6. 추 정 (Estimation)
|
|
|
- 민희 곽
- 6 years ago
- Views:
Transcription
1 6. 통계적추정 (Estimatio) updated: 017/4/10
2 6.1 머리말 (Itroductio) 통계적추론 (statistical iferece) 어느모집단으로부터구한표본에서얻어진결과를기초로그모집단에관해추측하는과정 To say somethig about the populatio based o the iformatio of the sample 1) 추정 (estimatio) ) 가설검정 (hypothesis testig)
3 추정치 (estimate) 1) 점추정 (poit estimate) ) 구간추정 (iterval estimate) 추정식 (estimator) 불편이성 (ubiasedess) x x i 의추정식 ˆ( rv.. based o data) is a ubaised estimator of (parameter) if E( ˆ ) ex. E( X ), so sample mea is a ue of the populatio mea if the samples are radomly selected from N(, ) 3
4 * 예 ) sample variace (S ) is a ubiased estimator of σ So E(S ) = σ 1 E ( yi y) Bias = E( ˆ ) : ot a ubiased estimator Bias of a ubiased estimator is zero Probability samplig ad o-probability samplig Radomizatio Blidig
5 표집모집단과목표모집단 (sampled populatio ad target populatio) 랜덤표본과비랜덤표본 (radom sample ad o-radom sample) 편의표본 (coveiece sample)
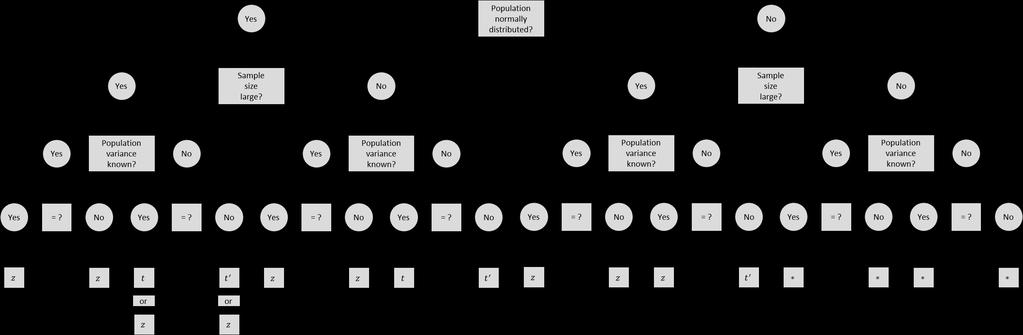
6 6. 모집단평균의신뢰구간 (Cofidece iterval of populatio mea) 추정량 ± 신뢰성계수 표준오차 estimator ± reliability coefficiet stadard error x ± z 1 α σ x, P Z < z 1 α = 1 α If we select samples repeatedly from ormal populatio, x ± z α 1 σ x will iclude μ with the probability of α % 1 α:cofidece level (ex..95) 신뢰수준 α :sigificace level (ex..05) 유의수준 정밀도 (precisio), 오차범위 (margi of error): reliability coefficiet stadard error
7 μ 에대한 95% 신뢰구간 (95% cofidece iterval of μ)
8 <Ex 6..1> 연구자가특정집단의효소의평균을추정하기위하여 10명의표본을뽑아효소값을측정했다. 그결과표본평균 x = 이었다. 효소값은분산이 45인정규분포를따른다고할때, μ의 95% 신뢰구간을추정하라. A researcher measures amout of a certai ezyme. =10, sample mea=, We ca assume ormality with pop variace= % C.I. of? x ± 1.96σ x ± = ± , 6.16
9 <Ex 6..> 물리치료사가한집단의개인에대한특정근육의최대근력의평균치를 99% 신뢰수준에서추정하려고한다. 근력지수는분산이 144 인정규분포를따른다고한다. 실험에참가한 15 명의근력지수평균은 84.3 이다. Measurig maximum stregth of a certai muscle. We wat 99% CI of the pop mea. We assume ormality with pop variace=144. =15, sample mea=84.3, 신뢰수준 0.99 에대응되는신뢰성계수는 R 함수 qorm(0.995) 에의해.58 표준오차는 σ x = 1 15 = μ 에대한 99% 신뢰구간은 84.3 ± = 84.3 ± 8.0 (76.3, 9.3)
10 정규모집단이아닌경우 Sample from o-ormal pop cetral limit theorem <Ex 6..3> 환자 35 명의지각시간조사. 평균 =17. 분이고, 모표준편차 = 8 분. 모집단이정규분포를따르는지모른다는가정하에지각시간의모평균 μ 에대한 90% 신뢰구간?. delay time because of patiet s beig late at a cliic, =35, sample mea=17. mi, sd from the previous study (assumed to be kow)=8 mi. Pop is ot ormally dist ed. what is 90% CI of? Sol) Sample size is big eough (=35>30) -> apply CLT qorm(0.95)= 이다. σ x = 8 35 = ± = 17. ±. 15.0, 19.4
11 * <Ex 6..4> whe pop variace is ot kow. birth.csv 자료에서 bweight 의 95% 신뢰구간을구하시오. (95% cofidece iterval of the variable bweight i birth.csv data) Sol) birth <- read.csv( C:\\Users\\ower\\Desktop\\ 보건통계학개론 \\birth.csv',header=t) head(birth) ; x <- birth$bweight <- legth(x) mea(x)-qorm(0.975)*sd(x)/sqrt(legth(x)) mea(x)+qorm(0.975)*sd(x)/sqrt(legth(x)) summary(x) sd(x)
12 * CI calculatio usig R m <- mea(x) ; m s <- sqrt(var(x)) ; s <- legth(x) ; alpha < error <- qorm(1-alpha/)*s/sqrt() left <- m-error right <- m+error left; right cofit <- fuctio(m,s,,alpha=0.05){ error <- qorm(1-alpha/)*s/sqrt() left <- m-error right <- m+error prit(c(left,right)) } cofit(m,s,) cofit(0.7164,sqrt(0.36),35)
13 [ 중위수를이용한추정 ] Estimatig populatio mea usig media of the sample. Robust 한결과를준다 -> 오차가많이포함된경우에선호 [ 절사평균 ] 가장크고작은관찰치들을제거한후평균계산 -> robust 한결과를준다. Trimmed mea > x<-c(1:9,100) > mea(x);?mea [1] 14.5 > mea(1:10, trim=0.1) [1] 5.5 > mea(:9) [1] 5.5 > mea(x, trim=0.5);media(x) [1] 5.5 [1] 5.5
14 6.3 t- 분포 (t-dist ) 모분산이알려져있고표본수가충분히큰경우에는 Z = X μ 에표준정규분포를적용한다. σ/ (Pop variace is kow ad is large-> use Z) 모분산을모르지만표본수가충분히큰경우에는 s = x i x /( 1) 를 σ대신에사용한다. (Pop variace is ot kow ad is large : use s istead of σ) 표본수가적은경우 (<30) Small sample size : derived by Gosset Studet s t-dist t = X μ S/ ~t 1
15 T- 분포의특성 (Some properties of t-dist ) 1) 평균은 0 (mea= 0) ) 확률밀도함수가평균에대해서대칭 (Symmetric about the mea) 3) t 4), 5) 분산 =df/(df-) for df >, -> 1 as -> Variace=df/(df-) for df >, -> 1 as -> 6) t- 분포는정규분포에비해꼬리가두꺼운형태. Tail of t-dist is thick tha that of ormal dist. 7) 자유도가커질수록정규분포에근사 T-dist approaches to ormal dist as df icreases
16 정규분포와 t- 분포의비교 자유도에따른 t- 분포의형태
17 [ 신뢰구간 ] CI : x ± t df= 1, 1 α Ex = 19 인관측값의평균은 50.8, 표준편차는 라고한다. 모집단이정규분포를따른다고할때, 모평균의 95% 신뢰구간을구하라. =19, measure physical stregth mea=50.8, sd= 130.9, pop variace is ot kow. 95% CI of the pop mea? x = 50.8, s/ = 130.9/ 19 = , df = 1 = 18 이다. qt(0.975,df=18), t df=18,0.975 =.1009 s 50.8 ± = 50.8 ± 63.1 (187.7, 313.9)
 No-parametric")
18 Z 와 t 의선택 (Choice of z ad t) No-parametric methods
19 * x <- seq(-4, 4, legth=100) hx <- dorm(x) degf <- c(1, 3, 8, 30) colors <- c("red", "blue", "darkgree", "gold", "black") labels <- c("df=1", "df=3", "df=8", "df=30", "ormal") plot(x, hx, type="l", lty=, xlab="x value", ylab="desity", mai="compariso of t Distributios") for (i i 1:4){ lies(x, dt(x,degf[i]), lwd=, col=colors[i]) } leged("topright", iset=.05, title="distributios", labels, lwd=, lty=c(1, 1, 1, 1, ), col=colors)
20 6.4 두모집단평균차이의신뢰구간 (CI of the differece of the two meas) Samples from ormal pop s x 1 x ± z 1 α σ σ <Ex 6.4.1> 어떤대형병원에서 1명의다운증후군환자들로부터계산한혈청요산수치의평균값은 x 1 = 4.5mg/100ml이고, 동일연령, 동일성별인정상인 15 명으로부터구한혈청요산수치의평균은 x = 3.4mg/100ml이라고한다. 만약두모집단이분산이각각 1, 1.5인정규분포를따른다고할때, μ 1 μ 의 95% 신뢰구간을구하라.
21 <Ex 6.4.1> Measure serum uric acid from 1 patiets x 1 = 4.5mg/100ml, measuremets from 15 ormal cotrols x = 3.4mg/100ml, variaces are kow to be 1 ad 1.5 for pt ad ct group, 95% CI for μ 1 μ? Sol) σ x 1 x = σ 1 + σ 1 = = ± = 1.1 ± , 1.94 CI does ot iclude 0
22 [ 모집단이정규분포를따르지않을때의신뢰구간 ] Sample from o-ormal pop ->cetral limit theorem < 보기 6.4.> To compare # cigarettes for pregat wome for two groups A: 1 = 38, x 1 = 5., s = 6.33, B: = 64, x = 15, s = 7.16, 99% CI of? Sample sizes are eough s x 1 x = = ± ( 1.8, 7.3)
23 평균비교시 t-분포를사용할때 (t-dist ad differece of the meas) 1) 모분산이동일할때 (Same variaces), ) 모분산이동일하지않을때 (Differet variaces) - 모분산이동일한경우 : 합동추정량을사용한다. (Whe the variaces are the same: we calculate pooled estimate by calculatig weighted average of the variaces) s p = 1 1 s s 1 +, s x 1 x = s p μ 1 μ 에대한 α % 신뢰구간 CI : ( x 1 x ) ± t 1 +,(1 α ) s p + s p s p
24 - 모분산이동일하지않은경우 (Whe the variaces are differet) ( x x ) ( ) s s 1 does ot follow t-dist! w1 t1 wt t ' 1 w1 w ( x1 x ) t '(1 ) s 1 s * w s, w s, df 1 t t, df 1 t t
25 <Ex 6.4.3>18 명의조현병환자의치료일수의평균은 4.7 일, 표준편차는 9.3 이다. 또한 10 명의조울증환자들의치료일수평균은 8.8 일, 표준편차는 11.5 이다. 두표본을이용하여두모평균차이의 95% 신뢰구간을구하라 mea sd mea sd Dx A: Dx B: % CI of? 동일분산의가정하에서 (if we assume that the variaces are the same) 분산의합동추정치 (pooled estimate of the variace) s (11.5 ) p = = 모평균의신뢰구간 ± ± , =
26 <Ex 6.4.4> 분산이다르다고가정한다면 (uder the heterogeeous assumptio) t 17 t 9 t = = ± ± , 5.3
27
28 1-1, 1, Homework
29 6.5 모집단비율의신뢰구간 (CI of proportio) p 에대한 α % 신뢰구간 p 1 p p ± z α 1 <Ex 6.5.1> 1,000명의의약품사용자, 0% 는정보검색위하여인터넷사용. 모비율의 95% 신뢰구간? =1,000, 0% iteret user p(1 p ) = 0.0)(0.80 ) 1000 = ± = 0.0± , 0.5
30 6.6 두모집단비율의차이의신뢰구간 CI of differece of two proportios p 1 p 의 α % 신뢰구간 (CI) p 1 p ± z 1 α p 1 1 p p 1 p <Ex 6.6.1>73 명의여자와 315 명의남자로구성된 388 명의어린이와청소년의확률표본에서 1 명의여자와 45 명의남자가자살충동을느낀경험이있다고한다. 두모집단에서자살충동을느낀사람의비율의차이에대한 99% 신뢰구간을구하라.
31 6.6 두모집단비율의차이의신뢰구간 CI of differece of two proportios <Ex 6.6.1> Out of 73 female, 315 male, 1, 45 said yes (suicidal thoughts) 99% CI for the differece p F = 1 73 = 0.877, p M = 45 = p F p M = = σ p F p M = (0.877)(0.713) 73 qorm(0.995)= (0.8571) 315 = ± ( , 0.906)
32 6.7 표본크기의결정 : 모평균 sample size calculatio: iferece of the mea 표본의크기가크거나혹은복원추출하는경우 (whe sample size is eough or samplig w replacemet) d = z 1 α/ : 신뢰구간의한쪽방향의길이 (width CI/) σ = z 1 α/σ d 표본의크기가작고비복원추출하는경우 (whe sample size is ot eough ad samplig w/o replacemet) d = z σ N N 1 = Nz 1 α/ σ d N 1 +z 1 α/ σ
33 [ 분산의추정 ]Estimatio of the variace 1. 모집단으로부터시험표본 (pilot sample) 을뽑고, 시험표본으로부터표본분산을이용하여필요한표본의크기를계산할수있다. 시험표본은나중에뽑을표본과함께분석에활용할수있다. 따라서필요한표본의크기는 ( 산출된표본크기 ) ( 시험표본의크기 ) 이다.. 이전 (previous) 혹은유사 (similar) 한연구 (studies) 에서 σ 의추정값을이용할수있다. 3. 모집단이정규분포를따를때, 범위는대략적으로표준편차의 6 배 (σ R/6) 이다. 따라서모집단의최솟값과최대값을알면표준편차의추정값을얻을수있다.
