Microsoft Word - EDA_Univariate.docx
|
|
|
- 호재 방
- 6 years ago
- Views:
Transcription
1 일변량분석개념 일변량분석은개체의특성을 측정한변수가하나인 통계분석 방법 변수의 종류 ( 수리 통계 ) 이산형 (discrete): 측정결과를셀수있는경우이다. 성별, 직업, 교통량, 나이등이여기해당된다. 연속형 (continuous): 측정결과가무한이 (infinite) 많은변수를연속형형변수라한다. 즉변수의범위 (range) 중어떤구간을설정하더라도측정치가발생할할수있는경우로키, 몸무게, IQ, 소득등이여기에해당된다. ( 자료분석 ) 측정형변수 (metric, measurable, quantitative): 실험개체의측정가능한특성을측정한변수, 측정단위가존재 ; 키, 몸무게, 평점, IQ, 교통량, 사망자수가그예이다. 연속형변수는모두측정형변수이고이산형변수중측정형변수가있을수있다. ( 예 ) 교통사고건수, 나이 ( 년 ) ( 1) 구간 interval : 값의크기가등간 ( 온도, 증가율 ) (2) 비율 ratio : 정대 0 이존재하며두값의비교가배수(times) 가능능 : 대부분측정형 평균 & 표준편차, 중앙값 &IQR 분류형 ( 범주형 ) 변수 (non-metric, classified, categorical, qualitative): 개체를분류하기위해측정된변수를의미하며성별, 결혼여부등이그예이다. (1) 명목형 (nominal) : 개체를분류만한다. 성별, 결혼여부, 학력 (2) 순서형 (ordinal) : 순서를가진다. 성적 (A, B,..) 소득수준 ( 상, 중, 하 ), 리커트척도 (5 점, 매우만족, 만족,, 매우불만족 ) 빈도분석, 비율 분석방법비율추론평균추론분산추론모수적방법 vs. 비모수적방법 1
2 in EDA 데이터를그래프로표현하여개체를구성한모집단의정보를얻는다. 범주형데이터는바차트로표현되어비율 ( 상대빈도 ) 로요약됨 측정형데이터는데이터의중앙위치, 흩어진정도, 봉우리형태등을 표현 그래프 요약필요성 개별변수에대한일변량분석은변수가가진정보를그래프로요약하거나나주요한숫자값으로 ( 통계량 ) 요약하게된다. 앞에서언급하였듯이그래프요약은변수에대한가정이 ( 확률표본, independently and identically y distributed) 성립하는지진단하게된다. 그래프진단은데이터의좌우대칭 ( 종모양 symmetric, bell shaped), 이상치치진단을하게된다. 그이유는평균이주된도구이기때문이다. 평균은치우침과이상치에취약하다. 확률분포함수 probability densityy functionn 일변량데이터가가진정보은확률밀도함수에의해표현된다. 확률변수표본공간 S 의모든원소 ( 결과 w ) 에실수 x 을대응시킨규칙을확률변수 X ( w) x 확률분포함수확률변수 X 의확률밀도함수 (probability density function, f pdf) 는확률변수 X 가가지는값 x 와그에대응하는확률 px ( ) 을그래프, 수식, 표형태로나타낸것이다. 만약좋은표본이 ( 모집단의축소판 ) 추출되었다면표본의분포는모집단의분포와같다. 그러므로만약모집단의분포 ( 실선 ) 함수를안다면다음을구할수있다. 모집단개체중 2
3 일부구간 ( 빨간점선구간 ) 에속한개체비율 ( 확률 )? 그러나불행히도표본자료의 분포로부터함수 식 (x) f ( 확률분포함수 : 실선그래프 ) 을아는것은불가능하다. 그러므로일반적으로통계학에서는모집단의분포에대한가정을하거나 ( 예 : 모평균검정을위한 t-검정에서소표본일경우모집단정규분포가정 ) 대표적인분포함수 ( 이항분포, 포아송분포, 지수분포, 감마분포, t-분포, F-분포, 정규분포 ) 를규정하고있다. 데이터 분석 : 확률분포를역할 데이터분석에서는모집단의확률분포함수형태를알고자하는것은아니다다. 모집단의특성을나타내는모수 parameter ( 예 : 평균, 비율, 분산 ) 에대한추정및가설검정이중요하다. 그러면데이터분석에서표본데이터확률분포를시각화하는이유는? 모집단으로부터확률표본기법을통하여얻어지는데이터 중심극한정리 에의하면표본의크기가크면표본평균 ( x ) 의분포는모집단의분포와관계없이 ( 모르더라도 ) 정규분포를따른다의미? CLT 는표본분포함수 (sample distribution) 에대한것이아니라표본평균의분포 (sampling dist.) 에관한것이다. 표본분포함수 ( 실선 ) 는여전히모집단의분포함수 f (x) 와동일하다. 그러니가정이나사전정보없이는그래프만가지고는알수없다. 그러나대표본 (n> 20~30) 일경우표본평균의분포는는 CLT에의해정규분포를따른다. 이것이왜그렇게중요하다. 우리가모집단에관심을가질때모집단자료전체에대한정보 ( 분포함수 ) 를구하는것보다는모집단의자료정보를요약한값 ( 이를모수 : parameter 라함 ) 에관심을갖게된다. 예를들면중앙의위치는?( 평균, 중앙값 ) 자료의흩어진정도는? ( 표준편차, 범위 ) 특히모집단의평균 ( ) 에관심을갖게된다. 이경우모집단의분포를모르더라도 CLT 에의해다음사실을알수있다. ( 이전페이지그림점선그래프참고) x Pr( z / 2 1 s / n ) s x z / 2 : 모평균 95% 신뢰뢰구간 n 만약대표본이아닌경우는 t-t 분포를이용해야되는데이런경우모집단은은정규분포를따르고있음을가정하게된다. 3
4 (1) B ( p 0.1) 베르누이확률분포를그리시오. (2) 베르누이분포 B( p 0.1) 에서크기 2인확률표본을추출하여표본평균을구하시오 (3) 표본평균을이용하여 95% 신뢰구간을구하고, 구해진신뢰구간이모평균을포함하고있는지판단하시오. (4) 위의 (2)-(3) 작업을 100 번반복하여 100개표본평균을구하고, 100 개 95% 신뢰구간중모평균을포함하지않은신뢰구간의수를적으시오. (5) 얻어진표본평균 100 개를이용하여표본데이터확률분포함수를그리시오. 즉히스토그램을그리시오. (6) 베르누이분포 B( p 0.1) 에서크기 20 인확률표본을추출하여평균을을구하고, 이런작업을 100 번반복하여 100 개표본평균을구하시오. (7) 얻어진표본평균 100 개를이용하여표본데이터확률분포함수를그리시오. 즉히스토그램을그리기 위의동일한작업은 Normal( 10,5) 에서실시하시오. 통계분포함수 (statistical distribution function) 함수 d*(x, 모수 ) p*(x, p, 모수 ) q*(p, 모수 ) r*(n, 모수 ) 기능확률밀도함수확률값, f(x) 분포함수값, F(x) 역분포함수값, F -1 (p) 분포함수따르는데이터 n 개랜덤하게생성 4
5 / ( 데이터관리 ) 제어문 control statement for( 변수 in 연속 ) { 문장 } 연속에지정된값만큼변수값이이변화하면서 문장 을반복실행한다. 5
6 if ( 조건 ) { 문장 } 조건이만족하면문장이 실행된다. while( 조건 ) { 문장 } 조건이만족하는동안문장반복실행된다. 함수만들기 6
7 plot(x, y, main=, sub=, xlim=c(a, b), ylab=, type= t ) 그래프함수 자신의 함수활용하기 7
8 Exploratory Data Analysis Spring, 2012 Chapter 2. Univariate Analysis 줄기잎그림 stem and leaf + 진단내용 1) 분포의개략적인형태를알수있다. (1) 좌우대칭인가? 아니면 skewed 되었는가? (2) 봉우리 (modal) 는하나인가? 아니면여러개인가? 2) 이상치의존재여부를쉽게파악할수있다. + 데이터 ( 정렬 ) ( 정렬않음 ) + 그리는순서 자료를크기순으로정리한다. 자료의수가많을때는자료정렬을수작업하기어려움으로이단계는무시해도되지만자료를크기순으로정렬해놓으면 plot 을그리기편리하다. 자료를살펴줄기와잎을결정한다. CEO 연봉자료를살펴보면 100 단위를줄기로하고 10 단위이하를잎으로하여 plot 을그리면될것이라는것을알수있다. 줄기수는히스토그램의계급구간수에해당되므로 8~12 정도가적절하다. 적정개수가아닌경우줄기수조정에대해서는다음에다루기로한다. 한열에줄기 (stem) 를먼저그린다. Professor Kwon, Sehyug Dept. of Statistics, HANNAM Univ
9 Exploratory Data Analysis Spring, 2012 Chapter 2. Univariate Analysis 위에서 100 단위이상을줄기로하기로결정하였고자료의최소값이 58, 최대값이 1103 이므로 0 부터 11 까지줄기를한열에크기순으로적는다. 줄기 (stem) 옆에잎을그린다. 잎을그리는방법은간단하다. 줄기바로뒤의숫자를줄기옆에차례로적으면된다. CEO 연봉자료는잎이두자리이지만앞에것하나만적으면된다. 굳이반올림하는수고를할필요는없다. 줄기-잎그림의목적은자료의분포형태와이상치를아는것이주된목적이기때문이다. 줄기 - 잎그림 + 엑셀에서콤마가있는파일형식으로저장한후읽어들인다. + ds$ 변수명 ; 오브젝트 ds 내의변수명변수를이용지정 줄기-잎그리기 합창단원의키에대한 ( 단위 : inch) 데이터이다. 1) 각파트의줄기-잎그림을그리고해석하시오. 2) 키데이터전체에대한줄기-잎을그리고해석하시오. Professor Kwon, Sehyug Dept. of Statistics, HANNAM Univ
10 Exploratory Data Analysis Spring, 2012 Chapter 2. Univariate Analysis + Stem-leaf plot 해석하기 > 자료의분포형태 stem-leaf plot 을통하여자료의분포형태를알수있으므로분포의형태를알수있다. 이는히스토그램과같은역할이다. > 봉우리 ( 최빈값 ) 위치및개수 => 봉우리의개수가집단의개수이다 > 좌우대칭여부 > 자료의범위및분산 > 이상치존재여부및위치 ( 히스토그램과비교 ) 줄기-잎그림을 90 도회전하면히스토그램 ( 이를 bar chart 라고도함 ) 이된다. 히스토그램은자료의값의정보가상실되지만 ( 실제값은알수없고빈도만바의크기로나타난다 ) stemleaf plot 은자료값이나타난다. 그러므로히스토그램에비해더많은정보를얻을수있다. (1) 확률분포함수추정 위의예제처럼 stem-leaf plot 의정점을연결하면확률분포함수를얻게된다. 아래그림은 모집단 CEO 연봉의확률밀도함수의추정형태이고 ( f (x) ) 면적은 1 이다. (2) 대칭, 치우침여부 symmetric (bell-shaped) 좌우대칭, 종모양 skewed to the right positively skewed 우로치우침 skewed to the left negatively skewed 좌로치우침 Professor Kwon, Sehyug Dept. of Statistics, HANNAM Univ
11 Exploratory Data Analysis Spring, 2012 Chapter 2. Univariate Analysis 평균과중앙값일치평균 > 중앙값평균 < 중앙값 좌우대칭으로만들려면 자료변환을하면된다. X* X mild pos. X* log( X ) pos. X * 1/ pos. X * 1/ severe X severe X more 2 X* X mild neg. 3 X* X extreme neg. ( 정규성검정 ) Anderson-Darling test for normality ( 연봉모평균에대한 95% 신뢰구간구하기 ) conf.level=0.95 Professor Kwon, Sehyug Dept. of Statistics, HANNAM Univ
12 Exploratory Data Analysis Spring, 2012 Chapter 2. Univariate Analysis 히스토그램그리기 우로치우침이있으므로제곱근변환, 혹은로그변환데이터중어느변환이더 좌우대칭분포에가까운지알아보시오. (3) 봉우리위치및개수히스토그램의봉우리는분포의최빈값에해당되는부분으로일반적으로최빈값은하나일가능성이가장높다. 구간설정에따라바로옆의구간이동시에최빈값이되는경향이가끔나타나기도한다. 다음의경우는 bi-modal 분포함수라하지는않는다. 왜냐하면구간을조정하면봉우리가하나로될수있기때문이다. CEO 연봉은단봉형태를갖는다. 단봉 uni-modal 다봉 bi-modal / multi-modal 봉우리가 2 개이상인의미는모집단이하나이상일가능성이많다. 예를들어한남대학생들 100 명의몸무게를조사하여히스토그램을그리면 bi-modal 형태가될가능성이높다. 왜냐하면여자와남자몸무게의차이가나기때문에그런현상이발생한다. 즉측정변수의특성에따라모집단이나누어진다. 용돈을조사하여히스토그램을그려보면아마봉우리가 3-4 개일가능성이있다. 왜? 학년별차이로인하여 이처럼어떤변수를측정하느냐에따라같은모집단이라도봉우리의개수가다를수있다. 봉우리가 2 개이상인경우는집단을분리하여추정및검정을시행하는것이바람직하다. 그러나집단에대한정보가없다면데이터를분리하여분석하는것이쉽지않다. Professor Kwon, Sehyug Dept. of Statistics, HANNAM Univ
13 Exploratory Data Analysis Spring, 2012 Chapter 2. Univariate Analysis ( 왜좌우대칭이어야하나?) 1) 회귀분석, 분산분석등대부분의통계분석에서종속변수는정규분포를따르고있다는가정을한다. 만약이것이무너지면 t-검정, F-검정을사용할수없다. 3 학년수업에서배우기를 2) 대표본표본크기 n 의크기? : 자료분석의목적은그래프정리 (bar chart, pie chart) 나숫자적정리 ( 평균, 표준편차 ) 에서끝나는것이아니라이정보를가지고모수 ( 예 : 모집단의평균 ) 를추정하거나그에대한가설을검정하게된다. CEO 30 명의연봉자료를이용하여전체 CEO 의연봉에대해알고싶은것이다. 통계소프트웨어에서출력되는 p- 값은 two-sided( 양측검정 ) 가설검정시값을출력한다. 그러므로위의경우대립가설을 H : 350( 양측검정 ) 설정하면 p-값이 로 a 0.05 보다크므로귀무가설을기각할수없으나대립가설을 H : 350( 단측검정 ) 설정하면 p-값이 이므로 0.05 보다적어귀무가설을기각하고연봉은높아졌다고결론지을수있다. 그러므로양측검정결과귀무가설이기각되면같은유의수준에서단측검정결과도귀무가설을기각한다. a (4) 범위와흩어진정도 분포의형태를알수있으므로자료의범위 (range= 최대값 - 최소값 ) 와흩어진 (spread) 정도를 알수있다. 흩어진정도 ( 표준편차 ) 범위 (range) (5) 이상치 (outlier) 발견다른관측치에비해매우크거나적은관측치를이상치 (outlier) 라한다. 이런이상치는히스토그램에서쉽게발견될수있다. 히스토그램이나 stem-leaf plot 의경우다른관측치와멀리떨어져있으면이를이상치라한다. CEO 연봉자료에서이상치는연봉이 1103( 백만 ) 인사람이다. 물론이값이이상치인지는검정통계량을이용하여 (Box-plot 이나검정방법을이용하여검정해야하지만우선쉽게찾을수있다는장점이있다. CEO 연봉의경우다른 CEO 에비해연봉을이상적으로높게받는 CEO ( 이를이상치라함 ) 가있음을알수있다. Professor Kwon, Sehyug Dept. of Statistics, HANNAM Univ
14 Exploratory Data Analysis Spring, 2012 Chapter 2. Univariate Analysis 이상치가발견되면그해결책은이상치인관측치의원자료를확인, 입력오류인지살펴본다. 오류가있으면정정한다. 이상치의대상인개체를조사해문제가있는개체이면자료에서제외한다. 예를들면 1103( 백만 ) 연봉을받는사람을조사하였더니외국인전문사장이었다. 국내 CEO 연봉으로간주하기어렵다면제외여전이유효한데이터이면자료변환을통하여이문제를해결하게된다. 변수변환 ( 자료변환 ) 을통하여이상치문제가해결되면이는치우침의한부분이된다. + 줄기수조정일반적으로자료의분포형태를잘파악하기위해서는줄기의수가 8-10 개정도되어야한다고한다. 연봉데이터예제에서본것처럼줄기수는변수측정치의범위에의해결정된다. 그러므로줄기의수를조정하여적절한줄기-잎그림을그려야한다. > 줄기수가너무많으면 (squeezed stems) 줄기를일정한수만큼합치는방법을생각하면된다. 만약줄기가 1-20 까지있다면 1-2, 3-4, 5-6,, 을각각줄기로하면줄기수가 20 개에서 10 개로줄어든다. 이처럼줄기수에따라 2 배, 3 배, 4 배씩줄이면된다. > 줄기수가너무적으면 (stretched stems) 줄기를 2 등분 (double stem) 혹은 5 등분 (five-line stem) 하여사용한다. ( 예 ) double stem: 1 * (1.0~1.4), 1. (1.5~1.9) ( 예 ) five-line stem: 1 * (.0,.1), 1 t (.2,.3), 1 f (.4,.5), 1 s (.6,.7), 1. (.8,.9) Professor Kwon, Sehyug Dept. of Statistics, HANNAM Univ
