SAS를 이용한 자료의 탐색
|
|
|
- 지환 류(유)
- 6 years ago
- Views:
Transcription
1 임상연구에서흔히사용 하는의학통계의실제 김호 서울대학교보건대학원
2 Outline 통계적가설검정의기본개념들 가설검정, 통계적오류, 검정력및표본수 연속형자료에서의통계분석 T-test, ANOVA, 회귀분석 ( 단순회귀, 중회귀 ) 범주형자료에서의통계분석 카이제곱검정, 로지스틱회귀분석 유전자형자료분석의기본개념
3 기본개념들 모집단과표본 ( 모수 ) p-value 통계적검정력과표본수계산 모수적방법과비모수적방법 정규성검정 변수의종류에따른분석법 통계적가설검정
4 통계적사고 <-> 결정론적사고 모집단과표본 정규분포를결정하는모수 ( 평균과분산 ) 평균 : 위치 분산 : 산포 ( 정밀도 )
5 모집단과표본 모집단 : 연구자가최종적으로관심을가지는집단 표본 : 모집단에대한통계적결정을하기위하여모집단으로부터대표성있게뽑은집단 표본이대표성이있게모집단을반영하여야함
6 모집단과표본 모집단 모수 2 N(, ) 표본 추정치 Y1,, Yn 1 n Y Y i n i 1 n ( i ) n 1 i1 S Y Y
7 모수 : 가정한모형의통계적성질을완전히결정하는상수 ( 들 ) Y=a+b x 2 N(, ) 1 ( x ) exp
8 관심모수 : 연구의가설을수학적인모수로표시해야함 두집단에서평균비교 d 1 2 두집단의비율비교 r p p 1 2 p1/(1 p1) OR p /(1 p ) 2 2
9 연구가설 두집단에서평균비교 귀무가설 Ho : d 대립가설 ( 양측검정 ) Ha : d 대립가설 ( 단측검정 ) 혹은 Ha : d Ha : d 0 1 2
10 연구가설 두집단의비율비교귀무가설 대립가설 ( 양측검정 ) 대립가설 ( 단측검정 ) 혹은 Ho r p p1/(1 p1) Ho : OR 1 p p /(1 p ) 1 : 1 Ho r Ho r Ho r 2 1 : p p1/(1 p1) Ho : OR 1 p p /(1 p ) p p 1 : 1 p p 2 1 : p /(1 p ) Ho OR p /(1 p ) 1 1 : p /(1 p ) Ho OR p /(1 p ) 1 1 : 1 2 2
11 P-value (1) 연구목적 : 관심변수의 ( 모 ) 평균이두집단에서다르다. 첫번째집단에서의표본평균 Y 1 두번째집단에서의표본평균 Y 2 만약두집단에서의모평균이같다고하면 두표본평균은비슷할것이다. 표본평균의차이를반복적으로구해보면
12 P-value (2) 0 통계적으로대단히일어나기어려운사건
13 P-value (3) P-value = 두집단의평균이같다고가정했을때우리의자료, 혹은더차이가나는자료를얻을확률 작은 p-value : 위의확률이작다 통계적으로가능하지않은일이일어났다. 두집단의평균이같다는가정에문제가있다. 두집단의평균은같지않다고결론내린다.
14 P-value (3) 작지않은 p-value : 두집단의평균이같다고가정하면우리의자료를관측할확률이작지않다. 두집단의평균이같다는가정에문제가없다. 양쪽검정, 한쪽검정
15 A( 얻은자료 ) -> B ( 연구가설 ) -B -> -A 귀무가설 (-B) : 두집단에차이가없다. (Ho) 대립가설 (B) : 두집단에차이가있다. (Ha) 일종의오류 : 옳은귀무가설을기각할확률 = Pr (reject Ho Ho is true) 이종의오류 : 틀린귀무가설을받아들일확률 = Pr (Not reject Ho Ha is true) Power = 1- ( 있는차이를발견할확률 )
16 가설검정시발생가능한 4 가지상황 표본을이용한가설검정결과 H 0 채택 H 0 기각 H 0 참 옳음 (1- ) 제1종오류 ( ) 모집단의진실 H 0 거짓 (Ha 참 ) 제2종오류 ( ) 옮음 ( 검정력 =1- )
17 검정방법 A( 모수적인방법, 검정력 =90%) 의검정방법 B ( 비모수적인방법, 검정력 =70%) 보다더큰검정력을주었다. -> 실제로차이가있을때 A 방법을 100 번실시했을때 90 번의경우차이가있다고 ( 귀무가설기각 ) 결정하였도 B 방법을실시하였을때는 100 번중 70 번귀무가설을기각하였다. -> A 가더좋은방법! ( 실제차이 =?) Total Sample Size Mean Std Dev
18 표본수계산, Get Motivated < 예시 1> Trt A Trt B 2 + n n n 1+ - n n n 2+ n +1 n +2 n ++ 2 n11 n 1n1 / n n n n n, v11 2 v n n / , p /
19 n 2 ij 100nij 라고하고, 를다시계산하면 100 / , p 두예에서비율은정확히같음에도불구하고통계적유의성은상당히다르다.??? 전통적통계적가설검정의유의성은표본수에크게의존한다. 통계적유의성이없었던경우라도표본수를크게하면유의성을볼수있다. 표본수 ( 실험의비용 ) 와통계적유의성 ( 실험의효용성 ) 의균형을맞추는것이요구됨 최소의비용으로효과를증명하고싶다.
20 통계학에서의표본수계산 표본조사의경우 - 목적 : 추정 (estimation) - 도구 : 표본오차 - 예 : 여론조사 임상시험의경우 - 목적 : 검정 (testing) - 도구 : 제1종의오류, 제2종의오류 - 예 : 임상시험
21 단순임의추출 (simple random sampling) 에서 N : 모집단의크기, n : 표본의크기라면 ˆ y y / n Var y n i1 i 2 N n n N 1 2 N n 1.96 Var( y) 2 B : n N 1 2 N n D B 2 ( N -1) D 2, / 4 95% 신뢰구간 ( 표준오차 )
22 만약가 0 혹은 1 의값을가지게되면, y y i 는비율이되고, 이경우 Npq 가된다. n ( N 1) D pq 예1) N=2000, 95% 신뢰수준, B=0.05이라면 n은? >> 사전정보가없다면 p=q=0.5 대입 D 2 2 B / / n 최소한 334 명의표본이필요하다.
23 연속형변수의비교 예 ) 새로운관절염치료제의치료효과에대한임상실험을실시한다고하자. 치료효과는 2주간치료후혈중 Prostag-landing 양이평균 10, 표준편차 2 이면치료가된것으로간주한다. 치료후두집단의혈중 Prostaglandin 양의변동이 20% 미만이면두치료제의효과는동등한것으로간주한다. 단측검정으로연구대상수를구하시오. 또동일한가정으로양측검정의결과와비교하시오. 검정력 =90%, 결과의척도 :Prostaglandin농도 ( 연속형 )
24 n c 2( Z ) 2 2 Z ( ) c t 2 A gm / dl(10 0.2), 2.0 gm / dl Z n t 1.645, Z nc ( ) / Effective Size (=E/S)= 1 2
25 proc power; twosamplemeans test=diff meandiff = 2 stddev = 2 power=0.90 sides=1 npergroup=. ; run;
26 The POWER Procedure Two-sample t Test for Mean Difference Fixed Scenario Elements Distribution Normal Method Exact Number of Sides 1 Mean Difference 2 Standard Deviation 2 Nominal Power 0.9 Null Difference 0 Alpha 0.05 Computed N Per Group Actual N Per Power Group
27 proc power; onesamplemeans means = 10 stddev = power=. ntotal=10 ; plot x=n min=10 max=50 ; run; Total Sample Size
28 proc power; onesamplemeans means = stddev = /* 10*sqrt(2) 15*sqrt(2) */ power=. ntotal=10 ; plot x=n min=10 max=50 ; run; Total Sample Size Mean Std Dev
29 모수적방법과비모수적방법 (1) 자료평균중앙값 1,2,3,4, ,2,3,4,5, 중앙값 (median) 은평균에비하여이상치에대해서둔감 (robust) 하다. 자료의정규성분포가정을하면평균과분산을통하여모집단의성질을완전히파악할수있다. ( 모수적방법 )
30 모수적방법과비모수적방법 (2) 비모수적방법은자료의 ( 정규성 ) 분포가정을하지않는다 자료의평균과분산이아닌순위를이용한방법을사용한다. 자료의분포가정 (eg 정규성 ) 이만족되면효율이떨어진다. Robust 한결과를준다. (outlier 에둔감 )
31 자료의정규성검정 (SAS 예제 ) data ; input label diameter='diameter in mm'; datalines; ; run; proc univariate data=rods normal; histogram diameter / normal (mu=est sigma=est) midpoints = 5 to 6.30 by 0.15; run;
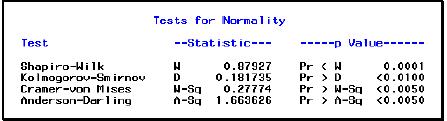
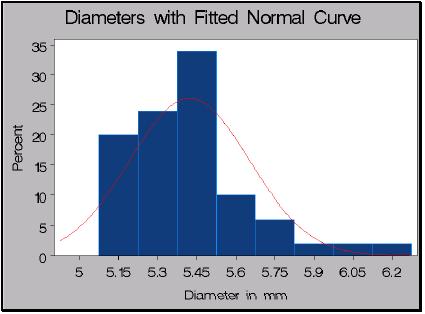
32 귀무가설 : 자료가정규분포를따른다
; run; Skewed to the")
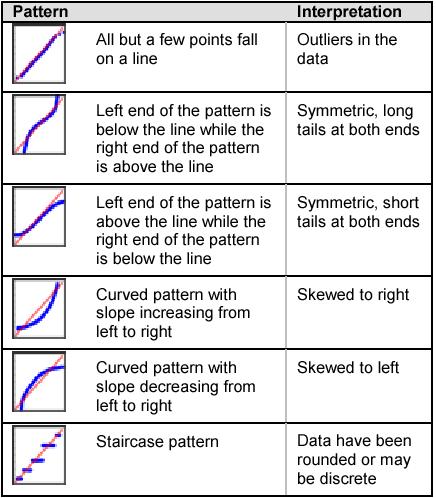
33 proc univariate data=rods noprint; probplot diameter / normal (mu=est sigma=est); run; Skewed to the right
34
35 Box plot
36 변수의분류 수학적개념 ( 척도 ) 에의한분류 1 명칭 or 명목척도 (nominal scale) - 범주로만의미 ex) 성별, 혈액형 2 순위척도 (ordinal scale) - 명목 + 대소관계 - 가감승제와같은수학적조작은불가능 ex) 교육정도 ( 국졸 / 중졸 / 고졸 / 대졸 ) 사회경제수준 ( 상 / 중 / 하 ) 특정사항에대한의견 ( 아주찬성 / 찬성 / 중립 / 반대 / 아주반대 )
37 3 간격척도 (interval scale) - 측정치간의간격에의미가있는경우 ex) 병리소견에 0의간격과 0+ 의간격이같은가? 온도의경우 20, 30 와 10, 20 의 10 는본질적으로같다. - 가감은가능, 승제는불가능즉, 비 (ratio) 의개념은가지지못함. ex) 100 / /122 왜냐하면 0, 0 는인위적인영점을정한것이기때문
38 4 비척도 (ratio scale) - 절대영점을가지게되므로수학적으로가장완전한형태의변수 ex) 40 세는 20 세에비해 20 살많고 ( 간격 ), 2 배 ( 비 ) 더살았다 어떤변수를어떤분류로할것인가를미리정해야함 ex) 연령 11, 12, 13 비척도 9, 10 19, 20 순위척도 성년 / 미성년 명칭척도 ( 순위척도 with 2 categories)
39 DATA 범주형변수 (categorical variable) 연속형변수 (continuous variable) 명목변수 순위변수 등간변수 비율변수 (nominal) (ordinal) (interval) (ratio)
40 인과관계에따른변수 독립변수 ( 설명변수 ) independent (explanatory) variable: 원인 종속변수 ( 반응변수 ) dependent (response) variable : 결과 전산입력형식에따른변수숫자변수문자변수날짜변수
41 변수종류에따른통계분석법 종속변수 독립변수 통계분석법 연속변수 ( 혈압 ) 명목척도 (2개범주 ) T 검정, paired T검정 연속변수 ( 혈압 ) 범주형 (3개이상 ) 분산분석 (ANOVA) 범주형 ( 병발생여부 ) 범주형 ( 투약여부 ) 카이제곱검정 ( 하나의독립변수 ) 로지스틱회귀분석 ( 둘이상의변수 ) 연속형 ( 아기의체중 ) 연속형 ( 재태임신기간 ) 회귀분석 연속형 ( 출생시체중 ) 연속형 + 범주형 ( 재태기간 smoking 여부 ) 공분산분석 (ANCOVA) 생존시간 ( 연속형, >0) 연속형 + 범주형나이 smoking 여부생존분석
42 자료의성격모수적방법비모수적방법 종속변수가범주형 종속변수가연속형 두개의독립된집단 카이제곱검정 T-test Fisher s exact test Ncnemar test Cochran s Q Wilcoxon rank sum test Man-whitney median test 두개의짝지은집단 Paired t-test Wilcoxon signed rank test 세개이상의집단 ANOVA Kruscal-Wallis test 제 3 의변수의영향고려 2-way ANOVA Friedman s 2-way ANOVA 상관분석 Pearson correlation Spearman s correlation Kendall s tau Stuart s tau
43 t-test ( 연속변수의두집단평균비교 )
44 T-test 관심변수가연속일때 ( 정규분포를따를때 ) 두집단간에평균의차이를보는검정 : 두개의독립적인집단간의차이 Paired( 짝지은 ) t-test : 한개체에서짝지은관찰치들의동질성을볼때 : 처치전의값과후의값을비교할때 ( 처치전과후에상관관계가존재한다는가정을고려 ) 표본수가적은경우에는정규분포가정을확인하기가곤란하다. -> 비모수적방법 두개이상의집단혹은다른변수로보정을할때 -> ANOVA ( 분산분석 )
45 Single Sample Analysis dataset: peppers Peppers Dataset Obs angle
46 proc means data=peppers mean std stderr t probt; run; options 1. stderr: the standard error of the mean 2. t: H 0 : 0 을검정하는 t test 3. probt: the significance probability of the t test The MEANS Procedure 분석변수 : angle 평균값표준편차표준오차 t값 Pr > t
47 Two Independent Samples Bullets Dataset dataset: bullets Obs powder velocity
48 proc ttest data=bullets; var velocity;class powder; run; The TTEST Procedure Lower CL Upper CL Lower CL Variable powder N Mean Mean Mean Std Dev velocity velocity velocity Diff (1-2) Upper CL Variable powder Std Dev Std Dev Std Err Minimum Maximum velocity velocity velocity Diff (1-2) Variable Method Variances DF t Value Pr > t velocity Pooled Equal velocity Satterthwaite Unequal Equality of Variances Variable Method Num DF Den DF F Value Pr > F velocity Folded F For H0: Variances are equal, F = 1.64 DF = (7,9)
49 Two Related Samples : paired t-test Pulse Dataset dataset: pulse Obs pre post d d = pre-post (difference in rate)
50 proc means data=pulse mean std stderr t probt; var d; run; The MEANS Procedure 분석변수 : d 평균값표준편차표준오차 t 값 Pr > t Two-sided p-value One-sided p-value=0.0285/2= for H0 : d 0 vs. H1 : d 0
51
52
53 ANOVA (Analysis of Variance) 분산분석세집단이상에서의연속변수평균들의비교
54 변수 ANOVA (Analysis of Variance) brand: 5 개의비닐 Brand wear: 얼마나약한가 model yij i i i ij 수준의평균 ij i i ACME 전체평균 수준의효과 AJAX CHAMP TUFFY XTRA Obs brand wear 1 ACME ACME ACME ACME CHAMP CHAMP CHAMP CHAMP AJAX AJAX AJAX AJAX TUFFY TUFFY TUFFY TUFFY XTRA XTRA XTRA XTRA 2.4
55 ANOVA for One-Way Classification proc anova data=veneer; class brand; model wear=brand; run; Dependent Variable: wear The ANOVA Procedure Sum of Source DF Squares Mean Square F Value Pr > F Model Error Corrected Total R-Square Coeff Var Root MSE wear Mean Source DF Anova SS Mean Square F Value Pr > F brand
56 Least Significant Difference Comparisons of BRAND Mean proc anova data=veneer; class brand; model wear=brand; means brand/lsd; run; The ANOVA Procedure t Tests (LSD) for wear Alpha 0.05 Error Degrees of Freedom 15 Error Mean Square Critical Value of t Least Significant Difference Means with the same letter are not significantly different. T Grouping Mean N brand A TUFFY B XTRA B B CHAMP B B ACME C AJAX