34 <Ex 6.7.1> 신뢰구간의폭은 0, 신뢰수준은 0.95, 그리고모분산은 15 라고할때, 표본의크기를구하는과정을설명하라. Width of CI=0 (+-10). Cofidece level= 0.95, pop sd=15, pop is very large; we ca igore fiite pop correctio factor z 1 α = 1.96, σ = 15, d = 10 = = > 9
35 6.8 표본크기의결정 : 모비율 sample size calculatio: iferece of the proportio 무한모집단 (Ifiite populatio) = z 1 α/pq d 유한모집단 (fiite populatio) = Nz 1 α/ pq d N 1 +z 1 α/ pq 모집단크기가충분히크면유한모집단가정가능 If /N.05 ifiite pop ca be assumed.
36 [ 모비율의추정 ] Estimatig the pop. proportio 시험표본 (pilot study) 으로부터계산한점추정값을모비율로이용할수있다. 이전연구나유사한연구 (previous or similar studies) 에서 p 의추정값을이용할수있다. p 를제외한다른값들이고정되어있다고가정하자. p 가 0.5 일때표본의크기가최대가된다. 따라서 p 에대하여알려진사실이전혀없으면 0.5 를이용하여표본의크기를계산할수있다. 하지만이럴경우필요이상으로표본의크기가커지므로, 연구에필요한비용이증가함을기억하자. ( is maximized whe p=.5. You may assume p=0.5 if you have o idea.) 만약 p 의범위를알고있다고하자. 범위에들어가는값들중에서표본의크기를최대로만들어주는 p 를이용하여표본의크기를계산할수있다. 표본의크기를최대로만들어주는 p 의값은식 (6.8.1), (6.8.) 의경우 0.5 에가장가까운값이다. 가령성차별을경험한여성의비율에대하여추정한다고가정하자. 이때성차별을경험한여성의비율 p 는 0.40 보다클수없다는사실이알려져있다면, p 의값으로 0.40 를이용하면된다. (If you kow the rage of p, choose p closest to.5)
37 <Ex 6.8.1> 어떤도시에서아파트에거주하는사람의비율을추정하려고한다. 아파트에거주하는사람의비율이 0.45 보다작다고알려져있다. 이때신뢰구간의폭이 0.1 보다작으며, 95% 의신뢰도를갖는신뢰구간을얻기위하여필요한표본의크기를구하라. proportio livig i a apartmet. We kow p<0.45. We wat that width of 95% CI < 0.10, =? = z 1 α/ pq d = =
38 6.9 정규분포모집단분산의신뢰구간 CI of the variace from ormal dist Poit estimator of variace Good estimator? ubiasedess 각표본이정규분포에서나왔다면 (uder the ormal assumptio) x i x ) = ( 1)σ E( i=1 E( 1 1 i=1 x i x ) = σ E(S )=σ
39 * 일반적으로모수 θ 를추정하기위한방법은수없이많으며그중에서 bias 를 0 로하면서 (ubiased estimator) 분산을최소화시키는방법이이상적이라고할수있다 -> 이러한방법을 Uiformly Miimum Variace Ubiased Estimator (UMVUE) 이라고한다. UMVUE (Uiformly Miimum Variace Ubiased Estimator) is a very good estimator satisfyig ubiasedess with small variace. 표본평균은정규분포조건하에서모평균의최소분산불편추정치이다. (sample mea is the UMVUE of the pop mea uder the ormal assumptio.)
 카이제곱분포의분위수 (Quatiles of Chi-square")
40 카이제곱분포 (chi-square distributio) 1 S σ = ( 1) σ 1 1 ~χ (df = 1) i=1 x i x = i=1 (x i x) σ α χ df,α 카이제곱분포의확률밀도함수 (Chi-square distributio) 카이제곱분포의분위수 (Quatiles of Chi-square distributio)
41 100(1 )% CI of? / (1 / ) ( 1) s ( 1) s 100(1 )% CI of ( 1) s ( 1) s (1 / ) / 100(1 )% CI of <Ex 6.9.1> 다음은 10명의 형당뇨병환자의공복혈을측정한결과이다 , 140.1, 144.3, 155.3, 175.4, 18.9, 140.7, 143.7, 139.0, 14.3 Uder the ormal assumptio, what is 95% CI of the pop variace? Sol) s = 이고, qchisq(0.975, df=9), qchisq(0.05, df=9) χ = 19.08, χ 0.05 = ( ) < σ < 9( ) < σ <

42 6.10 두정규분포모집단의분산비의대한신뢰구간 CI for the ratio of two variaces F-distributio s s 1 1 F 1, 1 1
43 1 100(1 )% CI of? F s, s s F s s s F F / (1 / ) (1 / ) / <Ex > 여성 16 명의체질량지수의표준편차는 5.84 이고, 4 명의남성체질량지수의표준편차는 6.3 이었다고한다. 남성과여성의분산의비에대한 95% 신뢰구간을구하라. ormal adults, =16 females ad 4 males. Sample sd s are 5.84 ad % C.I. of the ratio of the variaces? 1 = 16 = 4 s 1 = 5.84 = 34.11, s = 6.3 = df 1 = 15, df = 3 -> F 0.05 = F = /39.69 < σ σ < 34.11/ > qf(0.05,15,3) [1] > qf(0.975,15,3) [1] < σ 1 σ <
44 [F df1,df,1 (α/) 와 F df1,df, α 의관계 ] F df1,df,1 α = > qf(0.975,3,15) [1] F df,df1,α > 1/qf(0.05,15,3) [1]
45 *[Levee s test: 등분산성검정 (Homogeeity test)] library(car) male <- c(10.673, , 5.731, ) female <- c(6.086, 13.37, 5.195, 15.40,.537, 0.860,.409, , , , 4.403, , , 14.64, 9.136, ) data <- c(male,female) leve.test(male,female) leveetest(male,female)?leveetest group <-c(rep(1,legth(male)),rep(,legth(female))) leveetest(data,factor(group)) t.test(male,female)?t.test t.test(male,female,var.equal=t)
46 > t.test(male,female) Welch Two Sample t-test data: male ad female t = , df = 3.936, p-value = alterative hypothesis: true differece i meas is ot equal to 0 95 percet cofidece iterval: sample estimates: mea of x mea of y > t.test(male,female,var.equal=t) Two Sample t-test data: male ad female t = , df = 18, p-value = alterative hypothesis: true differece i meas is ot equal to 0 95 percet cofidece iterval: sample estimates: mea of x mea of y > leveetest(data,factor(group)) Levee's Test for Homogeeity of Variace (ceter = media) Df F value Pr(>F) group >
47 * SAS Example: Two Idepedet Samples dataset: bullets Bullets Dataset Obs powder velocity
48 proc ttest data=bullets; var velocity;class powder; ru; The TTEST Procedure Lower CL Upper CL Lower CL Variable powder N Mea Mea Mea Std Dev velocity velocity velocity Diff (1-) Upper CL Variable powder Std Dev Std Dev Std Err Miimum Maximum velocity velocity velocity Diff (1-) Variable Method Variaces DF t Value Pr > t velocity Pooled Equal velocity Satterthwaite Uequal Equality of Variaces Variable Method Num DF De DF F Value Pr > F velocity Folded F For H0: Variaces are equal, F = 1.64 DF = (7,9)
49 * Statistical distributios : sum of idepedet ormal rv s 1,,, N(, ) Y Y Y radom sample from iid, Y N 1 1 ( 1) i i Y Y s 0,1 / Y N 1 / Y t s 1 (0,1) i i i Y Y N /, 1 1 /, 1 ( 1) 1 s P
50 F 1, : ratio of idepedet chi-squares (df= 1, ) 1 / / 1 F, 1 s s 1 / 1 / F 1, 1 1 P F 1 s1 / F 1 / s 1
Microsoft Word - multiple
 Chapter 3. Multiple Liear Regressio Data structure ad the model yi 0 1xi1 pxip i, i1,, (Y X ),,, : idepedet with E( ) 0 ad 1 : ukow 0, 1,, p, 0 1 i var( i ) X (1, x,, xp), rak( X) p1, X : give where xj
Chapter 3. Multiple Liear Regressio Data structure ad the model yi 0 1xi1 pxip i, i1,, (Y X ),,, : idepedet with E( ) 0 ad 1 : ukow 0, 1,, p, 0 1 i var( i ) X (1, x,, xp), rak( X) p1, X : give where xj
R t-..
 R 과데이터분석 집단의차이비교 t- 검정 양창모 청주교육대학교컴퓨터교육과 2015 년겨울 t- 검정 변수의값이연속적이고정규분포를따른다고할때사용 t.test() 는모평균과모평균의 95% 신뢰구간을추청함과동시에가설검증을수행한다. 모평균의구간추정 - 일표본 t- 검정 이가설검정의귀무가설은 모평균이 0 이다 라는귀무가설이다. > x t.test(x)
R 과데이터분석 집단의차이비교 t- 검정 양창모 청주교육대학교컴퓨터교육과 2015 년겨울 t- 검정 변수의값이연속적이고정규분포를따른다고할때사용 t.test() 는모평균과모평균의 95% 신뢰구간을추청함과동시에가설검증을수행한다. 모평균의구간추정 - 일표본 t- 검정 이가설검정의귀무가설은 모평균이 0 이다 라는귀무가설이다. > x t.test(x)
 소표본 (
소표본 ( 10. ..
 점추정구간추정표본크기 차례 점추정구간추정표본크기 1 점추정 2 구간추정 3 표본크기 추정의종류 점추정구간추정표본크기 점추정 (point estimation): 모수를어떤하나의값으로추측하는것 구간추정 (interval estimation): 모수를어떤구간으로추측하는것 예 ) 피그미족 (Pygmytribe) 의평균키는모수 µ 표본을추출하여평균을구해보니 135cm
점추정구간추정표본크기 차례 점추정구간추정표본크기 1 점추정 2 구간추정 3 표본크기 추정의종류 점추정구간추정표본크기 점추정 (point estimation): 모수를어떤하나의값으로추측하는것 구간추정 (interval estimation): 모수를어떤구간으로추측하는것 예 ) 피그미족 (Pygmytribe) 의평균키는모수 µ 표본을추출하여평균을구해보니 135cm
생존분석의 추정과 비교 : 보충자료 이용희 December 12, 2018 Contents 1 생존함수와 위험함수 생존함수와 위험함수 예제: 지수분포
 생존분석의 추정과 비교 : 보충자료 이용희 December, 8 Cotets 생존함수와 위험함수. 생존함수와 위험함수....................................... 예제: 지수분포.......................................... 예제: 와이블분포.........................................
생존분석의 추정과 비교 : 보충자료 이용희 December, 8 Cotets 생존함수와 위험함수. 생존함수와 위험함수....................................... 예제: 지수분포.......................................... 예제: 와이블분포.........................................
statistics
 수치를이용한자료요약 statistics hmkang@hallym.ac.kr 한림대학교 통계학 강희모 ( 한림대학교 ) 수치를이용한자료요약 1 / 26 수치를 통한 자료의 요약 요약 방대한 자료를 몇 개의 의미있는 수치로 요약 자료의 분포상태를 알 수 있는 통계기법 사용 중심위치의 측도(measure of center) : 어떤 값을 중심으로 분포되어 있는지
수치를이용한자료요약 statistics hmkang@hallym.ac.kr 한림대학교 통계학 강희모 ( 한림대학교 ) 수치를이용한자료요약 1 / 26 수치를 통한 자료의 요약 요약 방대한 자료를 몇 개의 의미있는 수치로 요약 자료의 분포상태를 알 수 있는 통계기법 사용 중심위치의 측도(measure of center) : 어떤 값을 중심으로 분포되어 있는지
Microsoft PowerPoint - ºÐÆ÷ÃßÁ¤(ÀüÄ¡Çõ).ppt
.ppt") 수명분포및신뢰도의 통계적추정 포항공과대학교산업공학과전치혁.. 수명및수명분포 수명 - 고장 까지의시간 - 확률변수로간주 - 통상잘알려진분포를따른다고가정 수명분포 - 확률밀도함수또는 누적 분포함수로표현 - 신뢰도, 고장률, MTTF 등신뢰성지표는수명분포로부터도출 - 수명분포추정은분포함수관련모수의추정 누적분포함수및확률밀도함수 누적분포함수 cumulav dsbuo
수명분포및신뢰도의 통계적추정 포항공과대학교산업공학과전치혁.. 수명및수명분포 수명 - 고장 까지의시간 - 확률변수로간주 - 통상잘알려진분포를따른다고가정 수명분포 - 확률밀도함수또는 누적 분포함수로표현 - 신뢰도, 고장률, MTTF 등신뢰성지표는수명분포로부터도출 - 수명분포추정은분포함수관련모수의추정 누적분포함수및확률밀도함수 누적분포함수 cumulav dsbuo
제 8 장. 통계적추정 개요 : 통계적추정 ( 추론 ) 은모집단에서추출된표본의정보로모집단에대한값의추측또는그값에대한확신을결정하는과정이며다음의두단계가있다. 2 통계적추정 (statistical estimation): 모수인평균 ( m), 분산 ( s ), 표준편차 ( s
 은모집단에서추출된표본의정보로모집단에대한값의추측또는그값에대한확신을결정하는과정이며다음의두단계가있다. 2 통계적추정 (statistical estimation): 모수인평균 ( m), 분산 ( s ), 표준편차 ( s") 제 8 장. 통계적추정 개요 : 통계적추정 ( 추론 ) 은모집단에서추출된표본의정보로모집단에대한값의추측또는그값에대한확신을결정하는과정이며다음의두단계가있다. 통계적추정 (statistical estimati): 모수인평균 ( m), 분산 ( s ), 표준편차 ( s ), 상관계수 ( r ) 가갖 는값과범위를추정. 가설검정 (hypthesis testig): 모수에대한통계적추정값의옳고그름을판단.
