통계자료분석강희모 2013 년 11 월 29 일
|
|
|
- 이나 시
- 6 years ago
- Views:
Transcription
1 통계자료분석강희모 2013 년 11 월 29 일
2
3 목차 제 1 장 여러가지평균비교 단일표본검정 독립인두표본검정 대응표본검정 제 2 장 분산분석 (ANalysis Of VAriance) one way ANOVA 평균비교 다중비교 (multiple comparison) 대비 (contrast) two way ANOVA 제 3 장 공분산분석 (ANCOVA; ANalysis of COVAriance) 25 제 4 장 반복측정분산분석 (repeated measures anova) one way repeated measures two way repeated measures 제 5 장 회귀분석 (regression analysis) 45 제 6 장비모수검정 (nonparametric analysis) 적합도검정 (goodness of fit test) 부호검정 (sign test) Wilcoxon 부호순위검정 (Wilcoxon signed rank test) McNemar 검정 Wilcoxon 순위합검정 (Wilcoxon rank sum test, Mann Whitney U test) i
4 6.6. Kruskal Wallis 검정 Cochran Q 검정 Friedman 검정 제 7 장 범주형자료분석 적합도검정 (goodness of fit test) 독립성검정 동일성검정 likelihood ratio test linear by linear association 제 8 장 표본수 (sample size) 구하기 단일표본평균에대한표본수 독립인두표본평균차이에대한표본수 단일표본비율에대한표본수 독립인두표본비율차이에대한표본수 참고문헌 86 ii
5 표목차 3.1 나병간균환자 순차제곱합 부분제곱합 나병간균환자 근전도자료 정규성검정 부호평가 부호순위평가 순위합에서순위평가 독립표본과대응표본의순위평가 승산비 우도비검정 선형대선형결합 iii
6
7 그림목차 1.1 H 1 : µ > µ 0 일때 단일표본검정 SPSS 출력결과 ( 단일표본 ) 독립인두표본검정 SPSS 출력결과 ( 독립인두표본 ) 대응표본검정 SPSS 출력결과 ( 대응표본 ) 자료입력및분산분석 분산분석설정 등분산을가정한경우분산분석 등분산을가정하지않는경우분산분석 이원배치분산분석설정 이원배치분산분석출력결과 일원배치분산분석 공분산분석과정 공분산분석과정 반복측정분석과정 다변량과구형성 개체내효과와대비검정 사후검정 반복측정분석과정 (2원배치) 다변량과구형성 개체내효과 사후검정결과 v
8 5.1 회귀분석설정 회귀분석 저장 회귀분석분석결과 정규성검정 부호검정 Wilcoxon 부호순위검정 McNemar 검정 Wilcoxon 순위합검정 Kruskal Wallis 검정 Cochran Q 검정 Friedman 검정 적합도검정 독립성검정 승산비검정 승산비검정 (2 2 k) H 1 : µ > µ 0 일때 H 1 : µ > µ 0 일때 H 1 : µ µ 0 일때 엑셀목표값찾기
9 제 1 장 여러가지평균비교 모집단의평균비교검정은단일표본에대한평균검정, 독립인표본에대한평균차이검정, 대응표본평균검정등이있으며이장에서는이검정의사용방법을소개한다. 우선검정방법을알아보기전에검정에사용하는용어에대하여알아보자. 통계적가설검정계산에사용하는몇가지용어를소개하고그림 8.1에나타내었다. 귀무가설 (null hypothesis;h 0 ) : 이미전에연구자가입증한가설대립가설 (alternative hypothesis;h 1 ) : 연구자가연구결과입증하려는가설로귀무가설이아닌가설유의수준 (significance level;α) : 연구자가귀무가설이옳은데도잘못하여귀무가설을기각하는오류의최대허용한계의확률로많은경우 0.05로설정기각역 (rejection region for H 0 ) : 유의수준에서귀무가설을기각하는영역유의확률 (probability value) : 데이터에서구한검정통계량이귀무가설이옳은데도잘못하여귀무가설을기각하는오류의확률 검정통계량 (test statistic) : 귀무가설의기각, 채택여부판정할때사용하는통계량으로관측한데이터에서계산 제 1종의오류 (type I error; α) : 유의수준과동일한의미제 2종의오류 (type II error;β) : 귀무가설이옳지않을때귀무가설을기각하지않는오류의확률 1
10 검정력 (power;1 β) : 귀무가설이옳지않을때귀무가설을기각하는오류의확률 1.1. 단일표본검정 H 0 : µ = µ 0 β H 1 : µ = µ a µ 0 µ a acceptance region for H 0 rejection region for H 0 σ c = µ 0 + z α n σ = µ a z β n 그림 1.1: H 1 : µ > µ 0 일때 이검정은한집단의평균값이특정한값이라고할수있는지검정하는방법이다. 1 귀무가설 H 0 : µ = µ 0 ( 의미 : 어느집단의평균은 µ 0 이다.) 이며, 예전에조사한결과알려진평균이다. 대립가설은다음세가지중하나를연구자가정한다. 대립가설 H 1 : µ > µ 0 ( 의미 : 어느집단의평균은 µ 0 보다크다.) 단측검정 대립가설 H 1 : µ < µ 0 ( 의미 : 어느집단의평균은 µ 0 보다작다.) 단측검정 대립가설 H 1 : µ µ 0 ( 의미 : 어느집단의평균은 µ 0 이아니다. 즉 µ 0 보 다크거나 µ 0 보다작다 ) 양측검정 2 SPSS로통계적모델에대하여출력결과를얻는다. 3 연구자는 SPSS 출력결과에서유의확률을확인하여귀무가설 (H 0 ) 의기각, 채택여부를결정하고, 그결과를해석한다. 예를들어연구자가유의수준을 α = 0.05로설정하고 SPSS 출력결과유의확률 ( 양측 ) 이 0.07이라면 α 2
11 단측검정인경우는유의확률이 0.035이므로귀무가설을기각하고 양측검정인경우는유의확률이 0.07이므로귀무가설을기각하지못한다. 사례 : 1.1. ( 단일표본검정 ) 어느도시의남자중학생평균키가 5년전에 159cm으로알려져있다고하자. 현재중학생의평균키와같은지알아보려고 30명의중학생의키를조사하였다. 5년전과현재중학생의키의평균이동일한지검정과정을알아보자. 귀무가설 H 0 : µ = 159 ( 의미 : 어느도시의중학생평균키는 159cm이다.) 이고대립가설은다음세가지중하나를연구자가정한다. 대립가설 H 1 : µ > 159( 의미 : 어느도시남자중학생의평균키는 159cm보다크다.) 대립가설 H 1 : µ < 159( 의미 : 어느도시남자중학생의평균키는 159cm보다작다.) 대립가설 H 1 : µ 159( 의미 : 어느도시남자중학생의평균키는 159cm가아니다. 즉 159cm보다크거나 159cm보다작다 ) 여기서대립가설의설정은 H 1 : µ > 159라고하자. 그러면검정과정은다음과같다. 1 가설설정귀무가설 H 0 : µ = 159 ( 의미 : 어느도시의중학생평균키는 159cm이다.) 이고대립가설 H 1 : µ > 159( 의미 : 어느도시남자중학생의평균키는 159cm보다크다.) 2 SPSS 설정 ( 그림 1.2) 및출력결과 ( 그림 1.3) SPSS에서단일표본검정에대한자료입력은데이터보기시트에서한열에모든값을입력한다. 단일표본검정은분석 평균비교 일표본 T 검정메뉴를클릭하여그림 1.2 창에여러가지설정한후분석을실행한다. 이창에설정값으로 검정변수에는검정에사용할변수를추가하고, 검정값에는귀무가설의설정값을입력한후 3
.")
12 3 결론 : 그림 1.2: 단일표본검정 그림 1.3: SPSS 출력결과 ( 단일표본 ) 확인버튼을누르면분석이완료된다. 그림 1.3에서양쪽유의확률이 0.282이므로단측유의확률은 0.141이며유의수준 α = 0.05에서귀무가설을기각할수없다 독립인두표본검정 이검정법은독립인두집단의평균이같다고할수있는지알아보는방법이다. 먼 저두집단이분산이같은지다른지에따라통계량계산이다르므로두집단의분 산이같은지동일성검정을한다 ( 등분산성검정 ). 등분산성에대한검정은 SPSS 출 4
13 력결과에서확인할수있으며, 검정과정은다음과같다. 1 가설설정 (Levene 검정 ) 귀무가설 H 0 : σ1 2 = σ2 2 ( 의미 : 두집단의분산은같다.) 대립가설 H 1 : σ1 2 σ2 2 ( 의미 : 두집단의분산은같지않다.) 2 SPSS의출력결과에서 Levene 등분산검정의유의확률을확인한다. 3 등분산성에대한검정결과해석및평균비교방법선택 유의확률이 0.05보다작으면두집단의분산은서로다르다고할수있으며두집단의평균을비교할때두집단의분산이다른경우의유의확률로검정한다. 유의확률이 0.05보다크면두집단의분산은서로같고할수있으며두집단의평균을비교할때두집단의분산이같은경우의유의확률로검정한다. 두집단의평균비교과정은다음과같다. 1 귀무가설 H 0 : µ 1 µ 2 = 0 ( 의미 : 두집단의평균차이는 0이다.) 대립가설은다음세가지중하나를연구자가정한다. 대립가설 H 1 : µ 1 µ 2 > 0( 의미 : 두집단의평균차이는 0보다크다.) 단측검정 대립가설 H 1 : µ 1 µ 2 < 0( 의미 : 두집단의평균차이는 0보다작다.) 단측검정 대립가설 H 1 : µ 1 µ 2 0( 의미 : 두집단의평균차이는 0이아니다. 즉두집단의평균차이는 0보다크거나 0보다작다 ) 양측검정 2 SPSS로통계적모델에대하여출력결과를얻는다. 3 연구자는 SPSS 출력결과에서유의확률을확인하여귀무가설 (H 0 ) 의기각, 채 택여부를결정하고, 그결과를해석한다. 예를들어연구자가유의수준을 α = 0.05로설정하고 SPSS 출력결과유의확률 ( 양측 ) 이 0.07이라면 단측검정인경우는유의확률이 0.035이므로귀무가설을기각하고 양측검정인경우는유의확률이 0.07 이므로귀무가설을기각하지못환 다. 5
14 즉 대립가설이 H 1 : µ 1 µ 2 > 0일때귀무가설을기각하므로통계적으로두젖소집단의우유생산량평균차는 0보다크다고할수있고, 대립가설이 H 1 : µ 1 µ 2 0일때귀무가설을기각하지못하므로통계적으로두젖소집단의우유생산량평균차는 0라고할수있다. 사례 : 1.2. ( 독립인두표본검정 ) 두종류의사료가젖소의우유생산량에차이가있는지알아보기위하여 16 마리의젖소를임의로두집단으로나눈후 8 마리에는사료 A를다른 8 마리는사료 B를먹이고우유생산량을조사하였다. 사료 A 를먹은소의우유생산량과사료 B를먹은소의우유생산량이차이가있다고할수있는가? SPSS는등분산성검정의한종류로 Levene 등분산성검정방법을사용한다. Levene 검정결과가 두집단의분산이같다면그림 1.5의등분산이가정됨에서평균의동일성에대한검정의유의확률을사용하고 두집단의분산이같지않다면그림 1.5의등분산이가정되지않음에서평균의동일성에대한검정의유의확률을사용한다. 두종류의젖소의우유생산량자료로유의수준 α = 0.05에서가설검정하자. 귀무가설 H 0 : µ 1 µ 2 = 0 ( 의미 : 두젖소집단의우유생산량평균차는 0이다.) 이고대립가설은다음세가지중하나를연구자가정한다. 대립가설 H 1 : µ 1 µ 2 > 0( 의미 : 두젖소집단의우유생산량평균차는 0보다크다.) 대립가설 H 1 : µ 1 µ 2 < 0( 의미 : 두젖소집단의우유생산량평균차는 0보 다작다.) 대립가설 H 1 : µ 1 µ 2 0( 의미 : 두젖소집단의우유생산량평균차는 0이아니다. 즉 0보다크거나 0보다작다 ) 여기서대립가설의설정은 H 1 : µ 1 µ 2 0 일때다음과같은검정과정을진행하 자. 6



15 (b) 독립인두표본설정창 (a) 독립인두표본자료입력 그림 1.4: 독립인두표본검정 (c) 독립인두표본집단설정 1 1 두집단의분산의동일성에대한가설설정 귀무가설 H 0 : σ1 2 = σ2 2 ( 의미 : 두집단의분산은같다.) 대립가설 H 1 : σ1 2 σ2 2 ( 의미 : 두집단의분산은같지않다.) 7
16 그림 1.5: SPSS 출력결과 ( 독립인두표본 ) 출력결과그림 1.5에서 Levene 등분산검정의유의확률이 0.914이므로두집단의분산은같다고할수있다. 따라서등분산을가정하고두집단의평균비교에대한검정을한다. 1 2 두집단의평균차에대한가설설정귀무가설 H 0 : µ 1 µ 2 = 0 ( 의미 : 두젖소집단의우유생산량평균차는 0이다.) 대립가설 H 1 : µ 1 µ 2 0 ( 의미 : 두젖소집단의우유생산량평균차는 0이아니다. 즉 0보다크거나 0보다작다 ) 2 SPSS 설정 ( 그림 1.4) 및출력결과 ( 그림 1.5) SPSS에서자료분석하기전데이터의입력에대하여알아보자. 데이터를입력할때 한열에는분석에사용할종속변수인관측값을입력하고, 다른한열에는두집단을구분하는집단변수의구분값을 입력한다 ( 그림 1.4(a)). 데이터가올바르게입력되었다면분석을실행하자. SPSS에서독립인두표본검정은분석 평균비교 독립표본 T 검정메뉴를클릭한다 ( 그림 1.4(b)). 이창의설정값은 검정변수에는검정에사용할종속변수를추가하고, 집단변수에는두집단을구분하는변수를추가하며 8
17 집단정의버튼을누른후집단정의에사용한각집단의구분값을입력하고 ( 그림 1.4(c)) 확인버튼을누르면분석이완료된다. 3 결론 : 그림 1.5에서양쪽유의확률이 0.333이므로유의수준 α = 0.05에서귀무가설을기각할수없다. 즉두종류사료로먹인소의우유생산량은통계적으로차이가없다고할수있다 대응표본검정 두집단의자료가쌍으로된경우 ( 한개체에서두번자료를관측하거나동일한종류의기계두대에서자료를관측하는경우 ) 로쌍으로된두집단차이의평균을 δ라고할때이값에대하여검정하는방법이다. 만일두집단의차이가없다면 δ는 0이된다. 1 귀무가설 H 0 : δ = δ 0 ( 의미 : 쌍으로구성된두집단차이의평균은 δ 0 이다.) 대립가설은다음세가지중하나를연구자가정한다. 대립가설 H 1 : δ > δ 0 ( 의미 : 쌍으로구성된두집단차이의평균은 0보다크다.) 단측검정 대립가설 H 1 : δ < δ 0 ( 의미 : 쌍으로구성된두집단차이의평균은 0보다작다.) 단측검정 대립가설 H 1 : δ δ 0 ( 의미 : 쌍으로구성된두집단차이의평균은 0이아니다. 양측검정즉쌍으로구성된두집단차이의평균은 0보다크거나 0보다작다 ) 2 SPSS로통계적모델에대하여출력결과를얻는다. 3 연구자는 SPSS 출력결과에서유의확률을확인하여귀무가설 (H 0 ) 의기각, 채 택여부를결정하고, 그결과를해석한다. 예를들어연구자가유의수준을 α = 0.05로설정하고 SPSS 출력결과유의확률 ( 양측 ) 이 0.07이라면 단측검정인경우는유의확률이 0.035이므로귀무가설을기각하고 양측검정인경우는유의확률이 0.07이므로귀무가설을기각하지못환다. 9
 (b) 대응표본설정창 대립가설이 H 1 : δ >")

