클라우드 빅데이타 개발자 과정
|
|
|
- 인촌 위
- 7 years ago
- Views:
Transcription
1 2017 년정보처리학회단기강좌 빅데이터플랫폼과 Spark - 장형석 - 국민대학교빅데이터경영 MBA 과정교수 - [email protected]
2 Part I 빅데이터플랫폼
3 1. 빅데이터플랫폼 빅데이터수집 / 분석 / 서비스를위한목표플랫폼 빅데이터플랫폼 데이터 서비스 서비스 / 시각화 시각화 활용 내부DB 외부DB 공공DB 문서파일포털 (WEB) SNS A P I A g e n t SFTP HTTPS REST SOAP Agent Download SFTP Agent Download Crawling 빅데이터통합연계수집 OA, 보안,... 그룹사 A, B,... 분야 A, B,... 외부서비스 A, B,... 통계 / 분석 형태 정형 / 준정형 비정형 통계 / 분석 / 데이터마이닝 데이터마이닝 관리 메타데이터 데이터모델 텍스트마이닝 분석 소셜네트워크분석 저장 / 처리 데이터원본 DB 기초데이터 기초데이터 RDBMS/MPP NoSQL 분산파일시스템 연계 / 수집 추출전송변환저장 인프라 분석결과 DB 결과데이터 결과데이터 실시간분석 데이터시각화 고급분석 머신러닝 서비스시각화 처리 예측분석 배치처리 CEP SQL 경영진부서그룹사외부개인고객공공 통합보안 H/W N/W S/W 인증
4 1. 빅데이터플랫폼 빅데이터플랫폼과소프트웨어 데이터 DB 서비스 / 시각화 빅데이터분석가및고객 ( 서비스 ) 을위한웹인터페이스 분석 웹 / 모바일 Application D3.js DB A P I 통계 / 분석 / 마이닝고급분석통계 / 분석데이터마이닝 SNA 머신러닝실시간분석 R Pig Spark Mahout DB 형태 정형 / 준정형 구분 내부 DB 데이터원본 DB 기초데이터 저장 / 처리 분석결과 DB 결과데이터 Impala Hive 비정형 외부 /SNS 기초데이터 결과데이터 HDFS MapReduce 파일 로그 A g e n t RDBMS/MPP NoSQL 분산파일시스템 연계 / 수집 추출전송변환저장 인프라 Flume Sqoop 통합보안 H/W N/W S/W 인증 클라우드 (OpenStack) 클러스터매니저 (YARN)
5 2. 빅데이터프로세스및기술 빅데이터프로세스 데이터소스수집저장처리분석표현 내부데이터 수동 - 정형 - 비정형 - 준정형 배치처리 ( 맵리듀스 ) 전처리 서비스 ( 활용 ) 시각화 외부데이터 자동 - 로그수집기 - 크롤러 - 센서수집기 분산파일시스템 NoSQL SQL 분석 통계데이터마이닝머신러닝 데이터 ( 분석 ) 시각화 사물인터넷 ( 센서 ) 실시간처리

")

6 2. 빅데이터프로세스및기술 수집개요및기술 정형 로그수집기 반정형 크롤러 센서데이터수집기 빅데이터 저장소 비정형 Open API < 빅데이터의주요수집기술 > 기술 개발 최초공개 주요기능및특징 Sqoop 아파치 2009년 RDBMS와 HDFS(NoSQL) 간의데이터연동 Flume Cloudera 2010년 방대한양의이벤트로그수집 Kafka Linkedin 2010년 분산시스템에서메시지전송및수집
7 2. 빅데이터프로세스및기술 저장기술 구분기술최초개발주요기능및특징 HDFS 아파치대표적인오픈소스분산파일시스템 분산파일시스템 Hive 페이스북 HDFS 기반의 DataWarehouse S3 아마존아마존의클라우드기반분산스토리지서비스 HBase 아파치 HDFS 기반의 NoSQL NoSQL Cassandra A. Lakshman ACID 속성을유지한분산데이터베이스 Mongo DB 10gen DB 의수평확장및범위질의지원, 자체맵리듀스 처리기술 배치처리 : 하둡맵리듀스, Pig, Hive 분산병렬데이터처리기술의표준, 일반범용서버로구성된군집화시스템을기반으로 < 키, 값 > 입력데이터분할처리및처리결과통합기술, job 스케줄링기술, 작업분배기술, 태스크재수행기술이통합된분산컴퓨팅기술 SQL on Hadoop : Hive on Tez, Impala, Presto, Shark(SparkSQL) 배치처리중심의맵리듀스의한계를넘기위해만들어진 SQL 기반의자체쿼리실행엔진.
8 2. 빅데이터프로세스및기술 분석기술 R 오픈소스통계분석소프트웨어. 기본적인통계분석부터최신머신러닝까지다양한패키지를지원. 하둡및스팍과연동이가능 R, RStudio, RHadoop, RHive, SparkR Python 데이터마이닝과머신러닝을지원하는다양한패키지통계학과의기본적인프로그래밍언어로정착스크립트기반의대화형분석환경지원 ipython Notebook Mahout 추천시스템, 분류, 군집등머신러닝기능을지원하둡기반의머신러닝 Java 라이브러리현재 Spark의 MLlib로발전함 Spark 대화형분석, 머신러닝, SQL, 그래프알고리즘등다양한분석가능 Spark Core, Spark MLlib, SparkSQL, GraphX, Spark Streaming
9 2. 빅데이터프로세스및기술 실시간수집및처리사례 출처 : 엄태욱, 2015/12/18, SK 플래닛기술블로그
10 3. 빅데이터인프라 < 개발 / 파일럿시스템구성 > 수집서버 x86 2CPU, 64G RAM 36TB SATA HDD Linux 웹크롤러수집애플리케이션 분석서버 ( 하둡 / 스팍클라이언트 ) x86 2CPU, 64G RAM 36TB SATA HDD Linux Hadoop Ecosystem Clients(Hive,Spark 등 ) 분석서버 (RStudio Server) x86 2CPU, 64G RAM 36TB SATA HDD Linux R(Linux Server Version) 마스터노드 데이터노드 마스터노드 1 마스터노드 2 데이터노드 1 데이터노드 2 데이터노드 3 x86 2CPU, 96G RAM 4TB SAS HDD Linux NameNode(Acitve) Metastore(Mysql Server) x86 2CPU, 96G RAM 4TB SAS HDD Linux 2st NameNode(Stanby) YARN/Spark Master x86 2CPU, 64G RAM 36TB SATA HDD Linux DataNode TaskTracker Spark Worker x86 2CPU, 64G RAM 36TB SATA HDD Linux DataNode TaskTracker Spark Worker x86 2CPU, 64G RAM 36TB SATA HDD Linux DataNode TaskTracker Spark Worker
11 3. 빅데이터인프라 하둡클러스터 수집용 마스터노드 [ 수집서버 1] 수집서버 2 크롤링서버 [ 마스터노드 1] [ 마스터노드 2] 마스터노드 3 x86 2CPU, 96G RAM 4TB SAS HDD Linux NameNode(active) Metastore(Mysql) x86 2CPU, 96G RAM 4TB SAS HDD Linux 2st NameNode(Stanby) YARN/Spark Master x86 2CPU, 96G RAM 4TB SAS HDD Linux Cluster Manager Backup x86 2CPU, 64G RAM 36TB SATA HDD ETL Linux x86 2CPU, 64G RAM 36TB SATA HDD ETL Linux 분석용 x86 2CPU, 64G RAM 36TB SATA HDD Crawler LInux 데이터노드 [ 분석서버 1] [ 분석서버 2] 시각화서버 [ 데이터노드 1] x86 2CPU, 64G RAM 36TB SATA HDD Linux DataNode TaskTracker Spark Worker [ 데이터노드 2] [ 데이터노드 3] 데이터노드 4 데이터노드 5 x86 2CPU, 64G RAM 36TB SATA HDD Hadoop Clients(Hive 등 ) Linux x86 2CPU, 64G RAM 36TB SATA HDD RStudio Server Linux 서비스용 x86 2CPU, 64G RAM 36TB SATA HDD Tableau Server Linux 데이터노드 6 데이터노드 7 데이터노드 8 데이터노드 9 데이터노드 10 웹서버 1 x86 2CPU, 64G RAM 8TB SATA HDD WebServer/WAS 웹서버 2 x86 2CPU, 64G RAM 8TB SATA HDD WebServer/WAS
12 Part II 하둡에코시스템
 - 수퍼컴퓨터 - 하둡클러스터 -> N 대의범용컴퓨터를묶은클러스터 ( 하둡 HDFS")
13 1. 분산병렬처리 처리속도의발전 1단계 : CPU의 Clock Frequency 늘리기 - 무어의법칙 : 동일한면적의반도체직접회로의트랜지스터의개수가 18개월에 2배씩증가 - CPU Clock 물리적인한계 : 최대 4Ghz 2 단계 : Single CPU 에서 Multi CPU & Core - 1 CPU -> 2 CPU( 최적 ) -> 4 CPU -> 8 CPU - 1 CPU : 1 Core -> 2 Core -> 4 Core -> 6 Core -> 8 Core 2 배가아닌 10 배씩증가 3 단계 : Single Machine -> Cluster( N 대의 Machine 을 Network 로연결 ) - 수퍼컴퓨터 - 하둡클러스터 -> N 대의범용컴퓨터를묶은클러스터 ( 하둡 HDFS 와맵리듀스 )
14 1. 분산병렬처리 분산병렬처리를위한맵리듀스프레임워크 구글 년 GFS : 구글분산파일시스템아키텍처 -> 논문공개 년 MapReduce : 구글맵리듀스아키텍처 -> 논문공개 하둡 년 2월더그커팅 : 오픈소스로하둡 (HDFS,MapReduce) 공개 년야후 : 900노드에서 1테라바이트정렬 : 209초 ( 세계최고기록 ) - Hadoop, Pig, Hive, HBase, Mahout, Zookeeper... Spark : 하둡에코시스템및스팍으로발전 오픈소스 범용컴퓨터 수집 / 저장 / 처리 / 분석 / 시각화기술

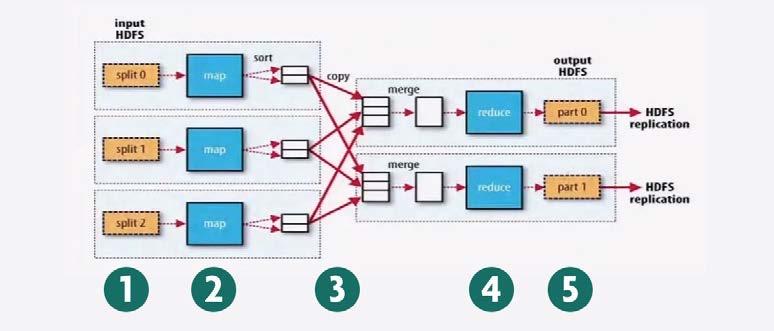
15 1. 분산병렬처리 하둡 MapReduce 출처 :
![2. Hadoop Ecosystem 빅데이터핵심기술 하둡 하둡에코시스템 < 분산파일시스템 + 분산병렬처리 > [ MapReduce ] CPU CPU CPU CPU RAM RAM RAM RAM... CPU CPU RAM RAM 모니터링및관리 1.Zookeeper 워크플로우 2.Oozie 분산데이터스토어 3.HBase 비정형데이터수집 9.Chukwa 10.](/docs-images/91/105473701/images/16-1.jpg "Flume 11.Scribe 배치분석 4.Pig 5.Hive 기계학습 6.Mahout 메타데이터관리 7.HCatalog 분산병렬처리 (MapReduce) 분산파일시스템 (HDFS) 정형데이터수집 12.Sqoop 13.Hiho 데이터직렬화 8.Avro Disk Disk Disk Disk [ HDFS ] Disk Disk 1.")
16 2. Hadoop Ecosystem 빅데이터핵심기술 하둡 하둡에코시스템 < 분산파일시스템 + 분산병렬처리 > [ MapReduce ] CPU CPU CPU CPU RAM RAM RAM RAM... CPU CPU RAM RAM 모니터링및관리 1.Zookeeper 워크플로우 2.Oozie 분산데이터스토어 3.HBase 비정형데이터수집 9.Chukwa 10.Flume 11.Scribe 배치분석 4.Pig 5.Hive 기계학습 6.Mahout 메타데이터관리 7.HCatalog 분산병렬처리 (MapReduce) 분산파일시스템 (HDFS) 정형데이터수집 12.Sqoop 13.Hiho 데이터직렬화 8.Avro Disk Disk Disk Disk [ HDFS ] Disk Disk 1. Zookeeper : 분산환경에서서버들간에상호조정이필요한다양한서비스제공 2. Oozie : 하둡작업을관리하는워크플로우및코디네이터시스템 3. Hbase : HDFS 기반의컬럼 NoSQL 4. Pig : 복잡한 MapReduce 프로그래밍을대체할 Pig Latin 언어제공 5. Hive : 하둡기반의데이터웨어하우스, 테이블단위의데이터저장과 SQL 쿼리를지원 6. Mahout : 하둡기반으로데이터마이닝알고리즘을구현한오픈소스라이브러리 7. Hcatalog : 하둡기반의테이블및스토리지관리 8. Avro : RPC(Remote Procedure Call) 과데이터직렬화를지원하는프레임워크 9. Chukwa : 분산환경에서생성되는데이터를 HDFS 에안정적으로저장시키는플랫폼 10. Flume : 소스서버에에이전트가설치, 에이전트로부터데이터를전달받는콜랙터로구성 11. Scribe : 페이스북에서개발, 데이터수집플랫폼, Chukwa 와달리중앙집중서버로전송 12. Sqoop : 대용량데이터전송솔루션이며, HDFS, RDBMS, DW,NoSQL 등다양한저장소에대용량데이터를신속하게전송할수있는방법제공 13. Hiho : Sqoop 과같은대용량데이터전송솔루션이며, 하둡에서데이터를가져오기위한 SQL 을지정할수있으며, JDBC 인터페이스를지원

17 2. Hadoop Ecosystem 출처 : 호튼웍스
18 Part III Spark 의이해
 - Spark는분산병렬처리엔진 기존 Hive, Pig, Mahout, R, Storm 등을모두대체가능 - 분산병렬처리엔진인 Spark Core를기반으로 -")
19 Spark 개요 Spark 개요 하둡 MapReduce 보다발전된새로운분산병렬처리 Framework - 저장소는로컬파일시스템, 하둡 HDFS, NoSQL(Hbase, Redis), RDBMS( 오라클,MSSQL) - Spark는분산병렬처리엔진 기존 Hive, Pig, Mahout, R, Storm 등을모두대체가능 - 분산병렬처리엔진인 Spark Core를기반으로 - 다양한내장패키지를지원

20 Spark 개요 Spark 의특징 하둡에코시스템발전의최고봉 - 구현원리및아키텍처는 Stinger Initiative와유사 - 레코드기반과컬럼기반데이터저장이모두가능 - YARN, Hive, Sqoop, Kafka 등다양한하둡에코시스템과통합

