크에 VM 데이터파일이위치합니다. 반면에, SMB
Windows Server 2012 Shared Nothing Live Migration Shared Nothing Live Migration 은 SMB Live Migration 방식과다른점은 VM 데이터파일의위치입니다. Shared Nothing Live Migration 방식은 Hyper-V 호스트의로컬디스크에 VM 데이터파일이위치합니다. 반면에, SMB
The Pocket Guide to TCP/IP Sockets: C Version
 인터넷프로토콜 5 장 데이터송수신 (3) 1 파일전송메시지구성예제 ( 고정크기메시지 ) 전송방식 : 고정크기 ( 바이너리전송 ) 필요한전송정보 파일이름 ( 최대 255 자 => 255byte 의메모리공간필요 ) 파일크기 (4byte 의경우최대 4GB 크기의파일처리가능 ) 파일내용 ( 가변길이, 0~4GB 크기 ) 메시지구성 FileName (255bytes)
인터넷프로토콜 5 장 데이터송수신 (3) 1 파일전송메시지구성예제 ( 고정크기메시지 ) 전송방식 : 고정크기 ( 바이너리전송 ) 필요한전송정보 파일이름 ( 최대 255 자 => 255byte 의메모리공간필요 ) 파일크기 (4byte 의경우최대 4GB 크기의파일처리가능 ) 파일내용 ( 가변길이, 0~4GB 크기 ) 메시지구성 FileName (255bytes)
Secure Programming Lecture1 : Introduction
 Malware and Vulnerability Analysis Lecture3-2 Malware Analysis #3-2 Agenda 안드로이드악성코드분석 악성코드분석 안드로이드악성코드정적분석 APK 추출 #1 adb 명령 안드로이드에설치된패키지리스트추출 adb shell pm list packages v0nui-macbook-pro-2:lecture3 v0n$
Malware and Vulnerability Analysis Lecture3-2 Malware Analysis #3-2 Agenda 안드로이드악성코드분석 악성코드분석 안드로이드악성코드정적분석 APK 추출 #1 adb 명령 안드로이드에설치된패키지리스트추출 adb shell pm list packages v0nui-macbook-pro-2:lecture3 v0n$
다른 JSP 페이지호출 forward() 메서드 - 하나의 JSP 페이지실행이끝나고다른 JSP 페이지를호출할때사용한다. 예 ) <% RequestDispatcher dispatcher = request.getrequestdispatcher(" 실행할페이지.jsp");
 메서드 - 하나의 JSP 페이지실행이끝나고다른 JSP 페이지를호출할때사용한다. 예 ) <% RequestDispatcher dispatcher = request.getrequestdispatcher( 실행할페이지.jsp);") 다른 JSP 페이지호출 forward() 메서드 - 하나의 JSP 페이지실행이끝나고다른 JSP 페이지를호출할때사용한다. 예 ) RequestDispatcher dispatcher = request.getrequestdispatcher(" 실행할페이지.jsp"); dispatcher.forward(request, response); - 위의예에서와같이 RequestDispatcher
다른 JSP 페이지호출 forward() 메서드 - 하나의 JSP 페이지실행이끝나고다른 JSP 페이지를호출할때사용한다. 예 ) RequestDispatcher dispatcher = request.getrequestdispatcher(" 실행할페이지.jsp"); dispatcher.forward(request, response); - 위의예에서와같이 RequestDispatcher
2) 활동하기 활동개요 활동과정 [ 예제 10-1]main.xml 1 <LinearLayout xmlns:android="http://schemas.android.com/apk/res/android" 2 xmlns:tools="http://schemas.android.
![2) 활동하기 활동개요 활동과정 [ 예제 10-1]main.xml 1 <LinearLayout xmlns:android=http://schemas.android.com/apk/res/android 2 xmlns:tools=http://schemas.android.](/thumbs/82/85519821.jpg "2) 활동하기 활동개요 활동과정 [ 예제 10-1]main.xml 1 <LinearLayout xmlns:android=http://schemas.android.com/apk/res/android 2 xmlns:tools=http://schemas.android.") 10 차시파일처리 1 학습목표 내장메모리의파일을처리하는방법을배운다. SD 카드의파일을처리하는방법을배운다. 2 확인해볼까? 3 내장메모리파일처리 1) 학습하기 [ 그림 10-1] 내장메모리를사용한파일처리 2) 활동하기 활동개요 활동과정 [ 예제 10-1]main.xml 1
10 차시파일처리 1 학습목표 내장메모리의파일을처리하는방법을배운다. SD 카드의파일을처리하는방법을배운다. 2 확인해볼까? 3 내장메모리파일처리 1) 학습하기 [ 그림 10-1] 내장메모리를사용한파일처리 2) 활동하기 활동개요 활동과정 [ 예제 10-1]main.xml 1
PowerPoint 프레젠테이션