15 Exploratory Data Analysis Spring, 2012 Chapter 2. Univariate Analysis 적정줄기수에관한공식 > Sturges formula L [ 1 log 2 n] ( 예 ) n=30 L=5 > Velleman formula L [ 2 n] ( 예 ) n=30 L=10 > Dixon-Kronmal formula L [ 10log10 n] ( 예 ) n=30 L=14 그러나위의공식에의해줄기수 (L) 를결정하면자료값에따라줄기를결정하기어렵고분포형태를제대로알기어려운문제가있어이공식들은사용되지는않는다. [x] 의의미는 x 보다크지않는최대정수값을의미한다. [2.9]=2 / [3.1]=3 R 활용 - nclass 옵션은구간의개수를결정한다. - freq 옵션은빈도대신상대빈도 ( 확률 ) 을 y- 축으로사용하라는옵션 - 함수 lines() 는확률밀도함수를그리라는옵션 히스토그램그리기 합창단원의키에대한 ( 단위 : inch) 데이터이다. 1) 각파트별히스토그램을그리고해석하시오. ( 확률밀도함수도그리시오 ) 2) 키전체에대한히스토그램을그리고해석하시오. Professor Kwon, Sehyug Dept. of Statistics, HANNAM Univ
16 Exploratory Data Analysis Spring, 2012 Chapter 2. Univariate Analysis 상자수염그림 box whisker plot Stem and leaf( 줄기-잎 ) plot 은자료의분포의형태 ( 좌우대칭, 단봉 ) 파악과이상치를발견할수있는도구이다. 그러나 S-L plot 만가지고는정확한중앙위치, 자료의사분위값의위치 (25%, 50%, 75% 부분의값들 ), 이상치라시각적으로판단되는관측치가정말이상치인지알수진단해야한다. Box-whisker ( 상자수염 ) 그림은 plot 중앙값 ( 때로평균까지 ) [ 상자안의실선 ], 사분위위치, [ 상자끝단 ], 자료의최대값, 최소값 (whisker), 이상치존재여부 (bullet) 를그려놓은상자형태의그림이다. + Box and whisker plot 그리기상자로부터나온선이수염처럼생겨 Box and whisker plot 이라고하는 Box plot 을그리는순서는다음과같다. [CEO 자료이용 ] [ 순서 1] 자료의최소값, 최대값을이용하여 y 축선을그린다. [ 순서 2] Q1, Q3 를이용하여상자를그린다. 상자의넓이는아무의미가없다. [ 순서 3] 상자가운데중앙값을그리고평균은기호로 (+) 표시한다 (+)/ Professor Kwon, Sehyug Dept. of Statistics, HANNAM Univ
17 Exploratory Data Analysis Spring, 2012 Chapter 2. Univariate Analysis [ 순서 4]IQR 을이용하여가상선 (imaginary line) Inner fence, Outer fence 를그린다. 가상 선은실제상자그림에표시되지않는다. 이상치존재여부를표현하기위한임시선이다. IQR=( )=281 Inner fence ( Q IQR, Q IQR ) =(-159.5, 964.5) Outer fence ( Q1 3 IQR, Q3 3 IQR ) =(-581, 1386) [ 순서 5] 수염과이상치를표시한다. 관측치중 Inner fence 를넘지않는최대, 최소값까지 수염을그린다. Fence 를넘는관측치를이상치라 (outlier) 한다. outer fence 까지넘는 관측치는 severe ( 극심한 ) 이상치, inner fence 만넘으면 mile 이상치라한다. [CEO 에서 1103 은 mild 이상치 ] outer fence 1000 inner fence [ 분포함수 ] Professor Kwon, Sehyug Dept. of Statistics, HANNAM Univ
18 Exploratory Data Analysis Spring, 2012 Chapter 2. Univariate Analysis 줄기 - 잎그림 + Box Plot 해석하기분포의형태박스, 박스안의선 ( 중앙값 ), 수염의길이를이용하여분포의형태를짐작할수있다. 박스에 50% 자료가있고박스위부분에 25%, 박스아래부분에 25% 가있다. 박스내에서도중앙선위부분에 25%, 아래부분에 25% 가있으므로분포의형태를알수있다. CEO 연봉은우측으로치우친형태를띠고있음을알수있다. ( 위쪽, 즉확률밀도함수의오른쪽상자와수염부분이왼쪽에비해살짝길다 ) 그러므로평균이중앙값보다크므로역시치우친형태임을알수있다. 확률분포함수는빨간선이다. 단점은봉우리의개수를알지못하는단점이있으므로보완적으로줄기-잎그림그린다. 중앙값, 산포정도, 군집자료관측치의중앙위치, 그리고관측치들의어디에모여있는지 ( 군집 ), 자료값들의흩어진정도를파악할수있다. 중앙값이 350 부근 ( 실제로는 365) 임을알수있다. 값의범위 (range), 사분위값을대략적으로알수있다. Professor Kwon, Sehyug Dept. of Statistics, HANNAM Univ
19 Exploratory Data Analysis Spring, 2012 Chapter 2. Univariate Analysis 이상치존재판단자료관측치중다른값들에비해지나치게크거나작은관측치, 이상치의존재여부를파악할수있다. 연봉이 1100 이상을받는 CEO 는이상치임을알수있다. 줄기-잎그림을통해서는이상치존재여부를짐작할수있지만, 상자수염그림을통하여판단가능하다. stem-leaf plot 과는관측치값들에대한정보를얻을수없다는단점이있으나표본분포의형태도파악할수있고중앙값과이상치를표시하여표본자료의정보파악이용이하다. 특히 box-whisker plot 은집단간자료의분포차이비교, 모평균차이검정시매우유용한 plot 이다. 상자수염그리기 합창단원의키에대한 ( 단위 : inch) 데이터이다. 1) 키데이터전체에대한줄기-잎을그리고해석하시오. 2) 각파트의상자수염그림을한그래프에그리고해석하시오. 상자수염그리기 FASTFOOD.xls 미국 fast-food 레스토랑 5 개의 Drive-through 서비스소요시간을측정한것이다. 레스토랑상자 - 수염그림을한화면에그리고결과를해석하자. Professor Kwon, Sehyug Dept. of Statistics, HANNAM Univ
")
 데이터변수변환 ( 예 ) 로그변환, 제곱근변환 (2) 절삭평균 trimmed")
")
20 숫자요약구하기 : 중앙위치 ( 평균 mean) 크기의중앙, 관측치크기 (magnitude) 의중앙으로모든관측치를합한후데이터크기로나눈값 x x i n ( 치우침 skewness 존재 ) 평균은치우침에취약하므로다음사항을처치한다. (1) 데이터변수변환 ( 예 ) 로그변환, 제곱근변환 (2) 절삭평균 trimmed mean; 양측꼬리일부데이터를제외한평균 (3) Winsorized mean; 양측꼬리부분데이터를바로전데이터로대체하여구한평균 ( 이상치존재 ) 평균은이상치에매우취약하므로제거후평균을계산하다다. R 활용 다시아래이상치가발생 = > 제외해 보자 20
21 ( 중앙값 median) 순서의중앙, 관측치를크기중앙깊이 Median Depth = 순으로 ( 순서통계량 ) 하였을때중앙에위치한한관측치 ( n 1) 2 M x(( n 1) / 2) 숫자요약 : 흩어짐 (spread) ( 분산 variance) 관측치들이평균으로부터떨어진거리의제곱합을데이터크기혹은 ( 크기-1) 로나눈값이다. 관측치들의크기의흩어짐을측정한값이다. ( 표준편차 standard deviation) 2 (x i n x) 2, 2 s ( x i x) 2 n 1 2 분산의양의제곱근이다., s s, 단위가평균과동일하여분산대신신 ( 평균, 표준편차 ) 를숫자요약으로제시한다. 순서통계량 (order statistics) 크기가 n인표본자료의관측치 (observation) ( x 1, x 2,, xn ) 을크기순으로정렬한후가장작은관측치를 x ( 1), 그다음큰관측치를 x (2),,, 가장큰관측치를 x(nn ) 이라표현하고 x (1), x (2),.., x(nn ) 을순서통계량이라한다. 1) x ( 1) x(2)... x( n) 2) 최소값 (min): 4) 중앙값 (median): x n 1 (n이홀수 ) [ x n x n ]/ 2 (nn 이짝수 ) ( ) ( ) ( 1) Quartile depth = QD MD 1 2 ( 범위 range) 순서의흩어짐에대한측정값, R x(max) x (min) (midrange) x (1), 3) 최대값 (max) x ) : (n 범위도이상치나 치우침에영향을받으므로제삼분위 ~ 제일사분위값을정의한다. 21
22 Quartile ( 사분위 값 ) 구하기 > 일사분위 (First Quartile, Low Quartile) ) Q1; 자료의 25% 가그값보다작고자료의 75% 가그값보다크게될때그값을큰일사분위라정의한다. > 이사분위 (Second Quartile, Median) Q2=Median; ; 자료의 50% 가그값보다작고자료의 50% 가그값보다크게될때그값을큰이사분위라정의한다. 이를특히히중앙값이라한다. > 삼사분위 (Third Quartile, Upper Quartile) Q3; 자료 75% 가그값보다작고자료의 25% 가그값보다크게될때그값을큰삼사분위라 (Lower percentile) 정의한다다. Inter-Quartile Range (IQR=Q3-Q1); ( 삼사분위값- 일사분위값 ) 을 IQR(= =Q3-Q1) 로정의한다. 깊이 (depth) 각사분위값을구하려면자료의깊이 (depth) 개념을이용하면편리하다다. (Tukey 제안 ) 관측치를크기순으로정렬한후각양쪽끝에서 1 부터번호를매겨그번호를자료의깊이라정의한다. 즉최대값, 최소값의깊이는각 1 이다. Depth( 중앙값 =M)= ( n 1) / 2 이다. CEO 자료에서 Depth(M)= =15.5 이다. 크기순으로정렬했을때 15 번째관측치와 16 번째관측치의평균이다. ( x ( 15) x( 161 ) ) / 이다. Depth( (Q1)=Depth(Q3)=([Depth(M)]+1)/22 이다. [x]=xx 를넘지않는최대정수. [2.6]=2 CEO 자료에서 Depth(Q1/Q3) )=([15.5]+1)/2=8 이다. Q x ( 2622 이고 Q3 x ( 543이다. 1 8) 18) EDA 에서의 skewness 개념 ( Q Skew 3 ( Q3 M ) ( M Q1 ), 1 ske ew 1 M ) ( M Q1 ) E( X ) 3 왜도 (skewness): 분포의치우침을나타내는값으로 0( 정규분포포, t-분포 ) 이면좌우 3 대칭이고양의값이면우로치우침 (skewed to the right, positively skewed) ), 음의값이면좌로치우침 (skewed to the left, negatively skewed) 이다. 검정통계량은존재하지않는다. 22
23 kurtosis( 첨도 ): E( X ) 4 분포의첨예 ( 뾰족하다 ) 정도나타내는값으로정규분포는 3, 4 3보다크면완첨 (leptokurtic) 하다고 ( 봉우리가낮고완만하여평균주위에에데이터가있을확률이정규분포에비해낮고꼬리는가는형태 ) 하고 3 보다적으면급첨첨 (platykurtic) 하다한다 ( 봉우리가높고뽀족하며, 꼬리가두꺼운형태). 검정통계량없음. 정규분포를 0 하는경우계산된첨도-3 을첨도값으로주는패키지도있음. 함수 moment() 는패키지 moments 를설치하여야한다. 적률 momnent => k 차적률계산식 E( X ) k R 활용 왜도 =0.97, 우로치우침첨도 = =0.591,, 정규분포에비해중심은낮고완만하며꼬리가가늘다. 변동계수 (variation coefficient): 측정단위에따라표준편차의값의크기가달라지므로단위가다른두집단을비교하는경우두표준편차의단위를같게할필요가있다. 이를위하여표준편차를를평균으로나눈값에 100 을곱한값을변동계수 (CV: Coefficient of Variation) 라하고상대대변동 ( 분산 ) s 개념으로정의하고있다. 표본자료의평균이 x, 표준편차가 s 인경우 CV 100(%) x 이다. EXAMPLE 고등학교 3 학년인 A 학생과 B 학생의공부습관을조사하여한달간조사하여 A 학생은평균 3 시간, 표준편차는 0.5, B 학생은 6 시간표준편차 0.8 인결과를얻었다. 어느학생이더꾸준히공부하는습관을가지고있을까? 이에대한한답을위해변동계수를계산하면된다. A 학생공부시간에대한변동계수 = 0.5 / 3 100(%) =16.7 (%) B 학생공부시간에대한변동계수 = 0.8 / 6 100(%) =13.3 (%) 위의계산결과 B 학생이더꾸준히공부하는습관을가지고있다고결론론지을수있다. 23
24 데이터 정렬 attach(ds) newds=ds[order(ceo.salary),] newds2=ds[order(-ceo.salary),] ] R 활용 FASTFOOD.xls ( 레스토랑드라이브 through 서비스시간 ) 레스토랑별평균, 표준편차, 중위수, 사분위, 그리고 CV 값을계산하시오. (1) 그래프요약 ( 치우침, 이상치 ) 와비교하시오. (2) 변동계수를이용하여레스토랑서비스시간에대한평가를하시오. 24
25 치우침진단및해결 ( 중심극한정리 ) CLT in R 평균이 0.5 인지수분포로부터표본의크기 n=5, 10, 15, 20 인표본을추출하여평균을구하고, 이런작업을 100 번하여평균에대한히스토그램을을그리시오. split.screen(c(2,2)) 함수를이용하여 4 개히스토그램을한화면에그리시오. 커널분포함수도그리시오. Let (x 1, x 2,, x n ) be an iid sample drawnn from some distribution with an unknown density ƒ. We are interested in estimating the shape of this function ƒ. Itss kernel density estimator is 25
26 where K( ) is the kernel a symmetric but not necessarily positive function that integrates to one and h > 0 is a smoothing parameter called the bandwidth. A kernel with subscript h is called the scaled kernel and definedd as K h (x) = 1/h K(x/h). Intuitively one wants to choose h as smalll as the dataa allows, however theree is always a trade-off between the bias of the estimator and its variance; more on the choice of bandwidth later. A range of kernel functions are commonly used: uniform, triangular, biweight, triweight, Epanechnikov, normal, and others. The Epanechnikov kernel is optimal in a minimum variance sense, thoughh the loss of efficiency is small for the kernels listed previously, and due d to its convenient mathematical properties, the normal kernel is often used K(x) = ϕ(x), where ϕ is the standard s normal density function. (From Wikipedia) 시각적 진단 o히스토그램이나 상자수염그림의치우침 숫자요약진단 o평균과중위수차이 E( ( X ) 3 o 수리왜도 : 3 ( Q o EDA 왜도 : Ske 3 M ) ( M Q ew 1) ( Q3 M ) ( M Q1 ) o 정규성검정 : Anderson Darling 검정, K-S 검정, Shapiro-Wil ks 검정 26