57 Sas 예제 options pageno=1 nodate ls=130 ps=60 nocenter; filename inbrakes 'c:\myweb\int\taillite.dat'; data one; infile inbrakes ; input id vehtype group positn speedzn resptime follotme folltmec; if group=1; label vehtype='vehicle Type' group='group - Light On=1 Light Off=2' positn='light Position' speedzn='speed Zone' resptime='response Time' follotme='following Time in Vedio Frames' folltmec='following Time in Categories' ;run; proc sort; by vehtype; /* Let's do one-way ANOVA to see the effect of vehicle type */ proc anova; class vehtype; model resptime=vehtype; title 'Parametric ANOVA analysis'; run; /* What's wrong with this? We didn't check the normality assumption. Let's do proc univariate to check the normality */
58 The ANOVA Procedure Class Level Information Class Levels Values vehtype Number of Observations Read 733 Number of Observations Used 733 Parametric ANOVA analysis 2 The ANOVA Procedure Dependent Variable: resptime Response Time Sum of Source DF Squares Mean Square F Value Pr > F Model Error Corrected Total R-Square Coeff Var Root MSE resptime Mean Source DF Anova SS Mean Square F Value Pr > F vehtype
59 proc univariate data=one normal plot; var resptime; by vehtype; histogram resptime /cfill=blue kernel(color=red) normal(color=black); probplot resptime / normal (mu=est sigma=est); title 'Normality Check'; run; proc boxplot data=one ; plot resptime*vehtype /boxstyle =SCHEMATIC cboxes =blue cboxfill =gray run; idcolor=red ;
60 Vehicle Type=1 UNIVARIATE 프로시저변수 : resptime (Response Time) 적률 N 157 가중합 157 평균 관측치합 6745 표준편차 분산 왜도 첨도 제곱합 수정제곱합 변동계수 평균의표준오차 정규분포에대한적합도검정 검정 통계량 p- 값 Kolmogorov-Smirnov D Pr > D <0.010 Cramer-von Mises W-Sq Pr > W-Sq <0.005 Anderson-Darling A-Sq Pr > A-Sq <0.005
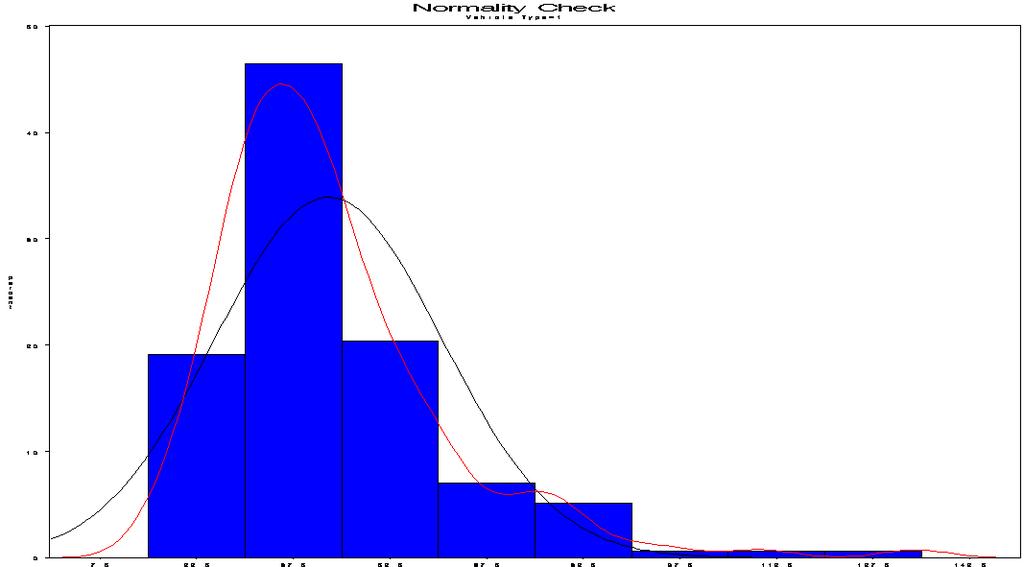
61
62
63 proc npar1way wilcoxon; class vehtype; var resptime ; title 'Nonpara One-Way ANOVA for Tail Light Study'; run; /* The other way is transformation. Let's take log transformation so that we have normal distribition. */ data t; set one; t=log(resptime); label t='ln (response time)'; run; proc sort; by vehtype; proc univariate data=t normal plot; var t; by vehtype; histogram t /cfill=blue kernel(color=red) normal(color=black); probplot t / normal (mu=est sigma=est); title 'Normality Check for transformed variable'; run; 정규분포에대한적합도검정 검정 통계량 p- 값 Kolmogorov-Smirnov D Pr > D >0.150 Cramer-von Mises W-Sq Pr > W-Sq Anderson-Darling A-Sq Pr > A-Sq 0.215
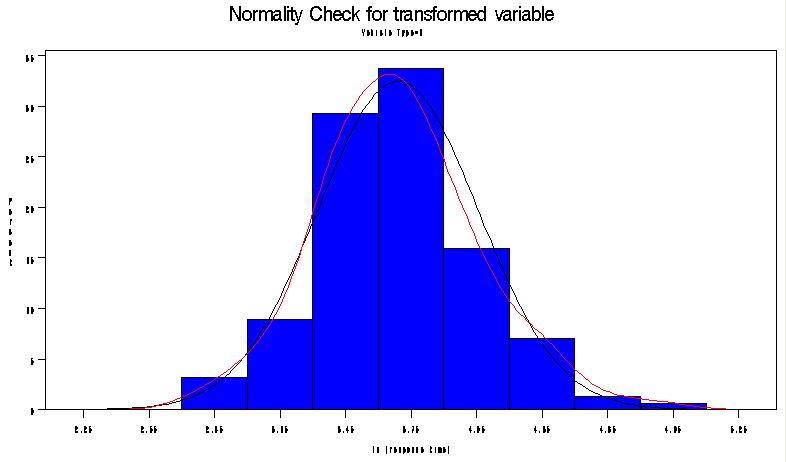
64
65 /* The transformed variable seems to normally ditributed. Then we can do parametric ANOVA with normality assumption */ proc anova; class vehtype; model t=vehtype; title 'ANOVA for the log transformed response time'; run; proc boxplot data=t ; plot t*vehtype /boxstyle =SCHEMATIC cboxes =blue cboxfill =gray idcolor=red ; run; The ANOVA Procedure Dependent Variable: t ln (response time) Sum of Source DF Squares Mean Square F Value Pr > F Model Error Corrected Total R-Square Coeff Var Root MSE t Mean Source DF Anova SS Mean Square F Value Pr > F vehtype
66
67 회귀분석 (Regression Analysis) 연속형설명변수가연속형종속 변수에미치는영향을분석
68 회귀계수의의미 단순회귀 : X 1 단위증가시 Y 증가분의기대치 Let Y X 0 1 E x x ( Y X 1) ( 1) E( Y X x) x EY ( X 0)
69 단순회귀와중회귀에서회귀 계수들의의미차이중회귀 : 다른 X 들이일정한값으로남아있을때관심 X 가 1 단위증가시 Y 의기대치의증가분 Let Y X X E( Y X x 1, X x ) ( x 1) x ( Y X, X ) E x x x x
70 한편 Y X * 이라면 은와는아무런관계없이 X1, Y의그림에서의기울기이다. * 1 X 2 X1 2 * 만약 1 과 이다르다면의효과를보는데있어서 X 1 를고려하느냐마느냐하는것에따라서결론이다르게된다. X 2 이러한경우를혼란변수 (confounder) 하고한다. 혼란변수를고려하지않은모형에서의결론은올바른결론이라할수없다. 연구설계시부터혼란변수로작용할수있는모든변수들을고려해야한다.
71 가상적예제 Y= 수축기혈압 X1= 고혈압여부, X2= 연령 * Y X * 의모형에서는고혈압여부와상관없이단순이자료에서연령이증가함에따라혈압이얼마나증가하는가를나타내고있다. 하지만 Y X X 의모형에서는가상의사람이고혈압상태가같다고할때의연령과혈압과의관계를나타낸다. 어떠한모수에우리가더관심이있는가?
72 자료 모형 중회귀 Y : 가축시장을운영하는비용 (COST) X : 각가축의수 CATTLE CALVES HOGS SHEEP = ( ) ( ) ( ) ( ), COST CATTLE CALVES HOGS SHEEP iid N(0, )
73 Proc reg data=auction; model cost=cattle calves hogs sheep; Model: MODEL1 Dependent Variable: cost SAS 시스템 Analysis of Variance Sum of Mean Source DF Squares Square F Value Pr > F Model <.0001 Error Corrected Total Root MSE R-Square Dependent Mean Adj R-Sq Coeff Var Parameter Estimate Parameter Standard Variable DF Estimate Error t Value Pr > t Intercept cattle <.0001 calves hogs sheep
74 중회귀방정식을위한 독립변수의선정 Forward selection Backward elimination Stepwise selection

75 분석 -> 회귀분석 -> 선형회귀분석 -> 방법 : 단계선택
76 진입 / 제거된변수 a 모형 진입된변수 제거된변수 방법 income. 단계선택 ( 기준 : 입력할 F의확률 <=. 050, 제거할 F의확률 >=. 100). aircapac. 단계선택 ( 기준 : 입력할 F의확률 <=. 050, 제거할 F의확률 >=. 100). applidx. 단계선택 ( 기준 : 입력할 F의확률 <=. 050, 제거할 F의확률 >=. 100).. income 단계선택 ( 기준 : 입력할 F의확률 <=. 050, 제거할 F의확률 >=. 100). housize. 단계선택 ( 기준 : 입력할 F의확률 <=. 050, 제거할 F의확률 >=. 100). family. 단계선택 ( 기준 : 입력할 F의확률 <=. 050, 제거할 F의확률 >=. 100). a. 종속변수 : peak 모형 모형요약 추정값의 R R 제곱 수정된 R 제곱 표준오차.930 a b c d e f a. 예측값 : ( 상수 ), income b. 예측값 : ( 상수 ), income, aircapac c. 예측값 : ( 상수 ), income, aircapac, applidx d. 예측값 : ( 상수 ), aircapac, applidx e. 예측값 : ( 상수 ), aircapac, applidx, housize f. 예측값 : ( 상수 ), aircapac, applidx, housize, family
77 모형 선형회귀분석잔차합계선형회귀분석잔차합계선형회귀분석잔차합계선형회귀분석잔차합계선형회귀분석잔차합계선형회귀분석잔차합계 a. 예측값 : ( 상수 ), income b. 예측값 : ( 상수 ), income, aircapac 분산분석 g c. 예측값 : ( 상수 ), income, aircapac, applidx d. 예측값 : ( 상수 ), aircapac, applidx e. 예측값 : ( 상수 ), aircapac, applidx, housize 제곱합 자유도 평균제곱 F 유의확률 a b c d e f f. 예측값 : ( 상수 ), aircapac, applidx, housize, family g. 종속변수 : peak
78 모형 housize aircapac applidx family housize applidx family housize family housize family income family income income 제외된변수 g 공선성통 계량 진입-베타 t 유의확률 편상관 공차한계.213 a a a a b b b c c d d d e e f a. 모형내의예측값 : ( 상수 ), income b. 모형내의예측값 : ( 상수 ), income, aircapac c. 모형내의예측값 : ( 상수 ), income, aircapac, applidx d. 모형내의예측값 : ( 상수 ), aircapac, applidx e. 모형내의예측값 : ( 상수 ), aircapac, applidx, housize f. 모형내의예측값 : ( 상수 ), aircapac, applidx, housize, family g. 종속변수 : peak
79 카이제곱검정 두이산변수간의관련성검정
80 카이제곱검정 (1) Satisfied Not Total Drug A 16 (45.2%) Drug B 9 (36.4%) 3 22
81 카이제곱검정 (2) 두사건 A와 B가독립 <-> P(A and B) = P(A) P(B) 만약약제와반응이독립이라면기대값은 Drug A Satisfied Not Total 31/53 * 25/53 * 53= Drug B 22 Total
82 카이제곱검정 (3) 카이제곱통계량은이기대치 (14.6) 와실제값 (16) 의차이의제곱의함수이다. 카이제곱통계량이크다 ( 작은 p-value) -> 기대치와실제값이다르다 -> 기대치를계산하기위한가정 ( 귀무가설 : 두변수가독립이다 ) 이틀리다 -> 두변수간에상관이있다 ( 약품에따라반응이다르다 ) 는대립가설을채택한다.
83 2 2 table Chi-square statistics n n11 12 n21 n22 n n n 1+ n 2+ N Mantel-Haenszel Chi-square Q ( n m ) v 11 Pearson chi-square Q P 2 2 i1 j1 2 ( n m ) ij m ij ij 2
84 data respire; input treat $ outcome $ count ; cards; test f 40 test u 20 placebo f 16 placebo u 48; proc freq; weight count; tables treat*outcome/chisq; run;
85 SAS 시스템 FREQ 프로시저 treat * outcome 교차표 treat outcome 빈도 백분율 행백분율 칼럼백분율 f u 총합 placebo test 총합
86 treat * outcome 테이블에대한통계량 통계량 자유도 값 확률값 카이제곱 <.0001 우도비카이제곱 <.0001 연속성수정카이제곱 <.0001 Mantel-Haenszel 카이제곱 <.0001 파이계수 분할계수 크래머의 V Fisher 의정확검정 (1,1) 셀빈도 (F) 16 하단측 p 값 Pr <= F 2.838E-06 상단측 p 값 Pr >= F 테이블확률 (P) 양측 p값 Pr <= P 2.397E E-06 표본크기 = 124
87 data severe; input treat $ outcome $ count ; cards; Test f 10 Test u 2 Control f 2 Control u 4 ; proc freq order=data; tables treat*outcome / chisq nocol; weight count; run;
88 SAS 시스템 FREQ 프로시저 treat * outcome 교차표 treat outcome 빈도 백분율 행백분율 f u 총합 Test Control 총합
89 treat * outcome 테이블에대한통계량 통계량자유도값확률값 카이제곱 우도비카이제곱 연속성수정카이제곱 Mantel-Haenszel 카이제곱 파이계수 분할계수 크래머의 V 경고 : 셀들의 75% 가 5 보다작은기대도수를가지고있습니다. 카이제곱검정은올바르지않을수있습니다. Fisher 의정확검정 (1,1) 셀빈도 (F) 10 하단측 p 값 Pr <= F 상단측 p 값 Pr >= F 테이블확률 (P) 양측 p 값 Pr <= P 표본크기 = 18
90 Exact Test Table Cell (1,1) (1,2) (2,1) (2,2) probabilities
91 Table Probabilities One-tailed p-value p Two-tailed p-value p
92 Difference in Proportions E{ p p } v d p1 (1 p1 ) p2(1 p2) n 1 n d { z vd ( )} 2 2 n n 1 2
93 Odds Ratio and Relative Risk OR f v f p /(1 p ) n n p /(1 p ) n n log{ OR} log p2 /(1 p2) /(1 p ) log{ p /(1 p )} log{ p /(1 p )} n n n n exp( f z v ) f p
94 RR RR p p 1 2 OR 1 1 n n n n if n and n are small relative to n and n rare outcome assumption Group1 Group2 total Yes No total n n n n n n n 1+ n 2+ N Proportion Yes p n n p2 n21 n12
95 data stress; input stress $ outcome $ count ; cards; low f 48 low u 12 high f 96 high u 94 ; proc freq order=data; tables stress*outcome / chisq measures nocol nopercent; weight count; run ;
96 FREQ 프로시저 stress * outcome 교차표 stress outcome 빈도 행백분율 f u 총합 low high 총합 stress * outcome 테이블에대한통계량 통계량자유도값확률값 카이제곱 <.0001 우도비카이제곱 <.0001 연속성수정카이제곱 Mantel-Haenszel 카이제곱 <.0001 파이계수 분할계수
97 Fisher 의정확검정 (1,1) 셀빈도 (F) 48 하단측 p 값 Pr <= F 상단측 p 값 Pr >= F 3.247E-05 테이블확률 (P) 양측 p값 Pr <= P 2.472E E-05 통계량 값 점근표준오차 감마 Kendall의타우-b Stuart 타우-c Somers D C R Somers D R C Pearson 상관계수 Spearman 상관계수 람다비대칭 C R 람다비대칭 R C 람다대칭 불확실계수 C R 불확실계수 R C 불확실계수대칭
98 상대위험도의추정값 ( 행 1/ 행 2) 연구유형값 95% 신뢰한계 사례대조연구 ( 오즈비 ) 코호트 ( 칼럼 1 리스크 ) 코호트 ( 칼럼 2 리스크 ) 표본크기 = 250
99 data respire; input treat $ outcome $ count ; cards; test yes 29 test no 16 placebo yes 14 placebo no 31 ; proc freq order=data; tables treat*outcome / measures chisq nocol nopercent; weight count; run ;
100 FREQ 프로시저 treat * outcome 교차표 treat outcome 빈도 행백분율 yes no 총합 test placebo 총합 상대위험도의추정값 ( 행 1/ 행 2) 연구유형값 95% 신뢰한계 사례대조연구 ( 오즈비 ) 코호트 ( 칼럼 1 리스크 ) 코호트 ( 칼럼 2 리스크 ) 표본크기 = 90
101
102
103 McNemar Test : Matched pairs
104 Frequency Percent Row Pct Col Pct yes no Total yes no Total Statistics for Table of hus_resp by wif_resp McNemar's Test Statistic (S) DF 1 Pr > S Ho : husband and wife 의 approval rates 는같다 를기각하지못함.