제 8 장. 통계적추정 개요 : 통계적추정 ( 추론 ) 은모집단에서추출된표본의정보로모집단에대한값의추측또는그값에대한확신을결정하는과정이며다음의두단계가있다. 통계적추정 (statistical estimati): 모수인평균 ( m), 분산 ( s ), 표준편차 ( s ), 상관계수 ( r ) 가갖 는값과범위를추정. 가설검정 (hypthesis testig): 모수에대한통계적추정값의옳고그름을판단.
Microsoft PowerPoint - IPYYUIHNPGFU
 분산분석 분산분석 (ANOVA: ANALYSIS OF VARIANCE) 두개이상의모집단의차이를검정 예 : 회사에서세종류의기계를설치하여동일한제품을생산하는경우, 각기계의생산량을조사하여평균생산량을비교 독립변수 : 다른변수에의해영향을주는변수 종속변수 : 다른변수에의해영향을받는변수 요인 (Factor): 독립변수 예에서의요인 : 기계의종류 (I, II, III) 요인수준
분산분석 분산분석 (ANOVA: ANALYSIS OF VARIANCE) 두개이상의모집단의차이를검정 예 : 회사에서세종류의기계를설치하여동일한제품을생산하는경우, 각기계의생산량을조사하여평균생산량을비교 독립변수 : 다른변수에의해영향을주는변수 종속변수 : 다른변수에의해영향을받는변수 요인 (Factor): 독립변수 예에서의요인 : 기계의종류 (I, II, III) 요인수준
ANOVA 란? ANalysis Of VAriance Ø 3개이상의모집단의평균의차이를검정하는방법 Ø 3개의모집단일경우 H0 : μ1 = μ2 = μ3 H0기각 : μ1 μ2 = μ3 or μ1 = μ2 μ3 or μ1 μ2 μ3 àpost hoc test 수행
 Ch4 one-way ANOVA ANOVA 란? ANalysis Of VAriance Ø 3개이상의모집단의평균의차이를검정하는방법 Ø 3개의모집단일경우 H0 : μ1 = μ2 = μ3 H0기각 : μ1 μ2 = μ3 or μ1 = μ2 μ3 or μ1 μ2 μ3 àpost hoc test 수행 One-way ANOVA 란? Group Sex pvas NSAID
Ch4 one-way ANOVA ANOVA 란? ANalysis Of VAriance Ø 3개이상의모집단의평균의차이를검정하는방법 Ø 3개의모집단일경우 H0 : μ1 = μ2 = μ3 H0기각 : μ1 μ2 = μ3 or μ1 = μ2 μ3 or μ1 μ2 μ3 àpost hoc test 수행 One-way ANOVA 란? Group Sex pvas NSAID
Microsoft PowerPoint - chap_2_rep.ppt [호환 모드]
![Microsoft PowerPoint - chap_2_rep.ppt [호환 모드]](/thumbs/102/157053588.jpg "Microsoft PowerPoint - chap_2_rep.ppt [호환 모드]") 제 강.1 통계적기초 확률변수 (Radom Variable). 확률변수 (r.v.): 관측되기전까지는그값이알려지지않은변수. 확률변수의값은확률적실험으로부터결과된다. 확률적실험은실제수행할수있는실험뿐아니라가상적실험도포함함 (ex. 주사위던지기, [0,1] 실선에점던지기 ) 확률변수는그변수의모든가능한값들의집합에대해정의된알려지거나알려지지않은어떤확률분포의존재가연계됨 반면에,
제 강.1 통계적기초 확률변수 (Radom Variable). 확률변수 (r.v.): 관측되기전까지는그값이알려지지않은변수. 확률변수의값은확률적실험으로부터결과된다. 확률적실험은실제수행할수있는실험뿐아니라가상적실험도포함함 (ex. 주사위던지기, [0,1] 실선에점던지기 ) 확률변수는그변수의모든가능한값들의집합에대해정의된알려지거나알려지지않은어떤확률분포의존재가연계됨 반면에,
모수검정과비모수검정 제 6 강 지리통계학
 모수검정과비모수검정 제 6 강 지리통계학 통계적추정의목적 연구자가주장하는연구가설을입증하기위한것 1 연구목적에맞는연구가설을설정 2 연구목적과수집된자료에부합되는적절한통계적검정방법을선택 3 귀무가설과연구가설 ( 대립가설 ) 을진술 4 유의수준을결정한후각분포유형에따라분포표를이용하여임계치를구하고기각역을설정 5 통계적검정유형에필요한통계량을각검정유형의공식을이용하여계산 6
모수검정과비모수검정 제 6 강 지리통계학 통계적추정의목적 연구자가주장하는연구가설을입증하기위한것 1 연구목적에맞는연구가설을설정 2 연구목적과수집된자료에부합되는적절한통계적검정방법을선택 3 귀무가설과연구가설 ( 대립가설 ) 을진술 4 유의수준을결정한후각분포유형에따라분포표를이용하여임계치를구하고기각역을설정 5 통계적검정유형에필요한통계량을각검정유형의공식을이용하여계산 6
 Y 1 Y β α β Independence p qp pq q if X and Y are independent then E(XY)=E(X)*E(Y) so Cov(X,Y) = 0 Covariance can be a measure of departure from independence q Conditional Probability if A and B are
Y 1 Y β α β Independence p qp pq q if X and Y are independent then E(XY)=E(X)*E(Y) so Cov(X,Y) = 0 Covariance can be a measure of departure from independence q Conditional Probability if A and B are
G Power
 G Power 부산대학교통계학과조영석 1. G Power 란? 2. G Power 설치및실행 2.1 G Power 설치 2.2 G Power 실행 3. 검정 (Test) 3.1 가설검정 (Test of hypothesis) 3.2 검정력 (Power) 3.3 효과크기 (Effect size) 3.4 표본수산정 4. 분석 4.1 t- 검정 (t-test) 4.2
G Power 부산대학교통계학과조영석 1. G Power 란? 2. G Power 설치및실행 2.1 G Power 설치 2.2 G Power 실행 3. 검정 (Test) 3.1 가설검정 (Test of hypothesis) 3.2 검정력 (Power) 3.3 효과크기 (Effect size) 3.4 표본수산정 4. 분석 4.1 t- 검정 (t-test) 4.2
자료의 이해 및 분석
 어떤실험이나치료의효과를측정할때독립이아닌표본으로부터관찰치를얻었을때처리하는방법 - 동일한개체에어떤처리를하기전과후의자료를얻을때 - 가능한동일한특성을갖는두개의개체에서로다른처리를하여그처리의효과를비교하는방법 (matching) 1 예제 : 혈청 cholesterol 치를줄이기위해서 12 명을대상으로운동과함께식이요법의효과를 측정하기위한실험실시 2 식이요법 - 운동실험전과후의
어떤실험이나치료의효과를측정할때독립이아닌표본으로부터관찰치를얻었을때처리하는방법 - 동일한개체에어떤처리를하기전과후의자료를얻을때 - 가능한동일한특성을갖는두개의개체에서로다른처리를하여그처리의효과를비교하는방법 (matching) 1 예제 : 혈청 cholesterol 치를줄이기위해서 12 명을대상으로운동과함께식이요법의효과를 측정하기위한실험실시 2 식이요법 - 운동실험전과후의
untitled
 Mathematcal Statstcs / 6. 87 Chapter 6 radom varable probablty desty ucto. dstrbuto ucto.. jot desty ucto... k k margal desty ucto k m.. Statstcs ; θ ereces Y... p. ~ ; θ d radom sample... ; θ ~ statstc
Mathematcal Statstcs / 6. 87 Chapter 6 radom varable probablty desty ucto. dstrbuto ucto.. jot desty ucto... k k margal desty ucto k m.. Statstcs ; θ ereces Y... p. ~ ; θ d radom sample... ; θ ~ statstc
<4D F736F F D20BDC3B0E8BFADBAD0BCAE20C1A B0AD5FBCF6C1A45FB0E8B7AEB0E6C1A6C7D E646F63>
 제 3 강계량경제학 Review Par I. 단순회귀모형 I. 계량경제학 A. 계량경제학 (Economerics 이란? i. 경제적이론이설명하는경제변수들간의관계를경제자료를바탕으로통 계적으로추정 (esimaion 고검정 (es 하는학문 거시소비함수 (Keynse. C=f(Y, 0
제 3 강계량경제학 Review Par I. 단순회귀모형 I. 계량경제학 A. 계량경제학 (Economerics 이란? i. 경제적이론이설명하는경제변수들간의관계를경제자료를바탕으로통 계적으로추정 (esimaion 고검정 (es 하는학문 거시소비함수 (Keynse. C=f(Y, 0
untitled
 Math. Statistics: Statistics? 1 What is Statistics? 1. (collection), (summarization), (analyzing), (presentation) (information) (statistics).., Survey, :, : : QC, 6-sigma, Data Mining(CRM) (Econometrics)
Math. Statistics: Statistics? 1 What is Statistics? 1. (collection), (summarization), (analyzing), (presentation) (information) (statistics).., Survey, :, : : QC, 6-sigma, Data Mining(CRM) (Econometrics)
- 1 -
 - 1 - External Shocks and the Heterogeneous Autoregressive Model of Realized Volatility Abstract: We examine the information effect of external shocks on the realized volatility based on the HAR-RV (heterogeneous
- 1 - External Shocks and the Heterogeneous Autoregressive Model of Realized Volatility Abstract: We examine the information effect of external shocks on the realized volatility based on the HAR-RV (heterogeneous
Microsoft Word - EDA_Univariate.docx
 일변량분석개념 일변량분석은개체의특성을 측정한변수가하나인 통계분석 방법 변수의 종류 ( 수리 통계 ) 이산형 (discrete): 측정결과를셀수있는경우이다. 성별, 직업, 교통량, 나이등이여기해당된다. 연속형 (continuous): 측정결과가무한이 (infinite) 많은변수를연속형형변수라한다. 즉변수의범위 (range) 중어떤구간을설정하더라도측정치가발생할할수있는경우로키,
일변량분석개념 일변량분석은개체의특성을 측정한변수가하나인 통계분석 방법 변수의 종류 ( 수리 통계 ) 이산형 (discrete): 측정결과를셀수있는경우이다. 성별, 직업, 교통량, 나이등이여기해당된다. 연속형 (continuous): 측정결과가무한이 (infinite) 많은변수를연속형형변수라한다. 즉변수의범위 (range) 중어떤구간을설정하더라도측정치가발생할할수있는경우로키,
3 장기술통계 : 수치척도 Part B 분포형태, 상대적위치, 극단값 탐색적자료분석 두변수간의관련성측정 가중평균과그룹화자료
 3 장기술통계 : 수치척도 Part B 분포형태, 상대적위치, 극단값 탐색적자료분석 두변수간의관련성측정 가중평균과그룹화자료 분포형태, 상대적위치, 극단값 분포형태 z-값 체비셰프의원리 경험법칙 극단값찾기 분포형태 : 왜도 (skewness) 분포형태를측정하는중요한척도중하나를 왜도 라고한다. 자료집합의왜도를구하는계산식은조금복잡하다. 통계프로그램을사용하여왜도를쉽게계산할수있다.
3 장기술통계 : 수치척도 Part B 분포형태, 상대적위치, 극단값 탐색적자료분석 두변수간의관련성측정 가중평균과그룹화자료 분포형태, 상대적위치, 극단값 분포형태 z-값 체비셰프의원리 경험법칙 극단값찾기 분포형태 : 왜도 (skewness) 분포형태를측정하는중요한척도중하나를 왜도 라고한다. 자료집합의왜도를구하는계산식은조금복잡하다. 통계프로그램을사용하여왜도를쉽게계산할수있다.