27 치우침 해결 X 3, left X 2, mildd left o Power 변환 Y * Y, mildd right ln( Y ), right 1/ Y, severe right 치우침침진단과 해결 (BED~FEXP) 변수의치우침을진단하고치우침을해결하시오. 시각적진단 ( 히스토그램과 Kernel 분포함수이용 ) 과정규성검정활용하여치우침진단하고, 적절한파워변환에의해데이터치우침해결 BED = number of beds in home MCDAYS = annual medical in-patientt days (hundreds) TDAYS = annual total patient days (hundreds) PCREV = annual total patient care revenue ($hundreds) NSAL = annual nursing salaries ($hundreds) FEXP = annual facilities expenditures ($hundreds) RURAL = rural (1) and non-rural (0) homes 27
28 봉우리문제진단및해결 ( 봉우리개수의미 ) o봉우리개수는서로다른개채집단을의미 o성별을고려하지않은키 / 몸무게데이터, 학년을진단히스토그램활용 고려하지않은월용돈돈지출데이터 해결 집단을분리하여 분석 이상치진단및해결진단 상자- 수염그림해결 이상치 제거 일변량분석 28


")


 평균")

29 모비율 o모비율추정치 o모비율 p 에대한신뢰구간 o 가설 H0 : p p 0 vs. H0 : p p 0 Yes no 정규분포와 t-분포의관계 n이커지면 t(df n) Normal( 0,1) 이다. 소표본 (small sample) 일 경우중심극한정리를사용할 수없으므로표본 평균 x 의 분포는정규분포라할수없다. 대신모집단이정규분포를 따르면다음분포는 t-분포를따르므로소표본인경우모집단 평균가설 검정은 t-분포를 이용한다. x n ~ t( df n 1) 평균 =0, 분산 = s / n n 2 까만선은표준정규분포함수, 빨간점선은 t-분포함수이다. Why? t-분포의분산이크다. 29







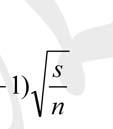

30 모평균 o모평균추정치 o모평균 에대한신뢰구간 o 가설 H0 : 0 vs. H0 : 0 pop. Dist. sample dist. Sampling dist. 30




31 모평균 차이검정 o모평균추정치 o모평균 1 2 에대한신뢰구간 pop. Dist. o 가설 H 0 : 1 2 vs. H0 : 1 2 sample dist. yes no Sampling dist. 31
32 METER.txt 이데이터는 47 개월동안 A시전체 (7,000 개 ) 주차요금징수기로부터터수금한주차비이다. CON 은주차비징수대행기관이 7,000 개전체를, CITY 는시청직원이징수한시청주변일부 47 개에서징수한요금이다. 위의데이터를징수요금 95% 이용하여 ( 대행기관, 시청직원직접징수 ) 주차요금 1 년평균 신뢰구간을구하시오. Wealth.txt 지역별기업인의재산, 나이, 지역을 조사한데이터이다. ASIA 와유럽기업가의재산평균차이에대한있는지검정하시오. 95% 신뢰구간을구하고고차이가 32
Microsoft Word - EDA_Univariate.docx
 일변량분석개념 일변량분석은개체의특성을 측정한변수가하나인 통계분석 방법 변수의 종류 ( 수리 통계 ) 이산형 (discrete): 측정결과를셀수있는경우이다. 성별, 직업, 교통량, 나이등이여기해당된다. 연속형 (continuous): 측정결과가무한이 (infinite) 많은변수를연속형형변수라한다. 즉변수의범위 (range) 중어떤구간을설정하더라도측정치가발생할할수있는경우로키,
일변량분석개념 일변량분석은개체의특성을 측정한변수가하나인 통계분석 방법 변수의 종류 ( 수리 통계 ) 이산형 (discrete): 측정결과를셀수있는경우이다. 성별, 직업, 교통량, 나이등이여기해당된다. 연속형 (continuous): 측정결과가무한이 (infinite) 많은변수를연속형형변수라한다. 즉변수의범위 (range) 중어떤구간을설정하더라도측정치가발생할할수있는경우로키,
위에서 100 단위이상을줄기로하기로결정하였고자료의최소값이 58, 최대값이 1103 이므로 0 부터 11 까지줄기를한열에크기순으로적는다. 줄기 (stem) 옆에잎을그린다. 잎을그리는방법은간단하다. 줄기바로뒤의숫자를줄기옆에차례로적으면된다. CEO 연봉자료는잎이두자리이지만앞
 옆에잎을그린다. 잎을그리는방법은간단하다. 줄기바로뒤의숫자를줄기옆에차례로적으면된다. CEO 연봉자료는잎이두자리이지만앞") 줄기잎그림 stem and leaf + 진단내용 1) 분포의개략적인형태를알수있다. (1) 좌우대칭인가? 아니면 skewed 되었는가? (2) 봉우리 (modal) 는하나인가? 아니면여러개인가? 2) 이상치의존재여부를쉽게파악할수있다. + 데이터 ( 정렬 ) ( 정렬않음 ) + 그리는순서 자료를크기순으로정리한다. 자료의수가많을때는자료정렬을수작업하기어려움으로이단계는무시해도되지만자료를크기순으로정렬해놓으면
줄기잎그림 stem and leaf + 진단내용 1) 분포의개략적인형태를알수있다. (1) 좌우대칭인가? 아니면 skewed 되었는가? (2) 봉우리 (modal) 는하나인가? 아니면여러개인가? 2) 이상치의존재여부를쉽게파악할수있다. + 데이터 ( 정렬 ) ( 정렬않음 ) + 그리는순서 자료를크기순으로정리한다. 자료의수가많을때는자료정렬을수작업하기어려움으로이단계는무시해도되지만자료를크기순으로정렬해놓으면
statistics
 수치를이용한자료요약 statistics hmkang@hallym.ac.kr 한림대학교 통계학 강희모 ( 한림대학교 ) 수치를이용한자료요약 1 / 26 수치를 통한 자료의 요약 요약 방대한 자료를 몇 개의 의미있는 수치로 요약 자료의 분포상태를 알 수 있는 통계기법 사용 중심위치의 측도(measure of center) : 어떤 값을 중심으로 분포되어 있는지
수치를이용한자료요약 statistics hmkang@hallym.ac.kr 한림대학교 통계학 강희모 ( 한림대학교 ) 수치를이용한자료요약 1 / 26 수치를 통한 자료의 요약 요약 방대한 자료를 몇 개의 의미있는 수치로 요약 자료의 분포상태를 알 수 있는 통계기법 사용 중심위치의 측도(measure of center) : 어떤 값을 중심으로 분포되어 있는지
Microsoft PowerPoint - SBE univariate5.pptx
 이상치 (outlier) 진단및해결 Homework 데이터 ( Option.XLS) 결과해석 치우침? 평균이중앙값에비해다소크다. 그러나이상치때문이지치우친것같지않음. Toys us 스톡옵션비율이이상치 해결방법 : Log 변환? 아니다치우쳐있지않기때문에제거 제거후 : 평균 :.74, 중위수 :.7 31 치우침과이상치 데이터 : 노트북평가점수 우로치우침과이상치가존재
이상치 (outlier) 진단및해결 Homework 데이터 ( Option.XLS) 결과해석 치우침? 평균이중앙값에비해다소크다. 그러나이상치때문이지치우친것같지않음. Toys us 스톡옵션비율이이상치 해결방법 : Log 변환? 아니다치우쳐있지않기때문에제거 제거후 : 평균 :.74, 중위수 :.7 31 치우침과이상치 데이터 : 노트북평가점수 우로치우침과이상치가존재
 소표본 (
소표본 ( R t-..
 R 과데이터분석 집단의차이비교 t- 검정 양창모 청주교육대학교컴퓨터교육과 2015 년겨울 t- 검정 변수의값이연속적이고정규분포를따른다고할때사용 t.test() 는모평균과모평균의 95% 신뢰구간을추청함과동시에가설검증을수행한다. 모평균의구간추정 - 일표본 t- 검정 이가설검정의귀무가설은 모평균이 0 이다 라는귀무가설이다. > x t.test(x)
R 과데이터분석 집단의차이비교 t- 검정 양창모 청주교육대학교컴퓨터교육과 2015 년겨울 t- 검정 변수의값이연속적이고정규분포를따른다고할때사용 t.test() 는모평균과모평균의 95% 신뢰구간을추청함과동시에가설검증을수행한다. 모평균의구간추정 - 일표본 t- 검정 이가설검정의귀무가설은 모평균이 0 이다 라는귀무가설이다. > x t.test(x)
Microsoft Word - SAS_Data Manipulate.docx
 수학계산관련 함수 함수 형태 내용 SIN(argument) TAN(argument) EXP( 변수명 ) SIN 값을계산 -1 argument 1 TAN 값을계산, -1 argument 1 지수함수로지수값을계산한다 SQRT( 변수명 ) 제곱근값을계산한다 제곱은 x**(1/3) = 3 x x 1/ 3 x**2, 세제곱근 LOG( 변수명 ) LOGN( 변수명 )
수학계산관련 함수 함수 형태 내용 SIN(argument) TAN(argument) EXP( 변수명 ) SIN 값을계산 -1 argument 1 TAN 값을계산, -1 argument 1 지수함수로지수값을계산한다 SQRT( 변수명 ) 제곱근값을계산한다 제곱은 x**(1/3) = 3 x x 1/ 3 x**2, 세제곱근 LOG( 변수명 ) LOGN( 변수명 )
3 장기술통계 : 수치척도 Part B 분포형태, 상대적위치, 극단값 탐색적자료분석 두변수간의관련성측정 가중평균과그룹화자료
 3 장기술통계 : 수치척도 Part B 분포형태, 상대적위치, 극단값 탐색적자료분석 두변수간의관련성측정 가중평균과그룹화자료 분포형태, 상대적위치, 극단값 분포형태 z-값 체비셰프의원리 경험법칙 극단값찾기 분포형태 : 왜도 (skewness) 분포형태를측정하는중요한척도중하나를 왜도 라고한다. 자료집합의왜도를구하는계산식은조금복잡하다. 통계프로그램을사용하여왜도를쉽게계산할수있다.
3 장기술통계 : 수치척도 Part B 분포형태, 상대적위치, 극단값 탐색적자료분석 두변수간의관련성측정 가중평균과그룹화자료 분포형태, 상대적위치, 극단값 분포형태 z-값 체비셰프의원리 경험법칙 극단값찾기 분포형태 : 왜도 (skewness) 분포형태를측정하는중요한척도중하나를 왜도 라고한다. 자료집합의왜도를구하는계산식은조금복잡하다. 통계프로그램을사용하여왜도를쉽게계산할수있다.
(001~006)개념RPM3-2(부속)
개념RPM3-2(부속)") www.imth.tv - (~9)개념RPM-(본문).. : PM RPM - 대푯값 페이지 다민 PI LPI 알피엠 대푯값과산포도 유형 ⑴ 대푯값 자료 전체의 중심적인 경향이나 특징을 하나의 수로 나타낸 값 ⑵ 평균 (평균)= Ⅰ 통계 (변량)의 총합 (변량의 개수) 개념플러스 대푯값에는 평균, 중앙값, 최 빈값 등이 있다. ⑶ 중앙값 자료를 작은 값부터 크기순으로
www.imth.tv - (~9)개념RPM-(본문).. : PM RPM - 대푯값 페이지 다민 PI LPI 알피엠 대푯값과산포도 유형 ⑴ 대푯값 자료 전체의 중심적인 경향이나 특징을 하나의 수로 나타낸 값 ⑵ 평균 (평균)= Ⅰ 통계 (변량)의 총합 (변량의 개수) 개념플러스 대푯값에는 평균, 중앙값, 최 빈값 등이 있다. ⑶ 중앙값 자료를 작은 값부터 크기순으로
untitled
 Math. Statistics: Statistics? 1 What is Statistics? 1. (collection), (summarization), (analyzing), (presentation) (information) (statistics).., Survey, :, : : QC, 6-sigma, Data Mining(CRM) (Econometrics)
Math. Statistics: Statistics? 1 What is Statistics? 1. (collection), (summarization), (analyzing), (presentation) (information) (statistics).., Survey, :, : : QC, 6-sigma, Data Mining(CRM) (Econometrics)
공공기관임금프리미엄추계 연구책임자정진호 ( 한국노동연구원선임연구위원 ) 연구원오호영 ( 한국직업능력개발원연구위원 ) 연구보조원강승복 ( 한국노동연구원책임연구원 ) 이연구는국회예산정책처의정책연구용역사업으로 수행된것으로서, 본연구에서제시된의견이나대안등은
 연구원오호영 ( 한국직업능력개발원연구위원 ) 연구보조원강승복 ( 한국노동연구원책임연구원 ) 이연구는국회예산정책처의정책연구용역사업으로 수행된것으로서, 본연구에서제시된의견이나대안등은") 2013 년도연구용역보고서 공공기관임금프리미엄추계 - 2013. 12.- 이연구는국회예산정책처의연구용역사업으로수행된것으로서, 보고서의내용은연구용역사업을수행한연구자의개인의견이며, 국회예산정책처의공식견해가아님을알려드립니다. 연구책임자 한국노동연구원선임연구위원정진호 공공기관임금프리미엄추계 2013. 12. 연구책임자정진호 ( 한국노동연구원선임연구위원 ) 연구원오호영
2013 년도연구용역보고서 공공기관임금프리미엄추계 - 2013. 12.- 이연구는국회예산정책처의연구용역사업으로수행된것으로서, 보고서의내용은연구용역사업을수행한연구자의개인의견이며, 국회예산정책처의공식견해가아님을알려드립니다. 연구책임자 한국노동연구원선임연구위원정진호 공공기관임금프리미엄추계 2013. 12. 연구책임자정진호 ( 한국노동연구원선임연구위원 ) 연구원오호영
통계학입문
 통계학입문 ( 기초통계학 ) 1. 1 개요 통계학 (statistics) 관심의대상에대해관련된자료를수집하고그 자료를요약, 정리하여이로부터불확실한사실에 대한결론이나일반적인규칙성을추구하는학문 Statistic : 통계치, 통계량 CH 1-2 1. 1 개요 통계학 (statistics) 기술통계학 (descriptive stat) 수집된자료의정리및요약방법을다룸
통계학입문 ( 기초통계학 ) 1. 1 개요 통계학 (statistics) 관심의대상에대해관련된자료를수집하고그 자료를요약, 정리하여이로부터불확실한사실에 대한결론이나일반적인규칙성을추구하는학문 Statistic : 통계치, 통계량 CH 1-2 1. 1 개요 통계학 (statistics) 기술통계학 (descriptive stat) 수집된자료의정리및요약방법을다룸
중심경향치 (measure of central tendency) 대표값이란용어이외에자료의중심값또는중심위치의척도 (measure of central location) 라고도함. 예 : 평균 (mean= 산술평균 ; arithmetic mean), 절사평균 (trimmed
 대표값이란용어이외에자료의중심값또는중심위치의척도 (measure of central location) 라고도함. 예 : 평균 (mean= 산술평균 ; arithmetic mean), 절사평균 (trimmed") 중심경향치 (measure of central tendency) 대표값이란용어이외에자료의중심값또는중심위치의척도 (measure of central location) 라고도함. 예 : 평균 (mean= 산술평균 ; arithmetic mean), 절사평균 (trimmed mean), 가중평균 (weighted mean), 기하평균 (geometric mean),
중심경향치 (measure of central tendency) 대표값이란용어이외에자료의중심값또는중심위치의척도 (measure of central location) 라고도함. 예 : 평균 (mean= 산술평균 ; arithmetic mean), 절사평균 (trimmed mean), 가중평균 (weighted mean), 기하평균 (geometric mean),
G Power
 G Power 부산대학교통계학과조영석 1. G Power 란? 2. G Power 설치및실행 2.1 G Power 설치 2.2 G Power 실행 3. 검정 (Test) 3.1 가설검정 (Test of hypothesis) 3.2 검정력 (Power) 3.3 효과크기 (Effect size) 3.4 표본수산정 4. 분석 4.1 t- 검정 (t-test) 4.2
G Power 부산대학교통계학과조영석 1. G Power 란? 2. G Power 설치및실행 2.1 G Power 설치 2.2 G Power 실행 3. 검정 (Test) 3.1 가설검정 (Test of hypothesis) 3.2 검정력 (Power) 3.3 효과크기 (Effect size) 3.4 표본수산정 4. 분석 4.1 t- 검정 (t-test) 4.2
생존분석의 추정과 비교 : 보충자료 이용희 December 12, 2018 Contents 1 생존함수와 위험함수 생존함수와 위험함수 예제: 지수분포
 생존분석의 추정과 비교 : 보충자료 이용희 December, 8 Cotets 생존함수와 위험함수. 생존함수와 위험함수....................................... 예제: 지수분포.......................................... 예제: 와이블분포.........................................