18 즉 (a) 대응표본자료입력 그림 1.6: 대응표본검정 그림 1.7: SPSS 출력결과 ( 대응표본 ) (b) 대응표본설정창 대립가설이 H 1 : δ > 0라면귀무가설을기각하므로통계적으로두집단의평균차이는 0보다크다고할수있고, 대립가설이 H 1 : δ 0라면귀무가설을기각하지못하므로두집단의평균차이는 0라고할수있다. 사례 : 1.3. ( 대응표본검정 ) 첨가제를사용하는차량과사용하지않는차량의주 행거리가같은지검정하려고다섯종류의동일한새차 2 대를추출하여임의로첨 가제를사용한경우와첨가제를사용하지않은경우주행거리를보고두경우가차 이가있는지알아보자. 10
19 귀무가설 H 0 : δ = 0 ( 의미 : 첨가제와휘발유를주유한차량의주행거리는같다.) 이고대립가설은다음세가지중하나를연구자가정한다. 대립가설 H 1 : δ > 0( 의미 : 첨가제와휘발유를주유한차량의주행거리차이의평균은 0보다크다.) 대립가설 H 1 : δ < 0( 의미 : 첨가제와휘발유를주유한차량의주행거리차이의평균은 0보다작다.) 대립가설 H 1 : δ 0( 의미 : 첨가제와휘발유를주유한차량의주행거리차이의평균은 0이아니다. 즉주행거리차이의평균은 0보다크거나 0보다작다 ) 1 가설설정귀무가설 H 0 : δ = 0 ( 의미 : 첨가제주입차량과주입하지않은차량의주행거리차이의평균은 0이다.) 이고대립가설 H 1 : δ ( 의미 : 첨가제주입차량과주입하지않은차량의주행거리차이의평균은 0이아니다.) 2 SPSS 설정 ( 그림 1.6) 및출력결과 ( 그림 1.7) SPSS에서자료분석하기전데이터의입력에대하여알아보자. 데이터를입력할때한열에는반복측정한변수값을입력하고, 나머지열에반복측정한또다른변수값을입력한다 (( 그림 1.6(b)). SPSS에서대응표본검정은분석 평균비교 대응표본 T 검정메뉴를클릭한다 ( 그림 1.6(b)). 이창에 대응변수에검정에사용할반복측정한두변수를추가하고 확인버튼을누르면분석이완료된다. 3 결론 : 그림 1.7에서양쪽유의확률이 0.032이므로유의수준 α = 0.05에서귀무가설을 기각한다. 첨가제주입한차량과주입하지않은차량의주행거리는통계적으로같지않다고할수있다. 11
20
21 제 2 장 분산분석 (ANalysis Of VAriance) 모수적검정에서한집단이나두집단의평균비교는 t 검정을사용하고셋이상집단의평균비교는 F 검정을사용한다. 이장에서는세집단평균비교인분산분석 (ANOVA) 에대하여알아보자 one way ANOVA 한요인 (factor) 에대하여셋이상집단의평균비교에대한통계학적모델을일원배치분산분석 (one way ANalysis Of VAriance; one way ANOVA) 이라고하며 y ij = µ + τ i + ɛ ij, ˆµ = y, ˆτ i = y i. y (2.1) 이며다음과같은조건을만족해야한다. ɛ ij 서로독립이다. ɛ ij 는 N(0, σ 2 ) 인정규분포를따른다. 각처리집단의분산은모두같다. 만일위의조건에서첫번째, 두번째조건은만족하고세번째조건에서처리집단 간분산이같은지같지않은지에따라분석방법을다르다. 따라서셋이상집단의평균을비교하기전에모든집단의분산이모두같은지등분산성에대한검정을해야한다. 가설설정귀무가설 H 0 : σ1 2 = σ2 2 = = σ2 k ( 의미 : k 집단의분산은같다.) 대립가설 H 1 : not H 0 ( 의미 : 적어도한집단은분산은같지않다.) 13
22 등분산성검정은 17 페이지그림 2.2(c) 에서분산동질성검정을선택하고분석하면 19 페이지그림 2.3(a) 에서분산의동질성검정에대한결과를확인할수있다. 등분산성검정결과 유의확률이 0.05보다크면모든집단의분산이같다고할수있고분산분석으로평균을비교한다 ( 그림 2.3, 19 페이지 ). 유의확률이 0.05보다작으면셋이상의집단중분산은같지않은집단이하나이상존재하며이런경우는 Welch 검정으로평균을비교한다. 이검정은 17 페이지그림 2.2(c) 에서 Welch 선택하고분석을실행하면 20 페이지그림 2.4(a) 의출력결과를확인할수있다 평균비교 1 귀무가설 H 0 : µ 1 = µ 2 =... = µ k ( 의미 : k개집단평균은모두같다.) 대립가설 H 1 : not H 0 ( 의미 : k개집단에서평균이다른집단이적어도한개이상이다.) 사례 : 2.1. ( 분산분석 ) 레코드테이프의코팅처리가음질의재생에효과가있는지알아보기위하여코팅처리가다른네종류의테이프에대하여잡음을조사하였다면귀무가설 H 0 : µ 1 = µ 2 = µ 3 = µ 4 ( 의미 : 네종류테이프의잡음소리의평균은모두같다.) 이고대립가설 H 0 : not H 0 ( 의미 : 4 종류테이프에서잡음의평균이다른테이프가적어도한개이상있다.) 2 SPSS로통계적모델에대하여출력결과를얻는다. SPSS에서자료분석하기전데이터의입력에대하여알아보자. 데이터를입 력할때 한열에는분석에사용할종속변수인관측값을입력하고, 다른한열에는 k 집단을구분하는집단변수의구분값을입력한다 ( 그림 2.1(a)). 데이터가올바르게입력되었다면분석을실행하자. SPSS에서독립인두표본검정은분석 평균비교 일원배치분산분석메뉴를클릭한다 ( 그림 2.1(b)). 이창에서 14
에서 기술통계를 선택하고 분석하면 출력결과에 기 초통계량을 확인할 수 있다.")
 귀무가설 H0 : µi = µ2 =.")
23 lym.ac.kr (a) 분산분석 자료입력 (b) 분산분석 화면 그림 2.1: 자료입력 및 al 종속변수에는 검정에 사용할 종속 변수를 추가하고, 요인에는 k 집단을 구분하는 변수를 추가하고(그림 2.1(b)) 확인 버튼을 누르면 분산분석표가 출력된다(그림 2.3(a), 19 페이지). 분산분석에서는 기본값으로 각 그룹마다 기술통계량을 보여주지 않기 때문 에 17 페이지 그림 2.2(c)에서 기술통계를 선택하고 분석하면 출력결과에 기 초통계량을 확인할 수 있다. kan g ③ 연구자는 SPSS 출력결과에서 유의확률을 확인하여 귀무가설(H0 )의 기각, 채 택 여부를 결정하고, 그 결과를 해석한다. 연구자가 유의수준을 α = 0.05로 설정하고 SPSS 출력결과 유의확률이 0.03이 라면 유의확률이 0.03이므로 귀무가설을 기각하므로 통계적으로 네 개의 레 hm 코드 중 적어도 한 집단의 평균은 다르다고 할 수 있다 다중비교(multiple comparison) 귀무가설 H0 : µi = µ2 =... = µk 를 기각한 경우 적어도 한 집단의 평균이 다르므 로 어떤 집단의 평균이 다르다고 할 수 있는지!알아보자. 집단 수가 k인 경우 두 집 k 단씩 묶어서 평균차를 비교하는 개수는 이다. 비교 방법은 2 등분산을 가정할 때 LSD, Duncan, Tukey, SNK 등 14개와 15
24 등분산을가정하지않을때 Tamhane, Dunnett 등 4개모두 18개를제공한다. 다중비교의분석과정은 1 귀무가설 H 0 : µ i µ j = 0 for all i, j( 의미 : 두집단평균은같다.) 대립가설 H 1 : µ i µ j 0 ( 의미 : 두집단의평균은같지않다.) 사례 : 2.2. ( 다중비교 ) 귀무가설 H 0 : µ 1 = µ 2 = µ 3 = µ 4 을기각하였을 ( ) 때 4 어떤집단의평균이다르다고할수있는지다중비교를하려면 = 6 2 개쌍의평균차를비교한다. 2 SPSS로통계적모델에대하여출력결과를얻는다. 3 연구자는 SPSS 출력결과에서유의확률을확인하여귀무가설 (H 0 ) 의기각, 채택여부를결정하고, 그결과를해석한다. 사례 : 2.3. ( 다중비교결과 (LSD)) 연구자가유의수준을 α = 0.05로설정하였을때, 4 개집단에서 2 개집단씩비교하는개수는 6개며 SPSS 결과가 H 0 : µ 1 µ 2 = 0 일때유의확률이 0.004면귀무가설을기각하며통계적으로두집단의평균은같지않다. H 0 : µ 1 µ 3 = 0 일때유의확률이 0.008이면귀무가설을기각하며통계적으로두집단의평균은같지않다. H 0 : µ 1 µ 4 = 0 일때유의확률이 0.044이면귀무가설을기각하며통계적으로두집단의평균은같지않다. H 0 : µ 2 µ 3 = 0 일때유의확률이 0.494이면귀무가설을기각못하며통계적으로두집단의평균은같다. H 0 : µ 2 µ 4 = 0 일때유의확률이 0.192면귀무가설을기각못하며통 계적으로두집단의평균은같다. H 0 : µ 3 µ 4 = 0 일때유의확률이 0.442면귀무가설을기각못하며통계적으로두집단의평균은같다. 16
 대립가설 H 0 : c 1 µ 1 + c 2 µ 2 + + c k µ k 0 ( 의미 : 두그룹의평균은같지않 다.")
 에계수의합이 0 이되도록설정하였고계수 가음수인첫번째변수를한그룹, 계수가양수인나머지세개의변수를다 른한그룹으로나눠두그룹을비교하였으며그림 2.3(b)(19 페이지 ) 에그 결과가있다.")
 의기각, 채 택여부를결정하고, 그결과를해석한다. 사례 : 2.5. ( 대비결과 ) 연구자가유의수준을 α = 0.05 로설정하였을때 유의확률이 0.")
25 대비 (contrast) (a) 다중비교 (b) 대비 (c) 옵션 그림 2.2: 분산분석설정 대비는사후검정결과통계적으로다른집단이존재한경우각변수를두개의그 룹으로나누어두그룹의평균이차이가있다고할수있는지검정하는것이다. 1 귀무가설 H 0 : c 1 µ 1 + c 2 µ c k µ k = 0( 의미 : 두그룹의평균은같다.) 대립가설 H 0 : c 1 µ 1 + c 2 µ c k µ k 0 ( 의미 : 두그룹의평균은같지않 다.) k 개그룹에대한대비는 C = c 1 µ 1 + c 2 µ c k µ k 로정의하며상수 c 는 k i=1 c i = 0 이되도록설정한다. 사례 : 2.4. ( 대비 ) 그림 2.2(b) 에계수의합이 0 이되도록설정하였고계수 가음수인첫번째변수를한그룹, 계수가양수인나머지세개의변수를다 른한그룹으로나눠두그룹을비교하였으며그림 2.3(b)(19 페이지 ) 에그 결과가있다. 다시말하자면그룹을 µ 1 과 µ 2, µ 3, µ 4 로하였을때귀무가설은 H 0 : 3µ 1 + µ 2 + µ 3 + µ 4 = 0 으로각상수의합이 0 이되도록한다. 2 SPSS 로통계적모델에대하여출력결과를얻는다. 3 연구자는 SPSS 출력결과에서유의확률을확인하여귀무가설 (H 0 ) 의기각, 채 택여부를결정하고, 그결과를해석한다. 사례 : 2.5. ( 대비결과 ) 연구자가유의수준을 α = 0.05 로설정하였을때 유의확률이 라면귀무가설을기각하므로집단 1 과집단 2, 집단 3, 집단 4 개를묶은그룹의평균은통계적으로다르다고할수있다. 17
26 사례 : 2.6. ( 등분산인경우분산분석 ) 레코드테이프의질을향상시키려고네종류 A, B, C, D의코팅처리에대하여음질의재생에얼마나효과가있는지를비교하려고한다. 데이터는레코드의잡음소리를기록한것이다. 1 1 네집단의분산의동일성에대한가설설정귀무가설 H 0 : σ1 2 = σ2 2 = σ2 3 = σ2 4 ( 의미 : 네집단의분산은같다.) 대립가설 H 1 : not H 0 ( 의미 : 적어도한집단은분산은같지않다.) 결과그림 2.3(a) 에서 Levene 등분산검정의유의확률이 0.101이므로유의수준 α = 0.05에서귀무가설을기각할수없으므로네집단의분산은모두같다고할수있다. 따라서등분산을가정하고네집단의평균비교에대한검정을한다. 1 2 네집단의평균차에대한가설설정귀무가설 H 0 : µ 1 = µ 2 = µ 3 = µ 4 ( 의미 : 네종류레코드의음질처리에대한잡음소리평균은모두같다.) 대립가설 H 1 : not H 0 ( 의미 : 적어도한종류의레코드는평균이다르다.) 결과그림 2.3(a) 에서분산분석결과유의확률이 0.018이므로유의수준 α = 0.05에서귀무가설을기각한다. 따라서적어도한레코드의평균이다르다는것을알수있다. 2 사후검정레코드의잡음에대한 ( 평균이 ) 적어도한집단이다르므로네개의 4 집단을두집단씩묶는개수가 = 6개이므로이것들에대하여두집단 2 의평균비교를한다. 귀무가설 H 0 : µ i µ j = 0 for all i, j when i j ( 의미 : 두집단의평균은같다 ) 대립가설 H 1 : not H 0 ( 의미 : 두집단의평균은같지않다.) 그림 2.3(b) 에서사후검정결과 A 레코드와 B, C, D 레코드의잡음에대한평 균이같은집단을묶을수있다. 그림 2.4(b) 에서적용한검정방법은등분산을가정한경우 Duncan을사용하였다. 3 대비레코드 A와레코드 B, C, D 그룹으로나눈후두그룹의평균이같다고할수있는지검정한다. 귀무가설 H 0 : 3µ 1 = µ 2 + µ 3 + µ 4 ( 의미 : 두그룹의평균은모두같다 ) 18
27 대립가설 H 1 : not H 0 ( 의미 : 두그룹의평균은다르다.) 그림 2.3(c) 에서양쪽유의확률이 0.003( 등분산가정 ) 이므로유의수준 α = 0.05에서귀무가설을기각한다. 따라서레코드 A 그룹과레코드 B, C, D 그룹의평균은같지않다. (a) 등분산성검정및분산분석 (c) 대비 (b) 사후검정 그림 2.3: 등분산을가정한경우분산분석사례 : 2.7. ( 등분산이아닌경우분산분석 ) 네종류의비료종류에대한수확량의평균을비교하려고한다. 19
28 (a) 등분산성검정및분산분석 (c) 대비 (b) 사후검정 그림 2.4: 등분산을가정하지않는경우분산분석 1 1 네집단의분산의동일성에대한가설설정 귀무가설 H 0 : σ1 2 = σ2 2 = σ2 3 = σ2 4 ( 의미 : 네집단의분산은같다.) 대립가설 H 1 : not H 0 ( 의미 : 적어도한집단은분산은같지않다.) 결과그림 2.4(a) 에서 Levene 등분산검정의유의확률이 0.013이므로유의수준 α = 0.05에서귀무가설을기각하므로적어도한집단의분산은다르다고할수있다. 따라서등분산을가정하지않고네집단의평균비교에대한검정을한다. 1 2 네집단의평균차에대한가설설정 귀무가설 H 0 : µ 1 = µ 2 = µ 3 = µ 4 ( 의미 : 네종류비료로경작한작물의수확 량의평균은모두같다.) 20
29 대립가설 H 1 : not H 0 ( 의미 : 적어도한종류의수확량의평균은다르다.) 결과그림 2.4(a) 에서 Welch 검정결과유의확률이 0.000이하이므로유의수준 α = 0.05에서귀무가설을기각한다. 따라서적어도한비료에대한수확량평균이다르다는것을알수있다. 2 사후검정농작물수확량에대한 ( 평균이 ) 적어도한집단이다르므로네개의 4 집단을두집단씩묶는개수가 = 6개이므로이것들에대하여두집단 2 의평균비교를한다. 귀무가설 H 0 : µ i µ j = 0 for all i, j when i j ( 의미 : 두집단의평균은같다 ) 대립가설 H 1 : not H 0 ( 의미 : 두집단의평균은같지않다.) 그림 2.4(b) 에서사후검정결과비료종류 1, 4와비료종류 3, 4는서로평균이다르다고할수있다. 그림 2.4(b) 에서적용한검정방법은등분산을가정하지않은경우 Dunnect의 T3을사용하였다. 3 대비비료 1,4 와비료 2,3 그룹으로나눈후두그룹의평균이같다고할수있는지검정한다. 귀무가설 H 0 : µ 1 + µ 4 = µ 2 + µ 3 ( 의미 : 두그룹의평균은모두같다 ) 대립가설 H 1 : not H 0 ( 의미 : 두그룹의평균은다르다.) 그림 2.4(c) 에서양쪽유의확률이 0.000이하 ( 등분산가정하지않음 ) 이므로유의수준 α = 0.05에서귀무가설을기각한다. 따라서비료 1, 4 그룹과비료 2, 3 그룹의평균은같지않다 two way ANOVA 두요인 (factor) 의각요인의평균비교와교호작용 (interaction) 을검정하는것을이 원배치분산분석 (two way ANalysis Of VAriance; two way ANOVA) 이라고한다. 교호작용은두변수의곱에대한검정으로유의확률이의미있는결과라면두변수는서로영향을준다고할수있으며수학적으로는두변수는서로독립이아니라고할수있다. 이원배치분산분석의통계학적모델은다음과같다. Y ij = µ + α i + β j + (αβ) ij + ɛ ijk 데이터가조건에맞는지알아보기위하여오차분산의동일성검정을한다. 21
 대립가설 H 1 : not H 0 ( 의미 : 오차분산은 σ 2 이아니다.")
 변수설정 (c) 사후분석 그림 2.")
 와변량효과 (random effect) 인경우에따라계산의차이가있다.")
30 가설설정귀무가설 H 0 : V (ɛ) = σ 2 ( 의미 : 오차분산은 σ 2 이다.) 대립가설 H 1 : not H 0 ( 의미 : 오차분산은 σ 2 이아니다.) 등분산성검정결과유의확률이 0.05보다작으면위의모델을사용하여분석할수없다. (a) 변수설정 (c) 사후분석 그림 2.5: 이원배치분산분석설정 (b) 모형설정 (d) 옵션 이원배치분산분석은요인의종류가모수효과 (fixed effect) 와변량효과 (random effect) 인경우에따라계산의차이가있다. 모수요인 (fixed effect) : 인자의수준이고정되어있는경우로그예로는인종, 부모교육수준, 성별, 학년변수등이있다. 22
31 변량요인 (random effect) : 인자의수준이임의로된경우로그예로는수요일과토요일에만자료를얻었을때요일변수, 춘천시 10개고등학교중 3개학교의학생점수를얻었을때변수등이변량요인이다. 이원배치분산분석에서 두요인이모두모수요인인경우 두요인이모두변량요인인경우 한요인은모수요인한요인은변량요인인경우자료분석자가적절하게분석방법을설정한다. SPSS에서이원배치분산분석은 (a) 분산분석표 (b) 분산의동질성검정 (c) 사후분석1 (d) 사후분석2 그림 2.6: 이원배치분산분석출력결과 1. 분석 일반선형모형 일변량메뉴를선택 23
32 2. 분석에교호작용은그림 2.5(a) 에서모형버튼을클릭한후그림 2.5(b) 의요인및공변량에서두변수를선택하고추가버튼을누르면모형에추가된다. 3. 사후분석은일원배치분산분석과유사하게그림 2.5(c) 창에검사후검정변수에변수를추가한후사후검정방법을선택한다. 4. 기술통계량, 동일성검정등은그림 2.5(a) 에서옵션버튼을클릭한후그림 2.5(d) 창에서통계량이나그림을선택한다. 분석방법은이원배치분산분석결과두변수간교호작용이있는지우선판단하고그결과에따라각요인에대한평균이다른지검정한다. 만일교호작용이의미있는결과를얻었다면각요인의평균비교결과가유의한결과가나타났다고하더라도두변수가서로독립이아니므로각요인에대한평균비교는의미가없다. 그림 2.5에이원배치분산분석의출력결과를일부분나타내었다. 그림 2.6(a) 에교호작용을포함한분산분석결과를보여주고있다. 여기서제곱합은 Type III 이며, 분석결과교호작용이유의한것으로나타났다. 그림 2.6(b) 에각그룹마다오차분산에대한동질성검정결과로유의확률이 0.221로귀무가설 H 0 : V (ɛ) = σ 2 를기각하지못하므로각요인의집단간오차분산은같다고할수있다. 그림 2.6(c) 에유리강도요인에대한 Turkey, Scheffe, LSD 등세가지분석에대한평균차, 유의확률, 신뢰구간의정보가출력되며, 그림 2.6(d) 에사후분석결과에대한동일집단군표시에대한결과를보여준다. 24
33 제 3 장 공분산분석 (ANCOVA; ANalysis of COVAriance) 실험에서얻어지는다변량자료들은연속형자료와이산형자료들이혼합되어있는경우가대다수이다. 이때성격이다른자료들을일반선형모델 (generalized linear modeling) 로분석할경우공분산분석 (ANCOVA, ANalysis of COVAriance) 이라고한다. 즉독립변수들이이산형, 연속형변수이고종속변수가연속형자료인경우에해당된다. 공분산분석은분산분석모형 y ij = µ + τ i + ɛ ij, ˆµ = y, ˆτ i = y i. y (3.1) 에공변량 (covariate) 을추가하면 y ij = µ + τ i + β(x ij x) + ɛ ij (3.2) 이되며각추정량들은 ˆµ = y ˆτ i = y i. y ˆβ(x i. x) ˆβ = Sxy S xx 이다. 이렇게분산분석모형에회귀분석모형을추가하면모델의설명력이높아지기때문에오차를줄이면서추정의정밀도를높이게된다. 공분산분석에추가되는연속변수공변량은종속변수에영향을주며, 종속변수의값과함께관측되지만실험자가그값을마음대로조절하지못하는변수이다. 25
34 그러나랜덤화블록설계에서는실험자가임의로블록요인의수준을조정하는것 이가능하였다. 따라서공분산분석의핵심은종속변수의값에영향을미치는공변 량의영향을보정 (adjust) 하는데있다. 나병환자의치료법을연구하기위하여 A, D 두항생제의효과를비교하려고한 다. 실험에참여하는나병환자를랜덤하게 30명을뽑은후 10명에게는항생제 A, 10명에게는항생제 D, 나머지 10명대조군에게는생리식염수를투여하고그경과 를관찰하였다. 일정기간치료한후환자의몸에서나병간균 (leprosy bacilli) 을측정 한결과가표 3.1에있다. 이자료를일원배치분산분석 (one way ANOVA) 방법으로 항생제 A 항생제 B 대조군 F 표 3.1: 나병간균환자 분석한결과가그림 3.1에있다. 그림 3.1(a) 의분산분석표에서유의확률이 0.03으 (a) 분산분석표 (b) 그룹간다중비교 그림 3.1: 일원배치분산분석 로귀무가설 세집단의평균은모두같다 를기각한다. 그러면어느집단의평균 26
35 sequential sum of squares SSR SSR(β 1, β 2, β 3 β 0 ) SSR(β 1 β 0 ) SSR(β 2 β 0, β 1 ) SSR(β 3 β 0, β 1, β 2 ) SSE SSE(β 0, β 1, β 2, β 3 ) 표 3.2: 순차제곱합이다른지그림 3.1(b) 에다중비교한결과유의수준 5% 에서항생제 A와대조군 F, 항생제 D와대조군 F의평균이다른것으로분석되었다. 표 3.4에는표 3.1의자료에치료전환자의나병간균자료가추가되어있다. 환자의세균수는치료전의세균수에많은영향을줄수있기때문에치료전세균수를공변량 (covariate) 에포함시키는것이바람직할것이다. 따라서독립변수가이산형, 연속형자료가모두포함되기때문에공분산분석을실시하면더명확한분석이진행될것이다. 공분산분석에서관심있는요인의수준간효과차이에대한검정은귀무가설 H 0 : τ 1 = τ 2 = = τ i = 0에대한가설검정으로이것을기각하면요인수준간효과차이가있다고할수있다. 공분산분석이나분산분석, 회귀분석모두일반선형모델이다. 일반선형모델에서변수를선택할때모델을설명하는제곱합으로그방법은네종류가있다. 세가지변수에대하여일반선형모델을설정한후제곱합에대하여알아보자. 세변수에대한일반선형모델은 Y i = β 0 + β 1 X i1 + β 2 X i2 + β 3 X i3 + ɛ i (3.3) 이며이식으로제곱합을알아보자. Type I(sequential) Sums of Squares : 순차제곱합으로부르기도한다. 추가되는변수에따라제곱합이증가하며추가되는변수의순서에따라제곱합이 다르다. 식 3.3의순차제곱합은표 3.2에나타내었다. Type II Sums of Squares : 완전모형 (full model) 에서변수를제거할때감소하는제곱합이다. Type III(partial) Sums of Squares : 부분제곱합이다. 변수가 p개일때 p 1개의독립변수가이미추가되어있고나머지한변수가추가될때증가되는제곱합이다. 식 3.3의부분제곱합은표 3.3에나타내었다. 27
36 partial sum of squares H 0 SSR(β 1 β 0, β 2, β 3 ) β 1 = 0 SSR(β 2 β 0, β 1, β 3 ) β 2 = 0 SSR(β 3 β 0, β 1, β 2 ) β 3 = 0 SSE(β 0, β 1, β 2, β 3 ) 표 3.3: 부분제곱합 Type IV Sums of Squares : 결측값이없는경우 Type III(partial) Sums of Squares와같다. 일반선형모델에서특이사항으로각변동의제곱합을모두합하더라도그합이총제곱합이되지않는제곱합이있는것을위에서확인하였다. 즉 SST SSR + SSE인제곱합의종류가존재한다. 공분산분석도일반선형모델에속하기때문에총제곱합이회귀제곱합과오차제곱합의합과같지않는제곱합이있다. 공분산분석에서는범주형자료의제곱합및오차제곱합이연속형자료인공변량에대하여보정되었기때문이다. 따라서요인간효과가있을때사후검정을실시하는경우각처리집단의평균은보정한자료를가지고비교하게된다. 보정된처리평균 (y i.(adj) ) 은 y i.(adj) = y i. ˆβ(x i. x) (3.4) 으로정의하여계산한다. 공분산분석을실시하려면다음과같이몇가지조건이만족되어야한다. 종속변수와공변량사이에는선형회귀관계가있어야한다. 공변량이회귀관계가존재하지않다면회귀분석으로제거할수있는변동이없으므로이때는분산분석의결과와별로다른결과가없을뿐만아니라오차의자유도만소모되어검출력이오히려나빠질수있다. 따라서귀무가설 H 0 : β = 0을기각해야한다. 종속변수와공변량사이의회귀계수가처리집단간동일해야한다. 공분산분석을올바로수행하려면기울기의동질성 (homogeneity of slopes) 이보장되어야하고귀무가설 H 0 : β 1 = β 2 = = β t = β를검정하여귀무가설을기각한다면공분산분석의의미가줄어든다. 즉각처리집단마다기울기가모두같아야보정된처리효과의평균을사용할수있다. 종속변수의각그룹마다기울기의동질성검정은독립변수와공변량의교호작용이유의성검정으로 28
37 한다. 교호작용이통계적으로유의하지않으면종속변수의집단마다각기울 기가모두같은것을의미한다. 따라서교호작용이존재하지않으면공분산 분석을실시할수있다. 표 3.4 자료로공분산분석을실행해보자. 치료후자료나병환자의세균수 (y) 항생제를투여한두집단과대조군한집단모두세집단의평균이차이가있는지 치료전세균수 (x) 를통제하여분석하자. 항생제 A 항생제 B 대조군 F 치료전 치료후 치료전 치료후 치료전 치료후 표 3.4: 나병간균환자 표 3.4 자료가공분산분석을실시하여도적합한지알아보자. 먼저교호작용변 수를포함한공분산분석을시행한후출력결과를보고판단한다. SPSS에서공분 산분석은 1. 분석 일반선형모형 일변량메뉴를선택 2. 일변량분석창에서종속변수에치료후변수, 모수요인에항생제변수, 공변량에 치료전변수를추가 ( 그림 3.2(a)) 3. 모형버튼클릭후일변량 : 모형창에서사용자정의선택하고항생제변수, 치료전변수, 두변수의교호작용인항생제 * 치료전을모형에추가하며, 제곱합의종류와절편을포함시킬지결정 ( 그림 3.2(b)) 4. 옵션버튼클릭후일변량 : 옵션창에서표시할변수에대한통계량이나검정방법을선택 ( 그림 3.2(c)) 29
 출력결과일부분 (a) 일변량분석 (b) 일변량 :")
 분산분석표그림 3.")
38 5. 출력결과 : 그림 3.2(d), 그림 3.2(e) 출력결과일부분 (a) 일변량분석 (b) 일변량 : 모형 ( 교호작용추가 ) (c) 일변량 : 옵션 (d) 통계량 (e) 분산분석표그림 3.2: 공분산분석과정1 공분산분석출력결과를살펴보자. 30
39 그림 3.2(e) 에서교호작용항생제 * 치료전변수의유의확률이 0.551로통계적으로유의하지않기때문에독립변수항생제변수의각그룹마다기울기가같다고할수있다. 따라서교호작용변수는분석에서제외하고나머지변수들로다시분석한다. 참고로교호작용변수에대한검정결과유의하였다면독립변수의각그룹별회귀식이서로교차하는것을의미하고유의하지않은것은각그룹별회귀식이서로평행한것을의미한다. 독립변수와공변량의교호작용에대한귀무가설은 H 0 : (αβ) ij = 0이다. 그림 3.2(e) 에서공변량치료전변수에대한유의확률이 0.000으로매우유의하므로회귀계수는 0이아니라고할수있다. 공변량의회귀계수에대한귀무가설은 H 0 : β = 0이다. 따라서표 3.4 자료가공분산분석에적합하다고할있다. 그러면독립변수와공변량의교호작용를분석에서제외하고다음과같이다시분석해보자. 1. 분석 일반선형모형 일변량메뉴를선택 2. 일변량분석창에서종속변수에치료후변수, 모수요인에항생제변수, 공변량에치료전변수를추가 ( 그림 3.2(a)) 3. 모형버튼클릭후일변량 : 모형창에서사용자정의선택하고항생제변수, 치료전변수는모형에추가하고, 두변수의교호작용인항생제 * 치료전는모형에서제외 ( 그림 3.3(b)) 4. 옵션버튼클릭후일변량 : 옵션창에서표시할변수에대한통계량이나검정방법을선택 ( 그림 3.3(b)) 5. 출력결과 : 그림 3.3(c), 그림 3.3(d), 그림 3.3(f), 그림 3.3(g), 그림 3.3(h) 출력결과일부분 다시분석한결과항생제종류에대한유의확률이 0.138( 그림 3.3(c)) 로항생제종류에따라나병세균수가다르다고할만한통계적근거가없으며, 회귀계수에대 한검정에서는유의확률이 0.000( 그림 3.3(c)) 으로계수가통계적으로매우의미가 있으므로공분산분석에사용하는것이적합하다고판정할수있다. 식 3.4 로보정된처리집단의평균 (adjusted treatment mean; y i.(adj) ) 은 y 1.(adj) = 5.30 (0.987)( ) =
 치료후통계량 (g) 보정평균 (h) 사후분석 그림 3.")
40 (a) 일변량 : 모형 (b) 일변량 : 옵션 (c) 분산분석표 (d) 모수추정 (e) 치료전통계량 (f) 치료후통계량 (g) 보정평균 (h) 사후분석 그림 3.3: 공분산분석과정 2 32
41 y 2.(adj) = (0.987)( ) = y 3.(adj) = (0.987)( ) = 로계산된다. 여기서 y i. 는그림 3.3(f), ˆβ 은그림 3.3(d) 의분석결과에계산된값이다. 또한 x i. 와 x는 SPSS에서분석 평균비교 일원배치분산분석메뉴를실행하고요인분석에항생제, 종속변수에치료전을입력한후옵션버튼을눌러기술통계를선택하고실행하여구하였으며그결과는그림 3.3(e) 에있다. 항생제별나병환자의세균수가차이가있는지검정한결과 일원배치분산분석결과항생제를사용한환자군과항생제를사용하지않은환자군이차이가있는것으로분석되었으나 공분산분석을실시하여공변량 ( 치료전나병환자균 ) 을모델에포함하여분석한결과나병환자의균수는통계적으로차이가없는것으로분석되었다. 33
42
43 제 4 장 반복측정분산분석 (repeated measures anova) 반복측정자료는동일한개체가통제된실험에참여하여여러번자료를관찰한것이다. 이자료는변수들이서로독립이아니기때문에일원배치에서서로독립적으로시행된결과와분석방법이약간다르다. 반복측정도분산분석이므로정규성, 독립성, 등분산성등몇가지가정이있다. 그중에서구형성가정에대하여알아보자. 구형성 (sphericity) 이란분산분석에서분산의동일성 (homogeneity of variance) 과같은것으로만일구형성가정이위배된다면검정력을잃어서 F 검정으로분석을실행할수없다. SPSS에서구형성검정은 Mauchly s test를사용하며통제된상태에서관찰한자료이므로각시행에서각변수의차이에대한분산의동일성검정법이다. 구형성검정에서 귀무가설 H 0 : σy 2 1 y 2 = σy 2 1 y 3 = = σy 2 k 1 y k 대립가설 H 1 : not H 0 로가설을설정할수있으며각변수의차이에대한개수는 k(k 1)/2 개이다. 구형성검정결과유의확률이 0.05보다작으면구형성을보장할수없으므로이런경우에는자유도를보정하여다시분석해야한다. SPSS에서자유도보정은 epsilon(ɛ) 으로출력되며 ɛ > 0.75 인경우는 Hyunh Feldt correction 그이외의경우는 Greenhouse Geisser corrected value를이용하여검정한다. 위에서설명한반복측정자료에대한분석방법을요약하면다음과같다 1. 1 Andy Field(2009)[1] 가제안 35
44 구형성이보장되는경우 : 구형성에대한검정결과유의확률이 0.05보다크면반복측정자료검정 구형성이보장되지않고 ɛ > 0.75 인경우 : Hyunh Feldt correction로반복측정자료검정 구형성이보장되지않고 ɛ <= 0.75 인경우 : Greenhouse Geisser corrected value로반복측정자료검정분석결과귀무가설을기각하였다면어느집단차이가유의한지사후검정으로알아본다. 만일귀무가설을기각하지못한상태에서사후검정을시행하더라도유의한집단차이를보이는것들이있을수도있으나주효과에서기각하지못하였다면결과를무시해도된다. 또한반복측정자료가어떤요인에대한차이가있는지검정하는방법은다변량 ANOVA 로분석할수있으며다음과같이여러가지검정방법이있다. Pillai s Trace Wilks Lambda Hotelling s Trace Roy s Largest Root 4.1. one way repeated measures 단일변량반복측정분산분석에대하여알아보자. 다음자료는 22 명에게세가지서로다른종류의음악을같은순서로들려주고음악에따른표정의미세한변화를알아보기위한실험 (Vasey and Thayer(1987)) 에서얻은자료이다. 이실험에서편안한음악 (1), 경쾌한음악 (2), 격렬한음악 (3) 을순서대로들려주고각단계에서 mean electromyographic(emg) amplitude( 단위 : µv ; 근전도 ) 를왼쪽눈섭부근 에서측정하였다. 각각의음악은 90 초간들려주었다. 음악간의차이에대하여알 아보자. 표 4.1를이용하여반복측정자료에대한분석을실행해보자. 실행과정은 1. SPSS에서분석 일반선형모형 반복측정메뉴를선택 2 2. 요인의수준수를설정 ( 그림 4.1(a)) 2 이메뉴는 SPSS 를 basic 로설치한경우에는없고 advanced 로설치해야사용할수있다. 36