21 Spark 개요 Spark vs MapReduce : Word Count

22 Spark 개요 구성요소

23 Spark 개요 Process & Scheduling

24 Spark 개요 Data Process Model MapReduce

25 Spark 개요 Data Process Model Spark

26 Spark 개요 Spark runs on Hadoop Cluster

27 Spark 개요 Example : Log Mining
28 Spark 개요 성능 : Logistic Regression
29 Part IV Spark 아키텍처
30 Spark 아키텍처와구현원리 함수형언어 : Scala 분산병렬처리에최적화된함수형언어의필요성 - 구글 MapReduce 프레임워크 : C/C++ 언어 - 하둡 MapReduce 프레임워크 : Java 6 / Java 7 - 하둡 Tez 프레임워크 : Java 7 / Java 8 - Spark Core 프레임워크 : Scala / Java 8 함수형언어 - 함수형언어 vs 절차형언어또는명령형언어 - 대표적인함수형언어로는 SQL # MapReduce의구현목표는분산병렬처리가가능한데이터집계기능 (SQL) # HiveQL, SQL on Hadoop( 임팔라, 타조, 프레스토등 ) - Data Work Flow는 DAG(Directed Acyclic Graph, 방향성비사이클그래프 ) # Start -> 입력 (Input) -> 처리 -> 분기 -> 처리 -> 병합 -> 처리 -> 결과 (Output) -> End - 입력이같으면결과도같아야함 - 단일머신에서병렬처리 & 클러스터에서분산병렬처리가가능 - 명령형언어이면서함수형언어의특징을가진대표적인언어 : R, Java Script, Python
 을각머신에배포해야함 ( Compile -> Job")
![Submit ) 스크립트방식 : 컴파일과정없이스크립트를그때마다해석하여 JVM에서바로실행 ( Console ) Java 컴파일 Java 실행파일 [ Console / Shell ]](/docs-images/91/105473701/images/31-6.jpg "Console > Scala 스크립트 1 Source Code (Byte Code) Console > Scala 스크립트 2 Java Virtual Machine Linux OS")
31 Spark 아키텍처와구현원리 함수형언어 : Scala 프로그래밍아키텍처 - OS : Linux - JVM( 자바가상머신 ) : 자바애플리케이션을실행하기위한가상머신 - Java 8 / Scala 프로그래밍언어 : JVM 기반의애플리케이션개발언어 - 컴파일 vs 스크립트컴파일방식 : 컴파일후실행파일 (JAR) 을각머신에배포해야함 ( Compile -> Job Submit ) 스크립트방식 : 컴파일과정없이스크립트를그때마다해석하여 JVM에서바로실행 ( Console ) Java 컴파일 Java 실행파일 [ Console / Shell ] Console > Scala 스크립트 1 Source Code (Byte Code) Console > Scala 스크립트 2 Java Virtual Machine Linux OS


32 Spark 아키텍처와구현원리 함수형언어 : Scala 분산병렬처리 : 프로그래밍실행구조 하둡 MapReduce 방식 - 하둡 MapReduce : Java/Pig/Hive 에서컴파일후 JobTracker 에 Submit -> 각머신에서실행 - Spark : 각머신에실행코드를바로전송후실행 [ Master 머신 ] JobTracker [ 클라이언트머신 ] 3.Job Submit 4.Task Assign ( 스케줄링 ) hive> 쿼리 ; 1.MapReduce [ Worker 머신 ] [ Worker 머신 ] [ Worker 머신 ] 코드생성 TaskTracker TaskTracker TaskTracker Java Source Code 5.JAR 배포 JAR 실행파일 JAR 실행파일 JAR 실행파일 2. 컴파일 6.fork() 6.fork() 6.fork() JAR 실행파일 JVM Linux OS JVM Linux OS JVM Linux OS
33 Spark 아키텍처와구현원리 함수형언어 : Scala 분산병렬처리 : 프로그래밍실행구조 - 하둡 MapReduce : Java/Pig/Hive 에서컴파일후 JobTracker 에 Submit -> 각머신에서실행 - Spark : 각머신에실행코드를전송후바로실행 Spark 방식 [ 클라이언트머신 ] [ Worker 머신 ] [ Worker 머신 ] [ Worker 머신 ] Spark Spark Spark Executor Executor Executor 2.fork() 2.fork() 2.fork() Scala> 스크립트 ; 1. 실행코드전송 JVM Linux OS JVM Linux OS JVM Linux OS [ Spark Driver ] ( 스케줄링 )
![Spark 아키텍처와구현원리 함수형언어 : Scala [ 하둡 MapReduce ] vs [ Spark ] [ 클라이언트 ]](/docs-images/91/105473701/images/34-1.jpg "Pig/Hive Shell >... [ 클라이언트 ] Spark Driver [ Master ] Scala shell >.")
![.. Job Tracker [ Worker ] [ Worker ] [ Worker ] [ Worker ] [ Worker ] [](/docs-images/91/105473701/images/34-2.jpg "Worker ] Task Tracker Task Tracker Task Tracker Spark Executor Spark")
34 Spark 아키텍처와구현원리 함수형언어 : Scala [ 하둡 MapReduce ] vs [ Spark ] [ 클라이언트 ] Pig/Hive Shell >... [ 클라이언트 ] Spark Driver [ Master ] Scala shell >... Job Tracker [ Worker ] [ Worker ] [ Worker ] [ Worker ] [ Worker ] [ Worker ] Task Tracker Task Tracker Task Tracker Spark Executor Spark Executor Spark Executor
35 Spark 아키텍처와구현원리 Data Work Flow Job DAG 의이해 - [ 하둡 MapReduce] Job : Input -> Map -> Shuffle -> Reduce -> Output - Job DAG : 1 번째 Job -> 2 번째 Job ->... -> N 번째 Job 단일 Job 2 Map Shuffle 3 Reduce 4 1 Input HDFS Output 5
![Spark 아키텍처와구현원리 Data Work Flow 단일 [ 하둡 MapReduce] Job 네트워크전송 Local I/O [ DataNode ] [ Worker ] [ Worker ] [ DataNode ] Disk Disk CPU CPU CPU CPU Disk Disk CPU CPU CPU CPU Disk Disk Disk Disk RAM RAM](/docs-images/91/105473701/images/36-3.jpg "RAM RAM Disk Disk RAM RAM RAM RAM Disk Disk [ DataNode ] [ Worker ] [ Worker ] [ DataNode ] Disk Disk CPU CPU CPU CPU Disk Disk CPU CPU CPU CPU Disk Disk Disk Disk RAM RAM RAM RAM Disk Disk RAM RAM")
36 Spark 아키텍처와구현원리 Data Work Flow 단일 [ 하둡 MapReduce] Job 네트워크전송 Local I/O [ DataNode ] [ Worker ] [ Worker ] [ DataNode ] Disk Disk CPU CPU CPU CPU Disk Disk CPU CPU CPU CPU Disk Disk Disk Disk RAM RAM RAM RAM Disk Disk RAM RAM RAM RAM Disk Disk [ DataNode ] [ Worker ] [ Worker ] [ DataNode ] Disk Disk CPU CPU CPU CPU Disk Disk CPU CPU CPU CPU Disk Disk Disk Disk RAM RAM RAM RAM Disk Disk RAM RAM RAM RAM Disk Disk [ DataNode ] [ Worker ] [ Worker ] [ DataNode ] Disk Disk CPU CPU CPU CPU Disk Disk CPU CPU CPU CPU Disk Disk Disk Disk RAM RAM RAM RAM Disk Disk RAM RAM RAM RAM Disk Disk



37 Spark 아키텍처와구현원리 Data Work Flow [ 하둡 MapReduce] Job DAG : 1 번째 Job -> 2 번째 Job ->... -> N 번째 Job 1번째 Job 2번째 Job 4번째 Job 5번째 Job 3 번째 Job Input Data 임시 Data Input Data 임시 Data 임시 Data Output Data HDFS
38 Spark 아키텍처와구현원리 Data Work Flow 하둡 MapReduce의단점 - Disk I/O가크다. - 네트워크부하가크다. - 전체 Work을여러단계의 Job으로분리하는것은굉장히어렵고이해하기도힘들다. 대안 => 스파크 - 입출력사이의중간과정은 Disk대신메모리에서처리. - 작업은단일 Job : 대신여러단계의 Stage로구분해서내부적으로실행됨. - 배치성작업뿐만아니라대화형분석이가능 - Data Work Flow : RDD(Resilient Distributed Dataset, 탄력적인분산데이터셋 ) Graph로유지관리. - Input, Map, Shuffle, Reduce, Output을위한체계적인 Operator 제공. - Operator는 Transformation과 Action로크게구분. - Action 연산시에만실제실행 : 지연실행 (Lazy Evaluation) - Persist( ) 를요청하면특정 RDD를인메모리에상주시킴. - 물리적인파티션을직접관리할수있음.
39 Spark 아키텍처와구현원리 Spark RDD 와인메모리방식 RDD 개요 - Resilient Distributed Dataset : 탄력적인분산데이터셋 - Resilient : 처리과정에서일부데이터가손상되어서복구가가능 ( 부분손상 -> 부분복구 ) - Distributed : 처리과정에서데이터를여러머신에분산저장 => 파티션 (Partition) - RDD Graph : [Input] -> RDD -> RDD ->... -> RDD -> [Output] RDD RDD RDD RDD RDD RDD RDD Input Input 데이터저장소 (HDFS or RDBMS) Output Output
![Spark 아키텍처와구현원리 Spark RDD 와인메모리방식 RDD 논리및물리계획 A Block1 A Block2 A Block3 B B Block1 Block2 C Block1 [ HDFS ] [ Worker ] [ Worker ] [ Worker ] Input - A Input - B Input - C B Part1 B Part1 RDD - B B1](/docs-images/91/105473701/images/40-3.jpg "Part1 B1 Part1 C Part1 RDD B1 RDD - C A Part1 A Part2 A Part3 BC Part1 BC Part2 BC Part3 RDD - A RDD - BC [ Worker ] [ Worker ] [ Worker ] A BC A BC A BC RDD - ABC B1 = B.filter( ) BC = B1.")
40 Spark 아키텍처와구현원리 Spark RDD 와인메모리방식 RDD 논리및물리계획 A Block1 A Block2 A Block3 B B Block1 Block2 C Block1 [ HDFS ] [ Worker ] [ Worker ] [ Worker ] Input - A Input - B Input - C B Part1 B Part1 RDD - B B1 Part1 B1 Part1 C Part1 RDD B1 RDD - C A Part1 A Part2 A Part3 BC Part1 BC Part2 BC Part3 RDD - A RDD - BC [ Worker ] [ Worker ] [ Worker ] A BC A BC A BC RDD - ABC B1 = B.filter( ) BC = B1.union( C ) ABC Part1 ABC Part2 ABC Part3 RDD - D ABC = A.join( BC ) D = ABC.aggregate( ) D Part1 D Part2 D Part3 Output - D 논리계획 물리계획 D Block1 D Block2 D Block3 [ HDFS ]
41 Spark 아키텍처와구현원리 Spark 연산및대화형분석 Transformation과 Action - Transformation은입력데이터셋을단계별 RDD로변형하는연산자 - Action은결과를콘솔에서보거나 HDFS등에저장하는연산자 - Action 연산자를실행하면입력소스에서데이터를불러와서처리하고그결과를보여주거나저장 => 즉 Transformation 연산은실제실행되지않고 Action 연산을요청할때에만실행되므로이런방식을 Lazy Evaluation( 지연실행 ) 이라고부름 특징 - Pig, Hive 등이제공하는연산자보다직관적이고효율적인다수의연산자를지원함 - 주의할점은 Action을요청할때마다데이터를입력소스에서불러와서처리함 => 원하는 RDD에 persist( ) 메소드로분산캐싱을명시하는방법을제공 - 대화형으로동일한입력데이터셋을처리하고요약 ( 집계 ) 할때효율적임 - Spark 연산자를이용한다양한라이브러리를제공
![Spark 아키텍처와구현원리 Spark 연산및대화형분석 효율적인대화형분석절차 [ 첫번째작업 ] Scala> A1.count( ) 12,300 콘솔에서바로확인 RDD-A 3.](/docs-images/91/105473701/images/42-2.jpg "캐싱 ( 인메모리 ) 2.RDD 변형 (Transformation) RDD-A1 RDD-AB RDD 변형 [ 두번째작업 ] Scala> B = load( 'B' ) A.")
 Scala> D.")
42 Spark 아키텍처와구현원리 Spark 연산및대화형분석 효율적인대화형분석절차 [ 첫번째작업 ] Scala> A1.count( ) 12,300 콘솔에서바로확인 RDD-A 3. 캐싱 ( 인메모리 ) 2.RDD 변형 (Transformation) RDD-A1 RDD-AB RDD 변형 [ 두번째작업 ] Scala> B = load( 'B' ) A.filter( ) A1.persist( ) RDD-B Scala> AB = A1.join( B ) Scala> C = AB.groupby( ) RDD-C 1. 입력데이터셋 로딩 집계후 [ N 번째작업 ] 결과저장 Input - A Input - B RDD-D Scala> D = C.aggregate( ) Scala> D.SaveAsText( 'D' ) Output - D
43 Spark 아키텍처와구현원리 Spark 연산및대화형분석 분산캐싱 ( 인메모리 ) - 매번 HDFS나 RDBMS에서데이터를불러오는것은비효율적이고시간이오래걸림 - 원하는특정 RDD를분산캐싱 ( 다수의머신에있는메모리에데이터를상주시킴 ) 할수있음 - 캐싱은메모리 ( 우선 ) 와 Disk 모두가능. - 직렬화 ( 압축, 컬럼기반 ) 옵션을지원. SSD 권장 옵션 필요공간 CPU시간 메모리저장 디스크저장 비고 MEMORY_ONLY 많음 낮음 YES X MEMORY_ONLY_SER 적음 높음 YES X 직렬화 MEMORY_AND_DISK 많음 중간 일부 ( 우선 ) 일부 MEMORY_AND_DISK_SER 적음 높음 일부 ( 우선 ) 일부 직렬화 DISK_ONLY 적음 낮음 X YES