105 신뢰구간이 0 을포함하지않으므로 =0 이라는귀무가설을 95% 신뢰수준에서기각한다. Simple Kappa Coefficient Kappa ASE % Lower Conf Bound % Upper Conf Bound Sample Size = 45 Kappa=1 Kappa > 0.8 Kappa > 0.4 >> perfect agreement, >> excellent agreement >> moderate agreement
106 Logistic Regression 로지스틱회귀분석설명변수 ( 연속, 혹은이산 ) 가이산형종속변수에미치는영향분석
107 Y 1 for disease X1 1 for male X 2 0 for non -disease 0 for female 불연속 연속 age p ( Y 1) X X linear predictor ( ) p Y 1 log logit link function 1- p Y 1 log it p Y 1 X X p Y exp X 1 1 exp X = 1 exp X X X X
108 PY 1 X 1 X log, X 1 X2 0 1 P Y 1 X1 X 2 0 PY 1 X 1 1, X 2 x log 0 1 2x 1 P Y 1 X1 1, X 2 x PY 1 X 1 0, X 2 x log 1 PY 1 X1 0, X 2 x x 0 2 일때의 log odds 값 1 = 연령으로보정한후 ( 연령이같은값으로남아있을때 ) 성별 이남일때 ( 여에비하여 ) 병걸릴확률이 log odds ratio 의증가분 exp( 1). odds ratio 의증가분
109 2 P Y 1 X1 a, X 2 x 1 P Y 1 X1 a, X 2 x log log 1 P Y 1 X a, X x 1 1 P Y 1 X a, X x : 다른 x 들이일정한값으로남아있을때 ( 성별이일정할때, 성별의 효과를보정한후 ) 연령이한단위증가할시병걸릴확률의 log odds ratio 의증가분 exp( 2)... odds ratio 의증가분
110 proc logistic data=esr descending; model response=fibrin globulin; title 'ESR Data'; run; y=0,1 인경우 default 는작은값 (0) 을기준으로, 큰값을기준으로하려면 descending option 이필요
111 The LOGISTIC Procedure Model Information Data Set WORK.ESR Response Variable response Number of Response Levels 2 Number of Observations 32 Link Function Logit Optimization Technique Fisher's scoring Response Profile Ordered Total Value response Frequency Model Convergence Status Convergence criterion (GCONV=1E-8) satisfied.
112 Model Fit Statistics Intercept Intercept and Criterion Only Covariates AIC SC Log L Testing Global Null Hypothesis: BETA=0 Test Chi-Square DF Pr > ChiSq Likelihood Ratio Score Wald
113 Analysis of Maximum Likelihood Estimates Parameter Standard Wald Standardized Variable DF Estimate Error Chi-Square Pr > ChiSq Estimate Intercept fibrin globulin Analysis of Maximum Likelihood Estimtemates Odds Variable Ratio Intercept fibrin globulin 1.169
114 유전자형자료분석의기본 개념 Genotype Freq, Allele Freq, Hardy-Weinberg Disequilibrium, (Mendelian) Genetic Models, LD, Haplotype, Heritability, SNP Association Study, Multiple Comparisons
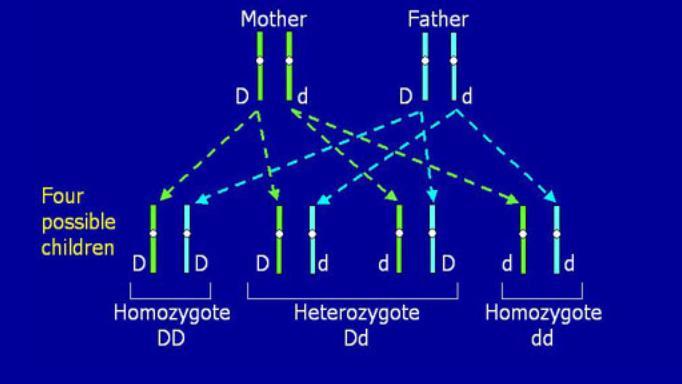
115 Genotype

116 Allele frequency

117 Genotype frequency

118 Hardy-Weinberg In a stable population with random mating, allele freq predicts genotype freq. Goodness-of-fit can be applied to test H-W Equilibrium
119 자유도 ( 유전형의개수) ( 추정할모수의개수) 1 통계기본이론 Chi-square Test Ho: 우리의자료가특정모형 2 (HWE) 을따른다 p pq qp q ( 관찰값- 기대값) 기대값 2 2 df 자유도 = 범주의개수 -1- 추정한모수의수 2 q
120 HWE 예제 1 개수 빈도 관찰값 기대값 관찰값 기대값 AA Aa aa total p = (2ⅹ )/(2ⅹ1000) = q = (489+2ⅹ213)/(2ⅹ1000) = P(A) = p 2 =(0.5425) 2 = P(Aa) = 2pq= 2ⅹ(0.5425)ⅹ(0.4575)= P(aa) = q 2 =(0.4575) 2 = 기대값 (expected frequency) AA = P(AA)ⅹ1000 = Aa = P(Aa)ⅹ1000 = aa = P(aa)ⅹ1000 =
121 검정통계량 2 ( ) ( ) ( ) = 자유도 =3-1-1= 자유도가 1 인카이제곱분포에근거가 p 값이 이므로관찰된값은 Ho (HWE 상태 ) 를기각할수있는충분한근거가없다. 즉 HWE 상태라고결론내린다. 실무에서는 genotype error check 의방법으로많이사용된다.
 2 p qp pq 1 2 Total q 2 Case n 11 n 12 n 1+ OR")
 /( n / n ) n / n n n p /(1 p ) ( n / n ) /(")


122 통계기본이론 Test of association (Odds ratio, Chi-square test) 2 p qp pq 1 2 Total q 2 Case n 11 n 12 n 1+ OR = Control n 21 n 22 n 2+ Total n +1 n +2 N p /(1 p ) ( n / n ) /( n / n ) n / n n n p /(1 p ) ( n / n ) /( n / n ) n / n n n q 2 Chi-square test with df=(#col-1)(#row-1) : Ho: OR=1 Expected cell freq is bigger than 5, if not use Fisher s Exact test 자유도 ( 유전형의개수) ( 추정할모수의개수) 1
123 자유도 ( 유전형의개수) ( 추정할모수의개수) 1 Chi-square 예제 : Genotype-based (Codominant model) p 2 MM Mm pq mm Total 2 qp Case n q 2A n 1A n 0A n +A Control n 2O n 1O n 0O n +O Total n 2+ n 1+ n 0+ N OR = MM/mm OR = Mm/mm n n n n 2A 0O 2O 0A n n n n 1A 0O 1O 0A Co-dominant model MM Mm mm 간의관계를가정하지않음 자유도 2 인검정 2 q
124 자유도 ( 유전형의개수) ( 추정할모수의개수) 1 Chi-square 예제 : Genotype-based (Dominant Model) p 2 MM or Mm pq mm Total 2 qp Case n q 2A + n 1A n 0A n +A Control n 2O +n 1O n 0O n +O Total n 2+ +n 1+ n 0+ N 2 q OR MM or Mm /mm Dominant model (MM = Mm) > mm 자유도 1 인검정
125 자유도 ( 유전형의개수) ( 추정할모수의개수) 1 Chi-square 예제 : Genotype-based (Recessive model) p 2 MM Mm pq or mm Total 2 qp Case n q 2A n 1A +n 0A n +A Control n 2O n 1O +n 0O n +O Total n 2+ n 1+ +n 0+ N 2 q OR MM/Mm or mm Recessive model MM > (Mm=mm) 자유도 1 인검정
126 Chi-square 예제 : Genotype-based (Additive Model) p 2 MM Mm pq mm Total 2 qp Case n q 2A n 1A n 0A n +A Control n 2O n 1O n 0O n +O Total n 2+ n 1+ n 0+ N OR = OR MM/Mm Mm/mm OR = 2 OR = 2 OR MM/mm Mm/mm MM/Mm Additive model (MM-Mm)=(Mm-mm) Dose-Response 가정 자유도 1 인검정 자유도 ( 유전형의개수) ( 추정할모수의개수) 1 2 q

127 Linkage Disequilibrium Alleles at different sites should occur in a combinations relative to their SNP allele freq
128 LD Block

129 Shaw et al. Am J of Medical Genet (2002)
130 SNP SNP From SNP to Haplotype Phenotype Black eye Brown eye Black eye Blue eye Brown eye Brown eye GATATTCGTACGGA-T GATGTTCGTACTGAAT GATATTCGTACGGA-T GATATTCGTACGGAAT GATGTTCGTACTGAAT GATGTTCGTACTGAAT Haplotypes AG- 2/6 GTA 3/6 AGA 1/6 DNA Sequence
131 Association study using haplotype Hap AG- GTA AGA Total Case Control Total 2N Hap Pair AG-/AG- AG-/GTA AG-/AGA AGA/AGA Total Case Control Total N
132 만약 AGA 가 risk hap Hap Pair Else Else/AGA AGA/AGA Total Case Control Total 만약 AGA 가 risk hap 이고 Dominant Model 을적용한다면 Hap Pair Else Else/AGA or AGA/AGA Total Case Control N Total N
133 How to identify the genes Family study Linkage analysis: pedigree 필요 Sib pair analysis: oligogenic, multigenic Population study Case-control association study


 Gene?")
134 New Gene Discovery Phenotype Segregation Association study Putative gene (locus) Gene? Linkage analysis (LD, sibpair et al)
135 Heritability 형질 (Trait) 유전율 (%) 형질 (Trait) 유전율 (%) 수명 29 언어능력 63 키 85 최대맥박수 84 몸무게 63 계산능력 76 아미노산분비 혈중지질농도 혈중최대젖산농도 72 기억력 사회적응력 감성 58
136
137
138 T k { ( D E )} i1 1i 1i k i1 V 1i 2
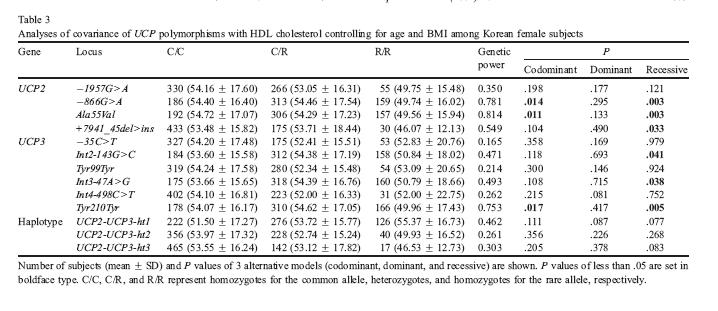
139 SNP Association Study 1. Study design 1. Select target disease 2. Case-control criteria 3. Determine # of samples 2. Sample and Data Collection 1. Genetic materials 2. Clinical information/phenotypic classification 3. Environmental Information 3. Genotyping 1. Select candidate genes/snp 2. Whole genome screening 3. Select appropriate method of genotyping 4. Statistical Analysis

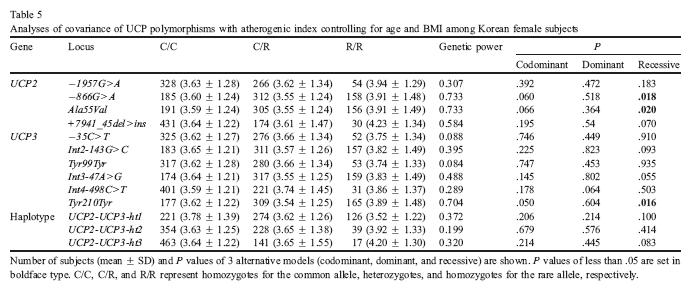
140 Statistical analysis scheme of SNP Genotyping Data
141
142 Multiple Comparisons ( 다중비교 ) ex) 한 test 에서유의수준이인 test 가있다고하자. 일반적으로 multiple comparison 을한다면 overall Inflate 되었다. Let H : 0, Pr(do not reject H H is true) 1 H : 0, Pr(do not reject H H is true) then Pr(do not reject H H ) where H H and H Pr(do not reject H 01 and do no H02 H0 t reject ) 2 (1- ) (1- ) (1- ) k 0 를 k (1 ) (1 ) (.95).95 는 0.05 가아니라 가되므로 type I error 가
143 Multiple Comparisons Bonferroni Correction : 만약 m개의 multiple comparison을한다면각각의유의수준을 로하면전체의유의수준을에가깝게할수있다. m 예 )m 이 4 인경우 (1 ) 응용 ) 10개의 mean을비교하는경우 p값의기준을 0.05로하면 overall p값을유지할수없으므로각각의경우 0.05 를기준으로 test를실시한다 이를 Bonferroni corrected p-value 라고한다.
144 Multiple Comparisons: FDR False Discovery Rate FDR = False Positive / Total Positive 1. Order p-values (largest to smallest) 2. Test 0.05 k/n, k=n, N-1,., 1 Sequentially reduce error rate > power reduced much less Bonferroni, too conservative ; FDR helpful
145 Multiple Comparisons: FDR (independent test) Benjamini and Hochberg (1995) 1. Order p-values by P (1), P (2),., P (m) 2. Find the largest k such that 3. 1,2,,k 까지는유의하다. ( 예 ) m=500k, 0.05/500K =10^(-7) : Bonferroni correction 0.05/500K * 2, 0.05/500K * 3 해서 P (2000) <2000*10^(-7) 이고 P (2001) >2001*10^(-7) 이라면 2000 개뽑는다.