 MySQL - 명령어 1. 데이터베이스관련명령 2. 데이터베이스테이블관련명령 3. SQL 명령의일괄실행 4. 레코드관련명령 5. 데이터베이스백업및복원명령 1. 데이터베이스관련명령 데이터베이스접속명령 데이터베이스접속명령 mysql -u계정 -p비밀번호데이터베이스명 C: > mysql -ukdhong p1234 kdhong_db 데이터베이스생성명령 데이터베이스생성명령
MySQL - 명령어 1. 데이터베이스관련명령 2. 데이터베이스테이블관련명령 3. SQL 명령의일괄실행 4. 레코드관련명령 5. 데이터베이스백업및복원명령 1. 데이터베이스관련명령 데이터베이스접속명령 데이터베이스접속명령 mysql -u계정 -p비밀번호데이터베이스명 C: > mysql -ukdhong p1234 kdhong_db 데이터베이스생성명령 데이터베이스생성명령
PowerPoint Template
 설치및실행방법 Jaewoo Shim Jun. 4. 2018 Contents SQL 인젝션이란 WebGoat 설치방법 실습 과제 2 SQL 인젝션이란 데이터베이스와연동된웹서버에입력값을전달시악의적동작을수행하는쿼리문을삽입하여공격을수행 SELECT * FROM users WHERE id= $_POST[ id ] AND pw= $_POST[ pw ] Internet
설치및실행방법 Jaewoo Shim Jun. 4. 2018 Contents SQL 인젝션이란 WebGoat 설치방법 실습 과제 2 SQL 인젝션이란 데이터베이스와연동된웹서버에입력값을전달시악의적동작을수행하는쿼리문을삽입하여공격을수행 SELECT * FROM users WHERE id= $_POST[ id ] AND pw= $_POST[ pw ] Internet
1) 인증서만들기 ssl]# cat >www.ucert.co.kr.pem // 설명 : 발급받은인증서 / 개인키파일을한파일로저장합니다. ( 저장방법 : cat [ 개인키
![1) 인증서만들기 ssl]# cat >www.ucert.co.kr.pem // 설명 : 발급받은인증서 / 개인키파일을한파일로저장합니다. ( 저장방법 : cat [ 개인키](/thumbs/80/81384531.jpg "1) 인증서만들기 ssl]# cat >www.ucert.co.kr.pem // 설명 : 발급받은인증서 / 개인키파일을한파일로저장합니다. ( 저장방법 : cat [ 개인키") Lighttpd ( 단일도메인 ) SSL 인증서신규설치가이드. [ 고객센터 ] 한국기업보안. 유서트기술팀 1) 인증서만들기 [root@localhost ssl]# cat www.ucert.co.kr.key www.ucert.co.kr.crt >www.ucert.co.kr.pem // 설명 : 발급받은인증서 / 개인키파일을한파일로저장합니다. ( 저장방법 : cat
Lighttpd ( 단일도메인 ) SSL 인증서신규설치가이드. [ 고객센터 ] 한국기업보안. 유서트기술팀 1) 인증서만들기 [root@localhost ssl]# cat www.ucert.co.kr.key www.ucert.co.kr.crt >www.ucert.co.kr.pem // 설명 : 발급받은인증서 / 개인키파일을한파일로저장합니다. ( 저장방법 : cat
PowerPoint 프레젠테이션
 Hadoop 애플리케이션 테스트하기 클라우다인대표김병곤 fharenheit@gmail.com 2 주제 Hadoop 의기본 MapReduce 의특징과테스트의어려운점 MRUnit 을이용한단위테스트기법 통합테스트를위한 Mini Cluster 성능테스트 3 V Model Requirement Acceptance Test Analysis System Test Design
Hadoop 애플리케이션 테스트하기 클라우다인대표김병곤 fharenheit@gmail.com 2 주제 Hadoop 의기본 MapReduce 의특징과테스트의어려운점 MRUnit 을이용한단위테스트기법 통합테스트를위한 Mini Cluster 성능테스트 3 V Model Requirement Acceptance Test Analysis System Test Design
PowerPoint 프레젠테이션
 배효철 th1g@nate.com 1 목차 표준입출력 파일입출력 2 표준입출력 표준입력은키보드로입력하는것, 주로 Scanner 클래스를사용. 표준출력은화면에출력하는메소드를사용하는데대표적으로 System.out.printf( ) 를사용 3 표준입출력 표준출력 : System.out.printlf() 4 표준입출력 Example 01 public static void
배효철 th1g@nate.com 1 목차 표준입출력 파일입출력 2 표준입출력 표준입력은키보드로입력하는것, 주로 Scanner 클래스를사용. 표준출력은화면에출력하는메소드를사용하는데대표적으로 System.out.printf( ) 를사용 3 표준입출력 표준출력 : System.out.printlf() 4 표준입출력 Example 01 public static void
Basic Template
 Hadoop EcoSystem 을홗용한 Hybrid DW 구축사례 2013-05-02 KT cloudware / NexR Project Manager 정구범 klaus.jung@{kt nexr}.com KT의대용량데이터처리이슈 적재 Data의폭발적인증가 LTE 등초고속무선 Data 통싞 : 트래픽이예상보다빨리 / 많이증가 비통싞 ( 컨텐츠 / 플랫폼 /Bio/
Hadoop EcoSystem 을홗용한 Hybrid DW 구축사례 2013-05-02 KT cloudware / NexR Project Manager 정구범 klaus.jung@{kt nexr}.com KT의대용량데이터처리이슈 적재 Data의폭발적인증가 LTE 등초고속무선 Data 통싞 : 트래픽이예상보다빨리 / 많이증가 비통싞 ( 컨텐츠 / 플랫폼 /Bio/