![데이터용 ] [ Spark](/docs-images/91/105473701/images/44-6.jpg "캐싱용 ] 10 GB/s [")
![RAM ] 100 MB/s](/docs-images/91/105473701/images/44-9.jpg "[ DISK ] 500")
44 Spark 아키텍처와구현원리 Spark 연산및대화형분석 성능고려사항 RAM 은빠르지만 저장용량이적음 DISK 보다빠름 RAM 보다용량이큼 [ HDFS 데이터용 ] [ Spark 캐싱용 ] 10 GB/s [ RAM ] 100 MB/s [ DISK ] 500 MB/s [ SSD ]
45 Spark 을활용한대화형분석 실행방식 로컬모드 $ bin/pyspark --master local - Shell을실행하는로컬머신에서, 단일프로세서로 Spark이실행됨 - Spark/PySpark Shell 모두가능 로컬 [N] 모드 $ bin/pyspark --master local[n] - Shell을실행하는로컬머신에서, [N] 개의프로세서로 Spark이병렬로실행됨 - Spark/PySpark Shell 모두가능 분산모드 $ bin/spark-shell --master spark://master.host: Spark Master/Worker 데몬이구동되고있는클러스터환경에서, 분산 + 병렬로실행됨 - Spark Shell 만가능 -> 클러스터매니저를 Mesos를사용할경우 $ bin/spark-shell --master mesos://mesos.host:port
46 Spark 을활용한대화형분석 Spark 기능구조도 [ 패키지 ] SparkSQL GraphX MLlib Streaming SparkR... [ 맵리듀스실행엔진 ] Spark Core [ 자원관리시스템 ] YARN, Mesos, Spark Standalone Manager [ 데이터저장소 ] HDFS, NoSQL, RDBMS
47 Spark 을활용한대화형분석 Spark 의주요기능 구분모듈기능분야 핵심 Spark Core 맵리듀스와같은병렬처리및반복연산분산병렬처리 Spark SQL 하이브와같은 SQL 분석데이터웨어하우스 주요패키지 MLlib 마훗과같은머신러닝라이브러리데이터마이닝 GraphX 네트워크분석 SNA 등네트워크분석 Spark Streaming 스톰과같은실시간스트리밍분석스트리밍처리및분석 확장프로젝트 BlinkDB 빠른응답속도를가진 SQL 쿼리분석 Ad-Hoc 분석 SparkR 통계패키지인 R 과의통합통계분석

48 Spark 을활용한대화형분석 SparkSQL SQL 쿼리분석 - 입력 : HDFS/Hive, RDBMS, NoSQL, Text File( Plain Text, JSON, XML 등 ) - 데이터셋을 DB Table로처리, 내부적으로는 DataFrame 형식 SparkSQL Spark Core Hive Presto HBase HDFS Text JSON XML Mysql Oracle 몽고 DB
49 Part V 머신러닝의이해


50 머신러닝개요 머신러닝주요기법
 INPUT 블랙박스 (Hidden Layer)")
51 머신러닝개요 머신러닝의기본구조 사전학습 ( Training ) INPUT 블랙박스 (Hidden Layer) OUTPUT
 패턴패턴 선정 (Selection) 목표데이터 분석주제선정 대상데이터원본데이터원천데이터 대상데이터대상데이터")
52 머신러닝개요 통계 / 분석프로세스 해석 / 평가 (Assessment) 모델링 (Modeling) 변형 (Transformation) 결과 정제 (Cleansing) 패턴패턴 선정 (Selection) 목표데이터 분석주제선정 대상데이터원본데이터원천데이터 대상데이터대상데이터 전처리



")
")
53 머신러닝개요 데이터마이닝 & 머신러닝프로세스 데이터 데이터 모델 모델 모델적용 획득 전처리 학습 평가 ( 서비스 ) 최적화 (AB 테스트 )
54 머신러닝개요 통계 데이터마이닝 머신러닝
55 머신러닝개요 Descriptive statistics via summary( ) > summary(mtcars[vars]) mpg hp wt Min. :10.4 Min. :52.0 Min. :1.51 1st Qu. :15.4 1st Qu. :96.5 1st Qu. :2.58 Median :19.2 Median :123.0 Median :3.33 Mean :20.1 Mean :146.7 Mean :3.22 3rd Qu. :22.8 3rd Qu. : rd Qu. :3.61 Max. :33.9 Max. :335.0 Max. :5.42

56 머신러닝개요 N=32 Bandwidth=2.477 Kernel Density of Miles Per Gallon
57 머신러닝개요
58 머신러닝개요
59 머신러닝개요
60 머신러닝개요
61 Part VI Spark MLlib
62 1. Data Model 1) Data Model ML을위해필요한 Data Type의분류 (1) Spark Basic Type - vector, matrix, array - list, dataframe (2) MLlib Type - LabeledPoint - Rating - 알고리즘별 Model Class
63 1. Data Model 1) Data Model Spark Basic Type (1) Vector - 동일한 Type의데이터 N개, 1차원, 고정길이 // Create a dense vector (1.0, 0.0, 3.0). val dv: Vector = Vectors.dense(1.0, 0.0, 3.0) [Note] 수학분야의방향과크기를가지고있는데이터를의미하지않음 (2) Matrix - 동일한 Type의데이터, 2차원, M개의행과 N개의열로구성 ( M*N 행열 ) // Create a dense matrix ((1.0, 2.0), (3.0, 4.0), (5.0, 6.0)) val dm: Matrix = Matrices.dense(3, 2, Array(1.0, 3.0, 5.0, 2.0, 4.0, 6.0)) (3) Array - 동일한 Type의데이터, N차원 (1차원, 2차원,... N차원 ), 고정길이 var z = new Array[String](3); z(0) = "Zara"; z(1) = "Nuha"; z(2) = "Ayan" var z2 = Array("Zara", "Nuha", "Ayan") (4) List - 동일한 Type의데이터, 1차원, 가변길이 (5) DataFrame - 다양한 Type의데이터, 2차원, 엑셀 Sheet or 데이터베이스테이블구조와유사
64 1. Data Model 1) Data Model Vector Type (1) Vector의분류 - 고밀도 : Dense -> 전체데이터를 double type의고정길이배열에저장 - 저밀도 : Sparse -> 0.0이아닌값과그인덱스를저장 (2) Example // Create the dense vector <1.0, 0.0, 2.0, 0.0>; val densevec1 = Vectors.dense(1.0, 0.0, 2.0, 0.0) val densevec2 = Vectors.dense(Array(1.0, 0.0, 2.0, 0.0)) // Create the sparse vector <1.0, 0.0, 2.0, 0.0>; val sparsevec1 = Vectors.sparse(4, Array(0, 2), Array(1.0, 2.0)) //(int size, int[] indices, double[] values) (3) Vectors 메소드 apply argmax asinstanceof compressed copy foreachactive isinstanceof numactives numnonzeros size toarray todense tojson tosparse tostring
65 1. Data Model 1) Data Model LabeledPoint Type (1) LabeledPoint = ( Labeled : double, Features : vectors ) - Labeled -> 1.Classification : 명목형값 (classes) -> double Binary( True, False ) -> 1.0 / 0.0 MultiClass -> N.0 2.Regression : 연속형값 ( 수치형 ), double - Features -> 속성값 Vectors(double) 명목형 Feature의값은 double type으로변환해야함 (2) Example scala> val examples = MLUtils.loadLibSVMFile(sc, "file:///data/spark-1.6.0/data/mllib/sample_binary_classification_data.txt") examples: org.apache.spark.rdd.rdd[org.apache.spark.mllib.regression.labeledpoint] scala> println(examples.take(2).mkstring("\n")) (0.0, (692, [127,128,129,...,656,657], [ 51.0,159.0,253.0,...,141.0, 37.0] ) ) (1.0, (692, [158,159,160,...,682,683], [124.0,253.0,255.0,...,253.0,220.0] ) ) scala> val data = sc.textfile("file:///data/spark-1.6.0/data/mllib/sample_binary_classification_data.txt") scala> println(data.take(2).mkstring("\n")) 0 128:51 129: : : : : : : : :220
66 2. Data 처리 2) 데이터처리 데이터처리개요 1. 데이터셋선택 2. 데이터로딩 3. 데이터탐색 4. 데이터클린징 5. 데이터변환
67 2. Data 처리 2) 데이터처리 머신러닝공개데이터셋 1. UCI 데이터저장소 - 300여개의데이터셋 (classification,regression, clustering, recommender systems) 2. 아마존공개데이터셋 - Human Genome Project, Common Crawl web corpus, Wikipedia data, Google Books Ngrams 3. 캐글 (Kaggle) 데이터셋 - 머신러닝대회, classification, regression, ranking, recommender systems, image analysis 4. KDnuggets 데이터셋 - 공개데이터셋목록
68 2. Data 처리 2) 데이터처리 Spark Examles 데이터셋 1. 위치 $SPARK_HOME/data/mllib/ 2. 파일목록 ( Line 개수, Word 개수, File Size ) gmm_data.txt kmeans_data.txt lr_data.txt pagerank_data.txt pic_data.txt sample_binary_classification_data.txt sample_fpgrowth.txt sample_isotonic_regression_data.txt sample_lda_data.txt sample_libsvm_data.txt sample_linear_regression_data.txt sample_movielens_data.txt sample_multiclass_classification_data.txt sample_naive_bayes_data.txt sample_svm_data.txt sample_tree_data.csv lr-data/random.data ridge-data/lpsa.data
69 2. Data 처리 2) 데이터처리 데이터로딩 1. 데이터소스 - 로컬파일시스템 - 분산파일시스템 : HDFS, 아마존 S3 등 - RDBMS / NoSQL : Mysql, Oralce, 카산드라, HBase, ElasticSearch 등 -> JDBC Driver로연결 2. 파일포맷 - Text File - JSON File - CSV File( CSV is ",", TSV is "\t" ) - Key/Value(Hadoop Format) File - Object
70 2. Data 처리 2) 데이터처리 데이터로딩 3. Text File 불러오기 val data = sc.textfile("file:///data/spark-1.6.0/data/mllib/pic_data.txt") println(data.take(3).mkstring("\n")) data.first() data.count() 4. 컬럼분리 ( BackSpace, CSV, TSV ) val initdata = data.map { line => val values = line.split(' ')map(_.todouble) Vectors.dense(values.init) } println(initdata.take(3).mkstring("\n")) val firstdata = data.map { line => val values = line.split(' ')map(_.todouble) Vectors.dense(values(0)) } println(firstdata.take(3).mkstring("\n")) val lastdata = data.map { line => val values = line.split(' ')map(_.todouble) Vectors.dense(values.last) } println(lastdata.take(3).mkstring("\n")) val taildata = data.map { line => val values = line.split(' ')map(_.todouble) Vectors.dense(values.tail) } println(taildata.take(3).mkstring("\n"))
71 2. Data 처리 2) 데이터처리 데이터탐색 1. RDD 기초통계 scala> val second = data.map { line => val values = line.split(' ').map(_.todouble) (values(1)) } second: org.apache.spark.rdd.rdd[double] = MapPartitionsRDD[23] at map at <console>:36 scala> println(second.collect().mkstring("\n")) scala> second.stats res42: org.apache.spark.util.statcounter = (count: 19, mean: , stdev: , max: , min: )
![2. Data 처리 2) 데이터처리 데이터탐색 2. RDD[Vector] 기초통계 scala> val features = data.map { line => val values = line.split(' ').map(_.todouble) Vectors.](/docs-images/91/105473701/images/72-2.jpg "dense(values) } # MultivariateStatisticalSummary 메소드목록 asinstanceof count isinstanceof max mean min norml1 norml2 numnonzeros tostring variance features: org.apache.spark.rdd.rdd[org.apache.spark.mllib.")
72 2. Data 처리 2) 데이터처리 데이터탐색 2. RDD[Vector] 기초통계 scala> val features = data.map { line => val values = line.split(' ').map(_.todouble) Vectors.dense(values) } # MultivariateStatisticalSummary 메소드목록 asinstanceof count isinstanceof max mean min norml1 norml2 numnonzeros tostring variance features: org.apache.spark.rdd.rdd[org.apache.spark.mllib.linalg.vector] = MapPartitionsRDD[30] at map at <console>:41 scala> println(features.take(3).mkstring("\n")) [0.0,1.0,1.0] [0.0,2.0,1.0] [0.0,3.0,1.0] scala> import org.apache.spark.mllib.stat.{multivariatestatisticalsummary, Statistics} scala> val summary: MultivariateStatisticalSummary = Statistics.colStats(features) scala> summary.mean res56: org.apache.spark.mllib.linalg.vector = [ , , ] scala> summary.variance res57: org.apache.spark.mllib.linalg.vector = [ , , ] scala> summary.numnonzeros res58: org.apache.spark.mllib.linalg.vector = [16.0, 19.0, 19.0]
73 2. Data 처리 2) 데이터처리 데이터탐색 3. RDD[Vector] Correlations scala> val correlmatrix: Matrix = Statistics.corr(features, "pearson") correlmatrix: org.apache.spark.mllib.linalg.matrix =
74 2. Data 처리 2) 데이터처리 데이터변환 1. 텍스트변환 : TF(Term Frequency) 데이터셋 : 개의뉴스그룹 scala> import org.apache.spark.mllib.feature.hashingtf scala> val data = sc.wholetextfiles("file:///data/spark-1.6.0/data/train.electronics/*") scala> val text = data.map { case (file, text) => text } scala> text.count res3: Long = 591 scala> text.first() res4: String = "From: [email protected]... scala> val tf = new HashingTF(numFeatures = 10000) scala> val termf = text.map(txt => tf.transform(txt.split(" "))) scala> termf.first() res5: org.apache.spark.mllib.linalg.vector = (10000,[0,22,43,45,54,73,145,182,334,434,866,1015,1075,1563,1577,1666,1691,1786,1818,2266,2284,2752,2932,3159,3355,3480,3502,3521,3524,3543,4145,4262,4304,4468,4773,4801,5240,5475,5636,5848,5853,5936,6048,6051,6216,6852,6979,6988,7118,7285,7525,7817,7865,8056,8642,8 661,8786,9011,9131,9467,9493,9792],[7.0,1.0,1.0,7.0,2.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,3.0,2.0,1.0,1.0,2.0,1.0,1.0,1.0,1.0,2.0,2.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,2.0,1.0,2.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,2.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,2.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0,1.0])
75 2. Data 처리 2) 데이터처리 데이터변환 2. 속성값정량화 : StandardScaler scala> import org.apache.spark.mllib.feature.standardscaler scala> val example = sc.textfile("file:///data/spark-1.6.0/data/mllib/ridge-data/lpsa.data") scala> val data = example.map { line => val parts = line.split(',') LabeledPoint(parts(0).toDouble, Vectors.dense(parts(1).split(' ').map(_.todouble))) }.cache() scala> val scaler1 = new StandardScaler().fit(data.map(x => x.features)) scala> val scaler2 = new StandardScaler(withMean = true, withstd = true).fit(data.map(x => x.features)) scala> val data1 = data.map(x => LabeledPoint(x.label, scaler1.transform(x.features))) scala> val data2 = data.map(x => LabeledPoint(x.label, scaler2.transform(vectors.dense(x.features.toarray)))) scala> val summary: MultivariateStatisticalSummary = Statistics.colStats(data.map(x => x.features)) scala> val summary1: MultivariateStatisticalSummary = Statistics.colStats(data1.map(x => x.features)) scala> val summary2: MultivariateStatisticalSummary = Statistics.colStats(data2.map(x => x.features))
76 2. Data 처리 2) 데이터처리 데이터변환 2. 속성값정량화 : StandardScaler scala> summary.mean [ , , , , , , , ] scala> summary1.mean [ , , , , , , , ] scala> summary2.mean [0.0, E-16, E-16, E-16, E-17, E-16, E-16, E-16] scala> summary.variance [ , , , , , , , ] scala> summary1.variance [1.0,1.0,1.0, ,1.0, , , ] scala> summary2.variance [1.0,1.0,1.0, , , , , ]
77 3. MLlib Example MLlib Process Process 1단계 : 데이터로딩 2단계 : 학습데이터 / 평가데이터로분리 3단계 : 학습 (Training) 4단계 : 평가 5단계 : 모델저장 6단계 : 서비스활용
78 3. MLlib Example Spark MLlib 예제
79 3. MLlib Example MLlib Example NaiveBayes 분류기 (1) scala> import org.apache.spark.mllib.classification.{naivebayes, NaiveBayesModel} scala> import org.apache.spark.mllib.linalg.vectors scala> import org.apache.spark.mllib.regression.labeledpoint scala> val data = sc.textfile("file:///data/spark-1.6.0/data/mllib/sample_naive_bayes_data.txt") scala> println(data.collect().mkstring("\n")) scala> val parseddata = data.map { line => val parts = line.split(',') LabeledPoint(parts(0).toDouble, Vectors.dense(parts(1).split(' ').map(_.todouble))) } scala> val splits = parseddata.randomsplit(array(0.6, 0.4), seed = 11L) scala> val training = splits(0) scala> val test = splits(1) scala> training.count()
80 3. MLlib Example MLlib Example NaiveBayes 분류기 (2) scala> val model = NaiveBayes.train(training, lambda = 1.0, modeltype = "multinomial") scala> val predictionandlabel = test.map(p => (model.predict(p.features), p.label)) scala> val accuracy = 1.0 * predictionandlabel.filter(x => x._1 == x._2).count() scala> test.count() scala> println(predictionandlabel.collect().mkstring("\n")) scala> val trainprediction = training.map(p => (model.predict(p.features), p.label)) scala> val trainaccuracy = 1.0 * trainprediction.filter(x => x._1 == x._2).count() scala> training.count() scala> println(training.collect().mkstring("\n")) scala> println(trainprediction.collect().mkstring("\n")) scala> model.save(sc, "mymodel_naivebayes") scala> val NBModel = NaiveBayesModel.load(sc, "mymodel_naivebayes")
81 3. MLlib Example MLlib Example DecisionTree 분류기 (1) scala> import org.apache.spark.mllib.tree.decisiontree scala> import org.apache.spark.mllib.tree.model.decisiontreemodel scala> import org.apache.spark.mllib.util.mlutils scala> val data = MLUtils.loadLibSVMFile(sc, "file:///data/spark-1.6.0/data/mllib/sample_libsvm_data.txt") scala> println(data.collect().mkstring("\n")) scala> val numclasses = 2 scala> val categoricalfeaturesinfo = Map[Int, Int]() scala> val impurity = "gini" scala> val maxdepth = 5 scala> val maxbins = 32
82 3. MLlib Example MLlib Example DecisionTree 분류기 (2) scala> val splits = data.randomsplit(array(0.7, 0.3)) scala> val (trainingdata, testdata) = (splits(0), splits(1)) scala> val model = DecisionTree.trainClassifier(trainingData, numclasses, categoricalfeaturesinfo, impurity, maxdepth, maxbins) scala> val labelandpreds = testdata.map { point => val prediction = model.predict(point.features) (point.label, prediction) } scala> val testerr = labelandpreds.filter(r => r._1!= r._2).count.todouble scala> testdata.count() scala> model.save(sc, "mymodel_dtree") scala> val DTModel = DecisionTreeModel.load(sc, "mymodel_dtree")
83 4. MLlib 알고리즘 Spark MLlib 알고리즘목록 logistic regression and linear support vector machine (SVM) classification and regression tree random forest and gradient-boosted trees recommendation via alternating least squares (ALS) clustering via k-means, bisecting k-means, Gaussian mixtures (GMM), and power iteration clustering topic modeling via latent Dirichlet allocation (LDA) survival analysis via accelerated failure time model singular value decomposition (SVD) and QR decomposition principal component analysis (PCA) linear regression with L1, L2, and elastic-net regularization isotonic regression multinomial/binomial naive Bayes frequent itemset mining via FP-growth and association rules sequential pattern mining via PrefixSpan summary statistics and hypothesis testing feature transformations model evaluation and hyper-parameter tuning
84 4. MLlib 알고리즘 Spark MLlib 알고리즘분류 분류및회귀 linear models (SVMs, logistic regression, linear regression) decision trees naive Bayes ensembles of trees (Random Forests and Gradient-Boosted Trees) isotonic regression 추천 (Collaborative filtering) alternating least squares (ALS) 군집 k-means, bisecting k-means, streaming k-means Gaussian mixture power iteration clustering (PIC) latent Dirichlet allocation (LDA) 차원축소 singular value decomposition (SVD) principal component analysis (PCA) 빈발패턴마이닝 (Frequent pattern mining) FP-growth association rules PrefixSpan
85 4. MLlib 알고리즘 분류및회귀 ( 예측 ) 모델 구분 모델 Binary Classification Multiclass Classification Regression linear SVMs, logistic regression, decision trees, random forests, gradient-boosted trees, naive Bayes logistic regression, decision trees, random forests, naive Bayes linear least squares, Lasso, ridge regression, decision trees, random forests, gradient-boosted trees, isotonic regression