146 Multiple Comparisons: FDR (dependent test) Benjamini and Yekutieli (2001) 1. Order p-values by P (1), P (2),., P (m) 2. Find the largest k such that 3. 1,2,,k 까지는유의하다. If tests are indep or positively correlated then If tests are negatively correlated then
147 Permutation test
148 Statistical Models for SNP Association Study Response Var Group Statistical Methods 연속변수 (BMI, BP, etc) 이항변수 (casecontrol) 2 groups 2 groups (N<5 per group) 3 groups or more 보정변수 2 groups 2 groups (N<5 per group) 보정변수 T-test Wilcoxon test ANOVA ANCOVA, regression Chi-square test Fisher s Exact test Logistic regression
149
150
151
152
153 감사합니다. /~hokim
<4D F736F F F696E74202D20BECBB7B9B8A3B1E2C7D0C8B C0CEBBF3BFACB1B8BFA1BCADC8E7C8F7BBE7BFEBB5C7B4C22E707074>
 임상연구에서흔히사용 하는의학통계의실제 김호서울대학교보건대학원미래세대를위한교육강좌 2007/6/17 Outline 통계적가설검정의기본개념들 가설검정, 통계적오류, 검정력및표본수 연속형자료에서의통계분석 T-test, ANOVA, 회귀분석 ( 단순회귀, 중회귀 ) 범주형자료에서의통계분석 카이제곱검정, 로지스틱회귀분석 유전자형자료분석의기본개념 기본개념들 모집단과표본
임상연구에서흔히사용 하는의학통계의실제 김호서울대학교보건대학원미래세대를위한교육강좌 2007/6/17 Outline 통계적가설검정의기본개념들 가설검정, 통계적오류, 검정력및표본수 연속형자료에서의통계분석 T-test, ANOVA, 회귀분석 ( 단순회귀, 중회귀 ) 범주형자료에서의통계분석 카이제곱검정, 로지스틱회귀분석 유전자형자료분석의기본개념 기본개념들 모집단과표본
 Y 1 Y β α β Independence p qp pq q if X and Y are independent then E(XY)=E(X)*E(Y) so Cov(X,Y) = 0 Covariance can be a measure of departure from independence q Conditional Probability if A and B are
Y 1 Y β α β Independence p qp pq q if X and Y are independent then E(XY)=E(X)*E(Y) so Cov(X,Y) = 0 Covariance can be a measure of departure from independence q Conditional Probability if A and B are
Chapter 분포와 도수분석
 2 χ Chapter 10 분포와도수분석 Chi-square dist n & the analysis of frequencies 2014/5/22 2 χ 10.2 분포의수리적특징 2 χ 의정의 (definition) Z,, Z ~ independent N(0,1) 1 n n i = 1 Z ~ χ 2 2 i n Y µ 2 eg.. Z = i Y ~ N( µσ,
2 χ Chapter 10 분포와도수분석 Chi-square dist n & the analysis of frequencies 2014/5/22 2 χ 10.2 분포의수리적특징 2 χ 의정의 (definition) Z,, Z ~ independent N(0,1) 1 n n i = 1 Z ~ χ 2 2 i n Y µ 2 eg.. Z = i Y ~ N( µσ,
G Power
 G Power 부산대학교통계학과조영석 1. G Power 란? 2. G Power 설치및실행 2.1 G Power 설치 2.2 G Power 실행 3. 검정 (Test) 3.1 가설검정 (Test of hypothesis) 3.2 검정력 (Power) 3.3 효과크기 (Effect size) 3.4 표본수산정 4. 분석 4.1 t- 검정 (t-test) 4.2
G Power 부산대학교통계학과조영석 1. G Power 란? 2. G Power 설치및실행 2.1 G Power 설치 2.2 G Power 실행 3. 검정 (Test) 3.1 가설검정 (Test of hypothesis) 3.2 검정력 (Power) 3.3 효과크기 (Effect size) 3.4 표본수산정 4. 분석 4.1 t- 검정 (t-test) 4.2
R t-..
 R 과데이터분석 집단의차이비교 t- 검정 양창모 청주교육대학교컴퓨터교육과 2015 년겨울 t- 검정 변수의값이연속적이고정규분포를따른다고할때사용 t.test() 는모평균과모평균의 95% 신뢰구간을추청함과동시에가설검증을수행한다. 모평균의구간추정 - 일표본 t- 검정 이가설검정의귀무가설은 모평균이 0 이다 라는귀무가설이다. > x t.test(x)
R 과데이터분석 집단의차이비교 t- 검정 양창모 청주교육대학교컴퓨터교육과 2015 년겨울 t- 검정 변수의값이연속적이고정규분포를따른다고할때사용 t.test() 는모평균과모평균의 95% 신뢰구간을추청함과동시에가설검증을수행한다. 모평균의구간추정 - 일표본 t- 검정 이가설검정의귀무가설은 모평균이 0 이다 라는귀무가설이다. > x t.test(x)
Microsoft PowerPoint - IPYYUIHNPGFU
 분산분석 분산분석 (ANOVA: ANALYSIS OF VARIANCE) 두개이상의모집단의차이를검정 예 : 회사에서세종류의기계를설치하여동일한제품을생산하는경우, 각기계의생산량을조사하여평균생산량을비교 독립변수 : 다른변수에의해영향을주는변수 종속변수 : 다른변수에의해영향을받는변수 요인 (Factor): 독립변수 예에서의요인 : 기계의종류 (I, II, III) 요인수준
분산분석 분산분석 (ANOVA: ANALYSIS OF VARIANCE) 두개이상의모집단의차이를검정 예 : 회사에서세종류의기계를설치하여동일한제품을생산하는경우, 각기계의생산량을조사하여평균생산량을비교 독립변수 : 다른변수에의해영향을주는변수 종속변수 : 다른변수에의해영향을받는변수 요인 (Factor): 독립변수 예에서의요인 : 기계의종류 (I, II, III) 요인수준
Chapter 11 비모수 및 무분포통계학
 Chapter 12 비모수통계학 (nonparametric analysis) 2017/6/5 9.1 머리말 (introduction) 모수적방법 모집단의분포를가정 그분포는모수의함수 모수를알면분포를완전히안다. 모수의추정과검정이주요문제 모집단의분포가정이틀리면전체논리가다틀리게된다. Parametric approach * assumes dist n of the pop
Chapter 12 비모수통계학 (nonparametric analysis) 2017/6/5 9.1 머리말 (introduction) 모수적방법 모집단의분포를가정 그분포는모수의함수 모수를알면분포를완전히안다. 모수의추정과검정이주요문제 모집단의분포가정이틀리면전체논리가다틀리게된다. Parametric approach * assumes dist n of the pop
abstract.dvi
 통계자료분석 강희모 2014년 5월 14일 목차 제 1장 여러가지평균비교 1 1.1. 단일표본검정.............................. 2 1.2. 독립인두표본검정........................... 4 1.3. 대응표본검정.............................. 9 제 2 장 분산분석(ANalysis Of VAriance)
통계자료분석 강희모 2014년 5월 14일 목차 제 1장 여러가지평균비교 1 1.1. 단일표본검정.............................. 2 1.2. 독립인두표본검정........................... 4 1.3. 대응표본검정.............................. 9 제 2 장 분산분석(ANalysis Of VAriance)
자료의 이해 및 분석
 어떤실험이나치료의효과를측정할때독립이아닌표본으로부터관찰치를얻었을때처리하는방법 - 동일한개체에어떤처리를하기전과후의자료를얻을때 - 가능한동일한특성을갖는두개의개체에서로다른처리를하여그처리의효과를비교하는방법 (matching) 1 예제 : 혈청 cholesterol 치를줄이기위해서 12 명을대상으로운동과함께식이요법의효과를 측정하기위한실험실시 2 식이요법 - 운동실험전과후의
어떤실험이나치료의효과를측정할때독립이아닌표본으로부터관찰치를얻었을때처리하는방법 - 동일한개체에어떤처리를하기전과후의자료를얻을때 - 가능한동일한특성을갖는두개의개체에서로다른처리를하여그처리의효과를비교하는방법 (matching) 1 예제 : 혈청 cholesterol 치를줄이기위해서 12 명을대상으로운동과함께식이요법의효과를 측정하기위한실험실시 2 식이요법 - 운동실험전과후의
자료의 이해 및 분석
 7. 평균치비교 1 두집단간평균차이검정 2 연속형변수 Interval scale( 간격척도 ) : 20 C, 30 C,, 변수간의가감가능 Ratio scale( 비척도 ) : 12, 13세, 변수간의가감승제모두가능 범주형자료로변환하여다양한분석가능 ( 연령 10 대, 20 대, 30 대.) 3 범주형자료의기술 분할표 (Contingency table) : 범주형자료를각변수별값의
7. 평균치비교 1 두집단간평균차이검정 2 연속형변수 Interval scale( 간격척도 ) : 20 C, 30 C,, 변수간의가감가능 Ratio scale( 비척도 ) : 12, 13세, 변수간의가감승제모두가능 범주형자료로변환하여다양한분석가능 ( 연령 10 대, 20 대, 30 대.) 3 범주형자료의기술 분할표 (Contingency table) : 범주형자료를각변수별값의
nonpara1.PDF
 Chapter 1 Introduction 1 Introduction (parameter) (assumption) (rank), (median) p-value distribution free, assumption free, statistical inference based on ranks 11 Nonparametric? John Arbuthnot (1710)
Chapter 1 Introduction 1 Introduction (parameter) (assumption) (rank), (median) p-value distribution free, assumption free, statistical inference based on ranks 11 Nonparametric? John Arbuthnot (1710)
 소표본 (
소표본 ( 조사연구 권 호 연구논문 한국노동패널조사자료의분석을위한패널가중치산출및사용방안사례연구 A Case Study on Construction and Use of Longitudinal Weights for Korea Labor Income Panel Survey 2)3) a
3) a") 조사연구 권 호 연구논문 한국노동패널조사자료의분석을위한패널가중치산출및사용방안사례연구 A Case Study on Construction and Use of Longitudinal Weights for Korea Labor Income Panel Survey 2)3) a) b) 조사연구 주제어 패널조사 횡단면가중치 종단면가중치 선형혼합모형 일반화선형혼 합모형
조사연구 권 호 연구논문 한국노동패널조사자료의분석을위한패널가중치산출및사용방안사례연구 A Case Study on Construction and Use of Longitudinal Weights for Korea Labor Income Panel Survey 2)3) a) b) 조사연구 주제어 패널조사 횡단면가중치 종단면가중치 선형혼합모형 일반화선형혼 합모형
untitled
 Math. Statistics: Statistics? 1 What is Statistics? 1. (collection), (summarization), (analyzing), (presentation) (information) (statistics).., Survey, :, : : QC, 6-sigma, Data Mining(CRM) (Econometrics)
Math. Statistics: Statistics? 1 What is Statistics? 1. (collection), (summarization), (analyzing), (presentation) (information) (statistics).., Survey, :, : : QC, 6-sigma, Data Mining(CRM) (Econometrics)
ANOVA 란? ANalysis Of VAriance Ø 3개이상의모집단의평균의차이를검정하는방법 Ø 3개의모집단일경우 H0 : μ1 = μ2 = μ3 H0기각 : μ1 μ2 = μ3 or μ1 = μ2 μ3 or μ1 μ2 μ3 àpost hoc test 수행
 Ch4 one-way ANOVA ANOVA 란? ANalysis Of VAriance Ø 3개이상의모집단의평균의차이를검정하는방법 Ø 3개의모집단일경우 H0 : μ1 = μ2 = μ3 H0기각 : μ1 μ2 = μ3 or μ1 = μ2 μ3 or μ1 μ2 μ3 àpost hoc test 수행 One-way ANOVA 란? Group Sex pvas NSAID
Ch4 one-way ANOVA ANOVA 란? ANalysis Of VAriance Ø 3개이상의모집단의평균의차이를검정하는방법 Ø 3개의모집단일경우 H0 : μ1 = μ2 = μ3 H0기각 : μ1 μ2 = μ3 or μ1 = μ2 μ3 or μ1 μ2 μ3 àpost hoc test 수행 One-way ANOVA 란? Group Sex pvas NSAID
Chapter 7 분산분석
 Chapter 7 분산분석 (ANalysis Of VAariance, ANOVA) 2014/4/29 7.1 머리말 (Introduction) 분산분석 (analysis of variance) : 전체변동을몇개의성분으로분할하는기법 (Divide total variation into several components) 전체변동에대해각각의변동요인의기여규모를파악 (contribution
Chapter 7 분산분석 (ANalysis Of VAariance, ANOVA) 2014/4/29 7.1 머리말 (Introduction) 분산분석 (analysis of variance) : 전체변동을몇개의성분으로분할하는기법 (Divide total variation into several components) 전체변동에대해각각의변동요인의기여규모를파악 (contribution
슬라이드 1
 빅데이터분석을위한데이터마이닝방법론 SAS Enterprise Miner 활용사례를중심으로 7 주차 회귀분석 Regression Analysis 최종후, 강현철 차례 4.1 선형회귀분석 (Linear Regression Analysis) 4.2 로지스틱회귀분석 (Logistic Regression Analysis) 4.3 회귀분석의특징과제약 4.4 분석사례 -
빅데이터분석을위한데이터마이닝방법론 SAS Enterprise Miner 활용사례를중심으로 7 주차 회귀분석 Regression Analysis 최종후, 강현철 차례 4.1 선형회귀분석 (Linear Regression Analysis) 4.2 로지스틱회귀분석 (Logistic Regression Analysis) 4.3 회귀분석의특징과제약 4.4 분석사례 -
저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할
 저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할수없습니다. 변경금지. 귀하는이저작물을개작, 변형또는가공할수없습니다. 귀하는, 이저작물의재이용이나배포의경우,
저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할수없습니다. 변경금지. 귀하는이저작물을개작, 변형또는가공할수없습니다. 귀하는, 이저작물의재이용이나배포의경우,
<4D F736F F D20BDC3B0E8BFADBAD0BCAE20C1A B0AD5FBCF6C1A45FB0E8B7AEB0E6C1A6C7D E646F63>