고객관계를 리드하는 서비스 리더십 전략
 제 13 장분산분석 1 13.1 일원분산분석 13. 분산분석 - 무작위블럭디자인 13.3 이원분산분석 - 팩토리얼디자인 분산분석 (ANOVA) - 두개이상의집단들의평균값을비교하는데사용. 일원분산분석 - 처치변수가한개인분산분석. 1. 분산분석의원리 A 3.0 8.0 7.0 5.0 5.0 6.0 4.0 7.0 6.0 4.0 평균 5.0 6.0 B 3.0 9.0
제 13 장분산분석 1 13.1 일원분산분석 13. 분산분석 - 무작위블럭디자인 13.3 이원분산분석 - 팩토리얼디자인 분산분석 (ANOVA) - 두개이상의집단들의평균값을비교하는데사용. 일원분산분석 - 처치변수가한개인분산분석. 1. 분산분석의원리 A 3.0 8.0 7.0 5.0 5.0 6.0 4.0 7.0 6.0 4.0 평균 5.0 6.0 B 3.0 9.0
nonpara1.PDF
 Chapter 1 Introduction 1 Introduction (parameter) (assumption) (rank), (median) p-value distribution free, assumption free, statistical inference based on ranks 11 Nonparametric? John Arbuthnot (1710)
Chapter 1 Introduction 1 Introduction (parameter) (assumption) (rank), (median) p-value distribution free, assumption free, statistical inference based on ranks 11 Nonparametric? John Arbuthnot (1710)
Microsoft Word - SAS_Data Manipulate.docx
 수학계산관련 함수 함수 형태 내용 SIN(argument) TAN(argument) EXP( 변수명 ) SIN 값을계산 -1 argument 1 TAN 값을계산, -1 argument 1 지수함수로지수값을계산한다 SQRT( 변수명 ) 제곱근값을계산한다 제곱은 x**(1/3) = 3 x x 1/ 3 x**2, 세제곱근 LOG( 변수명 ) LOGN( 변수명 )
수학계산관련 함수 함수 형태 내용 SIN(argument) TAN(argument) EXP( 변수명 ) SIN 값을계산 -1 argument 1 TAN 값을계산, -1 argument 1 지수함수로지수값을계산한다 SQRT( 변수명 ) 제곱근값을계산한다 제곱은 x**(1/3) = 3 x x 1/ 3 x**2, 세제곱근 LOG( 변수명 ) LOGN( 변수명 )
수리통계학
 제 강통계학 Revew Part I. 확률론 (Probablty Theory) I. 확률변수 (Radom Varable) 와확률분포 A. 확률변수 는표본공간 Ω 상에서정의되는 real valued fucto 임. 어떤확률적실험의결과로나올수있는모든가능한결과에대해어떤. 실수값이대응되어야함 하나의실험에대해여러가지의확률변수가정의될수있음. 주사위던지는실험 : 던진결과나오는값을대응시켜주는확률변수
제 강통계학 Revew Part I. 확률론 (Probablty Theory) I. 확률변수 (Radom Varable) 와확률분포 A. 확률변수 는표본공간 Ω 상에서정의되는 real valued fucto 임. 어떤확률적실험의결과로나올수있는모든가능한결과에대해어떤. 실수값이대응되어야함 하나의실험에대해여러가지의확률변수가정의될수있음. 주사위던지는실험 : 던진결과나오는값을대응시켜주는확률변수
#Ȳ¿ë¼®
 http://www.kbc.go.kr/ A B yk u δ = 2u k 1 = yk u = 0. 659 2nu k = 1 k k 1 n yk k Abstract Web Repertoire and Concentration Rate : Analysing Web Traffic Data Yong - Suk Hwang (Research
http://www.kbc.go.kr/ A B yk u δ = 2u k 1 = yk u = 0. 659 2nu k = 1 k k 1 n yk k Abstract Web Repertoire and Concentration Rate : Analysing Web Traffic Data Yong - Suk Hwang (Research
wess_usage.PDF
 인터넷을 이용한 통계 분석. 통계학이란? 자료로부터 정보를 얻는 일련의 과정에 Data Collectio, Summaizatio, Aalysis, Repesetatio 관련된 학문이다. Statistics is about data. 통계에 대한 비난: Lie, Dam Lie, ad Statistics, Statistics ca pove aythig 통계가 거짓말을
인터넷을 이용한 통계 분석. 통계학이란? 자료로부터 정보를 얻는 일련의 과정에 Data Collectio, Summaizatio, Aalysis, Repesetatio 관련된 학문이다. Statistics is about data. 통계에 대한 비난: Lie, Dam Lie, ad Statistics, Statistics ca pove aythig 통계가 거짓말을
Microsoft PowerPoint - SBE univariate5.pptx
 이상치 (outlier) 진단및해결 Homework 데이터 ( Option.XLS) 결과해석 치우침? 평균이중앙값에비해다소크다. 그러나이상치때문이지치우친것같지않음. Toys us 스톡옵션비율이이상치 해결방법 : Log 변환? 아니다치우쳐있지않기때문에제거 제거후 : 평균 :.74, 중위수 :.7 31 치우침과이상치 데이터 : 노트북평가점수 우로치우침과이상치가존재
이상치 (outlier) 진단및해결 Homework 데이터 ( Option.XLS) 결과해석 치우침? 평균이중앙값에비해다소크다. 그러나이상치때문이지치우친것같지않음. Toys us 스톡옵션비율이이상치 해결방법 : Log 변환? 아니다치우쳐있지않기때문에제거 제거후 : 평균 :.74, 중위수 :.7 31 치우침과이상치 데이터 : 노트북평가점수 우로치우침과이상치가존재
cat_data3.PDF
 ( ) IxJ ( 5 0% ) Pearson Fsher s exact test χ, LR Ch-square( G ) x, Odds Rato θ, Ch-square Ch-square (Goodness of ft) Pearson cross moment ( Mantel-Haenszel ), Ph-coeffcent, Gamma (γ ), Kendall τ (bnary)
( ) IxJ ( 5 0% ) Pearson Fsher s exact test χ, LR Ch-square( G ) x, Odds Rato θ, Ch-square Ch-square (Goodness of ft) Pearson cross moment ( Mantel-Haenszel ), Ph-coeffcent, Gamma (γ ), Kendall τ (bnary)
untitled
 5.8 PROC UNIVARIATE (hitogram, tem and leaf plot, box-whiker plot), (p- ). Univariate( ).. NORMAL (Shapiro- Wilk Kolmogorov-Smirno D- OUTPUT( SAS ). PROC MEANS PROC MEANS. (moment) E( X ). k Sehyug Kwon,
5.8 PROC UNIVARIATE (hitogram, tem and leaf plot, box-whiker plot), (p- ). Univariate( ).. NORMAL (Shapiro- Wilk Kolmogorov-Smirno D- OUTPUT( SAS ). PROC MEANS PROC MEANS. (moment) E( X ). k Sehyug Kwon,
메타분석: 통계적 방법의 기초
 메타분석: 통계적 방법의 기초 서울시립대학교 통계학과 이용희 209년 4월 23일 Contents 하나의 실험과 효과의 크기 관심있는 모수: 효과의 크기 2 모수의 추정량 3 추정량에 대한 믿음 4 추정량의 분산과 표준오차 5 추정량의 분산과 모집단의 분산 6 통계적 효과의 크기 7 신뢰구간 8 일반적인 관심 모수 2 2 2 3 개의 실험의 비교 실험들의 이질성
메타분석: 통계적 방법의 기초 서울시립대학교 통계학과 이용희 209년 4월 23일 Contents 하나의 실험과 효과의 크기 관심있는 모수: 효과의 크기 2 모수의 추정량 3 추정량에 대한 믿음 4 추정량의 분산과 표준오차 5 추정량의 분산과 모집단의 분산 6 통계적 효과의 크기 7 신뢰구간 8 일반적인 관심 모수 2 2 2 3 개의 실험의 비교 실험들의 이질성
... —....—
 통계학 추출분포 한국보건사회연구원 2017 년 5 월 22 일 ( 월요일 ) 강의슬라이드 6 1/ 36 목차 1 들어가며 2 표본평균의추출분포 3 추출분포결론 2/ 36 추출분포와통계적추론 통계량의추출분포모집단분포 통계적추론이어떤표본을토대로모집단에대한결론을내리게끔해줌 어떤표본을토대로모집단에대한결론을내릴때, 이표본이모집단을잘대표해야한다는것은이제두말하면잔소리 =
통계학 추출분포 한국보건사회연구원 2017 년 5 월 22 일 ( 월요일 ) 강의슬라이드 6 1/ 36 목차 1 들어가며 2 표본평균의추출분포 3 추출분포결론 2/ 36 추출분포와통계적추론 통계량의추출분포모집단분포 통계적추론이어떤표본을토대로모집단에대한결론을내리게끔해줌 어떤표본을토대로모집단에대한결론을내릴때, 이표본이모집단을잘대표해야한다는것은이제두말하면잔소리 =
01-07-0.hwp
 선거와 시장경제Ⅱ - 2000 국회의원 선거시장을 중심으로 - 발간사 차 례 표 차례 그림 차례 제1부 시장 메커니즘과 선거시장 Ⅰ. 서 론 Ⅱ. 선거시장의 원리와 운영방식 정당시장 지역구시장 문의사항은 Q&A를 참고하세요 정당시장 한나라당 사기 종목주가그래프 c 2000 중앙일보 Cyber중앙 All rights reserved. Terms
선거와 시장경제Ⅱ - 2000 국회의원 선거시장을 중심으로 - 발간사 차 례 표 차례 그림 차례 제1부 시장 메커니즘과 선거시장 Ⅰ. 서 론 Ⅱ. 선거시장의 원리와 운영방식 정당시장 지역구시장 문의사항은 Q&A를 참고하세요 정당시장 한나라당 사기 종목주가그래프 c 2000 중앙일보 Cyber중앙 All rights reserved. Terms
확률 및 분포
 확률및분포 박창이 서울시립대학교통계학과 박창이 ( 서울시립대학교통계학과 ) 확률및분포 1 / 15 학습내용 조건부확률막대그래프히스토그램선그래프산점도참고 박창이 ( 서울시립대학교통계학과 ) 확률및분포 2 / 15 조건부확률 I 첫째가딸일때두아이모두딸일확률 (1/2) 과둘중의하나가딸일때둘다딸일확률 (1/3) 에대한모의실험 >>> from collections import
확률및분포 박창이 서울시립대학교통계학과 박창이 ( 서울시립대학교통계학과 ) 확률및분포 1 / 15 학습내용 조건부확률막대그래프히스토그램선그래프산점도참고 박창이 ( 서울시립대학교통계학과 ) 확률및분포 2 / 15 조건부확률 I 첫째가딸일때두아이모두딸일확률 (1/2) 과둘중의하나가딸일때둘다딸일확률 (1/3) 에대한모의실험 >>> from collections import
중심경향치 (measure of central tendency) 대표값이란용어이외에자료의중심값또는중심위치의척도 (measure of central location) 라고도함. 예 : 평균 (mean= 산술평균 ; arithmetic mean), 절사평균 (trimmed
 대표값이란용어이외에자료의중심값또는중심위치의척도 (measure of central location) 라고도함. 예 : 평균 (mean= 산술평균 ; arithmetic mean), 절사평균 (trimmed") 중심경향치 (measure of central tendency) 대표값이란용어이외에자료의중심값또는중심위치의척도 (measure of central location) 라고도함. 예 : 평균 (mean= 산술평균 ; arithmetic mean), 절사평균 (trimmed mean), 가중평균 (weighted mean), 기하평균 (geometric mean),
중심경향치 (measure of central tendency) 대표값이란용어이외에자료의중심값또는중심위치의척도 (measure of central location) 라고도함. 예 : 평균 (mean= 산술평균 ; arithmetic mean), 절사평균 (trimmed mean), 가중평균 (weighted mean), 기하평균 (geometric mean),
(001~006)개념RPM3-2(부속)
개념RPM3-2(부속)") www.imth.tv - (~9)개념RPM-(본문).. : PM RPM - 대푯값 페이지 다민 PI LPI 알피엠 대푯값과산포도 유형 ⑴ 대푯값 자료 전체의 중심적인 경향이나 특징을 하나의 수로 나타낸 값 ⑵ 평균 (평균)= Ⅰ 통계 (변량)의 총합 (변량의 개수) 개념플러스 대푯값에는 평균, 중앙값, 최 빈값 등이 있다. ⑶ 중앙값 자료를 작은 값부터 크기순으로
www.imth.tv - (~9)개념RPM-(본문).. : PM RPM - 대푯값 페이지 다민 PI LPI 알피엠 대푯값과산포도 유형 ⑴ 대푯값 자료 전체의 중심적인 경향이나 특징을 하나의 수로 나타낸 값 ⑵ 평균 (평균)= Ⅰ 통계 (변량)의 총합 (변량의 개수) 개념플러스 대푯값에는 평균, 중앙값, 최 빈값 등이 있다. ⑶ 중앙값 자료를 작은 값부터 크기순으로
<C5EBB0E8C0FBB0A1BCB3B0CBC1F5C0C7C0FDC2F7BFCDB9AEC1A6C1A1B1D7B8AEB0EDB4EBBEC E687770>
 통계적가설검증의절차와문제점그리고대안 서울대학교심리학과, 인지과학협동과정교수조사연구편집위원장조사연구학회이사서울대사회과학대학교무부학장역임 주요연구 : Self-efficacy in information security : Its influence on end users information security practice behavior When fit indices
통계적가설검증의절차와문제점그리고대안 서울대학교심리학과, 인지과학협동과정교수조사연구편집위원장조사연구학회이사서울대사회과학대학교무부학장역임 주요연구 : Self-efficacy in information security : Its influence on end users information security practice behavior When fit indices
untitled
 Six Sigma - - Grouping Brainstorming : Observ. 8 - - 22 27 32 37 5 5 Capability -27.7552 63.7552 22 Capability 3.SL=69.82 X=29.73-3.SL=-.35 3.SL=49.24 R=5.7-2.29 7.7578-3.SL=.E+ 22 Data Source: Time Span:
Six Sigma - - Grouping Brainstorming : Observ. 8 - - 22 27 32 37 5 5 Capability -27.7552 63.7552 22 Capability 3.SL=69.82 X=29.73-3.SL=-.35 3.SL=49.24 R=5.7-2.29 7.7578-3.SL=.E+ 22 Data Source: Time Span:
Objective-driven systems modeling
 Lect 4: Hypothess Test ad Model Valdato Goodess of : Cofdece Iterval for μ of 5 X: ormal dstrbuto σ : ow s also ormal f () (-α) C.I. C.I for X (- ) P{ w w X w X P{ } / / / w w P{ z } / / P{ z z z } w z
Lect 4: Hypothess Test ad Model Valdato Goodess of : Cofdece Iterval for μ of 5 X: ormal dstrbuto σ : ow s also ormal f () (-α) C.I. C.I for X (- ) P{ w w X w X P{ } / / / w w P{ z } / / P{ z z z } w z
조사연구 권 호 연구논문 한국노동패널조사자료의분석을위한패널가중치산출및사용방안사례연구 A Case Study on Construction and Use of Longitudinal Weights for Korea Labor Income Panel Survey 2)3) a
3) a") 조사연구 권 호 연구논문 한국노동패널조사자료의분석을위한패널가중치산출및사용방안사례연구 A Case Study on Construction and Use of Longitudinal Weights for Korea Labor Income Panel Survey 2)3) a) b) 조사연구 주제어 패널조사 횡단면가중치 종단면가중치 선형혼합모형 일반화선형혼 합모형
조사연구 권 호 연구논문 한국노동패널조사자료의분석을위한패널가중치산출및사용방안사례연구 A Case Study on Construction and Use of Longitudinal Weights for Korea Labor Income Panel Survey 2)3) a) b) 조사연구 주제어 패널조사 횡단면가중치 종단면가중치 선형혼합모형 일반화선형혼 합모형
공공기관임금프리미엄추계 연구책임자정진호 ( 한국노동연구원선임연구위원 ) 연구원오호영 ( 한국직업능력개발원연구위원 ) 연구보조원강승복 ( 한국노동연구원책임연구원 ) 이연구는국회예산정책처의정책연구용역사업으로 수행된것으로서, 본연구에서제시된의견이나대안등은
 연구원오호영 ( 한국직업능력개발원연구위원 ) 연구보조원강승복 ( 한국노동연구원책임연구원 ) 이연구는국회예산정책처의정책연구용역사업으로 수행된것으로서, 본연구에서제시된의견이나대안등은") 2013 년도연구용역보고서 공공기관임금프리미엄추계 - 2013. 12.- 이연구는국회예산정책처의연구용역사업으로수행된것으로서, 보고서의내용은연구용역사업을수행한연구자의개인의견이며, 국회예산정책처의공식견해가아님을알려드립니다. 연구책임자 한국노동연구원선임연구위원정진호 공공기관임금프리미엄추계 2013. 12. 연구책임자정진호 ( 한국노동연구원선임연구위원 ) 연구원오호영
2013 년도연구용역보고서 공공기관임금프리미엄추계 - 2013. 12.- 이연구는국회예산정책처의연구용역사업으로수행된것으로서, 보고서의내용은연구용역사업을수행한연구자의개인의견이며, 국회예산정책처의공식견해가아님을알려드립니다. 연구책임자 한국노동연구원선임연구위원정진호 공공기관임금프리미엄추계 2013. 12. 연구책임자정진호 ( 한국노동연구원선임연구위원 ) 연구원오호영
이다. 즉 μ μ μ : 가아니다. 이러한검정을하기위하여분산분석은다음과같은가정을두고있다. 분산분석의가정 (1) r개모집단분포는모두정규분포를이루고있다. (2) r개모집단의평균은다를수있으나분산은모두같다. (3) r개모집단에서추출한표본은서로독립적이다. 분산분석은집단을구분하는
 r개모집단분포는모두정규분포를이루고있다. (2) r개모집단의평균은다를수있으나분산은모두같다. (3) r개모집단에서추출한표본은서로독립적이다. 분산분석은집단을구분하는") 제 12 강분산분석 분산분석 (ANOVA) (1) 1. 개요 비교하는집단의수가 3개이상일경우에사용되는통계기법이분산분석이다. 두표본 t검증에서는문제의단순성때문에야기되지않는문제들이다수의표본으로확대됨에따라문제들이야기되기도한다. 다음과같은 r개의모집단이있다고가정하자..... ~ N( μ σ ) ~ N( μ σ ).... ~ N ( μ σ )...... 위의그림과같이여러번에걸쳐두표본의
제 12 강분산분석 분산분석 (ANOVA) (1) 1. 개요 비교하는집단의수가 3개이상일경우에사용되는통계기법이분산분석이다. 두표본 t검증에서는문제의단순성때문에야기되지않는문제들이다수의표본으로확대됨에따라문제들이야기되기도한다. 다음과같은 r개의모집단이있다고가정하자..... ~ N( μ σ ) ~ N( μ σ ).... ~ N ( μ σ )...... 위의그림과같이여러번에걸쳐두표본의
Resampling Methods
 Resampling Methds 박창이 서울시립대학교통계학과 박창이 ( 서울시립대학교통계학과 ) Resampling Methds 1 / 18 학습내용 개요 CV(crss-validatin) 검증오차 LOOCV(leave-ne-ut crss-validatin) k-fld CV 편의-분산의관계분류문제에서의 CV Btstrap 박창이 ( 서울시립대학교통계학과 )
Resampling Methds 박창이 서울시립대학교통계학과 박창이 ( 서울시립대학교통계학과 ) Resampling Methds 1 / 18 학습내용 개요 CV(crss-validatin) 검증오차 LOOCV(leave-ne-ut crss-validatin) k-fld CV 편의-분산의관계분류문제에서의 CV Btstrap 박창이 ( 서울시립대학교통계학과 )
용역보고서
 신뢰성샘플링검사의설계방법 ( 정수관측중단시험 ) 9.. ( 주 ) 한국신뢰성기술서비스 목차 신뢰성샘플링검사의설계방법 ( 정수관측중단시험 ).... 개요.... 기호및용어정의.... 샘플링검사의설계방법... 3. 정수중단시샘플링검사설계방법...4 4. 신뢰성샘플링시험계획예제...5 hp://www.kors.co.kr 신뢰성샘플링검사의설계방법 ( 정수관측중단시험
신뢰성샘플링검사의설계방법 ( 정수관측중단시험 ) 9.. ( 주 ) 한국신뢰성기술서비스 목차 신뢰성샘플링검사의설계방법 ( 정수관측중단시험 ).... 개요.... 기호및용어정의.... 샘플링검사의설계방법... 3. 정수중단시샘플링검사설계방법...4 4. 신뢰성샘플링시험계획예제...5 hp://www.kors.co.kr 신뢰성샘플링검사의설계방법 ( 정수관측중단시험
nonpara6.PDF
 6 One-way layout 3 (oneway layout) k k y y y y n n y y K yn y y n n y y K yn k y k y k yknk n k yk yk K y nk (grand mean) (SST) (SStr: ) (SSE= SST-SStr), ( 39 ) ( )(rato) F- (normalty assumpton), Medan,
6 One-way layout 3 (oneway layout) k k y y y y n n y y K yn y y n n y y K yn k y k y k yknk n k yk yk K y nk (grand mean) (SST) (SStr: ) (SSE= SST-SStr), ( 39 ) ( )(rato) F- (normalty assumpton), Medan,
모수 θ의 추정량은 추출한 개의 표본값을 어떤 규칙에 의해 처리를 해서 모수의 값을 추정하는 방법입니다. 추정량에서 사용되는 규칙은 어떤 표본을 추출했냐에 따라 변하는 것이 아닌 고정된 규칙입니다. 예를 들어 우리의 관심 모수가 모집단의 평균이라고 하겠습니다. 즉 θ
 수리통계학(Mathematical Statistics)의 기초 I. 들어가며 지금부터 계량경제학이나 실험 및 준실험 연구설계 기법을 공부할 때 도움이 되는 수리통계 학의 기초에 대해 다룰 것입니다. 이 노트에서 다루게 될 내용은 어떤 추정량(estimator)이 지니고 있는 성질입니다. 한 가지 말씀 드릴 것은 이 노트에 나오는 대부분의 성질들은 지금까 지
수리통계학(Mathematical Statistics)의 기초 I. 들어가며 지금부터 계량경제학이나 실험 및 준실험 연구설계 기법을 공부할 때 도움이 되는 수리통계 학의 기초에 대해 다룰 것입니다. 이 노트에서 다루게 될 내용은 어떤 추정량(estimator)이 지니고 있는 성질입니다. 한 가지 말씀 드릴 것은 이 노트에 나오는 대부분의 성질들은 지금까 지
2-32
 Itroductio The field effect trasistor(fet) is a uiolar device because, ulike biolar trasistor that use both electro ad hole curret, they oerate oly with oe tye of charge carrier. (BJT) (FET). The two mai
Itroductio The field effect trasistor(fet) is a uiolar device because, ulike biolar trasistor that use both electro ad hole curret, they oerate oly with oe tye of charge carrier. (BJT) (FET). The two mai
슬라이드 1
 Principles of Econometrics (3e) 013 년 1 학기 윤성민 10.0 서론 The assumptions of the simple linear regression are: SR1. SR. yi =β 1 +β xi + ei i= 1,, N Ee ( i ) = 0 SR3. var( e i ) = σ SR4. cov( e, e ) = 0 i
Principles of Econometrics (3e) 013 년 1 학기 윤성민 10.0 서론 The assumptions of the simple linear regression are: SR1. SR. yi =β 1 +β xi + ei i= 1,, N Ee ( i ) = 0 SR3. var( e i ) = σ SR4. cov( e, e ) = 0 i
... —... ..—
 통계학 통계적추론 한국보건사회연구원 2017 년 5 월 29 일 ( 월요일 ) 강의슬라이드 7-1 1/ 72 목차 1 서론 2 신뢰구간을이용한통계적추론 3 통계적유의성검정 4 유의성검정과관련해서유의해야할점 2/ 72 지난시간복습 왜 x 가 µ 와완벽하게일치하지않고또어떤표본을추출했냐에따라 x 값이달라지는데이 x 를이용해서모집단 µ 를추정할까? 두가지사실때문 :
통계학 통계적추론 한국보건사회연구원 2017 년 5 월 29 일 ( 월요일 ) 강의슬라이드 7-1 1/ 72 목차 1 서론 2 신뢰구간을이용한통계적추론 3 통계적유의성검정 4 유의성검정과관련해서유의해야할점 2/ 72 지난시간복습 왜 x 가 µ 와완벽하게일치하지않고또어떤표본을추출했냐에따라 x 값이달라지는데이 x 를이용해서모집단 µ 를추정할까? 두가지사실때문 :
제 3 장평활법 지수평활법 (exponential smoothing) 최근자료에더큰가중값, 과거로갈수록가중값을지수적으로줄여나가는방법 시스템에변화가있을경우변화에쉽게대처가능 계산이쉽고많은자료의저장이필요없다 예측이주목적단순지수평활법, 이중지수평활법, 삼중지수평활법, Wint
 최근자료에더큰가중값, 과거로갈수록가중값을지수적으로줄여나가는방법 시스템에변화가있을경우변화에쉽게대처가능 계산이쉽고많은자료의저장이필요없다 예측이주목적단순지수평활법, 이중지수평활법, 삼중지수평활법, Wint") 제 3 장평활법 지수평활법 (exponential smoothing) 최근자료에더큰가중값, 과거로갈수록가중값을지수적으로줄여나가는방법 시스템에변화가있을경우변화에쉽게대처가능 계산이쉽고많은자료의저장이필요없다 예측이주목적단순지수평활법, 이중지수평활법, 삼중지수평활법, Winters의계절지수평활법 이동평균법 (moving average method) 평활에의해계절성분또는불규칙성분을제거하여전반적인추세를뚜렷하게파악
제 3 장평활법 지수평활법 (exponential smoothing) 최근자료에더큰가중값, 과거로갈수록가중값을지수적으로줄여나가는방법 시스템에변화가있을경우변화에쉽게대처가능 계산이쉽고많은자료의저장이필요없다 예측이주목적단순지수평활법, 이중지수평활법, 삼중지수평활법, Winters의계절지수평활법 이동평균법 (moving average method) 평활에의해계절성분또는불규칙성분을제거하여전반적인추세를뚜렷하게파악
 회귀분석의 기초 한국보건사회연구원 2017년 6월 19일(월요일) & 22일(목요일) 강의 슬라이드 9 1/ 78 목차 1 2 3 4 2/ 78 지난 시간 복습 모집단 평균 µ에 대한 통계적 추론을 하는 방법: σ 신뢰구간: x ± t 유의성 검정: t = x µ σ/ 위 공식을 보면 모집단 표준편차 σ가 들어 있는데 이 σ를 모르니까 표본 표준편차 s로 대체해서
회귀분석의 기초 한국보건사회연구원 2017년 6월 19일(월요일) & 22일(목요일) 강의 슬라이드 9 1/ 78 목차 1 2 3 4 2/ 78 지난 시간 복습 모집단 평균 µ에 대한 통계적 추론을 하는 방법: σ 신뢰구간: x ± t 유의성 검정: t = x µ σ/ 위 공식을 보면 모집단 표준편차 σ가 들어 있는데 이 σ를 모르니까 표본 표준편차 s로 대체해서
Microsoft PowerPoint - chap_11_rep.ppt [호환 모드]
![Microsoft PowerPoint - chap_11_rep.ppt [호환 모드]](/thumbs/91/105158542.jpg "Microsoft PowerPoint - chap_11_rep.ppt [호환 모드]") 제 11 강 111 자기상관 Autocorrelation 자기상관의본질 11 유효성 (efficiency, accurate estimation/prediction) 을위해서는모든체계적인정보가회귀모형에체화되어있어야함 표본의무작위성 (randomness) 은서로다른관측치들에대한오차항들이상관되어있지말아야함을의미함 자기상관 (Autocorrelation) 은이러한표본의무작위성을위반하게만드는오차항에있는체계적패턴임
제 11 강 111 자기상관 Autocorrelation 자기상관의본질 11 유효성 (efficiency, accurate estimation/prediction) 을위해서는모든체계적인정보가회귀모형에체화되어있어야함 표본의무작위성 (randomness) 은서로다른관측치들에대한오차항들이상관되어있지말아야함을의미함 자기상관 (Autocorrelation) 은이러한표본의무작위성을위반하게만드는오차항에있는체계적패턴임
Jeeshim & KUCC625 (08/04/2009) Statistical Data Analysis Using R:22 6. 집단간평균비교 집단간평균을비교하는것은기본방법이다. 따라서비교할변수는평균을계산할수있어야하고, 의미있게해석할수있어야한다. 두집단