생존분석의 추정과 비교 : 보충자료 이용희 December, 8 Cotets 생존함수와 위험함수. 생존함수와 위험함수....................................... 예제: 지수분포.......................................... 예제: 와이블분포.........................................
Microsoft PowerPoint - Stat03_Numerical technique(New) [Compatibility Mode]
![Microsoft PowerPoint - Stat03_Numerical technique(New) [Compatibility Mode]](/thumbs/104/163558433.jpg "Microsoft PowerPoint - Stat03_Numerical technique(New) [Compatibility Mode]") Descriptive Statistics Describing data with tables and graphs (quantitative or categorical variables) Descriptive Statistics (Numerical techniques) Numerical descriptions of center, variability, position
Descriptive Statistics Describing data with tables and graphs (quantitative or categorical variables) Descriptive Statistics (Numerical techniques) Numerical descriptions of center, variability, position
통계학입문
 확률및통계특강 세부사항 교수님 성함 : 김홍기 연락처 : 821-5433 E-mail : honggiekim@cnu.ac.kr 교재 : 통계학입문 ( 정익사 / 김주한외 ) 강의자료 ppt 파일은정보통계학과홈페이지 -> 대학원 -> 수업자료 또는사이버캠퍼스자료실 이사이트에서기출문제도얻을수있습니다. 중간고사 (closed book) : 45%, 기말고사 (open
확률및통계특강 세부사항 교수님 성함 : 김홍기 연락처 : 821-5433 E-mail : honggiekim@cnu.ac.kr 교재 : 통계학입문 ( 정익사 / 김주한외 ) 강의자료 ppt 파일은정보통계학과홈페이지 -> 대학원 -> 수업자료 또는사이버캠퍼스자료실 이사이트에서기출문제도얻을수있습니다. 중간고사 (closed book) : 45%, 기말고사 (open
Microsoft Word - Chapter6.doc
 CHAPTER 6 기초통계량분석 분류형 ( 범주형 ) 변수데이터에대한정리방법으로는숫자요약인빈도분석과그래프요약인파이차트, 바차트가이용된다. 측정형변수에대한숫자요약은일반적으로자료의중앙위치와자료의흩어진정도를나타내는두개의값으로축약된다. 즉, 크기 n 개의데이터의가진정보가 2 개숫자요약으로축약 (data reduction) 된다. 데이터의중앙위치에대한통계량평균 (mean)
CHAPTER 6 기초통계량분석 분류형 ( 범주형 ) 변수데이터에대한정리방법으로는숫자요약인빈도분석과그래프요약인파이차트, 바차트가이용된다. 측정형변수에대한숫자요약은일반적으로자료의중앙위치와자료의흩어진정도를나타내는두개의값으로축약된다. 즉, 크기 n 개의데이터의가진정보가 2 개숫자요약으로축약 (data reduction) 된다. 데이터의중앙위치에대한통계량평균 (mean)
10. ..
 점추정구간추정표본크기 차례 점추정구간추정표본크기 1 점추정 2 구간추정 3 표본크기 추정의종류 점추정구간추정표본크기 점추정 (point estimation): 모수를어떤하나의값으로추측하는것 구간추정 (interval estimation): 모수를어떤구간으로추측하는것 예 ) 피그미족 (Pygmytribe) 의평균키는모수 µ 표본을추출하여평균을구해보니 135cm
점추정구간추정표본크기 차례 점추정구간추정표본크기 1 점추정 2 구간추정 3 표본크기 추정의종류 점추정구간추정표본크기 점추정 (point estimation): 모수를어떤하나의값으로추측하는것 구간추정 (interval estimation): 모수를어떤구간으로추측하는것 예 ) 피그미족 (Pygmytribe) 의평균키는모수 µ 표본을추출하여평균을구해보니 135cm
확률과통계 강의자료-1.hwp
 1. 통계학이란? 1.1 수학적 모형 실험 또는 증명을 통하여 자연현상을 분석하기 위한 수학적인 모형 1 결정모형 (deterministic model) - 뉴톤의 운동방정식 : - 보일-샤를의 법칙 : 일정량의 기체의 부피( )는 절대 온도()에 정비례하고, 압력( )에 반비례한다. 2 확률모형 (probabilistic model) - 주사위를 던질 때
1. 통계학이란? 1.1 수학적 모형 실험 또는 증명을 통하여 자연현상을 분석하기 위한 수학적인 모형 1 결정모형 (deterministic model) - 뉴톤의 운동방정식 : - 보일-샤를의 법칙 : 일정량의 기체의 부피( )는 절대 온도()에 정비례하고, 압력( )에 반비례한다. 2 확률모형 (probabilistic model) - 주사위를 던질 때
슬라이드 1
 27 제 3 장수치요약 상자그림 1. 다섯수치요약평균 (Mean) 어떤경우에는상당히불확실하다. 예를들면점수분포가작은값에편중되고큰값쪽으로길게꼬리를뻗고있는경우점수분포가큰값쪽에편중되고작은값쪽으로길게꼬리를뻗고있는경우분포의대칭성여부를알지못하는경우평균은대표값의역할을할수없다. 작은값에편중, 큰값쪽으로꼬리가긴모형 큰값에편중, 작은값쪽으로꼬리가긴모형 28 중위수 (Median)
27 제 3 장수치요약 상자그림 1. 다섯수치요약평균 (Mean) 어떤경우에는상당히불확실하다. 예를들면점수분포가작은값에편중되고큰값쪽으로길게꼬리를뻗고있는경우점수분포가큰값쪽에편중되고작은값쪽으로길게꼬리를뻗고있는경우분포의대칭성여부를알지못하는경우평균은대표값의역할을할수없다. 작은값에편중, 큰값쪽으로꼬리가긴모형 큰값에편중, 작은값쪽으로꼬리가긴모형 28 중위수 (Median)
Microsoft PowerPoint - 26.pptx
 이산수학 () 관계와그특성 (Relations and Its Properties) 2011년봄학기 강원대학교컴퓨터과학전공문양세 Binary Relations ( 이진관계 ) Let A, B be any two sets. A binary relation R from A to B, written R:A B, is a subset of A B. (A 에서 B 로의이진관계
이산수학 () 관계와그특성 (Relations and Its Properties) 2011년봄학기 강원대학교컴퓨터과학전공문양세 Binary Relations ( 이진관계 ) Let A, B be any two sets. A binary relation R from A to B, written R:A B, is a subset of A B. (A 에서 B 로의이진관계
Microsoft PowerPoint - PDF3 SBE 20080417.pptx
 연속형 확률밀도함수 연속형 확률분포함수? 데이터 히스토그램의 정상을 연결하면 확률분포함수가 된다. 이를 이용하여 데이터(표본)의 분포(이는 모집단의 분포와 동일)를 구 하게 된다. 그러나 함수를 구하는 것은 불가능해 보인다. 그래서 현실에서는 확률분포를 가정하게 된다. (예)기다리는 시간: 지수분포, 측정 오 차: 정규분포 Gauss(천문학자): 행성들간 거리
연속형 확률밀도함수 연속형 확률분포함수? 데이터 히스토그램의 정상을 연결하면 확률분포함수가 된다. 이를 이용하여 데이터(표본)의 분포(이는 모집단의 분포와 동일)를 구 하게 된다. 그러나 함수를 구하는 것은 불가능해 보인다. 그래서 현실에서는 확률분포를 가정하게 된다. (예)기다리는 시간: 지수분포, 측정 오 차: 정규분포 Gauss(천문학자): 행성들간 거리
untitled
 5.8 PROC UNIVARIATE (hitogram, tem and leaf plot, box-whiker plot), (p- ). Univariate( ).. NORMAL (Shapiro- Wilk Kolmogorov-Smirno D- OUTPUT( SAS ). PROC MEANS PROC MEANS. (moment) E( X ). k Sehyug Kwon,
5.8 PROC UNIVARIATE (hitogram, tem and leaf plot, box-whiker plot), (p- ). Univariate( ).. NORMAL (Shapiro- Wilk Kolmogorov-Smirno D- OUTPUT( SAS ). PROC MEANS PROC MEANS. (moment) E( X ). k Sehyug Kwon,
<4D F736F F D20BDC3B0E8BFADBAD0BCAE20C1A B0AD5FBCF6C1A45FB0E8B7AEB0E6C1A6C7D E646F63>
 제 3 강계량경제학 Review Par I. 단순회귀모형 I. 계량경제학 A. 계량경제학 (Economerics 이란? i. 경제적이론이설명하는경제변수들간의관계를경제자료를바탕으로통 계적으로추정 (esimaion 고검정 (es 하는학문 거시소비함수 (Keynse. C=f(Y, 0
제 3 강계량경제학 Review Par I. 단순회귀모형 I. 계량경제학 A. 계량경제학 (Economerics 이란? i. 경제적이론이설명하는경제변수들간의관계를경제자료를바탕으로통 계적으로추정 (esimaion 고검정 (es 하는학문 거시소비함수 (Keynse. C=f(Y, 0
확률 및 분포
 확률및분포 박창이 서울시립대학교통계학과 박창이 ( 서울시립대학교통계학과 ) 확률및분포 1 / 15 학습내용 조건부확률막대그래프히스토그램선그래프산점도참고 박창이 ( 서울시립대학교통계학과 ) 확률및분포 2 / 15 조건부확률 I 첫째가딸일때두아이모두딸일확률 (1/2) 과둘중의하나가딸일때둘다딸일확률 (1/3) 에대한모의실험 >>> from collections import
확률및분포 박창이 서울시립대학교통계학과 박창이 ( 서울시립대학교통계학과 ) 확률및분포 1 / 15 학습내용 조건부확률막대그래프히스토그램선그래프산점도참고 박창이 ( 서울시립대학교통계학과 ) 확률및분포 2 / 15 조건부확률 I 첫째가딸일때두아이모두딸일확률 (1/2) 과둘중의하나가딸일때둘다딸일확률 (1/3) 에대한모의실험 >>> from collections import
untitled
 R 과함께하는통계학의이해 빅북이라명명된이책은지식공유의세계적인흐름에동참하고지적인업적들이세상과인류의지식이되도록하며, 누구나쉽게접근하고활용할수있는환경을만들고자한다. 이책의저작권은빅북 (www.bigbook.or.kr) 에있으며모든용도로활용할수있다. 다만상업용출판을하고자하는경우에는사전에문서로된허락을받아야한다. 공유와협력의교과서만들기운동본부 R 과함께하는 통계학의이해
R 과함께하는통계학의이해 빅북이라명명된이책은지식공유의세계적인흐름에동참하고지적인업적들이세상과인류의지식이되도록하며, 누구나쉽게접근하고활용할수있는환경을만들고자한다. 이책의저작권은빅북 (www.bigbook.or.kr) 에있으며모든용도로활용할수있다. 다만상업용출판을하고자하는경우에는사전에문서로된허락을받아야한다. 공유와협력의교과서만들기운동본부 R 과함께하는 통계학의이해
모수검정과비모수검정 제 6 강 지리통계학
 모수검정과비모수검정 제 6 강 지리통계학 통계적추정의목적 연구자가주장하는연구가설을입증하기위한것 1 연구목적에맞는연구가설을설정 2 연구목적과수집된자료에부합되는적절한통계적검정방법을선택 3 귀무가설과연구가설 ( 대립가설 ) 을진술 4 유의수준을결정한후각분포유형에따라분포표를이용하여임계치를구하고기각역을설정 5 통계적검정유형에필요한통계량을각검정유형의공식을이용하여계산 6
모수검정과비모수검정 제 6 강 지리통계학 통계적추정의목적 연구자가주장하는연구가설을입증하기위한것 1 연구목적에맞는연구가설을설정 2 연구목적과수집된자료에부합되는적절한통계적검정방법을선택 3 귀무가설과연구가설 ( 대립가설 ) 을진술 4 유의수준을결정한후각분포유형에따라분포표를이용하여임계치를구하고기각역을설정 5 통계적검정유형에필요한통계량을각검정유형의공식을이용하여계산 6
Microsoft PowerPoint Relations.pptx
 이산수학 () 관계와그특성 (Relations and Its Properties) 2010년봄학기강원대학교컴퓨터과학전공문양세 Binary Relations ( 이진관계 ) Let A, B be any two sets. A binary relation R from A to B, written R:A B, is a subset of A B. (A 에서 B 로의이진관계
이산수학 () 관계와그특성 (Relations and Its Properties) 2010년봄학기강원대학교컴퓨터과학전공문양세 Binary Relations ( 이진관계 ) Let A, B be any two sets. A binary relation R from A to B, written R:A B, is a subset of A B. (A 에서 B 로의이진관계
Vector Differential: 벡터 미분 Yonghee Lee October 17, 벡터미분의 표기 스칼라미분 벡터미분(Vector diffrential) 또는 행렬미분(Matrix differential)은 벡터와 행렬의 미분식에 대 한 표
 또는 행렬미분(Matrix differential)은 벡터와 행렬의 미분식에 대 한 표") Vector Differential: 벡터 미분 Yonhee Lee October 7, 08 벡터미분의 표기 스칼라미분 벡터미분(Vector diffrential) 또는 행렬미분(Matrix differential)은 벡터와 행렬의 미분식에 대 한 표기법을 정의하는 방법이다 보통 스칼라(scalar)에 대한 미분은 일분수 함수 f : < < 또는 다변수 함수(function
Vector Differential: 벡터 미분 Yonhee Lee October 7, 08 벡터미분의 표기 스칼라미분 벡터미분(Vector diffrential) 또는 행렬미분(Matrix differential)은 벡터와 행렬의 미분식에 대 한 표기법을 정의하는 방법이다 보통 스칼라(scalar)에 대한 미분은 일분수 함수 f : < < 또는 다변수 함수(function
확률과통계6
 확률과통계 6. 이산형확률분포 건국대학교스마트 ICT 융합공학과윤경로 (yoonk@konkuk.ac.kr) 6. 이산형확률분포 6.1 이산균일분포 6.2 이항분포 6.3 초기하분포 6.4 포아송분포 6.5 기하분포 6.6 음이항분포 * ( 제외 ) 6.7 다항분포 * ( 제외 ) 6.1 이산균일분포 [ 정의 6-1] 이산균일분포 (discrete uniform
확률과통계 6. 이산형확률분포 건국대학교스마트 ICT 융합공학과윤경로 (yoonk@konkuk.ac.kr) 6. 이산형확률분포 6.1 이산균일분포 6.2 이항분포 6.3 초기하분포 6.4 포아송분포 6.5 기하분포 6.6 음이항분포 * ( 제외 ) 6.7 다항분포 * ( 제외 ) 6.1 이산균일분포 [ 정의 6-1] 이산균일분포 (discrete uniform
Microsoft PowerPoint - ºÐÆ÷ÃßÁ¤(ÀüÄ¡Çõ).ppt
.ppt") 수명분포및신뢰도의 통계적추정 포항공과대학교산업공학과전치혁.. 수명및수명분포 수명 - 고장 까지의시간 - 확률변수로간주 - 통상잘알려진분포를따른다고가정 수명분포 - 확률밀도함수또는 누적 분포함수로표현 - 신뢰도, 고장률, MTTF 등신뢰성지표는수명분포로부터도출 - 수명분포추정은분포함수관련모수의추정 누적분포함수및확률밀도함수 누적분포함수 cumulav dsbuo
수명분포및신뢰도의 통계적추정 포항공과대학교산업공학과전치혁.. 수명및수명분포 수명 - 고장 까지의시간 - 확률변수로간주 - 통상잘알려진분포를따른다고가정 수명분포 - 확률밀도함수또는 누적 분포함수로표현 - 신뢰도, 고장률, MTTF 등신뢰성지표는수명분포로부터도출 - 수명분포추정은분포함수관련모수의추정 누적분포함수및확률밀도함수 누적분포함수 cumulav dsbuo
PowerPoint 프레젠테이션
 응용식물통계학 Statistics of Applied Plants Science 친환경식물학부유기농생태학전공황선구 13 장상관분석 1. 상관계수 2. 상관분석의가정과특성 3. 모상관계수의검정과신뢰한계 4. 순위상관 14 장회귀분석 1. 회귀직선의추정 2. 회귀직선의검정및추론 3. 모집단절편과회귀계수의구간추정 4. 곡선회귀 - 실습 - 상관분석 지금까지한가지확률변수에의한현상을검정하였다.