 제 3 강계량경제학 Review Par I. 단순회귀모형 I. 계량경제학 A. 계량경제학 (Economerics 이란? i. 경제적이론이설명하는경제변수들간의관계를경제자료를바탕으로통 계적으로추정 (esimaion 고검정 (es 하는학문 거시소비함수 (Keynse. C=f(Y, 0
제 3 강계량경제학 Review Par I. 단순회귀모형 I. 계량경제학 A. 계량경제학 (Economerics 이란? i. 경제적이론이설명하는경제변수들간의관계를경제자료를바탕으로통 계적으로추정 (esimaion 고검정 (es 하는학문 거시소비함수 (Keynse. C=f(Y, 0
Chapter 7 분산분석
 Chapter 8 실험계획및분산분석 (ANalysis Of VAariance, ANOVA) Updated 2018/4/30 7.1 머리말 (Introduction) 분산분석 (analysis of variance) : 전체변동을몇개의성분으로분할하는기법 (Divide total variation into several components) 전체변동에대해각각의변동요인의기여규모를파악
Chapter 8 실험계획및분산분석 (ANalysis Of VAariance, ANOVA) Updated 2018/4/30 7.1 머리말 (Introduction) 분산분석 (analysis of variance) : 전체변동을몇개의성분으로분할하는기법 (Divide total variation into several components) 전체변동에대해각각의변동요인의기여규모를파악
공공기관임금프리미엄추계 연구책임자정진호 ( 한국노동연구원선임연구위원 ) 연구원오호영 ( 한국직업능력개발원연구위원 ) 연구보조원강승복 ( 한국노동연구원책임연구원 ) 이연구는국회예산정책처의정책연구용역사업으로 수행된것으로서, 본연구에서제시된의견이나대안등은
 연구원오호영 ( 한국직업능력개발원연구위원 ) 연구보조원강승복 ( 한국노동연구원책임연구원 ) 이연구는국회예산정책처의정책연구용역사업으로 수행된것으로서, 본연구에서제시된의견이나대안등은") 2013 년도연구용역보고서 공공기관임금프리미엄추계 - 2013. 12.- 이연구는국회예산정책처의연구용역사업으로수행된것으로서, 보고서의내용은연구용역사업을수행한연구자의개인의견이며, 국회예산정책처의공식견해가아님을알려드립니다. 연구책임자 한국노동연구원선임연구위원정진호 공공기관임금프리미엄추계 2013. 12. 연구책임자정진호 ( 한국노동연구원선임연구위원 ) 연구원오호영
2013 년도연구용역보고서 공공기관임금프리미엄추계 - 2013. 12.- 이연구는국회예산정책처의연구용역사업으로수행된것으로서, 보고서의내용은연구용역사업을수행한연구자의개인의견이며, 국회예산정책처의공식견해가아님을알려드립니다. 연구책임자 한국노동연구원선임연구위원정진호 공공기관임금프리미엄추계 2013. 12. 연구책임자정진호 ( 한국노동연구원선임연구위원 ) 연구원오호영
슬라이드 1
 대한의료관련감염관리학회학술대회 2016년 5월 26일 ( 목 ) 15:40-17:40 서울아산병원동관 6층대강당서울성심병원김지형 기능, 가격, 모든것을종합 1 Excel 자료정리 2 SPSS 학교에서준다면설치 3 통계시작 : dbstat 4 Web-R : 표만들기, 메타분석 5 R SPSS www.cbgstat.com dbstat 직접 dbstat 길들이기
대한의료관련감염관리학회학술대회 2016년 5월 26일 ( 목 ) 15:40-17:40 서울아산병원동관 6층대강당서울성심병원김지형 기능, 가격, 모든것을종합 1 Excel 자료정리 2 SPSS 학교에서준다면설치 3 통계시작 : dbstat 4 Web-R : 표만들기, 메타분석 5 R SPSS www.cbgstat.com dbstat 직접 dbstat 길들이기
cat_data3.PDF
 ( ) IxJ ( 5 0% ) Pearson Fsher s exact test χ, LR Ch-square( G ) x, Odds Rato θ, Ch-square Ch-square (Goodness of ft) Pearson cross moment ( Mantel-Haenszel ), Ph-coeffcent, Gamma (γ ), Kendall τ (bnary)
( ) IxJ ( 5 0% ) Pearson Fsher s exact test χ, LR Ch-square( G ) x, Odds Rato θ, Ch-square Ch-square (Goodness of ft) Pearson cross moment ( Mantel-Haenszel ), Ph-coeffcent, Gamma (γ ), Kendall τ (bnary)
Microsoft Word - SAS_Data Manipulate.docx
 수학계산관련 함수 함수 형태 내용 SIN(argument) TAN(argument) EXP( 변수명 ) SIN 값을계산 -1 argument 1 TAN 값을계산, -1 argument 1 지수함수로지수값을계산한다 SQRT( 변수명 ) 제곱근값을계산한다 제곱은 x**(1/3) = 3 x x 1/ 3 x**2, 세제곱근 LOG( 변수명 ) LOGN( 변수명 )
수학계산관련 함수 함수 형태 내용 SIN(argument) TAN(argument) EXP( 변수명 ) SIN 값을계산 -1 argument 1 TAN 값을계산, -1 argument 1 지수함수로지수값을계산한다 SQRT( 변수명 ) 제곱근값을계산한다 제곱은 x**(1/3) = 3 x x 1/ 3 x**2, 세제곱근 LOG( 변수명 ) LOGN( 변수명 )
methods.hwp
 1. 교과목 개요 심리학 연구에 기저하는 기본 원리들을 이해하고, 다양한 심리학 연구설계(실험 및 비실험 설계)를 학습하여, 독립된 연구자로서의 기본적인 연구 설계 및 통계 분석능력을 함양한다. 2. 강의 목표 심리학 연구자로서 갖추어야 할 기본적인 지식들을 익힘을 목적으로 한다. 3. 강의 방법 강의, 토론, 조별 발표 4. 평가방법 중간고사 35%, 기말고사
1. 교과목 개요 심리학 연구에 기저하는 기본 원리들을 이해하고, 다양한 심리학 연구설계(실험 및 비실험 설계)를 학습하여, 독립된 연구자로서의 기본적인 연구 설계 및 통계 분석능력을 함양한다. 2. 강의 목표 심리학 연구자로서 갖추어야 할 기본적인 지식들을 익힘을 목적으로 한다. 3. 강의 방법 강의, 토론, 조별 발표 4. 평가방법 중간고사 35%, 기말고사
statistics
 수치를이용한자료요약 statistics hmkang@hallym.ac.kr 한림대학교 통계학 강희모 ( 한림대학교 ) 수치를이용한자료요약 1 / 26 수치를 통한 자료의 요약 요약 방대한 자료를 몇 개의 의미있는 수치로 요약 자료의 분포상태를 알 수 있는 통계기법 사용 중심위치의 측도(measure of center) : 어떤 값을 중심으로 분포되어 있는지
수치를이용한자료요약 statistics hmkang@hallym.ac.kr 한림대학교 통계학 강희모 ( 한림대학교 ) 수치를이용한자료요약 1 / 26 수치를 통한 자료의 요약 요약 방대한 자료를 몇 개의 의미있는 수치로 요약 자료의 분포상태를 알 수 있는 통계기법 사용 중심위치의 측도(measure of center) : 어떤 값을 중심으로 분포되어 있는지
01-07-0.hwp
 선거와 시장경제Ⅱ - 2000 국회의원 선거시장을 중심으로 - 발간사 차 례 표 차례 그림 차례 제1부 시장 메커니즘과 선거시장 Ⅰ. 서 론 Ⅱ. 선거시장의 원리와 운영방식 정당시장 지역구시장 문의사항은 Q&A를 참고하세요 정당시장 한나라당 사기 종목주가그래프 c 2000 중앙일보 Cyber중앙 All rights reserved. Terms
선거와 시장경제Ⅱ - 2000 국회의원 선거시장을 중심으로 - 발간사 차 례 표 차례 그림 차례 제1부 시장 메커니즘과 선거시장 Ⅰ. 서 론 Ⅱ. 선거시장의 원리와 운영방식 정당시장 지역구시장 문의사항은 Q&A를 참고하세요 정당시장 한나라당 사기 종목주가그래프 c 2000 중앙일보 Cyber중앙 All rights reserved. Terms
확률과통계 강의자료-1.hwp
 1. 통계학이란? 1.1 수학적 모형 실험 또는 증명을 통하여 자연현상을 분석하기 위한 수학적인 모형 1 결정모형 (deterministic model) - 뉴톤의 운동방정식 : - 보일-샤를의 법칙 : 일정량의 기체의 부피( )는 절대 온도()에 정비례하고, 압력( )에 반비례한다. 2 확률모형 (probabilistic model) - 주사위를 던질 때
1. 통계학이란? 1.1 수학적 모형 실험 또는 증명을 통하여 자연현상을 분석하기 위한 수학적인 모형 1 결정모형 (deterministic model) - 뉴톤의 운동방정식 : - 보일-샤를의 법칙 : 일정량의 기체의 부피( )는 절대 온도()에 정비례하고, 압력( )에 반비례한다. 2 확률모형 (probabilistic model) - 주사위를 던질 때
- 1 -
 - 1 - External Shocks and the Heterogeneous Autoregressive Model of Realized Volatility Abstract: We examine the information effect of external shocks on the realized volatility based on the HAR-RV (heterogeneous
- 1 - External Shocks and the Heterogeneous Autoregressive Model of Realized Volatility Abstract: We examine the information effect of external shocks on the realized volatility based on the HAR-RV (heterogeneous
Chapter 8 단순선형회귀분석과 상관분석
 Chapter 9 회귀모형 regression analysis 9.1 머리말 (Intro) Sir Francis Galton (18-1911) s studies on genetics Heights of parents and children: 부모의신장에비해 세의신장이일반평균치에복귀 (revert to the pop mean) 하는특성을발견하였다. 복귀 (revert)
Chapter 9 회귀모형 regression analysis 9.1 머리말 (Intro) Sir Francis Galton (18-1911) s studies on genetics Heights of parents and children: 부모의신장에비해 세의신장이일반평균치에복귀 (revert to the pop mean) 하는특성을발견하였다. 복귀 (revert)
고객관계를 리드하는 서비스 리더십 전략
 제 13 장분산분석 1 13.1 일원분산분석 13. 분산분석 - 무작위블럭디자인 13.3 이원분산분석 - 팩토리얼디자인 분산분석 (ANOVA) - 두개이상의집단들의평균값을비교하는데사용. 일원분산분석 - 처치변수가한개인분산분석. 1. 분산분석의원리 A 3.0 8.0 7.0 5.0 5.0 6.0 4.0 7.0 6.0 4.0 평균 5.0 6.0 B 3.0 9.0
제 13 장분산분석 1 13.1 일원분산분석 13. 분산분석 - 무작위블럭디자인 13.3 이원분산분석 - 팩토리얼디자인 분산분석 (ANOVA) - 두개이상의집단들의평균값을비교하는데사용. 일원분산분석 - 처치변수가한개인분산분석. 1. 분산분석의원리 A 3.0 8.0 7.0 5.0 5.0 6.0 4.0 7.0 6.0 4.0 평균 5.0 6.0 B 3.0 9.0
<B0A3C3DFB0E828C0DBBEF7292E687770>
 초청연자특강 대구가톨릭의대의학통계학교실 Meta analysis ( 메타분석 ) 예1) The effect of interferon on development of hepatocellular carcinoma in patients with chronic hepatitis B virus infection?? -:> 1998.1 ~2007.12.31 / RCT(2),
초청연자특강 대구가톨릭의대의학통계학교실 Meta analysis ( 메타분석 ) 예1) The effect of interferon on development of hepatocellular carcinoma in patients with chronic hepatitis B virus infection?? -:> 1998.1 ~2007.12.31 / RCT(2),
고차원에서의 유의성 검정
 고차원에서의유의성검정 박창이 서울시립대학교통계학과 박창이 ( 서울시립대학교통계학과 ) 고차원에서의유의성검정 1 / 15 학습내용 FDR(false discovery rate) SAM(significance analysis of microarray) FDR 에대한베이지안해석 박창이 ( 서울시립대학교통계학과 ) 고차원에서의유의성검정 2 / 15 서론 I 고차원데이터에서변수들에대한유의성검정
고차원에서의유의성검정 박창이 서울시립대학교통계학과 박창이 ( 서울시립대학교통계학과 ) 고차원에서의유의성검정 1 / 15 학습내용 FDR(false discovery rate) SAM(significance analysis of microarray) FDR 에대한베이지안해석 박창이 ( 서울시립대학교통계학과 ) 고차원에서의유의성검정 2 / 15 서론 I 고차원데이터에서변수들에대한유의성검정
nonpara6.PDF
 6 One-way layout 3 (oneway layout) k k y y y y n n y y K yn y y n n y y K yn k y k y k yknk n k yk yk K y nk (grand mean) (SST) (SStr: ) (SSE= SST-SStr), ( 39 ) ( )(rato) F- (normalty assumpton), Medan,
6 One-way layout 3 (oneway layout) k k y y y y n n y y K yn y y n n y y K yn k y k y k yknk n k yk yk K y nk (grand mean) (SST) (SStr: ) (SSE= SST-SStr), ( 39 ) ( )(rato) F- (normalty assumpton), Medan,
연속형 자료분석 R commander 예제
 R commander 를 이용핚통계처리소개 : 사용자편의성이강화된무료의고급통계프로그램 김호 서울대학교보건대학원 Useful sites R is a free software with powerful tools The Comprehensive R Archives Network http://cran.r-project.org/ -> Windows -> base ->
R commander 를 이용핚통계처리소개 : 사용자편의성이강화된무료의고급통계프로그램 김호 서울대학교보건대학원 Useful sites R is a free software with powerful tools The Comprehensive R Archives Network http://cran.r-project.org/ -> Windows -> base ->
<31372DB9DABAB4C8A32E687770>
 김경환 박병호 충북대학교 도시공학과 (2010. 5. 27. 접수 / 2011. 11. 23. 채택) Developing the Traffic Severity by Type Kyung-Hwan Kim Byung Ho Park Department of Urban Engineering, Chungbuk National University (Received May
김경환 박병호 충북대학교 도시공학과 (2010. 5. 27. 접수 / 2011. 11. 23. 채택) Developing the Traffic Severity by Type Kyung-Hwan Kim Byung Ho Park Department of Urban Engineering, Chungbuk National University (Received May
PowerPoint 프레젠테이션
 응용식물통계학 Statistics of Applied Plants Science 친환경식물학부유기농생태학전공황선구 13 장상관분석 1. 상관계수 2. 상관분석의가정과특성 3. 모상관계수의검정과신뢰한계 4. 순위상관 14 장회귀분석 1. 회귀직선의추정 2. 회귀직선의검정및추론 3. 모집단절편과회귀계수의구간추정 4. 곡선회귀 - 실습 - 상관분석 지금까지한가지확률변수에의한현상을검정하였다.
응용식물통계학 Statistics of Applied Plants Science 친환경식물학부유기농생태학전공황선구 13 장상관분석 1. 상관계수 2. 상관분석의가정과특성 3. 모상관계수의검정과신뢰한계 4. 순위상관 14 장회귀분석 1. 회귀직선의추정 2. 회귀직선의검정및추론 3. 모집단절편과회귀계수의구간추정 4. 곡선회귀 - 실습 - 상관분석 지금까지한가지확률변수에의한현상을검정하였다.