Microsoft PowerPoint - Java7.pptx
 HPC & OT Lab. 1 HPC & OT Lab. 2 실습 7 주차 Jin-Ho, Jang M.S. Hanyang Univ. HPC&OT Lab. jinhoyo@nate.com HPC & OT Lab. 3 Component Structure 객체 (object) 생성개념을이해한다. 외부클래스에대한접근방법을이해한다. 접근제어자 (public & private)
HPC & OT Lab. 1 HPC & OT Lab. 2 실습 7 주차 Jin-Ho, Jang M.S. Hanyang Univ. HPC&OT Lab. jinhoyo@nate.com HPC & OT Lab. 3 Component Structure 객체 (object) 생성개념을이해한다. 외부클래스에대한접근방법을이해한다. 접근제어자 (public & private)
PowerPoint Template
 JavaScript 회원정보 입력양식만들기 HTML & JavaScript Contents 1. Form 객체 2. 일반적인입력양식 3. 선택입력양식 4. 회원정보입력양식만들기 2 Form 객체 Form 객체 입력양식의틀이되는 태그에접근할수있도록지원 Document 객체의하위에위치 속성들은모두 태그의속성들의정보에관련된것
JavaScript 회원정보 입력양식만들기 HTML & JavaScript Contents 1. Form 객체 2. 일반적인입력양식 3. 선택입력양식 4. 회원정보입력양식만들기 2 Form 객체 Form 객체 입력양식의틀이되는 태그에접근할수있도록지원 Document 객체의하위에위치 속성들은모두 태그의속성들의정보에관련된것
1) 인증서만들기 ssl]# cat >www.ucert.co.kr.pem // 설명 : 발급받은인증서 / 개인키파일을한파일로저장합니다. ( 저장방법 : cat [ 개인키
![1) 인증서만들기 ssl]# cat >www.ucert.co.kr.pem // 설명 : 발급받은인증서 / 개인키파일을한파일로저장합니다. ( 저장방법 : cat [ 개인키](/thumbs/80/81384552.jpg "1) 인증서만들기 ssl]# cat >www.ucert.co.kr.pem // 설명 : 발급받은인증서 / 개인키파일을한파일로저장합니다. ( 저장방법 : cat [ 개인키") Lighttpd ( 멀티도메인 ) SSL 인증서신규설치가이드. [ 고객센터 ] 한국기업보안. 유서트기술팀 1) 인증서만들기 [root@localhost ssl]# cat www.ucert.co.kr.key www.ucert.co.kr.crt >www.ucert.co.kr.pem // 설명 : 발급받은인증서 / 개인키파일을한파일로저장합니다. ( 저장방법 : cat
Lighttpd ( 멀티도메인 ) SSL 인증서신규설치가이드. [ 고객센터 ] 한국기업보안. 유서트기술팀 1) 인증서만들기 [root@localhost ssl]# cat www.ucert.co.kr.key www.ucert.co.kr.crt >www.ucert.co.kr.pem // 설명 : 발급받은인증서 / 개인키파일을한파일로저장합니다. ( 저장방법 : cat
PowerPoint 프레젠테이션
 System Software Experiment 1 Lecture 5 - Array Spring 2019 Hwansoo Han (hhan@skku.edu) Advanced Research on Compilers and Systems, ARCS LAB Sungkyunkwan University http://arcs.skku.edu/ 1 배열 (Array) 동일한타입의데이터가여러개저장되어있는저장장소
System Software Experiment 1 Lecture 5 - Array Spring 2019 Hwansoo Han (hhan@skku.edu) Advanced Research on Compilers and Systems, ARCS LAB Sungkyunkwan University http://arcs.skku.edu/ 1 배열 (Array) 동일한타입의데이터가여러개저장되어있는저장장소
리눅스설치가이드 3. 3Rabbitz Book 을리눅스에서설치하기위한절차는다음과같습니다. 설치에대한예시는우분투서버 기준으로진행됩니다. 1. Java Development Kit (JDK) 또는 Java Runtime Environment (JRE) 를설치합니다. 2.
 또는 Java Runtime Environment (JRE) 를설치합니다. 2.") 3. 3Rabbitz Book 을리눅스에서설치하기위한절차는다음과같습니다. 설치에대한예시는우분투서버 기준으로진행됩니다. 1. Java Development Kit (JDK) 또는 Java Runtime Environment (JRE) 를설치합니다. 2. 3Rabbitz Book 애플리케이션파일다운로드하여압축파일을풀고복사합니다. 3. 3Rabbitz Book 실행합니다.
3. 3Rabbitz Book 을리눅스에서설치하기위한절차는다음과같습니다. 설치에대한예시는우분투서버 기준으로진행됩니다. 1. Java Development Kit (JDK) 또는 Java Runtime Environment (JRE) 를설치합니다. 2. 3Rabbitz Book 애플리케이션파일다운로드하여압축파일을풀고복사합니다. 3. 3Rabbitz Book 실행합니다.