 Statistical Data Analysis Using R:22 6. 집단간평균비교 집단간평균을비교하는것은기본방법이다. 따라서비교할변수는평균을계산할수있어야하고, 의미있게해석할수있어야한다. 두집단") 2008-2009 Jeeshim & KUCC625 (08/04/2009) Statistical Data Analysis Using R:22 6. 집단간평균비교 집단간평균을비교하는것은기본방법이다. 따라서비교할변수는평균을계산할수있어야하고, 의미있게해석할수있어야한다. 두집단을비교하는것은 T-test 로, 두집단이상이라면 ANOVA 를사용한다. 그림 6.1 은 T-test
2008-2009 Jeeshim & KUCC625 (08/04/2009) Statistical Data Analysis Using R:22 6. 집단간평균비교 집단간평균을비교하는것은기본방법이다. 따라서비교할변수는평균을계산할수있어야하고, 의미있게해석할수있어야한다. 두집단을비교하는것은 T-test 로, 두집단이상이라면 ANOVA 를사용한다. 그림 6.1 은 T-test
<B0A3C3DFB0E828C0DBBEF7292E687770>
 초청연자특강 대구가톨릭의대의학통계학교실 Meta analysis ( 메타분석 ) 예1) The effect of interferon on development of hepatocellular carcinoma in patients with chronic hepatitis B virus infection?? -:> 1998.1 ~2007.12.31 / RCT(2),
초청연자특강 대구가톨릭의대의학통계학교실 Meta analysis ( 메타분석 ) 예1) The effect of interferon on development of hepatocellular carcinoma in patients with chronic hepatitis B virus infection?? -:> 1998.1 ~2007.12.31 / RCT(2),
Chapter4.hwp
 Ch. 4. Spectral Density & Correlation 4.1 Energy Spectral Density 4.2 Power Spectral Density 4.3 Time-Averaged Noise Representation 4.4 Correlation Functions 4.5 Properties of Correlation Functions 4.6
Ch. 4. Spectral Density & Correlation 4.1 Energy Spectral Density 4.2 Power Spectral Density 4.3 Time-Averaged Noise Representation 4.4 Correlation Functions 4.5 Properties of Correlation Functions 4.6
01
 2019 학년도대학수학능력시험 9 월모의평가문제및정답 2019 학년도대학수학능력시험 9 월모의평가문제지 1 제 2 교시 5 지선다형 1. 두벡터, 모든성분의합은? [2 점 ] 에대하여벡터 의 3. 좌표공간의두점 A, B 에대하여선분 AB 를 로외분하는점의좌표가 일때, 의값은? [2점] 1 2 3 4 5 1 2 3 4 5 2. lim 의값은? [2점] 4. 두사건,
2019 학년도대학수학능력시험 9 월모의평가문제및정답 2019 학년도대학수학능력시험 9 월모의평가문제지 1 제 2 교시 5 지선다형 1. 두벡터, 모든성분의합은? [2 점 ] 에대하여벡터 의 3. 좌표공간의두점 A, B 에대하여선분 AB 를 로외분하는점의좌표가 일때, 의값은? [2점] 1 2 3 4 5 1 2 3 4 5 2. lim 의값은? [2점] 4. 두사건,
Communications of the Korean Statistical Society Vol. 15, No. 4, 2008, pp 국소적 강력 단위근 검정 최보승1), 우진욱2), 박유성3) 요약 시계열 자료를 분석할 때, 시계열 자료가 가지고 있는
, 우진욱2), 박유성3) 요약 시계열 자료를 분석할 때, 시계열 자료가 가지고 있는") Communications of the Korean Statistical Society Vol 5, No 4, 2008, pp 53 542 국소적 강력 단위근 검정 최보승), 우진욱2), 박유성3) 요약 시계열 자료를 분석할 때, 시계열 자료가 가지고 있는 추세를 제거하기 위하여 결 정적 추세인 경우 회귀모형을 이용하고, 확률적 추세인 경우 차분하는 방법을
Communications of the Korean Statistical Society Vol 5, No 4, 2008, pp 53 542 국소적 강력 단위근 검정 최보승), 우진욱2), 박유성3) 요약 시계열 자료를 분석할 때, 시계열 자료가 가지고 있는 추세를 제거하기 위하여 결 정적 추세인 경우 회귀모형을 이용하고, 확률적 추세인 경우 차분하는 방법을
표본재추출(resampling) 방법
 방법") 표본재추출 (resampling) 방법 박창이 서울시립대학교통계학과 박창이 ( 서울시립대학교통계학과 ) 표본재추출 (resampling) 방법 1 / 18 학습내용 개요 CV(crss-validatin) 검증오차 LOOCV(leave-ne-ut crss-validatin) k-fld CV 편의-분산의관계분류문제에서의 CV Btstrap 박창이 ( 서울시립대학교통계학과
표본재추출 (resampling) 방법 박창이 서울시립대학교통계학과 박창이 ( 서울시립대학교통계학과 ) 표본재추출 (resampling) 방법 1 / 18 학습내용 개요 CV(crss-validatin) 검증오차 LOOCV(leave-ne-ut crss-validatin) k-fld CV 편의-분산의관계분류문제에서의 CV Btstrap 박창이 ( 서울시립대학교통계학과
:,,.,. 456, 253 ( 89, 164 ), 203 ( 44, 159 ). Cronbach α= ,.,,..,,,.,. :,, ( )
, 203 ( 44, 159 ). Cronbach α= ,.,,..,,,.,. :,, ( )") :,,.,. 456, 253 ( 89, 164 ), 203 ( 44, 159 ). Cronbach α=.83.91.,.,,..,,,.,. :,, (402-751) 253 E-mail : yspark@inha.ac.kr ..,.,.,. Bandura(1997),.,,,,., (,,, 2009), (,,,, 2014).?.,,,.. Bandura (1995) (Resiliency
:,,.,. 456, 253 ( 89, 164 ), 203 ( 44, 159 ). Cronbach α=.83.91.,.,,..,,,.,. :,, (402-751) 253 E-mail : yspark@inha.ac.kr ..,.,.,. Bandura(1997),.,,,,., (,,, 2009), (,,,, 2014).?.,,,.. Bandura (1995) (Resiliency
(Exposure) Exposure (Exposure Assesment) EMF Unknown to mechanism Health Effect (Effect) Unknown to mechanism Behavior pattern (Micro- Environment) Re
 Exposure (Exposure Assesment) EMF Unknown to mechanism Health Effect (Effect) Unknown to mechanism Behavior pattern (Micro- Environment) Re") EMF Health Effect 2003 10 20 21-29 2-10 - - ( ) area spot measurement - - 1 (Exposure) Exposure (Exposure Assesment) EMF Unknown to mechanism Health Effect (Effect) Unknown to mechanism Behavior pattern
EMF Health Effect 2003 10 20 21-29 2-10 - - ( ) area spot measurement - - 1 (Exposure) Exposure (Exposure Assesment) EMF Unknown to mechanism Health Effect (Effect) Unknown to mechanism Behavior pattern
슬라이드 제목 없음
 계량치 Gage R&R 1 Gage R&R 의변동 반복성 (Equipment Variation) : EV- 계측장비에의한변동 - 동일측정자가동일조건에서반복하여발생된측정값의범위로부터계산되므로 Gage의변동을평가하게됨. 재현성 (Operator / Appraiser Variation) : AV- 평가자에의한변동 - 서로다른측정자가동일조건에서측정한값의차이로부터 계산되므로측정자에의한변동을평가함.
계량치 Gage R&R 1 Gage R&R 의변동 반복성 (Equipment Variation) : EV- 계측장비에의한변동 - 동일측정자가동일조건에서반복하여발생된측정값의범위로부터계산되므로 Gage의변동을평가하게됨. 재현성 (Operator / Appraiser Variation) : AV- 평가자에의한변동 - 서로다른측정자가동일조건에서측정한값의차이로부터 계산되므로측정자에의한변동을평가함.
<32332D322D303120B9E6BFB5BCAE20C0CCB5BFC1D6312D32302E687770>
 방 영 석 이 동 주 최근 들어 소셜커머스가 차세대 전자상거래 모형으로 부상하고 있다 년 국내에 첫 등장한 이래 소셜커머스 시장 규모는 년 조 원에 달했고 년 조 원을 넘어섰다 온라인 쇼핑몰 혹은 이마켓플레이스 등으로 대표되는 기존의 전 자상거래 모형은 일반적으로 판매자가 상품 가격 과 거래 형태를 제안하고 구매자가 해당 거래를 선택적으로 수용하는 일방향 모형의
방 영 석 이 동 주 최근 들어 소셜커머스가 차세대 전자상거래 모형으로 부상하고 있다 년 국내에 첫 등장한 이래 소셜커머스 시장 규모는 년 조 원에 달했고 년 조 원을 넘어섰다 온라인 쇼핑몰 혹은 이마켓플레이스 등으로 대표되는 기존의 전 자상거래 모형은 일반적으로 판매자가 상품 가격 과 거래 형태를 제안하고 구매자가 해당 거래를 선택적으로 수용하는 일방향 모형의
<30312D303720B9DAC1A4BCF62E666D>
 wz (010), 40«1y J. Kor. Pharm. Sci., Vol. 40, No. 1, 1-7 (010) 생물학적동등성시험을위한통계처리프로그램 (BioEquiv) 의개발 z 1 Áyù Á 3 Á 4 Á 1 1 û w m w, w wx, 3 û w w w, 4 û w w w (009 11 0 Á09 1 11 Á010 1 6 ) Developmet of
wz (010), 40«1y J. Kor. Pharm. Sci., Vol. 40, No. 1, 1-7 (010) 생물학적동등성시험을위한통계처리프로그램 (BioEquiv) 의개발 z 1 Áyù Á 3 Á 4 Á 1 1 û w m w, w wx, 3 û w w w, 4 û w w w (009 11 0 Á09 1 11 Á010 1 6 ) Developmet of
Microsoft PowerPoint - PDF3 SBE 20080417.pptx
 연속형 확률밀도함수 연속형 확률분포함수? 데이터 히스토그램의 정상을 연결하면 확률분포함수가 된다. 이를 이용하여 데이터(표본)의 분포(이는 모집단의 분포와 동일)를 구 하게 된다. 그러나 함수를 구하는 것은 불가능해 보인다. 그래서 현실에서는 확률분포를 가정하게 된다. (예)기다리는 시간: 지수분포, 측정 오 차: 정규분포 Gauss(천문학자): 행성들간 거리
연속형 확률밀도함수 연속형 확률분포함수? 데이터 히스토그램의 정상을 연결하면 확률분포함수가 된다. 이를 이용하여 데이터(표본)의 분포(이는 모집단의 분포와 동일)를 구 하게 된다. 그러나 함수를 구하는 것은 불가능해 보인다. 그래서 현실에서는 확률분포를 가정하게 된다. (예)기다리는 시간: 지수분포, 측정 오 차: 정규분포 Gauss(천문학자): 행성들간 거리
untitled
 R 과함께하는통계학의이해 빅북이라명명된이책은지식공유의세계적인흐름에동참하고지적인업적들이세상과인류의지식이되도록하며, 누구나쉽게접근하고활용할수있는환경을만들고자한다. 이책의저작권은빅북 (www.bigbook.or.kr) 에있으며모든용도로활용할수있다. 다만상업용출판을하고자하는경우에는사전에문서로된허락을받아야한다. 공유와협력의교과서만들기운동본부 R 과함께하는 통계학의이해
R 과함께하는통계학의이해 빅북이라명명된이책은지식공유의세계적인흐름에동참하고지적인업적들이세상과인류의지식이되도록하며, 누구나쉽게접근하고활용할수있는환경을만들고자한다. 이책의저작권은빅북 (www.bigbook.or.kr) 에있으며모든용도로활용할수있다. 다만상업용출판을하고자하는경우에는사전에문서로된허락을받아야한다. 공유와협력의교과서만들기운동본부 R 과함께하는 통계학의이해
통계적 표본조사론 소개
 통계적표본조사론소개 김호 서울대학교보건대학원 표본의대표성 (1) 2 표본의대표성 (2) 3 표본의대표성 (2) 4 표본의대표성 (2) 5 기초개념 전수조사혹은총조사 (census) vs. 표본조사 (sampling survey) : 전수조사가불가능하거나혹은더정확하지않을수도있음 대상모집단 (target population) and 추출모집단 (sampling
통계적표본조사론소개 김호 서울대학교보건대학원 표본의대표성 (1) 2 표본의대표성 (2) 3 표본의대표성 (2) 4 표본의대표성 (2) 5 기초개념 전수조사혹은총조사 (census) vs. 표본조사 (sampling survey) : 전수조사가불가능하거나혹은더정확하지않을수도있음 대상모집단 (target population) and 추출모집단 (sampling
MBA 통계6-12장.ppt
 tatstcs: Descrptve tatstcs: Iferetal tatstcs: Populato: ample: Quattatve : Qualtatve Categorcal : PC Cross sectoal : Tme seres : - Populato: : : Parameter: costat : : Relatve frequec Frequec dstrbuto Frequec
tatstcs: Descrptve tatstcs: Iferetal tatstcs: Populato: ample: Quattatve : Qualtatve Categorcal : PC Cross sectoal : Tme seres : - Populato: : : Parameter: costat : : Relatve frequec Frequec dstrbuto Frequec
Microsoft PowerPoint - chap08.ppt