45 음악 음악 표 4.1: 근전도자료 (a) 요인의수준수설정 (b) 설명변수설정 (c) 사후분석 그림 4.1: 반복측정분석과정 3. 반복측정에서설명변수설정 ( 그림 4.1(b)) 4. 사후분석 ( 그림 4.1(c)) 그림 4.2, 그림 4.3, 그림 4.4 에일변량반복측정출력결과가있다. 그림 4.2에반복측정에대한다변량검정결과유의확률이매우의미있는결과가나왔으므로각변수차에대하여서로다르다고할수있다. 그림 4.2에구형성검정결과유의확률이 0.002로매우유의하므로구형성을가정할수없다. 따라서자유도를보정한 Greenhouse Geisser 또는 Huynh Feldt로검정해야한다. 37
46 그림 4.3에엡실론이 Huynh Feldt인경우 0.716으로 0.75보다작으므로변수차이에대한검정은 Greenhouse Geisser로하는것이적합하다고할수있다. Greenhouse Geisser에서유의확률이 이하이므로변수간차이가있다고할수있다. 그림 4.3에대비에대한검정결과선형모형에대한유의확률이 이하이므로선형모형이라고할수있고, 2차선형모형은유의확률이 0.069로유의하지않으므로 2차선형모델을따른다고할수없다. 그림 4.4에사후분석결과 1과 3, 2과 3 변수차이가유의한결과를보였으며 1과 2 변수차이는유의하지않았다. 그림 4.2: 다변량과구형성 그림 4.3: 개체내효과와대비검정 38
47 그림 4.4: 사후검정 4.2. two way repeated measures 2개의요인에대하여반복측정한경우를이원배치반복측정 (two way repeated measures) 이라고한다. SPSS 메뉴사용법은단일요인반복측정과동일하다. 다 음자료는 30명에게 3가지연령대 (10, 15, 20) 에학교생활과직업에대한관심도를 조사하였다. 나이는 10세, 15세, 20세로구분하여학교생활관심도와직업관심도 를측정하였다. s10 s15 s20 w10 w15 w
48 이원배치반복측정을하려면원자료 (raw data) 의변수를이용하여새로운변수 를생성하여분석해야한다. 그과정은다음과같다. 학교생활의수준수도 3, 직업 의수준수도 3개이면총 9(3 3) 개의새로운변수가필요하며 SPSS에서변환 변수계산메뉴에서다음과같은변수를만든다. 10세학교생활관심도, 10세직업관심도 = 10세학교생활변수 + 10세직업 관심도변수 10세학교생활관심도, 15세직업관심도 = 10세학교생활변수 + 15세직업 관심도변수 10세학교생활관심도, 20세직업관심도 = 10세학교생활변수 + 20세직업관심도변수 15세학교생활관심도, 10세직업관심도 = 15세학교생활변수 + 10세직업관심도변수 15세학교생활관심도, 15세직업관심도 = 15세학교생활변수 + 15세직업관심도변수 40

 정은 1. 그림 4.5(a) 에학교생활관심도의수준수와직업관심도의수준수를설정하 고 2. 그림 4.5(b) 에 2원배치분산분석을하기위하여변환한변수 9개를추가하며 나머지과정은일원배치반복측정분산분석과동일하다.")
49 15세학교생활관심도, 20세직업관심도 = 15세학교생활변수 + 20세직업관심도변수 20세학교생활관심도, 10세직업관심도 = 20세학교생활변수 + 10세직업관심도변수 20세학교생활관심도, 15세직업관심도 = 20세학교생활변수 + 15세직업관심도변수 20세학교생활관심도, 20세직업관심도 = 20세학교생활변수 + 20세직업관심도변수위에서설정한자료를이용하여 SPSS로이원배치분산분석을실시하자. 설정과 (a) 요인의수준수설정 (b) 설명변수설정 그림 4.5: 반복측정분석과정 (2 원배치 ) 정은 1. 그림 4.5(a) 에학교생활관심도의수준수와직업관심도의수준수를설정하 고 2. 그림 4.5(b) 에 2원배치분산분석을하기위하여변환한변수 9개를추가하며 나머지과정은일원배치반복측정분산분석과동일하다. 출력결과는 41
50 그림 4.6: 다변량과구형성 그림 4.6 에다변량검정결과와구형성에대한검정결과 그림 4.7 에두반복측정요인에대한개체내효과의검정결과 그림 4.7: 개체내효과 그림 4.8에반복측정한두요인에대하여사후검정결과가있으며그림 4.8(a) 에 school 요인에대한사후검정결과가그림 4.8(b) 에 work 요인에대한검정결 과가있다. 다른 2원배치반복측정에대한통계적모델을소개하면한요인은반복측정한요인이고다른한요인은반복측정하지않은요인이다. 이런경우에는그림 4.5(b) 에 42
51 (a) 사후검정 (school) (b) 사후검정 (work) 그림 4.8: 사후검정결과 개체 내변수에반복측정한변수를추가하고 개체 간변수에반복측정하지않은변수를추가한다. 2원배치분산분석에대한 SPSS 출력결과는 개체 내변수에대한검정결과와 개체 간변수에대한검정결과를모두확인할수있다. 다음자료는 27마리쥐의체중을실험시작시 (wt0) 부터일주일마다 4주간측정하였으며쥐를 3개의그룹으로나누었는데 첫번째그룹은대조군 두번째그룹은 thiouracil을마실물에첨가 세번째그룹은 thyroxin을마실물에첨가하였다 이자료는다음과같다. group mouse wt0 wt1 wt2 wt3 wt
52
53 제 5 장 회귀분석 (regression analysis) 회귀분석은한개이상의독립변수와한개의종속변수의관계를분석하는방법이다. 회귀분석모델중단순선형회귀는종속변수와독립변수가모두한개인경우이고다중선형회귀는여러개의독립변수와한개의종속변수인것이다. 이장에서는회귀분석과정및회귀분석모델에대한성능평가, 진단등을소개한다. 1. 모형의성능평가방법중많이알려진것으로결정계수 (coefficient of determination) R 2 과수정된 (adjusted coefficient of determination) R 2 이있으며, 수정된결정계수 (adj R 2 ) 를사용하기를권장한다. 결정계수는 0 1 사이의값을가지며모델의성능을나타낸다. 만일수정된결정계수가 0.750이었다면이선형회귀모델은자료를 75% 설명한다고할수있다 ( 설정은그림 5.1(b), 결과는그림 5.3에서확인 ). 2. 분산분석 : 모든변수를분석에사용한경우 full 모델이라고하고이때모든변수의최소제곱추정치 β에대한가설검정 1 귀무가설 H 0 : β 1 = β 2 = = β p = 0 대립가설 H 1 : not H 0 ( 의미 : p 개회귀계수는적어도 1 개는 0이다.) 2 SPSS로통계적모델에대하여출력결과를얻는다. 3 연구자는 SPSS 출력결과에서유의확률을확인하여귀무가설 (H 0 ) 의기각, 채택여부를결정하고, 그결과를해석한다. 예를들어연구자가유의수준을 α = 0.05로설정하고 SPSS 출력결과유의확률이 0.007이라면귀무가설을기각하므로계수중적어도한개는 0이아니라고할수있다. 45
54 3. 계수 : 각계수마다별도로유의한지검정하는방법 ( 별도설정없으며그림 5.3에서확인 ) 1 귀무가설 H 0 : β 0 = 0 대립가설 H 1 : β 0 0( 상수계수값은 0이아니다.) 귀무가설 H 0 : β 1 = 0 대립가설 H 1 : β 1 0( 소득변수의계수값은 0이아니다.) 귀무가설 H 0 : β 2 = 0 대립가설 H 1 : β 2 0( 자녀수변수의계수값은 0이아니다.) 2 SPSS로통계적모델에대하여출력결과를얻는다. 3 연구자는 SPSS 출력결과에서유의확률을확인하여귀무가설 (H 0 ) 의기각, 채택여부를결정하고, 그결과를해석한다. 예를들어연구자가유의수준을 α = 0.05로설정하고 SPSS 출력결과각변수의계수값에대한유의확률이각각 0.069, 0.376, 0.042이라면첫번째상수와세번째자녀수변수는귀무가설을기각하지못하고두번째소득변수의계수는귀무가설을기각할수있다. 4. 유의한설명변수의선택 : 모든가능한회귀 (all possible regression), 앞으로부터선택 (forward selection), 뒤로부터제거 (backward elimination), 단계적회귀 (stepwise regression) 이있다. 모든가능한회귀 : p개의독립변수중에서일부를포함하는모든가능한회귀모형을얻어서이중가장적절한회귀모형선택 ( 그림 5.1(a) 에서입력선택 ) 앞으로부터선택 : 가장유의한독립변수부터하나씩추가하는방법 ( 그림 5.1(a) 에서전진선택 ) 뒤로부터제거 : 모두유의하다고생각되는독립변수를모형에추가한다음유의하지않은독립변수를하나씩제거 ( 그림 5.1(a) 에서후진선택 ) 단계적회귀 : 앞으로부터선택과뒤로부터제거를번갈아가면서변수를선택 ( 그림 5.1(a) 에서단계선택 ) 5. 다중공선성 (multicolinearity) 은다중회귀분석에서독립변수들사이의상 관관계가높을경우회귀계수 β i 의추정치분산이커쳐서추정량의밀도가떨 46
55 어지게된다. 다중공선성에대한척도로 VIF(variance inflation factor) 가있 으며 1 VIF k = 1 Rk 2 로계산한다. Rk 2은 x k를종속변수로 x 1, x 2,..., x k 1, x k+1,..., x p 를종속변수로 계산한결정계수이다. VIF 가 10 이상이면다중공선성을의심하고, 10 미만이 면다중공선성이없다고판단한다 ( 그림 5.1(b) 에서공선성진단선택 ). 6. 회귀분석에서이상치 (outlier) 은회귀모형에적합하였을때지나치게모형을 벗어나는것을말하고영향치 (influential data) 는회귀계수 β 나표준편차 σ 영향을주는것이다 ( 그림 5.2). 스트던트화잔차 (studentized residual) : 이상치판별에사용하며 ri = MSE (i) (1 h ii ) 로 MSE (i) 는 MSE 에서 i 번째자료를제외하고계산하였고, h ii 는 H = X(X X) 1 X 의대각원소이다. 이값이 r i > t n p 1;α/2 이면유의수준 α 에서이상치로판별한다. DFFITS i (Difference in Standardized Fit) 는회귀계수와표준편차에영 향을주는자료를판단하며 e i DFFITS i = xt i (b b (i) ) h ii MSE (i) 로계산한다. 영향력관측치는 DFFITS i > 2 p/n 을만족하는값이다. 공분산비율 (covariance ratio) 은표준편차에영향을주는관측치를판단 하며 COVRATIO i = (Xt (i) X (i) ) 1 MSE (i) X t X 1 ) MSE 로계산된다. 영향력관측치는 COVRATIO i > 3p/n 을만족하는값이 다. DFBETAS j,i (difference in betas) 는 i 번째자료를제외할때 b j(i) 와포함 할때 b j 의변화를관찰하며 로계산된다. b i b j(i) DFBETAS i = MSE (i) (X t X) 1 jj 47


 통계량")
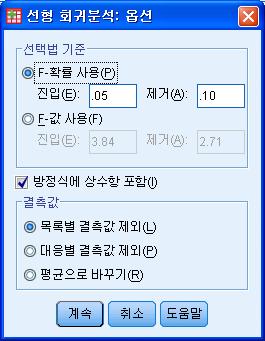
56 (a) 선도표회귀모형 (c) 도표 그림 5.1: 회귀분석설정 (b) 통계량 (d) 옵션

57 그림 5.2: 회귀분석 저장 49
58 (a) 전체모델분석결과 50 (b) 단계선택분석결과
59 제 6 장 비모수검정 (nonparametric analysis) 모집단의분포를알수없거나모집단이정규분포를따른다고가정할수없는경우에는모수적검정을사용할수없다. 이경우에자료의부호나순위로가설검정을실시하며이러한검정방법을비모수검정이라고한다 적합도검정 (goodness of fit test) 주어진자료가어떠한통계적모델을따른다고할수있는지검정하는방법으로범주형자료분석에서이미소개하였다. 이절에서주어진자료가특정한분포를따른다고할수있는지검정해보자. 이검정방법은 SPSS에서비모수검정 레거시대화상자 일표본 k-s 메뉴를선택한다. 검정방법은정규분포, 균일분포, 포아송분포, 지수분포등이있다. 1 귀무가설 H 0 : goodness of fit of a probability model ( 의미 : 어떤확률모델을따른다.) 대립가설 H 1 : not H 0 ( 의미 : 어떤확률모델을따르지않는다.) 사례 : 6.1. ( 정규성검정 ) 어떤자료가정규를따른다고할수있는지검정 해보자. 2 SPSS 로통계적모델에대하여출력결과를얻는다 ( 그림 6.1). 51
)이라면 귀무가설(H0 )를 기각한다. 따라서 주어진 자료가 정규분포 를 따르지 않는다고 할만한 통계적 근거가 있으므로 단일표본 t 검정을 사용 할 수 없고 비모수 검정을 실시해야 한다. 사례 : 6.2.")
 정규성 검정 설정 (b) 정규성 검정 결과 그림 6.1: 정규성 검정 6.2. 부호검정(sign test) 단일 집단의 분포가 정규분포를 따른다고 가정할 수 없는 경우 중앙값 θ를 θ0 로 할 수 있는지 검정하는 방법으로 SPSS에서 비모수 검정 레거시 대화 상자 이항 메뉴를 선택한다.")
60 lym.ac.kr ③ 연구자는 SPSS 출력결과에서 유의확률을 확인하여 귀무가설(H0 )의 기각, 채 택 여부를 결정한다. 예를 들어 연구자가 연구자료의 정규성을 검정하기 위 하여 유의수준을 α = 0.05로 설정하고 SPSS 출력결과 유의확률이 0.048(그 림 6.1(b))이라면 귀무가설(H0 )를 기각한다. 따라서 주어진 자료가 정규분포 를 따르지 않는다고 할만한 통계적 근거가 있으므로 단일표본 t 검정을 사용 할 수 없고 비모수 검정을 실시해야 한다. 사례 : 6.2. (정규성 검정 결과) 다음 자료는 어떤 12개 제품의 수명을 나타낸 것 이다(표 6.1). 이 자료는 정규분포를 따른다고 할 수 있는지 검정하여라. 그림 6.1의 출력결과 유의확률이 0.048이므로 이 자료는 정규분포를 따른다고 할 수 없다 al 5300 kan g 표 6.1: 정규성 검정 hm (a) 정규성 검정 설정 (b) 정규성 검정 결과 그림 6.1: 정규성 검정 6.2. 부호검정(sign test) 단일 집단의 분포가 정규분포를 따른다고 가정할 수 없는 경우 중앙값 θ를 θ0 로 할 수 있는지 검정하는 방법으로 SPSS에서 비모수 검정 레거시 대화 상자 이항 메뉴를 선택한다. 52
61 1 귀무가설 H 0 : θ = θ 0 ( 의미 : 어느집단의중앙값은 θ 0 이다.) 대립가설은다음세가지중하나를연구자가정한다. 대립가설 H 1 : θ > θ 0 ( 의미 : 어느집단의중앙값은 θ 0 보다크다.) 단측검정 대립가설 H 1 : θ < θ 0 ( 의미 : 어느집단의중앙값은 θ 0 보다작다.) 단측검정 대립가설 H 1 : θ θ 0 ( 의미 : 어느집단의중앙값은 θ 0 가아니다. 즉집단의중앙값은 0보다크거나 0보다작다 ) 양측검정사례 : 6.3. ( 부호검정 ) 표 6.1에서중앙값이 5210인지검정해보자. 귀무가설 H 0 : θ = 5210 ( 의미 : 제품수명의중앙값은 5210이다.) 이고대립가설은다음세가지중하나를연구자가정한다. 대립가설 H 1 : θ > 5210( 의미 : 제품수명의중앙값은 5210보다크다.) 대립가설 H 1 : θ < 5210( 의미 : 제품수명의중앙값은 5210보다작다.) 대립가설 H 1 : θ 5210( 의미 : 제품수명의중앙값은 5210이아니다. 즉 5210보다크거나 5210보다작다 ) 2 SPSS로통계적모델에대하여출력결과를얻는다 ( 그림 6.2). 3 연구자는 SPSS 출력결과에서유의확률을확인하여귀무가설 (H 0 ) 의기각, 채택여부를결정하고, 그결과를해석한다. 연구자가유의수준을 α = 0.05로설정하고 SPSS 출력결과유의확률 ( 양측 ) 이 0.039( 그림 6.2(b)) 라면 단측검정인경우는유의확률이 0.039/2=0.0185이므로귀무가설을기각 못하고 양측검정인경우도유의확률이 0.039이므로귀무가설을기각할수없다 표 6.2: 부호평가 53
 @h al 분포를 알 수 없는 쌍으로 된 대응 표본의 차이 검정에 사용하며 SPSS에서 비모수 검정 레거시 대화 상자 대응 2-표본 메뉴를 선택한다.")
 단측검정 kan g 대립가설 H1 : < 0(의미 : 어느 집단 차이의 중앙값은 0보다 작다.) 단측검정 대립가설 H1 : 6= 0(의미 : 어느 집단 차이의 중앙값은 0이 아니다. 즉 집단차의 중앙값은 0보다 크거나 0보다 작다) 양측검정 사례 : 6.4.")
62 lym.ac.kr (a) 부호 검정 설정 (b) 부호 검정 결과 그림 6.2: 부호 검정 6.3. Wilcoxon 부호 순위 검정(Wilcoxon signed rank al 분포를 알 수 없는 쌍으로 된 대응 표본의 차이 검정에 사용하며 SPSS에서 비모수 검정 레거시 대화 상자 대응 2-표본 메뉴를 선택한다. ① 귀무가설 H0 : = 0 (의미 : 어느 집단 차이의 중앙값은 0이다.) 대립가설은 다음 세 가지 중 하나를 연구자가 정한다. 대립가설 H1 : > 0(의미 : 어느 집단 차이의 중앙값은 0보다 크다.) 단측검정 kan g 대립가설 H1 : < 0(의미 : 어느 집단 차이의 중앙값은 0보다 작다.) 단측검정 대립가설 H1 : 6= 0(의미 : 어느 집단 차이의 중앙값은 0이 아니다. 즉 집단차의 중앙값은 0보다 크거나 0보다 작다) 양측검정 사례 : 6.4. (Wilcoxon 부호 순위 검정) 두 종류의 청량음료를 20명의 지 hm 원자에게 맛을 보게 한 다음 0에서 100점까지 점수로 평가하였다. 귀무가설 H0 : = 0 (의미 : 두 청량음료 점수 차이에 대한 중앙값은 0이 다.)이고 대립가설은 다음 세 가지 중 하나를 연구자가 정한다. 대립가설 H1 : > 0(의미 : 두 청량음료 점수 차이에 대한 중앙값은 0보 다 크다.) 54
의 기각, 채 택 여부를 결정하고, 그 결과를 해석한다. 연구자가 유의수준을 α = 0.05로 설정하고 SPSS 출력결과 유의확률(양측)이 0.042(그림 6.3(b))라면 단측검정인 경우는 유의확률이 0.")

63 lym.ac.kr 대립가설 H1 : < 0(의미 : 두 청량음료 점수 차이에 대한 중앙값은 0보 다 작다.) 대립가설 H1 : 6= 0(의미 : 두 청량음료 점수 차이에 대한 중앙값은 0이 아니다. 즉 0보다 크거나 0보다 작다) ② SPSS로 통계적 모델에 대하여 출력결과를 얻는다(그림 6.3). ③ 연구자는 SPSS 출력결과에서 유의확률을 확인하여 귀무가설(H0 )의 기각, 채 택 여부를 결정하고, 그 결과를 해석한다. 연구자가 유의수준을 α = 0.05로 설정하고 SPSS 출력결과 유의확률(양측)이 0.042(그림 6.3(b))라면 단측검정인 경우는 유의확률이 0.021이므로 귀무가설을 기각 못하고 kan al 양측검정인 경우도 유의확률이 0.042이므로 귀무가설을 기각할 수 없다. (a) Wilcoxon 부호 순위 검정 설정 (b) Wilcoxon 부호 순위 검정 결과 그림 6.3: Wilcoxon 부호 순위 검정 음료 부호순위 음료 음료 부호순위 hm 음료 1 표 6.3: 부호 순위 평가 55
64 6.4. McNemar 검정 McNemar 검정은명목형자료가 2 2 분할표로표현되는대응표본에대한검정이다. 이분석은 SPSS에서비모수검정 레거시대화상자 대응 2-표본메뉴를선택한다. 1 귀무가설 H 0 : p 12 = p 21 ( 의미 : 주변분포의확률은같다.) 대립가설 H 1 : p 12 p 21 ( 의미 : 주변분포의확률은같지않다.) 사례 : 6.5. (McNemar 검정 ) 경구용약이특별한질병에효과가있는지연구중이다. 이연구에서조사는약복용전질병유무와, 약복용후질병유무를조사하였다. 즉한사람에게두번검사하였다. 약복용전과복용후질병발병율이차이가있는지검정하자. 귀무가설 H 0 : p bp = p ap ( 의미 : 복용전질병 (bp) 발병율과복용후질병 (ap) 발병율은같다 ) 이고대립가설 H 1 : p bp p ap ( 의미 : 복용전질병 (bp) 발병율과복용후질병 (ap) 발병율은같지않다 ) 2 SPSS로통계적모델에대하여출력결과를얻는다 ( 그림 6.4). 3 연구자는 SPSS 출력결과에서유의확률을확인하여귀무가설 (H 0 ) 의기각, 채택여부를결정하고, 그결과를해석한다. 연구자가유의수준을 α = 0.05로설정하고 SPSS 출력결과유의확률 ( 양측 ) 이 ( 그림 6.4(b)) 이하이고, 양측검정인경우도유의확률이 이하이므로귀무가설을기각할수없다 Wilcoxon 순위합검정 (Wilcoxon rank sum test, Mann Whitney U test) 모수검정에서독립인두표본에대한검정은독립표본 t 검정을하였다. 그러나서로독립인두표본검정에서분포를모르거나분포의독립성을보장할수없을 때에는 Wilcoxon 순위합검정을실시해야한다. 이검정방법은 SPSS 에서비모수 검정 레거시대화상자 독립 2- 표본메뉴를선택하여분석할수있다. 1 귀무가설 H 0 : θ 1 = θ 2 ( 의미 : 두집단의순위평균은같다.) 대립가설 H 1 : θ 1 θ 2 ( 의미 : 두집단의순위평균은같지않다 ) 56
이고 대립가설 H1 : θ1 6= θ2 (의미 : 두 식이요법의 순위 평균은 다르다.) ② SPSS로 통계적 모델에 대하여 출력결과를 얻는다.")

65 lym.ac.kr (a) McNemar 검정 설정 (b) McNemar 검정 결과 그림 6.4: McNemar 검정 사례 : 6.6. (Wilcoxon 순위합 검정) 두 식이요법 A와 B를 실시한 후, al 중의 증가율을 조사한 자료이다(그림 6.5(a)). 두 가설은 귀무가설 H0 : θ1 = θ2 (의미 : 두 식이요법의 순위 평균은 같다.)이고 대립가설 H1 : θ1 6= θ2 (의미 : 두 식이요법의 순위 평균은 다르다.) ② SPSS로 통계적 모델에 대하여 출력결과를 얻는다. ③ 연구자는 SPSS 출력결과에서 유의확률을 확인하여 귀무가설(H0 )의 기각, 채 kan g 택 여부를 결정하고, 그 결과를 해석한다. 연구자가 유의수준을 α = 0.05로 설정하고 SPSS 출력결과 유의확률이 0.015(그 림 6.5(b)) 이므로 귀무가설을 기각한다. 즉 두 집단의 식이요법 결과 체중 증 가율이 다르다고 할 수 있다. 식이요법 hm 체중증가율 순위 식이요법 체중증가율 순위 A 방법 A 방법 A 방법 A 방법 A 방법 A 방법 B 방법 B 방법 B 방법 B 방법 B 방법 B 방법 B 방법 표 6.4: 순위합에서 순위 평가 57

 사례 : 6.7. (Kruskal Wallis 검정) 독일어 교육을 서로 다른 세 개의 집단 으로 나누고 교육이 끝난 후 시험을 보았다.")
66 lym.ac.kr (a) Wilcoxon 순위합 검정 설정 (b) Wilcoxon 순위합 검정 결과 그림 6.5: Wilcoxon 순위합 검정 6.6. Kruskal Wallis al 서로 독립인 세 지단 이상의 평균 비교는 분산분석으로 하였다. 그러나 정규성을 보장할 수 없어서 분포를 알 수 없는 경우에는 Kruskal Wallis 검정으로 세 집단의 분포비교를 한다. 이 분석방법은 서로 독립인 세 집단 이상에서 집단별 순위 평균 을 비교하는 검정방법이다. 순위는 모든 집단에 전체 순위를 계산하여 각 집단의 순위 비교로 SPSS에서 비모수 검정 레거시 대화 상자 독립 k-표본 메뉴를 선 택한다. kan g ① 귀무가설 H0 : θ1 = θ2 = = θk (의미 : k 집단의 순위 평균은 같다.) 대립가설 H1 : not H0 (의미 : k 집단 중 순위 평균이 같지 않은 집단이 있다.) 사례 : 6.7. (Kruskal Wallis 검정) 독일어 교육을 서로 다른 세 개의 집단 으로 나누고 교육이 끝난 후 시험을 보았다. 각 집단은 1은 교실에서 수업과 회화 실습실에서 실습을 병행 hm 2는 교실에서 수업 3은 학생 스스로 공부한 경우 두 가설은 귀무가설 H0 : θ1 = θ2 = θ3 (의미 : 세 집단 순위 평균은 같다.)이고 대립가설 H1 : not H0 (의미 : 세 집단 중 순위 평균이 같지 않는 집단이 있다.) ② SPSS로 통계적 모델에 대하여 출력결과를 얻는다(그림 6.6). 58
) 이므로 귀무가설을 기각한다. 즉 세 집단의 순위 평균은 모두 같다 @h al 고 할 수 없다. (a) Kruskal Wallis 검정 설정 (b) Kruskal Wallis 검정 결과 그림 6.")