(Exposure) Exposure (Exposure Assesment) EMF Unknown to mechanism Health Effect (Effect) Unknown to mechanism Behavior pattern (Micro- Environment) Re
 Exposure (Exposure Assesment) EMF Unknown to mechanism Health Effect (Effect) Unknown to mechanism Behavior pattern (Micro- Environment) Re") EMF Health Effect 2003 10 20 21-29 2-10 - - ( ) area spot measurement - - 1 (Exposure) Exposure (Exposure Assesment) EMF Unknown to mechanism Health Effect (Effect) Unknown to mechanism Behavior pattern
EMF Health Effect 2003 10 20 21-29 2-10 - - ( ) area spot measurement - - 1 (Exposure) Exposure (Exposure Assesment) EMF Unknown to mechanism Health Effect (Effect) Unknown to mechanism Behavior pattern
슬라이드 1
 회귀분석 (Regression Analysis) 회귀분석은종속변수와독립변수들갂의관련성, 또는독립변수를 이용하여종속변수를예측하는데사용하며, 종속변수와독립변수 들의함수적관련성을이용하여분석한다. 회귀분석의목적 (1) 예측을목적 주어진독립변수를이용하여종속변수의평균값을추정할목적으로 기존의자료를이용하여회귀모형을세움 (2) 각독립변수가종속변수에미치는영향을평가 종속변수에어떤독립변수들이유의한영향을미치는지를알아보고
회귀분석 (Regression Analysis) 회귀분석은종속변수와독립변수들갂의관련성, 또는독립변수를 이용하여종속변수를예측하는데사용하며, 종속변수와독립변수 들의함수적관련성을이용하여분석한다. 회귀분석의목적 (1) 예측을목적 주어진독립변수를이용하여종속변수의평균값을추정할목적으로 기존의자료를이용하여회귀모형을세움 (2) 각독립변수가종속변수에미치는영향을평가 종속변수에어떤독립변수들이유의한영향을미치는지를알아보고
저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할
 저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할수없습니다. 변경금지. 귀하는이저작물을개작, 변형또는가공할수없습니다. 귀하는, 이저작물의재이용이나배포의경우,
저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할수없습니다. 변경금지. 귀하는이저작물을개작, 변형또는가공할수없습니다. 귀하는, 이저작물의재이용이나배포의경우,
2156년올림픽 100미터육상경기에서여성의우승기록이남성의기록보다빠른첫해로남을수있음 2156년올림픽에서 100m 우승기록은남성의경우 8.098초, 여성은 8.079초로예측 통계적오차 ( 예측구간 ) 를고려하면빠르면 2064년, 늦어도 2788년에는그렇게될것이라고주장 유사
 를고려하면빠르면 2064년, 늦어도 2788년에는그렇게될것이라고주장 유사") 회귀분석 올림픽 100m 우승기록 2004년 9월과학저널 Nature에발표된 Oxford 대학교의임상병리학자인 Andrew Tatem과그의연구진의논문 1900~2004년까지의남성과여성의육상 100m 우승기록을분석하고앞으로최고기록이어떻게변할것인지를예측 2008년베이징올림픽에서남자의우승기록은 9.73±0.144(9.586, 9.874), 여자는 10.57±0.232(10.338,
회귀분석 올림픽 100m 우승기록 2004년 9월과학저널 Nature에발표된 Oxford 대학교의임상병리학자인 Andrew Tatem과그의연구진의논문 1900~2004년까지의남성과여성의육상 100m 우승기록을분석하고앞으로최고기록이어떻게변할것인지를예측 2008년베이징올림픽에서남자의우승기록은 9.73±0.144(9.586, 9.874), 여자는 10.57±0.232(10.338,
PowerPoint 프레젠테이션
 응용식물통계학 Statistics of Applied Plants Science 친환경식물학부유기농생태학전공황선구 14 장회귀분석 1. 회귀직선의추정 2. 회귀직선의검정및추론 3. 모집단절편과회귀계수의구간추정 4. 곡선회귀 15 장공분산분석 1. 공분산분석의통계적모형 2. 공분산분석에의한처리효과검정 3. 공분산분석과정 - 실습 - 회귀분석 두확률변수간에관계가있는지검정
응용식물통계학 Statistics of Applied Plants Science 친환경식물학부유기농생태학전공황선구 14 장회귀분석 1. 회귀직선의추정 2. 회귀직선의검정및추론 3. 모집단절편과회귀계수의구간추정 4. 곡선회귀 15 장공분산분석 1. 공분산분석의통계적모형 2. 공분산분석에의한처리효과검정 3. 공분산분석과정 - 실습 - 회귀분석 두확률변수간에관계가있는지검정
Jeeshim & KUCC625 (08/04/2009) Statistical Data Analysis Using R:22 6. 집단간평균비교 집단간평균을비교하는것은기본방법이다. 따라서비교할변수는평균을계산할수있어야하고, 의미있게해석할수있어야한다. 두집단
 Statistical Data Analysis Using R:22 6. 집단간평균비교 집단간평균을비교하는것은기본방법이다. 따라서비교할변수는평균을계산할수있어야하고, 의미있게해석할수있어야한다. 두집단") 2008-2009 Jeeshim & KUCC625 (08/04/2009) Statistical Data Analysis Using R:22 6. 집단간평균비교 집단간평균을비교하는것은기본방법이다. 따라서비교할변수는평균을계산할수있어야하고, 의미있게해석할수있어야한다. 두집단을비교하는것은 T-test 로, 두집단이상이라면 ANOVA 를사용한다. 그림 6.1 은 T-test
2008-2009 Jeeshim & KUCC625 (08/04/2009) Statistical Data Analysis Using R:22 6. 집단간평균비교 집단간평균을비교하는것은기본방법이다. 따라서비교할변수는평균을계산할수있어야하고, 의미있게해석할수있어야한다. 두집단을비교하는것은 T-test 로, 두집단이상이라면 ANOVA 를사용한다. 그림 6.1 은 T-test
PowerPoint Presentation
 09 th Week Correlation Analysis 상관관계분석 Jongseok Lee Business Administration Hallym University 변수형태와통계적분석방법 H 0 : X ㅗ Y H 1 : X ~ Y X Categorical Y Categorical Chi-square Test X Categorical Y Numerical
09 th Week Correlation Analysis 상관관계분석 Jongseok Lee Business Administration Hallym University 변수형태와통계적분석방법 H 0 : X ㅗ Y H 1 : X ~ Y X Categorical Y Categorical Chi-square Test X Categorical Y Numerical
제장 2 비모수 검정(NONPARAMETRIC ANALYSIS) ③ 연구자는 SPSS 출력결과에서 유의확률을 확인하여 귀무가설(H0 )의 기각, 채택 여부를 결정한다. 예를 들어 연구자가 연구자료의 정규성을 검정하기 위하여 유 의수준을 α = 0.05로 설정하고 SPS
 ③ 연구자는 SPSS 출력결과에서 유의확률을 확인하여 귀무가설(H0 )의 기각, 채택 여부를 결정한다. 예를 들어 연구자가 연구자료의 정규성을 검정하기 위하여 유 의수준을 α = 0.05로 설정하고 SPS") 제장 비모수 검정(nonparametric analysis) 모집단의 분포를 알 수 없거나 모집단이 정규분포를 따른다고 가정할 수 없는 경우에는 모수적 검정을 사용할 수 없다. 이 경우에 자료의 부호나 순위로 가설 검정을 실시하며 이러한 검정 방법을 비모수 검정이라고 한다. 제절 적합도 검정(goodness of fit test) 주어진 자료가 어떠한 통계적
제장 비모수 검정(nonparametric analysis) 모집단의 분포를 알 수 없거나 모집단이 정규분포를 따른다고 가정할 수 없는 경우에는 모수적 검정을 사용할 수 없다. 이 경우에 자료의 부호나 순위로 가설 검정을 실시하며 이러한 검정 방법을 비모수 검정이라고 한다. 제절 적합도 검정(goodness of fit test) 주어진 자료가 어떠한 통계적
4 CD Construct Special Model VI 2 nd Order Model VI 2 Note: Hands-on 1, 2 RC 1 RLC mass-spring-damper 2 2 ζ ω n (rad/sec) 2 ( ζ < 1), 1 (ζ = 1), ( ) 1
 2 ( ζ < 1), 1 (ζ = 1), ( ) 1") : LabVIEW Control Design, Simulation, & System Identification LabVIEW Control Design Toolkit, Simulation Module, System Identification Toolkit 2 (RLC Spring-Mass-Damper) Control Design toolkit LabVIEW
: LabVIEW Control Design, Simulation, & System Identification LabVIEW Control Design Toolkit, Simulation Module, System Identification Toolkit 2 (RLC Spring-Mass-Damper) Control Design toolkit LabVIEW
한국성인에서초기황반변성질환과 연관된위험요인연구
 한국성인에서초기황반변성질환과 연관된위험요인연구 한국성인에서초기황반변성질환과 연관된위험요인연구 - - i - - i - - ii - - iii - - iv - χ - v - - vi - - 1 - - 2 - - 3 - - 4 - 그림 1. 연구대상자선정도표 - 5 - - 6 - - 7 - - 8 - 그림 2. 연구의틀 χ - 9 - - 10 - - 11 -
한국성인에서초기황반변성질환과 연관된위험요인연구 한국성인에서초기황반변성질환과 연관된위험요인연구 - - i - - i - - ii - - iii - - iv - χ - v - - vi - - 1 - - 2 - - 3 - - 4 - 그림 1. 연구대상자선정도표 - 5 - - 6 - - 7 - - 8 - 그림 2. 연구의틀 χ - 9 - - 10 - - 11 -
R
 R 과데이터분석 상관관계 양창모 청주교육대학교컴퓨터교육과 2015 년여름 양창모 ( 청주교육대학교컴퓨터교육과 ) Data Analysis using R 2015 년여름 1 / 20 상관관계 양적변수quantitative variables 사이의관계relationships를나타내기위하여상관계수correlation coefficients를사용한다. ± 기호를사용하여관계의방향을나타낸다.
R 과데이터분석 상관관계 양창모 청주교육대학교컴퓨터교육과 2015 년여름 양창모 ( 청주교육대학교컴퓨터교육과 ) Data Analysis using R 2015 년여름 1 / 20 상관관계 양적변수quantitative variables 사이의관계relationships를나타내기위하여상관계수correlation coefficients를사용한다. ± 기호를사용하여관계의방향을나타낸다.
제 1 부 연구 개요
 2 출 문 차 1 부 과업의 개요 25 귀하 1 장 과업의 목적 27 1. 과업의 목적 및 목표 27 보고서를 2012년도 한돈자조금 성과분석 및 향후 사업방향 수립에 관한 연구 용역의 최종보고서로 제출합니다. 2013년 2월 제 2 장 주요 과업 내용 29 1. 과업 진행 과정 29 2. 과정별 수행 방법 30 가. 한돈자조금사업의 경제적 성과분석 30 나.
2 출 문 차 1 부 과업의 개요 25 귀하 1 장 과업의 목적 27 1. 과업의 목적 및 목표 27 보고서를 2012년도 한돈자조금 성과분석 및 향후 사업방향 수립에 관한 연구 용역의 최종보고서로 제출합니다. 2013년 2월 제 2 장 주요 과업 내용 29 1. 과업 진행 과정 29 2. 과정별 수행 방법 30 가. 한돈자조금사업의 경제적 성과분석 30 나.
모수검정과비모수검정 제 6 강 지리통계학
 모수검정과비모수검정 제 6 강 지리통계학 통계적추정의목적 연구자가주장하는연구가설을입증하기위한것 1 연구목적에맞는연구가설을설정 2 연구목적과수집된자료에부합되는적절한통계적검정방법을선택 3 귀무가설과연구가설 ( 대립가설 ) 을진술 4 유의수준을결정한후각분포유형에따라분포표를이용하여임계치를구하고기각역을설정 5 통계적검정유형에필요한통계량을각검정유형의공식을이용하여계산 6
모수검정과비모수검정 제 6 강 지리통계학 통계적추정의목적 연구자가주장하는연구가설을입증하기위한것 1 연구목적에맞는연구가설을설정 2 연구목적과수집된자료에부합되는적절한통계적검정방법을선택 3 귀무가설과연구가설 ( 대립가설 ) 을진술 4 유의수준을결정한후각분포유형에따라분포표를이용하여임계치를구하고기각역을설정 5 통계적검정유형에필요한통계량을각검정유형의공식을이용하여계산 6
저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할
 저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할수없습니다. 변경금지. 귀하는이저작물을개작, 변형또는가공할수없습니다. 귀하는, 이저작물의재이용이나배포의경우,
저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할수없습니다. 변경금지. 귀하는이저작물을개작, 변형또는가공할수없습니다. 귀하는, 이저작물의재이용이나배포의경우,
생존분석의 추정과 비교 : 보충자료 이용희 December 12, 2018 Contents 1 생존함수와 위험함수 생존함수와 위험함수 예제: 지수분포
 생존분석의 추정과 비교 : 보충자료 이용희 December, 8 Cotets 생존함수와 위험함수. 생존함수와 위험함수....................................... 예제: 지수분포.......................................... 예제: 와이블분포.........................................
생존분석의 추정과 비교 : 보충자료 이용희 December, 8 Cotets 생존함수와 위험함수. 생존함수와 위험함수....................................... 예제: 지수분포.......................................... 예제: 와이블분포.........................................
이다. 즉 μ μ μ : 가아니다. 이러한검정을하기위하여분산분석은다음과같은가정을두고있다. 분산분석의가정 (1) r개모집단분포는모두정규분포를이루고있다. (2) r개모집단의평균은다를수있으나분산은모두같다. (3) r개모집단에서추출한표본은서로독립적이다. 분산분석은집단을구분하는
 r개모집단분포는모두정규분포를이루고있다. (2) r개모집단의평균은다를수있으나분산은모두같다. (3) r개모집단에서추출한표본은서로독립적이다. 분산분석은집단을구분하는") 제 12 강분산분석 분산분석 (ANOVA) (1) 1. 개요 비교하는집단의수가 3개이상일경우에사용되는통계기법이분산분석이다. 두표본 t검증에서는문제의단순성때문에야기되지않는문제들이다수의표본으로확대됨에따라문제들이야기되기도한다. 다음과같은 r개의모집단이있다고가정하자..... ~ N( μ σ ) ~ N( μ σ ).... ~ N ( μ σ )...... 위의그림과같이여러번에걸쳐두표본의
제 12 강분산분석 분산분석 (ANOVA) (1) 1. 개요 비교하는집단의수가 3개이상일경우에사용되는통계기법이분산분석이다. 두표본 t검증에서는문제의단순성때문에야기되지않는문제들이다수의표본으로확대됨에따라문제들이야기되기도한다. 다음과같은 r개의모집단이있다고가정하자..... ~ N( μ σ ) ~ N( μ σ ).... ~ N ( μ σ )...... 위의그림과같이여러번에걸쳐두표본의
보고서(겉표지).PDF
.PDF") 11-13 10148-000092- 01 200 1 04 ( ) 2 0 0 1 ( ) E fficient Rules for Oper atin g the Det en tion B asin an d P umpin g St ation ( ) 2 0 0 1. 12 1 2 11-1310148- 000092-01 ( ) E fficien t Ru les for Oper
11-13 10148-000092- 01 200 1 04 ( ) 2 0 0 1 ( ) E fficient Rules for Oper atin g the Det en tion B asin an d P umpin g St ation ( ) 2 0 0 1. 12 1 2 11-1310148- 000092-01 ( ) E fficien t Ru les for Oper
Microsoft Word - multiple
 Chapter 3. Multiple Liear Regressio Data structure ad the model yi 0 1xi1 pxip i, i1,, (Y X ),,, : idepedet with E( ) 0 ad 1 : ukow 0, 1,, p, 0 1 i var( i ) X (1, x,, xp), rak( X) p1, X : give where xj
Chapter 3. Multiple Liear Regressio Data structure ad the model yi 0 1xi1 pxip i, i1,, (Y X ),,, : idepedet with E( ) 0 ad 1 : ukow 0, 1,, p, 0 1 i var( i ) X (1, x,, xp), rak( X) p1, X : give where xj
untitled
 5.8 PROC UNIVARIATE (hitogram, tem and leaf plot, box-whiker plot), (p- ). Univariate( ).. NORMAL (Shapiro- Wilk Kolmogorov-Smirno D- OUTPUT( SAS ). PROC MEANS PROC MEANS. (moment) E( X ). k Sehyug Kwon,
5.8 PROC UNIVARIATE (hitogram, tem and leaf plot, box-whiker plot), (p- ). Univariate( ).. NORMAL (Shapiro- Wilk Kolmogorov-Smirno D- OUTPUT( SAS ). PROC MEANS PROC MEANS. (moment) E( X ). k Sehyug Kwon,
슬라이드 1
 빅데이터분석을위한데이터마이닝방법론 SAS Enterprise Miner 활용사례를중심으로 9 주차 예측모형에대한평가 Assessment of Predictive Model 최종후, 강현철 차례 6. 모형평가의기본개념 6.2 모델비교 (Model Comparison) 노드 6.3 임계치 (Cutoff) 노드 6.4 의사결정 (Decisions) 노드 6.5 기타모형화노드들
빅데이터분석을위한데이터마이닝방법론 SAS Enterprise Miner 활용사례를중심으로 9 주차 예측모형에대한평가 Assessment of Predictive Model 최종후, 강현철 차례 6. 모형평가의기본개념 6.2 모델비교 (Model Comparison) 노드 6.3 임계치 (Cutoff) 노드 6.4 의사결정 (Decisions) 노드 6.5 기타모형화노드들
슬라이드 1
 빅데이터분석을위한데이터마이닝방법론 SAS Enterprise Miner 활용사례를중심으로 제 4 장 회귀분석 Chapter 4 Regression Analysis 차례 4.1 선형회귀분석 (Linear Regression Analysis) 4.2 로지스틱회귀분석 (Logistic Regression Analysis) 4.3 회귀분석의특징과제약 4.4 분석사례
빅데이터분석을위한데이터마이닝방법론 SAS Enterprise Miner 활용사례를중심으로 제 4 장 회귀분석 Chapter 4 Regression Analysis 차례 4.1 선형회귀분석 (Linear Regression Analysis) 4.2 로지스틱회귀분석 (Logistic Regression Analysis) 4.3 회귀분석의특징과제약 4.4 분석사례
 Abstract Musculoskeletal Symptoms and Related Factors for Nurses and Radiological Technologists Wearing a Lead Apron for Radiation Pro t e c t i o n Jung-Im Yoo, Jung-Wan Koo 1 ) Angio Unit, Team of Radiology,
Abstract Musculoskeletal Symptoms and Related Factors for Nurses and Radiological Technologists Wearing a Lead Apron for Radiation Pro t e c t i o n Jung-Im Yoo, Jung-Wan Koo 1 ) Angio Unit, Team of Radiology,
의학연구자료의 생존분석
 의학연구자료의생존분석 김호 서울대학교보건대학원 모집단과표본 모집단 모수 표본 추정치 Y,, 1 Yn 2 N(, ) 1 n Y Y i n i 1 n 2 1 2 ( i ) n 1 i 1 S Y Y 모수 : 가정한모형의통계적성질을완전히결정하는상수 ( 들 ) Y=a+b x 2 N(, ) 1 ( x ) exp 2 2 2 2 Y1, Y2, Yn 2 Yn, Sn 관심모수
의학연구자료의생존분석 김호 서울대학교보건대학원 모집단과표본 모집단 모수 표본 추정치 Y,, 1 Yn 2 N(, ) 1 n Y Y i n i 1 n 2 1 2 ( i ) n 1 i 1 S Y Y 모수 : 가정한모형의통계적성질을완전히결정하는상수 ( 들 ) Y=a+b x 2 N(, ) 1 ( x ) exp 2 2 2 2 Y1, Y2, Yn 2 Yn, Sn 관심모수
제 1 절 two way ANOVA 제1절 1 two way ANOVA 두 요인(factor)의 각 요인의 평균비교와 교호작용(interaction)을 검정하는 것을 이 원배치 분산분석(two way ANalysis Of VAriance; two way ANOVA)이라
의 각 요인의 평균비교와 교호작용(interaction)을 검정하는 것을 이 원배치 분산분석(two way ANalysis Of VAriance; two way ANOVA)이라") 제 절 two way ANOVA 제절 two way ANOVA 두 요인(factor)의 각 요인의 평균비교와 교호작용(interaction)을 검정하는 것을 이 원배치 분산분석(two way ANalysis Of VAriance; two way ANOVA)이라고 한다. 교호작용은 두 변수의 곱에 대한 검정으로 유의확률이 의미있는 결과라면 두 변수는 서로 영향을
제 절 two way ANOVA 제절 two way ANOVA 두 요인(factor)의 각 요인의 평균비교와 교호작용(interaction)을 검정하는 것을 이 원배치 분산분석(two way ANalysis Of VAriance; two way ANOVA)이라고 한다. 교호작용은 두 변수의 곱에 대한 검정으로 유의확률이 의미있는 결과라면 두 변수는 서로 영향을
ASETAOOOCRKG.hwp
 청년층 희망 일자리와 실제 취업 일자리 격차 분석 - 고학력 청년 실업 원인에 대한 일고찰 - 홍 성 민 * ** 박 진 희 세계적인 경기침체가 본격화되는 2009년에는 실업문제가 가장 큰 사회경제적 이슈로 등장할 가 능성이 높으며, 특히 청년층의 고실업 문제와 더불어 일자리 기피 인해 나타날 가능성이 있는 NEET 화 현상에 대한 우려가 커질 것으로 예상된다.