응용식물통계학 Statistics of Applied Plants Science 친환경식물학부유기농생태학전공황선구 13 장상관분석 1. 상관계수 2. 상관분석의가정과특성 3. 모상관계수의검정과신뢰한계 4. 순위상관 14 장회귀분석 1. 회귀직선의추정 2. 회귀직선의검정및추론 3. 모집단절편과회귀계수의구간추정 4. 곡선회귀 - 실습 - 상관분석 지금까지한가지확률변수에의한현상을검정하였다.
Microsoft PowerPoint - LN05 [호환 모드]
![Microsoft PowerPoint - LN05 [호환 모드]](/thumbs/103/161577104.jpg "Microsoft PowerPoint - LN05 [호환 모드]") 계량재무분석 I Chapter 6 & 7 Probability Distribution II 경영대학재무금융학과 윤선중 0 Objectives 확률변수 이산확률분포 (Discrete Random Variables): 셀수있는확률변수 연속확률분포 (Continuous Random Variables): 셀수없는경우의수 이산확률변수 분포의대표값 기대치 (Expected
계량재무분석 I Chapter 6 & 7 Probability Distribution II 경영대학재무금융학과 윤선중 0 Objectives 확률변수 이산확률분포 (Discrete Random Variables): 셀수있는확률변수 연속확률분포 (Continuous Random Variables): 셀수없는경우의수 이산확률변수 분포의대표값 기대치 (Expected
자료의 이해 및 분석
 어떤실험이나치료의효과를측정할때독립이아닌표본으로부터관찰치를얻었을때처리하는방법 - 동일한개체에어떤처리를하기전과후의자료를얻을때 - 가능한동일한특성을갖는두개의개체에서로다른처리를하여그처리의효과를비교하는방법 (matching) 1 예제 : 혈청 cholesterol 치를줄이기위해서 12 명을대상으로운동과함께식이요법의효과를 측정하기위한실험실시 2 식이요법 - 운동실험전과후의
어떤실험이나치료의효과를측정할때독립이아닌표본으로부터관찰치를얻었을때처리하는방법 - 동일한개체에어떤처리를하기전과후의자료를얻을때 - 가능한동일한특성을갖는두개의개체에서로다른처리를하여그처리의효과를비교하는방법 (matching) 1 예제 : 혈청 cholesterol 치를줄이기위해서 12 명을대상으로운동과함께식이요법의효과를 측정하기위한실험실시 2 식이요법 - 운동실험전과후의
= ``...(2011), , (.)''
, , (.)''") Finance Lecture Note Series 사회과학과 수학 제2강. 미분 조 승 모2 영남대학교 경제금융학부 학습목표. 미분의 개념: 미분과 도함수의 개념에 대해 알아본다. : 실제로 미분을 어떻게 하는지 알아본다. : 극값의 개념을 알아보고 미분을 통해 어떻게 구하는지 알아본다. 4. 미분과 극한: 미분을 이용하여 극한값을 구하는 방법에 대해 알아본다.
Finance Lecture Note Series 사회과학과 수학 제2강. 미분 조 승 모2 영남대학교 경제금융학부 학습목표. 미분의 개념: 미분과 도함수의 개념에 대해 알아본다. : 실제로 미분을 어떻게 하는지 알아본다. : 극값의 개념을 알아보고 미분을 통해 어떻게 구하는지 알아본다. 4. 미분과 극한: 미분을 이용하여 극한값을 구하는 방법에 대해 알아본다.
이다. 즉 μ μ μ : 가아니다. 이러한검정을하기위하여분산분석은다음과같은가정을두고있다. 분산분석의가정 (1) r개모집단분포는모두정규분포를이루고있다. (2) r개모집단의평균은다를수있으나분산은모두같다. (3) r개모집단에서추출한표본은서로독립적이다. 분산분석은집단을구분하는
 r개모집단분포는모두정규분포를이루고있다. (2) r개모집단의평균은다를수있으나분산은모두같다. (3) r개모집단에서추출한표본은서로독립적이다. 분산분석은집단을구분하는") 제 12 강분산분석 분산분석 (ANOVA) (1) 1. 개요 비교하는집단의수가 3개이상일경우에사용되는통계기법이분산분석이다. 두표본 t검증에서는문제의단순성때문에야기되지않는문제들이다수의표본으로확대됨에따라문제들이야기되기도한다. 다음과같은 r개의모집단이있다고가정하자..... ~ N( μ σ ) ~ N( μ σ ).... ~ N ( μ σ )...... 위의그림과같이여러번에걸쳐두표본의
제 12 강분산분석 분산분석 (ANOVA) (1) 1. 개요 비교하는집단의수가 3개이상일경우에사용되는통계기법이분산분석이다. 두표본 t검증에서는문제의단순성때문에야기되지않는문제들이다수의표본으로확대됨에따라문제들이야기되기도한다. 다음과같은 r개의모집단이있다고가정하자..... ~ N( μ σ ) ~ N( μ σ ).... ~ N ( μ σ )...... 위의그림과같이여러번에걸쳐두표본의
고객관계를 리드하는 서비스 리더십 전략
 제 13 장분산분석 1 13.1 일원분산분석 13. 분산분석 - 무작위블럭디자인 13.3 이원분산분석 - 팩토리얼디자인 분산분석 (ANOVA) - 두개이상의집단들의평균값을비교하는데사용. 일원분산분석 - 처치변수가한개인분산분석. 1. 분산분석의원리 A 3.0 8.0 7.0 5.0 5.0 6.0 4.0 7.0 6.0 4.0 평균 5.0 6.0 B 3.0 9.0
제 13 장분산분석 1 13.1 일원분산분석 13. 분산분석 - 무작위블럭디자인 13.3 이원분산분석 - 팩토리얼디자인 분산분석 (ANOVA) - 두개이상의집단들의평균값을비교하는데사용. 일원분산분석 - 처치변수가한개인분산분석. 1. 분산분석의원리 A 3.0 8.0 7.0 5.0 5.0 6.0 4.0 7.0 6.0 4.0 평균 5.0 6.0 B 3.0 9.0
..(..) (..) - statistics
 (..) - statistics") 수치 ( 數値 ) 를이용한자료요약 ( 要約 ) statistics hmkang@hallym.ac.kr 한림대학교 한중시장분석 강희모 ( 한림대학교 ) 수치 ( 數値 ) 를이용한자료요약 ( 要約 ) 1 / 26 수치를 통한 자료의 요약 요약(要約,summary) 많은 자료를 몇 개의 의미(意味)있는 수치로 요약 자료의 분포상태(分布狀態)를 알 수 있는 통계기법(統計技法)
수치 ( 數値 ) 를이용한자료요약 ( 要約 ) statistics hmkang@hallym.ac.kr 한림대학교 한중시장분석 강희모 ( 한림대학교 ) 수치 ( 數値 ) 를이용한자료요약 ( 要約 ) 1 / 26 수치를 통한 자료의 요약 요약(要約,summary) 많은 자료를 몇 개의 의미(意味)있는 수치로 요약 자료의 분포상태(分布狀態)를 알 수 있는 통계기법(統計技法)
기술통계
 기술통계 박창이 서울시립대학교통계학과 박창이 ( 서울시립대학교통계학과 ) 기술통계 1 / 17 친구수에대한히스토그램 I from matplotlib import pyplot as plt from collections import Counter num_friends = [100,49,41,40,25,21,21,19,19,18,18,16, 15,15,15,15,14,14,13,13,13,13,12,
기술통계 박창이 서울시립대학교통계학과 박창이 ( 서울시립대학교통계학과 ) 기술통계 1 / 17 친구수에대한히스토그램 I from matplotlib import pyplot as plt from collections import Counter num_friends = [100,49,41,40,25,21,21,19,19,18,18,16, 15,15,15,15,14,14,13,13,13,13,12,
Microsoft Word - SPSS_MDA_Ch6.doc
 Chapter 6. 정준상관분석 6.1 정준상관분석 정준상관분석 (Canonical Correlation Analysis) 은변수들의군집간선형상관관계를파악하는분석방법이다. 예를들어신체적조건 ( 키, 몸무게, 가슴둘레 ) 과운동력 ( 달리기, 윗몸일으키기, 턱걸이 ) 사이의선형상관관계가있는지알아보고, 관계가있다면어떤관계가있는지분석하는것이다. 정준상관분석은 (
Chapter 6. 정준상관분석 6.1 정준상관분석 정준상관분석 (Canonical Correlation Analysis) 은변수들의군집간선형상관관계를파악하는분석방법이다. 예를들어신체적조건 ( 키, 몸무게, 가슴둘레 ) 과운동력 ( 달리기, 윗몸일으키기, 턱걸이 ) 사이의선형상관관계가있는지알아보고, 관계가있다면어떤관계가있는지분석하는것이다. 정준상관분석은 (
Microsoft PowerPoint - IPYYUIHNPGFU
 분산분석 분산분석 (ANOVA: ANALYSIS OF VARIANCE) 두개이상의모집단의차이를검정 예 : 회사에서세종류의기계를설치하여동일한제품을생산하는경우, 각기계의생산량을조사하여평균생산량을비교 독립변수 : 다른변수에의해영향을주는변수 종속변수 : 다른변수에의해영향을받는변수 요인 (Factor): 독립변수 예에서의요인 : 기계의종류 (I, II, III) 요인수준
분산분석 분산분석 (ANOVA: ANALYSIS OF VARIANCE) 두개이상의모집단의차이를검정 예 : 회사에서세종류의기계를설치하여동일한제품을생산하는경우, 각기계의생산량을조사하여평균생산량을비교 독립변수 : 다른변수에의해영향을주는변수 종속변수 : 다른변수에의해영향을받는변수 요인 (Factor): 독립변수 예에서의요인 : 기계의종류 (I, II, III) 요인수준
ANOVA 란? ANalysis Of VAriance Ø 3개이상의모집단의평균의차이를검정하는방법 Ø 3개의모집단일경우 H0 : μ1 = μ2 = μ3 H0기각 : μ1 μ2 = μ3 or μ1 = μ2 μ3 or μ1 μ2 μ3 àpost hoc test 수행
 Ch4 one-way ANOVA ANOVA 란? ANalysis Of VAriance Ø 3개이상의모집단의평균의차이를검정하는방법 Ø 3개의모집단일경우 H0 : μ1 = μ2 = μ3 H0기각 : μ1 μ2 = μ3 or μ1 = μ2 μ3 or μ1 μ2 μ3 àpost hoc test 수행 One-way ANOVA 란? Group Sex pvas NSAID
Ch4 one-way ANOVA ANOVA 란? ANalysis Of VAriance Ø 3개이상의모집단의평균의차이를검정하는방법 Ø 3개의모집단일경우 H0 : μ1 = μ2 = μ3 H0기각 : μ1 μ2 = μ3 or μ1 = μ2 μ3 or μ1 μ2 μ3 àpost hoc test 수행 One-way ANOVA 란? Group Sex pvas NSAID
1 경영학을 위한 수학 Final Exam 2015/12/12(토) 13:00-15:00 풀이과정을 모두 명시하시오. 정리를 사용할 경우 명시하시오. 1. (각 6점) 다음 적분을 구하시오 Z 1 4 Z 1 (x + 1) dx (a) 1 (x 1)4 dx 1 Solut
 13:00-15:00 풀이과정을 모두 명시하시오. 정리를 사용할 경우 명시하시오. 1. (각 6점) 다음 적분을 구하시오 Z 1 4 Z 1 (x + 1) dx (a) 1 (x 1)4 dx 1 Solut") 경영학을 위한 수학 Fial Eam 5//(토) :-5: 풀이과정을 모두 명시하시오. 정리를 사용할 경우 명시하시오.. (각 6점) 다음 적분을 구하시오 4 ( ) (a) ( )4 8 8 (b) d이 성립한다. d C C log log (c) 이다. 양변에 적분을 취하면 log C (d) 라 하자. 그러면 d 4이다. 9 9 4 / si (e) cos si
경영학을 위한 수학 Fial Eam 5//(토) :-5: 풀이과정을 모두 명시하시오. 정리를 사용할 경우 명시하시오.. (각 6점) 다음 적분을 구하시오 4 ( ) (a) ( )4 8 8 (b) d이 성립한다. d C C log log (c) 이다. 양변에 적분을 취하면 log C (d) 라 하자. 그러면 d 4이다. 9 9 4 / si (e) cos si
저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할
 저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할수없습니다. 변경금지. 귀하는이저작물을개작, 변형또는가공할수없습니다. 귀하는, 이저작물의재이용이나배포의경우,
저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할수없습니다. 변경금지. 귀하는이저작물을개작, 변형또는가공할수없습니다. 귀하는, 이저작물의재이용이나배포의경우,
Microsoft Word - Ch1_Introduction_EDA.docx
 고전적데이터분석은연구목적이설정되면그에맞는 1) 통계적가설 (statistical hypothesis), 모형 (model) 을설정하고 2) 데이터수집하여 3) 가설혹은모형의유의성 (significance) 을검정하였다. 이를 Confirmatory ( 확증적 ) Data Analysis 라한다. 다음은 (confirmatory) 데이터분석의예로한남대학생들의용돈이대학평균과같은가를알아보는연구과정을요약한것이다.
고전적데이터분석은연구목적이설정되면그에맞는 1) 통계적가설 (statistical hypothesis), 모형 (model) 을설정하고 2) 데이터수집하여 3) 가설혹은모형의유의성 (significance) 을검정하였다. 이를 Confirmatory ( 확증적 ) Data Analysis 라한다. 다음은 (confirmatory) 데이터분석의예로한남대학생들의용돈이대학평균과같은가를알아보는연구과정을요약한것이다.