67 lym.ac.kr ③ 연구자는 SPSS 출력결과에서 유의확률을 확인하여 귀무가설(H0 )의 기각, 채 택 여부를 결정하고, 그 결과를 해석한다. 연구자가 유의수준을 α = 0.05로 설정하고 SPSS 출력결과 유의확률이 0.035(그 림 6.6(b)) 이므로 귀무가설을 기각한다. 즉 세 집단의 순위 평균은 모두 al 고 할 수 없다. (a) Kruskal Wallis 검정 설정 (b) Kruskal Wallis 검정 결과 그림 6.6: Kruskal Wallis 검정 독립인 세 표본 순위 대응된 세 표본 순위 집단 1 집단 2 집단 3 ID 집단 1 집단 2 집단 kan g ID hm 표 6.5: 독립 표본과 대응 표본의 순위 평가 6.7. Cochran Q 검정 세 집단 이상의 대응 표본에서 관측할 수 있는 값이 성공, 실패와 같이 두 개인 경 우 각 집단의 비율이 같은지 비교하는 분석방법이다. 이 분석은 SPSS에서 비모수 검정 레거시 대화 상자 대응 k-표본 메뉴를 선택한다. 59
이고 대립가설 H1 : not H0 (의미 : 세 집단 중 성공 비율이 같지 않는 집단이 있다.) ② SPSS로 통계적 모델에 대하여 출력결과를 얻는다(그림 6.7).")
68 lym.ac.kr ① 귀무가설 H0 : p1 = p2 = = pk (의미 : k 집단의 성공 비율은 모두 같다.) 대립가설 H1 : not H0 (의미 : k 집단 중 성공 비율이 같지 않은 집단이 있다.) 사례 : 6.8. (Cochran Q 검정) 직물원단을 4 가지 방법으로 가공하여 방수 원단을 만들려고 한다. 6 종류의 원단으로 효율성을 검사하였으며 만족하면 1, 그렇지 않으면 0으로 평가하였다. 두 가설은 귀무가설 H0 : p1 = p2 = p3 (의미 : 세 집단의 성공 비율은 같다.)이고 대립가설 H1 : not H0 (의미 : 세 집단 중 성공 비율이 같지 않는 집단이 있다.) ② SPSS로 통계적 모델에 대하여 출력결과를 얻는다(그림 6.7). ③ 연구자는 SPSS 출력결과에서 유의확률을 확인하여 귀무가설(H0 )의 기각, al 택 여부를 결정하고, 그 결과를 해석한다. 예를 들어 연구자가 유의수준을 α = 0.05로 설정하고 SPSS 출력결과 유의확률이 0.025(그림 6.7(b)) 이므로 귀무가설을 기각한다. 즉 세 집단의 성공 비율은 kan g 모두 같지 않다고 할 수 있다. (a) Cochran Q 검정 설정 (b) Cochran Q 검정 결과 hm 그림 6.7: Cochran Q 검정 6.8. Friedman 검정 세 집단 이상의 대응 표본의 중앙값을 비교하는 분석방법이다. 모수 검정에서 반복측정 분산분석(repeated measures ANOVA)이 있다. 이 분석 방법은 각 블 록(block)마다 순위를 계산하여 각 집단의 순위를 비교한다. 이 분석 방법은 SPSS 에서 비모수 검정 레거시 대화 상자 대응 k-표본 메뉴를 선택한다. 60
이고 대립가설 H1 : not H0 (의미 : 세 집단중 순위 평균이 같지 않는 집단이 있다.) ② SPSS로 통계적 모델에 대하여 출력결과를 얻는다(그림 6.8).")
69 lym.ac.kr ① 귀무가설 H0 : θ1 = θ2 = = θk (의미 : k 집단의 순위 평균은 같다.) 대립가설 H1 : not H0 (의미 : k 집단 중 순위 평균이 같지 않은 집단이 있다.) 사례 : 6.9. (Friedman 검정) 8 마리의 쥐에게 0, 24, 72 시간 동안 굶기고 음식을 주었을 때 음식 소비량을 조사하였다. 굶긴 시간에 따라 음식 소비량 이 차이가 있는지 검정해 보자. 두 가설은 귀무가설 H0 : θ1 = θ2 = θ3 (의미 : 세 집단의 순위 평균은 같다.)이고 대립가설 H1 : not H0 (의미 : 세 집단중 순위 평균이 같지 않는 집단이 있다.) ② SPSS로 통계적 모델에 대하여 출력결과를 얻는다(그림 6.8). ③ 연구자는 SPSS 출력결과에서 유의확률을 확인하여 귀무가설(H0 )의 기각, al 택 여부를 결정하고, 그 결과를 해석한다. 연구자가 유의수준을 α = 0.05로 설정하고 SPSS 출력결과 유의확률이 0.001(그 림 6.8(b)) 이므로 귀무가설을 기각한다. 즉 세 집단의 순위 평균은 모두 같지 kan g 않다고 할 수 있다. hm (a) Friedman 검정 설정 (b) Friedman 검정 결과 그림 6.8: Friedman 검정 61
70
71 제 7 장 범주형자료분석 자료의종류가몇개의범주로나누어진것을범주형자료라고부른다. 범주형자료에는 명목형자료 (nominal data) : 범주에가중치가없는자료 ( 예 : 남자, 여자 ; 강원도, 경기도, 충청도등 ) 순위형자료 (ordinal data) : 범주에가중치가있는자료 ( 예 : 상류층, 중류층, 하류층 ; 1급, 2급, 3급등 ) 이있으며, 자료의형태에따라분석방법이다른것들도있다 적합도검정 (goodness of fit test) 이검정법은통계적모델에자료가적합한지 Pearson χ 2 검정한다. 이경우각셀의값, 즉각해당범주의값이 5이상되어야근사확률이정확한확률에근접하며그렇지않은경우에는유의확률에대한보장이어렵다. 1 귀무가설 H 0 : goodness of fit of a probability model ( 의미 : k개범주의비율 은 p 1 = p 10, p 2 = p 20,..., p k = p k0 이다.) 대립가설 H 1 : not H 0 ( 의미 : k개범주의비율은 p 1 = p 10, p 2 = p 20,..., p k = p k0 가아니다.) 사례 : 7.1. ( 적합도검정 ) 어떤나무의자가수정결과로나올수있는유전형태가세종류일때생물학에서유전적비율이 1 : 2 : 1로알려져있을때 100 개의나무에대하여적합도검정을실시해보자. 63
72 귀무가설 H 0 : p 1 = 0.25 : p 2 = 0.5 : p 3 = 0.25 ( 의미 : 나무의유전적비율은 1:2:1) 이고대립가설은 H 1 : not H 0 ( 나무의유전적비율은 1:2:1 이아니다.) 2 SPSS로통계적모델에대하여출력결과를얻는다 ( 그림 7.1). 3 연구자는 SPSS 출력결과에서유의확률을확인하여귀무가설 (H 0 ) 의기각, 채택여부를결정하고, 그결과를해석한다. 사례 : 7.2. ( 적합도검정결과 ) 연구자가유의수준을 α = 0.05로설정하고 SPSS 출력결과유의확률이 0.27이라면 유의확률이 0.27이므로귀무가설을기각못하므로나무의자가수정비율은통계적으로 1:2:1이라고할수있다 독립성검정 독립성검정 (independence test) 은두집단이서로독립인지검정한다. 1 귀무가설 H 0 : P [i, j] = P [i] P [j] for all i, j ( 의미 : 두변수는서로독립이다.) 대립가설 H 1 : not H 0 ( 의미 : 두변수는서로독립이아니다.) 사례 : 7.3. ( 독립성검정 ) 텔레비젼에방송되는오락물에대한사람들의의견이성별과관련있는지알아보려고 1250명을임의추출하여성별 ( 남성, 여성 ) 과오락물방영 ( 너무많다, 적당하다, 너무적다 ) 에대한의견을조사하였다. 성별에따른오락불방영에의견은서로연관성이있다고할수있는가? 귀무가설 H 0 : P [i, j] = P [i] P [j] for i = 1, 2j = 1, 2, 3 ( 의미 : 성별에따라 오락물방영에대한의견은서로관련없다.) 대립가설은 H 1 : not H 0 ( 성별에따라오락물방영에대한의견은서로관련있다.) 2 SPSS로통계적모델에대하여출력결과를얻는다 ( 그림 7.2). 3 연구자는 SPSS 출력결과에서유의확률을확인하여귀무가설 (H 0 ) 의기각, 채택여부를결정하고, 그결과를해석한다. 64

")
")
 출력결과")
73 al (b) 가중치 설정 kan g (a) 적합도 분석 메뉴 hm (c) 검정변수와 기대값 설정 (d) 출력결과 그림 7.1: 적합도 검정 65
74 사례 : 7.4. ( 독립성검정결과 ) 연구자가유의수준을 α = 0.05 로설정하고 SPSS 출력결과 유의확률이 0.270( 그림 7.2(f)) 이므로귀무가설을기각못하므로성별에 따른오락물방영비율은서로독립이다고할수있다. 독립성검정에서두변수의범주가모두두개일때, 즉 2 2 인경우두변수의연 관성 (association) 의척도로승산비 (odds ratio) 가있다. 승산 (odds) 은어떤실험에 서성공일확률을 p라할때 odds = p 1 p 이며, 승산이주어졌을때성공확률은 p = odds 1 + odds 이다. 두변수의성공일확률이 p 1, p 2 일때승산비는 p 1 1 p 1 odds 1 p 2 = odds 2 1 p 2 이다. 또한두변수에대한상대위험도 (relative risk) 는 p 1 = odds ratio 1 p 2 p 2 1 p 1 이다. 상대위험도는한변수에대하여두범주의성공비율을비교할수있을때는 명확한설명을제시한다. 예를들어남자의음주율과여자의음주율이몇배가차 이가있는지알아보려면쉽게계산되며그의미도이해할수있다. 그러나이값은 분모값에제약이있기때문에많이사용되지않는다. 그예로분모의확률이 0.5 라 면분자의최대값이 1 이고이값은 = 2 를넘을수없는단점이있다. 반면승산비는각승산 ( 성공비율 / 실패비율 ) 의비율을제시하기때문에직관적 인해석이어려울수있다. 그러나승산비 OR 은근사적으로평균이 log(or) 이고 분산이 σ 2 인정규분포를따른다고알려져있기때문에통계적유의성을평가할수 있다. 두그룹의승산이같다면승산비는 1 이다. 따라서승산비에대한귀무가설 H 0 : odds 1 = 1로설정한다. odds 2 X N(log(OR), σ 2 ) 위식에표준오차 (standard error) 는근사적으로 1 S.E = n 11 n 12 n 21 n 22 로알려져있다. 66
 가중치")

")
 셀에 출력값")

75 lym.ac.kr (b) 가중치 al (a) 독립성 검정과 가중치 (d) 카이제곱 통계량 hm kan g (c) 행과 열에 변수 입력 (e) 셀에 출력값 설정 (f) 출력결과 그림 7.2: 독립성 검정 67
76 사례 : 7.5. ( 오즈비검정 ) 음주율이남녀별연관성이있는지알아려고각성별마 다 100명씩조사한결과남자는 80명이지난주음주하였고여자는 30명이음주하 였다고하자 ( 표 7.1). 이때남여별음주가연관성이있는지알아보고만일연관성 이있다면얼마만큼차이가있는지알아보자. 지난주음주여부 음주 금주 합계 성별 남자 여자 합계 표 7.1: 승산비 1 귀무가설 H 0 : odds 1 = 1 odds 2 대립가설 H 1 : odds 1 1 odds 2 2 SPSS로통계적모델에대하여출력결과를얻는다 ( 그림 7.3). 승산비설정는독립성검정단계중그림 7.2(d) 에서위험도메뉴를선택한 다 ( 그림 7.3). 3 그림 7.3(b) 에표 7.1 자료의출력결과가있으며남자음주율과여자음주율에 대한승산비는 9.333이며이통계량에대한 95% 신뢰구간은 (4.870, ) 이 다. 만일두승산비가통계적으로같다면신뢰구간에 1을포함할것이고같 지않다면 1을포함하지않을것이다. SPSS에서는유의확률을제공하지않 기때문에확인할수없으므로직접구해보면 [ ] 1 P Z log(9.333) = P [Z 6.731] = 이며, 통계적으로승산비가 1이아니라고할만큼매우큰유의성을가진다. 주어진변수가 3 개이고 2 2 k 인범주형자료에대하여알아보자. 이경우는 2 2 보 다분석할것이 68

, 통계량 설정은 그림 7.4(b)를 참 조한다. hm 각 도시별 2 2에 대한 분할표(그림 7.4(c)) 각 도시도시별 2 2에 대한 독립성 검정(그림 7.")
77 lym.ac.kr (a) 승산비 설정 (b) 승산비 출력결과 그림 7.3: 승산비 al k 개 집단별 2 2에 대한 분할표 k 개 집단별 2 2에 대한 독립성 검정 k 개 집단별 2 2에 대한 승산비 검정 전체 승산비에 대한 동질성 검정 전체 승산비에 대한 독립성 검정 kan g 전체 공통 승산비에 검정 이다. 다음 예를 보자. 사례 : 7.6. (오즈비 검정(2 2 k)) )중국 8개 도시를 대상으로 흡연과 폐암에 대 한 자료이다. 이 분석에 변수 설정은 그림 7.4(a), 통계량 설정은 그림 7.4(b)를 참 조한다. hm 각 도시별 2 2에 대한 분할표(그림 7.4(c)) 각 도시도시별 2 2에 대한 독립성 검정(그림 7.4(d)) 각 도시별 2 2에 대한 승산비 검정(그림 7.4(e)) 전체 승산비에 대한 동질성 검정(그림 7.4(f)) 전체 승산비에 대한 독립성 검정(그림 7.4(f)) 전체 공통 승산비에 검정(그림 7.4(f)) 69
 각집단의승산비 (f) 레이어전대상의통계량 그림 7.")
78 (a) 각집단을레이어에추가 (c) 분할표출력 (b) 통계량설정 (d) 각집단의카이제곱통계량 (e) 각집단의승산비 (f) 레이어전대상의통계량 그림 7.4: 승산비검정 (2 2 k) 70
79 7.3. 동일성검정 동일성검정 (homogeneity test) 은반응변수집단의범주에대하여모집단을부그룹 (subgroup) 로나눈경우부그룹의비율이모두같은지검정한다. 1 귀무가설 H 0 : P A1 = P B1,..., P Ak = P Bk ( 의미 : k 개반응변수마다부그룹 (A, B) 의비율은모두같다.) 대립가설 H 1 : not H 0 ( 의미 : k 개반응변수마다부그룹 (A, B) 의비율은같지않다.) 사례 : 7.7. ( 동일성검정 ) 두가지식이요법을비교하기위하여 150명환자를임의로두집단으로 80명과 70명으로나눈후한집단에는식이요법 A를다른집단에는식이요법 B를적용한후건강상태를세가지범주 ( 좋음, 보통, 않좋음 ) 로나누었을때환자의건강상태에따른식이요법비율이같은지검정해보자. 귀무가설 H 0 : P A1 = P B1, P A2 = P B2, P A3 = P B3 ( 의미 : 환자의건강상태에따른식이요법비율은모두같다.) 대립가설은 H 1 : not H 0 ( 환자의건강상태의마다식이요법비율은모두같지않다.) 2 SPSS로통계적모델에대하여출력결과를얻는다 ( 출력과정은독립성검정과같음 ). 3 연구자는 SPSS 출력결과에서유의확률을확인하여귀무가설 (H 0 ) 의기각, 채택여부를결정하고, 그결과를해석한다. 사례 : 7.8. ( 동일성검정결과 ) 연구자가유의수준을 α = 0.05로설정하고 SPSS 출력결과유의확률이 0.16이라면 유의확률이 0.16이므로귀무가설을기각못하므로통계적으로환자의건강상태의범주비율은식이요법마다모두같다고할수있다 likelihood ratio test 우도비검정 (likelihood ratio test) 은귀무가설 H 0 와대립가설 H 1 의두모델의적 합성을비교하는통계적가설검정법으로범주형자료에서도당연히적합도를검정 71
80 할수있다. 통계적모델에대한적합성을검정하기위한검정통계량을 deviance 라 고하며이값은 D = 2 log ( LH0 L max 로나타낸다. 여기서 L은우도함수 (likelihood function) 이며통계량은 χ 2 (df) 분포를따른다. 여기서가설은부모집단 (subgroup) 에대하여 1 귀무가설 H 0 : goodness of fit of a probability model ( 의미 : k개범주의비율은 p 1 = p 10, p 2 = p 20,..., p k = p k0 이다.) 대립가설 H 1 : not H 0 ( 의미 : k개범주의비율은 p 1 = p 10, p 2 = p 20,..., p k = p k0 가아니다.) 사례 : 7.9. ( 우도비검정 ) 표 7.2에우도비를검정할자료로각범주는근로자의독소노출상태와천식증상이다. 독소노출에따라천식증상이연관이있다고할수있는가? 독소노출없음보통강함천식증상없음 있음 표 7.2: 우도비검정 2 SPSS로통계적모델에대하여출력결과를얻는다 ( 출력과정은독립성검정과같음 ). 표 7.2에서 L H0 는 L(p, p, p) = pq 9 p 2 q 3 p 7 q 3 = p 10 q 15 이고 L Hmax 는 L(p 1, p 2, p 3 ) = p 1 q1 9 p 2 2q2 3 p 7 3q3 3 ( ) LH0 이다. 여기서 p 1 = 0.1, p 2 = 0.4, p 3 = 0.7이다. 따라서 log L max 는 log L H0 log L max = 10 log p + 15 log q (log log log log log log 0.3) = ) 72
81 여기서 p = 15 25, q = 이다. 따라서 deviance likelihood χ2 통계량은 χ 2 = 2 ( ) = 이며, 이때유의확률은 이다. SPSS로실행해보면이값이같음을확인할수있다. 3 유의확률이 이므로귀무가설을기각한다. 따라서천식정도는독소노출정도에따라다르다고할수있다. SPSS에서분석과정및출력결과는독립성검정과같으므로생략한다 linear by linear association 선형대선형결합 (linear by linear association) 은범주형자료가순위형 (ordinal) 자료인경우두변수에대한연관성을검정한다. 이경우 Pearson χ 2 과는달리셀의갯수가 5보다작더라도관계없다는면에서유용하게사용할수있다. 이분석방법은로그선형모델에서계수에대한검정으로통계적인모델은 log µ ij = λ + λ X i + λ Y j + βu i v j 이며, 각범주는 u 1 u 2 u I, v 1 v 2 v I 이다. 분석과정은 1 귀무가설 H 0 : β = 0 ( 의미 : 두범주는서로연관성이없다.) 대립가설 H 1 : β 0 ( 의미 : 두범주는서로연관성이있다.) 사례 : ( 선형대선형결합 ) 표 7.3에 10대여성의출생제한과미성년자성관계에대한조사결과가있다. 10대여성의출생제한과미성년자성관계가서로연관성이있는지알아보자. 2 SPSS로통계적모델에대하여출력결과를얻는다 ( 출력과정은독립성검정 과같음 ). 3 분석결과유의확률이 미만이므로귀무가설을기각한다. 즉 10대여성의출생제한과미성년자성관계는의견은서로연관성이있다고할수있다. SPSS 에서분석과정및출력결과는독립성검정과같으므로생략한다. 73
82 미성년자성관계 10 대출생제한매우반대반대찬성매우찬성 항상잘못됨 거의잘못됨 가끔잘못됨 전혀잘못없음 표 7.3: 선형대선형결합
83 제 8 장 표본수 (sample size) 구하기 현재각분야에서연구자가주장하려는가설을입증하려면많은경우에있어서표본을추출하여예전연구결과와현재연구결과가차이가있는지또는대조군과처리군이다른지통계분석을실시한다. 이때표본을어느정도추출해야통계적신뢰도를보장받는가가주된관심이다. 이장에서는표본수를계산하는방법에대하여소개한다. 표본수를계산하는프로그램은 연구논문 연구논문 통계프로그램 ( 무료 ) 통계프로그램 ( 무료 ) SPSS SamplePower 통계프로그램 ( 유료 ) 등이있다. 통계적가설검정계산에사용하는몇가지용어를소개하고그림 8.1에나타내었다. 귀무가설 (null hypothesis;h 0 ) : 이미전에연구자가입증한가설대립가설 (alternative hypothesis;h 1 ) : 연구자가연구결과입증하려는가설로귀무가설이아닌가설 75
84 유의수준 (significance level;α) : 연구자가귀무가설이옳은데도잘못하여귀무가설을기각하는오류의최대허용한계의확률로많은경우 0.05로설정기각역 (rejection region for H 0 ) : 유의수준에서귀무가설을기각하는영역유의확률 (probability value) : 데이터에서구한검정통계량이귀무가설이옳은데도잘못하여귀무가설을기각하는오류의확률검정통계량 (test statistic) : 귀무가설의기각, 채택여부판정할때사용하는통계량으로관측한데이터에서계산제 1종의오류 (type I error; α) : 유의수준과동일한의미제 2종의오류 (type II error;β) : 귀무가설이옳지않을때귀무가설을기각하지않는오류의확률검정력 (power;1 β) : 귀무가설이옳지않을때귀무가설을기각하는오류의확률 H 0 : µ = µ 0 β H 1 : µ = µ a µ 0 µ a acceptance region for H 0 rejection region for H 0 σ c = µ 0 + z α n σ = µ a z β n 그림 8.1: H 1 : µ > µ 0 일때 사례 : 8.1. ( 단일표본평균검정 ) 초콜렛제품의무게는평균 260g, 표준편차가 10g으로알려져있다. 이초콜렛은두개의공장에서만든다고하자. 각공장마다 20개씩표본을추출한결과, A 공장에서만든초콜렛의평균이 262.9g 이었고, B 공장은 264.7g 이었다. 각공장에서만든초콜렛은평균이 260g이라고할수있는가? 아니면 260g보다크다고할수있는가? 위에서주어진모수와통계량으로계산한결과가그림 8.2에있다. 여기서초콜렛의무게가 260g 보다크다고할수있는값, 즉통계적으로유의하다고판단할수 α 76
85 있는기각역은과자의평균무게가 264.7g 보다크면되겠다. 따라서 A 공장은통계 적으로유의하지않고, B 공장은통계적으로유의하다. 즉 A 공장의초콜렛평균 는예전평균 260g 보다크다고할수없고, B 공장의초콜렛평균 은예 전평균 260g 보다크다고할수있다 그림 8.2: H 1 : µ > µ 0 일때 8.1. 단일표본평균에대한표본수 단일표본인경우평균에대하여관심이있을때표본수를구하는방법에대하여알 아보자. 귀무가설 H 0 : µ = µ 0 vs 대립가설 H 1 : µ µ 0 일때, 즉양측검정 (two sided) 인경우표본수는 제 1 종의오류 (type I error, α) 만고려하는경우는 로구할수있다. 여기서 z 1 α/2 는정규분포분위수, α 는제 1 종의오류 σ 는표준편차 n = z2 1 α/2 σ2 d 2 (8.1) d = X µ 는표본평균 ( X) 과모집단의평균 (µ) 차 이다. 제 1 종의오류 (type I error, α) 와제 2 종의오류 (type II error, β) 모두고려 할때정규분포를사용하는경우에는 n = (z 1 α/2 + z 1 β ) 2 σ 2 (µ 0 µ a ) 2 (8.2) 77
86 로구할수있다. 여기서 z 1 α/2 는정규분포분위수, α 는제 1 종의오류 z 1 β 는정규분포분위수, β 는제 2 종의오류 σ 는표준편차 µ 0 는귀무가설 H 0 에서설정한평균, µ a 는대립가설 H 1 에서설정한평균 이다. 그림 8.3 에는모집단이정규분포라고가정할때, α 와 β 를모두고려한 경우의기각역과채택역을나타내었다. H 1 : µ = µ a H 0 : µ = µ 0 H 1 : µ = µ a α/2 β α/2 µ a µ 0 µ a rejection region for H 0 acceptance region for H 0 rejection region for H 0 t 분포로표본수계산은 이다. 여기서 c 그림 8.3: H 1 : µ µ 0 일때 c n = (t n 1;1 α/2 + t n 1;1 β ) 2 S 2 (µ 0 µ a ) 2 (8.3) t n 1;1 α/2 는 t 분포분위수, α 는제 1 종의오류 t n 1;1 β 는 t 분포분위수, β 는제 2 종의오류 S 는표준편차 µ 0 는귀무가설 H 0 에서설정한평균, µ a 는대립가설 H 1 에서설정한평균 이다. 정규분포분위수 z 1 α/2, z 1 β 와 t 분포분위수 t n 1;1 α/2, t n 1;1 β 는엑셀을이용 하여구할수있다. 엑셀에서정규분포분위수계산은 78
87 NORMSINV(probability) 함수이며, 입력값은 probability : 확률 이다. 양측검정에서유의수준 α = 0.05 로설정하였으면 z 1 α/2 = z 이므로다 음과같이입력하여구한다. =NORMSINV(0.975) t 분포분위수계산은 TINV(probability, d.f ) 함수이며, 입력값은 probability : 확률로입력할확률이 p 이면 (1 p) 2 를입력한다. d.f : 자유도 이다. 단일표본양측검정에서유의수준 α = 0.05 이고자료수가 10 개이면 t n 1;1 α/2 = t 0.975,9 이므로확률은 이고 ( ) 2 = 0.05 로계산하여다음과같이 입력한다. =TINV(0.05,9) t 분포인경우표본수 n 이양변에모두포함되어있기때문에직접계산을어 렵고수치해석방법으로해를구할수있다. 엑셀을사용하는경우에는목표값찾 기로구하고 ( 그림 8.4) 통계프로그램 R 에서는 power.t.test 함수를사용한다. 이 함수를사용한예는사례 : 8.2 에있다. 귀무가설 H 0 : µ = µ 0 vs 대립가설 H 1 : µ > µ 0 일때, 즉단측검정 (one sided) 인 경우표본수는 n = (z 1 α + z 1 β ) 2 σ 2 (µ 0 µ a ) 2 (8.4) 로구할수있다. 귀무가설 H 0 : µ = µ 0 vs 대립가설 H 1 : µ < µ 0 인경우도식 (8.4) 에서구한표본수계산식과동일하다. 만일선행연구가없는경우는단측검정결과보다양측검정결과를사용하는 것이적합하다고할수있다. 그래서이후에소개하는표본수는양측검정만소개 하고단측검정은소개하지않았다. 만일단측검정으로표본수를구하려면 α/2 값 을 α 로대치하여계산하면된다. 79
88 사례 : 8.2. ( 단일표본평균의표본수 ) 환자를대상으로한연구에서처음 MMSE 의복용전과복용후차이의평균이 3.3 점으로알려져있다. 이때복용전점수와 복용후점수차이에대한표준편차는 5.1, 유의수준 α = 0.05, 검정력 1 β = 0.8 일 때표본수는얼마인가? 식 (8.2) 의정규분포로구하면 n = ( ) = 계산결과 19 명이상표본을추출하면된다. 식 (8.3) 의 t 분포로구하면 n = (t n 1;1 0.05/2 + t n 1;0.8 ) = (8.5) 계산결과 21 명이상표본을추출하면된다. 계산식 (8.5) 에서표본수 n 이등식의양 쪽에모두포함되어있어서직접계산은어렵고다음과같이컴퓨터로계산한다. 첫번째, 엑셀로 t 분포의표본수계산은목표값찾기를사용한다. 이메뉴는 수치해석중 Newton Rapshon 방법으로해를구하는것으로, 예를들어 f 1 (x) = x 1, f 2 (x) = (x 1) 2 두식의해를구할때 f 1 (x) f 2 (x) < 10 4 조건을만족하 는값 x 를해로찾는것이다. 1. 주어진조건및계산식은그림 8.4 을참조하여엑셀에다음과같은순서로입 력한다. 유의수준 α = 0.05 : A9 셀에 0.05 입력한다. 제 2 종의오류 (1 검정력 )β = 0.2 : B9 셀에 0.2 입력한다. t 분포분위수 t n 1;1 0.05/2 : C9 셀에 =TINV(A9,H9-1) 입력한다. 엑셀 에서 t 분포분위수값은확률이 p 일때 (1 p) 2 를입력하므로확률 이 /2 = 일때 ( ) 2 값 0.05 를입력한다. t 분포분위수 t n 1;0.8 : D9 셀에 =TINV(B9*2,H9-1) 을입력한다. 검정력 이 0.8 이므로 (1 0.8) 2 값 0.4 를입력한다. 표준편차 s = 5.1 : E9 셀에 5.1 입력한다. 귀무가설 대립가설 δ = 3.3 : F9 셀에 3.3 입력한다. 계산식 (8.5) 의왼쪽값 n : G9 셀에초기값 3 을입력한다. 주의사항으로 계산식 (8.5) 의왼쪽값 n 은표본수를찾기위한초기화값으로 t 분포 에서자유도를 3 이상권장한다. 80
89 계산식 (8.5) 의가운데식 : 식 (8.3) 에해당값을입력한다. H9 셀에는셀참조하여 =(C9+D9)^2*E9^2/F9^2를입력한다. 그림 8.4(a) 의수식입력줄에서확인할수있다. 왼쪽 n 가운데식 : I9 셀에 =ABS(G9-H9) 입력한다. 여기서계산식 (8.5) 의가운데식과 왼쪽 n 가운데 값은각값을직접입력하지않고이미입력된각셀의값을셀참조 1 하여입력한다. 2. 데이터 데이터도구 가상분석 목표값찾기메뉴선택 ( 그림 8.4(a)) 3. 목표값찾기창에 (a) 수식셀에는 왼쪽 n 가운데식 인 H9 클릭한다. (b) 찾는값에는두식의차이 0을입력한다. (c) 값을바꿀셀에는구할표본수 n인 G9를클릭한다. (d) 확인버튼을클릭한다 ( 그림 8.4(a)). 4. 그림 8.4(b) 에서목표값을찾은결과를확인할수있다. 두번째는통계자료분석프로그램인 R로표본수를계산하였다. > power.t.test(sd=5.1,delta=3.3,type="one.sample", alternative="two.side",power=.8,sig.level=0.05) One-sample t test power calculation n = delta = 3.3 sd = 5.1 sig.level = 0.05 power = 0.8 alternative = two.sided 1 다른셀에입력된값을현재셀에서작업중클릭하여해당셀의값을참조하는것을말한다. 예 로 A1 셀에 4 가입력되었을때 B1 셀에 = 입력후 A1 셀을클릭하면 B1 셀에 4 가나타난다. 81