 제 8 장. Cotext-ree 언어의특성 학습목표 upig e 와 Closure 특성을통해 C 와 guge ily 간의관계이해 Regulr 언어에서의특성과유사점 / 상이점을집중적으로이해할것 개요 언어계통에서 C 의위상을점검해봅시다 Regulr deteriistic C C cotext sesitive pupig les Closure properties d decisio
제 8 장. Cotext-ree 언어의특성 학습목표 upig e 와 Closure 특성을통해 C 와 guge ily 간의관계이해 Regulr 언어에서의특성과유사점 / 상이점을집중적으로이해할것 개요 언어계통에서 C 의위상을점검해봅시다 Regulr deteriistic C C cotext sesitive pupig les Closure properties d decisio
통계적 표본조사론 소개
 통계적표본조사론소개 김호 서울대학교보건대학원 기초개념 전수조사혹은총조사 (census) vs. 표본조사 (sampling survey) : 전수조사가불가능하거나혹은더정확하지않을수도있음 대상모집단 (target population) and 추출모집단 (sampling population): 일치하지않을수도있음 (ex. 전화조사 ) 기초개념 표본오차 (sampling
통계적표본조사론소개 김호 서울대학교보건대학원 기초개념 전수조사혹은총조사 (census) vs. 표본조사 (sampling survey) : 전수조사가불가능하거나혹은더정확하지않을수도있음 대상모집단 (target population) and 추출모집단 (sampling population): 일치하지않을수도있음 (ex. 전화조사 ) 기초개념 표본오차 (sampling
DBPIA-NURIMEDIA
 The e-business Studies Volume 17, Number 6, December, 30, 2016:275~289 Received: 2016/12/02, Accepted: 2016/12/22 Revised: 2016/12/20, Published: 2016/12/30 [ABSTRACT] SNS is used in various fields. Although
The e-business Studies Volume 17, Number 6, December, 30, 2016:275~289 Received: 2016/12/02, Accepted: 2016/12/22 Revised: 2016/12/20, Published: 2016/12/30 [ABSTRACT] SNS is used in various fields. Although
국가기술자격 재위탁 효율성 평가
 - i - - ii - - iii - - iv - - v - - vi - - vii - - viii - - 1 - - 2 - - 3 - - 4 - - 5 - - 6 - - 7 - - 8 - - 9 - - 10 - - 11 - Ⅱ - 12 - - 13 - - 14 - - 15 - - 16 - - 17 - - 18 - - 19 - Ÿ Ÿ Ÿ Ÿ Ÿ Ÿ Ÿ Ÿ Ÿ
- i - - ii - - iii - - iv - - v - - vi - - vii - - viii - - 1 - - 2 - - 3 - - 4 - - 5 - - 6 - - 7 - - 8 - - 9 - - 10 - - 11 - Ⅱ - 12 - - 13 - - 14 - - 15 - - 16 - - 17 - - 18 - - 19 - Ÿ Ÿ Ÿ Ÿ Ÿ Ÿ Ÿ Ÿ Ÿ
저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할
 저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할수없습니다. 변경금지. 귀하는이저작물을개작, 변형또는가공할수없습니다. 귀하는, 이저작물의재이용이나배포의경우,
저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할수없습니다. 변경금지. 귀하는이저작물을개작, 변형또는가공할수없습니다. 귀하는, 이저작물의재이용이나배포의경우,
PowerSHAPE 따라하기 Calculate 버튼을 클릭한다. Close 버튼을 눌러 미러 릴리프 페이지를 닫는다. D 화면을 보기 위하여 F 키를 누른다. - 모델이 다음과 같이 보이게 될 것이다. 열매 만들기 Shape Editor를 이용하여 열매를 만들어 보도록
 PowerSHAPE 따라하기 가구 장식 만들기 이번 호에서는 ArtCAM V를 이용하여 가구 장식물에 대해서 D 조각 파트를 생성해 보도록 하겠다. 중심 잎 만들기 투 레일 스윕 기능을 이용하여 개의 잎을 만들어보도록 하겠다. 미리 준비된 Wood Decoration.art 파일을 불러온다. Main Leaves 벡터 레이어를 on 시킨다. 릴리프 탭에 있는
PowerSHAPE 따라하기 가구 장식 만들기 이번 호에서는 ArtCAM V를 이용하여 가구 장식물에 대해서 D 조각 파트를 생성해 보도록 하겠다. 중심 잎 만들기 투 레일 스윕 기능을 이용하여 개의 잎을 만들어보도록 하겠다. 미리 준비된 Wood Decoration.art 파일을 불러온다. Main Leaves 벡터 레이어를 on 시킨다. 릴리프 탭에 있는
한국성인에서초기황반변성질환과 연관된위험요인연구
 한국성인에서초기황반변성질환과 연관된위험요인연구 한국성인에서초기황반변성질환과 연관된위험요인연구 - - i - - i - - ii - - iii - - iv - χ - v - - vi - - 1 - - 2 - - 3 - - 4 - 그림 1. 연구대상자선정도표 - 5 - - 6 - - 7 - - 8 - 그림 2. 연구의틀 χ - 9 - - 10 - - 11 -
한국성인에서초기황반변성질환과 연관된위험요인연구 한국성인에서초기황반변성질환과 연관된위험요인연구 - - i - - i - - ii - - iii - - iv - χ - v - - vi - - 1 - - 2 - - 3 - - 4 - 그림 1. 연구대상자선정도표 - 5 - - 6 - - 7 - - 8 - 그림 2. 연구의틀 χ - 9 - - 10 - - 11 -
(Microsoft PowerPoint - Ch17_NumAnalysis.ppt [\310\243\310\257 \270\360\265\345])
![(Microsoft PowerPoint - Ch17_NumAnalysis.ppt [\310\243\310\257 \270\360\265\345])](/thumbs/89/99666589.jpg "(Microsoft PowerPoint - Ch17_NumAnalysis.ppt [\310\243\310\257 \270\360\265\345])") 수치해석 6009 Ch7. Polyomial Iterpolatio 다항식보간법 T C ρ kg/m µ N s/m v m /s -40 0 0 50 00 50 00 50 00 400.5.9.0.09 0.946 0.85 0.746 0.675 0.66 0.55.5 0-5.7 0-5.80 0-5.95 0-5.7 0-5.8 0-5.57 0-5.75 0-5.9 0-5.5
수치해석 6009 Ch7. Polyomial Iterpolatio 다항식보간법 T C ρ kg/m µ N s/m v m /s -40 0 0 50 00 50 00 50 00 400.5.9.0.09 0.946 0.85 0.746 0.675 0.66 0.55.5 0-5.7 0-5.80 0-5.95 0-5.7 0-5.8 0-5.57 0-5.75 0-5.9 0-5.5
LaTeX. [width=1em]Rlogo.jpg Sublime Text. ..
![LaTeX. [width=1em]Rlogo.jpg Sublime Text. ..](/thumbs/80/81096693.jpg "LaTeX. [width=1em]Rlogo.jpg Sublime Text. ..") L A TEX 과 을결합한문서작성 Sublime Text 의활용 2015. 01. 31. 차례 1 L A TEX 과활용에유용한 Sublime text 2 LaTeXing 과 Extend 3 LaTeXing 의 Snippet 을활용한 L A TEX 편집 4 L A TEX 과을결합한문서작성 5 Reproducible Research 의응용 활용에 유용한 Sublime
L A TEX 과 을결합한문서작성 Sublime Text 의활용 2015. 01. 31. 차례 1 L A TEX 과활용에유용한 Sublime text 2 LaTeXing 과 Extend 3 LaTeXing 의 Snippet 을활용한 L A TEX 편집 4 L A TEX 과을결합한문서작성 5 Reproducible Research 의응용 활용에 유용한 Sublime
확률과통계6
 확률과통계 6. 이산형확률분포 건국대학교스마트 ICT 융합공학과윤경로 (yoonk@konkuk.ac.kr) 6. 이산형확률분포 6.1 이산균일분포 6.2 이항분포 6.3 초기하분포 6.4 포아송분포 6.5 기하분포 6.6 음이항분포 * ( 제외 ) 6.7 다항분포 * ( 제외 ) 6.1 이산균일분포 [ 정의 6-1] 이산균일분포 (discrete uniform
확률과통계 6. 이산형확률분포 건국대학교스마트 ICT 융합공학과윤경로 (yoonk@konkuk.ac.kr) 6. 이산형확률분포 6.1 이산균일분포 6.2 이항분포 6.3 초기하분포 6.4 포아송분포 6.5 기하분포 6.6 음이항분포 * ( 제외 ) 6.7 다항분포 * ( 제외 ) 6.1 이산균일분포 [ 정의 6-1] 이산균일분포 (discrete uniform
한국보건사회연구원통계학및계량경제학의기초및응용 강의노트 2017 년 4 월 5 월 통계학 : 통계적추론 (Statistical Inference) I. 들어가며 이제통계학에서가장중요한토픽이라고할수있는통계적추론에대해서본격적으로공부를해보도록하겠습니다. 통계적추론을통해연구와관
 I. 들어가며 이제통계학에서가장중요한토픽이라고할수있는통계적추론에대해서본격적으로공부를해보도록하겠습니다. 통계적추론을통해연구와관") 통계학 : 통계적추론 (Statistical Inference) I. 들어가며 이제통계학에서가장중요한토픽이라고할수있는통계적추론에대해서본격적으로공부를해보도록하겠습니다. 통계적추론을통해연구와관련한두가지중요한일을할수가있습니다. i) 한개표본의통계량을토대로모집단에대한결론을내릴수있고 ii) 그결론에어느정도의신뢰를부여할수있는지에대한판단을할수있습니다. 통계적추론은두가지방식으로할수있습니다.
통계학 : 통계적추론 (Statistical Inference) I. 들어가며 이제통계학에서가장중요한토픽이라고할수있는통계적추론에대해서본격적으로공부를해보도록하겠습니다. 통계적추론을통해연구와관련한두가지중요한일을할수가있습니다. i) 한개표본의통계량을토대로모집단에대한결론을내릴수있고 ii) 그결론에어느정도의신뢰를부여할수있는지에대한판단을할수있습니다. 통계적추론은두가지방식으로할수있습니다.
제 1 부 연구 개요
 2 출 문 차 1 부 과업의 개요 25 귀하 1 장 과업의 목적 27 1. 과업의 목적 및 목표 27 보고서를 2012년도 한돈자조금 성과분석 및 향후 사업방향 수립에 관한 연구 용역의 최종보고서로 제출합니다. 2013년 2월 제 2 장 주요 과업 내용 29 1. 과업 진행 과정 29 2. 과정별 수행 방법 30 가. 한돈자조금사업의 경제적 성과분석 30 나.
2 출 문 차 1 부 과업의 개요 25 귀하 1 장 과업의 목적 27 1. 과업의 목적 및 목표 27 보고서를 2012년도 한돈자조금 성과분석 및 향후 사업방향 수립에 관한 연구 용역의 최종보고서로 제출합니다. 2013년 2월 제 2 장 주요 과업 내용 29 1. 과업 진행 과정 29 2. 과정별 수행 방법 30 가. 한돈자조금사업의 경제적 성과분석 30 나.
DBPIA-NURIMEDIA
 e- 비즈니스연구 (The e-business Studies) Volume 17, Number 1, February, 28, 2016:pp. 3~30 ISSN 1229-9936 (Print), ISSN 2466-1716 (Online) 원고접수일심사 ( 수정 ) 게재확정일 2016. 01. 08 2016. 01. 09 2016. 02. 25 ABSTRACT
e- 비즈니스연구 (The e-business Studies) Volume 17, Number 1, February, 28, 2016:pp. 3~30 ISSN 1229-9936 (Print), ISSN 2466-1716 (Online) 원고접수일심사 ( 수정 ) 게재확정일 2016. 01. 08 2016. 01. 09 2016. 02. 25 ABSTRACT
고차원에서의 유의성 검정
 고차원에서의유의성검정 박창이 서울시립대학교통계학과 박창이 ( 서울시립대학교통계학과 ) 고차원에서의유의성검정 1 / 15 학습내용 FDR(false discovery rate) SAM(significance analysis of microarray) FDR 에대한베이지안해석 박창이 ( 서울시립대학교통계학과 ) 고차원에서의유의성검정 2 / 15 서론 I 고차원데이터에서변수들에대한유의성검정
고차원에서의유의성검정 박창이 서울시립대학교통계학과 박창이 ( 서울시립대학교통계학과 ) 고차원에서의유의성검정 1 / 15 학습내용 FDR(false discovery rate) SAM(significance analysis of microarray) FDR 에대한베이지안해석 박창이 ( 서울시립대학교통계학과 ) 고차원에서의유의성검정 2 / 15 서론 I 고차원데이터에서변수들에대한유의성검정
..(..) (..) - statistics
 (..) - statistics") 수치 ( 數値 ) 를이용한자료요약 ( 要約 ) statistics hmkang@hallym.ac.kr 한림대학교 한중시장분석 강희모 ( 한림대학교 ) 수치 ( 數値 ) 를이용한자료요약 ( 要約 ) 1 / 26 수치를 통한 자료의 요약 요약(要約,summary) 많은 자료를 몇 개의 의미(意味)있는 수치로 요약 자료의 분포상태(分布狀態)를 알 수 있는 통계기법(統計技法)
수치 ( 數値 ) 를이용한자료요약 ( 要約 ) statistics hmkang@hallym.ac.kr 한림대학교 한중시장분석 강희모 ( 한림대학교 ) 수치 ( 數値 ) 를이용한자료요약 ( 要約 ) 1 / 26 수치를 통한 자료의 요약 요약(要約,summary) 많은 자료를 몇 개의 의미(意味)있는 수치로 요약 자료의 분포상태(分布狀態)를 알 수 있는 통계기법(統計技法)
R
 R 과데이터분석 상관관계 양창모 청주교육대학교컴퓨터교육과 2015 년여름 양창모 ( 청주교육대학교컴퓨터교육과 ) Data Analysis using R 2015 년여름 1 / 20 상관관계 양적변수quantitative variables 사이의관계relationships를나타내기위하여상관계수correlation coefficients를사용한다. ± 기호를사용하여관계의방향을나타낸다.
R 과데이터분석 상관관계 양창모 청주교육대학교컴퓨터교육과 2015 년여름 양창모 ( 청주교육대학교컴퓨터교육과 ) Data Analysis using R 2015 년여름 1 / 20 상관관계 양적변수quantitative variables 사이의관계relationships를나타내기위하여상관계수correlation coefficients를사용한다. ± 기호를사용하여관계의방향을나타낸다.