OCW_C언어 기초
 초보프로그래머를위한 C 언어기초 4 장 : 연산자 2012 년 이은주 학습목표 수식의개념과연산자및피연산자에대한학습 C 의알아보기 연산자의우선순위와결합방향에대하여알아보기 2 목차 연산자의기본개념 수식 연산자와피연산자 산술연산자 / 증감연산자 관계연산자 / 논리연산자 비트연산자 / 대입연산자연산자의우선순위와결합방향 조건연산자 / 형변환연산자 연산자의우선순위 연산자의결합방향
초보프로그래머를위한 C 언어기초 4 장 : 연산자 2012 년 이은주 학습목표 수식의개념과연산자및피연산자에대한학습 C 의알아보기 연산자의우선순위와결합방향에대하여알아보기 2 목차 연산자의기본개념 수식 연산자와피연산자 산술연산자 / 증감연산자 관계연산자 / 논리연산자 비트연산자 / 대입연산자연산자의우선순위와결합방향 조건연산자 / 형변환연산자 연산자의우선순위 연산자의결합방향
... —... ..—
 통계학 통계적추론 한국보건사회연구원 2017 년 5 월 29 일 ( 월요일 ) 강의슬라이드 7-1 1/ 72 목차 1 서론 2 신뢰구간을이용한통계적추론 3 통계적유의성검정 4 유의성검정과관련해서유의해야할점 2/ 72 지난시간복습 왜 x 가 µ 와완벽하게일치하지않고또어떤표본을추출했냐에따라 x 값이달라지는데이 x 를이용해서모집단 µ 를추정할까? 두가지사실때문 :
통계학 통계적추론 한국보건사회연구원 2017 년 5 월 29 일 ( 월요일 ) 강의슬라이드 7-1 1/ 72 목차 1 서론 2 신뢰구간을이용한통계적추론 3 통계적유의성검정 4 유의성검정과관련해서유의해야할점 2/ 72 지난시간복습 왜 x 가 µ 와완벽하게일치하지않고또어떤표본을추출했냐에따라 x 값이달라지는데이 x 를이용해서모집단 µ 를추정할까? 두가지사실때문 :
Microsoft PowerPoint - 3ÀÏ°_º¯¼ö¿Í »ó¼ö.ppt
 변수와상수 1 변수란무엇인가? 변수 : 정보 (data) 를저장하는컴퓨터내의특정위치 ( 임시저장공간 ) 메모리, register 메모리주소 101 번지 102 번지 변수의크기에따라 주로 byte 단위 메모리 2 기본적인변수형및변수의크기 변수의크기 해당컴퓨터에서는항상일정 컴퓨터마다다를수있음 short
변수와상수 1 변수란무엇인가? 변수 : 정보 (data) 를저장하는컴퓨터내의특정위치 ( 임시저장공간 ) 메모리, register 메모리주소 101 번지 102 번지 변수의크기에따라 주로 byte 단위 메모리 2 기본적인변수형및변수의크기 변수의크기 해당컴퓨터에서는항상일정 컴퓨터마다다를수있음 short
- 1 -
 - 1 - External Shocks and the Heterogeneous Autoregressive Model of Realized Volatility Abstract: We examine the information effect of external shocks on the realized volatility based on the HAR-RV (heterogeneous
- 1 - External Shocks and the Heterogeneous Autoregressive Model of Realized Volatility Abstract: We examine the information effect of external shocks on the realized volatility based on the HAR-RV (heterogeneous
Microsoft PowerPoint - chap04-연산자.pptx
 int num; printf( Please enter an integer: "); scanf("%d", &num); if ( num < 0 ) printf("is negative.\n"); printf("num = %d\n", num); } 1 학습목표 수식의 개념과 연산자, 피연산자에 대해서 알아본다. C의 를 알아본다. 연산자의 우선 순위와 결합 방향에
int num; printf( Please enter an integer: "); scanf("%d", &num); if ( num < 0 ) printf("is negative.\n"); printf("num = %d\n", num); } 1 학습목표 수식의 개념과 연산자, 피연산자에 대해서 알아본다. C의 를 알아본다. 연산자의 우선 순위와 결합 방향에
PowerPoint Presentation
 09 th Week Correlation Analysis 상관관계분석 Jongseok Lee Business Administration Hallym University 변수형태와통계적분석방법 H 0 : X ㅗ Y H 1 : X ~ Y X Categorical Y Categorical Chi-square Test X Categorical Y Numerical
09 th Week Correlation Analysis 상관관계분석 Jongseok Lee Business Administration Hallym University 변수형태와통계적분석방법 H 0 : X ㅗ Y H 1 : X ~ Y X Categorical Y Categorical Chi-square Test X Categorical Y Numerical
저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할
 저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할수없습니다. 변경금지. 귀하는이저작물을개작, 변형또는가공할수없습니다. 귀하는, 이저작물의재이용이나배포의경우,
저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할수없습니다. 변경금지. 귀하는이저작물을개작, 변형또는가공할수없습니다. 귀하는, 이저작물의재이용이나배포의경우,
이 장에서 사용되는 MATLAB 명령어들은 비교적 복잡하므로 MATLAB 창에서 명령어를 직접 입력하지 않고 확장자가 m 인 text 파일을 작성하여 실행을 한다
 이장에서사용되는 MATLAB 명령어들은비교적복잡하므로 MATLAB 창에서명령어를직접입력하지않고확장자가 m 인 text 파일을작성하여실행을한다. 즉, test.m 과같은 text 파일을만들어서 MATLAB 프로그램을작성한후실행을한다. 이와같이하면길고복잡한 MATLAB 프로그램을작성하여실행할수있고, 오류가발생하거나수정이필요한경우손쉽게수정하여실행할수있는장점이있으며,
이장에서사용되는 MATLAB 명령어들은비교적복잡하므로 MATLAB 창에서명령어를직접입력하지않고확장자가 m 인 text 파일을작성하여실행을한다. 즉, test.m 과같은 text 파일을만들어서 MATLAB 프로그램을작성한후실행을한다. 이와같이하면길고복잡한 MATLAB 프로그램을작성하여실행할수있고, 오류가발생하거나수정이필요한경우손쉽게수정하여실행할수있는장점이있으며,
Microsoft PowerPoint - chap_2_rep.ppt [호환 모드]
![Microsoft PowerPoint - chap_2_rep.ppt [호환 모드]](/thumbs/102/157053588.jpg "Microsoft PowerPoint - chap_2_rep.ppt [호환 모드]") 제 강.1 통계적기초 확률변수 (Radom Variable). 확률변수 (r.v.): 관측되기전까지는그값이알려지지않은변수. 확률변수의값은확률적실험으로부터결과된다. 확률적실험은실제수행할수있는실험뿐아니라가상적실험도포함함 (ex. 주사위던지기, [0,1] 실선에점던지기 ) 확률변수는그변수의모든가능한값들의집합에대해정의된알려지거나알려지지않은어떤확률분포의존재가연계됨 반면에,
제 강.1 통계적기초 확률변수 (Radom Variable). 확률변수 (r.v.): 관측되기전까지는그값이알려지지않은변수. 확률변수의값은확률적실험으로부터결과된다. 확률적실험은실제수행할수있는실험뿐아니라가상적실험도포함함 (ex. 주사위던지기, [0,1] 실선에점던지기 ) 확률변수는그변수의모든가능한값들의집합에대해정의된알려지거나알려지지않은어떤확률분포의존재가연계됨 반면에,
... —....—
 통계학 추출분포 한국보건사회연구원 2017 년 5 월 22 일 ( 월요일 ) 강의슬라이드 6 1/ 36 목차 1 들어가며 2 표본평균의추출분포 3 추출분포결론 2/ 36 추출분포와통계적추론 통계량의추출분포모집단분포 통계적추론이어떤표본을토대로모집단에대한결론을내리게끔해줌 어떤표본을토대로모집단에대한결론을내릴때, 이표본이모집단을잘대표해야한다는것은이제두말하면잔소리 =
통계학 추출분포 한국보건사회연구원 2017 년 5 월 22 일 ( 월요일 ) 강의슬라이드 6 1/ 36 목차 1 들어가며 2 표본평균의추출분포 3 추출분포결론 2/ 36 추출분포와통계적추론 통계량의추출분포모집단분포 통계적추론이어떤표본을토대로모집단에대한결론을내리게끔해줌 어떤표본을토대로모집단에대한결론을내릴때, 이표본이모집단을잘대표해야한다는것은이제두말하면잔소리 =
01
 2019 학년도대학수학능력시험 9 월모의평가문제및정답 2019 학년도대학수학능력시험 9 월모의평가문제지 1 제 2 교시 5 지선다형 1. 두벡터, 모든성분의합은? [2 점 ] 에대하여벡터 의 3. 좌표공간의두점 A, B 에대하여선분 AB 를 로외분하는점의좌표가 일때, 의값은? [2점] 1 2 3 4 5 1 2 3 4 5 2. lim 의값은? [2점] 4. 두사건,
2019 학년도대학수학능력시험 9 월모의평가문제및정답 2019 학년도대학수학능력시험 9 월모의평가문제지 1 제 2 교시 5 지선다형 1. 두벡터, 모든성분의합은? [2 점 ] 에대하여벡터 의 3. 좌표공간의두점 A, B 에대하여선분 AB 를 로외분하는점의좌표가 일때, 의값은? [2점] 1 2 3 4 5 1 2 3 4 5 2. lim 의값은? [2점] 4. 두사건,
 1 1 Department of Statistics University of Seoul August 28, 2017 확률분포 누적분포함수 확률공간이정의되었다고가정하자. 즉, 어떤사건 A 에대해서 P(A) 를항상생각할수있다고가정하자. 어떤확률변수 X 주어졌을때 Pr(X x) = P(X (, x]) 로정의하면 Pr(X x) 의값을모든 x 에대해생각할수있다. F
1 1 Department of Statistics University of Seoul August 28, 2017 확률분포 누적분포함수 확률공간이정의되었다고가정하자. 즉, 어떤사건 A 에대해서 P(A) 를항상생각할수있다고가정하자. 어떤확률변수 X 주어졌을때 Pr(X x) = P(X (, x]) 로정의하면 Pr(X x) 의값을모든 x 에대해생각할수있다. F
2156년올림픽 100미터육상경기에서여성의우승기록이남성의기록보다빠른첫해로남을수있음 2156년올림픽에서 100m 우승기록은남성의경우 8.098초, 여성은 8.079초로예측 통계적오차 ( 예측구간 ) 를고려하면빠르면 2064년, 늦어도 2788년에는그렇게될것이라고주장 유사
 를고려하면빠르면 2064년, 늦어도 2788년에는그렇게될것이라고주장 유사") 회귀분석 올림픽 100m 우승기록 2004년 9월과학저널 Nature에발표된 Oxford 대학교의임상병리학자인 Andrew Tatem과그의연구진의논문 1900~2004년까지의남성과여성의육상 100m 우승기록을분석하고앞으로최고기록이어떻게변할것인지를예측 2008년베이징올림픽에서남자의우승기록은 9.73±0.144(9.586, 9.874), 여자는 10.57±0.232(10.338,
회귀분석 올림픽 100m 우승기록 2004년 9월과학저널 Nature에발표된 Oxford 대학교의임상병리학자인 Andrew Tatem과그의연구진의논문 1900~2004년까지의남성과여성의육상 100m 우승기록을분석하고앞으로최고기록이어떻게변할것인지를예측 2008년베이징올림픽에서남자의우승기록은 9.73±0.144(9.586, 9.874), 여자는 10.57±0.232(10.338,
PowerPoint 프레젠테이션
 응용식물통계학 Statistics of Applied Plants Science 친환경식물학부유기농생태학전공황선구 14 장회귀분석 1. 회귀직선의추정 2. 회귀직선의검정및추론 3. 모집단절편과회귀계수의구간추정 4. 곡선회귀 15 장공분산분석 1. 공분산분석의통계적모형 2. 공분산분석에의한처리효과검정 3. 공분산분석과정 - 실습 - 회귀분석 두확률변수간에관계가있는지검정
응용식물통계학 Statistics of Applied Plants Science 친환경식물학부유기농생태학전공황선구 14 장회귀분석 1. 회귀직선의추정 2. 회귀직선의검정및추론 3. 모집단절편과회귀계수의구간추정 4. 곡선회귀 15 장공분산분석 1. 공분산분석의통계적모형 2. 공분산분석에의한처리효과검정 3. 공분산분석과정 - 실습 - 회귀분석 두확률변수간에관계가있는지검정
비트와바이트 비트와바이트 비트 (Bit) : 2진수값하나 (0 또는 1) 를저장할수있는최소메모리공간 1비트 2비트 3비트... n비트 2^1 = 2개 2^2 = 4개 2^3 = 8개... 2^n 개 1 바이트는 8 비트 2 2
 : 2진수값하나 (0 또는 1) 를저장할수있는최소메모리공간 1비트 2비트 3비트... n비트 2^1 = 2개 2^2 = 4개 2^3 = 8개... 2^n 개 1 바이트는 8 비트 2 2") 비트연산자 1 1 비트와바이트 비트와바이트 비트 (Bit) : 2진수값하나 (0 또는 1) 를저장할수있는최소메모리공간 1비트 2비트 3비트... n비트 2^1 = 2개 2^2 = 4개 2^3 = 8개... 2^n 개 1 바이트는 8 비트 2 2 진수법! 2, 10, 16, 8! 2 : 0~1 ( )! 10 : 0~9 ( )! 16 : 0~9, 9 a, b,
비트연산자 1 1 비트와바이트 비트와바이트 비트 (Bit) : 2진수값하나 (0 또는 1) 를저장할수있는최소메모리공간 1비트 2비트 3비트... n비트 2^1 = 2개 2^2 = 4개 2^3 = 8개... 2^n 개 1 바이트는 8 비트 2 2 진수법! 2, 10, 16, 8! 2 : 0~1 ( )! 10 : 0~9 ( )! 16 : 0~9, 9 a, b,
<B0A3C3DFB0E828C0DBBEF7292E687770>
 초청연자특강 대구가톨릭의대의학통계학교실 Meta analysis ( 메타분석 ) 예1) The effect of interferon on development of hepatocellular carcinoma in patients with chronic hepatitis B virus infection?? -:> 1998.1 ~2007.12.31 / RCT(2),
초청연자특강 대구가톨릭의대의학통계학교실 Meta analysis ( 메타분석 ) 예1) The effect of interferon on development of hepatocellular carcinoma in patients with chronic hepatitis B virus infection?? -:> 1998.1 ~2007.12.31 / RCT(2),
(3) 추론에서계산이모수적방법보다훨씬단순. (4) 사용자가이의논리를스스로발견하게하며이해하기쉬움. (5) 표본이정규분포를따를때에도검정력에큰손실이없으며, 정규분포와상이한경우에이의검정력은정규분포에의한방법보다크다. 3. 부호검정 (Sg test) 모집단의중앙값에대한검정으로관찰
 추론에서계산이모수적방법보다훨씬단순. (4) 사용자가이의논리를스스로발견하게하며이해하기쉬움. (5) 표본이정규분포를따를때에도검정력에큰손실이없으며, 정규분포와상이한경우에이의검정력은정규분포에의한방법보다크다. 3. 부호검정 (Sg test) 모집단의중앙값에대한검정으로관찰") 제 3 장. 비모수적방법 (Dstrbuto-free Method) 모수적방법 (parametrc method): 관측값이어느특정한확률분포, 예를들면정규분포, 이항분 포등을따른다고전제한후그분포의모수 (parameter) 에대한검정을실시하는방법이다. 비모수적방법 (oparametrc method): 관측값이어느특정한확률분포를따른다고전제할수 없거나또는모집단에대한아무런정보가없는경우에실시하는검정방법으로모수에대한언급이없으며분포무관방법이라고도한다.
제 3 장. 비모수적방법 (Dstrbuto-free Method) 모수적방법 (parametrc method): 관측값이어느특정한확률분포, 예를들면정규분포, 이항분 포등을따른다고전제한후그분포의모수 (parameter) 에대한검정을실시하는방법이다. 비모수적방법 (oparametrc method): 관측값이어느특정한확률분포를따른다고전제할수 없거나또는모집단에대한아무런정보가없는경우에실시하는검정방법으로모수에대한언급이없으며분포무관방법이라고도한다.
수도권과비수도권근로자의임금격차에영향을미치는 집적경제의미시적메커니즘에관한실증연구 I. 서론
 수도권과비수도권근로자의임금격차에영향을미치는 집적경제의미시적메커니즘에관한실증연구 I. 서론 Ⅱ. 선행연구고찰 집적경제메커니즘의유형공유메커니즘매칭메커니즘학습메커니즘 내용기업이군집을형성하여분리불가능한생산요소, 중간재공급자, 노동력풀등을공유하는과정에서집적경제발생한지역에기업과노동력이군집을이뤄기업과노동력사이의매칭이촉진됨에따라집적경제발생군집이형성되면사람들사이의교류가촉진되어지식이확산되고새로운지식이창출됨에따라집적경제발생
수도권과비수도권근로자의임금격차에영향을미치는 집적경제의미시적메커니즘에관한실증연구 I. 서론 Ⅱ. 선행연구고찰 집적경제메커니즘의유형공유메커니즘매칭메커니즘학습메커니즘 내용기업이군집을형성하여분리불가능한생산요소, 중간재공급자, 노동력풀등을공유하는과정에서집적경제발생한지역에기업과노동력이군집을이뤄기업과노동력사이의매칭이촉진됨에따라집적경제발생군집이형성되면사람들사이의교류가촉진되어지식이확산되고새로운지식이창출됨에따라집적경제발생
Microsoft Word - Software_Ch2_FUNCTION.docx
 Chapter 2 SAS 함수 SAS 함수는소프트웨어에내장되어작업자가손쉽게연산을할수있게데이터값은로그값을계산하려면 LOG() 함수를사용하면된다. 한다. 예를들어 맛보기 EXP() 함수 : () 안의관측치의지수값을구하는함수 RANNOR(seed) 함수 : 평균이 0 이고표준편차가 1인정규분포함수를따르는관측치를생성하는함수, SEED ( 시드 ) 는값을생성할때시작하는위치를나타내는는값으로
Chapter 2 SAS 함수 SAS 함수는소프트웨어에내장되어작업자가손쉽게연산을할수있게데이터값은로그값을계산하려면 LOG() 함수를사용하면된다. 한다. 예를들어 맛보기 EXP() 함수 : () 안의관측치의지수값을구하는함수 RANNOR(seed) 함수 : 평균이 0 이고표준편차가 1인정규분포함수를따르는관측치를생성하는함수, SEED ( 시드 ) 는값을생성할때시작하는위치를나타내는는값으로
<B4EBC7D0BCF6C7D02DBBEFB0A2C7D4BCF62E687770>
 삼각함수. 삼각함수의덧셈정리 삼각함수의덧셈정리 삼각함수 sin (α + β ), cos (α + β ), tan (α + β ) 등을 α 또는 β 의삼각함수로나 타낼수있다. 각 α 와각 β 에대하여 α >0, β >0이고 0 α - β < β 를만족한다고가정하 자. 다른경우에도같은방법으로증명할수있다. 각 α 와각 β 에대하여 θ = α - β 라고놓자. 위의그림에서원점에서거리가
삼각함수. 삼각함수의덧셈정리 삼각함수의덧셈정리 삼각함수 sin (α + β ), cos (α + β ), tan (α + β ) 등을 α 또는 β 의삼각함수로나 타낼수있다. 각 α 와각 β 에대하여 α >0, β >0이고 0 α - β < β 를만족한다고가정하 자. 다른경우에도같은방법으로증명할수있다. 각 α 와각 β 에대하여 θ = α - β 라고놓자. 위의그림에서원점에서거리가
마지막 변경일 2018년 5월 7일 ** 이항분포와 정규분포의 관계 ** Geogebra와 수학의 시각화 책의 3.2소절 내용임. 가장 최근 파일은 링크를 누르면 받아 보실 수 있습니다.