2 이다.")
90 al (a) 엑셀 목표값 찾기 설정 kan g (b) 엑셀 목표값 찾기 결과 그림 8.4: 엑셀 목표값 찾기 8.2. 독립인 두 표본 평균 차이에 대한 표본수 독립인 두 표본의 평균 차이에 대한 표본수는 귀무가설 H0 : µ1 µ2 = 0 vs 대립가설 H1 : µ1 µ2 6= 0일 때, 즉 양측검정(two sided)인 경우 정규분포로 계산하면를 사 hm 용한 표본수는 n= (σ1 + σ2 )2 (z1 α/2 + z1 β )2 (µ1a µ2a )2 이다. 여기서 z1 α/2 는 정규분포 분위수, α는 제 1종의 오류 z1 β 는 정규분포 분위수, β는 제 2종의 오류 σ1 과 σ2 는 각 집단의 표준편차 82 (8.6)
abstract.dvi
 통계자료분석 강희모 2014년 5월 14일 목차 제 1장 여러가지평균비교 1 1.1. 단일표본검정.............................. 2 1.2. 독립인두표본검정........................... 4 1.3. 대응표본검정.............................. 9 제 2 장 분산분석(ANalysis Of VAriance)
통계자료분석 강희모 2014년 5월 14일 목차 제 1장 여러가지평균비교 1 1.1. 단일표본검정.............................. 2 1.2. 독립인두표본검정........................... 4 1.3. 대응표본검정.............................. 9 제 2 장 분산분석(ANalysis Of VAriance)
제 1 절 two way ANOVA 제1절 1 two way ANOVA 두 요인(factor)의 각 요인의 평균비교와 교호작용(interaction)을 검정하는 것을 이 원배치 분산분석(two way ANalysis Of VAriance; two way ANOVA)이라
의 각 요인의 평균비교와 교호작용(interaction)을 검정하는 것을 이 원배치 분산분석(two way ANalysis Of VAriance; two way ANOVA)이라") 제 절 two way ANOVA 제절 two way ANOVA 두 요인(factor)의 각 요인의 평균비교와 교호작용(interaction)을 검정하는 것을 이 원배치 분산분석(two way ANalysis Of VAriance; two way ANOVA)이라고 한다. 교호작용은 두 변수의 곱에 대한 검정으로 유의확률이 의미있는 결과라면 두 변수는 서로 영향을
제 절 two way ANOVA 제절 two way ANOVA 두 요인(factor)의 각 요인의 평균비교와 교호작용(interaction)을 검정하는 것을 이 원배치 분산분석(two way ANalysis Of VAriance; two way ANOVA)이라고 한다. 교호작용은 두 변수의 곱에 대한 검정으로 유의확률이 의미있는 결과라면 두 변수는 서로 영향을
제장 2 비모수 검정(NONPARAMETRIC ANALYSIS) ③ 연구자는 SPSS 출력결과에서 유의확률을 확인하여 귀무가설(H0 )의 기각, 채택 여부를 결정한다. 예를 들어 연구자가 연구자료의 정규성을 검정하기 위하여 유 의수준을 α = 0.05로 설정하고 SPS
 ③ 연구자는 SPSS 출력결과에서 유의확률을 확인하여 귀무가설(H0 )의 기각, 채택 여부를 결정한다. 예를 들어 연구자가 연구자료의 정규성을 검정하기 위하여 유 의수준을 α = 0.05로 설정하고 SPS") 제장 비모수 검정(nonparametric analysis) 모집단의 분포를 알 수 없거나 모집단이 정규분포를 따른다고 가정할 수 없는 경우에는 모수적 검정을 사용할 수 없다. 이 경우에 자료의 부호나 순위로 가설 검정을 실시하며 이러한 검정 방법을 비모수 검정이라고 한다. 제절 적합도 검정(goodness of fit test) 주어진 자료가 어떠한 통계적
제장 비모수 검정(nonparametric analysis) 모집단의 분포를 알 수 없거나 모집단이 정규분포를 따른다고 가정할 수 없는 경우에는 모수적 검정을 사용할 수 없다. 이 경우에 자료의 부호나 순위로 가설 검정을 실시하며 이러한 검정 방법을 비모수 검정이라고 한다. 제절 적합도 검정(goodness of fit test) 주어진 자료가 어떠한 통계적
G Power
 G Power 부산대학교통계학과조영석 1. G Power 란? 2. G Power 설치및실행 2.1 G Power 설치 2.2 G Power 실행 3. 검정 (Test) 3.1 가설검정 (Test of hypothesis) 3.2 검정력 (Power) 3.3 효과크기 (Effect size) 3.4 표본수산정 4. 분석 4.1 t- 검정 (t-test) 4.2
G Power 부산대학교통계학과조영석 1. G Power 란? 2. G Power 설치및실행 2.1 G Power 설치 2.2 G Power 실행 3. 검정 (Test) 3.1 가설검정 (Test of hypothesis) 3.2 검정력 (Power) 3.3 효과크기 (Effect size) 3.4 표본수산정 4. 분석 4.1 t- 검정 (t-test) 4.2
Microsoft PowerPoint - IPYYUIHNPGFU
 분산분석 분산분석 (ANOVA: ANALYSIS OF VARIANCE) 두개이상의모집단의차이를검정 예 : 회사에서세종류의기계를설치하여동일한제품을생산하는경우, 각기계의생산량을조사하여평균생산량을비교 독립변수 : 다른변수에의해영향을주는변수 종속변수 : 다른변수에의해영향을받는변수 요인 (Factor): 독립변수 예에서의요인 : 기계의종류 (I, II, III) 요인수준
분산분석 분산분석 (ANOVA: ANALYSIS OF VARIANCE) 두개이상의모집단의차이를검정 예 : 회사에서세종류의기계를설치하여동일한제품을생산하는경우, 각기계의생산량을조사하여평균생산량을비교 독립변수 : 다른변수에의해영향을주는변수 종속변수 : 다른변수에의해영향을받는변수 요인 (Factor): 독립변수 예에서의요인 : 기계의종류 (I, II, III) 요인수준
R t-..
 R 과데이터분석 집단의차이비교 t- 검정 양창모 청주교육대학교컴퓨터교육과 2015 년겨울 t- 검정 변수의값이연속적이고정규분포를따른다고할때사용 t.test() 는모평균과모평균의 95% 신뢰구간을추청함과동시에가설검증을수행한다. 모평균의구간추정 - 일표본 t- 검정 이가설검정의귀무가설은 모평균이 0 이다 라는귀무가설이다. > x t.test(x)
R 과데이터분석 집단의차이비교 t- 검정 양창모 청주교육대학교컴퓨터교육과 2015 년겨울 t- 검정 변수의값이연속적이고정규분포를따른다고할때사용 t.test() 는모평균과모평균의 95% 신뢰구간을추청함과동시에가설검증을수행한다. 모평균의구간추정 - 일표본 t- 검정 이가설검정의귀무가설은 모평균이 0 이다 라는귀무가설이다. > x t.test(x)
 소표본 (
소표본 ( 자료의 이해 및 분석
 어떤실험이나치료의효과를측정할때독립이아닌표본으로부터관찰치를얻었을때처리하는방법 - 동일한개체에어떤처리를하기전과후의자료를얻을때 - 가능한동일한특성을갖는두개의개체에서로다른처리를하여그처리의효과를비교하는방법 (matching) 1 예제 : 혈청 cholesterol 치를줄이기위해서 12 명을대상으로운동과함께식이요법의효과를 측정하기위한실험실시 2 식이요법 - 운동실험전과후의
어떤실험이나치료의효과를측정할때독립이아닌표본으로부터관찰치를얻었을때처리하는방법 - 동일한개체에어떤처리를하기전과후의자료를얻을때 - 가능한동일한특성을갖는두개의개체에서로다른처리를하여그처리의효과를비교하는방법 (matching) 1 예제 : 혈청 cholesterol 치를줄이기위해서 12 명을대상으로운동과함께식이요법의효과를 측정하기위한실험실시 2 식이요법 - 운동실험전과후의
고객관계를 리드하는 서비스 리더십 전략
 제 13 장분산분석 1 13.1 일원분산분석 13. 분산분석 - 무작위블럭디자인 13.3 이원분산분석 - 팩토리얼디자인 분산분석 (ANOVA) - 두개이상의집단들의평균값을비교하는데사용. 일원분산분석 - 처치변수가한개인분산분석. 1. 분산분석의원리 A 3.0 8.0 7.0 5.0 5.0 6.0 4.0 7.0 6.0 4.0 평균 5.0 6.0 B 3.0 9.0
제 13 장분산분석 1 13.1 일원분산분석 13. 분산분석 - 무작위블럭디자인 13.3 이원분산분석 - 팩토리얼디자인 분산분석 (ANOVA) - 두개이상의집단들의평균값을비교하는데사용. 일원분산분석 - 처치변수가한개인분산분석. 1. 분산분석의원리 A 3.0 8.0 7.0 5.0 5.0 6.0 4.0 7.0 6.0 4.0 평균 5.0 6.0 B 3.0 9.0
<4D F736F F D20BDC3B0E8BFADBAD0BCAE20C1A B0AD5FBCF6C1A45FB0E8B7AEB0E6C1A6C7D E646F63>
 제 3 강계량경제학 Review Par I. 단순회귀모형 I. 계량경제학 A. 계량경제학 (Economerics 이란? i. 경제적이론이설명하는경제변수들간의관계를경제자료를바탕으로통 계적으로추정 (esimaion 고검정 (es 하는학문 거시소비함수 (Keynse. C=f(Y, 0
제 3 강계량경제학 Review Par I. 단순회귀모형 I. 계량경제학 A. 계량경제학 (Economerics 이란? i. 경제적이론이설명하는경제변수들간의관계를경제자료를바탕으로통 계적으로추정 (esimaion 고검정 (es 하는학문 거시소비함수 (Keynse. C=f(Y, 0
ANOVA 란? ANalysis Of VAriance Ø 3개이상의모집단의평균의차이를검정하는방법 Ø 3개의모집단일경우 H0 : μ1 = μ2 = μ3 H0기각 : μ1 μ2 = μ3 or μ1 = μ2 μ3 or μ1 μ2 μ3 àpost hoc test 수행
 Ch4 one-way ANOVA ANOVA 란? ANalysis Of VAriance Ø 3개이상의모집단의평균의차이를검정하는방법 Ø 3개의모집단일경우 H0 : μ1 = μ2 = μ3 H0기각 : μ1 μ2 = μ3 or μ1 = μ2 μ3 or μ1 μ2 μ3 àpost hoc test 수행 One-way ANOVA 란? Group Sex pvas NSAID
Ch4 one-way ANOVA ANOVA 란? ANalysis Of VAriance Ø 3개이상의모집단의평균의차이를검정하는방법 Ø 3개의모집단일경우 H0 : μ1 = μ2 = μ3 H0기각 : μ1 μ2 = μ3 or μ1 = μ2 μ3 or μ1 μ2 μ3 àpost hoc test 수행 One-way ANOVA 란? Group Sex pvas NSAID
이다. 즉 μ μ μ : 가아니다. 이러한검정을하기위하여분산분석은다음과같은가정을두고있다. 분산분석의가정 (1) r개모집단분포는모두정규분포를이루고있다. (2) r개모집단의평균은다를수있으나분산은모두같다. (3) r개모집단에서추출한표본은서로독립적이다. 분산분석은집단을구분하는
 r개모집단분포는모두정규분포를이루고있다. (2) r개모집단의평균은다를수있으나분산은모두같다. (3) r개모집단에서추출한표본은서로독립적이다. 분산분석은집단을구분하는") 제 12 강분산분석 분산분석 (ANOVA) (1) 1. 개요 비교하는집단의수가 3개이상일경우에사용되는통계기법이분산분석이다. 두표본 t검증에서는문제의단순성때문에야기되지않는문제들이다수의표본으로확대됨에따라문제들이야기되기도한다. 다음과같은 r개의모집단이있다고가정하자..... ~ N( μ σ ) ~ N( μ σ ).... ~ N ( μ σ )...... 위의그림과같이여러번에걸쳐두표본의
제 12 강분산분석 분산분석 (ANOVA) (1) 1. 개요 비교하는집단의수가 3개이상일경우에사용되는통계기법이분산분석이다. 두표본 t검증에서는문제의단순성때문에야기되지않는문제들이다수의표본으로확대됨에따라문제들이야기되기도한다. 다음과같은 r개의모집단이있다고가정하자..... ~ N( μ σ ) ~ N( μ σ ).... ~ N ( μ σ )...... 위의그림과같이여러번에걸쳐두표본의
Microsoft PowerPoint - ANOVA pptx
 분산분석개념및기초 인과관계 casual relationship X=>Y Y 종속변수, 반응변수, 내생변수 X 설명변수, 독립변수, 요인 ( 처리효과 ), 내생변수 X 측정형 Y 범주형 로지스틱회귀분석 측정형 회귀분석 범주형교차분석분산분석 DOE Design of Experiment ( 실험설계 ) 관심대상에대한정보를얻기위한계획된테스트나관측 절대실험 absolute
분산분석개념및기초 인과관계 casual relationship X=>Y Y 종속변수, 반응변수, 내생변수 X 설명변수, 독립변수, 요인 ( 처리효과 ), 내생변수 X 측정형 Y 범주형 로지스틱회귀분석 측정형 회귀분석 범주형교차분석분산분석 DOE Design of Experiment ( 실험설계 ) 관심대상에대한정보를얻기위한계획된테스트나관측 절대실험 absolute
공공기관임금프리미엄추계 연구책임자정진호 ( 한국노동연구원선임연구위원 ) 연구원오호영 ( 한국직업능력개발원연구위원 ) 연구보조원강승복 ( 한국노동연구원책임연구원 ) 이연구는국회예산정책처의정책연구용역사업으로 수행된것으로서, 본연구에서제시된의견이나대안등은
 연구원오호영 ( 한국직업능력개발원연구위원 ) 연구보조원강승복 ( 한국노동연구원책임연구원 ) 이연구는국회예산정책처의정책연구용역사업으로 수행된것으로서, 본연구에서제시된의견이나대안등은") 2013 년도연구용역보고서 공공기관임금프리미엄추계 - 2013. 12.- 이연구는국회예산정책처의연구용역사업으로수행된것으로서, 보고서의내용은연구용역사업을수행한연구자의개인의견이며, 국회예산정책처의공식견해가아님을알려드립니다. 연구책임자 한국노동연구원선임연구위원정진호 공공기관임금프리미엄추계 2013. 12. 연구책임자정진호 ( 한국노동연구원선임연구위원 ) 연구원오호영
2013 년도연구용역보고서 공공기관임금프리미엄추계 - 2013. 12.- 이연구는국회예산정책처의연구용역사업으로수행된것으로서, 보고서의내용은연구용역사업을수행한연구자의개인의견이며, 국회예산정책처의공식견해가아님을알려드립니다. 연구책임자 한국노동연구원선임연구위원정진호 공공기관임금프리미엄추계 2013. 12. 연구책임자정진호 ( 한국노동연구원선임연구위원 ) 연구원오호영
생존분석의 추정과 비교 : 보충자료 이용희 December 12, 2018 Contents 1 생존함수와 위험함수 생존함수와 위험함수 예제: 지수분포
 생존분석의 추정과 비교 : 보충자료 이용희 December, 8 Cotets 생존함수와 위험함수. 생존함수와 위험함수....................................... 예제: 지수분포.......................................... 예제: 와이블분포.........................................
생존분석의 추정과 비교 : 보충자료 이용희 December, 8 Cotets 생존함수와 위험함수. 생존함수와 위험함수....................................... 예제: 지수분포.......................................... 예제: 와이블분포.........................................
statistics
 수치를이용한자료요약 statistics hmkang@hallym.ac.kr 한림대학교 통계학 강희모 ( 한림대학교 ) 수치를이용한자료요약 1 / 26 수치를 통한 자료의 요약 요약 방대한 자료를 몇 개의 의미있는 수치로 요약 자료의 분포상태를 알 수 있는 통계기법 사용 중심위치의 측도(measure of center) : 어떤 값을 중심으로 분포되어 있는지
수치를이용한자료요약 statistics hmkang@hallym.ac.kr 한림대학교 통계학 강희모 ( 한림대학교 ) 수치를이용한자료요약 1 / 26 수치를 통한 자료의 요약 요약 방대한 자료를 몇 개의 의미있는 수치로 요약 자료의 분포상태를 알 수 있는 통계기법 사용 중심위치의 측도(measure of center) : 어떤 값을 중심으로 분포되어 있는지
 연구보고서 2009-05 일반화선형모형 (GLM) 을이용한 자동차보험요율상대도산출방법연구 Ⅰ. 요율상대도산출시일반화선형모형활용방법 1. 일반화선형모형 2 연구보고서 2009-05 2. 일반화선형모형의자동차보험요율산출에적용방법 요약 3 4 연구보고서 2009-05 Ⅱ. 일반화선형모형을이용한실증분석 1. 모형적용기준 < > = 요약 5 2. 통계자료및통계모형
연구보고서 2009-05 일반화선형모형 (GLM) 을이용한 자동차보험요율상대도산출방법연구 Ⅰ. 요율상대도산출시일반화선형모형활용방법 1. 일반화선형모형 2 연구보고서 2009-05 2. 일반화선형모형의자동차보험요율산출에적용방법 요약 3 4 연구보고서 2009-05 Ⅱ. 일반화선형모형을이용한실증분석 1. 모형적용기준 < > = 요약 5 2. 통계자료및통계모형
PowerPoint 프레젠테이션
 응용식물통계학 Statistics of Applied Plants Science 친환경식물학부유기농생태학전공황선구 14 장회귀분석 1. 회귀직선의추정 2. 회귀직선의검정및추론 3. 모집단절편과회귀계수의구간추정 4. 곡선회귀 15 장공분산분석 1. 공분산분석의통계적모형 2. 공분산분석에의한처리효과검정 3. 공분산분석과정 - 실습 - 회귀분석 두확률변수간에관계가있는지검정
응용식물통계학 Statistics of Applied Plants Science 친환경식물학부유기농생태학전공황선구 14 장회귀분석 1. 회귀직선의추정 2. 회귀직선의검정및추론 3. 모집단절편과회귀계수의구간추정 4. 곡선회귀 15 장공분산분석 1. 공분산분석의통계적모형 2. 공분산분석에의한처리효과검정 3. 공분산분석과정 - 실습 - 회귀분석 두확률변수간에관계가있는지검정
슬라이드 1
 회귀분석 (Regression Analysis) 회귀분석은종속변수와독립변수들갂의관련성, 또는독립변수를 이용하여종속변수를예측하는데사용하며, 종속변수와독립변수 들의함수적관련성을이용하여분석한다. 회귀분석의목적 (1) 예측을목적 주어진독립변수를이용하여종속변수의평균값을추정할목적으로 기존의자료를이용하여회귀모형을세움 (2) 각독립변수가종속변수에미치는영향을평가 종속변수에어떤독립변수들이유의한영향을미치는지를알아보고
회귀분석 (Regression Analysis) 회귀분석은종속변수와독립변수들갂의관련성, 또는독립변수를 이용하여종속변수를예측하는데사용하며, 종속변수와독립변수 들의함수적관련성을이용하여분석한다. 회귀분석의목적 (1) 예측을목적 주어진독립변수를이용하여종속변수의평균값을추정할목적으로 기존의자료를이용하여회귀모형을세움 (2) 각독립변수가종속변수에미치는영향을평가 종속변수에어떤독립변수들이유의한영향을미치는지를알아보고
저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할
 저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할수없습니다. 변경금지. 귀하는이저작물을개작, 변형또는가공할수없습니다. 귀하는, 이저작물의재이용이나배포의경우,
저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할수없습니다. 변경금지. 귀하는이저작물을개작, 변형또는가공할수없습니다. 귀하는, 이저작물의재이용이나배포의경우,
모수검정과비모수검정 제 6 강 지리통계학
 모수검정과비모수검정 제 6 강 지리통계학 통계적추정의목적 연구자가주장하는연구가설을입증하기위한것 1 연구목적에맞는연구가설을설정 2 연구목적과수집된자료에부합되는적절한통계적검정방법을선택 3 귀무가설과연구가설 ( 대립가설 ) 을진술 4 유의수준을결정한후각분포유형에따라분포표를이용하여임계치를구하고기각역을설정 5 통계적검정유형에필요한통계량을각검정유형의공식을이용하여계산 6
모수검정과비모수검정 제 6 강 지리통계학 통계적추정의목적 연구자가주장하는연구가설을입증하기위한것 1 연구목적에맞는연구가설을설정 2 연구목적과수집된자료에부합되는적절한통계적검정방법을선택 3 귀무가설과연구가설 ( 대립가설 ) 을진술 4 유의수준을결정한후각분포유형에따라분포표를이용하여임계치를구하고기각역을설정 5 통계적검정유형에필요한통계량을각검정유형의공식을이용하여계산 6
2156년올림픽 100미터육상경기에서여성의우승기록이남성의기록보다빠른첫해로남을수있음 2156년올림픽에서 100m 우승기록은남성의경우 8.098초, 여성은 8.079초로예측 통계적오차 ( 예측구간 ) 를고려하면빠르면 2064년, 늦어도 2788년에는그렇게될것이라고주장 유사
 를고려하면빠르면 2064년, 늦어도 2788년에는그렇게될것이라고주장 유사") 회귀분석 올림픽 100m 우승기록 2004년 9월과학저널 Nature에발표된 Oxford 대학교의임상병리학자인 Andrew Tatem과그의연구진의논문 1900~2004년까지의남성과여성의육상 100m 우승기록을분석하고앞으로최고기록이어떻게변할것인지를예측 2008년베이징올림픽에서남자의우승기록은 9.73±0.144(9.586, 9.874), 여자는 10.57±0.232(10.338,
회귀분석 올림픽 100m 우승기록 2004년 9월과학저널 Nature에발표된 Oxford 대학교의임상병리학자인 Andrew Tatem과그의연구진의논문 1900~2004년까지의남성과여성의육상 100m 우승기록을분석하고앞으로최고기록이어떻게변할것인지를예측 2008년베이징올림픽에서남자의우승기록은 9.73±0.144(9.586, 9.874), 여자는 10.57±0.232(10.338,
PPT Template
 External Use SPSS 를이용한분산분석 (ANOVA) 013 년 11 월 13 일 임찬수 0 Table of Contents 1 분산분석과실험계획법 일원배치분산분석 (One-way ANOVA) 3 사후분석 (Post-hoc test) 4 일원배치분산분석의예제 5 HomeWork 1 1 분산분석과실험계획법 분산분석 분산분석 : 평균값을기초로하여여러집단을비교하고,
External Use SPSS 를이용한분산분석 (ANOVA) 013 년 11 월 13 일 임찬수 0 Table of Contents 1 분산분석과실험계획법 일원배치분산분석 (One-way ANOVA) 3 사후분석 (Post-hoc test) 4 일원배치분산분석의예제 5 HomeWork 1 1 분산분석과실험계획법 분산분석 분산분석 : 평균값을기초로하여여러집단을비교하고,
Microsoft Word - sbe_anova.docx
 ANOVA 기본개요세집단이상인평균비교 => 일원분산분석집단을요인 (factor) 혹은처리효과 (treatment effect) 라하고집단의개별값을수준 (level) 이라한다. 요인이하나인경우 one-way ANOVA 분산분석 (ANOVA Analyss Of VArance) 은실험설계로부터유래, 분산 ( 변동 ) 에의해요인 ( 모형 ) 의유의성를검증한다. 실험관심대상에대한정보를얻기위한계획된테스트나관측절대실험
ANOVA 기본개요세집단이상인평균비교 => 일원분산분석집단을요인 (factor) 혹은처리효과 (treatment effect) 라하고집단의개별값을수준 (level) 이라한다. 요인이하나인경우 one-way ANOVA 분산분석 (ANOVA Analyss Of VArance) 은실험설계로부터유래, 분산 ( 변동 ) 에의해요인 ( 모형 ) 의유의성를검증한다. 실험관심대상에대한정보를얻기위한계획된테스트나관측절대실험
<B0A3C3DFB0E828C0DBBEF7292E687770>