rmi_박준용_final.PDF
 (RMI) - JSTORM http://wwwjstormpekr (RMI)- Document title: Document file name: Revision number: Issued by: Document Information (RMI)- rmi finaldoc Issue Date: Status:
(RMI) - JSTORM http://wwwjstormpekr (RMI)- Document title: Document file name: Revision number: Issued by: Document Information (RMI)- rmi finaldoc Issue Date: Status:
PowerPoint Presentation
 public class SumTest { public static void main(string a1[]) { int a, b, sum; a = Integer.parseInt(a1[0]); b = Integer.parseInt(a1[1]); sum = a + b ; // 두수를더하는부분입니다 System.out.println(" 두수의합은 " + sum +
public class SumTest { public static void main(string a1[]) { int a, b, sum; a = Integer.parseInt(a1[0]); b = Integer.parseInt(a1[1]); sum = a + b ; // 두수를더하는부분입니다 System.out.println(" 두수의합은 " + sum +
항목
 Cloud 컴퓨팅기반분산파일시스템개요 개발실 UPDATE : 2012. 11 18 INDEX 1. 가용성 2. 확장성 3. PrismFS 4. Q&A 2 가용성 3 Gmail 장애 2011년 2월 27일 34000명의 Gmail 사용자들이일어나보니메일, 주소록, 채팅기록등이사라진것을발견 2011년 2월 28일 스토리지소프트웨어업데이트를진행하는중 Bug로인해발생했다고공지
Cloud 컴퓨팅기반분산파일시스템개요 개발실 UPDATE : 2012. 11 18 INDEX 1. 가용성 2. 확장성 3. PrismFS 4. Q&A 2 가용성 3 Gmail 장애 2011년 2월 27일 34000명의 Gmail 사용자들이일어나보니메일, 주소록, 채팅기록등이사라진것을발견 2011년 2월 28일 스토리지소프트웨어업데이트를진행하는중 Bug로인해발생했다고공지
1. 자바프로그램기초 및개발환경 2 장 & 3 장. 자바개발도구 충남대학교 컴퓨터공학과
 1. 자바프로그램기초 및개발환경 2 장 & 3 장. 자바개발도구 충남대학교 컴퓨터공학과 학습내용 1. Java Development Kit(JDK) 2. Java API 3. 자바프로그래밍개발도구 (Eclipse) 4. 자바프로그래밍기초 2 자바를사용하려면무엇이필요한가? 자바프로그래밍개발도구 JDK (Java Development Kit) 다운로드위치 : http://www.oracle.com/technetwork/java/javas
1. 자바프로그램기초 및개발환경 2 장 & 3 장. 자바개발도구 충남대학교 컴퓨터공학과 학습내용 1. Java Development Kit(JDK) 2. Java API 3. 자바프로그래밍개발도구 (Eclipse) 4. 자바프로그래밍기초 2 자바를사용하려면무엇이필요한가? 자바프로그래밍개발도구 JDK (Java Development Kit) 다운로드위치 : http://www.oracle.com/technetwork/java/javas
<C0CCBCBCBFB52DC1A4B4EBBFF82DBCAEBBE7B3EDB9AE2D313939392D382E687770>
 i ii iii iv v vi 1 2 3 4 가상대학 시스템의 국내외 현황 조사 가상대학 플랫폼 개발 이상적인 가상대학시스템의 미래상 제안 5 웹-기반 가상대학 시스템 전통적인 교수 방법 시간/공간 제약을 극복한 학습동기 부여 교수의 일방적인 내용전달 교수와 학생간의 상호작용 동료 학생들 간의 상호작용 가상대학 운영 공지사항,강의록 자료실, 메모 질의응답,
i ii iii iv v vi 1 2 3 4 가상대학 시스템의 국내외 현황 조사 가상대학 플랫폼 개발 이상적인 가상대학시스템의 미래상 제안 5 웹-기반 가상대학 시스템 전통적인 교수 방법 시간/공간 제약을 극복한 학습동기 부여 교수의 일방적인 내용전달 교수와 학생간의 상호작용 동료 학생들 간의 상호작용 가상대학 운영 공지사항,강의록 자료실, 메모 질의응답,
Snort Install Manual Ad2m VMware libnet tar.gz DebianOS libpcap tar.gz Putty snort tar.gz WinSCP snort rules 1. 첫번째로네트워크설정 1) ifconf
 ifconf") Snort Install Manual Ad2m VMware libnet-1.1.5.tar.gz DebianOS libpcap-1.1.1.tar.gz Putty snort-2.8.6.tar.gz WinSCP snort rules 1. 첫번째로네트워크설정 1) ifconfig 명령어로현재 IP를확인해본다. 2) vi /etc/network/interfaces 네트워크설정파일에아래와같이설정을해준다.
Snort Install Manual Ad2m VMware libnet-1.1.5.tar.gz DebianOS libpcap-1.1.1.tar.gz Putty snort-2.8.6.tar.gz WinSCP snort rules 1. 첫번째로네트워크설정 1) ifconfig 명령어로현재 IP를확인해본다. 2) vi /etc/network/interfaces 네트워크설정파일에아래와같이설정을해준다.
Microsoft PowerPoint 웹 연동 기술.pptx
 웹프로그래밍및실습 ( g & Practice) 문양세강원대학교 IT 대학컴퓨터과학전공 URL 분석 (1/2) URL (Uniform Resource Locator) 프로토콜, 호스트, 포트, 경로, 비밀번호, User 등의정보를포함 예. http://kim:3759@www.hostname.com:80/doc/index.html URL 을속성별로분리하고자할경우
웹프로그래밍및실습 ( g & Practice) 문양세강원대학교 IT 대학컴퓨터과학전공 URL 분석 (1/2) URL (Uniform Resource Locator) 프로토콜, 호스트, 포트, 경로, 비밀번호, User 등의정보를포함 예. http://kim:3759@www.hostname.com:80/doc/index.html URL 을속성별로분리하고자할경우
<4D F736F F F696E74202D20C1A63234C0E520C0D4C3E2B7C228B0ADC0C729205BC8A3C8AF20B8F0B5E55D>
 Power Java 제 24 장입출력 이번장에서학습할내용 스트림이란? 스트림의분류 바이트스트림 문자스트림 형식입출력 명령어행에서입출력 파일입출력 스트림을이용한입출력에대하여살펴봅시다. 스트림 (stream) 스트림 (stream) 은 순서가있는데이터의연속적인흐름 이다. 스트림은입출력을물의흐름처럼간주하는것이다. 스트림들은연결될수있다. 중간점검문제 1. 자바에서는입출력을무엇이라고추상화하는가?