 마지막 변경일 2018년 5월 7일 ** 이항분포와 정규분포의 관계 ** Geogebra와 수학의 시각화 책의 3.2소절 내용임. http://min7014.iptime.org/math/2017063002.htm 가장 최근 파일은 링크를 누르면 받아 보실 수 있습니다. https://goo.gl/edxsm7 http://min7014.iptime.org/math/2018010602.pdf
마지막 변경일 2018년 5월 7일 ** 이항분포와 정규분포의 관계 ** Geogebra와 수학의 시각화 책의 3.2소절 내용임. http://min7014.iptime.org/math/2017063002.htm 가장 최근 파일은 링크를 누르면 받아 보실 수 있습니다. https://goo.gl/edxsm7 http://min7014.iptime.org/math/2018010602.pdf
LaTeX. [width=1em]Rlogo.jpg Sublime Text. ..
![LaTeX. [width=1em]Rlogo.jpg Sublime Text. ..](/thumbs/80/81096693.jpg "LaTeX. [width=1em]Rlogo.jpg Sublime Text. ..") L A TEX 과 을결합한문서작성 Sublime Text 의활용 2015. 01. 31. 차례 1 L A TEX 과활용에유용한 Sublime text 2 LaTeXing 과 Extend 3 LaTeXing 의 Snippet 을활용한 L A TEX 편집 4 L A TEX 과을결합한문서작성 5 Reproducible Research 의응용 활용에 유용한 Sublime
L A TEX 과 을결합한문서작성 Sublime Text 의활용 2015. 01. 31. 차례 1 L A TEX 과활용에유용한 Sublime text 2 LaTeXing 과 Extend 3 LaTeXing 의 Snippet 을활용한 L A TEX 편집 4 L A TEX 과을결합한문서작성 5 Reproducible Research 의응용 활용에 유용한 Sublime
Microsoft Word - Chapter9.doc
 CHAPTER 9 분산분석 9.1. 분산분석개념 분산분석 (ANOVA: Analysis of Variance) 이란종속변수 (dependent variable: 반응변수 : response variable) 의분산 (variation: 변동 통계에서는이를변수가가진정보라한다 ) 을설명하는독립변수 (independent: 설명변수 : explanatory) 의유의성
CHAPTER 9 분산분석 9.1. 분산분석개념 분산분석 (ANOVA: Analysis of Variance) 이란종속변수 (dependent variable: 반응변수 : response variable) 의분산 (variation: 변동 통계에서는이를변수가가진정보라한다 ) 을설명하는독립변수 (independent: 설명변수 : explanatory) 의유의성
용역보고서
 여러고장모드를갖는자료분석방법 2009. 1. ( 주 ) 한국신뢰성기술서비스 목차 여러고장모드를갖는자료분석방법...3 1. 개요...3 2. 분석방법및예제...4 2.1 CFM(Competing Failure Mode) 분석...4 2.2 Mixed Weibull 분석...4 2.3 Mixed Weibull 예제...5 3. 요약정리...9 ii http://www.korts.co.kr
여러고장모드를갖는자료분석방법 2009. 1. ( 주 ) 한국신뢰성기술서비스 목차 여러고장모드를갖는자료분석방법...3 1. 개요...3 2. 분석방법및예제...4 2.1 CFM(Competing Failure Mode) 분석...4 2.2 Mixed Weibull 분석...4 2.3 Mixed Weibull 예제...5 3. 요약정리...9 ii http://www.korts.co.kr
Microsoft PowerPoint - MDA DA pptx
 판별분석개념 Indvdual Drected Technque 측정변수 ( 항목 ) 에의한개체분류 분류되어있는집단간의차이를의미있게설명해줄수있는독립변수들을찾아내어 변수의선형결합으로판별식 (Dscrmnant functon) 을만들어낸다. 이판별식을이용하여분류하고자하는개체의집단을판별 데이터유형 집단변수 : 범주형혹은이진형 판별변수 : 측정형 ( 등간척도포함 ) 사례
판별분석개념 Indvdual Drected Technque 측정변수 ( 항목 ) 에의한개체분류 분류되어있는집단간의차이를의미있게설명해줄수있는독립변수들을찾아내어 변수의선형결합으로판별식 (Dscrmnant functon) 을만들어낸다. 이판별식을이용하여분류하고자하는개체의집단을판별 데이터유형 집단변수 : 범주형혹은이진형 판별변수 : 측정형 ( 등간척도포함 ) 사례
Microsoft PowerPoint - chap06-2pointer.ppt
 2010-1 학기프로그래밍입문 (1) chapter 06-2 참고자료 포인터 박종혁 Tel: 970-6702 Email: jhpark1@snut.ac.kr 한빛미디어 출처 : 뇌를자극하는 C프로그래밍, 한빛미디어 -1- 포인터의정의와사용 변수를선언하는것은메모리에기억공간을할당하는것이며할당된이후에는변수명으로그기억공간을사용한다. 할당된기억공간을사용하는방법에는변수명외에메모리의실제주소값을사용하는것이다.
2010-1 학기프로그래밍입문 (1) chapter 06-2 참고자료 포인터 박종혁 Tel: 970-6702 Email: jhpark1@snut.ac.kr 한빛미디어 출처 : 뇌를자극하는 C프로그래밍, 한빛미디어 -1- 포인터의정의와사용 변수를선언하는것은메모리에기억공간을할당하는것이며할당된이후에는변수명으로그기억공간을사용한다. 할당된기억공간을사용하는방법에는변수명외에메모리의실제주소값을사용하는것이다.
 연구보고서 2009-05 일반화선형모형 (GLM) 을이용한 자동차보험요율상대도산출방법연구 Ⅰ. 요율상대도산출시일반화선형모형활용방법 1. 일반화선형모형 2 연구보고서 2009-05 2. 일반화선형모형의자동차보험요율산출에적용방법 요약 3 4 연구보고서 2009-05 Ⅱ. 일반화선형모형을이용한실증분석 1. 모형적용기준 < > = 요약 5 2. 통계자료및통계모형
연구보고서 2009-05 일반화선형모형 (GLM) 을이용한 자동차보험요율상대도산출방법연구 Ⅰ. 요율상대도산출시일반화선형모형활용방법 1. 일반화선형모형 2 연구보고서 2009-05 2. 일반화선형모형의자동차보험요율산출에적용방법 요약 3 4 연구보고서 2009-05 Ⅱ. 일반화선형모형을이용한실증분석 1. 모형적용기준 < > = 요약 5 2. 통계자료및통계모형
집합 집합 오른쪽 l 3. (1) 집합 X 의각원소에대응하는집합 Y 의원소가단하나만인대응을 라할때, 이대응 를 X 에서 Y 로의라고하고이것을기호로 X Y 와같이나타낸다. (2) 정의역과공역정의역 : X Y 에서집합 X, 공역 : X Y 에서집합 Y (3) 의개수 X Y
 집합 X 의각원소에대응하는집합 Y 의원소가단하나만인대응을 라할때, 이대응 를 X 에서 Y 로의라고하고이것을기호로 X Y 와같이나타낸다. (2) 정의역과공역정의역 : X Y 에서집합 X, 공역 : X Y 에서집합 Y (3) 의개수 X Y") 어떤 다음 X 대응 1. 대응 (1) 어떤주어진관계에의하여집합 X 의원소에집합 Y 의원소를짝지어주는것을집합 X 에서집합 Y 로의대응이라고한다. l (2) 집합 X 의원소 에집합 Y 의원소 가짝지어지면 에 가대응한다고하며이것을기호로 와같이나타낸다. 2. 일대일대응 (1) 집합 A 의모든원소와집합 B 의모든원소가하나도빠짐없이꼭한개씩서로대응되는것을집합 A 에서집합
어떤 다음 X 대응 1. 대응 (1) 어떤주어진관계에의하여집합 X 의원소에집합 Y 의원소를짝지어주는것을집합 X 에서집합 Y 로의대응이라고한다. l (2) 집합 X 의원소 에집합 Y 의원소 가짝지어지면 에 가대응한다고하며이것을기호로 와같이나타낸다. 2. 일대일대응 (1) 집합 A 의모든원소와집합 B 의모든원소가하나도빠짐없이꼭한개씩서로대응되는것을집합 A 에서집합
nonpara1.PDF
 Chapter 1 Introduction 1 Introduction (parameter) (assumption) (rank), (median) p-value distribution free, assumption free, statistical inference based on ranks 11 Nonparametric? John Arbuthnot (1710)
Chapter 1 Introduction 1 Introduction (parameter) (assumption) (rank), (median) p-value distribution free, assumption free, statistical inference based on ranks 11 Nonparametric? John Arbuthnot (1710)
분산분석.pages
 예제데이터 R. A. Fisher (1919 영국통계학자, 생물학자, 수학자 - 분산분석창시자 iris 분꽃데이터 - 3 개종, 4 개변수관측데이터 - sepal 꽃받침 ( 길이, 넓이 - petal 꽃잎 ( 길이, 넓이 분산개념정의 변수의데이터흩어짐의척도이다. (x s i x = n 1 활용 변동계수 Coefficient of Variation CV - CV
예제데이터 R. A. Fisher (1919 영국통계학자, 생물학자, 수학자 - 분산분석창시자 iris 분꽃데이터 - 3 개종, 4 개변수관측데이터 - sepal 꽃받침 ( 길이, 넓이 - petal 꽃잎 ( 길이, 넓이 분산개념정의 변수의데이터흩어짐의척도이다. (x s i x = n 1 활용 변동계수 Coefficient of Variation CV - CV
슬라이드 제목 없음
 계량치 Gage R&R 1 Gage R&R 의변동 반복성 (Equipment Variation) : EV- 계측장비에의한변동 - 동일측정자가동일조건에서반복하여발생된측정값의범위로부터계산되므로 Gage의변동을평가하게됨. 재현성 (Operator / Appraiser Variation) : AV- 평가자에의한변동 - 서로다른측정자가동일조건에서측정한값의차이로부터 계산되므로측정자에의한변동을평가함.
계량치 Gage R&R 1 Gage R&R 의변동 반복성 (Equipment Variation) : EV- 계측장비에의한변동 - 동일측정자가동일조건에서반복하여발생된측정값의범위로부터계산되므로 Gage의변동을평가하게됨. 재현성 (Operator / Appraiser Variation) : AV- 평가자에의한변동 - 서로다른측정자가동일조건에서측정한값의차이로부터 계산되므로측정자에의한변동을평가함.
슬라이드 1
 Principles of Economerics (3e) Ch. 4 예측, 적합도, 모형화 013 년 1 학기 윤성민 4.1 OLS 예측 (1) 점예측 x0 y0 - 설명변수일때, 종속변수의값을예측하고자함 y ˆ = b + 0 1 b x 0 Ch. 4 예측, 적합도, 모형화 /60 4.1 OLS 예측 예측오차 (forecas error), f 예측오차의기대값
Principles of Economerics (3e) Ch. 4 예측, 적합도, 모형화 013 년 1 학기 윤성민 4.1 OLS 예측 (1) 점예측 x0 y0 - 설명변수일때, 종속변수의값을예측하고자함 y ˆ = b + 0 1 b x 0 Ch. 4 예측, 적합도, 모형화 /60 4.1 OLS 예측 예측오차 (forecas error), f 예측오차의기대값
FGB-P 학번수학과권혁준 2008 년 5 월 19 일 Lemma 1 p 를 C([0, 1]) 에속하는음수가되지않는함수라하자. 이때 y C 2 (0, 1) C([0, 1]) 가미분방정식 y (t) + p(t)y(t) = 0, t (0, 1), y(0)
![FGB-P 학번수학과권혁준 2008 년 5 월 19 일 Lemma 1 p 를 C([0, 1]) 에속하는음수가되지않는함수라하자. 이때 y C 2 (0, 1) C([0, 1]) 가미분방정식 y (t) + p(t)y(t) = 0, t (0, 1), y(0)](/thumbs/94/121635808.jpg "FGB-P 학번수학과권혁준 2008 년 5 월 19 일 Lemma 1 p 를 C([0, 1]) 에속하는음수가되지않는함수라하자. 이때 y C 2 (0, 1) C([0, 1]) 가미분방정식 y (t) + p(t)y(t) = 0, t (0, 1), y(0)") FGB-P8-3 8 학번수학과권혁준 8 년 5 월 9 일 Lemma p 를 C[, ] 에속하는음수가되지않는함수라하자. 이때 y C, C[, ] 가미분방정식 y t + ptyt, t,, y y 을만족하는해라고하면, y 는, 에서연속적인이계도함수를가지게확 장될수있다. Proof y 은 y 의도함수이므로미적분학의기본정리에의하여, y 은 y 의어떤원시 함수와적분상수의합으로표시될수있다.
FGB-P8-3 8 학번수학과권혁준 8 년 5 월 9 일 Lemma p 를 C[, ] 에속하는음수가되지않는함수라하자. 이때 y C, C[, ] 가미분방정식 y t + ptyt, t,, y y 을만족하는해라고하면, y 는, 에서연속적인이계도함수를가지게확 장될수있다. Proof y 은 y 의도함수이므로미적분학의기본정리에의하여, y 은 y 의어떤원시 함수와적분상수의합으로표시될수있다.