 초청연자특강 대구가톨릭의대의학통계학교실 Meta analysis ( 메타분석 ) 예1) The effect of interferon on development of hepatocellular carcinoma in patients with chronic hepatitis B virus infection?? -:> 1998.1 ~2007.12.31 / RCT(2),
초청연자특강 대구가톨릭의대의학통계학교실 Meta analysis ( 메타분석 ) 예1) The effect of interferon on development of hepatocellular carcinoma in patients with chronic hepatitis B virus infection?? -:> 1998.1 ~2007.12.31 / RCT(2),
Microsoft Word - Chapter9.doc
 CHAPTER 9 분산분석 9.1. 분산분석개념 분산분석 (ANOVA: Analysis of Variance) 이란종속변수 (dependent variable: 반응변수 : response variable) 의분산 (variation: 변동 통계에서는이를변수가가진정보라한다 ) 을설명하는독립변수 (independent: 설명변수 : explanatory) 의유의성
CHAPTER 9 분산분석 9.1. 분산분석개념 분산분석 (ANOVA: Analysis of Variance) 이란종속변수 (dependent variable: 반응변수 : response variable) 의분산 (variation: 변동 통계에서는이를변수가가진정보라한다 ) 을설명하는독립변수 (independent: 설명변수 : explanatory) 의유의성
제 4 장회귀분석
 회귀의역사적유래 (historical origin of the regression) 회귀 (regression) 라는용어는유전학자 Francis Galton(1886) 에의해처음사용된데서유래함. 그의논문에서 비정상적으로크거나작은부모의아이들키는전체인구의평균신장을향해움직이거나회귀 (regression) 하는경향이있다. 고주장 회귀의역사적유래 (historical
회귀의역사적유래 (historical origin of the regression) 회귀 (regression) 라는용어는유전학자 Francis Galton(1886) 에의해처음사용된데서유래함. 그의논문에서 비정상적으로크거나작은부모의아이들키는전체인구의평균신장을향해움직이거나회귀 (regression) 하는경향이있다. 고주장 회귀의역사적유래 (historical
PowerPoint 프레젠테이션
 응용식물통계학 Statistics of Applied Plants Science 친환경식물학부유기농생태학전공황선구 13 장상관분석 1. 상관계수 2. 상관분석의가정과특성 3. 모상관계수의검정과신뢰한계 4. 순위상관 14 장회귀분석 1. 회귀직선의추정 2. 회귀직선의검정및추론 3. 모집단절편과회귀계수의구간추정 4. 곡선회귀 - 실습 - 상관분석 지금까지한가지확률변수에의한현상을검정하였다.
응용식물통계학 Statistics of Applied Plants Science 친환경식물학부유기농생태학전공황선구 13 장상관분석 1. 상관계수 2. 상관분석의가정과특성 3. 모상관계수의검정과신뢰한계 4. 순위상관 14 장회귀분석 1. 회귀직선의추정 2. 회귀직선의검정및추론 3. 모집단절편과회귀계수의구간추정 4. 곡선회귀 - 실습 - 상관분석 지금까지한가지확률변수에의한현상을검정하였다.
슬라이드 1
 대한의료관련감염관리학회학술대회 2016년 5월 26일 ( 목 ) 15:40-17:40 서울아산병원동관 6층대강당서울성심병원김지형 기능, 가격, 모든것을종합 1 Excel 자료정리 2 SPSS 학교에서준다면설치 3 통계시작 : dbstat 4 Web-R : 표만들기, 메타분석 5 R SPSS www.cbgstat.com dbstat 직접 dbstat 길들이기
대한의료관련감염관리학회학술대회 2016년 5월 26일 ( 목 ) 15:40-17:40 서울아산병원동관 6층대강당서울성심병원김지형 기능, 가격, 모든것을종합 1 Excel 자료정리 2 SPSS 학교에서준다면설치 3 통계시작 : dbstat 4 Web-R : 표만들기, 메타분석 5 R SPSS www.cbgstat.com dbstat 직접 dbstat 길들이기
PPT Template
 External Use SPSS 를이용한분산분석 (ANOVA) 009 년 11 월 09 일 임찬수 0 Table of Contents 1 분산분석과실험계획법 일원배치분산분석 (One-way ANOVA) 3 사후분석 (Post-hoc test) 4 일원배치분산분석의예제 5 이원배치분산분석 (Two-way ANOVA) 1 Table of Contents 6 일원배치반복측정분산분석
External Use SPSS 를이용한분산분석 (ANOVA) 009 년 11 월 09 일 임찬수 0 Table of Contents 1 분산분석과실험계획법 일원배치분산분석 (One-way ANOVA) 3 사후분석 (Post-hoc test) 4 일원배치분산분석의예제 5 이원배치분산분석 (Two-way ANOVA) 1 Table of Contents 6 일원배치반복측정분산분석
시스템경영과 구조방정식모형분석
 2 st SPSS OPEN HOUSE, 2009 년 6 월 24 일 AMOS 를이용한잠재성장모형 (Latent Growth Model ) 세명대학교경영학과김계수교수 (043) 649-242 gskim@semyung.ac.kr 목차. LGM개념소개 2. LGM모형종류 3. LGM 예제 4. 결과치비교 5. 정리및요약 2 적합모형의판단방법 Tips SEM 결과해석방법
2 st SPSS OPEN HOUSE, 2009 년 6 월 24 일 AMOS 를이용한잠재성장모형 (Latent Growth Model ) 세명대학교경영학과김계수교수 (043) 649-242 gskim@semyung.ac.kr 목차. LGM개념소개 2. LGM모형종류 3. LGM 예제 4. 결과치비교 5. 정리및요약 2 적합모형의판단방법 Tips SEM 결과해석방법
슬라이드 1
 빅데이터분석을위한데이터마이닝방법론 SAS Enterprise Miner 활용사례를중심으로 7 주차 회귀분석 Regression Analysis 최종후, 강현철 차례 4.1 선형회귀분석 (Linear Regression Analysis) 4.2 로지스틱회귀분석 (Logistic Regression Analysis) 4.3 회귀분석의특징과제약 4.4 분석사례 -
빅데이터분석을위한데이터마이닝방법론 SAS Enterprise Miner 활용사례를중심으로 7 주차 회귀분석 Regression Analysis 최종후, 강현철 차례 4.1 선형회귀분석 (Linear Regression Analysis) 4.2 로지스틱회귀분석 (Logistic Regression Analysis) 4.3 회귀분석의특징과제약 4.4 분석사례 -
통계분석가이드라인 통계 (Statisitcs) 란? Second Language in Science 전남대학교치의학전문대학원임회정 1 2 모집단 (Population) 과표본 (Sample) 통계분석단계 Sampling 추정 1. 귀무가설수립 2.
 란? Second Language in Science 전남대학교치의학전문대학원임회정 1 2 모집단 (Population) 과표본 (Sample) 통계분석단계 Sampling 추정 1. 귀무가설수립 2.") 통계분석가이드라인 통계 (Statisitcs) 란? Second Language in Science 전남대학교치의학전문대학원임회정 1 2 모집단 (Population) 과표본 (Sample) 통계분석단계 Sampling 추정 1. 귀무가설수립 2. 검정통계량계산 ( 어떤검정을실시할것인가를결정 ) 3. 귀무가설을기각? 채택? (p 값으로결정 - 유의수준 0.05
통계분석가이드라인 통계 (Statisitcs) 란? Second Language in Science 전남대학교치의학전문대학원임회정 1 2 모집단 (Population) 과표본 (Sample) 통계분석단계 Sampling 추정 1. 귀무가설수립 2. 검정통계량계산 ( 어떤검정을실시할것인가를결정 ) 3. 귀무가설을기각? 채택? (p 값으로결정 - 유의수준 0.05
자료의 이해 및 분석
 7. 평균치비교 1 두집단간평균차이검정 2 연속형변수 Interval scale( 간격척도 ) : 20 C, 30 C,, 변수간의가감가능 Ratio scale( 비척도 ) : 12, 13세, 변수간의가감승제모두가능 범주형자료로변환하여다양한분석가능 ( 연령 10 대, 20 대, 30 대.) 3 범주형자료의기술 분할표 (Contingency table) : 범주형자료를각변수별값의
7. 평균치비교 1 두집단간평균차이검정 2 연속형변수 Interval scale( 간격척도 ) : 20 C, 30 C,, 변수간의가감가능 Ratio scale( 비척도 ) : 12, 13세, 변수간의가감승제모두가능 범주형자료로변환하여다양한분석가능 ( 연령 10 대, 20 대, 30 대.) 3 범주형자료의기술 분할표 (Contingency table) : 범주형자료를각변수별값의
(001~006)개념RPM3-2(부속)
개념RPM3-2(부속)") www.imth.tv - (~9)개념RPM-(본문).. : PM RPM - 대푯값 페이지 다민 PI LPI 알피엠 대푯값과산포도 유형 ⑴ 대푯값 자료 전체의 중심적인 경향이나 특징을 하나의 수로 나타낸 값 ⑵ 평균 (평균)= Ⅰ 통계 (변량)의 총합 (변량의 개수) 개념플러스 대푯값에는 평균, 중앙값, 최 빈값 등이 있다. ⑶ 중앙값 자료를 작은 값부터 크기순으로
www.imth.tv - (~9)개념RPM-(본문).. : PM RPM - 대푯값 페이지 다민 PI LPI 알피엠 대푯값과산포도 유형 ⑴ 대푯값 자료 전체의 중심적인 경향이나 특징을 하나의 수로 나타낸 값 ⑵ 평균 (평균)= Ⅰ 통계 (변량)의 총합 (변량의 개수) 개념플러스 대푯값에는 평균, 중앙값, 최 빈값 등이 있다. ⑶ 중앙값 자료를 작은 값부터 크기순으로
분산분석.pages
 예제데이터 R. A. Fisher (1919 영국통계학자, 생물학자, 수학자 - 분산분석창시자 iris 분꽃데이터 - 3 개종, 4 개변수관측데이터 - sepal 꽃받침 ( 길이, 넓이 - petal 꽃잎 ( 길이, 넓이 분산개념정의 변수의데이터흩어짐의척도이다. (x s i x = n 1 활용 변동계수 Coefficient of Variation CV - CV
예제데이터 R. A. Fisher (1919 영국통계학자, 생물학자, 수학자 - 분산분석창시자 iris 분꽃데이터 - 3 개종, 4 개변수관측데이터 - sepal 꽃받침 ( 길이, 넓이 - petal 꽃잎 ( 길이, 넓이 분산개념정의 변수의데이터흩어짐의척도이다. (x s i x = n 1 활용 변동계수 Coefficient of Variation CV - CV
저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할
 저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할수없습니다. 변경금지. 귀하는이저작물을개작, 변형또는가공할수없습니다. 귀하는, 이저작물의재이용이나배포의경우,
저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할수없습니다. 변경금지. 귀하는이저작물을개작, 변형또는가공할수없습니다. 귀하는, 이저작물의재이용이나배포의경우,
<3235B0AD20BCF6BFADC0C720B1D8C7D120C2FC20B0C5C1FE20322E687770>
 25 강. 수열의극한참거짓 2 두수열 { }, {b n } 의극한에대한 < 보기 > 의설명중옳은것을모두고르면? Ⅰ. < b n 이고 lim = 이면 lim b n =이다. Ⅱ. 두수열 { }, {b n } 이수렴할때 < b n 이면 lim < lim b n 이다. Ⅲ. lim b n =0이면 lim =0또는 lim b n =0이다. Ⅰ 2Ⅱ 3Ⅲ 4Ⅰ,Ⅱ 5Ⅰ,Ⅲ
25 강. 수열의극한참거짓 2 두수열 { }, {b n } 의극한에대한 < 보기 > 의설명중옳은것을모두고르면? Ⅰ. < b n 이고 lim = 이면 lim b n =이다. Ⅱ. 두수열 { }, {b n } 이수렴할때 < b n 이면 lim < lim b n 이다. Ⅲ. lim b n =0이면 lim =0또는 lim b n =0이다. Ⅰ 2Ⅱ 3Ⅲ 4Ⅰ,Ⅱ 5Ⅰ,Ⅲ
nonpara6.PDF
 6 One-way layout 3 (oneway layout) k k y y y y n n y y K yn y y n n y y K yn k y k y k yknk n k yk yk K y nk (grand mean) (SST) (SStr: ) (SSE= SST-SStr), ( 39 ) ( )(rato) F- (normalty assumpton), Medan,
6 One-way layout 3 (oneway layout) k k y y y y n n y y K yn y y n n y y K yn k y k y k yknk n k yk yk K y nk (grand mean) (SST) (SStr: ) (SSE= SST-SStr), ( 39 ) ( )(rato) F- (normalty assumpton), Medan,
 1 1 Department of Statistics University of Seoul August 29, 2017 T-test T 검정은스튜던트 t 통계량의분포를귀무가설하에서살펴봄으러써가설의기각여부를결정하는의사결정모형임 검정 : X i iid N(µ, σ 2 ) 이라고가정하고, 귀무가설과대립가설을아래와같이놓자. 귀무가설즉, µ = µ 0 하에서 H : µ
1 1 Department of Statistics University of Seoul August 29, 2017 T-test T 검정은스튜던트 t 통계량의분포를귀무가설하에서살펴봄으러써가설의기각여부를결정하는의사결정모형임 검정 : X i iid N(µ, σ 2 ) 이라고가정하고, 귀무가설과대립가설을아래와같이놓자. 귀무가설즉, µ = µ 0 하에서 H : µ
저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할
 저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할수없습니다. 변경금지. 귀하는이저작물을개작, 변형또는가공할수없습니다. 귀하는, 이저작물의재이용이나배포의경우,
저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할수없습니다. 변경금지. 귀하는이저작물을개작, 변형또는가공할수없습니다. 귀하는, 이저작물의재이용이나배포의경우,
Microsoft Word - SPSS_MDA_Ch6.doc
 Chapter 6. 정준상관분석 6.1 정준상관분석 정준상관분석 (Canonical Correlation Analysis) 은변수들의군집간선형상관관계를파악하는분석방법이다. 예를들어신체적조건 ( 키, 몸무게, 가슴둘레 ) 과운동력 ( 달리기, 윗몸일으키기, 턱걸이 ) 사이의선형상관관계가있는지알아보고, 관계가있다면어떤관계가있는지분석하는것이다. 정준상관분석은 (
Chapter 6. 정준상관분석 6.1 정준상관분석 정준상관분석 (Canonical Correlation Analysis) 은변수들의군집간선형상관관계를파악하는분석방법이다. 예를들어신체적조건 ( 키, 몸무게, 가슴둘레 ) 과운동력 ( 달리기, 윗몸일으키기, 턱걸이 ) 사이의선형상관관계가있는지알아보고, 관계가있다면어떤관계가있는지분석하는것이다. 정준상관분석은 (
3 장기술통계 : 수치척도 Part B 분포형태, 상대적위치, 극단값 탐색적자료분석 두변수간의관련성측정 가중평균과그룹화자료
 3 장기술통계 : 수치척도 Part B 분포형태, 상대적위치, 극단값 탐색적자료분석 두변수간의관련성측정 가중평균과그룹화자료 분포형태, 상대적위치, 극단값 분포형태 z-값 체비셰프의원리 경험법칙 극단값찾기 분포형태 : 왜도 (skewness) 분포형태를측정하는중요한척도중하나를 왜도 라고한다. 자료집합의왜도를구하는계산식은조금복잡하다. 통계프로그램을사용하여왜도를쉽게계산할수있다.
3 장기술통계 : 수치척도 Part B 분포형태, 상대적위치, 극단값 탐색적자료분석 두변수간의관련성측정 가중평균과그룹화자료 분포형태, 상대적위치, 극단값 분포형태 z-값 체비셰프의원리 경험법칙 극단값찾기 분포형태 : 왜도 (skewness) 분포형태를측정하는중요한척도중하나를 왜도 라고한다. 자료집합의왜도를구하는계산식은조금복잡하다. 통계프로그램을사용하여왜도를쉽게계산할수있다.
(3) 추론에서계산이모수적방법보다훨씬단순. (4) 사용자가이의논리를스스로발견하게하며이해하기쉬움. (5) 표본이정규분포를따를때에도검정력에큰손실이없으며, 정규분포와상이한경우에이의검정력은정규분포에의한방법보다크다. 3. 부호검정 (Sg test) 모집단의중앙값에대한검정으로관찰
 추론에서계산이모수적방법보다훨씬단순. (4) 사용자가이의논리를스스로발견하게하며이해하기쉬움. (5) 표본이정규분포를따를때에도검정력에큰손실이없으며, 정규분포와상이한경우에이의검정력은정규분포에의한방법보다크다. 3. 부호검정 (Sg test) 모집단의중앙값에대한검정으로관찰") 제 3 장. 비모수적방법 (Dstrbuto-free Method) 모수적방법 (parametrc method): 관측값이어느특정한확률분포, 예를들면정규분포, 이항분 포등을따른다고전제한후그분포의모수 (parameter) 에대한검정을실시하는방법이다. 비모수적방법 (oparametrc method): 관측값이어느특정한확률분포를따른다고전제할수 없거나또는모집단에대한아무런정보가없는경우에실시하는검정방법으로모수에대한언급이없으며분포무관방법이라고도한다.
제 3 장. 비모수적방법 (Dstrbuto-free Method) 모수적방법 (parametrc method): 관측값이어느특정한확률분포, 예를들면정규분포, 이항분 포등을따른다고전제한후그분포의모수 (parameter) 에대한검정을실시하는방법이다. 비모수적방법 (oparametrc method): 관측값이어느특정한확률분포를따른다고전제할수 없거나또는모집단에대한아무런정보가없는경우에실시하는검정방법으로모수에대한언급이없으며분포무관방법이라고도한다.
한국정책학회학회보
 한국정책학회보제 22 권 2 호 (2013.6): 181~206 정부신뢰에대한연구 - 대통령에대한신뢰와정부정책에대한평가비교를중심으로 * - 주제어 : 민주화이후정부신뢰, 대통령신뢰, 정부정책만족도 Ⅰ. 서론 182 한국정책학회보제 22 권 2 호 (2013.6) 정부신뢰에대한연구 183 Ⅱ Ⅲ Ⅳ Ⅴ Ⅱ. 정부신뢰에대한이론적논의 184 한국정책학회보제 22
한국정책학회보제 22 권 2 호 (2013.6): 181~206 정부신뢰에대한연구 - 대통령에대한신뢰와정부정책에대한평가비교를중심으로 * - 주제어 : 민주화이후정부신뢰, 대통령신뢰, 정부정책만족도 Ⅰ. 서론 182 한국정책학회보제 22 권 2 호 (2013.6) 정부신뢰에대한연구 183 Ⅱ Ⅲ Ⅳ Ⅴ Ⅱ. 정부신뢰에대한이론적논의 184 한국정책학회보제 22
Vector Differential: 벡터 미분 Yonghee Lee October 17, 벡터미분의 표기 스칼라미분 벡터미분(Vector diffrential) 또는 행렬미분(Matrix differential)은 벡터와 행렬의 미분식에 대 한 표
 또는 행렬미분(Matrix differential)은 벡터와 행렬의 미분식에 대 한 표") Vector Differential: 벡터 미분 Yonhee Lee October 7, 08 벡터미분의 표기 스칼라미분 벡터미분(Vector diffrential) 또는 행렬미분(Matrix differential)은 벡터와 행렬의 미분식에 대 한 표기법을 정의하는 방법이다 보통 스칼라(scalar)에 대한 미분은 일분수 함수 f : < < 또는 다변수 함수(function
Vector Differential: 벡터 미분 Yonhee Lee October 7, 08 벡터미분의 표기 스칼라미분 벡터미분(Vector diffrential) 또는 행렬미분(Matrix differential)은 벡터와 행렬의 미분식에 대 한 표기법을 정의하는 방법이다 보통 스칼라(scalar)에 대한 미분은 일분수 함수 f : < < 또는 다변수 함수(function
Microsoft PowerPoint - MDA DA pptx
 판별분석개념 Indvdual Drected Technque 측정변수 ( 항목 ) 에의한개체분류 분류되어있는집단간의차이를의미있게설명해줄수있는독립변수들을찾아내어 변수의선형결합으로판별식 (Dscrmnant functon) 을만들어낸다. 이판별식을이용하여분류하고자하는개체의집단을판별 데이터유형 집단변수 : 범주형혹은이진형 판별변수 : 측정형 ( 등간척도포함 ) 사례
판별분석개념 Indvdual Drected Technque 측정변수 ( 항목 ) 에의한개체분류 분류되어있는집단간의차이를의미있게설명해줄수있는독립변수들을찾아내어 변수의선형결합으로판별식 (Dscrmnant functon) 을만들어낸다. 이판별식을이용하여분류하고자하는개체의집단을판별 데이터유형 집단변수 : 범주형혹은이진형 판별변수 : 측정형 ( 등간척도포함 ) 사례
PowerPoint Presentation
 09 th Week Correlation Analysis 상관관계분석 Jongseok Lee Business Administration Hallym University 변수형태와통계적분석방법 H 0 : X ㅗ Y H 1 : X ~ Y X Categorical Y Categorical Chi-square Test X Categorical Y Numerical
09 th Week Correlation Analysis 상관관계분석 Jongseok Lee Business Administration Hallym University 변수형태와통계적분석방법 H 0 : X ㅗ Y H 1 : X ~ Y X Categorical Y Categorical Chi-square Test X Categorical Y Numerical
선형모형_LM.pdf
 변수선택 8 경제성의 원리로 불리우는 Occam s Razor는 어떤 현상을 설명할 때 불필요한 가정을 해서는 안 된다는 것이다. 같은 현상을 설 명하는 두 개의 주장이 있다면, 간 단한 쪽을 선택하라. 통계학의 유 의성 검정, 유의하지 않은 설명변 수 제거의 근거가 된다. 섹션 1 개요 개념 1) 경험이나 이론에 의해 종속변수에 영향을 미칠 것 같은 설명변수를
변수선택 8 경제성의 원리로 불리우는 Occam s Razor는 어떤 현상을 설명할 때 불필요한 가정을 해서는 안 된다는 것이다. 같은 현상을 설 명하는 두 개의 주장이 있다면, 간 단한 쪽을 선택하라. 통계학의 유 의성 검정, 유의하지 않은 설명변 수 제거의 근거가 된다. 섹션 1 개요 개념 1) 경험이나 이론에 의해 종속변수에 영향을 미칠 것 같은 설명변수를
Microsoft Word - sbe13_anova.docx
 실험설계개요어떤원인이반응에유의한영향을주고있는가를파악하고그영향이양적으로어느정도큰가를알아내고자실시함 ( 추정과검정 적은영향밖에미치지못하는요인 ( 오차 들은전체적으로어느정도도영향을주고있으며, 측정오차는어느정도인가를알아내고자실시함 ( 오차항추정 유의한영향을미치는원인들이어떠한조건을수있는가를알아내기위해서실시함 ( 최적화 가질때가장바람직한반응을얻을 용어 요인 (Factor:
실험설계개요어떤원인이반응에유의한영향을주고있는가를파악하고그영향이양적으로어느정도큰가를알아내고자실시함 ( 추정과검정 적은영향밖에미치지못하는요인 ( 오차 들은전체적으로어느정도도영향을주고있으며, 측정오차는어느정도인가를알아내고자실시함 ( 오차항추정 유의한영향을미치는원인들이어떠한조건을수있는가를알아내기위해서실시함 ( 최적화 가질때가장바람직한반응을얻을 용어 요인 (Factor:
슬라이드 1
 Principles of Economerics (3e) Ch. 4 예측, 적합도, 모형화 013 년 1 학기 윤성민 4.1 OLS 예측 (1) 점예측 x0 y0 - 설명변수일때, 종속변수의값을예측하고자함 y ˆ = b + 0 1 b x 0 Ch. 4 예측, 적합도, 모형화 /60 4.1 OLS 예측 예측오차 (forecas error), f 예측오차의기대값
Principles of Economerics (3e) Ch. 4 예측, 적합도, 모형화 013 년 1 학기 윤성민 4.1 OLS 예측 (1) 점예측 x0 y0 - 설명변수일때, 종속변수의값을예측하고자함 y ˆ = b + 0 1 b x 0 Ch. 4 예측, 적합도, 모형화 /60 4.1 OLS 예측 예측오차 (forecas error), f 예측오차의기대값
Microsoft PowerPoint - ºÐÆ÷ÃßÁ¤(ÀüÄ¡Çõ).ppt
.ppt") 수명분포및신뢰도의 통계적추정 포항공과대학교산업공학과전치혁.. 수명및수명분포 수명 - 고장 까지의시간 - 확률변수로간주 - 통상잘알려진분포를따른다고가정 수명분포 - 확률밀도함수또는 누적 분포함수로표현 - 신뢰도, 고장률, MTTF 등신뢰성지표는수명분포로부터도출 - 수명분포추정은분포함수관련모수의추정 누적분포함수및확률밀도함수 누적분포함수 cumulav dsbuo
수명분포및신뢰도의 통계적추정 포항공과대학교산업공학과전치혁.. 수명및수명분포 수명 - 고장 까지의시간 - 확률변수로간주 - 통상잘알려진분포를따른다고가정 수명분포 - 확률밀도함수또는 누적 분포함수로표현 - 신뢰도, 고장률, MTTF 등신뢰성지표는수명분포로부터도출 - 수명분포추정은분포함수관련모수의추정 누적분포함수및확률밀도함수 누적분포함수 cumulav dsbuo
Microsoft Word - SAS_Data Manipulate.docx
 수학계산관련 함수 함수 형태 내용 SIN(argument) TAN(argument) EXP( 변수명 ) SIN 값을계산 -1 argument 1 TAN 값을계산, -1 argument 1 지수함수로지수값을계산한다 SQRT( 변수명 ) 제곱근값을계산한다 제곱은 x**(1/3) = 3 x x 1/ 3 x**2, 세제곱근 LOG( 변수명 ) LOGN( 변수명 )
수학계산관련 함수 함수 형태 내용 SIN(argument) TAN(argument) EXP( 변수명 ) SIN 값을계산 -1 argument 1 TAN 값을계산, -1 argument 1 지수함수로지수값을계산한다 SQRT( 변수명 ) 제곱근값을계산한다 제곱은 x**(1/3) = 3 x x 1/ 3 x**2, 세제곱근 LOG( 변수명 ) LOGN( 변수명 )
Microsoft Word - SBE2012_anova.docx
 실험설계개요어떤원인이반응에유의한영향을주고있는가를파악하고그영향이양적으로어느정도큰가를알아내고자실시함 ( 추정과검정 ) 적은영향밖에미치지못하는요인 ( 오차 ) 들은전체적으로어느정도영향을주고있으며, 측정오차는어느정도인가를알아내고자실시함 ( 오차항추정 ) 유의한영향을미치는원인들이어떠한조건을가질때가장바람직한반응을얻을수있는가를알아내기위해서실시함 ( 최적화 ) 용어 요인
실험설계개요어떤원인이반응에유의한영향을주고있는가를파악하고그영향이양적으로어느정도큰가를알아내고자실시함 ( 추정과검정 ) 적은영향밖에미치지못하는요인 ( 오차 ) 들은전체적으로어느정도영향을주고있으며, 측정오차는어느정도인가를알아내고자실시함 ( 오차항추정 ) 유의한영향을미치는원인들이어떠한조건을가질때가장바람직한반응을얻을수있는가를알아내기위해서실시함 ( 최적화 ) 용어 요인
국가기술자격 재위탁 효율성 평가
 - i - - ii - - iii - - iv - - v - - vi - - vii - - viii - - 1 - - 2 - - 3 - - 4 - - 5 - - 6 - - 7 - - 8 - - 9 - - 10 - - 11 - Ⅱ - 12 - - 13 - - 14 - - 15 - - 16 - - 17 - - 18 - - 19 - Ÿ Ÿ Ÿ Ÿ Ÿ Ÿ Ÿ Ÿ Ÿ
- i - - ii - - iii - - iv - - v - - vi - - vii - - viii - - 1 - - 2 - - 3 - - 4 - - 5 - - 6 - - 7 - - 8 - - 9 - - 10 - - 11 - Ⅱ - 12 - - 13 - - 14 - - 15 - - 16 - - 17 - - 18 - - 19 - Ÿ Ÿ Ÿ Ÿ Ÿ Ÿ Ÿ Ÿ Ÿ
nonpara1.PDF
 Chapter 1 Introduction 1 Introduction (parameter) (assumption) (rank), (median) p-value distribution free, assumption free, statistical inference based on ranks 11 Nonparametric? John Arbuthnot (1710)
Chapter 1 Introduction 1 Introduction (parameter) (assumption) (rank), (median) p-value distribution free, assumption free, statistical inference based on ranks 11 Nonparametric? John Arbuthnot (1710)
Microsoft PowerPoint - SBE univariate5.pptx
 이상치 (outlier) 진단및해결 Homework 데이터 ( Option.XLS) 결과해석 치우침? 평균이중앙값에비해다소크다. 그러나이상치때문이지치우친것같지않음. Toys us 스톡옵션비율이이상치 해결방법 : Log 변환? 아니다치우쳐있지않기때문에제거 제거후 : 평균 :.74, 중위수 :.7 31 치우침과이상치 데이터 : 노트북평가점수 우로치우침과이상치가존재
이상치 (outlier) 진단및해결 Homework 데이터 ( Option.XLS) 결과해석 치우침? 평균이중앙값에비해다소크다. 그러나이상치때문이지치우친것같지않음. Toys us 스톡옵션비율이이상치 해결방법 : Log 변환? 아니다치우쳐있지않기때문에제거 제거후 : 평균 :.74, 중위수 :.7 31 치우침과이상치 데이터 : 노트북평가점수 우로치우침과이상치가존재
메타분석: 통계적 방법의 기초
 메타분석: 통계적 방법의 기초 서울시립대학교 통계학과 이용희 209년 4월 23일 Contents 하나의 실험과 효과의 크기 관심있는 모수: 효과의 크기 2 모수의 추정량 3 추정량에 대한 믿음 4 추정량의 분산과 표준오차 5 추정량의 분산과 모집단의 분산 6 통계적 효과의 크기 7 신뢰구간 8 일반적인 관심 모수 2 2 2 3 개의 실험의 비교 실험들의 이질성
메타분석: 통계적 방법의 기초 서울시립대학교 통계학과 이용희 209년 4월 23일 Contents 하나의 실험과 효과의 크기 관심있는 모수: 효과의 크기 2 모수의 추정량 3 추정량에 대한 믿음 4 추정량의 분산과 표준오차 5 추정량의 분산과 모집단의 분산 6 통계적 효과의 크기 7 신뢰구간 8 일반적인 관심 모수 2 2 2 3 개의 실험의 비교 실험들의 이질성
저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할
 저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할수없습니다. 변경금지. 귀하는이저작물을개작, 변형또는가공할수없습니다. 귀하는, 이저작물의재이용이나배포의경우,
저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할수없습니다. 변경금지. 귀하는이저작물을개작, 변형또는가공할수없습니다. 귀하는, 이저작물의재이용이나배포의경우,
수도권과비수도권근로자의임금격차에영향을미치는 집적경제의미시적메커니즘에관한실증연구 I. 서론
 수도권과비수도권근로자의임금격차에영향을미치는 집적경제의미시적메커니즘에관한실증연구 I. 서론 Ⅱ. 선행연구고찰 집적경제메커니즘의유형공유메커니즘매칭메커니즘학습메커니즘 내용기업이군집을형성하여분리불가능한생산요소, 중간재공급자, 노동력풀등을공유하는과정에서집적경제발생한지역에기업과노동력이군집을이뤄기업과노동력사이의매칭이촉진됨에따라집적경제발생군집이형성되면사람들사이의교류가촉진되어지식이확산되고새로운지식이창출됨에따라집적경제발생
수도권과비수도권근로자의임금격차에영향을미치는 집적경제의미시적메커니즘에관한실증연구 I. 서론 Ⅱ. 선행연구고찰 집적경제메커니즘의유형공유메커니즘매칭메커니즘학습메커니즘 내용기업이군집을형성하여분리불가능한생산요소, 중간재공급자, 노동력풀등을공유하는과정에서집적경제발생한지역에기업과노동력이군집을이뤄기업과노동력사이의매칭이촉진됨에따라집적경제발생군집이형성되면사람들사이의교류가촉진되어지식이확산되고새로운지식이창출됨에따라집적경제발생
Microsoft Word - ch8_influence.doc
 REGRESSION / 8 장. 영향치및잔차분석 172 Chapter 8 영향치와잔차분석 단순회귀모형에서관측점이이상치 (outlier) 인지영향치 (influential) 인지판단하는것은 매우쉽다. 산점도에서이상치혹은영향치의존재여부를미리감지한다. x- 축 ( 설명변수 ) 의 동일수준의다른관측치에비해종속변수의값이상이한빨간점은이상치이다. 반면판 단할다른관측치가동일설명변수수준에없는파란점은영향치이다.
REGRESSION / 8 장. 영향치및잔차분석 172 Chapter 8 영향치와잔차분석 단순회귀모형에서관측점이이상치 (outlier) 인지영향치 (influential) 인지판단하는것은 매우쉽다. 산점도에서이상치혹은영향치의존재여부를미리감지한다. x- 축 ( 설명변수 ) 의 동일수준의다른관측치에비해종속변수의값이상이한빨간점은이상치이다. 반면판 단할다른관측치가동일설명변수수준에없는파란점은영향치이다.
Chapter 7 분산분석
 Chapter 8 실험계획및분산분석 (Experimental Design & ANalysis Of VAariance, ANOVA) 2017/5/01 8.1 선형모형과분산분석 (Linear Model & Analysis of Variance) 선형모형 (linear model): 설명변수들의선형의선형결합의형태로반응변수를설명하고자함. (to explain the
Chapter 8 실험계획및분산분석 (Experimental Design & ANalysis Of VAariance, ANOVA) 2017/5/01 8.1 선형모형과분산분석 (Linear Model & Analysis of Variance) 선형모형 (linear model): 설명변수들의선형의선형결합의형태로반응변수를설명하고자함. (to explain the
untitled
 R 과함께하는통계학의이해 빅북이라명명된이책은지식공유의세계적인흐름에동참하고지적인업적들이세상과인류의지식이되도록하며, 누구나쉽게접근하고활용할수있는환경을만들고자한다. 이책의저작권은빅북 (www.bigbook.or.kr) 에있으며모든용도로활용할수있다. 다만상업용출판을하고자하는경우에는사전에문서로된허락을받아야한다. 공유와협력의교과서만들기운동본부 R 과함께하는 통계학의이해
R 과함께하는통계학의이해 빅북이라명명된이책은지식공유의세계적인흐름에동참하고지적인업적들이세상과인류의지식이되도록하며, 누구나쉽게접근하고활용할수있는환경을만들고자한다. 이책의저작권은빅북 (www.bigbook.or.kr) 에있으며모든용도로활용할수있다. 다만상업용출판을하고자하는경우에는사전에문서로된허락을받아야한다. 공유와협력의교과서만들기운동본부 R 과함께하는 통계학의이해
용역보고서
 신뢰성샘플링검사의설계방법 ( 정수관측중단시험 ) 9.. ( 주 ) 한국신뢰성기술서비스 목차 신뢰성샘플링검사의설계방법 ( 정수관측중단시험 ).... 개요.... 기호및용어정의.... 샘플링검사의설계방법... 3. 정수중단시샘플링검사설계방법...4 4. 신뢰성샘플링시험계획예제...5 hp://www.kors.co.kr 신뢰성샘플링검사의설계방법 ( 정수관측중단시험
신뢰성샘플링검사의설계방법 ( 정수관측중단시험 ) 9.. ( 주 ) 한국신뢰성기술서비스 목차 신뢰성샘플링검사의설계방법 ( 정수관측중단시험 ).... 개요.... 기호및용어정의.... 샘플링검사의설계방법... 3. 정수중단시샘플링검사설계방법...4 4. 신뢰성샘플링시험계획예제...5 hp://www.kors.co.kr 신뢰성샘플링검사의설계방법 ( 정수관측중단시험
외국인투자유치성과평가기준개발
 2010 년도연구용역보고서 외국인투자유치의성과평가기준개발 - 2010. 10. - 이연구는국회예산정책처의연구용역사업으로수행된것으로서, 보고서의내용은연구용역사업을수행한연구자의개인의견이며, 국회예산정책처의공식견해가아님을알려드립니다. 책임연구원 국립부경대학교지역사회연구소권오혁 수신 : 대한민국국회예산정책처장귀하. 2010 10 : : : : 요약문 I. 서론 1.
2010 년도연구용역보고서 외국인투자유치의성과평가기준개발 - 2010. 10. - 이연구는국회예산정책처의연구용역사업으로수행된것으로서, 보고서의내용은연구용역사업을수행한연구자의개인의견이며, 국회예산정책처의공식견해가아님을알려드립니다. 책임연구원 국립부경대학교지역사회연구소권오혁 수신 : 대한민국국회예산정책처장귀하. 2010 10 : : : : 요약문 I. 서론 1.
조사연구 권 호 연구논문 한국노동패널조사자료의분석을위한패널가중치산출및사용방안사례연구 A Case Study on Construction and Use of Longitudinal Weights for Korea Labor Income Panel Survey 2)3) a
3) a") 조사연구 권 호 연구논문 한국노동패널조사자료의분석을위한패널가중치산출및사용방안사례연구 A Case Study on Construction and Use of Longitudinal Weights for Korea Labor Income Panel Survey 2)3) a) b) 조사연구 주제어 패널조사 횡단면가중치 종단면가중치 선형혼합모형 일반화선형혼 합모형
조사연구 권 호 연구논문 한국노동패널조사자료의분석을위한패널가중치산출및사용방안사례연구 A Case Study on Construction and Use of Longitudinal Weights for Korea Labor Income Panel Survey 2)3) a) b) 조사연구 주제어 패널조사 횡단면가중치 종단면가중치 선형혼합모형 일반화선형혼 합모형
MATLAB for C/C++ Programmers
 오늘강의내용 (2014/01/16) 회귀분석 1 회귀분석 (Regression Analysis) 2 회귀분석 회귀분석이란? 연관된변수들간의관계를찾는통계적방법 즉, 어떠한변수 x가변수 Y에함수관계를통해영향을미친다는것을찾아내는것 예를들어 강우량 ( 변수 x) 이곡물의수확량 ( 변수 Y) 에미치는영향 화학공정의수율 ( 변수 x) 이촉매의사용량 ( 변수 Y) 에따라어떻게변하는지..
오늘강의내용 (2014/01/16) 회귀분석 1 회귀분석 (Regression Analysis) 2 회귀분석 회귀분석이란? 연관된변수들간의관계를찾는통계적방법 즉, 어떠한변수 x가변수 Y에함수관계를통해영향을미친다는것을찾아내는것 예를들어 강우량 ( 변수 x) 이곡물의수확량 ( 변수 Y) 에미치는영향 화학공정의수율 ( 변수 x) 이촉매의사용량 ( 변수 Y) 에따라어떻게변하는지..
<B4EBC7D0BCF6C7D02DBBEFB0A2C7D4BCF62E687770>
 삼각함수. 삼각함수의덧셈정리 삼각함수의덧셈정리 삼각함수 sin (α + β ), cos (α + β ), tan (α + β ) 등을 α 또는 β 의삼각함수로나 타낼수있다. 각 α 와각 β 에대하여 α >0, β >0이고 0 α - β < β 를만족한다고가정하 자. 다른경우에도같은방법으로증명할수있다. 각 α 와각 β 에대하여 θ = α - β 라고놓자. 위의그림에서원점에서거리가
삼각함수. 삼각함수의덧셈정리 삼각함수의덧셈정리 삼각함수 sin (α + β ), cos (α + β ), tan (α + β ) 등을 α 또는 β 의삼각함수로나 타낼수있다. 각 α 와각 β 에대하여 α >0, β >0이고 0 α - β < β 를만족한다고가정하 자. 다른경우에도같은방법으로증명할수있다. 각 α 와각 β 에대하여 θ = α - β 라고놓자. 위의그림에서원점에서거리가
<4D F736F F F696E74202D20C1A63132C0E520C0CCBFF8BAD0BBEABAD0BCAE205BC8A3C8AF20B8F0B5E55D>
 제 12 장이원분산분석 1 t분포와정규분포의관계 일반적으로자료수 n이증가하면 t분포는정규분포에접근 2 두집단평균비교 : 가설검정절차 [ 단계 1] 두집단집단간의간의등분산성에등분산성에대한대한검정을검정을먼저먼저수행한다. [ 단계 2] [ 단계 1] 의결과에따라따라다음의다음의두가지의검정검정방법이방법이있다. (1) 두집단집단간의간의분산이분산이동일한동일한경우 : 두집단집단간의간의평균차이평균차이검정
제 12 장이원분산분석 1 t분포와정규분포의관계 일반적으로자료수 n이증가하면 t분포는정규분포에접근 2 두집단평균비교 : 가설검정절차 [ 단계 1] 두집단집단간의간의등분산성에등분산성에대한대한검정을검정을먼저먼저수행한다. [ 단계 2] [ 단계 1] 의결과에따라따라다음의다음의두가지의검정검정방법이방법이있다. (1) 두집단집단간의간의분산이분산이동일한동일한경우 : 두집단집단간의간의평균차이평균차이검정
Microsoft PowerPoint - LM 2014s_Ch4.pptx
 1. 회귀모형및가정 모형설명 선형 linearity 함수 (,,,, ) 회귀계수 : 모수, unknown but fixed 절편 : y-축을통과하는곳 기울기 : 편미분, 한단위증가 p개의설명변수 들은결정변수 ( 확률변수아님 ) 종속변수만확률변수 모형 설명변수개수 p 개 관측치개수 n, 1,2,, ~ 0, ( 행렬 ),, 가정 ~ 0, 정규성 normality
1. 회귀모형및가정 모형설명 선형 linearity 함수 (,,,, ) 회귀계수 : 모수, unknown but fixed 절편 : y-축을통과하는곳 기울기 : 편미분, 한단위증가 p개의설명변수 들은결정변수 ( 확률변수아님 ) 종속변수만확률변수 모형 설명변수개수 p 개 관측치개수 n, 1,2,, ~ 0, ( 행렬 ),, 가정 ~ 0, 정규성 normality
저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할
 저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할수없습니다. 변경금지. 귀하는이저작물을개작, 변형또는가공할수없습니다. 귀하는, 이저작물의재이용이나배포의경우,
저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할수없습니다. 변경금지. 귀하는이저작물을개작, 변형또는가공할수없습니다. 귀하는, 이저작물의재이용이나배포의경우,
비선형으로의 확장
 비선형으로의확장 박창이 서울시립대학교통계학과 박창이 ( 서울시립대학교통계학과 ) 비선형으로의확장 1 / 30 개요 선형모형은해석과추론에장점이있는반면예측력은제한됨능형회귀, lasso, PCR 등의방법은선형모형을이용하는방법으로모형의복잡도를감소시켜추정치의분산을줄이는효과가있음해석력을유지하면서비선형으로확장다항회귀 (polynomial regression): ( 예 )
비선형으로의확장 박창이 서울시립대학교통계학과 박창이 ( 서울시립대학교통계학과 ) 비선형으로의확장 1 / 30 개요 선형모형은해석과추론에장점이있는반면예측력은제한됨능형회귀, lasso, PCR 등의방법은선형모형을이용하는방법으로모형의복잡도를감소시켜추정치의분산을줄이는효과가있음해석력을유지하면서비선형으로확장다항회귀 (polynomial regression): ( 예 )
자료분석론 - 국민건강영양조사 분석
 2014. 5. 10 ( 토 ) 자료분석론 국민건강영양조사자료 - 자료분석 (2) 서울대학교보건대학원 홍지민 강의순서 1) 국민건강영양조사이해 (4/19) - 자료의개요및원시자료 DB 2) 가중치및자료분석개요 (4/26) 3) 국민건강영양조사자료활용실습 (5/10) 2014-05-10 2 목차 자료분석개요 복합표본설계자료회귀분석 복합표본설계자료로지스틱회귀분석
2014. 5. 10 ( 토 ) 자료분석론 국민건강영양조사자료 - 자료분석 (2) 서울대학교보건대학원 홍지민 강의순서 1) 국민건강영양조사이해 (4/19) - 자료의개요및원시자료 DB 2) 가중치및자료분석개요 (4/26) 3) 국민건강영양조사자료활용실습 (5/10) 2014-05-10 2 목차 자료분석개요 복합표본설계자료회귀분석 복합표본설계자료로지스틱회귀분석
642 또한통계적유의성은실제적유의성과더불어검토되어야할문제이므로통계적유의성만의지나친집착과확대해석은바람직하지않으며, 통계적유의성이검출되지않은연구결과도때로는그자체로휼륭한의미를지닐수있다는점과추후연구에기여할수있다는점에서발표될수있어야할것이다 [6]. 여기에서실제적유의성이란실제적인
![642 또한통계적유의성은실제적유의성과더불어검토되어야할문제이므로통계적유의성만의지나친집착과확대해석은바람직하지않으며, 통계적유의성이검출되지않은연구결과도때로는그자체로휼륭한의미를지닐수있다는점과추후연구에기여할수있다는점에서발표될수있어야할것이다 [6]. 여기에서실제적유의성이란실제적인](/thumbs/87/96630507.jpg "642 또한통계적유의성은실제적유의성과더불어검토되어야할문제이므로통계적유의성만의지나친집착과확대해석은바람직하지않으며, 통계적유의성이검출되지않은연구결과도때로는그자체로휼륭한의미를지닐수있다는점과추후연구에기여할수있다는점에서발표될수있어야할것이다 [6]. 여기에서실제적유의성이란실제적인") REVIEW ARTICLE 대한간호학회지제 45 권제 5 호, 2015 년 10 월 ISSN (Print) 2005-3673 ISSN (Online) 2093-758X J Korean Acad Nurs Vol.45 No.5, 641-649 http://dx.doi.org/10.4040/jan.2015.45.5.641 간호학연구에서효과크기의사용에대한고찰 호서대학교응용통계학과
REVIEW ARTICLE 대한간호학회지제 45 권제 5 호, 2015 년 10 월 ISSN (Print) 2005-3673 ISSN (Online) 2093-758X J Korean Acad Nurs Vol.45 No.5, 641-649 http://dx.doi.org/10.4040/jan.2015.45.5.641 간호학연구에서효과크기의사용에대한고찰 호서대학교응용통계학과
1 경영학을 위한 수학 Final Exam 2015/12/12(토) 13:00-15:00 풀이과정을 모두 명시하시오. 정리를 사용할 경우 명시하시오. 1. (각 6점) 다음 적분을 구하시오 Z 1 4 Z 1 (x + 1) dx (a) 1 (x 1)4 dx 1 Solut
 13:00-15:00 풀이과정을 모두 명시하시오. 정리를 사용할 경우 명시하시오. 1. (각 6점) 다음 적분을 구하시오 Z 1 4 Z 1 (x + 1) dx (a) 1 (x 1)4 dx 1 Solut") 경영학을 위한 수학 Fial Eam 5//(토) :-5: 풀이과정을 모두 명시하시오. 정리를 사용할 경우 명시하시오.. (각 6점) 다음 적분을 구하시오 4 ( ) (a) ( )4 8 8 (b) d이 성립한다. d C C log log (c) 이다. 양변에 적분을 취하면 log C (d) 라 하자. 그러면 d 4이다. 9 9 4 / si (e) cos si