Power Java 제 24 장입출력 이번장에서학습할내용 스트림이란? 스트림의분류 바이트스트림 문자스트림 형식입출력 명령어행에서입출력 파일입출력 스트림을이용한입출력에대하여살펴봅시다. 스트림 (stream) 스트림 (stream) 은 순서가있는데이터의연속적인흐름 이다. 스트림은입출력을물의흐름처럼간주하는것이다. 스트림들은연결될수있다. 중간점검문제 1. 자바에서는입출력을무엇이라고추상화하는가?
Eclipse 와 Firefox 를이용한 Javascript 개발 발표자 : 문경대 11 년 10 월 26 일수요일
 Eclipse 와 Firefox 를이용한 Javascript 개발 발표자 : 문경대 Introduce Me!!! Job Jeju National University Student Ubuntu Korean Jeju Community Owner E-Mail: ned3y2k@hanmail.net Blog: http://ned3y2k.wo.tc Facebook: http://www.facebook.com/gyeongdae
Eclipse 와 Firefox 를이용한 Javascript 개발 발표자 : 문경대 Introduce Me!!! Job Jeju National University Student Ubuntu Korean Jeju Community Owner E-Mail: ned3y2k@hanmail.net Blog: http://ned3y2k.wo.tc Facebook: http://www.facebook.com/gyeongdae
Microsoft PowerPoint - 11주차_Android_GoogleMap.ppt [호환 모드]
![Microsoft PowerPoint - 11주차_Android_GoogleMap.ppt [호환 모드]](/thumbs/90/102499718.jpg "Microsoft PowerPoint - 11주차_Android_GoogleMap.ppt [호환 모드]") Google Map View 구현 학습목표 교육목표 Google Map View 구현 Google Map 지원 Emulator 생성 Google Map API Key 위도 / 경도구하기 위도 / 경도에따른 Google Map View 구현 Zoom Controller 구현 Google Map View (1) () Google g Map View 기능 Google
Google Map View 구현 학습목표 교육목표 Google Map View 구현 Google Map 지원 Emulator 생성 Google Map API Key 위도 / 경도구하기 위도 / 경도에따른 Google Map View 구현 Zoom Controller 구현 Google Map View (1) () Google g Map View 기능 Google
Connection 8 22 UniSQLConnection / / 9 3 UniSQL OID SET
 135-080 679-4 13 02-3430-1200 1 2 11 2 12 2 2 8 21 Connection 8 22 UniSQLConnection 8 23 8 24 / / 9 3 UniSQL 11 31 OID 11 311 11 312 14 313 16 314 17 32 SET 19 321 20 322 23 323 24 33 GLO 26 331 GLO 26
135-080 679-4 13 02-3430-1200 1 2 11 2 12 2 2 8 21 Connection 8 22 UniSQLConnection 8 23 8 24 / / 9 3 UniSQL 11 31 OID 11 311 11 312 14 313 16 314 17 32 SET 19 321 20 322 23 323 24 33 GLO 26 331 GLO 26
Microsoft PowerPoint - java1-lab5-ImageProcessorTestOOP.pptx
 2018 학년도 1 학기 JAVA 프로그래밍 II 514760-1 2018 년봄학기 5/10/2018 박경신 Lab#1 (ImageTest) Lab#1 은영상파일 (Image) 을읽어서정보를출력 Java Tutorials Lesson: Working with Images https://docs.oracle.com/javase/tutorial/2d/images/index.html
2018 학년도 1 학기 JAVA 프로그래밍 II 514760-1 2018 년봄학기 5/10/2018 박경신 Lab#1 (ImageTest) Lab#1 은영상파일 (Image) 을읽어서정보를출력 Java Tutorials Lesson: Working with Images https://docs.oracle.com/javase/tutorial/2d/images/index.html
8 장데이터베이스 8.1 기본개념 - 데이터베이스 : 데이터를조직적으로구조화한집합 (cf. 엑셀파일 ) - 테이블 : 데이터의기록형식 (cf. 엑셀시트의첫줄 ) - 필드 : 같은종류의데이터 (cf. 엑셀시트의각칸 ) - 레코드 : 데이터내용 (cf. 엑셀시트의한줄 )
 - 테이블 : 데이터의기록형식 (cf. 엑셀시트의첫줄 ) - 필드 : 같은종류의데이터 (cf. 엑셀시트의각칸 ) - 레코드 : 데이터내용 (cf. 엑셀시트의한줄 )") 8 장데이터베이스 8.1 기본개념 - 데이터베이스 : 데이터를조직적으로구조화한집합 (cf. 엑셀파일 ) - 테이블 : 데이터의기록형식 (cf. 엑셀시트의첫줄 ) - 필드 : 같은종류의데이터 (cf. 엑셀시트의각칸 ) - 레코드 : 데이터내용 (cf. 엑셀시트의한줄 ) - DDL(Data Definition Language) : show, create, drop