86 # 참고자료 Spark Papers Spark RDD Spark: Cluster Computing with Working Sets June Spark RDD : Fault Tolerant & In-Memory Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In- Memory Cluster Computing April



87 # 참고자료 Spark Books
88 감사합니다.
Slide 1
 빅데이터기술의이해 2016. 8. 23 장형석 충북대비즈니스데이터융합학과교수 [email protected] 장형석교수 # 경력 ( 현직 ) - 충북대학교비즈니스데이터융합학과 - 국민대학교빅데이터경영 MBA 과정겸임교수 - 연세대학교데이터사이언스과정외래교수 # 저서및역서 - [ 실전하둡운용가이드 ] 한빛미디어, 2013.07 - [ 빅데이터컴퓨팅기술 ]
빅데이터기술의이해 2016. 8. 23 장형석 충북대비즈니스데이터융합학과교수 [email protected] 장형석교수 # 경력 ( 현직 ) - 충북대학교비즈니스데이터융합학과 - 국민대학교빅데이터경영 MBA 과정겸임교수 - 연세대학교데이터사이언스과정외래교수 # 저서및역서 - [ 실전하둡운용가이드 ] 한빛미디어, 2013.07 - [ 빅데이터컴퓨팅기술 ]
PowerPoint 프레젠테이션
 In-memory 클러스터컴퓨팅프레임워크 Hadoop MapReduce 대비 Machine Learning 등반복작업에특화 2009년, UC Berkeley AMPLab에서 Mesos 어플리케이션으로시작 2010년 Spark 논문발표, 2012년 RDD 논문발표 2013년에 Apache 프로젝트로전환후, 2014년 Apache op-level Project
In-memory 클러스터컴퓨팅프레임워크 Hadoop MapReduce 대비 Machine Learning 등반복작업에특화 2009년, UC Berkeley AMPLab에서 Mesos 어플리케이션으로시작 2010년 Spark 논문발표, 2012년 RDD 논문발표 2013년에 Apache 프로젝트로전환후, 2014년 Apache op-level Project
DB진흥원 BIG DATA 전문가로 가는 길 발표자료.pptx
 빅데이터의기술영역과 요구역량 줌인터넷 ( 주 ) 김우승 소개 http://zum.com 줌인터넷(주) 연구소 이력 줌인터넷 SK planet SK Telecom 삼성전자 http://kimws.wordpress.com @kimws 목차 빅데이터살펴보기 빅데이터에서다루는문제들 NoSQL 빅데이터라이프사이클 빅데이터플랫폼 빅데이터를위한역량 빅데이터를위한역할별요구지식
빅데이터의기술영역과 요구역량 줌인터넷 ( 주 ) 김우승 소개 http://zum.com 줌인터넷(주) 연구소 이력 줌인터넷 SK planet SK Telecom 삼성전자 http://kimws.wordpress.com @kimws 목차 빅데이터살펴보기 빅데이터에서다루는문제들 NoSQL 빅데이터라이프사이클 빅데이터플랫폼 빅데이터를위한역량 빅데이터를위한역할별요구지식
Open Cloud Engine Open Source Big Data Platform Flamingo Project Open Cloud Engine Flamingo Project Leader 김병곤
 Open Cloud Engine Open Source Big Data Platform Flamingo Project Open Cloud Engine Flamingo Project Leader 김병곤 ([email protected]) 빅데이터분석및서비스플랫폼 모바일 Browser 인포메이션카탈로그 Search 인포메이션유형 보안등급 생성주기 형식
Open Cloud Engine Open Source Big Data Platform Flamingo Project Open Cloud Engine Flamingo Project Leader 김병곤 ([email protected]) 빅데이터분석및서비스플랫폼 모바일 Browser 인포메이션카탈로그 Search 인포메이션유형 보안등급 생성주기 형식
김기남_ATDC2016_160620_[키노트].key
![김기남_ATDC2016_160620_[키노트].key](/thumbs/85/91488855.jpg "김기남_ATDC2016_160620_[키노트].key") metatron Enterprise Big Data SKT Metatron/Big Data Big Data Big Data... metatron Ready to Enterprise Big Data Big Data Big Data Big Data?? Data Raw. CRM SCM MES TCO Data & Store & Processing Computational
metatron Enterprise Big Data SKT Metatron/Big Data Big Data Big Data... metatron Ready to Enterprise Big Data Big Data Big Data Big Data?? Data Raw. CRM SCM MES TCO Data & Store & Processing Computational
슬라이드 1
 Data-driven Industry Reinvention All Things Data Con 2016, Opening speech SKT 종합기술원 최진성원장 Big Data Landscape Expansion Big Data Tech/Biz 진화방향 SK Telecom Big Data Activities Lesson Learned and Other Topics
Data-driven Industry Reinvention All Things Data Con 2016, Opening speech SKT 종합기술원 최진성원장 Big Data Landscape Expansion Big Data Tech/Biz 진화방향 SK Telecom Big Data Activities Lesson Learned and Other Topics
[Brochure] KOR_TunA
![[Brochure] KOR_TunA](/thumbs/95/123928128.jpg "[Brochure] KOR_TunA") LG CNS LG CNS APM (TunA) LG CNS APM (TunA) 어플리케이션의 성능 개선을 위한 직관적이고 심플한 APM 솔루션 APM 이란? Application Performance Management 란? 사용자 관점 그리고 비즈니스 관점에서 실제 서비스되고 있는 어플리케이션의 성능 관리 체계입니다. 이를 위해서는 신속한 장애 지점 파악 /
LG CNS LG CNS APM (TunA) LG CNS APM (TunA) 어플리케이션의 성능 개선을 위한 직관적이고 심플한 APM 솔루션 APM 이란? Application Performance Management 란? 사용자 관점 그리고 비즈니스 관점에서 실제 서비스되고 있는 어플리케이션의 성능 관리 체계입니다. 이를 위해서는 신속한 장애 지점 파악 /
빅데이터_DAY key
 Big Data Near You 2016. 06. 16 Prof. Sehyug Kwon Dept. of Statistics 4V s of Big Data Volume Variety Velocity Veracity Value 대용량 다양한 유형 실시간 정보 (불)확실성 가치 tera(1,0004) - peta -exazetta(10007) bytes in 2020
Big Data Near You 2016. 06. 16 Prof. Sehyug Kwon Dept. of Statistics 4V s of Big Data Volume Variety Velocity Veracity Value 대용량 다양한 유형 실시간 정보 (불)확실성 가치 tera(1,0004) - peta -exazetta(10007) bytes in 2020
CONTENTS Volume.174 2013 09+10 06 테마 즐겨찾기 빅데이터의 현주소 진일보하는 공개 기술, 빅데이터 새 시대를 열다 12 테마 활동 빅데이터 플랫폼 기술의 현황 빅데이터, 하둡 품고 병렬처리 가속화 16 테마 더하기 국내 빅데이터 산 학 연 관
 방송 통신 전파 KOREA COMMUNICATIONS AGENCY MAGAZINE 2013 VOL.174 09+10 CONTENTS Volume.174 2013 09+10 06 테마 즐겨찾기 빅데이터의 현주소 진일보하는 공개 기술, 빅데이터 새 시대를 열다 12 테마 활동 빅데이터 플랫폼 기술의 현황 빅데이터, 하둡 품고 병렬처리 가속화 16 테마 더하기 국내
방송 통신 전파 KOREA COMMUNICATIONS AGENCY MAGAZINE 2013 VOL.174 09+10 CONTENTS Volume.174 2013 09+10 06 테마 즐겨찾기 빅데이터의 현주소 진일보하는 공개 기술, 빅데이터 새 시대를 열다 12 테마 활동 빅데이터 플랫폼 기술의 현황 빅데이터, 하둡 품고 병렬처리 가속화 16 테마 더하기 국내
RUCK2015_Gruter_public
 Apache Tajo 와 R 을연동한빅데이터분석 고영경 / 그루터 [email protected] 목차 : R Tajo Tajo RJDBC Tajo Tajo UDF( ) TajoR Demo Q&A R 과빅데이터분석 ' R 1) R 2) 3) R (bigmemory, snowfall,..) 4) R (NoSQL, MapReduce, Hive / RHIPE, RHive,..)
Apache Tajo 와 R 을연동한빅데이터분석 고영경 / 그루터 [email protected] 목차 : R Tajo Tajo RJDBC Tajo Tajo UDF( ) TajoR Demo Q&A R 과빅데이터분석 ' R 1) R 2) 3) R (bigmemory, snowfall,..) 4) R (NoSQL, MapReduce, Hive / RHIPE, RHive,..)
 Amazon EBS (Elastic Block Storage) Amazon EC2 Local Instance Store (Ephemeral Volumes) Amazon S3 (Simple Storage Service) / Glacier Elastic File Syste (EFS) Storage Gateway AWS Import/Export 1 Instance
Amazon EBS (Elastic Block Storage) Amazon EC2 Local Instance Store (Ephemeral Volumes) Amazon S3 (Simple Storage Service) / Glacier Elastic File Syste (EFS) Storage Gateway AWS Import/Export 1 Instance
Basic Template
 Hadoop EcoSystem 을홗용한 Hybrid DW 구축사례 2013-05-02 KT cloudware / NexR Project Manager 정구범 klaus.jung@{kt nexr}.com KT의대용량데이터처리이슈 적재 Data의폭발적인증가 LTE 등초고속무선 Data 통싞 : 트래픽이예상보다빨리 / 많이증가 비통싞 ( 컨텐츠 / 플랫폼 /Bio/
Hadoop EcoSystem 을홗용한 Hybrid DW 구축사례 2013-05-02 KT cloudware / NexR Project Manager 정구범 klaus.jung@{kt nexr}.com KT의대용량데이터처리이슈 적재 Data의폭발적인증가 LTE 등초고속무선 Data 통싞 : 트래픽이예상보다빨리 / 많이증가 비통싞 ( 컨텐츠 / 플랫폼 /Bio/
빅데이터분산컴퓨팅-5-수정
 Apache Hive 빅데이터분산컴퓨팅 박영택 Apache Hive 개요 Apache Hive 는 MapReduce 기반의 High-level abstraction HiveQL은 SQL-like 언어를사용 Hadoop 클러스터에서 MapReduce 잡을생성함 Facebook 에서데이터웨어하우스를위해개발되었음 현재는오픈소스인 Apache 프로젝트 Hive 유저를위한
Apache Hive 빅데이터분산컴퓨팅 박영택 Apache Hive 개요 Apache Hive 는 MapReduce 기반의 High-level abstraction HiveQL은 SQL-like 언어를사용 Hadoop 클러스터에서 MapReduce 잡을생성함 Facebook 에서데이터웨어하우스를위해개발되었음 현재는오픈소스인 Apache 프로젝트 Hive 유저를위한
들어가는글 2012년 IT 분야에서최고의관심사는아마도빅데이터일것이다. 관계형데이터진영을대표하는오라클은 2011년 10월개최된 오라클오픈월드 2011 에서오라클빅데이터어플라이언스 (Oracle Big Data Appliance, 이하 BDA) 를출시한다고발표하였다. 이와
 를출시한다고발표하였다. 이와") Oracle Data Integrator 와 Oracle Big Data Appliance 저자 - 김태완부장, 한국오라클 Fusion Middleware([email protected]) 오라클은최근 Big Data 분약에 End-To-End 솔루션을지원하는벤더로급부상하고있고, 기존관계형데이터저장소와새로운트랜드인비정형빅데이터를통합하는데이터아키텍처로엔터프로이즈시장에서주목을받고있다.
Oracle Data Integrator 와 Oracle Big Data Appliance 저자 - 김태완부장, 한국오라클 Fusion Middleware([email protected]) 오라클은최근 Big Data 분약에 End-To-End 솔루션을지원하는벤더로급부상하고있고, 기존관계형데이터저장소와새로운트랜드인비정형빅데이터를통합하는데이터아키텍처로엔터프로이즈시장에서주목을받고있다.
오픈데크넷서밋_Spark Overview _SK주식회사 이상훈
 Spark Overview ( 아파치스파크를써야하는이유 ) SK 주식회사 C&C 이상훈 빅데이터플랫폼 Spark Overview Spark 란? Spark Streaming 고급분석 빅데이터플랫폼 빅데이터플랫폼의필요성 Client UX Log HTTP Server WAS Biz Logic Data Legacy DW Report IoT Mobile Sensor
Spark Overview ( 아파치스파크를써야하는이유 ) SK 주식회사 C&C 이상훈 빅데이터플랫폼 Spark Overview Spark 란? Spark Streaming 고급분석 빅데이터플랫폼 빅데이터플랫폼의필요성 Client UX Log HTTP Server WAS Biz Logic Data Legacy DW Report IoT Mobile Sensor
PowerPoint Presentation
 하둡전문가로가는길 심탁길 [email protected] 목차 1. 하둡과에코시스템개요 2. 홗용사례붂석 3. 하둡젂문가의필요성 4. 무엇을어떻게준비할까? 5. 하둡기반추천시스템데모 하둡개요 구글인프라 배치애플리케이션 온라인서비스 MapReduce Bigtable GFS Client API Chubby Cluster Mgmt 주요소프트웨어스택 Google
하둡전문가로가는길 심탁길 [email protected] 목차 1. 하둡과에코시스템개요 2. 홗용사례붂석 3. 하둡젂문가의필요성 4. 무엇을어떻게준비할까? 5. 하둡기반추천시스템데모 하둡개요 구글인프라 배치애플리케이션 온라인서비스 MapReduce Bigtable GFS Client API Chubby Cluster Mgmt 주요소프트웨어스택 Google
<목 차 > 제 1장 일반사항 4 I.사업의 개요 4 1.사업명 4 2.사업의 목적 4 3.입찰 방식 4 4.입찰 참가 자격 4 5.사업 및 계약 기간 5 6.추진 일정 6 7.사업 범위 및 내용 6 II.사업시행 주요 요건 8 1.사업시행 조건 8 2.계약보증 9 3
 열차운행정보 승무원 확인시스템 구축 제 안 요 청 서 2014.6. 제 1장 일반사항 4 I.사업의 개요 4 1.사업명 4 2.사업의 목적 4 3.입찰 방식 4 4.입찰 참가 자격 4 5.사업 및 계약 기간 5 6.추진 일정 6 7.사업 범위 및 내용 6 II.사업시행 주요 요건 8 1.사업시행 조건 8 2.계약보증 9 3.시운전 및 하자보증 10