저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할
 저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할수없습니다. 변경금지. 귀하는이저작물을개작, 변형또는가공할수없습니다. 귀하는, 이저작물의재이용이나배포의경우,
저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할수없습니다. 변경금지. 귀하는이저작물을개작, 변형또는가공할수없습니다. 귀하는, 이저작물의재이용이나배포의경우,
모수 θ의 추정량은 추출한 개의 표본값을 어떤 규칙에 의해 처리를 해서 모수의 값을 추정하는 방법입니다. 추정량에서 사용되는 규칙은 어떤 표본을 추출했냐에 따라 변하는 것이 아닌 고정된 규칙입니다. 예를 들어 우리의 관심 모수가 모집단의 평균이라고 하겠습니다. 즉 θ
 수리통계학(Mathematical Statistics)의 기초 I. 들어가며 지금부터 계량경제학이나 실험 및 준실험 연구설계 기법을 공부할 때 도움이 되는 수리통계 학의 기초에 대해 다룰 것입니다. 이 노트에서 다루게 될 내용은 어떤 추정량(estimator)이 지니고 있는 성질입니다. 한 가지 말씀 드릴 것은 이 노트에 나오는 대부분의 성질들은 지금까 지
수리통계학(Mathematical Statistics)의 기초 I. 들어가며 지금부터 계량경제학이나 실험 및 준실험 연구설계 기법을 공부할 때 도움이 되는 수리통계 학의 기초에 대해 다룰 것입니다. 이 노트에서 다루게 될 내용은 어떤 추정량(estimator)이 지니고 있는 성질입니다. 한 가지 말씀 드릴 것은 이 노트에 나오는 대부분의 성질들은 지금까 지
22 장정규성검정과정규화변환 22.1 시각적방법 Q-Q 플롯과정규확률그림 Q-Q 플롯( 분위수- 분위수플롯, Quantile-Quantile plot) 은하나의자료셋이특정분포( 정규분 포나와이블분포등) 를따르는지또는두개의자료셋이같은모집단분포로부터나왔는지를
 은하나의자료셋이특정분포( 정규분 포나와이블분포등) 를따르는지또는두개의자료셋이같은모집단분포로부터나왔는지를") 22 장정규성검정과정규화변환 22.1 시각적방법 22.1.1 Q-Q 플롯과정규확률그림 Q-Q 플롯( 분위수- 분위수플롯, Quantile-Quantile plot) 은하나의자료셋이특정분포( 정규분 포나와이블분포등) 를따르는지또는두개의자료셋이같은모집단분포로부터나왔는지를 판단하는시각적분석방법이다. Q-Q 플롯은자료의분위수와특정( 이론적) 분포의분위수를구하여산점도로나타내거나,
22 장정규성검정과정규화변환 22.1 시각적방법 22.1.1 Q-Q 플롯과정규확률그림 Q-Q 플롯( 분위수- 분위수플롯, Quantile-Quantile plot) 은하나의자료셋이특정분포( 정규분 포나와이블분포등) 를따르는지또는두개의자료셋이같은모집단분포로부터나왔는지를 판단하는시각적분석방법이다. Q-Q 플롯은자료의분위수와특정( 이론적) 분포의분위수를구하여산점도로나타내거나,
Gray level 변환 및 Arithmetic 연산을 사용한 영상 개선
 Point Operation Histogram Modification 김성영교수 금오공과대학교 컴퓨터공학과 학습내용 HISTOGRAM HISTOGRAM MODIFICATION DETERMINING THRESHOLD IN THRESHOLDING 2 HISTOGRAM A simple datum that gives the number of pixels that a
Point Operation Histogram Modification 김성영교수 금오공과대학교 컴퓨터공학과 학습내용 HISTOGRAM HISTOGRAM MODIFICATION DETERMINING THRESHOLD IN THRESHOLDING 2 HISTOGRAM A simple datum that gives the number of pixels that a
Microsoft PowerPoint - ANOVA pptx
 분산분석개념및기초 인과관계 casual relationship X=>Y Y 종속변수, 반응변수, 내생변수 X 설명변수, 독립변수, 요인 ( 처리효과 ), 내생변수 X 측정형 Y 범주형 로지스틱회귀분석 측정형 회귀분석 범주형교차분석분산분석 DOE Design of Experiment ( 실험설계 ) 관심대상에대한정보를얻기위한계획된테스트나관측 절대실험 absolute
분산분석개념및기초 인과관계 casual relationship X=>Y Y 종속변수, 반응변수, 내생변수 X 설명변수, 독립변수, 요인 ( 처리효과 ), 내생변수 X 측정형 Y 범주형 로지스틱회귀분석 측정형 회귀분석 범주형교차분석분산분석 DOE Design of Experiment ( 실험설계 ) 관심대상에대한정보를얻기위한계획된테스트나관측 절대실험 absolute
1 1 장. 함수와극한 1.1 함수를표현하는네가지방법 1.2 수학적모형 : 필수함수의목록 1.3 기존함수로부터새로운함수구하기 1.4 접선문제와속도문제 1.5 함수의극한 1.6 극한법칙을이용한극한계산 1.7 극한의엄밀한정의 1.8 연속
 1 1 장. 함수와극한 1.1 함수를표현하는네가지방법 1.2 수학적모형 : 필수함수의목록 1.3 기존함수로부터새로운함수구하기 1.4 접선문제와속도문제 1.5 함수의극한 1.6 극한법칙을이용한극한계산 1.7 극한의엄밀한정의 1.8 연속 2 1.1 함수를표현하는네가지방법 함수 f : D E 는집합 D 의각원소 x 에집합 E 에속하는단하나의원소 f(x) 를 대응시키는규칙이다.
1 1 장. 함수와극한 1.1 함수를표현하는네가지방법 1.2 수학적모형 : 필수함수의목록 1.3 기존함수로부터새로운함수구하기 1.4 접선문제와속도문제 1.5 함수의극한 1.6 극한법칙을이용한극한계산 1.7 극한의엄밀한정의 1.8 연속 2 1.1 함수를표현하는네가지방법 함수 f : D E 는집합 D 의각원소 x 에집합 E 에속하는단하나의원소 f(x) 를 대응시키는규칙이다.
제 1 절 two way ANOVA 제1절 1 two way ANOVA 두 요인(factor)의 각 요인의 평균비교와 교호작용(interaction)을 검정하는 것을 이 원배치 분산분석(two way ANalysis Of VAriance; two way ANOVA)이라
의 각 요인의 평균비교와 교호작용(interaction)을 검정하는 것을 이 원배치 분산분석(two way ANalysis Of VAriance; two way ANOVA)이라") 제 절 two way ANOVA 제절 two way ANOVA 두 요인(factor)의 각 요인의 평균비교와 교호작용(interaction)을 검정하는 것을 이 원배치 분산분석(two way ANalysis Of VAriance; two way ANOVA)이라고 한다. 교호작용은 두 변수의 곱에 대한 검정으로 유의확률이 의미있는 결과라면 두 변수는 서로 영향을
제 절 two way ANOVA 제절 two way ANOVA 두 요인(factor)의 각 요인의 평균비교와 교호작용(interaction)을 검정하는 것을 이 원배치 분산분석(two way ANalysis Of VAriance; two way ANOVA)이라고 한다. 교호작용은 두 변수의 곱에 대한 검정으로 유의확률이 의미있는 결과라면 두 변수는 서로 영향을
<B1B3C0B0B0FAC1A45FC3E2B7C22E687770>
 확률및통계 확률및통계 1 성격 본과정은과학기술특성화대학의 확률및통계 ( 또는 기초통계학 ) 과목에해당하는내용을다룬다. 이과정을통하여학생들은대학과정이수에필요한정성적 / 정량적자료분석을위한통계적사고의기초를습득하게된다. 또한수학, 통계학, 또는계량적분석을많이요구하는학문을전공하고자하는학생들에게는과학적분석방법의수리적토대를갖추도록하여상위교과목을수강할수있는능력을기르도록한다.
확률및통계 확률및통계 1 성격 본과정은과학기술특성화대학의 확률및통계 ( 또는 기초통계학 ) 과목에해당하는내용을다룬다. 이과정을통하여학생들은대학과정이수에필요한정성적 / 정량적자료분석을위한통계적사고의기초를습득하게된다. 또한수학, 통계학, 또는계량적분석을많이요구하는학문을전공하고자하는학생들에게는과학적분석방법의수리적토대를갖추도록하여상위교과목을수강할수있는능력을기르도록한다.
7) 다음의 다음 9) 남학생과 9. zb 여학생 각각 명이 갖고 있는 여름 티 셔츠의 개수를 조사하여 꺾은선그래프로 나타낸 것 이다. 이 두 그래프의 설명으로 옳지 않은 것은? ㄱ. ㄴ. 회째의 수학 점수는 점이다. 수학 점수의 분산은 이다. ㄷ. 영어점수가 수학 점
 다음의 다음 9) 남학생과 9. zb 여학생 각각 명이 갖고 있는 여름 티 셔츠의 개수를 조사하여 꺾은선그래프로 나타낸 것 이다. 이 두 그래프의 설명으로 옳지 않은 것은? ㄱ. ㄴ. 회째의 수학 점수는 점이다. 수학 점수의 분산은 이다. ㄷ. 영어점수가 수학 점") 1) 은경이네 2) 어느 3) 다음은 자연수 그림은 6) 학생 학년 고사종류 과목 과목코드번호 성명 3 2012 2학기 중간고사 대비 수학 201 대청중 콘텐츠산업 진흥법 시행령 제33조에 의한 표시 1) 제작연월일 : 2012-08-27 2) 제작자 : 교육지대 3) 이 콘텐츠는 콘텐츠산업 진흥법 에 따라 최초 제작일부터 년간 보호됩니다. 콘텐츠산업 진흥법
1) 은경이네 2) 어느 3) 다음은 자연수 그림은 6) 학생 학년 고사종류 과목 과목코드번호 성명 3 2012 2학기 중간고사 대비 수학 201 대청중 콘텐츠산업 진흥법 시행령 제33조에 의한 표시 1) 제작연월일 : 2012-08-27 2) 제작자 : 교육지대 3) 이 콘텐츠는 콘텐츠산업 진흥법 에 따라 최초 제작일부터 년간 보호됩니다. 콘텐츠산업 진흥법
PowerPoint Presentation
 Class - Property Jo, Heeseung 목차 section 1 클래스의일반구조 section 2 클래스선언 section 3 객체의생성 section 4 멤버변수 4-1 객체변수 4-2 클래스변수 4-3 종단 (final) 변수 4-4 멤버변수접근방법 section 5 멤버변수접근한정자 5-1 public 5-2 private 5-3 한정자없음
Class - Property Jo, Heeseung 목차 section 1 클래스의일반구조 section 2 클래스선언 section 3 객체의생성 section 4 멤버변수 4-1 객체변수 4-2 클래스변수 4-3 종단 (final) 변수 4-4 멤버변수접근방법 section 5 멤버변수접근한정자 5-1 public 5-2 private 5-3 한정자없음
adfasdfasfdasfasfadf
 C 4.5 Source code Pt.3 ISL / 강한솔 2019-04-10 Index Tree structure Build.h Tree.h St-thresh.h 2 Tree structure *Concpets : Node, Branch, Leaf, Subtree, Attribute, Attribute Value, Class Play, Don't Play.
C 4.5 Source code Pt.3 ISL / 강한솔 2019-04-10 Index Tree structure Build.h Tree.h St-thresh.h 2 Tree structure *Concpets : Node, Branch, Leaf, Subtree, Attribute, Attribute Value, Class Play, Don't Play.
슬라이드 1
 Version 3 ( 강의용수정 ) R 을이용한통계기반데이터분석 2017 윤형기 (hky@openwith.net) 일정표 빅데이터개념과분석플랫폼 데이터분석개념과모델링 통계분석 기계학습 R 언어 1 일차 2 일차 3 일차 4 일차 오전 도입 빅데이터배경 / 개념 빅데이터플랫폼 데이터분석개념과절차 1 CRISP-DM 분석전략 ( 목표와가설 / 지표체계 ) 분석도구
Version 3 ( 강의용수정 ) R 을이용한통계기반데이터분석 2017 윤형기 (hky@openwith.net) 일정표 빅데이터개념과분석플랫폼 데이터분석개념과모델링 통계분석 기계학습 R 언어 1 일차 2 일차 3 일차 4 일차 오전 도입 빅데이터배경 / 개념 빅데이터플랫폼 데이터분석개념과절차 1 CRISP-DM 분석전략 ( 목표와가설 / 지표체계 ) 분석도구
2
 에너지경제연구 Korean Energy Economic Review Volume 10, Number 1, March 2011 : pp. 1~24 국내화력발전산업에대한연료와자본의대체성분석 1 2 3 ~ 4 5 F F P F P F ln ln ln ln ln ln ln ln ln ln ln ln ln ln ln ln ln 6 ln ln ln ln ln 7 ln
에너지경제연구 Korean Energy Economic Review Volume 10, Number 1, March 2011 : pp. 1~24 국내화력발전산업에대한연료와자본의대체성분석 1 2 3 ~ 4 5 F F P F P F ln ln ln ln ln ln ln ln ln ln ln ln ln ln ln ln ln 6 ln ln ln ln ln 7 ln
Microsoft PowerPoint Predicates and Quantifiers.ppt
 이산수학 () 1.3 술어와한정기호 (Predicates and Quantifiers) 2006 년봄학기 문양세강원대학교컴퓨터과학과 술어 (Predicate), 명제함수 (Propositional Function) x is greater than 3. 변수 (variable) = x 술어 (predicate) = P 명제함수 (propositional function)
이산수학 () 1.3 술어와한정기호 (Predicates and Quantifiers) 2006 년봄학기 문양세강원대학교컴퓨터과학과 술어 (Predicate), 명제함수 (Propositional Function) x is greater than 3. 변수 (variable) = x 술어 (predicate) = P 명제함수 (propositional function)
untitled
 Mathematics 4 Statistics / 6. 89 Chapter 6 ( ), ( /) (Euclid geometry ( ), (( + )* /).? Archimedes,... (standard normal distriution, Gaussian distriution) X (..) (a, ). = ep{ } π σ a 6. f ( F ( = F( f
Mathematics 4 Statistics / 6. 89 Chapter 6 ( ), ( /) (Euclid geometry ( ), (( + )* /).? Archimedes,... (standard normal distriution, Gaussian distriution) X (..) (a, ). = ep{ } π σ a 6. f ( F ( = F( f
Microsoft PowerPoint - chap02-C프로그램시작하기.pptx
 #include int main(void) { int num; printf( Please enter an integer "); scanf("%d", &num); if ( num < 0 ) printf("is negative.\n"); printf("num = %d\n", num); return 0; } 1 학습목표 을 작성하면서 C 프로그램의
#include int main(void) { int num; printf( Please enter an integer "); scanf("%d", &num); if ( num < 0 ) printf("is negative.\n"); printf("num = %d\n", num); return 0; } 1 학습목표 을 작성하면서 C 프로그램의
목차 1. 통계학이란무엇인가? 2. 통계학의응용분야 3. 통계학의분야들 4. 강의소개 5. 그리고..
 경영통계학 경영통계학에서는무엇을배우게될까? 2014 년도 2 학기 목차 1. 통계학이란무엇인가? 2. 통계학의응용분야 3. 통계학의분야들 4. 강의소개 5. 그리고.. 1. 통계학이란무엇인가? 매일접하는통계적결과들 연극티켓의평균가격은 18,670원이며우리나라가정의연평균관람횟수는 3.4회이다. 지난해투신사들의평균수익률은 26.5% 였으며투신사에예금한금액은 230억원이증가하였다.
경영통계학 경영통계학에서는무엇을배우게될까? 2014 년도 2 학기 목차 1. 통계학이란무엇인가? 2. 통계학의응용분야 3. 통계학의분야들 4. 강의소개 5. 그리고.. 1. 통계학이란무엇인가? 매일접하는통계적결과들 연극티켓의평균가격은 18,670원이며우리나라가정의연평균관람횟수는 3.4회이다. 지난해투신사들의평균수익률은 26.5% 였으며투신사에예금한금액은 230억원이증가하였다.
저작자표시 - 비영리 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 이차적저작물을작성할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물
 저작자표시 - 비영리 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 이차적저작물을작성할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할수없습니다. 귀하는, 이저작물의재이용이나배포의경우, 이저작물에적용된이용허락조건을명확하게나타내어야합니다.
저작자표시 - 비영리 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 이차적저작물을작성할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할수없습니다. 귀하는, 이저작물의재이용이나배포의경우, 이저작물에적용된이용허락조건을명확하게나타내어야합니다.
실험 5
 실험. OP Amp 의기초회로 Inverting Amplifier OP amp 를이용한아래와같은 inverting amplifier 회로를고려해본다. ( 그림 ) Inverting amplifier 위의회로에서 OP amp의 입력단자는 + 입력단자와동일한그라운드전압, 즉 0V를유지한다. 또한 OP amp 입력단자로흘러들어가는전류는 0 이므로, 저항에흐르는전류는다음과같다.
실험. OP Amp 의기초회로 Inverting Amplifier OP amp 를이용한아래와같은 inverting amplifier 회로를고려해본다. ( 그림 ) Inverting amplifier 위의회로에서 OP amp의 입력단자는 + 입력단자와동일한그라운드전압, 즉 0V를유지한다. 또한 OP amp 입력단자로흘러들어가는전류는 0 이므로, 저항에흐르는전류는다음과같다.
PowerPoint 프레젠테이션
 System Software Experiment 1 Lecture 5 - Array Spring 2019 Hwansoo Han (hhan@skku.edu) Advanced Research on Compilers and Systems, ARCS LAB Sungkyunkwan University http://arcs.skku.edu/ 1 배열 (Array) 동일한타입의데이터가여러개저장되어있는저장장소
System Software Experiment 1 Lecture 5 - Array Spring 2019 Hwansoo Han (hhan@skku.edu) Advanced Research on Compilers and Systems, ARCS LAB Sungkyunkwan University http://arcs.skku.edu/ 1 배열 (Array) 동일한타입의데이터가여러개저장되어있는저장장소
확률과통계4
 확률과통계 4. 확률변수와확률분포 건국대학교스마트 ICT 융합공학과윤경로 (yoonk@konkuk.ac.kr) 4. 확률변수와확률분포 4.1 확률변수와확률분포의개념 4.2 결합확률분포 4.3 주변확률분포 4.4 조건부확률분포 4.5 확률변수의독립 4.1 확률변수와확률분포의개념 [ 정의 4-1] 확률변수 (random variable) 표본공간의각원소를실수값으로
확률과통계 4. 확률변수와확률분포 건국대학교스마트 ICT 융합공학과윤경로 (yoonk@konkuk.ac.kr) 4. 확률변수와확률분포 4.1 확률변수와확률분포의개념 4.2 결합확률분포 4.3 주변확률분포 4.4 조건부확률분포 4.5 확률변수의독립 4.1 확률변수와확률분포의개념 [ 정의 4-1] 확률변수 (random variable) 표본공간의각원소를실수값으로