8 장데이터베이스 8.1 기본개념 - 데이터베이스 : 데이터를조직적으로구조화한집합 (cf. 엑셀파일 ) - 테이블 : 데이터의기록형식 (cf. 엑셀시트의첫줄 ) - 필드 : 같은종류의데이터 (cf. 엑셀시트의각칸 ) - 레코드 : 데이터내용 (cf. 엑셀시트의한줄 ) - DDL(Data Definition Language) : show, create, drop
PowerPoint Presentation
 오에스아이소프트코리아세미나세미나 2012 Copyright Copyright 2012 OSIsoft, 2012 OSIsoft, LLC. LLC. PI Coresight and Mobility Presented by Daniel Kim REGIONAL 세미나 SEMINAR 세미나 2012 2012 2 Copyright Copyright 2012 OSIsoft,
오에스아이소프트코리아세미나세미나 2012 Copyright Copyright 2012 OSIsoft, 2012 OSIsoft, LLC. LLC. PI Coresight and Mobility Presented by Daniel Kim REGIONAL 세미나 SEMINAR 세미나 2012 2012 2 Copyright Copyright 2012 OSIsoft,
gnu-lee-oop-kor-lec06-3-chap7
 어서와 Java 는처음이지! 제 7 장상속 Super 키워드 상속과생성자 상속과다형성 서브클래스의객체가생성될때, 서브클래스의생성자만호출될까? 아니면수퍼클래스의생성자도호출되는가? class Base{ public Base(String msg) { System.out.println("Base() 생성자 "); ; class Derived extends Base
어서와 Java 는처음이지! 제 7 장상속 Super 키워드 상속과생성자 상속과다형성 서브클래스의객체가생성될때, 서브클래스의생성자만호출될까? 아니면수퍼클래스의생성자도호출되는가? class Base{ public Base(String msg) { System.out.println("Base() 생성자 "); ; class Derived extends Base
Network Programming
 Part 5 확장된 Network Programming 기술 1. Remote Procedure Call 2. Remote Method Invocation 3. Object Request Broker 2. Java RMI
Part 5 확장된 Network Programming 기술 1. Remote Procedure Call 2. Remote Method Invocation 3. Object Request Broker 2. Java RMI
Splentec V-WORM Quick Installation Guide Version: 1.0 Contact Information 올리브텍 주소 : 경기도성남시분당구구미로 11 ( 포인트타운 701호 ) URL: E-M
 URL: E-M") Splentec V-WORM Quick Installation Guide Version: 1.0 Contact Information 올리브텍 주소 : 경기도성남시분당구구미로 11 ( 포인트타운 701호 ) URL: http://www.olivetech.co.kr E-Mail: tech@olivetech.co.kr TEL: 031-726-4217 FAX: 031-726-4219
Splentec V-WORM Quick Installation Guide Version: 1.0 Contact Information 올리브텍 주소 : 경기도성남시분당구구미로 11 ( 포인트타운 701호 ) URL: http://www.olivetech.co.kr E-Mail: tech@olivetech.co.kr TEL: 031-726-4217 FAX: 031-726-4219
슬라이드 1
 - 1 - 전자정부모바일표준프레임워크실습 LAB 개발환경 실습목차 LAB 1-1 모바일프로젝트생성실습 LAB 1-2 모바일사이트템플릿프로젝트생성실습 LAB 1-3 모바일공통컴포넌트생성및조립도구실습 - 2 - LAB 1-1 모바일프로젝트생성실습 (1/2) Step 1-1-01. 구현도구에서 egovframe>start>new Mobile Project 메뉴를선택한다.
- 1 - 전자정부모바일표준프레임워크실습 LAB 개발환경 실습목차 LAB 1-1 모바일프로젝트생성실습 LAB 1-2 모바일사이트템플릿프로젝트생성실습 LAB 1-3 모바일공통컴포넌트생성및조립도구실습 - 2 - LAB 1-1 모바일프로젝트생성실습 (1/2) Step 1-1-01. 구현도구에서 egovframe>start>new Mobile Project 메뉴를선택한다.
adfasdfasfdasfasfadf
 C 4.5 Source code Pt.3 ISL / 강한솔 2019-04-10 Index Tree structure Build.h Tree.h St-thresh.h 2 Tree structure *Concpets : Node, Branch, Leaf, Subtree, Attribute, Attribute Value, Class Play, Don't Play.
C 4.5 Source code Pt.3 ISL / 강한솔 2019-04-10 Index Tree structure Build.h Tree.h St-thresh.h 2 Tree structure *Concpets : Node, Branch, Leaf, Subtree, Attribute, Attribute Value, Class Play, Don't Play.