열차운행정보 승무원 확인시스템 구축 제 안 요 청 서 2014.6. 제 1장 일반사항 4 I.사업의 개요 4 1.사업명 4 2.사업의 목적 4 3.입찰 방식 4 4.입찰 참가 자격 4 5.사업 및 계약 기간 5 6.추진 일정 6 7.사업 범위 및 내용 6 II.사업시행 주요 요건 8 1.사업시행 조건 8 2.계약보증 9 3.시운전 및 하자보증 10
Intra_DW_Ch4.PDF
 The Intranet Data Warehouse Richard Tanler Ch4 : Online Analytic Processing: From Data To Information 2000. 4. 14 All rights reserved OLAP OLAP OLAP OLAP OLAP OLAP is a label, rather than a technology
The Intranet Data Warehouse Richard Tanler Ch4 : Online Analytic Processing: From Data To Information 2000. 4. 14 All rights reserved OLAP OLAP OLAP OLAP OLAP OLAP is a label, rather than a technology
분산처리 프레임워크를 활용한대용량 영상 고속분석 시스템
 분산처리프레임워크를활용한 대용량영상고속분석시스템 2015.07.16 SK C&C 융합기술본부오상문 ([email protected]) 목차 I. 영상분석서비스 II. Apache Storm III.JNI (Java Native Interface) IV. Image Processing Libraries 2 1.1. 배경및필요성 I. 영상분석서비스 현재대부분의영상관리시스템에서영상분석은
분산처리프레임워크를활용한 대용량영상고속분석시스템 2015.07.16 SK C&C 융합기술본부오상문 ([email protected]) 목차 I. 영상분석서비스 II. Apache Storm III.JNI (Java Native Interface) IV. Image Processing Libraries 2 1.1. 배경및필요성 I. 영상분석서비스 현재대부분의영상관리시스템에서영상분석은
PowerPoint 프레젠테이션
 ㆍ Natural Language Understanding 관련기술 ㆍ Semantic Parsing Conversational AI Natural Language Understanding / Machine Learning ㆍEntity Extraction and Resolution - Machine Learning 관련기술연구개발경험보유자ㆍStatistical
ㆍ Natural Language Understanding 관련기술 ㆍ Semantic Parsing Conversational AI Natural Language Understanding / Machine Learning ㆍEntity Extraction and Resolution - Machine Learning 관련기술연구개발경험보유자ㆍStatistical
PCServerMgmt7
 Web Windows NT/2000 Server DP&NM Lab 1 Contents 2 Windows NT Service Provider Management Application Web UI 3 . PC,, Client/Server Network 4 (1),,, PC Mainframe PC Backbone Server TCP/IP DCS PLC Network
Web Windows NT/2000 Server DP&NM Lab 1 Contents 2 Windows NT Service Provider Management Application Web UI 3 . PC,, Client/Server Network 4 (1),,, PC Mainframe PC Backbone Server TCP/IP DCS PLC Network
Cloud Friendly System Architecture
 -Service Clients Administrator 1. -Service 구성도 : ( 좌측참고 ) LB(LoadBlancer) 2. -Service 개요 ucloud Virtual Router F/W Monitoring 개념 특징 적용가능분야 Server, WAS, DB 로구성되어 web service 를클라우드환경에서제공하기위한 service architecture
-Service Clients Administrator 1. -Service 구성도 : ( 좌측참고 ) LB(LoadBlancer) 2. -Service 개요 ucloud Virtual Router F/W Monitoring 개념 특징 적용가능분야 Server, WAS, DB 로구성되어 web service 를클라우드환경에서제공하기위한 service architecture
ETL_project_best_practice1.ppt
 ETL ETL Data,., Data Warehouse DataData Warehouse ETL tool/system: ETL, ETL Process Data Warehouse Platform Database, Access Method Data Source Data Operational Data Near Real-Time Data Modeling Refresh/Replication
ETL ETL Data,., Data Warehouse DataData Warehouse ETL tool/system: ETL, ETL Process Data Warehouse Platform Database, Access Method Data Source Data Operational Data Near Real-Time Data Modeling Refresh/Replication
슬라이드 1
 장비지원사례연구 ( 세종대학교인공지능 - 빅데이터연구센터중심으로 ) 신병주 [email protected] 문제 기업의빅데이터인력및시스템투자예산 데이터분석역량및경험부족 19.6% 시스템구축비, 관리비등예산부족 19.4% 정보보호및안정성에대한우려 17.5% 투자대비수익 (ROI) 의불투명성 15.1% 빅데이터에준비되지않은기업문화 15.9% 적합한데이터관리솔루션의부재
장비지원사례연구 ( 세종대학교인공지능 - 빅데이터연구센터중심으로 ) 신병주 [email protected] 문제 기업의빅데이터인력및시스템투자예산 데이터분석역량및경험부족 19.6% 시스템구축비, 관리비등예산부족 19.4% 정보보호및안정성에대한우려 17.5% 투자대비수익 (ROI) 의불투명성 15.1% 빅데이터에준비되지않은기업문화 15.9% 적합한데이터관리솔루션의부재
PowerPoint 프레젠테이션
 Spider For MySQL 실전사용기 피망플러스유닛최윤묵 Spider For MySQL Data Sharding By Spider Storage Engine http://spiderformysql.com/ 성능 8 만 / 분 X 4 대 32 만 / 분 많은 DB 중에왜 spider 를? Source: 클라우드컴퓨팅구 선택의기로 Consistency RDBMS
Spider For MySQL 실전사용기 피망플러스유닛최윤묵 Spider For MySQL Data Sharding By Spider Storage Engine http://spiderformysql.com/ 성능 8 만 / 분 X 4 대 32 만 / 분 많은 DB 중에왜 spider 를? Source: 클라우드컴퓨팅구 선택의기로 Consistency RDBMS
<49534F20323030303020C0CEC1F520BBE7C8C4BDC9BBE720C4C1BCB3C6C320B9D7204954534D20BDC3BDBAC5DB20B0EDB5B5C8AD20C1A6BEC8BFE4C3BBBCAD2E687770>
 ISO 20000 인증 사후심사 컨설팅 및 ITSM 시스템 고도화를 위한 제 안 요 청 서 2008. 6. 한 국 학 술 진 흥 재 단 이 자료는 한국학술진흥재단 제안서 작성이외의 목적으로 복제, 전달 및 사용을 금함 목 차 Ⅰ. 사업개요 1 1. 사업명 1 2. 추진배경 1 3. 목적 1 4. 사업내용 2 5. 기대효과 2 Ⅱ. 사업추진계획 4 1. 추진체계
ISO 20000 인증 사후심사 컨설팅 및 ITSM 시스템 고도화를 위한 제 안 요 청 서 2008. 6. 한 국 학 술 진 흥 재 단 이 자료는 한국학술진흥재단 제안서 작성이외의 목적으로 복제, 전달 및 사용을 금함 목 차 Ⅰ. 사업개요 1 1. 사업명 1 2. 추진배경 1 3. 목적 1 4. 사업내용 2 5. 기대효과 2 Ⅱ. 사업추진계획 4 1. 추진체계
초보자를 위한 분산 캐시 활용 전략
 초보자를위한분산캐시활용전략 강대명 [email protected] 우리가꿈꾸는서비스 우리가꿈꾸는서비스 우리가꿈꾸는서비스 우리가꿈꾸는서비스 그러나현실은? 서비스에필요한것은? 서비스에필요한것은? 핵심적인기능 서비스에필요한것은? 핵심적인기능 서비스에필요한것은? 핵심적인기능 서비스에필요한것은? 적절한기능 서비스안정성 트위터에매일고래만보이면? 트위터에매일고래만보이면?
초보자를위한분산캐시활용전략 강대명 [email protected] 우리가꿈꾸는서비스 우리가꿈꾸는서비스 우리가꿈꾸는서비스 우리가꿈꾸는서비스 그러나현실은? 서비스에필요한것은? 서비스에필요한것은? 핵심적인기능 서비스에필요한것은? 핵심적인기능 서비스에필요한것은? 핵심적인기능 서비스에필요한것은? 적절한기능 서비스안정성 트위터에매일고래만보이면? 트위터에매일고래만보이면?
Integ
 HP Integrity HP Chipset Itanium 2(Processor 9100) HP Integrity HP, Itanium. HP Integrity Blade BL860c HP Integrity Blade BL870c HP Integrity rx2660 HP Integrity rx3600 HP Integrity rx6600 2 HP Integrity
HP Integrity HP Chipset Itanium 2(Processor 9100) HP Integrity HP, Itanium. HP Integrity Blade BL860c HP Integrity Blade BL870c HP Integrity rx2660 HP Integrity rx3600 HP Integrity rx6600 2 HP Integrity
이도경, 최덕재 Dokyeong Lee, Deokjai Choi 1. 서론
 이도경, 최덕재 Dokyeong Lee, Deokjai Choi 1. 서론 2. 관련연구 2.1 MQTT 프로토콜 Fig. 1. Topic-based Publish/Subscribe Communication Model. Table 1. Delivery and Guarantee by MQTT QoS Level 2.1 MQTT-SN 프로토콜 Fig. 2. MQTT-SN
이도경, 최덕재 Dokyeong Lee, Deokjai Choi 1. 서론 2. 관련연구 2.1 MQTT 프로토콜 Fig. 1. Topic-based Publish/Subscribe Communication Model. Table 1. Delivery and Guarantee by MQTT QoS Level 2.1 MQTT-SN 프로토콜 Fig. 2. MQTT-SN
PowerPoint Presentation
 Data Protection Rapid Recovery x86 DR Agent based Backup - Physical Machine - Virtual Machine - Cluster Agentless Backup - VMware ESXi Deploy Agents - Windows - AD, ESXi Restore Machine - Live Recovery
Data Protection Rapid Recovery x86 DR Agent based Backup - Physical Machine - Virtual Machine - Cluster Agentless Backup - VMware ESXi Deploy Agents - Windows - AD, ESXi Restore Machine - Live Recovery
서현수
 Introduction to TIZEN SDK UI Builder S-Core 서현수 2015.10.28 CONTENTS TIZEN APP 이란? TIZEN SDK UI Builder 소개 TIZEN APP 개발방법 UI Builder 기능 UI Builder 사용방법 실전, TIZEN APP 개발시작하기 마침 TIZEN APP? TIZEN APP 이란? Mobile,
Introduction to TIZEN SDK UI Builder S-Core 서현수 2015.10.28 CONTENTS TIZEN APP 이란? TIZEN SDK UI Builder 소개 TIZEN APP 개발방법 UI Builder 기능 UI Builder 사용방법 실전, TIZEN APP 개발시작하기 마침 TIZEN APP? TIZEN APP 이란? Mobile,
슬라이드 1
 실시간분산병렬 CEP 플랫폼 2015. 10 Agenda 목차 I. SK 빅데이터솔루션소개 III. 실시간분산병렬 CEP PoC 사례 1. 배경및필요성 2. 확보방안 3. 솔루션 Coverage 4. 솔루션아키텍처 1. 동기및개선방향 2. 데이터흐름도 3. 아키텍처 II. 실시간분산병렬 CEP IV. 맺음말 1. 개요 1. 향후추진방향 2. 고려사항 2. Summary
실시간분산병렬 CEP 플랫폼 2015. 10 Agenda 목차 I. SK 빅데이터솔루션소개 III. 실시간분산병렬 CEP PoC 사례 1. 배경및필요성 2. 확보방안 3. 솔루션 Coverage 4. 솔루션아키텍처 1. 동기및개선방향 2. 데이터흐름도 3. 아키텍처 II. 실시간분산병렬 CEP IV. 맺음말 1. 개요 1. 향후추진방향 2. 고려사항 2. Summary
Global Bigdata 사용 현황 및 향후 활용 전망 빅데이터 미도입 이유 필요성 못느낌, 분석 가치 판단 불가 향후 투자를 집중할 분야는 보안 모니터링 분야 와 자동화 시스템 분야 빅데이터의 핵심 가치 - 트랜드 예측 과 제품 개선 도움 빅데이터 운영 애로 사항
 Global Bigdata 사용 현황 및 향후 활용 전망 빅데이터 미도입 이유 필요성 못느낌, 분석 가치 판단 불가 향후 투자를 집중할 분야는 보안 모니터링 분야 와 자동화 시스템 분야 빅데이터의 핵심 가치 - 트랜드 예측 과 제품 개선 도움 빅데이터 운영 애로 사항 - 재직자 전문성, 복잡성으로 인해 알고리즘 개발 난항 본 조사 내용은 美 Techpro Research
Global Bigdata 사용 현황 및 향후 활용 전망 빅데이터 미도입 이유 필요성 못느낌, 분석 가치 판단 불가 향후 투자를 집중할 분야는 보안 모니터링 분야 와 자동화 시스템 분야 빅데이터의 핵심 가치 - 트랜드 예측 과 제품 개선 도움 빅데이터 운영 애로 사항 - 재직자 전문성, 복잡성으로 인해 알고리즘 개발 난항 본 조사 내용은 美 Techpro Research
solution map_....
 SOLUTION BROCHURE RELIABLE STORAGE SOLUTIONS ETERNUS FOR RELIABILITY AND AVAILABILITY PROTECT YOUR DATA AND SUPPORT BUSINESS FLEXIBILITY WITH FUJITSU STORAGE SOLUTIONS kr.fujitsu.com INDEX 1. Storage System
SOLUTION BROCHURE RELIABLE STORAGE SOLUTIONS ETERNUS FOR RELIABILITY AND AVAILABILITY PROTECT YOUR DATA AND SUPPORT BUSINESS FLEXIBILITY WITH FUJITSU STORAGE SOLUTIONS kr.fujitsu.com INDEX 1. Storage System
AGENDA 01 02 03 모바일 산업의 환경변화 모바일 클라우드 서비스의 등장 모바일 클라우드 서비스 융합사례
 모바일 클라우드 서비스 융합사례와 시장 전망 및 신 사업전략 2011. 10 AGENDA 01 02 03 모바일 산업의 환경변화 모바일 클라우드 서비스의 등장 모바일 클라우드 서비스 융합사례 AGENDA 01. 모바일 산업의 환경 변화 가치 사슬의 분화/결합 모바일 업계에서도 PC 산업과 유사한 모듈화/분업화 진행 PC 산업 IBM à WinTel 시대 à