DBPIA-NURIMEDIA
 e- 비즈니스연구 (The e-business Studies) Volume 17, Number 1, February, 28, 2016:pp. 293~316 ISSN 1229-9936 (Print), ISSN 2466-1716 (Online) 원고접수일심사 ( 수정 ) 게재확정일 2015. 12. 04 2015. 12. 24 2016. 02. 25 ABSTRACT
e- 비즈니스연구 (The e-business Studies) Volume 17, Number 1, February, 28, 2016:pp. 293~316 ISSN 1229-9936 (Print), ISSN 2466-1716 (Online) 원고접수일심사 ( 수정 ) 게재확정일 2015. 12. 04 2015. 12. 24 2016. 02. 25 ABSTRACT

Microsoft Word - sbe_anova.docx
 ANOVA 기본개요세집단이상인평균비교 => 일원분산분석집단을요인 (factor) 혹은처리효과 (treatment effect) 라하고집단의개별값을수준 (level) 이라한다. 요인이하나인경우 one-way ANOVA 분산분석 (ANOVA Analyss Of VArance) 은실험설계로부터유래, 분산 ( 변동 ) 에의해요인 ( 모형 ) 의유의성를검증한다. 실험관심대상에대한정보를얻기위한계획된테스트나관측절대실험
ANOVA 기본개요세집단이상인평균비교 => 일원분산분석집단을요인 (factor) 혹은처리효과 (treatment effect) 라하고집단의개별값을수준 (level) 이라한다. 요인이하나인경우 one-way ANOVA 분산분석 (ANOVA Analyss Of VArance) 은실험설계로부터유래, 분산 ( 변동 ) 에의해요인 ( 모형 ) 의유의성를검증한다. 실험관심대상에대한정보를얻기위한계획된테스트나관측절대실험
Microsoft Word - Chapter9.doc
 CHAPTER 9 분산분석 9.1. 분산분석개념 분산분석 (ANOVA: Analysis of Variance) 이란종속변수 (dependent variable: 반응변수 : response variable) 의분산 (variation: 변동 통계에서는이를변수가가진정보라한다 ) 을설명하는독립변수 (independent: 설명변수 : explanatory) 의유의성
CHAPTER 9 분산분석 9.1. 분산분석개념 분산분석 (ANOVA: Analysis of Variance) 이란종속변수 (dependent variable: 반응변수 : response variable) 의분산 (variation: 변동 통계에서는이를변수가가진정보라한다 ) 을설명하는독립변수 (independent: 설명변수 : explanatory) 의유의성

 Breathing problems Pa t i e n t: I have been having some breathing problems lately. I always seem to be out of breath no matter what I am d o i n g. ( Nurse : How long have you been experiencing this problem?
Breathing problems Pa t i e n t: I have been having some breathing problems lately. I always seem to be out of breath no matter what I am d o i n g. ( Nurse : How long have you been experiencing this problem?
Microsoft PowerPoint - chap_11_rep.ppt [호환 모드]
![Microsoft PowerPoint - chap_11_rep.ppt [호환 모드]](/thumbs/91/105737384.jpg "Microsoft PowerPoint - chap_11_rep.ppt [호환 모드]") 제 11 강 자기상관 Auocorrelaion 111 유효성 (efficiency, accurae esimaion/predicion) 을위해서는모든체계적인정보가회귀모형에체화되어있어야함 표본의무작위성 (randomness) 은서로다른관측치들에대한오차항들이상관되어있지말아야함을의미함 자기상관 (Auocorrelaion) 은이러한표본의무작위성을위반하게만드는오차항에있는체계적패턴임
제 11 강 자기상관 Auocorrelaion 111 유효성 (efficiency, accurae esimaion/predicion) 을위해서는모든체계적인정보가회귀모형에체화되어있어야함 표본의무작위성 (randomness) 은서로다른관측치들에대한오차항들이상관되어있지말아야함을의미함 자기상관 (Auocorrelaion) 은이러한표본의무작위성을위반하게만드는오차항에있는체계적패턴임
2156년올림픽 100미터육상경기에서여성의우승기록이남성의기록보다빠른첫해로남을수있음 2156년올림픽에서 100m 우승기록은남성의경우 8.098초, 여성은 8.079초로예측 통계적오차 ( 예측구간 ) 를고려하면빠르면 2064년, 늦어도 2788년에는그렇게될것이라고주장 유사
 를고려하면빠르면 2064년, 늦어도 2788년에는그렇게될것이라고주장 유사") 회귀분석 올림픽 100m 우승기록 2004년 9월과학저널 Nature에발표된 Oxford 대학교의임상병리학자인 Andrew Tatem과그의연구진의논문 1900~2004년까지의남성과여성의육상 100m 우승기록을분석하고앞으로최고기록이어떻게변할것인지를예측 2008년베이징올림픽에서남자의우승기록은 9.73±0.144(9.586, 9.874), 여자는 10.57±0.232(10.338,
회귀분석 올림픽 100m 우승기록 2004년 9월과학저널 Nature에발표된 Oxford 대학교의임상병리학자인 Andrew Tatem과그의연구진의논문 1900~2004년까지의남성과여성의육상 100m 우승기록을분석하고앞으로최고기록이어떻게변할것인지를예측 2008년베이징올림픽에서남자의우승기록은 9.73±0.144(9.586, 9.874), 여자는 10.57±0.232(10.338,
Microsoft Word - Software_Ch2_FUNCTION.docx
 Chapter 2 SAS 함수 SAS 함수는소프트웨어에내장되어작업자가손쉽게연산을할수있게데이터값은로그값을계산하려면 LOG() 함수를사용하면된다. 한다. 예를들어 맛보기 EXP() 함수 : () 안의관측치의지수값을구하는함수 RANNOR(seed) 함수 : 평균이 0 이고표준편차가 1인정규분포함수를따르는관측치를생성하는함수, SEED ( 시드 ) 는값을생성할때시작하는위치를나타내는는값으로
Chapter 2 SAS 함수 SAS 함수는소프트웨어에내장되어작업자가손쉽게연산을할수있게데이터값은로그값을계산하려면 LOG() 함수를사용하면된다. 한다. 예를들어 맛보기 EXP() 함수 : () 안의관측치의지수값을구하는함수 RANNOR(seed) 함수 : 평균이 0 이고표준편차가 1인정규분포함수를따르는관측치를생성하는함수, SEED ( 시드 ) 는값을생성할때시작하는위치를나타내는는값으로
878 Yu Kim, Dongjae Kim 지막 용량수준까지도 멈춤 규칙이 만족되지 않아 시행이 종료되지 않는 경우에는 MTD의 추정이 불가 능하다는 단점이 있다. 최근 이 SM방법의 단점을 보완하기 위해 O Quigley 등 (1990)이 제안한 CRM(Continu
이 제안한 CRM(Continu") 한 국 통 계 학 회 논 문 집 2012, 19권, 6호, 877 884 DOI: http://dx.doi.org/10.5351/ckss.2012.19.6.877 Maximum Tolerated Dose Estimation Applied Biased Coin Design in a Phase Ⅰ Clinical Trial Yu Kim a, Dongjae Kim
한 국 통 계 학 회 논 문 집 2012, 19권, 6호, 877 884 DOI: http://dx.doi.org/10.5351/ckss.2012.19.6.877 Maximum Tolerated Dose Estimation Applied Biased Coin Design in a Phase Ⅰ Clinical Trial Yu Kim a, Dongjae Kim
Microsoft Word - skku_TS2.docx
 Statistical Package & Statistics Univariate : Time Series Data () ARMA 개념 ARIMA(Auto-Regressive Integrated Moving-Average) 모형은시계열데이터 { Y t } 의과거치 (previous observation Y t 1,,... ) 들이설명변수인 AR 과과거의오차항 (
Statistical Package & Statistics Univariate : Time Series Data () ARMA 개념 ARIMA(Auto-Regressive Integrated Moving-Average) 모형은시계열데이터 { Y t } 의과거치 (previous observation Y t 1,,... ) 들이설명변수인 AR 과과거의오차항 (
JAVA 프로그래밍실습 실습 1) 실습목표 - 메소드개념이해하기 - 매개변수이해하기 - 새메소드만들기 - Math 클래스의기존메소드이용하기 ( ) 문제 - 직사각형모양의땅이있다. 이땅의둘레, 면적과대각
 실습목표 - 메소드개념이해하기 - 매개변수이해하기 - 새메소드만들기 - Math 클래스의기존메소드이용하기 ( ) 문제 - 직사각형모양의땅이있다. 이땅의둘레, 면적과대각") JAVA 프로그래밍실습 실습 1) 실습목표 - 메소드개념이해하기 - 매개변수이해하기 - 새메소드만들기 - Math 클래스의기존메소드이용하기 ( http://java.sun.com/javase/6/docs/api ) 문제 - 직사각형모양의땅이있다. 이땅의둘레, 면적과대각선의길이를계산하는메소드들을작성하라. 직사각형의가로와세로의길이는주어진다. 대각선의길이는 Math클래스의적절한메소드를이용하여구하라.
JAVA 프로그래밍실습 실습 1) 실습목표 - 메소드개념이해하기 - 매개변수이해하기 - 새메소드만들기 - Math 클래스의기존메소드이용하기 ( http://java.sun.com/javase/6/docs/api ) 문제 - 직사각형모양의땅이있다. 이땅의둘레, 면적과대각선의길이를계산하는메소드들을작성하라. 직사각형의가로와세로의길이는주어진다. 대각선의길이는 Math클래스의적절한메소드를이용하여구하라.
<B4EBC7D0BCF6C7D02DBBEFB0A2C7D4BCF62E687770>
 삼각함수. 삼각함수의덧셈정리 삼각함수의덧셈정리 삼각함수 sin (α + β ), cos (α + β ), tan (α + β ) 등을 α 또는 β 의삼각함수로나 타낼수있다. 각 α 와각 β 에대하여 α >0, β >0이고 0 α - β < β 를만족한다고가정하 자. 다른경우에도같은방법으로증명할수있다. 각 α 와각 β 에대하여 θ = α - β 라고놓자. 위의그림에서원점에서거리가
삼각함수. 삼각함수의덧셈정리 삼각함수의덧셈정리 삼각함수 sin (α + β ), cos (α + β ), tan (α + β ) 등을 α 또는 β 의삼각함수로나 타낼수있다. 각 α 와각 β 에대하여 α >0, β >0이고 0 α - β < β 를만족한다고가정하 자. 다른경우에도같은방법으로증명할수있다. 각 α 와각 β 에대하여 θ = α - β 라고놓자. 위의그림에서원점에서거리가
Chapter 8 단순선형회귀분석과 상관분석
 Chapter 9 회귀모형 regression analysis 9.1 머리말 (Intro) Sir Francis Galton (18-1911) s studies on genetics Heights of parents and children: 부모의신장에비해 세의신장이일반평균치에복귀 (revert to the pop mean) 하는특성을발견하였다. 복귀 (revert)
Chapter 9 회귀모형 regression analysis 9.1 머리말 (Intro) Sir Francis Galton (18-1911) s studies on genetics Heights of parents and children: 부모의신장에비해 세의신장이일반평균치에복귀 (revert to the pop mean) 하는특성을발견하였다. 복귀 (revert)
저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할
 저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할수없습니다. 변경금지. 귀하는이저작물을개작, 변형또는가공할수없습니다. 귀하는, 이저작물의재이용이나배포의경우,
저작자표시 - 비영리 - 변경금지 2.0 대한민국 이용자는아래의조건을따르는경우에한하여자유롭게 이저작물을복제, 배포, 전송, 전시, 공연및방송할수있습니다. 다음과같은조건을따라야합니다 : 저작자표시. 귀하는원저작자를표시하여야합니다. 비영리. 귀하는이저작물을영리목적으로이용할수없습니다. 변경금지. 귀하는이저작물을개작, 변형또는가공할수없습니다. 귀하는, 이저작물의재이용이나배포의경우,
1 경영학을 위한 수학 Final Exam 2015/12/12(토) 13:00-15:00 풀이과정을 모두 명시하시오. 정리를 사용할 경우 명시하시오. 1. (각 6점) 다음 적분을 구하시오 Z 1 4 Z 1 (x + 1) dx (a) 1 (x 1)4 dx 1 Solut
 13:00-15:00 풀이과정을 모두 명시하시오. 정리를 사용할 경우 명시하시오. 1. (각 6점) 다음 적분을 구하시오 Z 1 4 Z 1 (x + 1) dx (a) 1 (x 1)4 dx 1 Solut") 경영학을 위한 수학 Fial Eam 5//(토) :-5: 풀이과정을 모두 명시하시오. 정리를 사용할 경우 명시하시오.. (각 6점) 다음 적분을 구하시오 4 ( ) (a) ( )4 8 8 (b) d이 성립한다. d C C log log (c) 이다. 양변에 적분을 취하면 log C (d) 라 하자. 그러면 d 4이다. 9 9 4 / si (e) cos si
경영학을 위한 수학 Fial Eam 5//(토) :-5: 풀이과정을 모두 명시하시오. 정리를 사용할 경우 명시하시오.. (각 6점) 다음 적분을 구하시오 4 ( ) (a) ( )4 8 8 (b) d이 성립한다. d C C log log (c) 이다. 양변에 적분을 취하면 log C (d) 라 하자. 그러면 d 4이다. 9 9 4 / si (e) cos si
G5 G25 H5 I5 J5 K5 AVERAGE B5 F5 AVERAGE G5 G24 MAX B5 F5 MIN B5 F5 $G$25 0.58 $H$25 $G$25 $G$25 0.58 $H$25 G24 H25 H24 I24 J24 K24 A5 A24 G5 G24, I5
 C15 B6 B12 / B6 B7 C16 F6 F12 / F6 F7 G16 C16/C15 1 C18 B6 B12 / B6 B8 B9 C19 F6 F12 / F6 F8 F9 G19 C19/C18 1 1 G5 G25 H5 I5 J5 K5 AVERAGE B5 F5 AVERAGE G5 G24 MAX B5 F5 MIN B5 F5 $G$25 0.58 $H$25 $G$25
C15 B6 B12 / B6 B7 C16 F6 F12 / F6 F7 G16 C16/C15 1 C18 B6 B12 / B6 B8 B9 C19 F6 F12 / F6 F8 F9 G19 C19/C18 1 1 G5 G25 H5 I5 J5 K5 AVERAGE B5 F5 AVERAGE G5 G24 MAX B5 F5 MIN B5 F5 $G$25 0.58 $H$25 $G$25