경영학을 위한 수학 Fial Eam 5//(토) :-5: 풀이과정을 모두 명시하시오. 정리를 사용할 경우 명시하시오.. (각 6점) 다음 적분을 구하시오 4 ( ) (a) ( )4 8 8 (b) d이 성립한다. d C C log log (c) 이다. 양변에 적분을 취하면 log C (d) 라 하자. 그러면 d 4이다. 9 9 4 / si (e) cos si
R
 R 과데이터분석 상관관계 양창모 청주교육대학교컴퓨터교육과 2015 년여름 양창모 ( 청주교육대학교컴퓨터교육과 ) Data Analysis using R 2015 년여름 1 / 20 상관관계 양적변수quantitative variables 사이의관계relationships를나타내기위하여상관계수correlation coefficients를사용한다. ± 기호를사용하여관계의방향을나타낸다.
R 과데이터분석 상관관계 양창모 청주교육대학교컴퓨터교육과 2015 년여름 양창모 ( 청주교육대학교컴퓨터교육과 ) Data Analysis using R 2015 년여름 1 / 20 상관관계 양적변수quantitative variables 사이의관계relationships를나타내기위하여상관계수correlation coefficients를사용한다. ± 기호를사용하여관계의방향을나타낸다.
PowerPoint 프레젠테이션
 응용식물통계학 Statistics of Applied Plants Science 친환경식물학부유기농생태학전공황선구 - 1. 분산분석 2. 회귀분석 준비 R과 R studio 설치 https://cran.r-project.org/bin/windows/base/ R 다운로드후설치 https://www.rstudio.com/products/rstudio/download/#download
응용식물통계학 Statistics of Applied Plants Science 친환경식물학부유기농생태학전공황선구 - 1. 분산분석 2. 회귀분석 준비 R과 R studio 설치 https://cran.r-project.org/bin/windows/base/ R 다운로드후설치 https://www.rstudio.com/products/rstudio/download/#download
슬라이드 1
 빅데이터분석을위한데이터마이닝방법론 SAS Enterprise Miner 활용사례를중심으로 제 4 장 회귀분석 Chapter 4 Regression Analysis 차례 4.1 선형회귀분석 (Linear Regression Analysis) 4.2 로지스틱회귀분석 (Logistic Regression Analysis) 4.3 회귀분석의특징과제약 4.4 분석사례
빅데이터분석을위한데이터마이닝방법론 SAS Enterprise Miner 활용사례를중심으로 제 4 장 회귀분석 Chapter 4 Regression Analysis 차례 4.1 선형회귀분석 (Linear Regression Analysis) 4.2 로지스틱회귀분석 (Logistic Regression Analysis) 4.3 회귀분석의특징과제약 4.4 분석사례
SPSS를 이용한 반복측정 및 종단자료의 분석: 다층모형을 중심으로
 SPSS 를이용한반복측정및종 단자료의분석 : 다층모형을중심으로 장승민 한림대학교심리학과 강의순서 반복측정자료분석의기초 반복측정자료의이해 반복측정자료분석을위한기본모형 다층모형을이용한종단자료분석 다층성장모형 SPSS를이용한분석예제 질의응답 010 년핚국심리학회연차학술대회 1 강 : 반복측정자료분석의기초 반복측정 반복측정 - 하나이상의변인을동일한대상에대해여러번에걸쳐반복적으로관찰,
SPSS 를이용한반복측정및종 단자료의분석 : 다층모형을중심으로 장승민 한림대학교심리학과 강의순서 반복측정자료분석의기초 반복측정자료의이해 반복측정자료분석을위한기본모형 다층모형을이용한종단자료분석 다층성장모형 SPSS를이용한분석예제 질의응답 010 년핚국심리학회연차학술대회 1 강 : 반복측정자료분석의기초 반복측정 반복측정 - 하나이상의변인을동일한대상에대해여러번에걸쳐반복적으로관찰,
동아시아국가들의실질환율, 순수출및 경제성장간의상호관계비교연구 : 시계열및패널자료인과관계분석
 동아시아국가들의실질환율, 순수출및 경제성장간의상호관계비교연구 : 시계열및패널자료인과관계분석 목차 I. 서론 II. 동아시아각국의무역수지, 실질실효환율및 GDP간의관계 III. 패널데이터를이용한 Granger인과관계분석 IV. 개별국실증분석모형및 TYDL을이용한 Granger 인과관계분석 V. 결론 참고문헌 I. 서론 - 1 - - 2 - - 3 - - 4
동아시아국가들의실질환율, 순수출및 경제성장간의상호관계비교연구 : 시계열및패널자료인과관계분석 목차 I. 서론 II. 동아시아각국의무역수지, 실질실효환율및 GDP간의관계 III. 패널데이터를이용한 Granger인과관계분석 IV. 개별국실증분석모형및 TYDL을이용한 Granger 인과관계분석 V. 결론 참고문헌 I. 서론 - 1 - - 2 - - 3 - - 4
Microsoft Word - EDA_Univariate.docx
 일변량분석개념 일변량분석은개체의특성을 측정한변수가하나인 통계분석 방법 변수의 종류 ( 수리 통계 ) 이산형 (discrete): 측정결과를셀수있는경우이다. 성별, 직업, 교통량, 나이등이여기해당된다. 연속형 (continuous): 측정결과가무한이 (infinite) 많은변수를연속형형변수라한다. 즉변수의범위 (range) 중어떤구간을설정하더라도측정치가발생할할수있는경우로키,
일변량분석개념 일변량분석은개체의특성을 측정한변수가하나인 통계분석 방법 변수의 종류 ( 수리 통계 ) 이산형 (discrete): 측정결과를셀수있는경우이다. 성별, 직업, 교통량, 나이등이여기해당된다. 연속형 (continuous): 측정결과가무한이 (infinite) 많은변수를연속형형변수라한다. 즉변수의범위 (range) 중어떤구간을설정하더라도측정치가발생할할수있는경우로키,
제 3 장평활법 지수평활법 (exponential smoothing) 최근자료에더큰가중값, 과거로갈수록가중값을지수적으로줄여나가는방법 시스템에변화가있을경우변화에쉽게대처가능 계산이쉽고많은자료의저장이필요없다 예측이주목적단순지수평활법, 이중지수평활법, 삼중지수평활법, Wint
 최근자료에더큰가중값, 과거로갈수록가중값을지수적으로줄여나가는방법 시스템에변화가있을경우변화에쉽게대처가능 계산이쉽고많은자료의저장이필요없다 예측이주목적단순지수평활법, 이중지수평활법, 삼중지수평활법, Wint") 제 3 장평활법 지수평활법 (exponential smoothing) 최근자료에더큰가중값, 과거로갈수록가중값을지수적으로줄여나가는방법 시스템에변화가있을경우변화에쉽게대처가능 계산이쉽고많은자료의저장이필요없다 예측이주목적단순지수평활법, 이중지수평활법, 삼중지수평활법, Winters의계절지수평활법 이동평균법 (moving average method) 평활에의해계절성분또는불규칙성분을제거하여전반적인추세를뚜렷하게파악
제 3 장평활법 지수평활법 (exponential smoothing) 최근자료에더큰가중값, 과거로갈수록가중값을지수적으로줄여나가는방법 시스템에변화가있을경우변화에쉽게대처가능 계산이쉽고많은자료의저장이필요없다 예측이주목적단순지수평활법, 이중지수평활법, 삼중지수평활법, Winters의계절지수평활법 이동평균법 (moving average method) 평활에의해계절성분또는불규칙성분을제거하여전반적인추세를뚜렷하게파악
슬라이드 제목 없음
 계량치 Gage R&R 1 Gage R&R 의변동 반복성 (Equipment Variation) : EV- 계측장비에의한변동 - 동일측정자가동일조건에서반복하여발생된측정값의범위로부터계산되므로 Gage의변동을평가하게됨. 재현성 (Operator / Appraiser Variation) : AV- 평가자에의한변동 - 서로다른측정자가동일조건에서측정한값의차이로부터 계산되므로측정자에의한변동을평가함.
계량치 Gage R&R 1 Gage R&R 의변동 반복성 (Equipment Variation) : EV- 계측장비에의한변동 - 동일측정자가동일조건에서반복하여발생된측정값의범위로부터계산되므로 Gage의변동을평가하게됨. 재현성 (Operator / Appraiser Variation) : AV- 평가자에의한변동 - 서로다른측정자가동일조건에서측정한값의차이로부터 계산되므로측정자에의한변동을평가함.
완벽한개념정립 _ 행렬의참, 거짓 수학전문가 NAMU 선생 1. 행렬의참, 거짓개념정리 1. 교환법칙과관련한내용, 는항상성립하지만 는항상성립하지는않는다. < 참인명제 > (1),, (2) ( ) 인경우에는 가성립한다.,,, (3) 다음과같은관계식을만족하는두행렬 A,B에
,, (2) ( ) 인경우에는 가성립한다.,,, (3) 다음과같은관계식을만족하는두행렬 A,B에") 1. 행렬의참, 거짓개념정리 1. 교환법칙과관련한내용, 는항상성립하지만 는항상성립하지는않는다. < 참인명제 > (1),, (2) ( ) 인경우에는 가성립한다.,,, (3) 다음과같은관계식을만족하는두행렬 A,B에대하여 AB=BA 1 가성립한다 2 3 (4) 이면 1 곱셈공식및변형공식성립 ± ± ( 복호동순 ), 2 지수법칙성립 (은자연수 ) < 거짓인명제 >
1. 행렬의참, 거짓개념정리 1. 교환법칙과관련한내용, 는항상성립하지만 는항상성립하지는않는다. < 참인명제 > (1),, (2) ( ) 인경우에는 가성립한다.,,, (3) 다음과같은관계식을만족하는두행렬 A,B에대하여 AB=BA 1 가성립한다 2 3 (4) 이면 1 곱셈공식및변형공식성립 ± ± ( 복호동순 ), 2 지수법칙성립 (은자연수 ) < 거짓인명제 >
집단의효과 ( 모평균에대한오차, j는오차. 모수모형에서 a 0 (. 변수모형에서 ( a 0 (.3..3 실험순서에의한분류 모든실험의순서를임의로행하는것 ( 완전확률화실험 과일부만임의로하는분할법 (splt-plot desgn 의두가지가있다...4 실험 동일한실험에서비교및검
 제 장. 분산분석 (nalss of Varance: NOV 분산분석은 R. Fsher에의해개발된 3 개이상의모평균에대한분석으로, 측정치의변동을총제곱합 (total sum of squares 으로나타내고이총제곱합을실험과관련된요인 ( 인자의작용 에 대한각자의제곱합으로분해한후, 나머지를오차변동으로해석하는검정법을말한다. 각요인마다분해한분산을오차분산과비교하여특히큰영향을주는인자
제 장. 분산분석 (nalss of Varance: NOV 분산분석은 R. Fsher에의해개발된 3 개이상의모평균에대한분석으로, 측정치의변동을총제곱합 (total sum of squares 으로나타내고이총제곱합을실험과관련된요인 ( 인자의작용 에 대한각자의제곱합으로분해한후, 나머지를오차변동으로해석하는검정법을말한다. 각요인마다분해한분산을오차분산과비교하여특히큰영향을주는인자
PowerPoint 프레젠테이션
 통계분석에대한이용안내자료 ㅣ수업활용 과학적탐구학습및토론식수업지원 ㅣ설문조사 쉽고간편한설문조사대규모조사가능 ㅣ통계분석 SPSS 없이분석가능통계분석컨설팅 ㅣ교육지원 유레카이용교육지원연구방법론교육지원 IPP 형일 학습병행제개선을위한인식조사 Contents 1. IPP 프로그램참여학생대상 2. IPP 프로그램참여기업인사담당자대상 3. IPP 프로그램참여기업멘토대상
통계분석에대한이용안내자료 ㅣ수업활용 과학적탐구학습및토론식수업지원 ㅣ설문조사 쉽고간편한설문조사대규모조사가능 ㅣ통계분석 SPSS 없이분석가능통계분석컨설팅 ㅣ교육지원 유레카이용교육지원연구방법론교육지원 IPP 형일 학습병행제개선을위한인식조사 Contents 1. IPP 프로그램참여학생대상 2. IPP 프로그램참여기업인사담당자대상 3. IPP 프로그램참여기업멘토대상
... —... ..—
 통계학 통계적추론 한국보건사회연구원 2017 년 5 월 29 일 ( 월요일 ) 강의슬라이드 7-1 1/ 72 목차 1 서론 2 신뢰구간을이용한통계적추론 3 통계적유의성검정 4 유의성검정과관련해서유의해야할점 2/ 72 지난시간복습 왜 x 가 µ 와완벽하게일치하지않고또어떤표본을추출했냐에따라 x 값이달라지는데이 x 를이용해서모집단 µ 를추정할까? 두가지사실때문 :
통계학 통계적추론 한국보건사회연구원 2017 년 5 월 29 일 ( 월요일 ) 강의슬라이드 7-1 1/ 72 목차 1 서론 2 신뢰구간을이용한통계적추론 3 통계적유의성검정 4 유의성검정과관련해서유의해야할점 2/ 72 지난시간복습 왜 x 가 µ 와완벽하게일치하지않고또어떤표본을추출했냐에따라 x 값이달라지는데이 x 를이용해서모집단 µ 를추정할까? 두가지사실때문 :
Resampling Methods
 Resampling Methds 박창이 서울시립대학교통계학과 박창이 ( 서울시립대학교통계학과 ) Resampling Methds 1 / 18 학습내용 개요 CV(crss-validatin) 검증오차 LOOCV(leave-ne-ut crss-validatin) k-fld CV 편의-분산의관계분류문제에서의 CV Btstrap 박창이 ( 서울시립대학교통계학과 )
Resampling Methds 박창이 서울시립대학교통계학과 박창이 ( 서울시립대학교통계학과 ) Resampling Methds 1 / 18 학습내용 개요 CV(crss-validatin) 검증오차 LOOCV(leave-ne-ut crss-validatin) k-fld CV 편의-분산의관계분류문제에서의 CV Btstrap 박창이 ( 서울시립대학교통계학과 )
중심경향치 (measure of central tendency) 대표값이란용어이외에자료의중심값또는중심위치의척도 (measure of central location) 라고도함. 예 : 평균 (mean= 산술평균 ; arithmetic mean), 절사평균 (trimmed
 대표값이란용어이외에자료의중심값또는중심위치의척도 (measure of central location) 라고도함. 예 : 평균 (mean= 산술평균 ; arithmetic mean), 절사평균 (trimmed") 중심경향치 (measure of central tendency) 대표값이란용어이외에자료의중심값또는중심위치의척도 (measure of central location) 라고도함. 예 : 평균 (mean= 산술평균 ; arithmetic mean), 절사평균 (trimmed mean), 가중평균 (weighted mean), 기하평균 (geometric mean),
중심경향치 (measure of central tendency) 대표값이란용어이외에자료의중심값또는중심위치의척도 (measure of central location) 라고도함. 예 : 평균 (mean= 산술평균 ; arithmetic mean), 절사평균 (trimmed mean), 가중평균 (weighted mean), 기하평균 (geometric mean),
Microsoft PowerPoint 상 교류 회로
 3상교류회로 11.1. 3 상교류의발생 평등자계중에놓인회전자철심에기계적으로 120 씩차이가나게감은코일 aa, bb,cc 를배치하고각속도의속도로회전하면각코일의양단에는다음식으로표현되는기전력이발생하게된다. 11.1. 3 상교류의발생 여기서 e a, e b, e c 는각각코일aa, bb, cc 양단에서얻어지는전압의순시치식이며, 각각을상 (phase) 이라한다. 이와같이전압의크기는같고위상이
3상교류회로 11.1. 3 상교류의발생 평등자계중에놓인회전자철심에기계적으로 120 씩차이가나게감은코일 aa, bb,cc 를배치하고각속도의속도로회전하면각코일의양단에는다음식으로표현되는기전력이발생하게된다. 11.1. 3 상교류의발생 여기서 e a, e b, e c 는각각코일aa, bb, cc 양단에서얻어지는전압의순시치식이며, 각각을상 (phase) 이라한다. 이와같이전압의크기는같고위상이
Microsoft PowerPoint - MDA DA pptx
 SPSS 2 집단 ( 데이터및준비 ) 데이터 TURKEY.SAV 미국 Kansas 주립대학 Dr. Michael Finnegan 교수는야생칠면조와사육칠면조를구별하기위하여수컷칠면조 82마리에대해 9개항목을조사하였다. ID: 칠면조 id HUM: 상완골길이 ULN: 척골길이 CAR: car metacarus 길이 COR: 오탁상길이 RAD: 요골길이 FEMUR:
SPSS 2 집단 ( 데이터및준비 ) 데이터 TURKEY.SAV 미국 Kansas 주립대학 Dr. Michael Finnegan 교수는야생칠면조와사육칠면조를구별하기위하여수컷칠면조 82마리에대해 9개항목을조사하였다. ID: 칠면조 id HUM: 상완골길이 ULN: 척골길이 CAR: car metacarus 길이 COR: 오탁상길이 RAD: 요골길이 FEMUR:
표본재추출(resampling) 방법
 방법") 표본재추출 (resampling) 방법 박창이 서울시립대학교통계학과 박창이 ( 서울시립대학교통계학과 ) 표본재추출 (resampling) 방법 1 / 18 학습내용 개요 CV(crss-validatin) 검증오차 LOOCV(leave-ne-ut crss-validatin) k-fld CV 편의-분산의관계분류문제에서의 CV Btstrap 박창이 ( 서울시립대학교통계학과
표본재추출 (resampling) 방법 박창이 서울시립대학교통계학과 박창이 ( 서울시립대학교통계학과 ) 표본재추출 (resampling) 방법 1 / 18 학습내용 개요 CV(crss-validatin) 검증오차 LOOCV(leave-ne-ut crss-validatin) k-fld CV 편의-분산의관계분류문제에서의 CV Btstrap 박창이 ( 서울시립대학교통계학과
14-X25-JSJ.hwp
 지경택 송영호 * 정국삼 ** ( 주 ) 한라 * 충북대학교대학원안전공학과 ** 충북대학교안전공학과 (2001. 9. 12. 접수 / 2001. 10. 30. 채택 ) Categorical Analysis for the Factors of Industrial Accident Cases Kyung-Tek Jhee Young-Ho Song * Kook-Sam Chung
지경택 송영호 * 정국삼 ** ( 주 ) 한라 * 충북대학교대학원안전공학과 ** 충북대학교안전공학과 (2001. 9. 12. 접수 / 2001. 10. 30. 채택 ) Categorical Analysis for the Factors of Industrial Accident Cases Kyung-Tek Jhee Young-Ho Song * Kook-Sam Chung
 아시아연구 16(1), 2013 pp. 105-130 중국의경제성장과보험업발전간의 장기균형관계 Ⅰ. 서론 Ⅲ. 실증분석 1. 분석방법 < 그림 1> 중국의보험밀도와국민 1 인당명목 GNI 성장추이 보험밀도 국민 1 인당명목 GNI < 그림 2> 중국의주요거시경제지표변화추이 총저축액 금리, 물가, 실업률 < 표 1> 변수정의 변수명 정의 자료출처 LTP
아시아연구 16(1), 2013 pp. 105-130 중국의경제성장과보험업발전간의 장기균형관계 Ⅰ. 서론 Ⅲ. 실증분석 1. 분석방법 < 그림 1> 중국의보험밀도와국민 1 인당명목 GNI 성장추이 보험밀도 국민 1 인당명목 GNI < 그림 2> 중국의주요거시경제지표변화추이 총저축액 금리, 물가, 실업률 < 표 1> 변수정의 변수명 정의 자료출처 LTP
10. ..
 점추정구간추정표본크기 차례 점추정구간추정표본크기 1 점추정 2 구간추정 3 표본크기 추정의종류 점추정구간추정표본크기 점추정 (point estimation): 모수를어떤하나의값으로추측하는것 구간추정 (interval estimation): 모수를어떤구간으로추측하는것 예 ) 피그미족 (Pygmytribe) 의평균키는모수 µ 표본을추출하여평균을구해보니 135cm
점추정구간추정표본크기 차례 점추정구간추정표본크기 1 점추정 2 구간추정 3 표본크기 추정의종류 점추정구간추정표본크기 점추정 (point estimation): 모수를어떤하나의값으로추측하는것 구간추정 (interval estimation): 모수를어떤구간으로추측하는것 예 ) 피그미족 (Pygmytribe) 의평균키는모수 µ 표본을추출하여평균을구해보니 135cm
<4D F736F F D20BDC3B0E8BFADBAD0BCAE20C1A B0AD5FBCF6C1A45FB0E8B7AEB0E6C1A6C7D E646F63>
 Par II. 다중회귀모형및기본가정의완화 I. 다중회귀모형 A. 다중회귀모형에대한가정 = β+β x + +β x +ε, =,..., ( x ) 관측치의수, 설명변수의수 K-, 추정모수의수 K 개별모수들의의미 : E( ) 예컨대, β = : 다른설명변수들이일정할때, x 의한 x 단위변화에대한종속변수의평균값의변화 즉다른변수들의영향력이통제 (conrol) 된상황에서첫번째설명변수의종속변수에대한영향력을나타내는값임
Par II. 다중회귀모형및기본가정의완화 I. 다중회귀모형 A. 다중회귀모형에대한가정 = β+β x + +β x +ε, =,..., ( x ) 관측치의수, 설명변수의수 K-, 추정모수의수 K 개별모수들의의미 : E( ) 예컨대, β = : 다른설명변수들이일정할때, x 의한 x 단위변화에대한종속변수의평균값의변화 즉다른변수들의영향력이통제 (conrol) 된상황에서첫번째설명변수의종속변수에대한영향력을나타내는값임
untitled
 통계청 통계분석연구 제 3 권제 1 호 (98. 봄 ) 91-104 장기예측방법의비교 - 전도시소비자물가지수를중심으로 - 서두성 *, 최종후 ** 본논문의목적은소비자물가지수와같이시간의흐름에따라변동의폭이크지않은시계열자료의장기예측에있어서쉽고, 정확한예측모형을찾고자하는데에있다. 이를위하여네가지의장기예측방법 - 1회귀적방법 2Autoregressive error 방법
통계청 통계분석연구 제 3 권제 1 호 (98. 봄 ) 91-104 장기예측방법의비교 - 전도시소비자물가지수를중심으로 - 서두성 *, 최종후 ** 본논문의목적은소비자물가지수와같이시간의흐름에따라변동의폭이크지않은시계열자료의장기예측에있어서쉽고, 정확한예측모형을찾고자하는데에있다. 이를위하여네가지의장기예측방법 - 1회귀적방법 2Autoregressive error 방법
슬라이드 1
 Principles of Econometrics (3e) Ch. 6 다중회귀모형에관한 추가적인논의 013 년 1 학기 윤성민 6장의주요내용 다중회귀모형의모수에관한둘이상의가설로구성된귀무가설을동시에검정하는경우 ( 결합가설의검정 ) F-검정 표본의정보이외에비표본정보도함께이용하는경우 제한최소제곱법 모형설정의오류를찾는방법 RESET 검정 다중공선성문제의탐지와해결방법
Principles of Econometrics (3e) Ch. 6 다중회귀모형에관한 추가적인논의 013 년 1 학기 윤성민 6장의주요내용 다중회귀모형의모수에관한둘이상의가설로구성된귀무가설을동시에검정하는경우 ( 결합가설의검정 ) F-검정 표본의정보이외에비표본정보도함께이용하는경우 제한최소제곱법 모형설정의오류를찾는방법 RESET 검정 다중공선성문제의탐지와해결방법
Microsoft PowerPoint - Info R(3) pptx
 pptx") Coelaton Analyss 개념 Bvaate analyss 측정형두변수간의관계분석 상관관계? 두측정형변수의산점도 : 상호직선적관련성을상관계수 (Coelaton Coeffcent 측정. 잠재설명 ( 원인 변수 (X s 상관관계, 잠재변인과결과변수 (Y 의상관관계 Peason 상관계수 측정형변수직선관계정도 cov( X, Y E( X E( X E( Y E( Y
Coelaton Analyss 개념 Bvaate analyss 측정형두변수간의관계분석 상관관계? 두측정형변수의산점도 : 상호직선적관련성을상관계수 (Coelaton Coeffcent 측정. 잠재설명 ( 원인 변수 (X s 상관관계, 잠재변인과결과변수 (Y 의상관관계 Peason 상관계수 측정형변수직선관계정도 cov( X, Y E( X E( X E( Y E( Y