모바일 클라우드 서비스 융합사례와 시장 전망 및 신 사업전략 2011. 10 AGENDA 01 02 03 모바일 산업의 환경변화 모바일 클라우드 서비스의 등장 모바일 클라우드 서비스 융합사례 AGENDA 01. 모바일 산업의 환경 변화 가치 사슬의 분화/결합 모바일 업계에서도 PC 산업과 유사한 모듈화/분업화 진행 PC 산업 IBM à WinTel 시대 à
Microsoft PowerPoint - 알고리즘_5주차_1차시.pptx
 Basic Idea of External Sorting run 1 run 2 run 3 run 4 run 5 run 6 750 records 750 records 750 records 750 records 750 records 750 records run 1 run 2 run 3 1500 records 1500 records 1500 records run 1
Basic Idea of External Sorting run 1 run 2 run 3 run 4 run 5 run 6 750 records 750 records 750 records 750 records 750 records 750 records run 1 run 2 run 3 1500 records 1500 records 1500 records run 1
C# Programming Guide - Types
 C# Programming Guide - Types 최도경 [email protected] 이문서는 MSDN 의 Types 를요약하고보충한것입니다. http://msdn.microsoft.com/enus/library/ms173104(v=vs.100).aspx Types, Variables, and Values C# 은 type 에민감한언어이다. 모든
C# Programming Guide - Types 최도경 [email protected] 이문서는 MSDN 의 Types 를요약하고보충한것입니다. http://msdn.microsoft.com/enus/library/ms173104(v=vs.100).aspx Types, Variables, and Values C# 은 type 에민감한언어이다. 모든
1217 WebTrafMon II
 (1/28) (2/28) (10 Mbps ) Video, Audio. (3/28) 10 ~ 15 ( : telnet, ftp ),, (4/28) UDP/TCP (5/28) centralized environment packet header information analysis network traffic data, capture presentation network
(1/28) (2/28) (10 Mbps ) Video, Audio. (3/28) 10 ~ 15 ( : telnet, ftp ),, (4/28) UDP/TCP (5/28) centralized environment packet header information analysis network traffic data, capture presentation network
PowerPoint Presentation
 MapR Platform 2017 MapR Technologies 1 빅데이터시장동향 2017 MapR Technologies 2 빅데이터시장동향 기업 IT 환경의변화 1980 년대모든데이터를플랫파일로관리하던어려움을극복하고자데이터베이스시스템이시장에출시된이후로기업용 어플리케이션등장, 인터넷의등장, 디지털변혁접목등기업혁신의핵심에는항상데이터가중요한역할을함 1980s
MapR Platform 2017 MapR Technologies 1 빅데이터시장동향 2017 MapR Technologies 2 빅데이터시장동향 기업 IT 환경의변화 1980 년대모든데이터를플랫파일로관리하던어려움을극복하고자데이터베이스시스템이시장에출시된이후로기업용 어플리케이션등장, 인터넷의등장, 디지털변혁접목등기업혁신의핵심에는항상데이터가중요한역할을함 1980s
vm-웨어-01장
 Chapter 16 21 (Agenda). (Green),., 2010. IT IT. IT 2007 3.1% 2030 11.1%, IT 2007 1.1.% 2030 4.7%, 2020 4 IT. 1 IT, IT. (Virtualization),. 2009 /IT 2010 10 2. 6 2008. 1970 MIT IBM (Mainframe), x86 1. (http
Chapter 16 21 (Agenda). (Green),., 2010. IT IT. IT 2007 3.1% 2030 11.1%, IT 2007 1.1.% 2030 4.7%, 2020 4 IT. 1 IT, IT. (Virtualization),. 2009 /IT 2010 10 2. 6 2008. 1970 MIT IBM (Mainframe), x86 1. (http
BMP 파일 처리
 BMP 파일처리 김성영교수 금오공과대학교 컴퓨터공학과 학습내용 영상반전프로그램제작 2 Inverting images out = 255 - in 3 /* 이프로그램은 8bit gray-scale 영상을입력으로사용하여반전한후동일포맷의영상으로저장한다. */ #include #include #define WIDTHBYTES(bytes)
BMP 파일처리 김성영교수 금오공과대학교 컴퓨터공학과 학습내용 영상반전프로그램제작 2 Inverting images out = 255 - in 3 /* 이프로그램은 8bit gray-scale 영상을입력으로사용하여반전한후동일포맷의영상으로저장한다. */ #include #include #define WIDTHBYTES(bytes)
슬라이드 1
 Big Architecture 2014.10.23 SK C&C Platform 사업팀이정일차장 Table of 1. Big 개요 2. Big 플랫폼아키텍처 3. 아키텍처수립시고려사항 4. 하둡배포판기반아키텍처 5. Case Study 1. Big 개요 Big 란 Big Big Big Big 3 1. Big 개요 Big 의특성 3V 데이터의크기 (Volume)
Big Architecture 2014.10.23 SK C&C Platform 사업팀이정일차장 Table of 1. Big 개요 2. Big 플랫폼아키텍처 3. 아키텍처수립시고려사항 4. 하둡배포판기반아키텍처 5. Case Study 1. Big 개요 Big 란 Big Big Big Big 3 1. Big 개요 Big 의특성 3V 데이터의크기 (Volume)
TTA Journal No.157_서체변경.indd
 표준 시험인증 기술 동향 FIDO(Fast IDentity Online) 생체 인증 기술 표준화 동향 이동기 TTA 모바일응용서비스 프로젝트그룹(PG910) 의장 SK텔레콤 NIC 담당 매니저 76 l 2015 01/02 PASSWORDLESS EXPERIENCE (UAF standards) ONLINE AUTH REQUEST LOCAL DEVICE AUTH
표준 시험인증 기술 동향 FIDO(Fast IDentity Online) 생체 인증 기술 표준화 동향 이동기 TTA 모바일응용서비스 프로젝트그룹(PG910) 의장 SK텔레콤 NIC 담당 매니저 76 l 2015 01/02 PASSWORDLESS EXPERIENCE (UAF standards) ONLINE AUTH REQUEST LOCAL DEVICE AUTH
SQL Developer Connect to TimesTen 유니원아이앤씨 DB 기술지원팀 2010 년 07 월 28 일 문서정보 프로젝트명 SQL Developer Connect to TimesTen 서브시스템명 버전 1.0 문서명 작성일 작성자
 SQL Developer Connect to TimesTen 유니원아이앤씨 DB 팀 2010 년 07 월 28 일 문서정보 프로젝트명 SQL Developer Connect to TimesTen 서브시스템명 버전 1.0 문서명 작성일 2010-07-28 작성자 김학준 최종수정일 2010-07-28 문서번호 20100728_01_khj 재개정이력 일자내용수정인버전
SQL Developer Connect to TimesTen 유니원아이앤씨 DB 팀 2010 년 07 월 28 일 문서정보 프로젝트명 SQL Developer Connect to TimesTen 서브시스템명 버전 1.0 문서명 작성일 2010-07-28 작성자 김학준 최종수정일 2010-07-28 문서번호 20100728_01_khj 재개정이력 일자내용수정인버전
PowerPoint 프레젠테이션
 How Hadoop Works 박영택 컴퓨터학부 HDFS Basic Concepts HDFS 는 Java 로작성된파일시스템 Google 의 GFS 기반 기존파일시스템의상위에서동작 ext3, ext4 or xfs HDFS 의 file 저장방식 File 은 block 단위로분할 각 block 은기본적으로 64MB 또는 128MB 크기 데이터가로드될때여러 machine
How Hadoop Works 박영택 컴퓨터학부 HDFS Basic Concepts HDFS 는 Java 로작성된파일시스템 Google 의 GFS 기반 기존파일시스템의상위에서동작 ext3, ext4 or xfs HDFS 의 file 저장방식 File 은 block 단위로분할 각 block 은기본적으로 64MB 또는 128MB 크기 데이터가로드될때여러 machine
 OZ-LMS TM OZ-LMS 2008 OZ-LMS 2006 OZ-LMS Lite Best IT Serviece Provider OZNET KOREA Management Philosophy & Vision Introduction OZNETKOREA IT Mission Core Values KH IT ERP Web Solution IT SW 2000 4 3 508-2
OZ-LMS TM OZ-LMS 2008 OZ-LMS 2006 OZ-LMS Lite Best IT Serviece Provider OZNET KOREA Management Philosophy & Vision Introduction OZNETKOREA IT Mission Core Values KH IT ERP Web Solution IT SW 2000 4 3 508-2
PowerPoint 프레젠테이션
 Flamingo Big Data Performance Management Product Documentation It s the Best Big Data Performance Management Solution. Maximize Your Hadoop Cluster with Flamingo. Monitoring, Analyzing, and Visualizing.
Flamingo Big Data Performance Management Product Documentation It s the Best Big Data Performance Management Solution. Maximize Your Hadoop Cluster with Flamingo. Monitoring, Analyzing, and Visualizing.
Eclipse 와 Firefox 를이용한 Javascript 개발 발표자 : 문경대 11 년 10 월 26 일수요일
 Eclipse 와 Firefox 를이용한 Javascript 개발 발표자 : 문경대 Introduce Me!!! Job Jeju National University Student Ubuntu Korean Jeju Community Owner E-Mail: [email protected] Blog: http://ned3y2k.wo.tc Facebook: http://www.facebook.com/gyeongdae
Eclipse 와 Firefox 를이용한 Javascript 개발 발표자 : 문경대 Introduce Me!!! Job Jeju National University Student Ubuntu Korean Jeju Community Owner E-Mail: [email protected] Blog: http://ned3y2k.wo.tc Facebook: http://www.facebook.com/gyeongdae
백봉현, 하일규, 안병철 Bong-Hyun Back, Ilkyu Ha, ByoungChul Ahn 1. 서론 최근들어소셜네트워크활성화로 에서발생하는대량의데이터 로부터정보를추출하여이를정치 경제 개인서비 스 연애등다양한분야에활용하고자하는노력이 계속되고있다 상의데이터를빠르게
 백봉현, 하일규, 안병철 Bong-Hyun Back, Ilkyu Ha, ByoungChul Ahn 1. 서론 최근들어소셜네트워크활성화로 에서발생하는대량의데이터 로부터정보를추출하여이를정치 경제 개인서비 스 연애등다양한분야에활용하고자하는노력이 계속되고있다 상의데이터를빠르게분석하여 의미있는정보를추출하고 이를통해대중들이요구 하는의견과생각들을실시간으로파악하여 제품을
백봉현, 하일규, 안병철 Bong-Hyun Back, Ilkyu Ha, ByoungChul Ahn 1. 서론 최근들어소셜네트워크활성화로 에서발생하는대량의데이터 로부터정보를추출하여이를정치 경제 개인서비 스 연애등다양한분야에활용하고자하는노력이 계속되고있다 상의데이터를빠르게분석하여 의미있는정보를추출하고 이를통해대중들이요구 하는의견과생각들을실시간으로파악하여 제품을
기타자료.PDF
 < > 1 1 2 1 21 1 22 2 221 2 222 3 223 4 3 5 31 5 311 (netting)5 312 (matching) 5 313 (leading) (lagging)6 314 6 32 6 321 7 322 8 323 13 324 19 325 20 326 20 327 20 33 21 331 (ALM)21 332 VaR(Value at Risk)
< > 1 1 2 1 21 1 22 2 221 2 222 3 223 4 3 5 31 5 311 (netting)5 312 (matching) 5 313 (leading) (lagging)6 314 6 32 6 321 7 322 8 323 13 324 19 325 20 326 20 327 20 33 21 331 (ALM)21 332 VaR(Value at Risk)
1
 1 1....6 1.1...6 2. Java Architecture...7 2.1 2SDK(Software Development Kit)...8 2.2 JRE(Java Runtime Environment)...9 2.3 (Java Virtual Machine, JVM)...10 2.4 JVM...11 2.5 (runtime)jvm...12 2.5.1 2.5.2
1 1....6 1.1...6 2. Java Architecture...7 2.1 2SDK(Software Development Kit)...8 2.2 JRE(Java Runtime Environment)...9 2.3 (Java Virtual Machine, JVM)...10 2.4 JVM...11 2.5 (runtime)jvm...12 2.5.1 2.5.2
6주차.key
 6, Process concept A program in execution Program code PCB (process control block) Program counter, registers, etc. Stack Heap Data section => global variable Process in memory Process state New Running
6, Process concept A program in execution Program code PCB (process control block) Program counter, registers, etc. Stack Heap Data section => global variable Process in memory Process state New Running
Hadoop 10주년과 Hadoop3.0의 등장_Dongjin Seo
 Hadoop 10 th Birthday and Hadoop 3 Alpha Dongjin Seo Cloudera Korea, SE 1 Agenda Ⅰ. Hadoop 10 th Birthday Ⅱ. Hadoop 3 Alpha 2 Apache Hadoop at 10 Apache Hadoop 3 Apache Hadoop s Timeline The Invention