Tablespace On-Offline 테이블스페이스 온라인/오프라인
 2018/11/10 12:06 1/2 Tablespace On-Offline 테이블스페이스온라인 / 오프라인 목차 Tablespace On-Offline 테이블스페이스온라인 / 오프라인... 1 일반테이블스페이스 (TABLESPACE)... 1 일반테이블스페이스생성하기... 1 테이블스페이스조회하기... 1 테이블스페이스에데이터파일 (DATA FILE) 추가
2018/11/10 12:06 1/2 Tablespace On-Offline 테이블스페이스온라인 / 오프라인 목차 Tablespace On-Offline 테이블스페이스온라인 / 오프라인... 1 일반테이블스페이스 (TABLESPACE)... 1 일반테이블스페이스생성하기... 1 테이블스페이스조회하기... 1 테이블스페이스에데이터파일 (DATA FILE) 추가
Microsoft PowerPoint - 04-UDP Programming.ppt
 Chapter 4. UDP Dongwon Jeong djeong@kunsan.ac.kr http://ist.kunsan.ac.kr/ Dept. of Informatics & Statistics 목차 UDP 1 1 UDP 개념 자바 UDP 프로그램작성 클라이언트와서버모두 DatagramSocket 클래스로생성 상호간통신은 DatagramPacket 클래스를이용하여
Chapter 4. UDP Dongwon Jeong djeong@kunsan.ac.kr http://ist.kunsan.ac.kr/ Dept. of Informatics & Statistics 목차 UDP 1 1 UDP 개념 자바 UDP 프로그램작성 클라이언트와서버모두 DatagramSocket 클래스로생성 상호간통신은 DatagramPacket 클래스를이용하여
Interstage5 SOAP서비스 설정 가이드
 Interstage 5 Application Server ( Solaris ) SOAP Service Internet Sample Test SOAP Server Application SOAP Client Application CORBA/SOAP Server Gateway CORBA/SOAP Gateway Client INTERSTAGE SOAP Service
Interstage 5 Application Server ( Solaris ) SOAP Service Internet Sample Test SOAP Server Application SOAP Client Application CORBA/SOAP Server Gateway CORBA/SOAP Gateway Client INTERSTAGE SOAP Service
운영체제실습_명령어
 운영체제실습 리눅스네트워크기본개념및설정 서 기옥 Contents 네트워크용어정의 IP 주소 네트워크기본명령어 네트워크관리명령어 네트워크설정파일 telnet 서버설정 네트워크용어정의 네트워크 (Network) : 전자적으로데이터를주고받기위한목적으로연결된 2 개이상의컴퓨터시스템 IP 주소와 Ethernet 주소 IP 주소 : 네트워크에연결된시스템을구분하는소프트웨어적인주소
운영체제실습 리눅스네트워크기본개념및설정 서 기옥 Contents 네트워크용어정의 IP 주소 네트워크기본명령어 네트워크관리명령어 네트워크설정파일 telnet 서버설정 네트워크용어정의 네트워크 (Network) : 전자적으로데이터를주고받기위한목적으로연결된 2 개이상의컴퓨터시스템 IP 주소와 Ethernet 주소 IP 주소 : 네트워크에연결된시스템을구분하는소프트웨어적인주소
네이버블로그 :: 포스트내용 Print VMw are 에서 Linux 설치하기 (Centos 6.3, 리눅스 ) Linux 2013/02/23 22:52 /carrena/ VMware 에서 l
 Linux 2013/02/23 22:52 /carrena/ VMware 에서 l") VMw are 에서 Linux 설치하기 (Centos 6.3, 리눅스 ) Linux 2013/02/23 22:52 http://blog.naver.com /carrena/50163909320 VMware 에서 linux 설치하기 linux 는다양한버전이존재합니다. OS 자체가오픈소스이기때문에 redhat fedora, 우분투, centos 등등 100 가지가넘는버전이존재함
VMw are 에서 Linux 설치하기 (Centos 6.3, 리눅스 ) Linux 2013/02/23 22:52 http://blog.naver.com /carrena/50163909320 VMware 에서 linux 설치하기 linux 는다양한버전이존재합니다. OS 자체가오픈소스이기때문에 redhat fedora, 우분투, centos 등등 100 가지가넘는버전이존재함
Microsoft PowerPoint - CSharp-10-예외처리
 10 장. 예외처리 예외처리개념 예외처리구문 사용자정의예외클래스와예외전파 순천향대학교컴퓨터학부이상정 1 예외처리개념 순천향대학교컴퓨터학부이상정 2 예외처리 오류 컴파일타임오류 (Compile-Time Error) 구문오류이기때문에컴파일러의구문오류메시지에의해쉽게교정 런타임오류 (Run-Time Error) 디버깅의절차를거치지않으면잡기어려운심각한오류 시스템에심각한문제를줄수도있다.
10 장. 예외처리 예외처리개념 예외처리구문 사용자정의예외클래스와예외전파 순천향대학교컴퓨터학부이상정 1 예외처리개념 순천향대학교컴퓨터학부이상정 2 예외처리 오류 컴파일타임오류 (Compile-Time Error) 구문오류이기때문에컴파일러의구문오류메시지에의해쉽게교정 런타임오류 (Run-Time Error) 디버깅의절차를거치지않으면잡기어려운심각한오류 시스템에심각한문제를줄수도있다.
02 C h a p t e r Java
 02 C h a p t e r Java Bioinformatics in J a va,, 2 1,,,, C++, Python, (Java),,, (http://wwwbiojavaorg),, 13, 3D GUI,,, (Java programming language) (Sun Microsystems) 1995 1990 (green project) TV 22 CHAPTER
02 C h a p t e r Java Bioinformatics in J a va,, 2 1,,,, C++, Python, (Java),,, (http://wwwbiojavaorg),, 13, 3D GUI,,, (Java programming language) (Sun Microsystems) 1995 1990 (green project) TV 22 CHAPTER
들어가는글 2012년 IT 분야에서최고의관심사는아마도빅데이터일것이다. 관계형데이터진영을대표하는오라클은 2011년 10월개최된 오라클오픈월드 2011 에서오라클빅데이터어플라이언스 (Oracle Big Data Appliance, 이하 BDA) 를출시한다고발표하였다. 이와
 를출시한다고발표하였다. 이와") Oracle Data Integrator 와 Oracle Big Data Appliance 저자 - 김태완부장, 한국오라클 Fusion Middleware(taewan.kim@oracle.com) 오라클은최근 Big Data 분약에 End-To-End 솔루션을지원하는벤더로급부상하고있고, 기존관계형데이터저장소와새로운트랜드인비정형빅데이터를통합하는데이터아키텍처로엔터프로이즈시장에서주목을받고있다.