청년층 희망 일자리와 실제 취업 일자리 격차 분석 - 고학력 청년 실업 원인에 대한 일고찰 - 홍 성 민 * ** 박 진 희 세계적인 경기침체가 본격화되는 2009년에는 실업문제가 가장 큰 사회경제적 이슈로 등장할 가 능성이 높으며, 특히 청년층의 고실업 문제와 더불어 일자리 기피 인해 나타날 가능성이 있는 NEET 화 현상에 대한 우려가 커질 것으로 예상된다.
제 4 장회귀분석
 회귀의역사적유래 (historical origin of the regression) 회귀 (regression) 라는용어는유전학자 Francis Galton(1886) 에의해처음사용된데서유래함. 그의논문에서 비정상적으로크거나작은부모의아이들키는전체인구의평균신장을향해움직이거나회귀 (regression) 하는경향이있다. 고주장 회귀의역사적유래 (historical
회귀의역사적유래 (historical origin of the regression) 회귀 (regression) 라는용어는유전학자 Francis Galton(1886) 에의해처음사용된데서유래함. 그의논문에서 비정상적으로크거나작은부모의아이들키는전체인구의평균신장을향해움직이거나회귀 (regression) 하는경향이있다. 고주장 회귀의역사적유래 (historical
 저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할수없습니다. 변경금지. 귀하는이저작물을개작, 변형또는가공할수없습니다. 귀하는, 이저작물의재이용이나배포의경우,
저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할수없습니다. 변경금지. 귀하는이저작물을개작, 변형또는가공할수없습니다. 귀하는, 이저작물의재이용이나배포의경우,
Microsoft PowerPoint - chap_11_rep.ppt [호환 모드]
![Microsoft PowerPoint - chap_11_rep.ppt [호환 모드]](/thumbs/91/105158542.jpg "Microsoft PowerPoint - chap_11_rep.ppt [호환 모드]") 제 11 강 111 자기상관 Autocorrelation 자기상관의본질 11 유효성 (efficiency, accurate estimation/prediction) 을위해서는모든체계적인정보가회귀모형에체화되어있어야함 표본의무작위성 (randomness) 은서로다른관측치들에대한오차항들이상관되어있지말아야함을의미함 자기상관 (Autocorrelation) 은이러한표본의무작위성을위반하게만드는오차항에있는체계적패턴임
제 11 강 111 자기상관 Autocorrelation 자기상관의본질 11 유효성 (efficiency, accurate estimation/prediction) 을위해서는모든체계적인정보가회귀모형에체화되어있어야함 표본의무작위성 (randomness) 은서로다른관측치들에대한오차항들이상관되어있지말아야함을의미함 자기상관 (Autocorrelation) 은이러한표본의무작위성을위반하게만드는오차항에있는체계적패턴임
(000-000)실험계획법-머리말 ok
실험계획법-머리말 ok") iii Design Analysis Optimization Design Expert Minitab Minitab Design Expert iv 2008 1 v 1 1. 1 2 1. 2 4 1. 3 6 1. 4 8 1. 5 12 2 2. 1 16 2. 2 17 2. 3 20 2. 4 27 2. 5 30 2. 6 33 2. 7 37 2. 8 42 46 3 3.
iii Design Analysis Optimization Design Expert Minitab Minitab Design Expert iv 2008 1 v 1 1. 1 2 1. 2 4 1. 3 6 1. 4 8 1. 5 12 2 2. 1 16 2. 2 17 2. 3 20 2. 4 27 2. 5 30 2. 6 33 2. 7 37 2. 8 42 46 3 3.
전립선암발생률추정과관련요인분석 : The Korean Cancer Prevention Study-II (KCPS-II)
") 전립선암발생률추정과관련요인분석 : The Korean Cancer Prevention Study-II (KCPS-II) 전립선암발생률추정과관련요인분석 : The Korean Cancer Prevention Study-II (KCPS-II) - i - - ii - - iii - - iv - - v - - vi - - vii - - viii - - ix - -
전립선암발생률추정과관련요인분석 : The Korean Cancer Prevention Study-II (KCPS-II) 전립선암발생률추정과관련요인분석 : The Korean Cancer Prevention Study-II (KCPS-II) - i - - ii - - iii - - iv - - v - - vi - - vii - - viii - - ix - -
자료분석론 - 국민건강영양조사 분석
 2014. 5. 10 ( 토 ) 자료분석론 국민건강영양조사자료 - 자료분석 (2) 서울대학교보건대학원 홍지민 강의순서 1) 국민건강영양조사이해 (4/19) - 자료의개요및원시자료 DB 2) 가중치및자료분석개요 (4/26) 3) 국민건강영양조사자료활용실습 (5/10) 2014-05-10 2 목차 자료분석개요 복합표본설계자료회귀분석 복합표본설계자료로지스틱회귀분석
2014. 5. 10 ( 토 ) 자료분석론 국민건강영양조사자료 - 자료분석 (2) 서울대학교보건대학원 홍지민 강의순서 1) 국민건강영양조사이해 (4/19) - 자료의개요및원시자료 DB 2) 가중치및자료분석개요 (4/26) 3) 국민건강영양조사자료활용실습 (5/10) 2014-05-10 2 목차 자료분석개요 복합표본설계자료회귀분석 복합표본설계자료로지스틱회귀분석
슬라이드 1
 Principles of Econometrics (3e) 013 년 1 학기 윤성민 10.0 서론 The assumptions of the simple linear regression are: SR1. SR. yi =β 1 +β xi + ei i= 1,, N Ee ( i ) = 0 SR3. var( e i ) = σ SR4. cov( e, e ) = 0 i
Principles of Econometrics (3e) 013 년 1 학기 윤성민 10.0 서론 The assumptions of the simple linear regression are: SR1. SR. yi =β 1 +β xi + ei i= 1,, N Ee ( i ) = 0 SR3. var( e i ) = σ SR4. cov( e, e ) = 0 i
서론 34 2
 34 2 Journal of the Korean Society of Health Information and Health Statistics Volume 34, Number 2, 2009, pp. 165 176 165 진은희 A Study on Health related Action Rates of Dietary Guidelines and Pattern of
34 2 Journal of the Korean Society of Health Information and Health Statistics Volume 34, Number 2, 2009, pp. 165 176 165 진은희 A Study on Health related Action Rates of Dietary Guidelines and Pattern of
<C0C7B7E1B1E2B1E2C0D3BBF3BDC3C7E8B0E8C8B9BCADC0DBBCBAC0BBC0A7C7D1B1E6B6F3C0E2C0CC28C4A1C1D6C1B6C1F7C0E7BBFDC0AFB5B5C0E7295F20BCF6C1A43130303532352E687770>
 의료기기 임상시험계획서 작성을 위한 길라잡이 No.8 의료기기 임상시험계획서 작성을 위한 길라잡이 치주조직재생유도재 2010. 5. 1. 의료기기 임상시험 관련법규 (1) 의료기기법 제10조 (임상시험계획의 승인 등) (2) 시행규칙 제7조 (기술문서 등의 심사) 제12조 (임상시험계획승인 등) 제13조 (임상시험실시기준 등) (3) 고시 의료기기임상시험계획승인지침
의료기기 임상시험계획서 작성을 위한 길라잡이 No.8 의료기기 임상시험계획서 작성을 위한 길라잡이 치주조직재생유도재 2010. 5. 1. 의료기기 임상시험 관련법규 (1) 의료기기법 제10조 (임상시험계획의 승인 등) (2) 시행규칙 제7조 (기술문서 등의 심사) 제12조 (임상시험계획승인 등) 제13조 (임상시험실시기준 등) (3) 고시 의료기기임상시험계획승인지침
Chapter 7 분산분석
 Chapter 8 실험계획및분산분석 (Experimental Design & ANalysis Of VAariance, ANOVA) 2017/5/01 8.1 선형모형과분산분석 (Linear Model & Analysis of Variance) 선형모형 (linear model): 설명변수들의선형의선형결합의형태로반응변수를설명하고자함. (to explain the
Chapter 8 실험계획및분산분석 (Experimental Design & ANalysis Of VAariance, ANOVA) 2017/5/01 8.1 선형모형과분산분석 (Linear Model & Analysis of Variance) 선형모형 (linear model): 설명변수들의선형의선형결합의형태로반응변수를설명하고자함. (to explain the
통계분석가이드라인 통계 (Statisitcs) 란? Second Language in Science 전남대학교치의학전문대학원임회정 1 2 모집단 (Population) 과표본 (Sample) 통계분석단계 Sampling 추정 1. 귀무가설수립 2.
 란? Second Language in Science 전남대학교치의학전문대학원임회정 1 2 모집단 (Population) 과표본 (Sample) 통계분석단계 Sampling 추정 1. 귀무가설수립 2.") 통계분석가이드라인 통계 (Statisitcs) 란? Second Language in Science 전남대학교치의학전문대학원임회정 1 2 모집단 (Population) 과표본 (Sample) 통계분석단계 Sampling 추정 1. 귀무가설수립 2. 검정통계량계산 ( 어떤검정을실시할것인가를결정 ) 3. 귀무가설을기각? 채택? (p 값으로결정 - 유의수준 0.05
통계분석가이드라인 통계 (Statisitcs) 란? Second Language in Science 전남대학교치의학전문대학원임회정 1 2 모집단 (Population) 과표본 (Sample) 통계분석단계 Sampling 추정 1. 귀무가설수립 2. 검정통계량계산 ( 어떤검정을실시할것인가를결정 ) 3. 귀무가설을기각? 채택? (p 값으로결정 - 유의수준 0.05
<313630313032C6AFC1FD28B1C7C7F5C1DF292E687770>
 양성자가속기연구센터 양성자가속기 개발 및 운영현황 DOI: 10.3938/PhiT.25.001 권혁중 김한성 Development and Operational Status of the Proton Linear Accelerator at the KOMAC Hyeok-Jung KWON and Han-Sung KIM A 100-MeV proton linear accelerator
양성자가속기연구센터 양성자가속기 개발 및 운영현황 DOI: 10.3938/PhiT.25.001 권혁중 김한성 Development and Operational Status of the Proton Linear Accelerator at the KOMAC Hyeok-Jung KWON and Han-Sung KIM A 100-MeV proton linear accelerator
슬라이드 1
 Principles of Economerics (3e) Ch. 4 예측, 적합도, 모형화 013 년 1 학기 윤성민 4.1 OLS 예측 (1) 점예측 x0 y0 - 설명변수일때, 종속변수의값을예측하고자함 y ˆ = b + 0 1 b x 0 Ch. 4 예측, 적합도, 모형화 /60 4.1 OLS 예측 예측오차 (forecas error), f 예측오차의기대값
Principles of Economerics (3e) Ch. 4 예측, 적합도, 모형화 013 년 1 학기 윤성민 4.1 OLS 예측 (1) 점예측 x0 y0 - 설명변수일때, 종속변수의값을예측하고자함 y ˆ = b + 0 1 b x 0 Ch. 4 예측, 적합도, 모형화 /60 4.1 OLS 예측 예측오차 (forecas error), f 예측오차의기대값
PowerPoint 프레젠테이션
 Independence tests using coin package in R Jinheum Kim(Univ. Suwon), Jungdong Lee(Univ. Suwon, Master student) 2014.11.14 OUTLINE Permutation test: review Introduce 15 built-in functions in coin package
Independence tests using coin package in R Jinheum Kim(Univ. Suwon), Jungdong Lee(Univ. Suwon, Master student) 2014.11.14 OUTLINE Permutation test: review Introduce 15 built-in functions in coin package
슬라이드 1
 Principles of Econometrics (3e) Ch. 6 다중회귀모형에관한 추가적인논의 013 년 1 학기 윤성민 6장의주요내용 다중회귀모형의모수에관한둘이상의가설로구성된귀무가설을동시에검정하는경우 ( 결합가설의검정 ) F-검정 표본의정보이외에비표본정보도함께이용하는경우 제한최소제곱법 모형설정의오류를찾는방법 RESET 검정 다중공선성문제의탐지와해결방법
Principles of Econometrics (3e) Ch. 6 다중회귀모형에관한 추가적인논의 013 년 1 학기 윤성민 6장의주요내용 다중회귀모형의모수에관한둘이상의가설로구성된귀무가설을동시에검정하는경우 ( 결합가설의검정 ) F-검정 표본의정보이외에비표본정보도함께이용하는경우 제한최소제곱법 모형설정의오류를찾는방법 RESET 검정 다중공선성문제의탐지와해결방법
 연구보고서 2009-05 일반화선형모형 (GLM) 을이용한 자동차보험요율상대도산출방법연구 Ⅰ. 요율상대도산출시일반화선형모형활용방법 1. 일반화선형모형 2 연구보고서 2009-05 2. 일반화선형모형의자동차보험요율산출에적용방법 요약 3 4 연구보고서 2009-05 Ⅱ. 일반화선형모형을이용한실증분석 1. 모형적용기준 < > = 요약 5 2. 통계자료및통계모형
연구보고서 2009-05 일반화선형모형 (GLM) 을이용한 자동차보험요율상대도산출방법연구 Ⅰ. 요율상대도산출시일반화선형모형활용방법 1. 일반화선형모형 2 연구보고서 2009-05 2. 일반화선형모형의자동차보험요율산출에적용방법 요약 3 4 연구보고서 2009-05 Ⅱ. 일반화선형모형을이용한실증분석 1. 모형적용기준 < > = 요약 5 2. 통계자료및통계모형
cha4_ocw.hwp
 제 4장 확률 우리는 일상생활에서 확률이라는 용어를 많이 접하게 된다. 확률(probability)는 한자어로 확실할 확( 確 ), 비율 률( 率 )로 해석된다. 로또당첨확률, 야구 한국시리즈에서 특정 팀이 우승 할 확률, 흡연자가 폐암에 걸릴 확률, 집값이 오를 확률 등 수없이 많은 확률들이 현대생활 에서 사용되어지고 있다. 대부분의 일간신문에는 기상예보
제 4장 확률 우리는 일상생활에서 확률이라는 용어를 많이 접하게 된다. 확률(probability)는 한자어로 확실할 확( 確 ), 비율 률( 率 )로 해석된다. 로또당첨확률, 야구 한국시리즈에서 특정 팀이 우승 할 확률, 흡연자가 폐암에 걸릴 확률, 집값이 오를 확률 등 수없이 많은 확률들이 현대생활 에서 사용되어지고 있다. 대부분의 일간신문에는 기상예보
012임수진
 Received : 2012. 11. 27 Reviewed : 2012. 12. 10 Accepted : 2012. 12. 12 A Clinical Study on Effect of Electro-acupuncture Treatment for Low Back Pain and Radicular Pain in Patients Diagnosed with Lumbar
Received : 2012. 11. 27 Reviewed : 2012. 12. 10 Accepted : 2012. 12. 12 A Clinical Study on Effect of Electro-acupuncture Treatment for Low Back Pain and Radicular Pain in Patients Diagnosed with Lumbar
<4D F736F F F696E74202D20BBF3B0FCBAD0BCAE5FC0CCB7D0B0ADC0C72E BC0D0B1E220C0FCBFEB5D>
 상관분석 (Correlation) 목차 1. 상관분석은? 2. 분산, 공분산, 상관 3. 상관계수 4. 상관분석해석의유의점 5. 상관분석실제 상관분석은? 상관관계는서열척도, 등간척도, 비율척도로측정된변수들간의관련성정도를알아보기위한것 하나의변수가다른변수와의어느정도밀접한관련성을갖고변화하는가를알아보기위해사용 두변수간의관련성을구할경우단순상관관계를실시하며, 부분또는편상관관계는어떤변수를통제한상태에서두변수의상관관계를구하는것
상관분석 (Correlation) 목차 1. 상관분석은? 2. 분산, 공분산, 상관 3. 상관계수 4. 상관분석해석의유의점 5. 상관분석실제 상관분석은? 상관관계는서열척도, 등간척도, 비율척도로측정된변수들간의관련성정도를알아보기위한것 하나의변수가다른변수와의어느정도밀접한관련성을갖고변화하는가를알아보기위해사용 두변수간의관련성을구할경우단순상관관계를실시하며, 부분또는편상관관계는어떤변수를통제한상태에서두변수의상관관계를구하는것
<4D F736F F F696E74202D20C0D3BBF3BFACB1B8BFA120C7CABFE4C7D120C5EBB0E820BAD0BCAE F >
 임상연구에필요한통계분석 () - 범주형자료에대한분석 - 순천향대중앙의료원의학통계상담실이지성 totoro96@schmc.ac.kr Introduction Categorical data: 그변수가가질수있는값이명목형 (nomial) 척도또는순위형 (ordinal) 척도인경우 명목형척도 : 혈액형 (A,B,AB,O), 성별 ( 남, 여 ) 처럼그값들이서로다르다는것을표현함.