Hadoop 10 th Birthday and Hadoop 3 Alpha Dongjin Seo Cloudera Korea, SE 1 Agenda Ⅰ. Hadoop 10 th Birthday Ⅱ. Hadoop 3 Alpha 2 Apache Hadoop at 10 Apache Hadoop 3 Apache Hadoop s Timeline The Invention
따끈따끈한 한국 Azure 데이터센터 서비스를 활용한 탁월한 데이터 분석 방안 (To be named)
") 오늘그리고미래의전략적자산 데이터. 데이터에서인사이트까지 무엇이? 왜? 그리고? 그렇다면? Insight 데이터의변화 CONNECTED DIGITAL ANALOG 1985 1990 1995 2000 2005 2010 2015 2020 데이터의변화 CONNECTED DIGITAL ANALOG 1985 1990 1995 2000 2005 2010 2015 2020
오늘그리고미래의전략적자산 데이터. 데이터에서인사이트까지 무엇이? 왜? 그리고? 그렇다면? Insight 데이터의변화 CONNECTED DIGITAL ANALOG 1985 1990 1995 2000 2005 2010 2015 2020 데이터의변화 CONNECTED DIGITAL ANALOG 1985 1990 1995 2000 2005 2010 2015 2020
플랫폼을말하다 2
 데이터를실시간으로모아서 처리하고자하는다양한기법들 김병곤 [email protected] 플랫폼을말하다 2 실시간빅데이터의요건들 l 쇼핑몰사이트의사용자클릭스트림을통해실시간개인화 l 대용량이메일서버의스팸탐지및필터링 l 위치정보기반광고서비스 l 사용자및시스템이벤트를이용한실시간보안감시 l 시스템정보수집을통한장비고장예측 l 실시간차량추적및위치정보수집을이용한도로교통상황파악
데이터를실시간으로모아서 처리하고자하는다양한기법들 김병곤 [email protected] 플랫폼을말하다 2 실시간빅데이터의요건들 l 쇼핑몰사이트의사용자클릭스트림을통해실시간개인화 l 대용량이메일서버의스팸탐지및필터링 l 위치정보기반광고서비스 l 사용자및시스템이벤트를이용한실시간보안감시 l 시스템정보수집을통한장비고장예측 l 실시간차량추적및위치정보수집을이용한도로교통상황파악
Web Application Hosting in the AWS Cloud Contents 개요 가용성과 확장성이 높은 웹 호스팅은 복잡하고 비용이 많이 드는 사업이 될 수 있습니다. 전통적인 웹 확장 아키텍처는 높은 수준의 안정성을 보장하기 위해 복잡한 솔루션으로 구현
 02 Web Application Hosting in the AWS Cloud www.wisen.co.kr Wisely Combine the Network platforms Web Application Hosting in the AWS Cloud Contents 개요 가용성과 확장성이 높은 웹 호스팅은 복잡하고 비용이 많이 드는 사업이 될 수 있습니다. 전통적인
02 Web Application Hosting in the AWS Cloud www.wisen.co.kr Wisely Combine the Network platforms Web Application Hosting in the AWS Cloud Contents 개요 가용성과 확장성이 높은 웹 호스팅은 복잡하고 비용이 많이 드는 사업이 될 수 있습니다. 전통적인
adfasdfasfdasfasfadf
 C 4.5 Source code Pt.3 ISL / 강한솔 2019-04-10 Index Tree structure Build.h Tree.h St-thresh.h 2 Tree structure *Concpets : Node, Branch, Leaf, Subtree, Attribute, Attribute Value, Class Play, Don't Play.
C 4.5 Source code Pt.3 ISL / 강한솔 2019-04-10 Index Tree structure Build.h Tree.h St-thresh.h 2 Tree structure *Concpets : Node, Branch, Leaf, Subtree, Attribute, Attribute Value, Class Play, Don't Play.
170918_hjk_datayanolja_v1.0.1.
 모 금융회사 오픈소스 및 머신러닝 도입 이야기 김 형 준 2 0 발표자소개 1 인터넷폐쇄망에서분석시스템구축 (feat. 엔지니어가없을때 ) 2 분석보고서자동화 3 Machine Learning 삽질기 ( 분석 & 개발 ) 3 0 발표자소개 1 인터넷폐쇄망에서분석시스템구축 (feat. 엔지니어가없을때 ) 2 분석보고서자동화하기 3 Machine Learning
모 금융회사 오픈소스 및 머신러닝 도입 이야기 김 형 준 2 0 발표자소개 1 인터넷폐쇄망에서분석시스템구축 (feat. 엔지니어가없을때 ) 2 분석보고서자동화 3 Machine Learning 삽질기 ( 분석 & 개발 ) 3 0 발표자소개 1 인터넷폐쇄망에서분석시스템구축 (feat. 엔지니어가없을때 ) 2 분석보고서자동화하기 3 Machine Learning
15인플레이션01-목차1~9
 ISSN 87-381 15. 1 15. 1 13 1 1.3 1. 1.8 1.5 1. 1.1 () 1.5 1..1 1.8 1.7 1.3 () 1..7.6...3 (). 1.5 3.6 3.3.9. 6.3 5.5 5.5 5.3.9.9 ().6.3.. 1.6 1. i 6 5 6 5 5 5 3 3 3 3 1 1 1 1-1 -1 13 1 1).6..3.1.3.
ISSN 87-381 15. 1 15. 1 13 1 1.3 1. 1.8 1.5 1. 1.1 () 1.5 1..1 1.8 1.7 1.3 () 1..7.6...3 (). 1.5 3.6 3.3.9. 6.3 5.5 5.5 5.3.9.9 ().6.3.. 1.6 1. i 6 5 6 5 5 5 3 3 3 3 1 1 1 1-1 -1 13 1 1).6..3.1.3.
Microsoft Word - th1_Big Data 시대의 기술_ _조성우
 Theme Article Big Data 시대의기술 중앙연구소 Intelligent Knowledge Service 조성우 1. 시대의화두 Big Data 최근 IT 분야의화두가무엇인지물어본다면, 빅데이터가대답들중하나일것이다. 20년전의 PC의메모리, 하드디스크의용량과최신 PC, 노트북사양을비교해보면과거에비해데이터가폭발적으로늘어났다는것을실감할수있을것이다. 특히스마트단말및소셜미디어등으로대표되는다양한정보채널의등장과이로인한정보의생산,
Theme Article Big Data 시대의기술 중앙연구소 Intelligent Knowledge Service 조성우 1. 시대의화두 Big Data 최근 IT 분야의화두가무엇인지물어본다면, 빅데이터가대답들중하나일것이다. 20년전의 PC의메모리, 하드디스크의용량과최신 PC, 노트북사양을비교해보면과거에비해데이터가폭발적으로늘어났다는것을실감할수있을것이다. 특히스마트단말및소셜미디어등으로대표되는다양한정보채널의등장과이로인한정보의생산,
PowerPoint 프레젠테이션
 Synergy EDMS www.comtrue.com opyright 2001 ComTrue Technologies. All right reserved. - 1 opyright 2001 ComTrue Technologies. All right reserved. - 2 opyright 2001 ComTrue Technologies. All right reserved.
Synergy EDMS www.comtrue.com opyright 2001 ComTrue Technologies. All right reserved. - 1 opyright 2001 ComTrue Technologies. All right reserved. - 2 opyright 2001 ComTrue Technologies. All right reserved.
빅데이터 라이프사이클관리 심탁길
 빅데이터 라이프사이클관리 심탁길 [email protected] 목차 1. 빅데이터개요 2. 빅데이터라이프사이클 3. 주요오픈소스기술소개 빅데이터개요 빅데이터란? Big Data 데이터베이스관점업무관점 기존의방식으로 저장 / 관리분석하기어려울정도의큰규모의자료 일반적인데이터베이스 SW 가저장, 관리분석할수있는범위를초과하는규모의데이터 ( 맥킨지, 2011)
빅데이터 라이프사이클관리 심탁길 [email protected] 목차 1. 빅데이터개요 2. 빅데이터라이프사이클 3. 주요오픈소스기술소개 빅데이터개요 빅데이터란? Big Data 데이터베이스관점업무관점 기존의방식으로 저장 / 관리분석하기어려울정도의큰규모의자료 일반적인데이터베이스 SW 가저장, 관리분석할수있는범위를초과하는규모의데이터 ( 맥킨지, 2011)
RED HAT JBoss Data Grid (JDG)? KANGWUK HEO Middleware Solu6on Architect Service Team, Red Hat Korea 1
? KANGWUK HEO Middleware Solu6on Architect Service Team, Red Hat Korea 1") RED HAT JBoss Data Grid (JDG)? KANGWUK HEO Middleware Solu6on Architect Service Team, Red Hat Korea 1 Agenda TITLE SLIDE: HEADLINE 1.? 2. Presenter Infinispan JDG 3. Title JBoss Data Grid? 4. Date JBoss
RED HAT JBoss Data Grid (JDG)? KANGWUK HEO Middleware Solu6on Architect Service Team, Red Hat Korea 1 Agenda TITLE SLIDE: HEADLINE 1.? 2. Presenter Infinispan JDG 3. Title JBoss Data Grid? 4. Date JBoss
..........(......).hwp
.hwp") START START 질문을 통해 우선순위를 결정 의사결정자가 질문에 답함 모형데이터 입력 목표계획법 자료 목표계획법 모형에 의한 해의 도출과 득실/확률 분석 END 목표계획법 산출결과 결과를 의사 결정자에게 제공 의사결정자가 결과를 검토하여 만족여부를 대답 의사결정자에게 만족하는가? Yes END No 목표계획법 수정 자료 개선을 위한 선택의 여지가 있는지
START START 질문을 통해 우선순위를 결정 의사결정자가 질문에 답함 모형데이터 입력 목표계획법 자료 목표계획법 모형에 의한 해의 도출과 득실/확률 분석 END 목표계획법 산출결과 결과를 의사 결정자에게 제공 의사결정자가 결과를 검토하여 만족여부를 대답 의사결정자에게 만족하는가? Yes END No 목표계획법 수정 자료 개선을 위한 선택의 여지가 있는지
02 C h a p t e r Java
 02 C h a p t e r Java Bioinformatics in J a va,, 2 1,,,, C++, Python, (Java),,, (http://wwwbiojavaorg),, 13, 3D GUI,,, (Java programming language) (Sun Microsystems) 1995 1990 (green project) TV 22 CHAPTER
02 C h a p t e r Java Bioinformatics in J a va,, 2 1,,,, C++, Python, (Java),,, (http://wwwbiojavaorg),, 13, 3D GUI,,, (Java programming language) (Sun Microsystems) 1995 1990 (green project) TV 22 CHAPTER
CRM Fair 2004
 easycrm Workbench ( ) 2004.04.02 I. CRM 1. CRM 2. CRM 3. II. easybi(business Intelligence) Framework 1. 2. - easydataflow Workbench - easycampaign Workbench - easypivot Reporter. 1. CRM 1.?! 1.. a. & b.
easycrm Workbench ( ) 2004.04.02 I. CRM 1. CRM 2. CRM 3. II. easybi(business Intelligence) Framework 1. 2. - easydataflow Workbench - easycampaign Workbench - easypivot Reporter. 1. CRM 1.?! 1.. a. & b.
Observational Determinism for Concurrent Program Security
 웹응용프로그램보안취약성 분석기구현 소프트웨어무결점센터 Workshop 2010. 8. 25 한국항공대학교, 안준선 1 소개 관련연구 Outline Input Validation Vulnerability 연구내용 Abstract Domain for Input Validation Implementation of Vulnerability Analyzer 기존연구
웹응용프로그램보안취약성 분석기구현 소프트웨어무결점센터 Workshop 2010. 8. 25 한국항공대학교, 안준선 1 소개 관련연구 Outline Input Validation Vulnerability 연구내용 Abstract Domain for Input Validation Implementation of Vulnerability Analyzer 기존연구
CONTENTS CONTENTS CONTENT 1. SSD & HDD 비교 2. SSD 서버 & HDD 서버 비교 3. LSD SSD 서버 & HDD 서버 비교 4. LSD SSD 서버 & 글로벌 SSD 서버 비교 2
 읽기속도 1초에 20Gbps www.lsdtech.co.kr 2011. 7. 01 Green Computing SSD Server & SSD Storage 이기택 82-10-8724-0575 [email protected] CONTENTS CONTENTS CONTENT 1. SSD & HDD 비교 2. SSD 서버 & HDD 서버 비교 3. LSD
읽기속도 1초에 20Gbps www.lsdtech.co.kr 2011. 7. 01 Green Computing SSD Server & SSD Storage 이기택 82-10-8724-0575 [email protected] CONTENTS CONTENTS CONTENT 1. SSD & HDD 비교 2. SSD 서버 & HDD 서버 비교 3. LSD
MAX+plus II Getting Started - 무작정따라하기
 무작정 따라하기 2001 10 4 / Version 20-2 0 MAX+plus II Digital, Schematic Capture MAX+plus II, IC, CPLD FPGA (Logic) ALTERA PLD FLEX10K Series EPF10K10QC208-4 MAX+plus II Project, Schematic, Design Compilation,
무작정 따라하기 2001 10 4 / Version 20-2 0 MAX+plus II Digital, Schematic Capture MAX+plus II, IC, CPLD FPGA (Logic) ALTERA PLD FLEX10K Series EPF10K10QC208-4 MAX+plus II Project, Schematic, Design Compilation,
PowerPoint 프레젠테이션
 Reasons for Poor Performance Programs 60% Design 20% System 2.5% Database 17.5% Source: ORACLE Performance Tuning 1 SMS TOOL DBA Monitoring TOOL Administration TOOL Performance Insight Backup SQL TUNING
Reasons for Poor Performance Programs 60% Design 20% System 2.5% Database 17.5% Source: ORACLE Performance Tuning 1 SMS TOOL DBA Monitoring TOOL Administration TOOL Performance Insight Backup SQL TUNING