Oracle Data Integrator 와 Oracle Big Data Appliance 저자 - 김태완부장, 한국오라클 Fusion Middleware(taewan.kim@oracle.com) 오라클은최근 Big Data 분약에 End-To-End 솔루션을지원하는벤더로급부상하고있고, 기존관계형데이터저장소와새로운트랜드인비정형빅데이터를통합하는데이터아키텍처로엔터프로이즈시장에서주목을받고있다.
BMP 파일 처리
 BMP 파일처리 김성영교수 금오공과대학교 컴퓨터공학과 학습내용 영상반전프로그램제작 2 Inverting images out = 255 - in 3 /* 이프로그램은 8bit gray-scale 영상을입력으로사용하여반전한후동일포맷의영상으로저장한다. */ #include #include #define WIDTHBYTES(bytes)
BMP 파일처리 김성영교수 금오공과대학교 컴퓨터공학과 학습내용 영상반전프로그램제작 2 Inverting images out = 255 - in 3 /* 이프로그램은 8bit gray-scale 영상을입력으로사용하여반전한후동일포맷의영상으로저장한다. */ #include #include #define WIDTHBYTES(bytes)
<30322E F6F7020BCB3C4A1BFCD20BED6C7C3B8AEC4C9C0CCBCC7C0C720B1B8B5BF28B1DDC5C2C8C62C20B1E8BCBCC8B82C20C0CCBBF3C1D8292E687770>
 한국컴퓨터정보학회지제 18 권제 1 호, 2010. 6. Hadoop 설치와애플리케이션의구동 금태훈 ( 한양대학교컴퓨터공학과 ) 김세회 ( 한양대학교컴퓨터공학과 ) 이상준 ( 평택대학교물류정보대학원 ) Ⅰ. 서론 클라우드컴퓨팅이란개인용컴퓨터또는기업의서버에개별적으로저장해두었던자료와소프트웨어들을클라우드클러스터로구축하여필요할때 PC나휴대폰과같은각종단말기를이용하여원격작업을수행할수있는환경을의미한다.
한국컴퓨터정보학회지제 18 권제 1 호, 2010. 6. Hadoop 설치와애플리케이션의구동 금태훈 ( 한양대학교컴퓨터공학과 ) 김세회 ( 한양대학교컴퓨터공학과 ) 이상준 ( 평택대학교물류정보대학원 ) Ⅰ. 서론 클라우드컴퓨팅이란개인용컴퓨터또는기업의서버에개별적으로저장해두었던자료와소프트웨어들을클라우드클러스터로구축하여필요할때 PC나휴대폰과같은각종단말기를이용하여원격작업을수행할수있는환경을의미한다.
제11장 프로세스와 쓰레드
 제9장자바쓰레드 9.1 Thread 기초 (1/5) 프로그램 명령어들의연속 (a sequence of instruction) 프로세스 / Thread 실행중인프로그램 (program in execution) 프로세스생성과실행을위한함수들 자바 Thread 2 9.1 Thread 기초 (2/5) 프로세스단위작업의문제점 프로세스생성시오버헤드 컨텍스트스위치오버헤드
제9장자바쓰레드 9.1 Thread 기초 (1/5) 프로그램 명령어들의연속 (a sequence of instruction) 프로세스 / Thread 실행중인프로그램 (program in execution) 프로세스생성과실행을위한함수들 자바 Thread 2 9.1 Thread 기초 (2/5) 프로세스단위작업의문제점 프로세스생성시오버헤드 컨텍스트스위치오버헤드
Raspbian 설치 라즈비안 OS (Raspbian OS) 라즈베리파이 3 Model B USB 마우스 USB 키보드 마이크로 SD 카드 마이크로 SD 카드리더기 HDM I 케이블모니터
 라즈베리파이 3 Model B USB 마우스 USB 키보드 마이크로 SD 카드 마이크로 SD 카드리더기 HDM I 케이블모니터") 운영체제실습 Raspbian 설치 2017. 3 표월성 wspyo74@naver.com cherub.sungkyul.ac.kr 목차 Ⅰ. 설치 1. 라즈비안 (Raspbian 설치 ) 2. 설치후, 설정 설정사항 Raspbian 설치 라즈비안 OS (Raspbian OS) 라즈베리파이 3 Model B USB 마우스 USB 키보드 마이크로 SD 카드 마이크로
운영체제실습 Raspbian 설치 2017. 3 표월성 wspyo74@naver.com cherub.sungkyul.ac.kr 목차 Ⅰ. 설치 1. 라즈비안 (Raspbian 설치 ) 2. 설치후, 설정 설정사항 Raspbian 설치 라즈비안 OS (Raspbian OS) 라즈베리파이 3 Model B USB 마우스 USB 키보드 마이크로 SD 카드 마이크로