임상연구에필요한통계분석 () - 범주형자료에대한분석 - 순천향대중앙의료원의학통계상담실이지성 totoro96@schmc.ac.kr Introduction Categorical data: 그변수가가질수있는값이명목형 (nomial) 척도또는순위형 (ordinal) 척도인경우 명목형척도 : 혈액형 (A,B,AB,O), 성별 ( 남, 여 ) 처럼그값들이서로다르다는것을표현함.
<352E20BAAFBCF6BCB1C5C320B1E2B9FDC0BB20C0CCBFEBC7D120C7D1B1B920C7C1B7CEBEDFB1B8C0C720B5E6C1A1B0FA20BDC7C1A120BCB3B8ED28313531323231292D2DB1E8C7F5C1D62E687770>
 통계연구(2015), 제20권 제3호, 71-92 변수선택 기법을 이용한 한국 프로야구의 득점과 실점 설명 1) 김혁주 2) 김예형 3) 요약 한국 프로야구에서 팀들의 득점과 실점에 영향을 미치는 요인들을 규명하기 위한 연구를 하였 다. 2007년부터 2014년까지의 정규리그 전 경기 자료를 대상으로 분석하였다. 전방선택법, 후방 소거법, 단계별 회귀법, 선택법,
통계연구(2015), 제20권 제3호, 71-92 변수선택 기법을 이용한 한국 프로야구의 득점과 실점 설명 1) 김혁주 2) 김예형 3) 요약 한국 프로야구에서 팀들의 득점과 실점에 영향을 미치는 요인들을 규명하기 위한 연구를 하였 다. 2007년부터 2014년까지의 정규리그 전 경기 자료를 대상으로 분석하였다. 전방선택법, 후방 소거법, 단계별 회귀법, 선택법,
저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할
 저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할수없습니다. 변경금지. 귀하는이저작물을개작, 변형또는가공할수없습니다. 귀하는, 이저작물의재이용이나배포의경우,
저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할수없습니다. 변경금지. 귀하는이저작물을개작, 변형또는가공할수없습니다. 귀하는, 이저작물의재이용이나배포의경우,
Abstract Background : Most hospitalized children will experience physical pain as well as psychological distress. Painful procedure can increase anxie
 Volume 12, Number 1, 92~102, An Intervention Study of Pain Reduction during IV Therapy in Hospitalized Children Myo-Jin Kim 1), Joung-Hae Bak 1), Won-Seok Seo 2) Mi-Young Kim 3), Sun-Kyoung Park 3), Jai-Soung
Volume 12, Number 1, 92~102, An Intervention Study of Pain Reduction during IV Therapy in Hospitalized Children Myo-Jin Kim 1), Joung-Hae Bak 1), Won-Seok Seo 2) Mi-Young Kim 3), Sun-Kyoung Park 3), Jai-Soung
02¿ÀÇö¹Ì(5~493s
 Korean Journal of Remote Sensing, Vol.22, No.6, 2006, pp.485~493 Estimation of Quantitative Precipitation Rate Using an Optimal Weighting Method with RADAR Estimated Rainrate and AWS Rainrate Hyun-Mi Oh,
Korean Journal of Remote Sensing, Vol.22, No.6, 2006, pp.485~493 Estimation of Quantitative Precipitation Rate Using an Optimal Weighting Method with RADAR Estimated Rainrate and AWS Rainrate Hyun-Mi Oh,
Microsoft PowerPoint - ANOVA pptx
 분산분석개념및기초 인과관계 casual relationship X=>Y Y 종속변수, 반응변수, 내생변수 X 설명변수, 독립변수, 요인 ( 처리효과 ), 내생변수 X 측정형 Y 범주형 로지스틱회귀분석 측정형 회귀분석 범주형교차분석분산분석 DOE Design of Experiment ( 실험설계 ) 관심대상에대한정보를얻기위한계획된테스트나관측 절대실험 absolute
분산분석개념및기초 인과관계 casual relationship X=>Y Y 종속변수, 반응변수, 내생변수 X 설명변수, 독립변수, 요인 ( 처리효과 ), 내생변수 X 측정형 Y 범주형 로지스틱회귀분석 측정형 회귀분석 범주형교차분석분산분석 DOE Design of Experiment ( 실험설계 ) 관심대상에대한정보를얻기위한계획된테스트나관측 절대실험 absolute
untitled
 Six Sigma - - Grouping Brainstorming : Observ. 8 - - 22 27 32 37 5 5 Capability -27.7552 63.7552 22 Capability 3.SL=69.82 X=29.73-3.SL=-.35 3.SL=49.24 R=5.7-2.29 7.7578-3.SL=.E+ 22 Data Source: Time Span:
Six Sigma - - Grouping Brainstorming : Observ. 8 - - 22 27 32 37 5 5 Capability -27.7552 63.7552 22 Capability 3.SL=69.82 X=29.73-3.SL=-.35 3.SL=49.24 R=5.7-2.29 7.7578-3.SL=.E+ 22 Data Source: Time Span:
[INPUT] 뒤에는변수와관련된정보를표기한다. [CARDS;] 뒤에는각각의변수가가지는관측값들을표기한다. >> 위의프로그램에서데이터셋명은 wghtclub 이고, 변수는 idno, name, team, strtwght, endwght 이다. 이중 name 과 team 은
![[INPUT] 뒤에는변수와관련된정보를표기한다. [CARDS;] 뒤에는각각의변수가가지는관측값들을표기한다. >> 위의프로그램에서데이터셋명은 wghtclub 이고, 변수는 idno, name, team, strtwght, endwght 이다. 이중 name 과 team 은](/thumbs/77/75104228.jpg "[INPUT] 뒤에는변수와관련된정보를표기한다. [CARDS;] 뒤에는각각의변수가가지는관측값들을표기한다. >> 위의프로그램에서데이터셋명은 wghtclub 이고, 변수는 idno, name, team, strtwght, endwght 이다. 이중 name 과 team 은") SAS 의기본형식 1. INPUT 문 DATA wghtclub; INPUT idno 1-4 name $ 6-24 team $ strtwght endwght; loss=strtwght -endwght; CARDS; 1023 David Shaw red 189 165 1049 Amelia Serrno yellow 145 124 1219 Alan Nance red
SAS 의기본형식 1. INPUT 문 DATA wghtclub; INPUT idno 1-4 name $ 6-24 team $ strtwght endwght; loss=strtwght -endwght; CARDS; 1023 David Shaw red 189 165 1049 Amelia Serrno yellow 145 124 1219 Alan Nance red
DBPIA-NURIMEDIA
 The e-business Studies Volume 17, Number 4, August, 30, 2016:319~332 Received: 2016/07/28, Accepted: 2016/08/28 Revised: 2016/08/27, Published: 2016/08/30 [ABSTRACT] This paper examined what determina
The e-business Studies Volume 17, Number 4, August, 30, 2016:319~332 Received: 2016/07/28, Accepted: 2016/08/28 Revised: 2016/08/27, Published: 2016/08/30 [ABSTRACT] This paper examined what determina
PPT Template
 External Use SPSS 를이용한분산분석 (ANOVA) 013 년 11 월 13 일 임찬수 0 Table of Contents 1 분산분석과실험계획법 일원배치분산분석 (One-way ANOVA) 3 사후분석 (Post-hoc test) 4 일원배치분산분석의예제 5 HomeWork 1 1 분산분석과실험계획법 분산분석 분산분석 : 평균값을기초로하여여러집단을비교하고,
External Use SPSS 를이용한분산분석 (ANOVA) 013 년 11 월 13 일 임찬수 0 Table of Contents 1 분산분석과실험계획법 일원배치분산분석 (One-way ANOVA) 3 사후분석 (Post-hoc test) 4 일원배치분산분석의예제 5 HomeWork 1 1 분산분석과실험계획법 분산분석 분산분석 : 평균값을기초로하여여러집단을비교하고,
 - i - - ii - - iii - - iv - - v - - vi - - 1 - - 2 - - 3 - 1) 통계청고시제 2010-150 호 (2010.7.6 개정, 2011.1.1 시행 ) - 4 - 요양급여의적용기준및방법에관한세부사항에따른골밀도검사기준 (2007 년 11 월 1 일시행 ) - 5 - - 6 - - 7 - - 8 - - 9 - - 10 -
- i - - ii - - iii - - iv - - v - - vi - - 1 - - 2 - - 3 - 1) 통계청고시제 2010-150 호 (2010.7.6 개정, 2011.1.1 시행 ) - 4 - 요양급여의적용기준및방법에관한세부사항에따른골밀도검사기준 (2007 년 11 월 1 일시행 ) - 5 - - 6 - - 7 - - 8 - - 9 - - 10 -
<C5EBB0E8C0FBB0A1BCB3B0CBC1F5C0C7C0FDC2F7BFCDB9AEC1A6C1A1B1D7B8AEB0EDB4EBBEC E687770>
 통계적가설검증의절차와문제점그리고대안 서울대학교심리학과, 인지과학협동과정교수조사연구편집위원장조사연구학회이사서울대사회과학대학교무부학장역임 주요연구 : Self-efficacy in information security : Its influence on end users information security practice behavior When fit indices
통계적가설검증의절차와문제점그리고대안 서울대학교심리학과, 인지과학협동과정교수조사연구편집위원장조사연구학회이사서울대사회과학대학교무부학장역임 주요연구 : Self-efficacy in information security : Its influence on end users information security practice behavior When fit indices
Buy one get one with discount promotional strategy
 Buy one get one with discount Promotional Strategy Kyong-Kuk Kim, Chi-Ghun Lee and Sunggyun Park ISysE Department, FEG 002079 Contents Introduction Literature Review Model Solution Further research 2 ISysE
Buy one get one with discount Promotional Strategy Kyong-Kuk Kim, Chi-Ghun Lee and Sunggyun Park ISysE Department, FEG 002079 Contents Introduction Literature Review Model Solution Further research 2 ISysE
시스템경영과 구조방정식모형분석
 2 st SPSS OPEN HOUSE, 2009 년 6 월 24 일 AMOS 를이용한잠재성장모형 (Latent Growth Model ) 세명대학교경영학과김계수교수 (043) 649-242 gskim@semyung.ac.kr 목차. LGM개념소개 2. LGM모형종류 3. LGM 예제 4. 결과치비교 5. 정리및요약 2 적합모형의판단방법 Tips SEM 결과해석방법
2 st SPSS OPEN HOUSE, 2009 년 6 월 24 일 AMOS 를이용한잠재성장모형 (Latent Growth Model ) 세명대학교경영학과김계수교수 (043) 649-242 gskim@semyung.ac.kr 목차. LGM개념소개 2. LGM모형종류 3. LGM 예제 4. 결과치비교 5. 정리및요약 2 적합모형의판단방법 Tips SEM 결과해석방법
untitled
 R 과함께하는통계학의이해 빅북이라명명된이책은지식공유의세계적인흐름에동참하고지적인업적들이세상과인류의지식이되도록하며, 누구나쉽게접근하고활용할수있는환경을만들고자한다. 이책의저작권은빅북 (www.bigbook.or.kr) 에있으며모든용도로활용할수있다. 다만상업용출판을하고자하는경우에는사전에문서로된허락을받아야한다. 공유와협력의교과서만들기운동본부 R 과함께하는 통계학의이해
R 과함께하는통계학의이해 빅북이라명명된이책은지식공유의세계적인흐름에동참하고지적인업적들이세상과인류의지식이되도록하며, 누구나쉽게접근하고활용할수있는환경을만들고자한다. 이책의저작권은빅북 (www.bigbook.or.kr) 에있으며모든용도로활용할수있다. 다만상업용출판을하고자하는경우에는사전에문서로된허락을받아야한다. 공유와협력의교과서만들기운동본부 R 과함께하는 통계학의이해
통계적 표본조사론 소개
 통계적표본조사론소개 김호 서울대학교보건대학원 기초개념 전수조사혹은총조사 (census) vs. 표본조사 (sampling survey) : 전수조사가불가능하거나혹은더정확하지않을수도있음 대상모집단 (target population) and 추출모집단 (sampling population): 일치하지않을수도있음 (ex. 전화조사 ) 기초개념 표본오차 (sampling
통계적표본조사론소개 김호 서울대학교보건대학원 기초개념 전수조사혹은총조사 (census) vs. 표본조사 (sampling survey) : 전수조사가불가능하거나혹은더정확하지않을수도있음 대상모집단 (target population) and 추출모집단 (sampling population): 일치하지않을수도있음 (ex. 전화조사 ) 기초개념 표본오차 (sampling
에너지경제연구 Korean Energy Economic Review Volume 9, Number 2, September 2010 : pp. 1~18 가격비대칭성검정모형민감도분석 1
 에너지경제연구 Korean Energy Economic Review Volume 9, Number 2, September 2010 : pp. 1~18 가격비대칭성검정모형민감도분석 1 2 3 < 표 1> ECM 을이용한선행연구 4 5 6 7 and 8 < 표 2> 오차수정모형 (ECM1~ECM4) 9 10 < 표 3> 민감도분석에쓰인더미변수 11 12 < 표
에너지경제연구 Korean Energy Economic Review Volume 9, Number 2, September 2010 : pp. 1~18 가격비대칭성검정모형민감도분석 1 2 3 < 표 1> ECM 을이용한선행연구 4 5 6 7 and 8 < 표 2> 오차수정모형 (ECM1~ECM4) 9 10 < 표 3> 민감도분석에쓰인더미변수 11 12 < 표
14-X25-JSJ.hwp
 지경택 송영호 * 정국삼 ** ( 주 ) 한라 * 충북대학교대학원안전공학과 ** 충북대학교안전공학과 (2001. 9. 12. 접수 / 2001. 10. 30. 채택 ) Categorical Analysis for the Factors of Industrial Accident Cases Kyung-Tek Jhee Young-Ho Song * Kook-Sam Chung
지경택 송영호 * 정국삼 ** ( 주 ) 한라 * 충북대학교대학원안전공학과 ** 충북대학교안전공학과 (2001. 9. 12. 접수 / 2001. 10. 30. 채택 ) Categorical Analysis for the Factors of Industrial Accident Cases Kyung-Tek Jhee Young-Ho Song * Kook-Sam Chung
3 장기술통계 : 수치척도 Part B 분포형태, 상대적위치, 극단값 탐색적자료분석 두변수간의관련성측정 가중평균과그룹화자료
 3 장기술통계 : 수치척도 Part B 분포형태, 상대적위치, 극단값 탐색적자료분석 두변수간의관련성측정 가중평균과그룹화자료 분포형태, 상대적위치, 극단값 분포형태 z-값 체비셰프의원리 경험법칙 극단값찾기 분포형태 : 왜도 (skewness) 분포형태를측정하는중요한척도중하나를 왜도 라고한다. 자료집합의왜도를구하는계산식은조금복잡하다. 통계프로그램을사용하여왜도를쉽게계산할수있다.
3 장기술통계 : 수치척도 Part B 분포형태, 상대적위치, 극단값 탐색적자료분석 두변수간의관련성측정 가중평균과그룹화자료 분포형태, 상대적위치, 극단값 분포형태 z-값 체비셰프의원리 경험법칙 극단값찾기 분포형태 : 왜도 (skewness) 분포형태를측정하는중요한척도중하나를 왜도 라고한다. 자료집합의왜도를구하는계산식은조금복잡하다. 통계프로그램을사용하여왜도를쉽게계산할수있다.