PowerPoint Presentation
 1 2 Enterprise AI 인공지능 (AI) 을업무에도입하는최적의제안 Taewan Kim Solution Engineer Data & Analytics @2045 Imagine the endless possibilities to learn from 2.5 quintillion bytes of data generated every day AI REVOLUTION
1 2 Enterprise AI 인공지능 (AI) 을업무에도입하는최적의제안 Taewan Kim Solution Engineer Data & Analytics @2045 Imagine the endless possibilities to learn from 2.5 quintillion bytes of data generated every day AI REVOLUTION
Spring Boot/JDBC JdbcTemplate/CRUD 예제
 Spring Boot/JDBC JdbcTemplate/CRUD 예제 오라클자바커뮤니티 (ojc.asia, ojcedu.com) Spring Boot, Gradle 과오픈소스인 MariaDB 를이용해서 EMP 테이블을만들고 JdbcTemplate, SimpleJdbcTemplate 을이용하여 CRUD 기능을구현해보자. 마리아 DB 설치는다음 URL 에서확인하자.
Spring Boot/JDBC JdbcTemplate/CRUD 예제 오라클자바커뮤니티 (ojc.asia, ojcedu.com) Spring Boot, Gradle 과오픈소스인 MariaDB 를이용해서 EMP 테이블을만들고 JdbcTemplate, SimpleJdbcTemplate 을이용하여 CRUD 기능을구현해보자. 마리아 DB 설치는다음 URL 에서확인하자.
2002년 2학기 자료구조
 자료구조 (Data Structures) Chapter 1 Basic Concepts Overview : Data (1) Data vs Information (2) Data Linear list( 선형리스트 ) - Sequential list : - Linked list : Nonlinear list( 비선형리스트 ) - Tree : - Graph : (3)
자료구조 (Data Structures) Chapter 1 Basic Concepts Overview : Data (1) Data vs Information (2) Data Linear list( 선형리스트 ) - Sequential list : - Linked list : Nonlinear list( 비선형리스트 ) - Tree : - Graph : (3)
 OPCTalk for Hitachi Ethernet 1 2. Path. DCOMwindow NT/2000 network server. Winsock update win95. . . 3 Excel CSV. Update Background Thread Client Command Queue Size Client Dynamic Scan Block Block
OPCTalk for Hitachi Ethernet 1 2. Path. DCOMwindow NT/2000 network server. Winsock update win95. . . 3 Excel CSV. Update Background Thread Client Command Queue Size Client Dynamic Scan Block Block
Week13
 Week 13 Social Data Mining 02 Joonhwan Lee human-computer interaction + design lab. Crawling Twitter Data OAuth Crawling Data using OpenAPI Advanced Web Crawling 1. Crawling Twitter Data Twitter API API
Week 13 Social Data Mining 02 Joonhwan Lee human-computer interaction + design lab. Crawling Twitter Data OAuth Crawling Data using OpenAPI Advanced Web Crawling 1. Crawling Twitter Data Twitter API API
빅데이터처리의핵심인 Hadoop 을오라클은어떻게지원하나요? Oracle Big Data Appliance Solution 01 빅데이터처리를위한전문솔루션이 Oracle Big Data Appliance 군요. Oracle Big Data Appliance 와함께라면더이
 Cover Story 03 28 Oracle Big Data Solution 01_Oracle Big Data Appliance 02_Oracle Big Data Connectors 03_Oracle Exdata In-Memory Database Machine 04_Oracle Endeca Information Discovery 05_Oracle Event
Cover Story 03 28 Oracle Big Data Solution 01_Oracle Big Data Appliance 02_Oracle Big Data Connectors 03_Oracle Exdata In-Memory Database Machine 04_Oracle Endeca Information Discovery 05_Oracle Event
Web Scraper in 30 Minutes 강철
 Web Scraper in 30 Minutes 강철 발표자 소개 KAIST 전산학과 2015년부터 G사에서 일합니다. 에서 대한민국 정치의 모든 것을 개발하고 있습니다. 목표 웹 스크래퍼를 프레임웍 없이 처음부터 작성해 본다. 목표 웹 스크래퍼를 프레임웍 없이 처음부터 작성해 본다. 스크래퍼/크롤러의 작동 원리를 이해한다. 목표
Web Scraper in 30 Minutes 강철 발표자 소개 KAIST 전산학과 2015년부터 G사에서 일합니다. 에서 대한민국 정치의 모든 것을 개발하고 있습니다. 목표 웹 스크래퍼를 프레임웍 없이 처음부터 작성해 본다. 목표 웹 스크래퍼를 프레임웍 없이 처음부터 작성해 본다. 스크래퍼/크롤러의 작동 원리를 이해한다. 목표
Hallym Communication Policy Research Center 15 빅데이터기술은대용량의데이터를다룰때, 여러과정을거치게되는데, 데이터수집및데이터전처리, 저장, 분석, 활용 ( 시각화 ) 까지의과정을 거치게되며각과정별로핵심기술이존재한다. 빅데이터기술은대용
 까지의과정을 거치게되며각과정별로핵심기술이존재한다. 빅데이터기술은대용") 14 한림 ICT 정책저널 H a l l y m I C T P o l i c y J o u r n a l 빅데이터기술동향 전략적클라우드림 김광호이재준이사교수 빅데이터기술이란? 빅데이터기술은기존의데이터분석기법에비해 100배이상많은데이터를다루는기술이다. 빅데이터기술이다루는데이터의성격은다양하다. 예를들어시스템운영을통해산출되는로그데이터와구매기록데이터등의정형데이터뿐만아니라,
14 한림 ICT 정책저널 H a l l y m I C T P o l i c y J o u r n a l 빅데이터기술동향 전략적클라우드림 김광호이재준이사교수 빅데이터기술이란? 빅데이터기술은기존의데이터분석기법에비해 100배이상많은데이터를다루는기술이다. 빅데이터기술이다루는데이터의성격은다양하다. 예를들어시스템운영을통해산출되는로그데이터와구매기록데이터등의정형데이터뿐만아니라,
Microsoft PowerPoint - eSlim SV5-2410 [20080402]
![Microsoft PowerPoint - eSlim SV5-2410 [20080402]](/thumbs/40/20557413.jpg "Microsoft PowerPoint - eSlim SV5-2410 [20080402]") Innovation for Total Solution Provider!! eslim SV5-2410 Opteron Server 2008. 3 ESLIM KOREA INC. 1. 제 품 개 요 eslim SV5-2410 Server Quad-Core and Dual-Core Opteron 2000 Series Max. 4 Disk Bays for SAS and
Innovation for Total Solution Provider!! eslim SV5-2410 Opteron Server 2008. 3 ESLIM KOREA INC. 1. 제 품 개 요 eslim SV5-2410 Server Quad-Core and Dual-Core Opteron 2000 Series Max. 4 Disk Bays for SAS and
PowerPoint 프레젠테이션
 www.vmon.vsystems.co.kr Vmon 소개자료 Ⅰ. EMS 란? Ⅱ. Vmon 소개 Ⅲ. Vmon 의도입효과 Ⅰ. EMS 란? - EMS 의정의 - EMS 의필요성 : IT 환경의변화 Ⅱ. Vmon 소개 - Vmon 개요 - Vmon 제품구성 - Vmon Solutions - Vmon Services Ⅲ. Vmon 의도입효과 Ⅰ. EMS 란?
www.vmon.vsystems.co.kr Vmon 소개자료 Ⅰ. EMS 란? Ⅱ. Vmon 소개 Ⅲ. Vmon 의도입효과 Ⅰ. EMS 란? - EMS 의정의 - EMS 의필요성 : IT 환경의변화 Ⅱ. Vmon 소개 - Vmon 개요 - Vmon 제품구성 - Vmon Solutions - Vmon Services Ⅲ. Vmon 의도입효과 Ⅰ. EMS 란?
DW 개요.PDF
 Data Warehouse Hammersoftkorea BI Group / DW / 1960 1970 1980 1990 2000 Automating Informating Source : Kelly, The Data Warehousing : The Route to Mass Customization, 1996. -,, Data .,.., /. ...,.,,,.
Data Warehouse Hammersoftkorea BI Group / DW / 1960 1970 1980 1990 2000 Automating Informating Source : Kelly, The Data Warehousing : The Route to Mass Customization, 1996. -,, Data .,.., /. ...,.,,,.
スライド タイトルなし
 2 3 회사 소개 60%출자 40%출자 주식회사 NTT데이타 아이테크 NTT DATA의 영업협력이나 첨단기술제공, 인재육성등 여러가지 지원을 통해서 SII 그룹을 대상으로 고도의 정보 서비스를 제공 함과 동시에 NTT DATA ITEC 가 보유하고 있는 높은 업무 노하우 와 SCM을 비롯한 ERP분야의 기술력을 살려서 조립가공계 및 제조업 등 새로운 시장에
2 3 회사 소개 60%출자 40%출자 주식회사 NTT데이타 아이테크 NTT DATA의 영업협력이나 첨단기술제공, 인재육성등 여러가지 지원을 통해서 SII 그룹을 대상으로 고도의 정보 서비스를 제공 함과 동시에 NTT DATA ITEC 가 보유하고 있는 높은 업무 노하우 와 SCM을 비롯한 ERP분야의 기술력을 살려서 조립가공계 및 제조업 등 새로운 시장에
졸업작품중간보고서 - 구글 MapReduce 를이용한클라우드컴퓨팅 조중연 서종덕 지도교수님진현욱교수님 ( 인 )
") 졸업작품중간보고서 - 구글 MapReduce 를이용한클라우드컴퓨팅 - 200814194 조중연 200814187 서종덕 지도교수님진현욱교수님 ( 인 ) 목 차 1. 개요및목적 2. 관련기술및기술동향 I. 관련기술 II. 기술동향및사례조사 3. 프로젝트세부사항 I. 개발내용 II. 동작과정 III. 개발환경 4. 진행사항 I. 개발환경설정 II. 설치및환경설정현황
졸업작품중간보고서 - 구글 MapReduce 를이용한클라우드컴퓨팅 - 200814194 조중연 200814187 서종덕 지도교수님진현욱교수님 ( 인 ) 목 차 1. 개요및목적 2. 관련기술및기술동향 I. 관련기술 II. 기술동향및사례조사 3. 프로젝트세부사항 I. 개발내용 II. 동작과정 III. 개발환경 4. 진행사항 I. 개발환경설정 II. 설치및환경설정현황
The Self-Managing Database : Automatic Health Monitoring and Alerting
 The Self-Managing Database : Automatic Health Monitoring and Alerting Agenda Oracle 10g Enterpirse Manager Oracle 10g 3 rd Party PL/SQL API Summary (Self-Managing Database) ? 6% 6% 12% 55% 6% Source: IOUG
The Self-Managing Database : Automatic Health Monitoring and Alerting Agenda Oracle 10g Enterpirse Manager Oracle 10g 3 rd Party PL/SQL API Summary (Self-Managing Database) ? 6% 6% 12% 55% 6% Source: IOUG
출원국 권 리 구 분 상 태 권리번호 KR 특허 등록 10-2012-0092520 10-2012-0092518 10-2007-0071793 10-2012-0092517
 기술사업성평가서 경쟁정보분석서비스 제공 기술 2014 8 출원국 권 리 구 분 상 태 권리번호 KR 특허 등록 10-2012-0092520 10-2012-0092518 10-2007-0071793 10-2012-0092517 Ⅰ 기술 구현 메커니즘 - 1 - 경쟁정보분석서비스 항목 - 2 - 핵심 기술 특징 및 주요 도면
기술사업성평가서 경쟁정보분석서비스 제공 기술 2014 8 출원국 권 리 구 분 상 태 권리번호 KR 특허 등록 10-2012-0092520 10-2012-0092518 10-2007-0071793 10-2012-0092517 Ⅰ 기술 구현 메커니즘 - 1 - 경쟁정보분석서비스 항목 - 2 - 핵심 기술 특징 및 주요 도면
VOL.76.2008/2 Technical SmartPlant Materials - Document Management SmartPlant Materials에서 기본적인 Document를 관리하고자 할 때 필요한 세팅, 파일 업로드 방법 그리고 Path Type인 Ph
 인터그래프코리아(주)뉴스레터 통권 제76회 비매품 News Letters Information Systems for the plant Lifecycle Proccess Power & Marine Intergraph 2008 Contents Intergraph 2008 SmartPlant Materials Customer Status 인터그래프(주) 파트너사
인터그래프코리아(주)뉴스레터 통권 제76회 비매품 News Letters Information Systems for the plant Lifecycle Proccess Power & Marine Intergraph 2008 Contents Intergraph 2008 SmartPlant Materials Customer Status 인터그래프(주) 파트너사
Microsoft PowerPoint 자동설치시스템검증-V05-Baul.pptx
 DMSLAB 자동설치시스템의 HW 정보 및사용자설정기반설치 신뢰성에대한정형검증 건국대학교컴퓨터 정보통신공학과 김바울 1 Motivation Problem: 대규모서버시스템구축 Installation ti Server 2 Introduction 1) 사용자가원하는 이종분산플랫폼구성 대로 2) 전체시스템 들의성능을반영 3) 이종분산플랫폼을지능적으로자동구축 24
DMSLAB 자동설치시스템의 HW 정보 및사용자설정기반설치 신뢰성에대한정형검증 건국대학교컴퓨터 정보통신공학과 김바울 1 Motivation Problem: 대규모서버시스템구축 Installation ti Server 2 Introduction 1) 사용자가원하는 이종분산플랫폼구성 대로 2) 전체시스템 들의성능을반영 3) 이종분산플랫폼을지능적으로자동구축 24